
![]()
How to be more productive
Work Chronicles 06 07 2021
The post How to be more productive appeared first on Work Chronicles.
Software Engineering Manager (Clojure Team)
Banzai Inc. | Anywhere | US & Canada
remote
Unparalleled financial education.
$125000 - $200000
tl;dr
- Manager, or senior-level developer moving to management
- Direct software engineering for a growing ed-tech firm
- Functional programming experience a plus
- Remote (if desired), competitive salary, unbeatable health insurance, and generous PTO
What we're looking for
Senior-level developer looking for management experience, or experienced manager furthering his or her career.
Culturally, we tend to promote from within; for this position, however, we want you to introduce stronger programming standards, mentor younger developers, and generally help us reach bigger goals we have as a company.
What you will do
Banzai's development group consists of three Clojure devs, an architect, and two JavaScript devs, with one more front-end position currently open. You will shape the team according to your own vision; vet and hire future engineers; measure individual performance; and demonstrate how to hit company goals. You will lead by example.
We have two initiatives: create more complex types of interactive software for schools, banks, and credit unions; and complete a greenfield project for small- to mid-size businesses helping employers deepen their employees' understanding of their benefits.
While you will be a manager first, you may also contribute to the code: we believe great managers stay close to the problems their teams face daily. You will report to the Head of Product.
What we expect
You have well-developed opinions about leading people, organizing processes, and writing software.
Our front-end stack is built on JavaScript, with a Clojure backend. While you do not need Clojure experience, familiarity with innovative tooling native to functional programming is a plus (e.g. REPL-driven development, React, Vue, Elm, RxJS, Elixir, F#, etc.).
You have a deep understanding of programming for the web, including monitoring performance, deploying, testing, reviewing code, and generally helping us understand what's required of a company with more developers than we have.
Our architecture
Our software architecture is based around a monolithic repository with several application and worker subsystems running on a PaaS. Three of our web applications are SPAs, and two are server-driven templating engines. The Clojure code has more than 50% test coverage. We use a host of caching mechanisms to help keep the site running at or below 50ms at the 95th percentile.
We hope you will find new ways to help us improve the architecture for the sake of the business.
What we're offering
Our goal is to make sure you're not worried about benefits:
Our product team offers a competitive salary, reviewed every six months. We don't like offer wars, and you shouldn't have to switch jobs for a raise. Every six months we'll discuss your pay in a simple performance review. It's common for employees to get raises at each review, assuming the company is growing and you're regularly hitting expectations.
You may work remotely or join us at our office.
Best of all we offer full-health care coverage. We cover ~95% of your insurance premium, and all of your out-of-pocket expenses via a reimbursable account. You will get access to a Flexible Spending Account (FSA), letting you purchase things like eyeglasses and over-the-counter medications tax free.
Paid time off (PTO) is very flexible. We recommend three business weeks per year, in addition to a generous holiday schedule. There is, however, no technical limit inasmuch as it is approved with your manager and you're regularly hitting company goals.
We offer a 401(k) with a generous 5% match, with a wide variety of investment options. Half of your employer contributions will vest in one year, the remainder in two.
You will be eligible for company stock options. The options plan is simple and straightforward, with a four-year vesting schedule. When your options vest, you will have the opportunity to buy them and become an owner of company stock, if you choose.
You will be set you up with a phone and company-paid service.
Additional benefits include life and disability insurance, food and drinks on company premises, and other fringes. Should you become a parent (either for the first time or again!), you will have access to plenty of paid leave.
Finally, while strong benefits are essential to Banzai's compensation package, more importantly, you will have varied and interesting opportunities to grow in your careerand assume meaningful responsibility. You will be expected to learn new things on your own, but we also make time for training.
Tell me about the company
Banzai is an independent, owner-operated technology company dedicated to helping people become wise stewards of their finances through online solutions and local partnerships. We employ over 50 professionals in management, sales, sponsor relations, support, public relations, and product development.
Owner operated
Banzai has been in business for nearly 15 years, and the company's co-founders continue to lead it today. While we are aggressively growth-minded, the company is profitable, self-sustaining, and it requires neither debt nor venture funding.
Banzai is unique in the technology industry---our mindset is long-term. No unrealistic growth targets; no investor drama; no chasing unicorns. We aim for steady, reliable growth that compounds over time, making the company a more lucrative, happier place for employees in the long run.
Oh, and you can be an owner too: every full-time employee receives a stock option grant.
- www.teachbanzai.com
- Located @ 2230 N. University Pkwy., Bldg. 14, Provo Utah
Tell me about the culture
Banzai's culture marries a high level of trust and flexibility with equally high levels of responsibility. We place important jobs on our employees' shoulders, even juniors. For leadership, we tend to promote from within.
We ask you to bring your best self to work.
Meeting these expectations also earns you a great deal of freedom. At Banzai we don't count hours, nor do we set your schedule. (Although it is generally expected that you will work 40 hours per week.) Your personal time is your own; there's plenty of space in the day to take breaks and run errands; and our holiday schedule and PTO policy is generous. Fire drills and late nights are rare.
How do I apply?
We want to see what you've accomplished. Please send a portfolio and cover letter explaining why you're a great fit to Kendall Buchanan, CTO, kendall [at] teachbanzai.com.
IV Mar i jazz
AU Agenda 06 07 2021
La entrada IV Mar i jazz aparece primero en AU Agenda.
PARC DR. LLUCH marijazz.es Ara més que mai necessitem música, oci i cultura, i millor si és en un espai obert. D’aqueixa necessitat nasqueren les Jam Sesions en 27 Amigos, un bar insígnia del barri del Cabanyal que ara, amb recolzament de l’Ajuntament de València, Sedajazz i l’Associació de Comerciants del Marítim, ens porta Mar […]
La entrada IV Mar i jazz aparece primero en AU Agenda.
XI Russafa Escència
AU Agenda 06 07 2021
La entrada XI Russafa Escència aparece primero en AU Agenda.
russafaescenica.com El festival Russafa Escènica se expande como una gota de aceite, ahora con un proyecto de residencias artísticas en diferentes municipios de la provincia llamado Via Escènica. Al cierre de la edición de esta revista, el festival estaba en pleno proceso de selección de los viveros (30 min.) y los bosques (60 min.) de […]
La entrada XI Russafa Escència aparece primero en AU Agenda.
La entrada 31è MIM aparece primero en AU Agenda.
mimsueca.com Torna la Mostra Internacional de MIM de Sueca aquest setembre amb companyies de Portugal, Brasil, Xile, Alemanya, França i Regne Unit, sense por a les fronteres. De les illes britàniques venen Gandini Juggling per presentar 4×4: Ephemeral architectures, on quatre malabaristes i quatre ballarins de ballet comparteixen escenari. Francesos son Cie. Bivouac, que alternen […]
Bürstner Club
AU Agenda 06 07 2021
La entrada Bürstner Club aparece primero en AU Agenda.
ESPACIO INESTABLE. Aparisi i Guijarro, 7 Dels altres es una joven compañía valenciana fundada en el año 2020 y dirigida por Eleonora Gronchi i Pablo Meneu para darle una vuelta al circo contemporáneo. Han creado piezas como Staged para la compañía Circumference (galardonada con el Total TheatreAward del Festival Fringe de Edinburgo 2019 como mejor espectáculo de […]
La entrada Bürstner Club aparece primero en AU Agenda.
Espaldas de plata
AU Agenda 06 07 2021
La entrada Espaldas de plata aparece primero en AU Agenda.
SALA ULTRAMAR. Alzira, 9 De veritat en Àfrica s’escolten tambors en la llunyania, a totes hores, com en els sons d’ambient insufribles dels zoos? Walter no ho sap, mai ha estat allí. En l’agència de publicitat en la qual treballa té l’“oportunitat” d’acceptar un encàrrec per a un home, un polític a qui detesta, però […]
La entrada Espaldas de plata aparece primero en AU Agenda.
Señora de rojo sobre fondo gris
AU Agenda 06 07 2021
La entrada Señora de rojo sobre fondo gris aparece primero en AU Agenda.
TEATRO OLYMPIA. Sant Vicent Màrtir, 44 Delibes y José Sacristán, una fórmula que ya ha demostrado funcionar a la perfección en este soliloquio dirigido por José Sámano. Un pintor con una carrera dilatada, Nicolás, padece una importante crisis existencial, su creatividad se ha esfumado tras la muerte de su mujer. El fondo gris que imprima […]
La entrada Señora de rojo sobre fondo gris aparece primero en AU Agenda.
V Cicle Escèniques LGTBI
AU Agenda 06 07 2021
La entrada V Cicle Escèniques LGTBI aparece primero en AU Agenda.
CARME TEATRE. Gregori Gea, 6 Dansa de València, Madrid, Galícia i Canàries és el que ofereix la cinquena edició del Cicle Escèniques LGTBI del Carme Teatre, on el plat primícia arriba en forma d’entrant. Arrenca la mostra amb l’estrena absoluta de Nus-altres possibles del valencià Javier J. Hedrosa [2-5], un habitual de La Coja Dansa […]
La entrada V Cicle Escèniques LGTBI aparece primero en AU Agenda.
La entrada Maixabel aparece primero en AU Agenda.
Icíar Bollaín · España · 2021 · Guion: Icíar Bollaín e Isa Campo · Intérpretes: Blanca Portillo, Luis Tosar, Bruno Sevilla… Reparto de lujo con dos grandes de la interpretación en España como Blanca Portillo y Luis Tosar. Maixabel cuenta la historia de Maixabel Lasa, mujer del político Juan María Jaúregui, asesinado por ETA en el […]
Cuestión de sangre
AU Agenda 06 07 2021
La entrada Cuestión de sangre aparece primero en AU Agenda.
Tom McCarthy · USA · 2021 · Guión: Thomas Bidegain, Noé Debré, Marcus Hinchey y Tom McCarthy · Intérpretes: Matt Damon, Abigail Breslin, Camille Cottin… El realizador de la galardonada Spotlight regresa con este largometraje que transita los códigos del thriller y el drama político y social. En Cuestión de sangre, Matt Damon interpreta a […]
La entrada Cuestión de sangre aparece primero en AU Agenda.
La entrada BABii aparece primero en AU Agenda.
CENTRE DEL CARME. Museu, 2 Escoltar MiiRROR, l’àlbum de la talentosa artista multidisciplinària britànica BABii, és endinsar-se en l’atmosfera vaporosa i etèria d’un pop electrònic i garage, és evolucionar en el cor d’una realitat paral·lela que explora les emocions íntimes i els dimonis interiors de la seua creadora. BABii, en una estètica alienadora do it […]
![]()
An Hour About… Psuedo.com
The History of the Web 06 07 2021
Pseudo.com is a forgotten relic of the dot-com era. Was it ahead of its time? A moonshot that went too far? Or simply a piece of elaborate performance art?
The post An Hour About… Psuedo.com appeared first on The History of the Web.


