mirror of
https://github.com/minio/minio.git
synced 2025-11-20 09:56:07 -05:00
Support variable server pools (#11256)
Current implementation requires server pools to have same erasure stripe sizes, to facilitate same SLA and expectations. This PR allows server pools to be variadic, i.e they do not have to be same erasure stripe sizes - instead they should have SLA for parity ratio. If the parity ratio cannot be guaranteed by the new server pool, the deployment is rejected i.e server pool expansion is not allowed.
This commit is contained in:
@@ -97,16 +97,9 @@ func initTestErasureObjLayer(ctx context.Context) (ObjectLayer, []string, error)
|
||||
if err != nil {
|
||||
return nil, nil, err
|
||||
}
|
||||
endpoints := mustGetNewEndpoints(erasureDirs...)
|
||||
storageDisks, format, err := waitForFormatErasure(true, endpoints, 1, 1, 16, "")
|
||||
if err != nil {
|
||||
removeRoots(erasureDirs)
|
||||
return nil, nil, err
|
||||
}
|
||||
|
||||
endpoints := mustGetZoneEndpoints(erasureDirs...)
|
||||
globalPolicySys = NewPolicySys()
|
||||
objLayer := &erasureServerPools{serverPools: make([]*erasureSets, 1)}
|
||||
objLayer.serverPools[0], err = newErasureSets(ctx, endpoints, storageDisks, format)
|
||||
objLayer, err := newErasureServerPools(ctx, endpoints)
|
||||
if err != nil {
|
||||
return nil, nil, err
|
||||
}
|
||||
|
||||
@@ -342,7 +342,7 @@ func validateConfig(s config.Config, setDriveCount int) error {
|
||||
return notify.TestNotificationTargets(GlobalContext, s, NewGatewayHTTPTransport(), globalNotificationSys.ConfiguredTargetIDs())
|
||||
}
|
||||
|
||||
func lookupConfigs(s config.Config, setDriveCount int) {
|
||||
func lookupConfigs(s config.Config, minSetDriveCount int) {
|
||||
ctx := GlobalContext
|
||||
|
||||
var err error
|
||||
@@ -429,7 +429,7 @@ func lookupConfigs(s config.Config, setDriveCount int) {
|
||||
logger.LogIf(ctx, fmt.Errorf("Invalid api configuration: %w", err))
|
||||
}
|
||||
|
||||
globalAPIConfig.init(apiConfig, setDriveCount)
|
||||
globalAPIConfig.init(apiConfig, minSetDriveCount)
|
||||
|
||||
// Initialize remote instance transport once.
|
||||
getRemoteInstanceTransportOnce.Do(func() {
|
||||
@@ -437,7 +437,7 @@ func lookupConfigs(s config.Config, setDriveCount int) {
|
||||
})
|
||||
|
||||
if globalIsErasure {
|
||||
globalStorageClass, err = storageclass.LookupConfig(s[config.StorageClassSubSys][config.Default], setDriveCount)
|
||||
globalStorageClass, err = storageclass.LookupConfig(s[config.StorageClassSubSys][config.Default], minSetDriveCount)
|
||||
if err != nil {
|
||||
logger.LogIf(ctx, fmt.Errorf("Unable to initialize storage class config: %w", err))
|
||||
}
|
||||
|
||||
@@ -88,14 +88,13 @@ var (
|
||||
// StorageClass - holds storage class information
|
||||
type StorageClass struct {
|
||||
Parity int
|
||||
DMA string
|
||||
}
|
||||
|
||||
// Config storage class configuration
|
||||
type Config struct {
|
||||
Standard StorageClass `json:"standard"`
|
||||
RRS StorageClass `json:"rrs"`
|
||||
DMA StorageClass `json:"dma"`
|
||||
DMA string `json:"dma"`
|
||||
}
|
||||
|
||||
// UnmarshalJSON - Validate SS and RRS parity when unmarshalling JSON.
|
||||
@@ -112,7 +111,7 @@ func (sCfg *Config) UnmarshalJSON(data []byte) error {
|
||||
// IsValid - returns true if input string is a valid
|
||||
// storage class kind supported.
|
||||
func IsValid(sc string) bool {
|
||||
return sc == RRS || sc == STANDARD || sc == DMA
|
||||
return sc == RRS || sc == STANDARD
|
||||
}
|
||||
|
||||
// UnmarshalText unmarshals storage class from its textual form into
|
||||
@@ -122,14 +121,6 @@ func (sc *StorageClass) UnmarshalText(b []byte) error {
|
||||
if scStr == "" {
|
||||
return nil
|
||||
}
|
||||
if scStr == DMAWrite {
|
||||
sc.DMA = DMAWrite
|
||||
return nil
|
||||
}
|
||||
if scStr == DMAReadWrite {
|
||||
sc.DMA = DMAReadWrite
|
||||
return nil
|
||||
}
|
||||
s, err := parseStorageClass(scStr)
|
||||
if err != nil {
|
||||
return err
|
||||
@@ -143,14 +134,14 @@ func (sc *StorageClass) MarshalText() ([]byte, error) {
|
||||
if sc.Parity != 0 {
|
||||
return []byte(fmt.Sprintf("%s:%d", schemePrefix, sc.Parity)), nil
|
||||
}
|
||||
return []byte(sc.DMA), nil
|
||||
return []byte{}, nil
|
||||
}
|
||||
|
||||
func (sc *StorageClass) String() string {
|
||||
if sc.Parity != 0 {
|
||||
return fmt.Sprintf("%s:%d", schemePrefix, sc.Parity)
|
||||
}
|
||||
return sc.DMA
|
||||
return ""
|
||||
}
|
||||
|
||||
// Parses given storageClassEnv and returns a storageClass structure.
|
||||
@@ -218,14 +209,16 @@ func validateParity(ssParity, rrsParity, setDriveCount int) (err error) {
|
||||
}
|
||||
|
||||
// GetParityForSC - Returns the data and parity drive count based on storage class
|
||||
// If storage class is set using the env vars MINIO_STORAGE_CLASS_RRS and MINIO_STORAGE_CLASS_STANDARD
|
||||
// or config.json fields
|
||||
// -- corresponding values are returned
|
||||
// If storage class is not set during startup, default values are returned
|
||||
// -- Default for Reduced Redundancy Storage class is, parity = 2 and data = N-Parity
|
||||
// -- Default for Standard Storage class is, parity = N/2, data = N/2
|
||||
// If storage class is empty
|
||||
// -- standard storage class is assumed and corresponding data and parity is returned
|
||||
// If storage class is set using the env vars MINIO_STORAGE_CLASS_RRS and
|
||||
// MINIO_STORAGE_CLASS_STANDARD or server config fields corresponding values are
|
||||
// returned.
|
||||
//
|
||||
// -- if input storage class is empty then standard is assumed
|
||||
// -- if input is RRS but RRS is not configured default '2' parity
|
||||
// for RRS is assumed
|
||||
// -- if input is STANDARD but STANDARD is not configured '0' parity
|
||||
// is returned, the caller is expected to choose the right parity
|
||||
// at that point.
|
||||
func (sCfg Config) GetParityForSC(sc string) (parity int) {
|
||||
switch strings.TrimSpace(sc) {
|
||||
case RRS:
|
||||
@@ -241,7 +234,7 @@ func (sCfg Config) GetParityForSC(sc string) (parity int) {
|
||||
|
||||
// GetDMA - returns DMA configuration.
|
||||
func (sCfg Config) GetDMA() string {
|
||||
return sCfg.DMA.DMA
|
||||
return sCfg.DMA
|
||||
}
|
||||
|
||||
// Enabled returns if etcd is enabled.
|
||||
@@ -254,8 +247,6 @@ func Enabled(kvs config.KVS) bool {
|
||||
// LookupConfig - lookup storage class config and override with valid environment settings if any.
|
||||
func LookupConfig(kvs config.KVS, setDriveCount int) (cfg Config, err error) {
|
||||
cfg = Config{}
|
||||
cfg.Standard.Parity = setDriveCount / 2
|
||||
cfg.RRS.Parity = defaultRRSParity
|
||||
|
||||
if err = config.CheckValidKeys(config.StorageClassSubSys, kvs, DefaultKVS); err != nil {
|
||||
return Config{}, err
|
||||
@@ -271,9 +262,6 @@ func LookupConfig(kvs config.KVS, setDriveCount int) (cfg Config, err error) {
|
||||
return Config{}, err
|
||||
}
|
||||
}
|
||||
if cfg.Standard.Parity == 0 {
|
||||
cfg.Standard.Parity = setDriveCount / 2
|
||||
}
|
||||
|
||||
if rrsc != "" {
|
||||
cfg.RRS, err = parseStorageClass(rrsc)
|
||||
@@ -291,7 +279,7 @@ func LookupConfig(kvs config.KVS, setDriveCount int) (cfg Config, err error) {
|
||||
if dma != DMAReadWrite && dma != DMAWrite {
|
||||
return Config{}, errors.New(`valid dma values are "read-write" and "write"`)
|
||||
}
|
||||
cfg.DMA.DMA = dma
|
||||
cfg.DMA = dma
|
||||
|
||||
// Validation is done after parsing both the storage classes. This is needed because we need one
|
||||
// storage class value to deduce the correct value of the other storage class.
|
||||
|
||||
@@ -276,7 +276,16 @@ func parseEndpointSet(customSetDriveCount uint64, args ...string) (ep endpointSe
|
||||
// specific set size.
|
||||
// For example: {1...64} is divided into 4 sets each of size 16.
|
||||
// This applies to even distributed setup syntax as well.
