MinIO in distributed mode lets you pool multiple drives (even on different machines) into a single object storage server. As drives are distributed across several nodes, distributed MinIO can withstand multiple node failures and yet ensure full data protection.
MinIO in distributed mode can help you setup a highly-available storage system with a single object storage deployment. With distributed MinIO, you can optimally use storage devices, irrespective of their location in a network.
Distributed MinIO provides protection against multiple node/drive failures and [bit rot](https://github.com/minio/minio/blob/master/docs/erasure/README.md#what-is-bit-rot-protection) using [erasure code](https://docs.min.io/docs/minio-erasure-code-quickstart-guide). As the minimum disks required for distributed MinIO is 4 (same as minimum disks required for erasure coding), erasure code automatically kicks in as you launch distributed MinIO.
If one or more disks are offline at the start of a PutObject or NewMultipartUpload operation the object will have additional data protection bits added automatically to provide additional safety for these objects.
A stand-alone MinIO server would go down if the server hosting the disks goes offline. In contrast, a distributed MinIO setup with _m_ servers and _n_ disks will have your data safe as long as _m/2_ servers or _m*n_/2 or more disks are online.
For example, an 16-server distributed setup with 200 disks per node would continue serving files, up to 4 servers can be offline in default configuration i.e around 800 disks down MinIO would continue to read and write objects.
Refer to sizing guide for more understanding on default values chosen depending on your erasure stripe size [here](https://github.com/minio/minio/blob/master/docs/distributed/SIZING.md). Parity settings can be changed using [storage classes](https://github.com/minio/minio/tree/master/docs/erasure/storage-class).
MinIO follows strict **read-after-write** and **list-after-write** consistency model for all i/o operations both in distributed and standalone modes. This consistency model is only guaranteed if you use disk filesystems such as xfs, ext4 or zfs etc.. for distributed setup.
**If MinIO distributed setup is using NFS volumes underneath it is not guaranteed MinIO will provide these consistency guarantees since NFS is not consistent filesystem by design (If you must use NFS we recommend that you atleast use NFSv4 instead of NFSv3).**
If you're aware of stand-alone MinIO set up, the process remains largely the same. MinIO server automatically switches to stand-alone or distributed mode, depending on the command line parameters.
To start a distributed MinIO instance, you just need to pass drive locations as parameters to the minio server command. Then, you’ll need to run the same command on all the participating nodes.
- All the nodes running distributed MinIO should share a common root credentials, for the nodes to connect and trust each other. To achieve this, it is **recommended** to export root user and root password as environment variables, `MINIO_ROOT_USER` and `MINIO_ROOT_PASSWORD`, on all the nodes before executing MinIO server command. If not exported, default `minioadmin/minioadmin` credentials shall be used.
- **MinIO creates erasure-coding sets of _4_ to _16_ drives per set. The number of drives you provide in total must be a multiple of one of those numbers.**
- **MinIO chooses the largest EC set size which divides into the total number of drives or total number of nodes given - making sure to keep the uniform distribution i.e each node participates equal number of drives per set**.
- **Each object is written to a single EC set, and therefore is spread over no more than 16 drives.**
- **All the nodes running distributed MinIO setup are recommended to be homogeneous, i.e. same operating system, same number of disks and same network interconnects.**
- MinIO distributed mode requires **fresh directories**. If required, the drives can be shared with other applications. You can do this by using a sub-directory exclusive to MinIO. For example, if you have mounted your volume under `/export`, pass `/export/data` as arguments to MinIO server.
- The IP addresses and drive paths below are for demonstration purposes only, you need to replace these with the actual IP addresses and drive paths/folders.
- Servers running distributed MinIO instances should be less than 15 minutes apart. You can enable [NTP](http://www.ntp.org/) service as a best practice to ensure same times across servers.