CUÑADOS
Cinestudio d'Or 04 07 2021
del 5 al 11 de julio
17:15h. 20:55h. versión doblada / digital

BORRAR EL HISTORIAL
Cinestudio d'Or 04 07 2021
del 5 al 11 de julio
19:00h. versión doblada / digital

UNA JOVEN PROMETEDORA
Cinestudio d'Or 04 07 2021

Radar verano mix Parte 1
República Web 03 07 2021
Debido a un error de grabación la pista de Antony no está disponible. Esta primera parte es una versión editada con las partes de Antony (que no salen en la mezcla). Intentaremos que Antony grabe sus enlaces por separado para la parte 2.
Despedimos temporada 4 del podcast con un episodio cargado de enlaces de interés, salpicados eso sí, con nuestras anotaciones personales. Como es habitual en la sección Radar, este episodio recoge recursos y herramientas que nos parecen valiosas para nuestro trabajo. En esta primera parte se incluyen las recomendaciones recopiladas por Javier y Andros. También al inicio del podcast David Vaquero hace un valoración del Congreso Eslibre que se celebró la semana pasada, y que tuvo al propio David participando como colaborador y dando un taller. Andros también participó ofreciendo una charla sobre el desarrollo de Glosa, su solución personal para agregar comentarios en un sitio web estático.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

RUEGA POR NOSOTROS
Cinestudio d'Or 03 07 2021
![]()
Greatest weakness
Work Chronicles 03 07 2021
The post Greatest weakness appeared first on Work Chronicles.
Clojure Deref (July 2, 2021)
Clojure News 02 07 2021
Welcome to the Clojure Deref! This is a weekly link/news roundup for the Clojure ecosystem. (@ClojureDeref RSS)
Highlights
Clojurists Together announced a more varied set of funding models moving forward to better match what projects have been seeking.
All of the clojureD 2021 videos are now available, including my video discussing a set of new Clojure CLI features and the tools.build library. We have been hard at work polishing documentation and finalizing a last few bits of the source prep functionality and we expect it will be available soon for you to work with! For now, the video is a good overview of what’s coming: expanded source for source-based libs, a new tools.build library, and some extensions to tool support in the Clojure CLI.
In the core
We have mostly been working on Clojure CLI and tools.build lately but these items went by this week, maybe of interest:
-
Does Clojure still have rooms to improve at compiler level? - some discussion at ClojureVerse
-
CLJ-2637 - Automatic argument conversion to Functional Interface (Lambda) from Clojure fn - this patch was proposed to do automatic SAM conversion for Clojure functions in the compiler.
This is an area we’ve actually spent a lot of time thinking about for Clojure 1.11, (tracking under CLJ-2365 although most of the work has happened off ticket). In particular we have talked about a long list of possible use cases for functional interop and also a long list of ideas for making functional interop less cumbersome, both syntax and implementation. The examples given in CLJ-2637 are primarily about the Java Stream API but we don’t think that’s particularly high on the list of what’s interesting (if you’re in Clojure, just use Clojure’s apis!). But there are cases where you have Java APIs in the JDK or elsewhere that now take one of the SAM-style interfaces, or a java.function interface and it would be nice to reduce the friction in passing a Clojure function without needing to reify - either by automatic detection and conversion, or helper fns, or even new syntax and compiler support. No conclusions yet.
Podcasts and videos
-
Apropos - Mia, Mike, Ray, and Eric chat about Clojure
Blogs, discussions, tutorials
-
Clojure Morsels - a new biweekly mailing list for Clojure news starting soon
-
REPL vs CLI: IDE wars - Vlad thinks about REPLs vs the command line for dev
-
Clojure Building Blocks - Gustavo Santos
-
Getting Started with Clojure - Gustavo Santos
-
Rich Comment Blocks - Thomas Mattacchione
Training and hiring
-
Learn Datomic - is a new course for learning Datomic and Datalog by Jacek Schae, coming soon!
-
Who’s Hiring - monthly hiring thread on Clojure subreddit
Libraries and tools
Some interesting library and tool updates and posts this week:
-
PCP - Clojure replacement for PHP
-
holy-lambda 0.2.2 - A micro-framework that integrates Clojure with AWS Lambda on either Java, Clojure Native, or Babashka runtime
-
clojure-lsp 2021.07.01-13.46.18 - Language Server (LSP) for Clojure, this release with new API/CLI support!
-
clojureflare - a new ClojureScript lib for using Cloudflare workers
-
Calva 2.0.202 - Clojure & ClojureScript in Visual Studio Code
![]()
Speed of execution
Work Chronicles 01 07 2021
The post Speed of execution appeared first on Work Chronicles.

No sin mis cookies 01 07 2021
Si hasta 2020 el SEO local era importante, ahora toma el carácter de plenamente imprescindible. Si competir ya es de por sí difícil, hacerlo con tus vecinos de localidad es todo un desafío.
The post appeared first on No sin mis cookies.
667
Extra Ordinary 30 06 2021
![]()
Expertise
Work Chronicles 30 06 2021
The post Expertise appeared first on Work Chronicles.


¿Quieres vender en la Apple Store? Lo siento pero tenemos que hablar.
Cuando decides poner a la venta algún elemento dentro de un App no todas las ganancias van a tu bolsillo. Dependiendo de ciertas variables Apple se llevará un porcentaje por cada transacción, que puede ser de un 0% (ninguna), 15% o un 30%.
Un ejemplo rápido. Acabas de publicar un App de cocina donde ofreces deliciosas recetas veganas para perros. Decides que la vas a monetizar por media de una suscripción a un precio de 10 euros al mes. Solamente quienes paguen podrán visualizar las recetas completas con todos sus pasos; el resto únicamente disfrutaran del primer paso. En este caso de cada suscripción a ti te llegará 7 euros (un 70%) mientras que Apple se quedará una comisión de 3 euros (un 30%). Y esta situación ser repetirá en cada usuario y renovación.
Existen 2 servicios que no debes confundir, ya que su uso es completamente diferente a pesar que ambos gestionen dinero.
-
Apple Pay: Implementación para hacer pagos en una web o App por medio de una tarjeta que ha sido vinculada con la cartera de Apple.
-
In-App Purchase: Implementación para realizar pagos dentro de un App. Orientado a ofrecer contenido como: productos digitales, suscripciones y contenido premium.
El último servicio es el que nos interesa. Dentro podremos encontrar 3 subcategorías de posibles pagos:
- Consumibles: como gemas en un videojuego o incrementar la visibilidad de un perfil temporalmente en un red de citas.
- No consumibles: características premium que son compradas en una ocasión y no expiran.
- Suscripciones: características premium o acceso a contenido a través de un pago recurrente. Cuando el usuario decide cancelar el siguiente pago, estas características dejan de ser accesibles transcurrido el periodo pagado.
Es importante que sepas donde encaja el App en estas subcategorías porque las comisiones cambiarán.
Comisiones
- El App es gratis en tienda, no se vende nada: 0%.
- El App es gratis en tienda pero posee anuncios: 0%.
- El App es gratis en tienda pero se vende productos o servicios físicos: 0%.
- El App es gratis en tienda aunque puedes pagar por consumibles: 30%.
- El App es de pago, no se vende nada: 30%.
- El App es gratis en tienda aunque puedes pagar una suscripción: 30%, aunque después del primer año baja a 15%.
- Existe pagos o suscripciones fuera del App: 0%, sin embargo no debe existir ningún enlace o referencia al lugar donde se pueden realizar los pagos.
- Existen pagos o suscripciones fuera del App con posibilidad de hacerlo también dentro de un dispositivo Apple: 0% si no es en el ecosistema de Apple, dentro del App se debe pagar las comisiones anteriormente mencionadas.
Tabla de precios disponibles
Los precios no los eliges libremente, Apple te da una tabla de posibilidades que si o si debes seleccionar la opción que más se ajuste con tu negocio. Te aviso que las cantidades a percibir varían dependiendo del país. Puede darse el caso que marques 10 euros, pero en un lugar como la India se venda por 4 euros.