|
||||
func GetAllSets(customSetDriveCount uint64, args ...string) ([][]string, error) {
|
||||
func GetAllSets(args ...string) ([][]string, error) {
|
||||
var customSetDriveCount uint64
|
||||
if v := env.Get(EnvErasureSetDriveCount, ""); v != "" {
|
||||
driveCount, err := strconv.Atoi(v)
|
||||
if err != nil {
|
||||
return nil, config.ErrInvalidErasureSetSize(err)
|
||||
}
|
||||
customSetDriveCount = uint64(driveCount)
|
||||
}
|
||||
|
||||
var setArgs [][]string
|
||||
if !ellipses.HasEllipses(args...) {
|
||||
var setIndexes [][]uint64
|
||||
@@ -335,16 +344,8 @@ func createServerEndpoints(serverAddr string, args ...string) (
|
||||
return nil, -1, errInvalidArgument
|
||||
}
|
||||
|
||||
var setDriveCount int
|
||||
if v := env.Get(EnvErasureSetDriveCount, ""); v != "" {
|
||||
setDriveCount, err = strconv.Atoi(v)
|
||||
if err != nil {
|
||||
return nil, -1, config.ErrInvalidErasureSetSize(err)
|
||||
}
|
||||
}
|
||||
|
||||
if !ellipses.HasEllipses(args...) {
|
||||
setArgs, err := GetAllSets(uint64(setDriveCount), args...)
|
||||
setArgs, err := GetAllSets(args...)
|
||||
if err != nil {
|
||||
return nil, -1, err
|
||||
}
|
||||
@@ -362,18 +363,23 @@ func createServerEndpoints(serverAddr string, args ...string) (
|
||||
}
|
||||
|
||||
var foundPrevLocal bool
|
||||
var commonParityDrives int
|
||||
|
||||
for _, arg := range args {
|
||||
setArgs, err := GetAllSets(uint64(setDriveCount), arg)
|
||||
setArgs, err := GetAllSets(arg)
|
||||
if err != nil {
|
||||
return nil, -1, err
|
||||
}
|
||||
|
||||
parityDrives := ecDrivesNoConfig(len(setArgs[0]))
|
||||
if commonParityDrives != 0 && commonParityDrives != parityDrives {
|
||||
return nil, -1, fmt.Errorf("All serverPools should have same parity ratio - expected %d, got %d", commonParityDrives, parityDrives)
|
||||
}
|
||||
|
||||
endpointList, gotSetupType, err := CreateEndpoints(serverAddr, foundPrevLocal, setArgs...)
|
||||
if err != nil {
|
||||
return nil, -1, err
|
||||
}
|
||||
if setDriveCount != 0 && setDriveCount != len(setArgs[0]) {
|
||||
return nil, -1, fmt.Errorf("All serverPools should have same drive per set ratio - expected %d, got %d", setDriveCount, len(setArgs[0]))
|
||||
}
|
||||
if err = endpointServerPools.Add(ZoneEndpoints{
|
||||
SetCount: len(setArgs),
|
||||
DrivesPerSet: len(setArgs[0]),
|
||||
@@ -382,9 +388,10 @@ func createServerEndpoints(serverAddr string, args ...string) (
|
||||
return nil, -1, err
|
||||
}
|
||||
foundPrevLocal = endpointList.atleastOneEndpointLocal()
|
||||
if setDriveCount == 0 {
|
||||
setDriveCount = len(setArgs[0])
|
||||
if commonParityDrives == 0 {
|
||||
commonParityDrives = ecDrivesNoConfig(len(setArgs[0]))
|
||||
}
|
||||
|
||||
if setupType == UnknownSetupType {
|
||||
setupType = gotSetupType
|
||||
}
|
||||
|
||||
@@ -42,7 +42,10 @@ func (er erasureObjects) HealBucket(ctx context.Context, bucket string, opts mad
|
||||
storageEndpoints := er.getEndpoints()
|
||||
|
||||
// get write quorum for an object
|
||||
writeQuorum := getWriteQuorum(len(storageDisks))
|
||||
writeQuorum := len(storageDisks) - er.defaultParityCount
|
||||
if writeQuorum == er.defaultParityCount {
|
||||
writeQuorum++
|
||||
}
|
||||
|
||||
// Heal bucket.
|
||||
return healBucket(ctx, storageDisks, storageEndpoints, bucket, writeQuorum, opts)
|
||||
@@ -308,7 +311,7 @@ func (er erasureObjects) healObject(ctx context.Context, bucket string, object s
|
||||
err = toObjectErr(errFileVersionNotFound, bucket, object, versionID)
|
||||
}
|
||||
// File is fully gone, fileInfo is empty.
|
||||
return defaultHealResult(FileInfo{}, storageDisks, storageEndpoints, errs, bucket, object, versionID), err
|
||||
return defaultHealResult(FileInfo{}, storageDisks, storageEndpoints, errs, bucket, object, versionID, er.defaultParityCount), err
|
||||
}
|
||||
|
||||
// If less than read quorum number of disks have all the parts
|
||||
@@ -490,8 +493,8 @@ func (er erasureObjects) healObjectDir(ctx context.Context, bucket, object strin
|
||||
Bucket: bucket,
|
||||
Object: object,
|
||||
DiskCount: len(storageDisks),
|
||||
ParityBlocks: getDefaultParityBlocks(len(storageDisks)),
|
||||
DataBlocks: getDefaultDataBlocks(len(storageDisks)),
|
||||
ParityBlocks: er.defaultParityCount,
|
||||
DataBlocks: len(storageDisks) - er.defaultParityCount,
|
||||
ObjectSize: 0,
|
||||
}
|
||||
|
||||
@@ -562,7 +565,7 @@ func (er erasureObjects) healObjectDir(ctx context.Context, bucket, object strin
|
||||
|
||||
// Populates default heal result item entries with possible values when we are returning prematurely.
|
||||
// This is to ensure that in any circumstance we are not returning empty arrays with wrong values.
|
||||
func defaultHealResult(lfi FileInfo, storageDisks []StorageAPI, storageEndpoints []string, errs []error, bucket, object, versionID string) madmin.HealResultItem {
|
||||
func defaultHealResult(lfi FileInfo, storageDisks []StorageAPI, storageEndpoints []string, errs []error, bucket, object, versionID string, defaultParityCount int) madmin.HealResultItem {
|
||||
// Initialize heal result object
|
||||
result := madmin.HealResultItem{
|
||||
Type: madmin.HealItemObject,
|
||||
@@ -608,8 +611,8 @@ func defaultHealResult(lfi FileInfo, storageDisks []StorageAPI, storageEndpoints
|
||||
|
||||
if !lfi.IsValid() {
|
||||
// Default to most common configuration for erasure blocks.
|
||||
result.ParityBlocks = getDefaultParityBlocks(len(storageDisks))
|
||||
result.DataBlocks = getDefaultDataBlocks(len(storageDisks))
|
||||
result.ParityBlocks = defaultParityCount
|
||||
result.DataBlocks = len(storageDisks) - defaultParityCount
|
||||
} else {
|
||||
result.ParityBlocks = lfi.Erasure.ParityBlocks
|
||||
result.DataBlocks = lfi.Erasure.DataBlocks
|
||||
@@ -690,7 +693,7 @@ func (er erasureObjects) purgeObjectDangling(ctx context.Context, bucket, object
|
||||
if ok {
|
||||
writeQuorum := m.Erasure.DataBlocks
|
||||
if m.Erasure.DataBlocks == 0 || m.Erasure.DataBlocks == m.Erasure.ParityBlocks {
|
||||
writeQuorum = getWriteQuorum(len(storageDisks))
|
||||
writeQuorum++
|
||||
}
|
||||
var err error
|
||||
var returnNotFound bool
|
||||
@@ -722,18 +725,15 @@ func (er erasureObjects) purgeObjectDangling(ctx context.Context, bucket, object
|
||||
if versionID != "" {
|
||||
err = toObjectErr(errFileVersionNotFound, bucket, object, versionID)
|
||||
}
|
||||
return defaultHealResult(m, storageDisks, storageEndpoints, errs, bucket, object, versionID), err
|
||||
return defaultHealResult(m, storageDisks, storageEndpoints, errs, bucket, object, versionID, er.defaultParityCount), err
|
||||
}
|
||||
return defaultHealResult(m, storageDisks, storageEndpoints, errs, bucket, object, versionID), toObjectErr(err, bucket, object, versionID)
|
||||
return defaultHealResult(m, storageDisks, storageEndpoints, errs, bucket, object, versionID, er.defaultParityCount), toObjectErr(err, bucket, object, versionID)
|
||||
}
|
||||
|
||||
readQuorum := m.Erasure.DataBlocks
|
||||
if m.Erasure.DataBlocks == 0 || m.Erasure.DataBlocks == m.Erasure.ParityBlocks {
|
||||
readQuorum = getReadQuorum(len(storageDisks))
|
||||
}
|
||||
readQuorum := len(storageDisks) - er.defaultParityCount
|
||||
|
||||
err := toObjectErr(reduceReadQuorumErrs(ctx, errs, objectOpIgnoredErrs, readQuorum), bucket, object, versionID)
|
||||
return defaultHealResult(m, storageDisks, storageEndpoints, errs, bucket, object, versionID), err
|
||||
return defaultHealResult(m, storageDisks, storageEndpoints, errs, bucket, object, versionID, er.defaultParityCount), err
|
||||
}
|
||||
|
||||
// Object is considered dangling/corrupted if any only
|
||||
@@ -819,7 +819,7 @@ func (er erasureObjects) HealObject(ctx context.Context, bucket, object, version
|
||||
err = toObjectErr(errFileVersionNotFound, bucket, object, versionID)
|
||||
}
|
||||
// Nothing to do, file is already gone.