Example 1: Start distributed MinIO instance on n nodes with m drives each mounted at `/export1` to `/exportm` (pictured below), by running this command on all the n nodes:
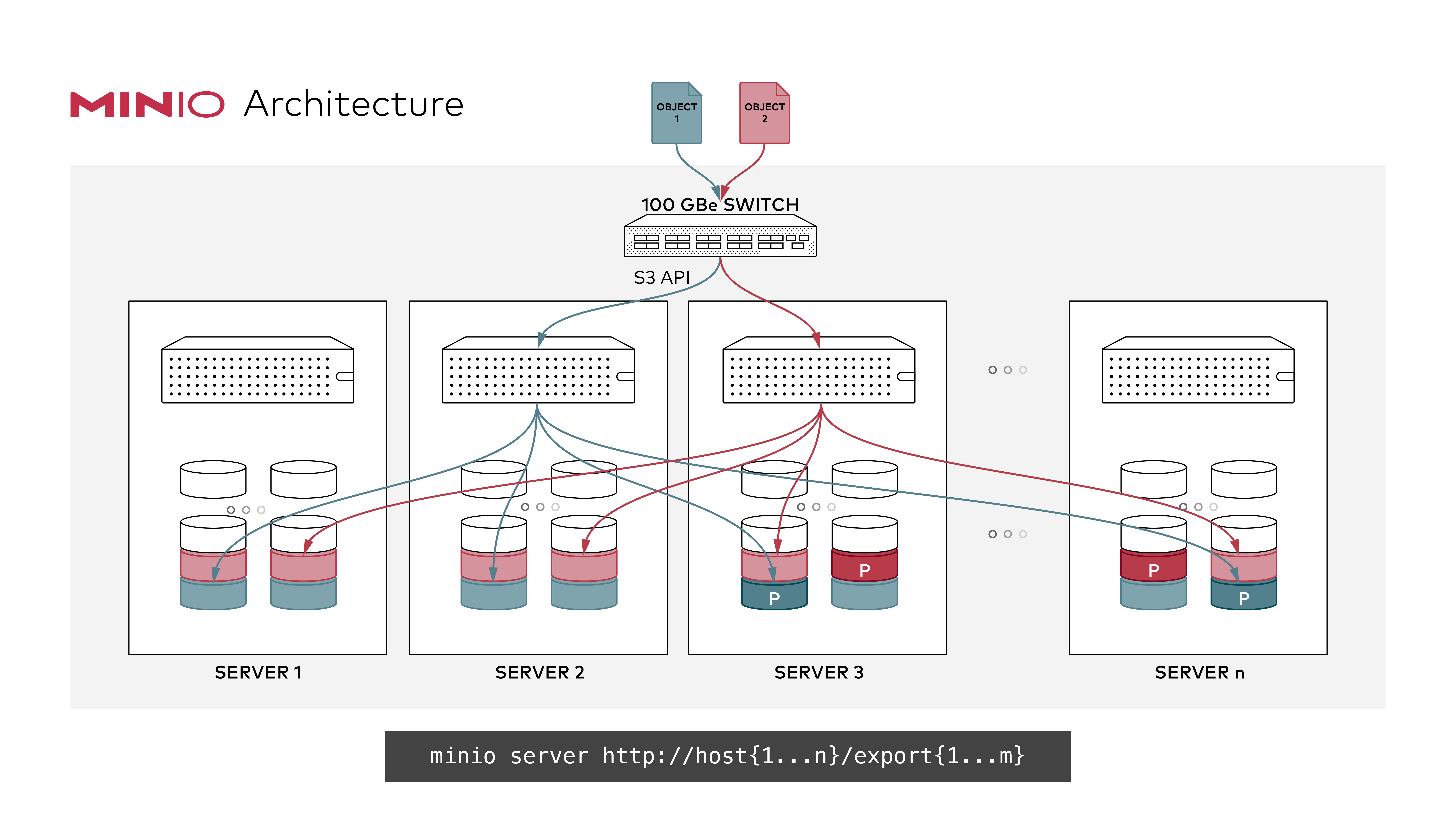
> **NOTE:** In above example `n` and `m` represent positive integers, _do not copy paste and expect it work make the changes according to local deployment and setup_.
> **NOTE:** `{1...n}` shown have 3 dots! Using only 2 dots `{1..n}` will be interpreted by your shell and won't be passed to MinIO server, affecting the erasure coding order, which would impact performance and high availability. **Always use ellipses syntax `{1...n}` (3 dots!) for optimal erasure-code distribution**
Now the server has expanded total storage by _(newly_added_servers\*m)_ more disks, taking the total count to _(existing_servers\*m)+(newly_added_servers\*m)_ disks. New object upload requests automatically start using the least used cluster. This expansion strategy works endlessly, so you can perpetually expand your clusters as needed. When you restart, it is immediate and non-disruptive to the applications. Each group of servers in the command-line is called a pool. There are 2 server pools in this example. New objects are placed in server pools in proportion to the amount of free space in each pool. Within each pool, the location of the erasure-set of drives is determined based on a deterministic hashing algorithm.
> **NOTE:** **Each pool you add must have the same erasure coding parity configuration as the original pool, so the same data redundancy SLA is maintained.**