Otras comisiones
No olvides que independientemente de Apple debes integrar una pasarela de pago. Alguien debe gestionar el movimiento de dinero entre la tarjeta del cliente y tu cuenta bancaria. Corre por tu cuenta. Las más populares son las siguientes.
- Stripe: Se lleva una comisión de 1,4 % + 0,25 € para tarjetas europeas y 2,9 % + 0,25 € para tarjetas no europeas.
- Paypal: Se lleva una comisión de 2,8 % + una tarifa fija dependiendo de la moneda.
Sin olvidar el pago anual de Apple Developer Program, que son 100 dolares. Es el precio para que tu App esté accesible en la tienda. En caso de no pagarlo sería retirada.
Y por último los impuestos locales de cada país. Pero esto es inabarcable de explicar en un artículo de blog.
Conclusión
Para publicar un App en la Apple Store debemos tener en cuenta las siguientes comisiones.
- Apple Developer Program: 100 dolares anuales.
- In-App Purchase: Entre 0% al 30%.
- Pasarela de pagos: Los mencionados rondan de entre 1,4% al 2.9% + una tarifa fija.
- Reducción de precio en algunos países.
- Impuestos locales.
Aún así, sigue siendo la plataforma más rentable dentro del desarrollo de Apps.
Más información
Todas las funciones: In‑App Purchase
Comisiones: Principales prácticas

![]()
Follow Through
Work Chronicles 28 06 2021
The post Follow Through appeared first on Work Chronicles.
Tecnología GPON - FTTH
Blog elhacker.NET 28 06 2021
Demystifying styled-components
Josh Comeau's blog 27 06 2021
![]()
Wonder Why
Work Chronicles 25 06 2021
The post Wonder Why appeared first on Work Chronicles.
Clojure Deref (June 25, 2021)
Clojure News 25 06 2021
Welcome to the Clojure Deref! This is a weekly link/news roundup for the Clojure ecosystem. (@ClojureDeref RSS)
Highlights
It is common to see complaints that both Clojure jobs and Clojure developers are hard to find. The real truth is: both exist, but there is sometimes a mismatch in either experience or geographic distribution. We don’t typically highlight jobs in the Deref but here are some great places to find Clojure jobs:
-
Brave Clojure - job board
-
Functional Works - job board
-
Clojurians slack - #jobs and #remote-jobs channel
-
Clojure subreddit - monthly thread
-
Who is hiring - search at HackerNews
Also, I want to highlight that clojureD 2021 conference videos are coming out now, about one per day, check them out!
Sponsorship spotlight
Over the last couple years, the Calva team has been putting a ton of effort into making VS Code a great place to Clojure. If you enjoy the fruits of that effort, consider supporting one of these fine folks working in this area:
-
Peter Strömberg - sponsor for Calva
-
Brandon Ringe - sponsor for Calva
-
Eric Dallo - sponsor for clojure-lsp
Podcasts and videos
-
CaSE - Conversations about Software Engineering talks with Eric Normand
-
ClojureScript podcast - Jacek Schae interviews Howard Lewis Ship
-
Apropos - Mia, Mike, Ray, Eric chat plus special guest Martin Kavalar
Blogs, discussions, tutorials
-
Open and Closed Systems with Clojure - Daniel Gregoire
-
What is simplicity in programming and why does it matter? - Jakub Holý
-
Counterfactuals are not Causality - Michael Nygard - not about Clojure but worth a read!
-
How I’m learning Clojure - Rob Haisfield
-
Clojure metadata - Roman Ostash
-
Data notation in Clojure - Roman Ostash
-
Specific vs. general: Which is better? - Jakub Holý
Libraries
Some interesting library updates and posts this week:
-
spock 0.1.1 - a Prolog in Clojure
-
recife 0.3.0 - model checker library in Clojure
-
datascript 1.2.1 - immutable in-memory database and Datalog query engine
-
sparql-endpoint 0.1.2 - utilities for interfacing with SPARQL 1.1 endpoints
-
pulumi-cljs - ClojureScript wrapper for Pulumi’s infrastructure as code Node API
-
c4k-keycloak - k8s deployment for keycloak
-
clj-statecharts 0.1.0 - State Machine and StateCharts for Clojure(Script)
-
clojure-lsp 2021.06.24-14.24.11 - Language Server (LSP) for Clojure
-
tick 0.4.32 - Time as a value
-
aws-api 0.8.515 - programmatic access to AWS services from Clojure
Tools
-
Clojure LibHunt - find Clojure open source projects!
-
syncretism - options search engine based on Yahoo! Finance market data
-
mastodon-bot - bot for mirroring Twitter/Tumblr accounts and RSS feeds on Mastodon
Fun and Games
Chris Ford did a live coding performance (on keytar!) - see the code
Throwback Friday (I know, I’m doing it wrong)
In this recurring segment, we harken back to talks from an older time of yore. This week, we’re featuring:
-
How to Think about Parallel Programming: Not! by Guy L. Steele Jr from Strange Loop 2010 - it’s a decade+ old but still worth watching for how we think about what languages should provide, and a particular inspiration to the later design of Clojure reducers
-
Advent of Code 2020, Day 17 by Zach Tellman - a wonderful example of how to work in Clojure. write code in your editor, eval small exprs to your REPL, building iteratively up to a final solution
Clojure Engineer (Remote)
Brave Clojure Jobs 24 06 2021
Clojure Engineer (Remote)
Composer | US & Canada
remote
Build, test, and deploy automated trading strategies without any code!
$130000 - $200000
Build the infrastructure powering our automated portfolio management platform!
Composer is a no-code platform for automated investment management. Composer allows you to build, test, deploy, and manage automated investing strategies - all without writing a line of code.
As an early backend engineer at Composer you will:
- Be responsible for designing and building critical pieces of our infrastructure
- Work closely with the executive team to guide our decisions regarding technical architecture
Projects you will work on:
- Creating a language that clients can use to define any conceivable trading strategy ("strategies as data")
- Determining the best way to collaborate on, share, and/or monetize strategies
- Allowing clients to develop custom logic to further personalize their strategies
- See here for more ideas!
We're looking for someone who:
- Loves Clojure! (Clojurescript a bonus)
- Has familiarity with cloud platforms (We use GCP)
- Will be a technical thought leader within the company
- Understands database design
- Makes educated decisions when faced with uncertainty
What's it like to work at Composer?
- We believe diverse perspectives are necessary if we aim to disrupt finance. To that end, we are an equal opportunity employer and welcome a wide array of backgrounds, experiences, and abilities.
- We believe the simplest solution is most likely the best one
- We encourage self-improvement and learning new skills
- We are venture-backed by top investors
- We are 100% remote :)
- We offer generous equity!
- Our Values
Nos podrían estar detectando
NeoFronteras 24 06 2021
I complete. You?
Manuel Uberti 24 06 2021
Tracking the Emacs development by building its master branch may not be a smooth experience for everyone, but for the average enthusiast is the perfect way to see their favourite tool evolve, trying experimental things, and reporting back to the core developers to help them. Sure, one has to deal with occasional build failures, but with Git at one’s service it’s always easy to reset to a working commit and find happiness again.
Recently a shiny new mode has been implemented on master:
icomplete-vertical-mode. Now, if you had the chance to read this blog in the
past you know that when it comes to candidate completion I am a gangsta jumping
back and forth among packages with excessive self-satisfaction. But you should
also already know that I like to use as many Emacs built-ins as possible. Hence,
I could not wait to give icomplete-vertical-mode a try.
Turning it on is trivial:
(icomplete-mode +1)
(add-hook 'icomplete-mode-hook #'icomplete-vertical-mode)
Since other completion systems have spoiled me, I prefer scrolling over the
rotating behaviour of the standard icomplete:
(setq icomplete-scroll t)
Furthermore, I always want to see the candidate list:
(setq icomplete-show-matches-on-no-input t)
This is pretty much it. I use icomplete-fido-backward-updir to move up one
directory and I have exit-minibuffer bound to C-j for convenience.
I have been using icomplete-vertical-mode daily for a while now and everything
has been working as expected. For the record, this mode works seamlessly with
your favourite completion-styles settings, so moving from, say, Vertico to
icomplete-vertical-mode is simple and easy.
I complete. You?
Manuel Uberti 24 06 2021
Tracking the Emacs development by building its master branch may not be a smooth experience for everyone, but for the average enthusiast is the perfect way to see their favourite tool evolve, trying experimental things, and reporting back to the core developers to help them. Sure, one has to deal with occasional build failures, but with Git at one’s service it’s always easy to reset to a working commit and find happiness again.
Recently a shiny new mode has been implemented on master:
icomplete-vertical-mode. Now, if you had the chance to read this blog in the
past you know that when it comes to candidate completion I am a gangsta jumping
back and forth among packages with excessive self-satisfaction. But you should
also already know that I like to use as many Emacs built-ins as possible. Hence,
I could not wait to give icomplete-vertical-mode a try.
Turning it on is trivial:
(icomplete-mode +1)
(add-hook 'icomplete-mode-hook #'icomplete-vertical-mode)
Since other completion systems have spoiled me, I prefer scrolling over the
rotating behaviour of the standard icomplete:
(setq icomplete-scroll t)
Furthermore, I always want to see the candidate list:
(setq icomplete-show-matches-on-no-input t)
This is pretty much it. I use icomplete-fido-backward-updir to move up one
directory and I have exit-minibuffer bound to C-j for convenience.
I have been using icomplete-vertical-mode daily for a while now and everything
has been working as expected. For the record, this mode works seamlessly with
your favourite completion-styles settings, so moving from, say, Vertico to
icomplete-vertical-mode is simple and easy.
Introducing the new GitHub Issues
The GitHub Blog 23 06 2021
666
Extra Ordinary 23 06 2021