|
||||
return defaultHealResult(FileInfo{}, storageDisks, storageEndpoints, errs, bucket, object, versionID), err
|
||||
return defaultHealResult(FileInfo{}, storageDisks, storageEndpoints, errs, bucket, object, versionID, er.defaultParityCount), err
|
||||
}
|
||||
|
||||
fi, err := getLatestFileInfo(healCtx, partsMetadata, errs)
|
||||
|
||||
@@ -277,8 +277,8 @@ func TestHealObjectCorrupted(t *testing.T) {
|
||||
|
||||
// Test 4: checks if HealObject returns an error when xl.meta is not found
|
||||
// in more than read quorum number of disks, to create a corrupted situation.
|
||||
for i := 0; i <= len(er.getDisks())/2; i++ {
|
||||
er.getDisks()[i].Delete(context.Background(), bucket, pathJoin(object, xlStorageFormatFile), false)
|
||||
for i := 0; i <= nfi.Erasure.DataBlocks; i++ {
|
||||
erasureDisks[i].Delete(context.Background(), bucket, pathJoin(object, xlStorageFormatFile), false)
|
||||
}
|
||||
|
||||
// Try healing now, expect to receive errFileNotFound.
|
||||
|
||||
@@ -334,7 +334,7 @@ func writeUniqueFileInfo(ctx context.Context, disks []StorageAPI, bucket, prefix
|
||||
// Returns per object readQuorum and writeQuorum
|
||||
// readQuorum is the min required disks to read data.
|
||||
// writeQuorum is the min required disks to write data.
|
||||
func objectQuorumFromMeta(ctx context.Context, er erasureObjects, partsMetaData []FileInfo, errs []error) (objectReadQuorum, objectWriteQuorum int, err error) {
|
||||
func objectQuorumFromMeta(ctx context.Context, partsMetaData []FileInfo, errs []error, defaultParityCount int) (objectReadQuorum, objectWriteQuorum int, err error) {
|
||||
// get the latest updated Metadata and a count of all the latest updated FileInfo(s)
|
||||
latestFileInfo, err := getLatestFileInfo(ctx, partsMetaData, errs)
|
||||
if err != nil {
|
||||
@@ -343,13 +343,13 @@ func objectQuorumFromMeta(ctx context.Context, er erasureObjects, partsMetaData
|
||||
|
||||
dataBlocks := latestFileInfo.Erasure.DataBlocks
|
||||
parityBlocks := globalStorageClass.GetParityForSC(latestFileInfo.Metadata[xhttp.AmzStorageClass])
|
||||
if parityBlocks == 0 {
|
||||
parityBlocks = dataBlocks
|
||||
if parityBlocks <= 0 {
|
||||
parityBlocks = defaultParityCount
|
||||
}
|
||||
|
||||
writeQuorum := dataBlocks
|
||||
if dataBlocks == parityBlocks {
|
||||
writeQuorum = dataBlocks + 1
|
||||
writeQuorum++
|
||||
}
|
||||
|
||||
// Since all the valid erasure code meta updated at the same time are equivalent, pass dataBlocks
|
||||
|
||||
@@ -48,7 +48,7 @@ func (er erasureObjects) checkUploadIDExists(ctx context.Context, bucket, object
|
||||
// Read metadata associated with the object from all disks.
|
||||
metaArr, errs := readAllFileInfo(ctx, disks, minioMetaMultipartBucket, er.getUploadIDDir(bucket, object, uploadID), "", false)
|
||||
|
||||
readQuorum, _, err := objectQuorumFromMeta(ctx, er, metaArr, errs)
|
||||
readQuorum, _, err := objectQuorumFromMeta(ctx, metaArr, errs, er.defaultParityCount)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
@@ -242,18 +242,18 @@ func (er erasureObjects) newMultipartUpload(ctx context.Context, bucket string,
|
||||
|
||||
onlineDisks := er.getDisks()
|
||||
parityBlocks := globalStorageClass.GetParityForSC(opts.UserDefined[xhttp.AmzStorageClass])
|
||||
if parityBlocks == 0 {
|
||||
parityBlocks = len(onlineDisks) / 2
|
||||
if parityBlocks <= 0 {
|
||||
parityBlocks = er.defaultParityCount
|
||||
}
|
||||
dataBlocks := len(onlineDisks) - parityBlocks
|
||||
|
||||
dataBlocks := len(onlineDisks) - parityBlocks
|
||||
fi := newFileInfo(object, dataBlocks, parityBlocks)
|
||||
|
||||
// we now know the number of blocks this object needs for data and parity.
|
||||
// establish the writeQuorum using this data
|
||||
writeQuorum := dataBlocks
|
||||
if dataBlocks == parityBlocks {
|
||||
writeQuorum = dataBlocks + 1
|
||||
writeQuorum++
|
||||
}
|
||||
|
||||
if opts.UserDefined["content-type"] == "" {
|
||||
@@ -374,7 +374,7 @@ func (er erasureObjects) PutObjectPart(ctx context.Context, bucket, object, uplo
|
||||
uploadIDPath, "", false)
|
||||
|
||||
// get Quorum for this object
|
||||
_, writeQuorum, err := objectQuorumFromMeta(ctx, er, partsMetadata, errs)
|
||||
_, writeQuorum, err := objectQuorumFromMeta(ctx, partsMetadata, errs, er.defaultParityCount)
|
||||
if err != nil {
|
||||
return pi, toObjectErr(err, bucket, object)
|
||||
}
|
||||
@@ -555,7 +555,7 @@ func (er erasureObjects) GetMultipartInfo(ctx context.Context, bucket, object, u
|
||||
partsMetadata, errs := readAllFileInfo(ctx, storageDisks, minioMetaMultipartBucket, uploadIDPath, opts.VersionID, false)
|
||||
|
||||
// get Quorum for this object
|
||||
readQuorum, _, err := objectQuorumFromMeta(ctx, er, partsMetadata, errs)
|
||||
readQuorum, _, err := objectQuorumFromMeta(ctx, partsMetadata, errs, er.defaultParityCount)
|
||||
if err != nil {
|
||||
return result, toObjectErr(err, minioMetaMultipartBucket, uploadIDPath)
|
||||
}
|
||||
@@ -603,7 +603,7 @@ func (er erasureObjects) ListObjectParts(ctx context.Context, bucket, object, up
|
||||
partsMetadata, errs := readAllFileInfo(ctx, storageDisks, minioMetaMultipartBucket, uploadIDPath, "", false)
|
||||
|
||||
// get Quorum for this object
|
||||
_, writeQuorum, err := objectQuorumFromMeta(ctx, er, partsMetadata, errs)
|
||||
_, writeQuorum, err := objectQuorumFromMeta(ctx, partsMetadata, errs, er.defaultParityCount)
|
||||
if err != nil {
|
||||
return result, toObjectErr(err, minioMetaMultipartBucket, uploadIDPath)
|
||||
}
|
||||
@@ -707,7 +707,7 @@ func (er erasureObjects) CompleteMultipartUpload(ctx context.Context, bucket str
|
||||
partsMetadata, errs := readAllFileInfo(ctx, storageDisks, minioMetaMultipartBucket, uploadIDPath, "", false)
|
||||
|
||||
// get Quorum for this object
|
||||
_, writeQuorum, err := objectQuorumFromMeta(ctx, er, partsMetadata, errs)
|
||||
_, writeQuorum, err := objectQuorumFromMeta(ctx, partsMetadata, errs, er.defaultParityCount)
|
||||
if err != nil {
|
||||
return oi, toObjectErr(err, bucket, object)
|
||||
}
|
||||
@@ -892,7 +892,7 @@ func (er erasureObjects) AbortMultipartUpload(ctx context.Context, bucket, objec
|
||||
partsMetadata, errs := readAllFileInfo(ctx, er.getDisks(), minioMetaMultipartBucket, uploadIDPath, "", false)
|
||||
|
||||
// get Quorum for this object
|
||||
_, writeQuorum, err := objectQuorumFromMeta(ctx, er, partsMetadata, errs)
|
||||
_, writeQuorum, err := objectQuorumFromMeta(ctx, partsMetadata, errs, er.defaultParityCount)
|
||||
if err != nil {
|
||||
return toObjectErr(err, bucket, object, uploadID)
|
||||
}
|
||||
|
||||
@@ -62,7 +62,7 @@ func (er erasureObjects) CopyObject(ctx context.Context, srcBucket, srcObject, d
|
||||
metaArr, errs := readAllFileInfo(ctx, storageDisks, srcBucket, srcObject, srcOpts.VersionID, false)
|
||||
|
||||
// get Quorum for this object
|
||||
readQuorum, writeQuorum, err := objectQuorumFromMeta(ctx, er, metaArr, errs)
|
||||
readQuorum, writeQuorum, err := objectQuorumFromMeta(ctx, metaArr, errs, er.defaultParityCount)
|
||||
if err != nil {
|
||||
return oi, toObjectErr(err, srcBucket, srcObject)
|
||||
}
|
||||
@@ -380,7 +380,7 @@ func (er erasureObjects) getObjectFileInfo(ctx context.Context, bucket, object s
|
||||
// Read metadata associated with the object from all disks.