Don Clojure de la Mancha
Programador Web Valencia 22 06 2021
Próximamente será publicado el libro: Don Clojure de la Mancha. ¿Quieres ser el primero en enterarte? Tan solo debes dejar un comentario. El email que introduzcas no será visible y solo le daré uso para avisarte del momento y lugar. NO TE ESTAS SUSCRIBIENDO A UNA NEWSLETTER.
Gracias por apoyar al software libre, la programación funcional y la comunidad hispana de Clojure.
Custom Scrollbars In CSS
Ahmad Shadeed Blog 22 06 2021
Los blogs están a la orden del día. Cada vez son más las personas que ganan dinero con sus propios dominios, apostando por una idea de negocio innovadora. Si tú también has optado por la creación de un blog, estoy seguro de que sabes de lo que te hablo. Pero entonces ocurre el primer desencuentro: ... Read more
The post 5 errores de SEO que perjudican tu blog appeared first on No sin mis cookies.
Pandemic Progress
Stratechery by Ben Thompson 21 06 2021
![]()
Accountability
Work Chronicles 20 06 2021
The post Accountability appeared first on Work Chronicles.
Paraceratherium linxiaense
NeoFronteras 20 06 2021

En caso que intentes ordenar una consulta de la base de datos y no uses PosgreSQL como base de datos principal te vas a encontrar un pequeño problema: Cuando hay acentos no se ordena de una forma lógica. Si utilizas SQLite te lo habrás encontrado de frente. Por ejemplo, si yo tengo una tabla con nombres e intento ordenarlas con order_by pasaré de:
Zaragoza, Ávila, Murcia, Albacete...
al siguiente orden
Albacete, Murcia, Zaragoza, Ávila...
Las palabras con acento, con ñ u otros carácteres acabarán al final de la lista.
Para arreglarlo he creado la siguiente solución que debes copiarlo en el archivo donde necesites realizar el orden deseado.
import re
import functools
def order_ignore_accents(queryset, column):
"""Order Queryset ignoring accents"""
def remove_accents(raw_text):
"""Removes common accent characters."""
sustitutions = {
"[àáâãäå]": "a",
"[ÀÁÂÃÄÅ]": "A",
"[èéêë]": "e",
"[ÈÉÊË]": "E",
"[ìíîï]": "i",
"[ÌÍÎÏ]": "I",
"[òóôõö]": "o",
"[ÒÓÔÕÖ]": "O",
"[ùúûü]": "u",
"[ÙÚÛÜ]": "U",
"[ýÿ]": "y",
"[ÝŸ]": "Y",
"[ß]": "ss",
"[ñ]": "n",
"[Ñ]": "N",
}
return functools.reduce(
lambda text, key: re.sub(key, sustitutions[key], text),
sustitutions.keys(),
raw_text,
)
return sorted(queryset, key=lambda x: remove_accents(eval(f"x.{column}")))
Supongamos, por ejemplo, que necesitas ordenar unos pueblos o municipios. Lo que haría cualquier desarrollador es:
towns = Town.objects.all().order_by('name')
En su lugar, omitirás order_by y añadirás la consulta a la función order_ignore_accents. Y como segundo argumento la columna que quieres usar para ordenar. En este caso será name.
towns_order = order_ignore_accents(Town.objects.all(), 'name')
Se ordenará como esperamos.
Albacete, Ávila, Murcia, Zaragoza...
![]()
Honest Review
Work Chronicles 19 06 2021
The post Honest Review appeared first on Work Chronicles.
Vuelve Drupal al podcast y para esta ocasión contamos con la compañía del desarrollador web especializado en Drupal Borja Vicente, creador de la web y el canal escueladrupal.com Invitamos a Borja para que nos cuente muchas cosas sobre su proyecto y el estado actual de Drupal. Borja desarrolla en backend con Drupal desde hace más de 10 años y actualmente su labor profesional se desarrolla con Drupal, aunque suele también experimentar con Symfony, Laravel, Django y también Ruby on Rails. Además Borja también tiene publicado cursos especializados en Drupal a través de la plataforma Udemy.
Con Borja tratamos muchas cuestiones relacionados con Drupal y su proyecto de contenidos:
- Evolución de Drupal hasta su última versión
- Comunidad Drupal a nivel internacional y nacional
- Proyectos o casos de uso ideales para desarrollar con Drupal 9?
- Recomendaciones esenciales para gestionar una instalación de Drupal
- Motivaciones para crear Escuela Drupal y lo que gustaría conseguir.
- Entorno de desarrollo usado para Drupal.
- Módulos que más te ayudan al desarrollo web con Drupal.
Muy agradecidos a Manu por propiciar en Twitter este episodio sobre Drupal con Borja.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Senior Software Engineer (Clojure)
Compute Software | USA and Canada
remote
Startup that helps enterprises to run optimally on the public cloud.
About Us
With ever-growing workloads on the cloud, companies face significant challenges in managing productivity and spending, and maximizing impact to their businesses. Compute Software is addressing a huge market opportunity to help companies make good business decisions and run optimally on the public cloud. We're building a powerful platform to give customers the tools they need to gain transparency, optimize their usage, and execute change across their organizations.
We're a small, distributed team, currently spanning California to Quebec, and we offer early stage market-rate compensation (including equity), health and dental insurance, and 401K benefits. You'll be joining a venture capital-backed, distributed team with ambitious goals, and you will have the ability to make a direct and lasting impact on the team and product.
Your Role
Be one of the earliest employees and join our early-stage engineering team as a Senior Software Engineer. You will be essential in shaping the features and functionality of our SaaS platform, culture and processes.
You'll spend your day enveloped in Clojure. The backend is written in Clojure and driven by data in Datomic and InfluxDB. The frontend is written in ClojureScript using re-frame and communicates with the backend using Pathom. We deploy to AWS Fargate and Datomic Ions.
For product development, we follow Shape Up. We use Notion, Slack, and ClubHouse.
What will you do at Compute Software?
- Write Clojure and ClojureScript.
- Design, build, and deploy features and bug fixes across the entire stack.
- Become an expert in all the nuances of the various cloud platforms like Amazon Web Services, Google Cloud, and Microsoft Azure.
- Provide product feedback and evaluate trade-offs to impact product direction.
- Debug production problems.
What We're Looking For Passion - you are excited about the large, high-growth cloud computing market and figuring out how to help customers, who are using cloud computing solutions today. You are excited by being one of the earliest employees and getting to work with a small team.
Engineering experience - you're a Clojure practitioner with 6+ years of professional experience. You know what it takes to create large-scale b2b software. You can create effective and simple solutions to problems quickly, and communicate your ideas clearly to your teammates.
Product-minded - you love building products and you care about the details of creating a great user experience. You have an interest in how users will use our platform and the impact we will have on them. You can balance your consideration of the product and user requirements with technical complexity and implementation details to make appropriate decisions when things are unclear.
Effective communication - you're great at communicating. If something is unclear you reach out and ask questions. You're comfortable owning, communicating and presenting information on specific projects or initiatives, both in writing and in person.
Organizational and project management - you are highly organized and able to self-manage projects in a fast-moving company. You are able to take high level goals and break them down into achievable steps.
Updated Debian 10: 10.10 released
Debian News 19 06 2021
buster). This point release mainly adds corrections for security issues, along with a few adjustments for serious problems. Security advisories have already been published separately and are referenced where available.
![]()
Turn on your cameras
Work Chronicles 18 06 2021
The post Turn on your cameras appeared first on Work Chronicles.
Clojure Deref (June 18, 2021)
Clojure News 18 06 2021
Welcome to the Clojure Deref! This is a periodic link/news roundup for the Clojure ecosystem. (@ClojureDeref RSS)
Highlights
-
HOPL IV (History of Programming Languages) at PLDI 2021 is happening on Monday and Tuesday and includes a talk from Rich Hickey about the History of Clojure paper. Registration is still available and the conference is online and features many other fine language developers!
-
The results are out from the JVM Ecosystem Report 2021 and Clojure continues to make a strong showing as one of the most popular JVM languages (other than Java), rising from 2.9% last year to 8.4% this year. Lots of other interesting tidbits in there as well.
Sponsorship Spotlight
Lately Christophe Grand and Baptiste Dupuch have been teasing their work on a new ClojureDart runtime with Flutter support. You can support their work on GitHub: cgrand dupuchba. Nubank (users of both Clojure and Flutter) are now supporting both!
Podcasts and videos
-
LispCast - Eric Normand talks about stratified design
-
defn - Vijay Kiran and Ray McDermott interview Paula Gearon
-
REPL-driven development - demo from Jakub Holý
Blogs, discussions, tutorials
-
Clojure Transducers - Joanne Cheng explains transducers
-
Clojure’s Destructuring - Daniel Gregoire dives into destructuring
-
Better performance with Java arrays in Clojure - Daw-Ran Liou on using Java arrays in Clojure
-
Backpressure - Kenny Tilton talks about core.async and ETL
-
Fun of clojure - wrap some code around data - @Sharas_ on the data ethos of Clojure
-
Lambda Island is Changing - Arne Brasseur and his merry band of Clojurists at Gaiwan are changing directions a bit
-
Should you adopt Clojure at your company? - Shivek Khurana, TLDR: yes! :)
Libraries and Tools
Some interesting library updates and posts this week:
-
ordnungsamt - a tool for running ad-hoc migrations over a code repository
-
clj-github - a library for working with the GitHub developer API
-
umschreiben-clj - extensions to rewrite-clj
-
Copilot - Tony Kay teased a new upcoming code analysis tool for Clojure and ClojureScript
-
scittle - Michiel Borkent did the first release of the SCI interpreter for use in script tags
-
clojure-lsp - Eric Dallo released a new version with enhanced path support for deps.edn projects
-
holy-lambda - Karol Wójcik released a new version
-
honeysql - Sean Corfield added :distinct syntax and some other features and fixes
-
Fulcro - Tony Kay released 3.5.0-RC1 with more support for non-React apps
-
refl - Michiel Borkent released a new example project to clean up reflection configs for GraalVM for Clojure projects
Fun and Games
-
Fidenza - Tyler Hobbs has a long history of doing interesting generative art with Clojure and he has published a rundown of his newest generative algorithm. Not explicitly Clojure but fascinating to read.
-
ClojureScript racing game - Ertuğrul Çetin published this game this week
Throwback Friday (I know, I’m doing it wrong)
In this recurring segment, we harken back to a talk from an older time to a favorite talk of yore. This week, we’re featuring:
-
Why is a Monad Like a Writing Desk? by Carin Meier from Clojure/West 2012
In this lovely story from 2012, Carin Meier talks about monads through the lens of Clojure and Alice in Wonderland.
Contaminación luminosa e insectos
NeoFronteras 17 06 2021
![]()
Virtual Meetings
Work Chronicles 16 06 2021
The post Virtual Meetings appeared first on Work Chronicles.
![]()
If you build a web application, chances are good that you’ve received user requests for dark mode support in the past couple of years. While some users may simply prefer the aesthetics of dark UI, others may find that dark mode helps ease eye strai
The post Dark Mode for HTML Form Controls appeared first on Microsoft Edge Blog.
665
Extra Ordinary 16 06 2021
Nos vamos al Congreso esLibre 2021
República Web 15 06 2021
En este episodio Andros Fenollosa y David Vaquero hablan sobre la edición del Congreso esLibre 2021, una nueva edición en formato virtual, sobre tecnologías libres enfocadas a compartir conocimiento. Esta edición contará con la participación de una charla de Andros sobre su sistema Glosa de comentarios para sitios estáticos y un taller de David sobre su contenedor Docker para Drupal.
En el episodio también se habla sobre la participación de algunas personas que han pasado por el podcast como Eduardo Collado, Sergio López, Lorenzo Carbonell, Rubén Ojeda o Jesús Amieiro. Como ha comentado David Vaquero con anterioridad, en esta edición se ha apostado por involucrar a la comunidad en español de podcasts tecnológicos, para lograr dar mayor difusión a los contenidos del Congreso.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
![]()
Creating accessible products means most of all being aware of the usability issues your designs and code can cause. When creating new products, Microsoft follows a strict workflow of accessibility reviews of designs, code reviews and mandatory audits
The post Improving contrast in Microsoft Edge DevTools: A bugfix case study appeared first on Microsoft Edge Blog.
The Cicilline Salvo
Stratechery by Ben Thompson 15 06 2021