|
||||
metaArr, errs := readAllFileInfo(ctx, disks, bucket, object, opts.VersionID, readData)
|
||||
|
||||
readQuorum, _, err := objectQuorumFromMeta(ctx, er, metaArr, errs)
|
||||
readQuorum, _, err := objectQuorumFromMeta(ctx, metaArr, errs, er.defaultParityCount)
|
||||
if err != nil {
|
||||
return fi, nil, nil, err
|
||||
}
|
||||
@@ -595,8 +595,8 @@ func (er erasureObjects) putObject(ctx context.Context, bucket string, object st
|
||||
|
||||
// Get parity and data drive count based on storage class metadata
|
||||
parityDrives := globalStorageClass.GetParityForSC(opts.UserDefined[xhttp.AmzStorageClass])
|
||||
if parityDrives == 0 {
|
||||
parityDrives = getDefaultParityBlocks(len(storageDisks))
|
||||
if parityDrives <= 0 {
|
||||
parityDrives = er.defaultParityCount
|
||||
}
|
||||
dataDrives := len(storageDisks) - parityDrives
|
||||
|
||||
@@ -604,7 +604,7 @@ func (er erasureObjects) putObject(ctx context.Context, bucket string, object st
|
||||
// writeQuorum is dataBlocks + 1
|
||||
writeQuorum := dataDrives
|
||||
if dataDrives == parityDrives {
|
||||
writeQuorum = dataDrives + 1
|
||||
writeQuorum++
|
||||
}
|
||||
|
||||
// Delete temporary object in the event of failure.
|
||||
@@ -1093,7 +1093,7 @@ func (er erasureObjects) PutObjectTags(ctx context.Context, bucket, object strin
|
||||
// Read metadata associated with the object from all disks.
|
||||
metaArr, errs := readAllFileInfo(ctx, disks, bucket, object, opts.VersionID, false)
|
||||
|
||||
readQuorum, writeQuorum, err := objectQuorumFromMeta(ctx, er, metaArr, errs)
|
||||
readQuorum, writeQuorum, err := objectQuorumFromMeta(ctx, metaArr, errs, er.defaultParityCount)
|
||||
if err != nil {
|
||||
return toObjectErr(err, bucket, object)
|
||||
}
|
||||
@@ -1154,7 +1154,7 @@ func (er erasureObjects) updateObjectMeta(ctx context.Context, bucket, object st
|
||||
// Read metadata associated with the object from all disks.
|
||||
metaArr, errs := readAllFileInfo(ctx, disks, bucket, object, opts.VersionID, false)
|
||||
|
||||
readQuorum, writeQuorum, err := objectQuorumFromMeta(ctx, er, metaArr, errs)
|
||||
readQuorum, writeQuorum, err := objectQuorumFromMeta(ctx, metaArr, errs, er.defaultParityCount)
|
||||
if err != nil {
|
||||
return toObjectErr(err, bucket, object)
|
||||
}
|
||||
|
||||
@@ -196,6 +196,13 @@ func TestErasureDeleteObjectsErasureSet(t *testing.T) {
|
||||
}
|
||||
|
||||
func TestErasureDeleteObjectDiskNotFound(t *testing.T) {
|
||||
restoreGlobalStorageClass := globalStorageClass
|
||||
defer func() {
|
||||
globalStorageClass = restoreGlobalStorageClass
|
||||
}()
|
||||
|
||||
globalStorageClass = storageclass.Config{}
|
||||
|
||||
ctx, cancel := context.WithCancel(context.Background())
|
||||
defer cancel()
|
||||
|
||||
@@ -230,7 +237,7 @@ func TestErasureDeleteObjectDiskNotFound(t *testing.T) {
|
||||
erasureDisks := xl.getDisks()
|
||||
z.serverPools[0].erasureDisksMu.Lock()
|
||||
xl.getDisks = func() []StorageAPI {
|
||||
for i := range erasureDisks[:7] {
|
||||
for i := range erasureDisks[:4] {
|
||||
erasureDisks[i] = newNaughtyDisk(erasureDisks[i], nil, errFaultyDisk)
|
||||
}
|
||||
return erasureDisks
|
||||
@@ -501,6 +508,8 @@ func testObjectQuorumFromMeta(obj ObjectLayer, instanceType string, dirs []strin
|
||||
globalStorageClass = restoreGlobalStorageClass
|
||||
}()
|
||||
|
||||
globalStorageClass = storageclass.Config{}
|
||||
|
||||
bucket := getRandomBucketName()
|
||||
|
||||
var opts ObjectOptions
|
||||
@@ -528,7 +537,6 @@ func testObjectQuorumFromMeta(obj ObjectLayer, instanceType string, dirs []strin
|
||||
}
|
||||
|
||||
parts1, errs1 := readAllFileInfo(ctx, erasureDisks, bucket, object1, "", false)
|
||||
|
||||
parts1SC := globalStorageClass
|
||||
|
||||
// Object for test case 2 - No StorageClass defined, MetaData in PutObject requesting RRS Class
|
||||
@@ -626,7 +634,7 @@ func testObjectQuorumFromMeta(obj ObjectLayer, instanceType string, dirs []strin
|
||||
// Reset global storage class flags
|
||||
object7 := "object7"
|
||||
metadata7 := make(map[string]string)
|
||||
metadata7["x-amz-storage-class"] = storageclass.RRS
|
||||
metadata7["x-amz-storage-class"] = storageclass.STANDARD
|
||||
globalStorageClass = storageclass.Config{
|
||||
Standard: storageclass.StorageClass{
|
||||
Parity: 5,
|
||||
@@ -653,19 +661,19 @@ func testObjectQuorumFromMeta(obj ObjectLayer, instanceType string, dirs []strin
|
||||
storageClassCfg storageclass.Config
|
||||
expectedError error
|
||||
}{
|
||||
{parts1, errs1, 8, 9, parts1SC, nil},
|
||||
{parts1, errs1, 12, 12, parts1SC, nil},
|
||||
{parts2, errs2, 14, 14, parts2SC, nil},
|
||||
{parts3, errs3, 8, 9, parts3SC, nil},
|
||||
{parts3, errs3, 12, 12, parts3SC, nil},
|
||||
{parts4, errs4, 10, 10, parts4SC, nil},
|
||||
{parts5, errs5, 14, 14, parts5SC, nil},
|
||||
{parts6, errs6, 8, 9, parts6SC, nil},
|
||||
{parts7, errs7, 14, 14, parts7SC, nil},
|
||||
{parts6, errs6, 12, 12, parts6SC, nil},
|
||||
{parts7, errs7, 11, 11, parts7SC, nil},
|
||||
}
|
||||
for _, tt := range tests {
|
||||
tt := tt
|
||||
t.(*testing.T).Run("", func(t *testing.T) {
|
||||
globalStorageClass = tt.storageClassCfg
|
||||
actualReadQuorum, actualWriteQuorum, err := objectQuorumFromMeta(ctx, *xl, tt.parts, tt.errs)
|
||||
actualReadQuorum, actualWriteQuorum, err := objectQuorumFromMeta(ctx, tt.parts, tt.errs, getDefaultParityBlocks(len(erasureDisks)))
|
||||
if tt.expectedError != nil && err == nil {
|
||||
t.Errorf("Expected %s, got %s", tt.expectedError, err)
|
||||
}
|
||||
|
||||
@@ -78,6 +78,7 @@ func newErasureServerPools(ctx context.Context, endpointServerPools EndpointServ
|
||||
return nil, err
|
||||
}
|
||||
if deploymentID == "" {
|
||||
// all zones should have same deployment ID
|
||||
deploymentID = formats[i].ID
|
||||
}
|
||||
z.serverPools[i], err = newErasureSets(ctx, ep.Endpoints, storageDisks[i], formats[i])
|
||||
@@ -277,15 +278,16 @@ func (z *erasureServerPools) Shutdown(ctx context.Context) error {
|
||||
func (z *erasureServerPools) BackendInfo() (b BackendInfo) {
|
||||
b.Type = BackendErasure
|
||||
|
||||
setDriveCount := z.SetDriveCount()
|
||||
scParity := globalStorageClass.GetParityForSC(storageclass.STANDARD)
|
||||
if scParity == 0 {
|
||||
scParity = z.SetDriveCount() / 2
|
||||
if scParity <= 0 {
|
||||
scParity = z.serverPools[0].defaultParityCount
|
||||
}
|
||||
b.StandardSCData = z.SetDriveCount() - scParity
|
||||
b.StandardSCData = setDriveCount - scParity
|
||||
b.StandardSCParity = scParity
|
||||
|
||||
rrSCParity := globalStorageClass.GetParityForSC(storageclass.RRS)
|
||||
b.RRSCData = z.SetDriveCount() - rrSCParity
|
||||
b.RRSCData = setDriveCount - rrSCParity
|
||||
b.RRSCParity = rrSCParity
|
||||
return
|
||||
}
|
||||
@@ -1437,15 +1439,9 @@ func (z *erasureServerPools) Health(ctx context.Context, opts HealthOptions) Hea
|
||||
|
||||
reqInfo := (&logger.ReqInfo{}).AppendTags("maintenance", strconv.FormatBool(opts.Maintenance))
|
||||
|
||||
parityDrives := globalStorageClass.GetParityForSC(storageclass.STANDARD)
|
||||
diskCount := z.SetDriveCount()
|
||||
|
||||
if parityDrives == 0 {
|
||||
parityDrives = getDefaultParityBlocks(diskCount)
|
||||
}
|
||||
dataDrives := diskCount - parityDrives
|
||||
writeQuorum := dataDrives
|
||||
if dataDrives == parityDrives {
|
||||
b := z.BackendInfo()
|
||||
writeQuorum := b.StandardSCData
|
||||
if b.StandardSCData == b.StandardSCParity {
|
||||
writeQuorum++
|
||||
}
|
||||
|
||||
|
||||
@@ -81,6 +81,7 @@ type erasureSets struct {
|
||||
|
||||
// Total number of sets and the number of disks per set.
|
||||
setCount, setDriveCount int
|
||||
defaultParityCount int
|
||||
|
||||
disksConnectEvent chan diskConnectInfo
|
||||
|
||||
@@ -355,21 +356,36 @@ func newErasureSets(ctx context.Context, endpoints Endpoints, storageDisks []Sto
|
||||
|
||||
endpointStrings := make([]string, len(endpoints))
|
||||
|
||||
// If storage class is not set during startup, default values are used
|
||||
// -- Default for Reduced Redundancy Storage class is, parity = 2
|
||||
// -- Default for Standard Storage class is, parity = 2 - disks 4, 5
|
||||
// -- Default for Standard Storage class is, parity = 3 - disks 6, 7
|
||||
// -- Default for Standard Storage class is, parity = 4 - disks 8 to 16
|
||||
var defaultParityCount int
|
||||
|
||||
switch format.Erasure.DistributionAlgo {
|
||||
case formatErasureVersionV3DistributionAlgoV3:
|
||||
defaultParityCount = getDefaultParityBlocks(setDriveCount)
|
||||
default:
|
||||
defaultParityCount = setDriveCount / 2
|
||||
}
|
||||
|
||||
// Initialize the erasure sets instance.
|
||||
s := &erasureSets{
|
||||
sets: make([]*erasureObjects, setCount),
|
||||
erasureDisks: make([][]StorageAPI, setCount),
|
||||
erasureLockers: make([][]dsync.NetLocker, setCount),
|
||||
erasureLockOwner: GetLocalPeer(globalEndpoints),
|
||||
endpoints: endpoints,
|
||||
endpointStrings: endpointStrings,
|
||||
setCount: setCount,
|
||||
setDriveCount: setDriveCount,
|
||||
format: format,
|
||||
disksConnectEvent: make(chan diskConnectInfo),
|
||||
distributionAlgo: format.Erasure.DistributionAlgo,
|
||||
deploymentID: uuid.MustParse(format.ID),
|
||||
mrfOperations: make(map[healSource]int),
|
||||
sets: make([]*erasureObjects, setCount),
|
||||
erasureDisks: make([][]StorageAPI, setCount),
|
||||
erasureLockers: make([][]dsync.NetLocker, setCount),
|
||||
erasureLockOwner: GetLocalPeer(globalEndpoints),
|
||||
endpoints: endpoints,
|
||||
endpointStrings: endpointStrings,
|
||||
setCount: setCount,
|
||||
setDriveCount: setDriveCount,
|
||||
defaultParityCount: defaultParityCount,
|
||||
format: format,
|
||||
disksConnectEvent: make(chan diskConnectInfo),
|
||||
distributionAlgo: format.Erasure.DistributionAlgo,
|
||||
deploymentID: uuid.MustParse(format.ID),
|
||||
mrfOperations: make(map[healSource]int),
|
||||
}
|
||||
|
||||
mutex := newNSLock(globalIsDistErasure)
|
||||
@@ -416,13 +432,14 @@ func newErasureSets(ctx context.Context, endpoints Endpoints, storageDisks []Sto
|
||||
|
||||
// Initialize erasure objects for a given set.
|
||||
s.sets[i] = &erasureObjects{
|
||||
setDriveCount: setDriveCount,
|
||||
getDisks: s.GetDisks(i),
|
||||
getLockers: s.GetLockers(i),
|
||||
getEndpoints: s.GetEndpoints(i),
|
||||
nsMutex: mutex,
|
||||
bp: bp,
|
||||
mrfOpCh: make(chan partialOperation, 10000),
|
||||
setDriveCount: setDriveCount,
|
||||
defaultParityCount: defaultParityCount,
|
||||
getDisks: s.GetDisks(i),
|
||||
getLockers: s.GetLockers(i),
|
||||
getEndpoints: s.GetEndpoints(i),
|
||||
nsMutex: mutex,
|
||||
bp: bp,
|
||||
mrfOpCh: make(chan partialOperation, 10000),
|
||||
}
|
||||
}
|
||||
|
||||
@@ -466,6 +483,12 @@ func (s *erasureSets) SetDriveCount() int {
|
||||
return s.setDriveCount
|
||||
}
|
||||
|
||||
// ParityCount returns the default parity count used while erasure
|
||||
// coding objects
|
||||
func (s *erasureSets) ParityCount() int {
|
||||
return s.defaultParityCount
|
||||
}
|
||||
|
||||
// StorageUsageInfo - combines output of StorageInfo across all erasure coded object sets.
|
||||
// This only returns disk usage info for ServerPools to perform placement decision, this call
|
||||
// is not implemented in Object interface and is not meant to be used by other object
|
||||
@@ -616,9 +639,9 @@ func crcHashMod(key string, cardinality int) int {
|
||||
|
||||
func hashKey(algo string, key string, cardinality int, id [16]byte) int {
|
||||
switch algo {
|
||||
case formatErasureVersionV2DistributionAlgoLegacy:
|
||||
case formatErasureVersionV2DistributionAlgoV1:
|
||||
return crcHashMod(key, cardinality)
|
||||
case formatErasureVersionV3DistributionAlgo:
|
||||
case formatErasureVersionV3DistributionAlgoV2, formatErasureVersionV3DistributionAlgoV3:
|
||||
return sipHashMod(key, cardinality, id)
|
||||
default:
|
||||
// Unknown algorithm returns -1, also if cardinality is lesser than 0.
|
||||
|
||||
@@ -48,7 +48,8 @@ type partialOperation struct {
|
||||
type erasureObjects struct {
|
||||
GatewayUnsupported
|
||||
|
||||
setDriveCount int
|
||||
setDriveCount int
|
||||
defaultParityCount int
|
||||
|
||||
// getDisks returns list of storageAPIs.
|
||||
getDisks func() []StorageAPI
|
||||
|
||||
@@ -48,10 +48,13 @@ const (
|
||||
formatErasureVersionV3 = "3"
|
||||
|
||||
// Distribution algorithm used, legacy
|
||||
formatErasureVersionV2DistributionAlgoLegacy = "CRCMOD"
|
||||
formatErasureVersionV2DistributionAlgoV1 = "CRCMOD"
|
||||
|
||||
// Distributed algorithm used, current
|
||||
formatErasureVersionV3DistributionAlgo = "SIPMOD"
|
||||
// Distributed algorithm used, with N/2 default parity
|
||||
formatErasureVersionV3DistributionAlgoV2 = "SIPMOD"
|
||||
|
||||
// Distributed algorithm used, with EC:4 default parity
|
||||
formatErasureVersionV3DistributionAlgoV3 = "SIPMOD+PARITY"
|
||||
)
|
||||
|
||||
// Offline disk UUID represents an offline disk.
|
||||
@@ -130,17 +133,13 @@ func (f *formatErasureV3) Clone() *formatErasureV3 {
|
||||
}
|
||||
|
||||
// Returns formatErasure.Erasure.Version
|
||||
func newFormatErasureV3(numSets int, setLen int, distributionAlgo string) *formatErasureV3 {
|
||||
func newFormatErasureV3(numSets int, setLen int) *formatErasureV3 {
|
||||
format := &formatErasureV3{}
|
||||
format.Version = formatMetaVersionV1
|
||||
format.Format = formatBackendErasure
|
||||
format.ID = mustGetUUID()
|
||||
format.Erasure.Version = formatErasureVersionV3
|
||||
if distributionAlgo == "" {
|
||||
format.Erasure.DistributionAlgo = formatErasureVersionV3DistributionAlgo
|
||||
} else {
|
||||
format.Erasure.DistributionAlgo = distributionAlgo
|
||||
}
|
||||
format.Erasure.DistributionAlgo = formatErasureVersionV3DistributionAlgoV3
|
||||
format.Erasure.Sets = make([][]string, numSets)
|
||||
|
||||
for i := 0; i < numSets; i++ {
|
||||
@@ -230,7 +229,7 @@ func formatErasureMigrateV1ToV2(export, version string) error {
|
||||
formatV2.Version = formatMetaVersionV1
|
||||
formatV2.Format = formatBackendErasure
|
||||
formatV2.Erasure.Version = formatErasureVersionV2
|
||||
formatV2.Erasure.DistributionAlgo = formatErasureVersionV2DistributionAlgoLegacy
|
||||
formatV2.Erasure.DistributionAlgo = formatErasureVersionV2DistributionAlgoV1
|
||||
formatV2.Erasure.This = formatV1.Erasure.Disk
|
||||
formatV2.Erasure.Sets = make([][]string, 1)
|
||||
formatV2.Erasure.Sets[0] = make([]string, len(formatV1.Erasure.JBOD))
|
||||
@@ -471,9 +470,9 @@ func checkFormatErasureValues(formats []*formatErasureV3, setDriveCount int) err
|
||||
return fmt.Errorf("%s disk is already being used in another erasure deployment. (Number of disks specified: %d but the number of disks found in the %s disk's format.json: %d)",
|
||||
humanize.Ordinal(i+1), len(formats), humanize.Ordinal(i+1), len(formatErasure.Erasure.Sets)*len(formatErasure.Erasure.Sets[0]))
|
||||
}
|
||||
// Only if custom erasure drive count is set,
|
||||
// we should fail here other proceed to honor what
|
||||
// is present on the disk.
|
||||
// Only if custom erasure drive count is set, verify if the
|
||||
// set_drive_count was manually set - we need to honor what is
|
||||
// present on the drives.
|
||||
if globalCustomErasureDriveCount && len(formatErasure.Erasure.Sets[0]) != setDriveCount {
|
||||
return fmt.Errorf("%s disk is already formatted with %d drives per erasure set. This cannot be changed to %d, please revert your MINIO_ERASURE_SET_DRIVE_COUNT setting", humanize.Ordinal(i+1), len(formatErasure.Erasure.Sets[0]), setDriveCount)
|
||||
}
|
||||
@@ -838,8 +837,8 @@ func fixFormatErasureV3(storageDisks []StorageAPI, endpoints Endpoints, formats
|
||||
}
|
||||
|
||||
// initFormatErasure - save Erasure format configuration on all disks.