Measure Twice, Cut Once
MonkeyUser 15 06 2021
The Importance of Learning CSS
Josh Comeau's blog 13 06 2021
Clojure Deref (June 11, 2021)
Clojure News 11 06 2021
Welcome to the Clojure Deref! This is a periodic link/news roundup for the Clojure ecosystem. (RSS feed)
Highlights
This week Nubank announced a new $750M investment, led by $500M from Berkshire Hathaway at a $30B valuation. Nubank is the largest user of Clojure and Datomic in the world and a great example of the benefits of Clojure’s approach to managing complexity at scale.
Chris Nuernberger presented a great talk this week for London Clojurians about his work on high performance data processing with the dtype-next and tech.ml.dataset libraries.
The ClojureD conference last weekend was great with lots of interesting Clojure (and some non-Clojure) talks! Keep an eye out for videos soon.
Podcasts
We have a bumper crop of Clojure-related podcast episodes this week, put these in your ears…
-
Cognicast - Christian Romney interviews Jarrod Taylor from the Datomic team
-
Get Smarter and Make Stuff - Craig Andera interviews Michael Fogus from the Clojure core team
-
Lost in Lambduhhs - Jordan Miller interviews Alex Miller from the Clojure core team
-
ClojureScript Podcast - Jacek Schae interviews Tommi Reiman about Malli
-
defn - Vijay Kiran and Ray McDermott interview Chris Badahdah about Portal
Libraries and Databases
Some interesting library updates and posts this week:
-
Mirabelle - 0.1.0 of this stream processing tool inspired by Riemann - check out the docs and a use case
-
sicmutils - Sam Ritchie released version 0.19.0 of this math and physics based library (based on the books by Sussman and Wisdom)
-
Cybermonday - Kiran Shila releases the first release of this Clojure data interface to Markdown (like Hiccup for Markdown)
-
HoneyEQL - Tamizhvendan S introduced 0.1.0-alpha36 for EQL queries to relational databases
-
Expectations - Sean Corfield released 2.0.0-alpha2 of this clojure.test-compatible implementation of Expectations
-
Snoop - Luis Thiam-Nye announced the initial release of a library for runtime function validation using Malli
-
OSS Clojure DBs - a summary and comparison of open-source Clojure databases (but don’t forget Datomic! :)
Blogs, discussions, tutorials
-
Tetris in ClojureScript - by Shaun Lebron
-
Apache Kafka & Ziggurat - Ziggurat is an event stream processing tool written in Clojure and this article shows how to use it to consume events from Kafka
-
Why are Clojure beginners just like vegans searching for good cheese? - on Lambda Island
-
Ping CRM on Clojure - a demo of implementing Ping CRM on Clojure+ClojureScript
-
Organizing Clojure code - a discussion from Clojureverse
-
An Animated Introduction to Clojure - by Mark Mahoney
Throwback Friday (I know, I’m doing it wrong)
In this recurring segment, we harken back to a talk from an older time to a favorite talk of yore. This week, we’re featuring:
-
Clojure: Programming with Hand Tools by Tim Ewald
Is it about woodworking? Is it about Clojure? Is it about how to work? Yes.
Blacktocats turn five
The GitHub Blog 10 06 2021
Boop!
Josh Comeau's blog 10 06 2021
Let's Bring Spacer GIFs Back!
Josh Comeau's blog 10 06 2021
The Rules of Margin Collapse
Josh Comeau's blog 09 06 2021
What the heck, z-index??
Josh Comeau's blog 09 06 2021
Building a Magical 3D Button
Josh Comeau's blog 09 06 2021
How I Built My Blog
Josh Comeau's blog 09 06 2021
664
Extra Ordinary 09 06 2021

Exposed
MonkeyUser 08 06 2021
Data Platform Engineer
Brave Clojure Jobs 07 06 2021
Data Platform Engineer
Analytical Flavor Systems | Remote/NY,NY
remote
Advancing sensory science and reaching new taste buds
$120000 - $180000
Description
Analytical Flavor Systems is a venture-backed startup that models human sensory perception of flavor, aroma, and texture using proprietary machine learning in order to predict consumer preference of food and beverage products. The work we do allows our clients in the food & beverage industry to ask and answer questions about:
- their competitive landscape ("what do people like and dislike about my competitors' products?")
- optimizing existing products ("how can I make this cookie taste better?")
- novel flavor combinations for new product development ("would people like it if I combined matcha and strawberry in yogurt?")
Our data science capabilities are evolving from report generation to a data platform. That's where you come in.
The work expected of a data platform engineer at Analytical Flavor Systems covers several major areas:
- Building out a data model on Datomic to capture the information generated by our day-to-day data processing tasks in an immutable and readily queryable data store.
- Creating a data platform application layer to serve the needs of our data science team, our web console and our mobile data collection app.
- Rewriting existing data science code for execution in a distributed rather than single-machine environment.
- Maintaining and enhancing batch processing jobs to make them faster, more reliable, and more observable.
- Refactoring an existing codebase to be more modular: separating data transformations, modeling, and prediction steps into discrete functions with well-understood inputs and outputs, while testing for regressions in predictive capabilities.
Depending on your background and areas of expertise, your day-to-day work may focus more on one of these areas than others, but you should be able to keep the big picture in mind, and understand how the changes you make to one part of our system affect the whole. Your work will improve our ability to execute this code reliably, and replicate previous results. This work will also help us observe and capture the outputs of the analytical operations we perform so we get better insight into the state of the systems built atop our data science code.
You will be expected to become comfortable working in both Clojure and R, though no prior experience in R is required. This role offers you the chance to help develop the language of our research domain, which may help us identify potential new avenues of theoretical research in human sensory perception.
We are only considering candidates with USA work authorization or work visa (including OPT). AFS can sponsor H1-B renewals or transfers.
Requirements
Candidates should have at least 4 years of total programming experience, with at least 1 year of work in either a data engineering context or in building backend systems. Experience with Clojure or other functional programming languages is a plus, but not a requirement. Functional programming is as much a style and idiom of development as it is a family of languages. Candidates that have experience building modular systems that put data front and center, regardless of the implementation language, should be attracted to this role.
Candidates with experience supporting the work of researchers and data scientists are also strongly encouraged to apply. Have you made an analytical method production-ready after reading through someone else's prototype code? Are you interested in interoperability between R and Clojure? Have you helped deploy and monitor models in production? Experience with these questions gives you a good understanding of the requirements and scope of the systems we build.
The company is roughly 15 people total, so candidates will be working closely with other teams and areas of the business. Good communication skills, especially across varying levels of technical depth and skill, are preferred.
A good candidate should have experience in at least two of the following areas:
- Data science and analytics: you have enabled more powerful access to data for both technical and non-technical stakeholders. You understand how to support and enhance systems based on machine learning, and aren't afraid of diving in to build a more efficient implementation of an algorithm than one provided by a library.
- Data modeling: you have, either on your own or as part of a team, designed or extended a relational database schema to support application and business requirements.
- System design and maintenance: you know how to build and extend existing systems to make them more observable, fault-tolerant, and performant. You can ssh into a remote box to contextualize a problem that doesn't have an obvious cause.
- Automated QA and testing: you know what the invariant properties of both individual functions and system components are, and can represent those properties in code.
Benefits
- Competitive salary
- Standard benefits package (health insurance/vision/dental + 401k)
- Equity stake (Restricted Stock Units with 4-year annual vesting schedule)
- Remote-friendly (who isn't these days?). While we do plan on an eventual return to our office space in Manhattan once it's safe, immediate relocation to the NYC area is not an expectation of this role.
- That said, if you do end up in our NYC office you'll be able to join regular in-person tasting panels to get hands-on experience with the sensory data collection methods we use.
- Unlimited vacation policy
- Professional development budget
Cómo instalar Git en Centos 7
ochobitshacenunbyte 07 06 2021
Aprendemos a instalar Git en Centos 7. Aunque este programa de control de versiones ya viene en los repositorios de Centos o de Red Hat, si utilizamos la distribución del sombrero rojo, lo cierto...
La entrada Cómo instalar Git en Centos 7 se publicó primero en ochobitshacenunbyte.

Trabajar con un motor de plantillas en PHP simplifica la labor de concadenar variables en ficheros con mucho texto, como puede ser un html. Cualquier Framework que imagines incorpora un sistema similar pero podemos usarlo de manera independiente para pequeñas páginas o funcionalidades.
Primero debemos instalar Twig en su versión más reciente en la raíz del proyecto. Esto lo podemos realizar con composer.
composer require "twig/twig:^3.0"
Ahora creamos una carpeta donde almacenaremos todas las plantillas.
mkdir templates
Dentro creamos el archivo contacto.txt con el siguiente contenido.
Hola {{ nombre }},
gracias por escribirnos desde {{ email }} con el asunto "{{ asunto }}".
¡Nos vemos!
Como es un ejemplo, vamos a crear otro archivo, llamado contacto.html, con el contenido:
<h1>Hola {{ nombre }},</h1>
<p>gracias por escribirnos desde {{ email }} con el asunto "{{ asunto }}".</p>
<p>¡Nos vemos!</p>
Todas las variables entre {{ }} serán sustituidas por las variables que se definan. Si no ha quedado claro en breve lo entenderás.
En estos momentos disponemos de 2 plantillas con diferentes extensiones y formatos. No es obligatorio disponer de varias plantillas, busque aprecies que funciona de manera independiente con cualquier formato en texto plano.
Ahora creamos un archivo PHP donde ejecutaremos el código. Podemos llamarlo, por ejemplo, renderizar.php. Añadimos:
// Cargamos todas las extensiones. En este caso solo disponemos de Twig
require_once('vendor/autoload.php');
// Indicamos en Twig el lugar donde estarán las plantillas.
$loader = new \Twig\Loader\FilesystemLoader('templates');
// Cargamos las plantillas al motor de Twig
$twig = new \Twig\Environment($loader);
// Definimos las variables que deseamos rellenar en las plantillas.
$variablesEmail = [
'nombre' => 'Cid',
'email' => 'cid@campeador.vlc',
'asunto' => 'Reconquista'
];
// Renderizamos con la plantilla 'contacto.txt'
$plantillaPlana = $twig->render('contacto.txt', $variablesEmail);
// Renderizamos con la plantilla 'contacto.html'
$plantillaHTML = $twig->render('contacto.html', $variablesEmail);
Si yo hiciera un echo de cada variable podemos ver el trabajo realizado.
echo $plantillaPlana;
/**
Hola Cid,
gracias por escribirnos desde cid@campeador.vlc con el asunto "Reconquista".
¡Nos vemos!
**/
echo $plantillaHTML;
/**
<h1>Hola Cid,</h1>
<p>gracias por escribirnos desde cid@campeador.vlc con el asunto "econquista".</p>
<p>¡Nos vemos!</p>
**/
Y eso es todo.
Es realmente interesante para trabajar con emails, plantillas más complejas o en la búsqueda de renderizar un PDF. Sea cual sea tu objetivo final, disponer de un motor de plantillas en PHP hará más fácil tu trabajo.

A diferencia de otros sectores, los profesionales de las habilidades relacionadas con la tecnología, suelen contar con más opciones y oportunidades laborales. Por si fuera poco ese mercado de programadores, desarrolladores y consultores tecnológicos, opta desde hace tiempo, a trabajos en remoto y a condiciones laborales que durante la pandemia han experimentado un notable auge.
Los developers están por tanto en una especie de burbuja laboral, donde a la hora de valorar un puesto de trabajo o un cambio, existen diferentes motivaciones que merece la pena discutir.
En este episodio queremos hablar sobre los motivos que tienen los developers a la hora de afrontar cambios laborales y el punto de vista que a menudo tienen con respecto a su vida profesional. Aunque en muchas ocasiones esas motivaciones coincidan con otros perfiles profesionales, creemos muy interesante poder contar las experiencias o casos que hayamos visto o vivido.
El próximo episodio del podcast irá sobre los motivos que llevan a los «developers» a cambiar de trabajo. ¿Qué te motiva **principalmente** para valorar un cambio de trabajo?
— Podcast República Web (@republicawebes) June 4, 2021
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Clojure Deref (June 4, 2021)
Clojure News 04 06 2021
Welcome to the Clojure Deref! This is a new periodic (thinking bi-weekly) link/news roundup for the Clojure ecosystem. We’ll be including links to Clojure articles, Clojure libraries, and when relevant, what’s happening in the Clojure core team.
Highlights
ClojureScript turns 10 this week! Happy birthday ClojureScript! :cake: We mark this from the first commit by Rich Hickey in the repo. Several thousand commits later things are still going strong and David Nolen and Mike Fikes continue to lead the project. ClojureScript recently released version 1.10.866.
The StackOverflow developer’s survey for 2021 just opened. Last year they removed Clojure from the survey because they were scared we were growing too powerful (I assume). But this year’s survey includes Clojure as an option again, so let them know you’re out there! (It also seems a lot shorter this year.)
The :clojureD Conference is just hours away! Ticket sales have ended but presumably talks will be made available afterwards. If you’re going, we’ll see you there!
Experience reports
This week we saw several interesting Clojure experience reports worth mentioning:
-
Red Planet Labs gave an overview of their codebase and some of the techniques they use pervasively - using Schema, monorepo, Specter for polymorphic data, Component, with-redefs for testing, macros and more.
-
Jakub Holý at Telia talked about the importance of interactive development with Clojure.
-
Crossbeam did a talk at Philly Tech Week about why they bet on Clojure and their experience with hiring.
-
Shivek Khurana talked about how to find a job using Clojure. There are now many companies using and hiring for Clojure, although sometimes it’s challenging to find a Clojure job that is a good match for your location and/or experience - these are some great tips!
Libraries
Some interesting library updates and posts this week:
-
Asami - Paula Gearon wrote a nice overivew of querying graph dbs
-
Joe Littlejohn at Juxt wrote an overview of the Clojure JSON ecosystem covering many popular libraries and their tradeoffs
-
odoyle-rules - Zach Oakes added a new section on defining rules dynamically
-
Reveal - Vlad wrote about viewing Vega charts in Reveal
-
Pathom - Wilker Lucio gives some updates on many features
Art
-
As always Jack Rusher has been up to making beautiful art with Clojure, in particular exploring 3D rendered attractors like the Golden Aizwa Attractor (the Clojure code) and Three-Scroll Uunified Attractor, and one made in bone. Hit his feed for lots more cool projects, often made with Clojure.
Feedback
You can find future episodes on the RSS feed for this blog. Should it be an email newsletter too?
Let us know!