|
||||
func initFormatErasure(ctx context.Context, storageDisks []StorageAPI, setCount, setDriveCount int, distributionAlgo string, deploymentID string, sErrs []error) (*formatErasureV3, error) {
|
||||
format := newFormatErasureV3(setCount, setDriveCount, distributionAlgo)
|
||||
func initFormatErasure(ctx context.Context, storageDisks []StorageAPI, setCount, setDriveCount int, deploymentID string, sErrs []error) (*formatErasureV3, error) {
|
||||
format := newFormatErasureV3(setCount, setDriveCount)
|
||||
formats := make([]*formatErasureV3, len(storageDisks))
|
||||
wantAtMost := ecDrivesNoConfig(setDriveCount)
|
||||
|
||||
@@ -890,18 +889,25 @@ func initFormatErasure(ctx context.Context, storageDisks []StorageAPI, setCount,
|
||||
return getFormatErasureInQuorum(formats)
|
||||
}
|
||||
|
||||
func getDefaultParityBlocks(drive int) int {
|
||||
switch drive {
|
||||
case 3, 2:
|
||||
return 1
|
||||
case 4, 5:
|
||||
return 2
|
||||
case 6, 7:
|
||||
return 3
|
||||
default:
|
||||
return 4
|
||||
}
|
||||
}
|
||||
|
||||
// ecDrivesNoConfig returns the erasure coded drives in a set if no config has been set.
|
||||
// It will attempt to read it from env variable and fall back to drives/2.
|
||||
func ecDrivesNoConfig(setDriveCount int) int {
|
||||
ecDrives := globalStorageClass.GetParityForSC(storageclass.STANDARD)
|
||||
if ecDrives == 0 {
|
||||
cfg, err := storageclass.LookupConfig(nil, setDriveCount)
|
||||
if err == nil {
|
||||
ecDrives = cfg.Standard.Parity
|
||||
}
|
||||
if ecDrives == 0 {
|
||||
ecDrives = setDriveCount / 2
|
||||
}
|
||||
if ecDrives <= 0 {
|
||||
ecDrives = getDefaultParityBlocks(setDriveCount)
|
||||
}
|
||||
return ecDrives
|
||||
}
|
||||
|
||||
@@ -43,7 +43,8 @@ func TestFixFormatV3(t *testing.T) {
|
||||
}
|
||||
}
|
||||
|
||||
format := newFormatErasureV3(1, 8, "CRCMOD")
|
||||
format := newFormatErasureV3(1, 8)
|
||||
format.Erasure.DistributionAlgo = formatErasureVersionV2DistributionAlgoV1
|
||||
formats := make([]*formatErasureV3, 8)
|
||||
|
||||
for j := 0; j < 8; j++ {
|
||||
@@ -77,7 +78,8 @@ func TestFixFormatV3(t *testing.T) {
|
||||
|
||||
// tests formatErasureV3ThisEmpty conditions.
|
||||
func TestFormatErasureEmpty(t *testing.T) {
|
||||
format := newFormatErasureV3(1, 16, "CRCMOD")
|
||||
format := newFormatErasureV3(1, 16)
|
||||
format.Erasure.DistributionAlgo = formatErasureVersionV2DistributionAlgoV1
|
||||
formats := make([]*formatErasureV3, 16)
|
||||
|
||||
for j := 0; j < 16; j++ {
|
||||
@@ -276,7 +278,8 @@ func TestGetFormatErasureInQuorumCheck(t *testing.T) {
|
||||
setCount := 2
|
||||
setDriveCount := 16
|
||||
|
||||
format := newFormatErasureV3(setCount, setDriveCount, "CRCMOD")
|
||||
format := newFormatErasureV3(setCount, setDriveCount)
|
||||
format.Erasure.DistributionAlgo = formatErasureVersionV2DistributionAlgoV1
|
||||
formats := make([]*formatErasureV3, 32)
|
||||
|
||||
for i := 0; i < setCount; i++ {
|
||||
@@ -342,7 +345,8 @@ func TestGetErasureID(t *testing.T) {
|
||||
setCount := 2
|
||||
setDriveCount := 8
|
||||
|
||||
format := newFormatErasureV3(setCount, setDriveCount, "CRCMOD")
|
||||
format := newFormatErasureV3(setCount, setDriveCount)
|
||||
format.Erasure.DistributionAlgo = formatErasureVersionV2DistributionAlgoV1
|
||||
formats := make([]*formatErasureV3, 16)
|
||||
|
||||
for i := 0; i < setCount; i++ {
|
||||
@@ -397,7 +401,8 @@ func TestNewFormatSets(t *testing.T) {
|
||||
setCount := 2
|
||||
setDriveCount := 16
|
||||
|
||||
format := newFormatErasureV3(setCount, setDriveCount, "CRCMOD")
|
||||
format := newFormatErasureV3(setCount, setDriveCount)
|
||||
format.Erasure.DistributionAlgo = formatErasureVersionV2DistributionAlgoV1
|
||||
formats := make([]*formatErasureV3, 32)
|
||||
errs := make([]error, 32)
|
||||
|
||||
|
||||
@@ -340,8 +340,8 @@ func testGetObjectDiskNotFound(obj ObjectLayer, instanceType string, disks []str
|
||||
}
|
||||
}
|
||||
|
||||
// Take 8 disks down before GetObject is called, one more we loose quorum on 16 disk node.
|
||||
for _, disk := range disks[:8] {
|
||||
// Take 4 disks down before GetObject is called, one more we loose quorum on 16 disk node.
|
||||
for _, disk := range disks[:4] {
|
||||
os.RemoveAll(disk)
|
||||
}
|
||||
|
||||
|
||||
@@ -225,8 +225,8 @@ func testObjectAPIPutObjectDiskNotFound(obj ObjectLayer, instanceType string, di
|
||||
t.Fatalf("%s : %s", instanceType, err.Error())
|
||||
}
|
||||
|
||||
// Take 8 disks down, one more we loose quorum on 16 disk node.
|
||||
for _, disk := range disks[:7] {
|
||||
// Take 4 disks down, one more we loose quorum on 16 disk node.
|
||||
for _, disk := range disks[:4] {
|
||||
os.RemoveAll(disk)
|
||||
}
|
||||
|
||||
|
||||
@@ -276,7 +276,7 @@ func connectLoadInitFormats(retryCount int, firstDisk bool, endpoints Endpoints,
|
||||
humanize.Ordinal(poolCount), setCount, setDriveCount)
|
||||
|
||||
// Initialize erasure code format on disks
|
||||
format, err = initFormatErasure(GlobalContext, storageDisks, setCount, setDriveCount, "", deploymentID, sErrs)
|
||||
format, err = initFormatErasure(GlobalContext, storageDisks, setCount, setDriveCount, deploymentID, sErrs)
|
||||
if err != nil {
|
||||
return nil, nil, err
|
||||
}
|
||||
|
||||
15
cmd/utils.go
15
cmd/utils.go
@@ -92,21 +92,14 @@ func path2BucketObject(s string) (bucket, prefix string) {
|
||||
return path2BucketObjectWithBasePath("", s)
|
||||
}
|
||||
|
||||
func getDefaultParityBlocks(drive int) int {
|
||||
return drive / 2
|
||||
}
|
||||
|
||||
func getDefaultDataBlocks(drive int) int {
|
||||
func getReadQuorum(drive int) int {
|
||||
return drive - getDefaultParityBlocks(drive)
|
||||
}
|
||||
|
||||
func getReadQuorum(drive int) int {
|
||||
return getDefaultDataBlocks(drive)
|
||||
}
|
||||
|
||||
func getWriteQuorum(drive int) int {
|
||||
quorum := getDefaultDataBlocks(drive)
|
||||
if getDefaultParityBlocks(drive) == quorum {
|
||||
parity := getDefaultParityBlocks(drive)
|
||||
quorum := drive - parity
|
||||
if quorum == parity {
|
||||
quorum++
|
||||
}
|
||||
return quorum
|
||||
|
||||
@@ -571,7 +571,7 @@ func (s *xlStorage) GetDiskID() (string, error) {
|
||||
s.Lock()
|
||||
defer s.Unlock()
|
||||
s.diskID = format.Erasure.This
|
||||
s.formatLegacy = format.Erasure.DistributionAlgo == formatErasureVersionV2DistributionAlgoLegacy
|
||||
s.formatLegacy = format.Erasure.DistributionAlgo == formatErasureVersionV2DistributionAlgoV1
|
||||
s.formatFileInfo = fi
|
||||
s.formatLastCheck = time.Now()
|
||||
return s.diskID, nil
|
||||
|
||||
@@ -1152,7 +1152,7 @@ func TestXLStorageReadFile(t *testing.T) {
|
||||
for l := 0; l < 2; l++ {
|
||||
// 1st loop tests with dma=write, 2nd loop tests with dma=read-write.
|
||||
if l == 1 {
|
||||
globalStorageClass.DMA.DMA = storageclass.DMAReadWrite
|
||||
globalStorageClass.DMA = storageclass.DMAReadWrite
|
||||
}
|
||||
// Following block validates all ReadFile test cases.
|
||||
for i, testCase := range testCases {
|
||||
@@ -1212,7 +1212,7 @@ func TestXLStorageReadFile(t *testing.T) {
|
||||
}
|
||||
|
||||
// Reset the flag.
|
||||
globalStorageClass.DMA.DMA = storageclass.DMAWrite
|
||||
globalStorageClass.DMA = storageclass.DMAWrite
|
||||
|
||||
// TestXLStorage for permission denied.