Loading Weekend
MonkeyUser 04 06 2021
Passport
Stratechery by Ben Thompson 03 06 2021
Senior Software Developer
Brave Clojure Jobs 03 06 2021
Senior Software Developer
LegalMate | Toronto || Anywhere
remote
We are bringing progressive and modern financial services to the legal world.
$110000 - $140000
About LegalMate
Our mission is make access to justice affordable. In North America, almost $400 billion dollars is spent every year on legal services, yet 86% of of civil legal problems faced by low-income individuals receive either inadequate or no legal help at all. The legal system is intended to benefit us all, not just the top 10% of income earners.
We are bringing progressive and modern financial services to the legal world, opening the door for more people to access legal services and seek justice.
- We're VC-backed and well capitalized
- We have paying customers and exciting MoM growth
- Our founding team has an exceptional track record
- ($2.5 billion in shareholder value created in previous 3 ventures)
- Our first product is "Buy Now Pay Later" for legal services: think Affirm for lawyers
Role & Responsibilities
This is the first full-time hire on our engineering team, apart from our CTO. Consequently, candidates should expect a high degree of trust and autonomy. We intend to do great work together over the long-term, and we insist that anybody joining LegalMate at this stage is ready to grow with the company and take on more responsibility as we scale.
We are a Clojure shop and are looking to work with engineers eager to apply functional programming concepts. We are happy to train folks up on Clojure!
- Write production-grade Clojure and ClojureScript
- Review code, and provide constructive and useful feedback
- Create and collaborate on technical designs, document them
- Coach and mentor junior Clojurians in the making
- Introducing new developers to Clojure is a critical to our strategy
- Elevate the test-ability and re-usability of existing code
- Help evaluate and hire additional engineering team members (in the future)
Recommended Experience
These are provided for you to understand the relative skill and experience level of the candidates we're seeking. If you don't meet or exceed these 100%, that's OK! Please consider applying regardless.
- 5+ yrs of professional software development experience (Clojure or otherwise)
- 2+ yrs of Clojure development experience (professional or hobby)
- Previous experience working on small teams that scaled up
- You have a track record of leading successful projects
- You can give concrete examples of when you've received some hard feedback, and when you've had to deliver some hard feedback too
About You
This role is ideal for a senior developer who's comfortable with Clojure (or wants to learn), and who wants to participate in building and growing a world-class engineering team and company.
- You're more motivated to help humans than you are to solve coding puzzles
- You're comfortable with Clojure idioms (or want to learn) and functional programming concepts
- The idea of working with functional programming (Clojure) full-time is exciting and motivating
- You use data to help make decisions and inform designs
- You know how to manage your energy and time
Nice-to-have Qualities You Might Have
- You have prior experience in financial technology, or legal technology
- To you, working on legal financial tech doesn't sound boring: it sounds awesome
- You're ready to quit programming if you don't get to use functional programming in you're next position
Remote Clojure Developer
Brave Clojure Jobs 02 06 2021
Remote Clojure Developer
Insight Global | US Based
remote
$135000 - $165000
Do you like solving interesting problems? Are you passionate about working in one of the fastest growing product lines in the cybersecurity industry? Want a competitive salary and benefits to support a stable, high-quality life outside of work? Want to work for an organization that will assist in developing your skills, talents, help you grow? Are you someone who wants flexibility and good work/life balance? Do you love working from home?
If you enjoy working with a group of creative, talented and enthusiastic individuals on problems at the intersection of data design, transparency and interaction, then please apply so we can make the connection to the decision makers for this opening.
Required: - Bachelor’s Degree - 8+ years industry experience - 2+ years’ experience in Clojure/ClojureScript
Ideal but not Required: - Advanced UI and visualization in the browser (SVG, D3, Grammar of Graphics, Tufte, Bertin) - Systems architecture (Object orientation, patterns, service orientation, reactive, functional-relational, and back again) - Logic programming (Prolog, rule systems) - Databases, inverted indexes, message queueing (Elasticsearch, Kafka, etc.) - Provisioning and configuration management (cough, cloud)
On behalf of our Client, we are seeking 3 Remote Clojure Developers to join a team of experienced Senior Clojure developers to on their Threat Response team. They use Clojure to mesh large volumes of high dimensional network, host and service information with taxonomic information about malicious software. Much of our work involves understanding and reasoning about this data, which describes the behavior of systems, and by extension, the capabilities, and intentions of these systems’ users.
Consequently, there is a lot of room to explore and apply techniques of logic programming in a practical, useful, fascinating, expansive, and evolving problem domain. The overarching goal is to provide tools that benefit the security of their end customers’ infrastructure.
The Threat Response team is distributed across North America and Europe, working from home, key characteristics included excellent verbal and written communication skills, sociability, and pride in carrying out duties and discharging responsibilities with exuberance and alacrity. The team draws on the best of agile themes and techniques of the past 30 years—continuous integration and deployment, testing, flexible collaboration with globally distributed team members via chat and video, and gradual, deliberate optimization of process in the name of keeping projects and releases flowing smoothly, in order to provide an excellent product to customers. The team is surrounded by talented QA, UX, support, documentation writers, and management - we hold ourselves to high standards.
![]()
Today we are excited to announce improved font rendering in the latest Canary builds of Microsoft Edge on Windows. We have improved the contrast enhancement and gamma correction to match the quality and clarity of other native Windows applications. F
The post Improving font rendering in Microsoft Edge appeared first on Microsoft Edge Blog.
663
Extra Ordinary 02 06 2021
Software Developer, Full Stack
Brave Clojure Jobs 02 06 2021
Software Developer, Full Stack
Pilloxa | Remote, 4h overlap with Stockholm (CET) during workday
remote
€40000 - €80000
About Pilloxa
Pilloxa is on a mission to improve patients' adherence to their treatment. Non-adherence to one's treatment plan is all too common. It is estimated to be the root cause of every 10th hospitalization and 8 deaths daily, in Sweden alone. Adherence to treatment is hard, and at Pilloxa we have set our minds to making it easier.
Pilloxa is a medtech company based in Stockholm, Sweden working with the latest technologies in an effort to improve the patient journey and quality of life for patients. We work together with patients, healthcare and pharmaceutical companies in bringing together all actors that have an impact on patients' treatment.
Role
You'll be an integral part of our small and flat team, working closely with the product and building a first-class user experience. The app is the centerpiece of Pilloxa's service and this is where you'll likely spend most of your time hacking in ClojureScript. As we grow you'll also likely be extending our still small Clojure backend and dabble with all parts of the stack.
Preferred experience
The more boxes you tick, the better.
- Passion for making a positive impact in peoples' lives
- 2+ years full-stack engineer
- MSc in Computer Science or equivalent
- Experience with Clojure
- Experience with React Native
- Experience with reagent/re-frame
- Startup experience
Process
- Call with CTO
- Call with Co-founder
- Technical assignment (max 8h)
- Presentation of assignment
- Call with CEO
- Reference calls
![]()
Starting with Microsoft Edge 92, users can preview the Automatic HTTPS feature, which automatically switches your connections to websites from HTTP to HTTPS.
As you browse the web, you may notice that the Microsoft Edge address bar displays a “not
The post Available for preview: Automatic HTTPS helps keep your browsing more secure appeared first on Microsoft Edge Blog.
![]()
A look at how we can save our websites from ourselves, and the stories that keep us going.
The post May 2021 Weblog: Communities Long Gone appeared first on The History of the Web.

Una buena práctica es no dejar secretos, como contraseñas o Tokens, dentro del código. Y ni mencionar el peligro que conlleva subirlo a un repositorio. En gran medida se hace hincapié en esta omisión de variables por no dejar expuesto al resto del equipo un contenido sensible. Además otorga la posibilidad de jugar con diferentes credenciales durante el desarrollo, algunas pueden ser solo para hacer pruebas y otras las que serán usadas en el proyecto final.
Muchos Frameworks ya incorporan un sistema similar al que vamos a mencionar. En breve descubrirás que la técnica es tan sencilla que puedes montártelo por tu cuenta.
Primero crea un archivo plano con el siguiente contenido. Yo lo llamaré: .env
TOKEN=123456789
USER=TUX
PASSWORD=qwe123
Son 3 futuras variables de entorno con sus valores.
A continuación ejecuta el siguiente comando en el terminal, en la misma carpeta donde se encuentra el fichero. Convertirá cada línea del fichero en una variable de entorno.
export $(cat .env | egrep -v "(^#.*|^$)" | xargs)
Si quieres comprobar que se ha ejecutado correctamente puedes hacer un echo con cualquier variable añadiendo el prefijo $.
echo $TOKEN
123456789
Tarea terminada. Recuerda que si cierras el terminal o modificas el archivo, debes volver a ejecutar el comando.
Leer variables de entorno en PHP
$token = getenv('TOKEN');
$user = getenv('USER');
$password = getenv('PASSWORD');
echo $token;
// 123456789
Leer variables de entorno en Python
import os
token = os.getenv('TOKEN')
user = os.getenv('USER')
password = os.getenv('PASSWORD')
Leer variables de entorno en Clojure
(def token (System/getenv "TOKEN"))
(def user (System/getenv "USER"))
(def password (System/getenv "PASSWORD"))
Aunque también puedes usar la dependencia environ.
Añade en project.clj.
[environ "0.5.0"]
Y usa con total libertad.
(require [environ.core :refer [env]])
(def token (env :TOKEN))
(def user (env :USER))
(def password (env :PASSWORD))
![]()
The Perils of Rehydration
Josh Comeau's blog 30 05 2021
La evolución del Jamstack
República Web 28 05 2021
Dedicamos este episodio a comentar el artículo de Matt Biilmann publicado recientemente en Smashing Magazine titulado The evolution of Jamstack. Mathias Biilmann es CEO de Netlify y uno de los precursores del termino Jamstack. En este artículo Biilmann empieza rememorando su presentación en el 2016 durante la SmashingConf, donde daba a conocer los principios que sustentan la arquitectura Jamstack. Ahora en 2021 Matt quiere ofrecer una perspectiva sobre cómo están evolucionando las técnicas y las soluciones orientadas a esta arquitectura de Jamstack.
Empezamos el episodio hablando recordando los principios del Jamstack, como son la prioridad a que el front se construya lo antes posible y que exista un sólido desacople entre el front y el back. El segundo principio del Jamstack hace referencia a la obtención de datos bajo demanda (JavaScript y APIs).
En la segunda parte hablamos de los tres puntos que según Matt marcan la evolución del Jamstack:
- Renderizado Persistente Distribuido o DPR.
- Actualizaciones en streaming desde la capa de datos.
- Colaboración entre desarrolladores se hace popular.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

Evercade VS Pre-Orders NOW OPEN
Evercade 28 05 2021
The Evercade VS Pre-Orders are now open! You can pre-order your Starter and Premium Packs from your preferred retailer right now. Find the link to your local retailer below, or visit the Retailers Page: AUSTRALIA PIXEL CRIB: Starter Pack – https://www.pixelcrib.com.au/collections/evercade/products/evercade-vs Premium Pack – https://www.pixelcrib.com.au/collections/evercade/products/evercade-vs-premium-pack CANADA AMAZON.CA: Starter Pack – https://www.amazon.ca/dp/B094F6GJ83 Premium Pack – https://www.amazon.ca/dp/B094F5ZGX8... View Article
The post Evercade VS Pre-Orders NOW OPEN appeared first on Evercade.
Evercade VS – What’s in the Box?
Evercade 27 05 2021
The Evercade VS will be available to Pre-Order from May 28th with the release date of November 3rd 2021. The console is available in two packs: STARTER PACK The Evercade VS Starter Pack is the entry point to the new Evercade home console system. This package comes with: Evercade VS Console Evercade VS Controller Technos... View Article
The post Evercade VS – What’s in the Box? appeared first on Evercade.
When we came up with the idea for the Evercade VS Founder Edition, we wanted to reward our fans and our most passionate adopters. To give them something that really allows them to become a part of the console and in some way to thank everyone for the passion, dedication and love shown from the... View Article
The post Evercade VS Founder Edition – How to get Your Name in the Evercade VS Credits appeared first on Evercade.
662
Extra Ordinary 26 05 2021
App Store Arguments
Stratechery by Ben Thompson 25 05 2021
![]()
Welcome back to Microsoft Build! Wherever this finds you, we hope that you’re safe and healthy.
Since last Build, the Microsoft Edge platform continues to empower developers with the latest tools ready for today’s evolving web land
The post What’s new for Microsoft Edge at Microsoft Build 2021 appeared first on Microsoft Edge Blog.