|
||||
if runtime.GOOS != globalWindowsOSName {
|
||||
|
||||
@@ -26,7 +26,7 @@ GET requests by specifying a version ID as shown below, you can retrieve the spe
|
||||
|
||||
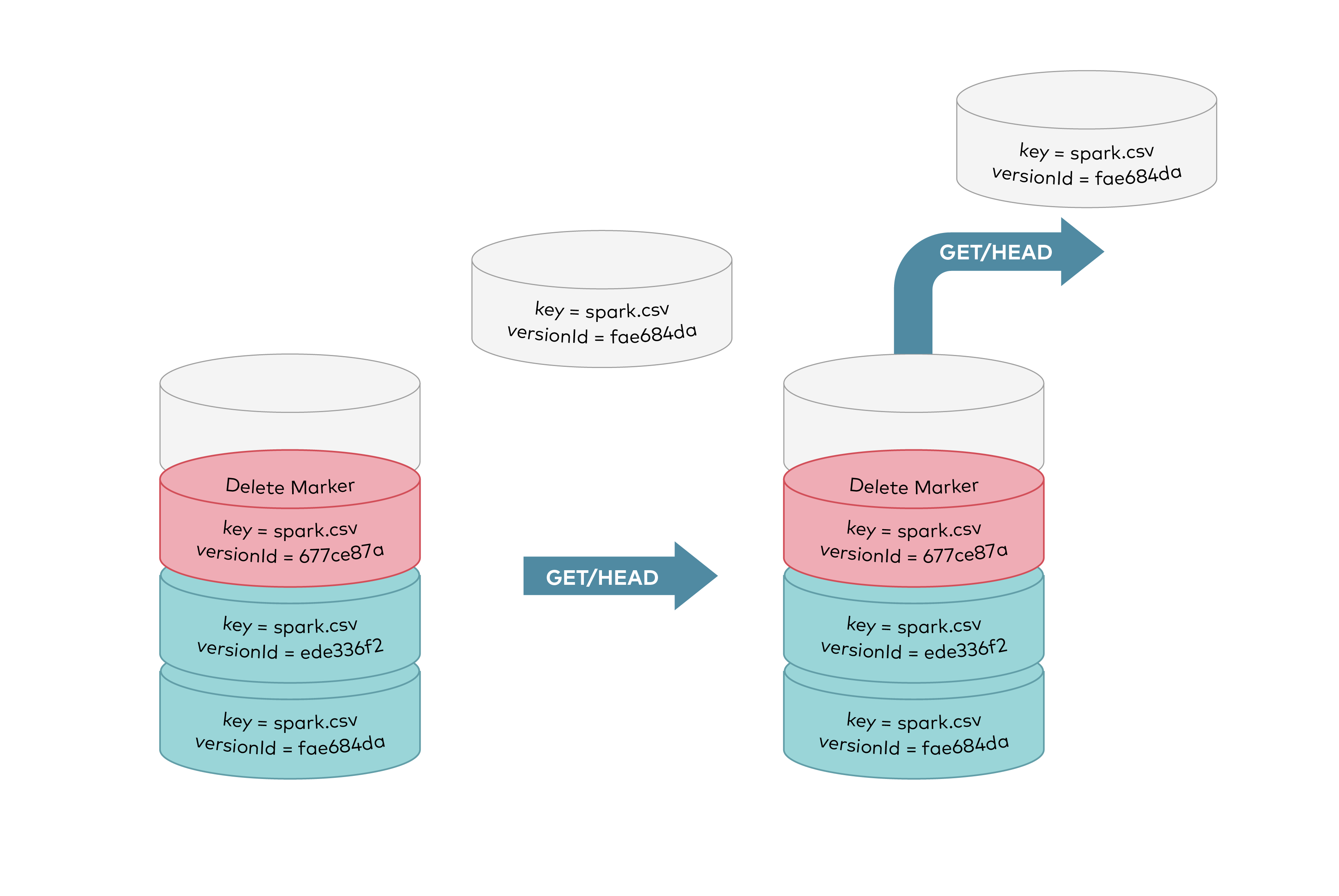
|
||||
|
||||
To permanently delete an object you need to specify the version you want to delete. Only the user with appropriate permissions can permanently delete a version. As shown below, a DELETE request called with a specific version id permanently deletes an object from a bucket. A delete marker is not added for DELETE requests with version id.
|
||||
To permanently delete an object you need to specify the version you want to delete, only the user with appropriate permissions can permanently delete a version. As shown below DELETE request called with a specific version id permanently deletes an object from a bucket. Delete marker is not added for DELETE requests with version id.
|
||||
|
||||
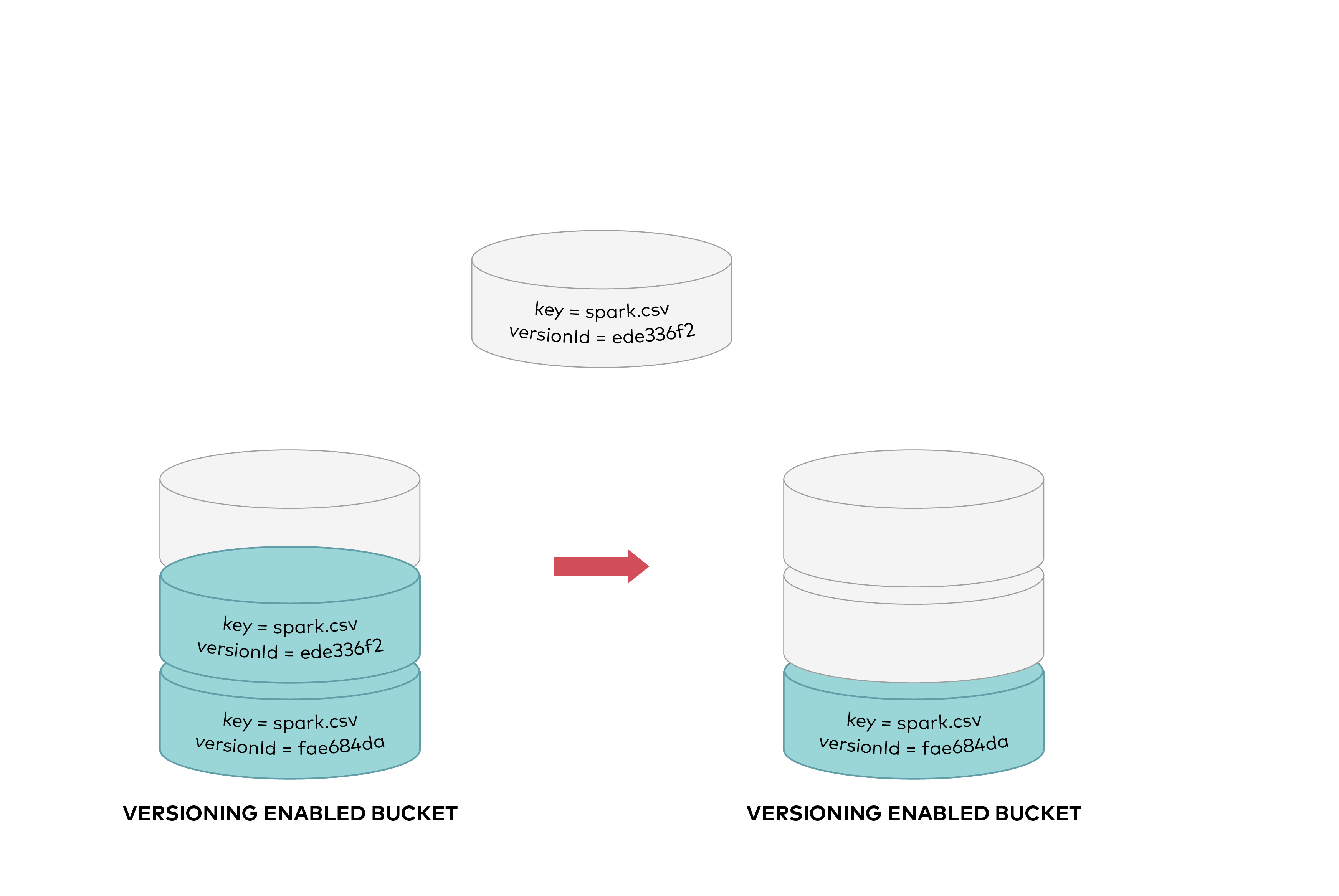
|
||||
|
||||
|
||||
@@ -94,20 +94,22 @@ Input for the key is the object name specified in `PutObject()`, returns a uniqu
|
||||
|
||||
- MinIO does erasure coding at the object level not at the volume level, unlike other object storage vendors. This allows applications to choose different storage class by setting `x-amz-storage-class=STANDARD/REDUCED_REDUNDANCY` for each object uploads so effectively utilizing the capacity of the cluster. Additionally these can also be enforced using IAM policies to make sure the client uploads with correct HTTP headers.
|
||||
|
||||
- MinIO also supports expansion of existing clusters in server pools. Each pool is a self contained entity with same SLA's (read/write quorum) for each object as original cluster. By using the existing namespace for lookup validation MinIO ensures conflicting objects are not created. When no such object exists then MinIO simply uses the least used pool.
|
||||
- MinIO also supports expansion of existing clusters in server pools. Each pool is a self contained entity with same SLA's (read/write quorum) for each object as original cluster. By using the existing namespace for lookup validation MinIO ensures conflicting objects are not created. When no such object exists then MinIO simply uses the least used pool to place new objects.
|
||||
|
||||
__There are no limits on how many server pools can be combined__
|
||||
|
||||
```
|
||||
minio server http://host{1...32}/export{1...32} http://host{5...6}/export{1...8}
|
||||
minio server http://host{1...32}/export{1...32} http://host{1...12}/export{1...12}
|
||||
```
|
||||
|
||||
In above example there are two server pools
|
||||
|
||||
- 32 * 32 = 1024 drives pool1
|
||||
- 2 * 8 = 16 drives pool2
|
||||
- 12 * 12 = 144 drives pool2
|
||||
|
||||
> Notice the requirement of common SLA here original cluster had 1024 drives with 16 drives per erasure set, second pool is expected to have a minimum of 16 drives to match the original cluster SLA or it should be in multiples of 16.
|
||||
> Notice the requirement of common SLA here original cluster had 1024 drives with 16 drives per erasure set with default parity of '4', second pool is expected to have a minimum of 8 drives per erasure set to match the original cluster SLA (parity count) of '4'. '12' drives stripe per erasure set in the second pool satisfies the original pool's parity count.
|
||||
|
||||
Refer to the sizing guide with details on the default parity count chosen for different erasure stripe sizes [here](https://github.com/minio/minio/blob/master/docs/distributed/SIZING.md)
|
||||
|
||||
MinIO places new objects in server pools based on proportionate free space, per pool. Following pseudo code demonstrates this behavior.
|
||||
```go
|
||||
|
||||
@@ -14,9 +14,9 @@ Distributed MinIO provides protection against multiple node/drive failures and [
|
||||
|
||||
A stand-alone MinIO server would go down if the server hosting the disks goes offline. In contrast, a distributed MinIO setup with _m_ servers and _n_ disks will have your data safe as long as _m/2_ servers or _m*n_/2 or more disks are online.
|
||||
|
||||
For example, an 16-server distributed setup with 200 disks per node would continue serving files, even if up to 8 servers are offline in default configuration i.e around 1600 disks can down MinIO would continue service files. But, you'll need at least 9 servers online to create new objects.
|
||||
For example, an 16-server distributed setup with 200 disks per node would continue serving files, up to 4 servers can be offline in default configuration i.e around 800 disks down MinIO would continue to read and write objects.
|
||||
|
||||
You can also use [storage classes](https://github.com/minio/minio/tree/master/docs/erasure/storage-class) to set custom parity distribution per object.
|
||||
Refer to sizing guide for more understanding on default values chosen depending on your erasure stripe size [here](https://github.com/minio/minio/blob/master/docs/distributed/SIZING.md). Parity settings can be changed using [storage classes](https://github.com/minio/minio/tree/master/docs/erasure/storage-class).
|
||||
|
||||
### Consistency Guarantees
|
||||
|
||||
@@ -38,14 +38,14 @@ __NOTE:__
|
||||
|
||||
- All the nodes running distributed MinIO need to have same access key and secret key for the nodes to connect. To achieve this, it is __recommended__ to export access key and secret key as environment variables, `MINIO_ROOT_USER` and `MINIO_ROOT_PASSWORD`, on all the nodes before executing MinIO server command.
|
||||
- __MinIO creates erasure-coding sets of *4* to *16* drives per set. The number of drives you provide in total must be a multiple of one of those numbers.__
|
||||
- __MinIO chooses the largest EC set size which divides into the total number of drives or total number of nodes given - making sure to keep the uniform distribution i.e each node participates equal number of drives per set.
|
||||
- __MinIO chooses the largest EC set size which divides into the total number of drives or total number of nodes given - making sure to keep the uniform distribution i.e each node participates equal number of drives per set__.
|
||||
- __Each object is written to a single EC set, and therefore is spread over no more than 16 drives.__
|
||||
- __All the nodes running distributed MinIO setup are recommended to be homogeneous, i.e. same operating system, same number of disks and same network interconnects.__
|
||||
- MinIO distributed mode requires __fresh directories__. If required, the drives can be shared with other applications. You can do this by using a sub-directory exclusive to MinIO. For example, if you have mounted your volume under `/export`, pass `/export/data` as arguments to MinIO server.
|
||||
- The IP addresses and drive paths below are for demonstration purposes only, you need to replace these with the actual IP addresses and drive paths/folders.
|
||||
- Servers running distributed MinIO instances should be less than 15 minutes apart. You can enable [NTP](http://www.ntp.org/) service as a best practice to ensure same times across servers.
|
||||
- `MINIO_DOMAIN` environment variable should be defined and exported for bucket DNS style support.
|
||||
- Running Distributed MinIO on __Windows__ operating system is experimental. Please proceed with caution.
|
||||
- Running Distributed MinIO on __Windows__ operating system is considered **experimental**. Please proceed with caution.
|
||||
|
||||
Example 1: Start distributed MinIO instance on n nodes with m drives each mounted at `/export1` to `/exportm` (pictured below), by running this command on all the n nodes:
|
||||
|
||||
@@ -79,8 +79,7 @@ minio server http://host{1...4}/export{1...16} http://host{5...12}/export{1...16
|
||||
|
||||
Now the server has expanded total storage by _(newly_added_servers\*m)_ more disks, taking the total count to _(existing_servers\*m)+(newly_added_servers\*m)_ disks. New object upload requests automatically start using the least used cluster. This expansion strategy works endlessly, so you can perpetually expand your clusters as needed. When you restart, it is immediate and non-disruptive to the applications. Each group of servers in the command-line is called a pool. There are 2 server pools in this example. New objects are placed in server pools in proportion to the amount of free space in each pool. Within each pool, the location of the erasure-set of drives is determined based on a deterministic hashing algorithm.
|
||||
|
||||
> __NOTE:__ __Each pool you add must have the same erasure coding set size as the original pool, so the same data redundancy SLA is maintained.__
|
||||
> For example, if your first pool was 8 drives, you could add further server pools of 16, 32 or 1024 drives each. All you have to make sure is deployment SLA is multiples of original data redundancy SLA i.e 8.
|
||||
> __NOTE:__ __Each pool you add must have the same erasure coding parity configuration as the original pool, so the same data redundancy SLA is maintained.__
|
||||
|
||||
## 3. Test your setup
|
||||
To test this setup, access the MinIO server via browser or [`mc`](https://docs.min.io/docs/minio-client-quickstart-guide).
|
||||
|
||||
34
docs/distributed/SIZING.md
Normal file
34
docs/distributed/SIZING.md
Normal file
@@ -0,0 +1,34 @@
|
||||
## Erasure code sizing guide
|
||||
|
||||
### Toy Setups
|
||||
|
||||
Capacity constrained environments, MinIO will work but not recommended for production.
|
||||
|
||||
| servers | drives (per node) | stripe_size | parity chosen (default) | tolerance for reads (servers) | tolerance for writes (servers) |
|
||||
|--------:|------------------:|------------:|------------------------:|------------------------------:|-------------------------------:|
|
||||
| 1 | 1 | 1 | 0 | 0 | 0 |
|
||||
| 1 | 4 | 4 | 2 | 0 | 0 |
|
||||
| 4 | 1 | 4 | 2 | 2 | 3 |
|
||||
| 5 | 1 | 5 | 2 | 2 | 2 |
|
||||
| 6 | 1 | 6 | 3 | 3 | 4 |
|
||||
| 7 | 1 | 7 | 3 | 3 | 3 |
|
||||
|
||||
### Minimum System Configuration for Production
|
||||
|
||||
| servers | drives (per node) | stripe_size | parity chosen (default) | tolerance for reads (servers) | tolerance for writes (servers) |
|
||||
|--------:|------------------:|------------:|------------------------:|------------------------------:|-------------------------------:|
|
||||
| 4 | 2 | 8 | 4 | 2 | 1 |
|
||||
| 5 | 2 | 10 | 4 | 2 | 2 |
|
||||
| 6 | 2 | 12 | 4 | 2 | 2 |
|
||||
| 7 | 2 | 14 | 4 | 2 | 2 |
|
||||
| 8 | 1 | 8 | 4 | 4 | 3 |
|
||||
| 8 | 2 | 16 | 4 | 2 | 2 |
|
||||
| 9 | 2 | 9 | 4 | 4 | 4 |
|
||||
| 10 | 2 | 10 | 4 | 4 | 4 |
|
||||
| 11 | 2 | 11 | 4 | 4 | 4 |
|
||||
| 12 | 2 | 12 | 4 | 4 | 4 |
|
||||
| 13 | 2 | 13 | 4 | 4 | 4 |
|
||||
| 14 | 2 | 14 | 4 | 4 | 4 |
|
||||
| 15 | 2 | 15 | 4 | 4 | 4 |
|
||||
| 16 | 2 | 16 | 4 | 4 | 4 |
|
||||
|
||||
@@ -57,8 +57,8 @@ The main difference between various MinIO-KMS deployments is the KMS implementat
|
||||
|:---------------------------------------------------------------------------------------------|:------------------------------------------------------------------|
|
||||
| [Hashicorp Vault](https://github.com/minio/kes/wiki/Hashicorp-Vault-Keystore) | Local KMS. MinIO and KMS on-prem (**Recommended**) |
|
||||
| [AWS-KMS + SecretsManager](https://github.com/minio/kes/wiki/AWS-SecretsManager) | Cloud KMS. MinIO in combination with a managed KMS installation |
|
||||
| [Gemalto KeySecure /Thales CipherTrust](https://github.com/minio/kes/wiki/Gemalto-KeySecure) | Local KMS. MinIO and KMS On-Premises. |
|
||||
| [Google Cloud Platform SecretManager](https://github.com/minio/kes/wiki/GCP-SecretManager) | Cloud KMS. MinIO in combination with a managed KMS installation |
|
||||
| [Gemalto KeySecure /Thales CipherTrust](https://github.com/minio/kes/wiki/Gemalto-KeySecure) | Local KMS. MinIO and KMS On-Premises. |
|
||||
| [Google Cloud Platform SecretManager](https://github.com/minio/kes/wiki/GCP-SecretManager) | Cloud KMS. MinIO in combination with a managed KMS installation |
|
||||
| [FS](https://github.com/minio/kes/wiki/Filesystem-Keystore) | Local testing or development (**Not recommended for production**) |
|
||||
|
||||
|
||||
|
||||
Reference in New Issue
Block a user