Observer
MonkeyUser 25 05 2021
Principal Software Engineer
Brave Clojure Jobs 24 05 2021
Principal Software Engineer
Barracuda Networks | United States
remote
****Description****
Come Join Our Passionate Team! At Barracuda, we make the world a safer place. We believe every business deserves access to cloud-enabled, enterprise-grade security solutions that are easy to buy, deploy, and use. We protect email, networks, data and applications with innovative solutions that grow and adapt with our customers' journey. More than 220,000 organizations worldwide trust Barracuda to protect them --- in ways they may not even know they are at risk --- so they can focus on taking their business to the next level.
We know a diverse workforce adds to our collective value and strength as an organization. Barracuda Networks is proud to be an Equal Opportunity Employer, committed to equal employment opportunity and equitable compensation regardless of race, gender, religion, sex, sexual orientation, national origin, or disability.
Envision yourself at Barracuda
We are looking for a Principal Software Engineer to join our distributed team. This is a great opportunity to work on large scale distributed systems underpinning our SaaS cloud applications for email security. These products process massive data coming at us in a steady stream with performance requirements in near real time. Our engineers know they make a difference because the solutions developed are protecting our customers against a growing number of threats. Each of our team members has varied talents that, together create an environment with a depth of knowledge. This allows for autonomy and innovation in developing solutions. The products we work on evolve with your added experience and likewise, you'll be immersed in a rewarding environment. We solve tough problems related to scalability and system architecture.
Tech Stack:
- Clojure, Elasticsearch, Kafka, Postgres, Kubernetes, Docker, AWS, Amazon Managed Services, Redis, Sumo Logic, etc.
What you'll be working on:
- Solve important scaling problems around processing of huge volumes of data in near real-time and providing features atop petabytes of data under management.
- Introduce advanced security features.
- Drive design, implementation, and review of major areas of the codebase, adding new features and evolving our next generation architecture.
- Contribute to a team that values code quality, innovative thinking, good communication, occasional pair programming, sound testing practices, and opportunities for mentoring.
What you bring to the role:
- 8+ years of relevant experience delivering well-designed, scalable cloud software
- Experience with functional programming (e.g. Clojure, java, etc.)
- Experience with Lucene or Elasticsearch, or Streaming systems like Kafka
- Demonstrated success in an Agile/Scrum development environment
- Ability to communicate in a collaborative environment - in your code, in the documentation, and in chats and conversations with others
- Bachelor's degree in a technology field or equivalent work experience
- Ability to learn and adapt quickly in a high-energy environment
- Knowledge of search, content management, and analytics is a plus
- Exposure to Kubernetes is a plus
What you'll get from us
A team where you can voice your opinion, make an impact, and where you and your experience are valued. Internal mobility -- there are opportunities for cross training and the ability to attain your next career step within Barracuda.
- High-quality health benefits
- Retirement Plan with employer match
- Career-growth opportunities
- Flexible Time Off and Paid Time Off benefits
- Volunteer opportunities
- Job ID 22-081

Discovering the Lispworks IDE
Lisp journey 24 05 2021
LispWorks is a Common Lisp implementation that comes with its own Integrated Development Environment (IDE) and its share of unique features, such as the CAPI GUI toolkit. It is proprietary and provides a free limited version.
Here, we will mainly explore its IDE, asking ourselves what it can offer to a seasoned lisper used to Emacs and Slime. The short answer is: more graphical tools, such as an easy to use graphical stepper, a tracer, a code coverage browser or again a class browser. Setting and using breakpoints was easier than on Slime.
LispWorks also provides more integrated tools (the Process browser lists all processes running in the Lisp image and we can stop, break or debug them) and presents many information in the form of graphs (for example, a graph of function calls or a graph of all the created windows).
Note: you will find updated versions of this review on the Cookbook.
LispWorks features
We can see a matrix of LispWorks features by edition and platform here: http://www.lispworks.com/products/features.html.
We highlight:
- 32-bit, 64-bit and ARM support on Windows, MacOS, Linux, Solaris, FreeBSD,
- CAPI portable GUI toolkit: provides native look-and-feel on Windows, Cocoa, GTK+ and Motif.
- comes with a graphical “Interface Builder” (think QtCreator) (though not available on MacOS (nor on mobile))
- LispWorks for mobile runtime, for Android and iOS,
- optimized application delivery: LispWorks can use a tree shaker to remove unused lisp code from the delivered applicatiion, thus shipping lighter binaries than existing open-source implementations.
- ability to deliver a dynamic library,
- a Java interface, allowing to call from Lisp to Java or the other way around,
- an Objective-C and Cocoa interface, with drag and drop and multi-touch support,
- a Foreign Language Interface,
- TCP/UDP sockets with SSL & IPv6 support,
- natived threads and symmetric multiprocessing, unicode support, and all other Common Lisp features, and all other LispWorks Enterprise features.
And, of course, a built-in IDE.
LispWorks is used in diverse areas of the industry. They maintain a list of success stories. As for software that we can use ourselves, we find ScoreCloud amazing (a music notation software: you play an instrument, sing or whistle and it writes the music) or OpenMusic (opensource composition environment).
Free edition limitations
The download instructions and the limitations are given on the download page.
The limitations are the following:
- There is a heap size limit which, if exceeded, causes the image to exit. A warning is provided when the limit is approached.
What does it prevent us to do? As an illustration, we can not load this set of libraries together in the same image:
(ql:quickload '("alexandria" "serapeum" "bordeaux-threads" "lparallel" "dexador" "hunchentoot" "quri" "ltk" "cl-ppcre" "mito"))
There is a time limit of 5 hours for each session, after which LispWorks Personal exits, possibly without saving your work or performing cleanups such as removing temporary files. You are warned after 4 hours of use.
It is impossible to build a binary. Indeed, the functions save-image, deliver (the function to create a stand-alone executable), and load-all-patches are not available.
Initialization files are not loaded. If you are used to initializing Quicklisp from your
~/.sbclrcon Emacs, you’ll have to load an init file manually every time you start LispWorks ((load #p"~/.your-init-file)).
For the record, the snippet provided by Quicklisp to put in one’s startup file is the following:
;; provided you installed quicklisp in ~/quicklisp/
(let ((quicklisp-init (merge-pathnames "quicklisp/setup.lisp" (user-homedir-pathname))))
(when (probe-file quicklisp-init)
(load quicklisp-init)))
You’ll have to paste it to the listener window (with the C-y key, y as “yank”).
- Layered products that are part of LispWorks Professional and Enterprise Editions (CLIM, KnowledgeWorks, Common SQL and LispWorks ORB) are not included. But we can try the CAPI toolkit.
The installation process requires you to fill an HTML form to receive a download link, then to run a first script that makes you accept the terms and the licence, then to run a second script that installs the software.
Licencing model
LispWorks actually comes in four paid editions. It’s all explained by themselves here: http://www.lispworks.com/products/lispworks.html. In short, there is:
- a Hobbyist edition with
save-imageandload-all-patches, to apply updates of minor versions, without the obvious limitations, for non-commercial and non-academic use, - a HobbyistDV edition with the
deliverfunction to create executables (still for non-commercial and non-academic uses), - a Professional edition, with the
deliverfunction, for commercial and academic uses, - an Enterprise one, with their enterprise modules: the Common SQL interface, LispWorks ORB, KnowledgeWorks.
At the time of writing, the licence of the hobbyist edition costs 750 USD, the pro version the double. They are bought for a LW version, per platform. They have no limit of time.
NB: Please double check their upstream resources and don't hesitate to contact them.
LispWorks IDE
The LispWorks IDE is self-contained, but it is also possible to use LispWorks-the-implementation from Emacs and Slime (see below).
The editor
The editor offers what’s expected: a TAB-completion pop-up, syntax
highlighting, Emacs-like keybindings (including the M-x extended
command). The menus help the discovery.
We personally found the editing experience a bit “raw”. For example: - indention after a new line is not automatic, one has to press TAB again. - the auto-completion is not fuzzy. - there are no plugins similar to Paredit or Lispy, nor a Vim layer.
We also had an issue, in that the go-to-source function bound to M-.
did not work out for built-in Lisp symbols. This is probably a free
edition limitation too.
The editor provides an interesting tab: Changed Definitions. It lists the functions and methods that were redefined since, at our choosing: the first edit of the session, the last save, the last compile.
See also:
- the Editor User Guide.
Keybindings
Most of the keybindings are similar to Emacs, but not all. Here are some differences:
- to compile a function, use
C-S-c(control, shift and c), instead of C-c C-c. - to compile the current buffer, use
C-S-b(instead of C-c C-k).
Similar ones include:
C-gto cancel what you’re doing,C-x C-sto save the current buffer,M-wandC-yto copy and paste,M-b,M-f,C-a,C-e… to move around words, to go to the beginning or the end of the line,C-kto kill until the end of the line,C-wto kill a selected region,M-.to find the source of a symbol,C-x C-eto evaluate the current defun,- …
Some useful functions don’t have a keybinding by default, for example:
- clear the REPL with
M-x Clear Listener Backward Kill Line
It is possible to use classical keybindings, à la KDE/Gnome. Go to the Preferences menu, Environment and in the Emulation tab.
There is no Vim layer.
Searching keybindings by name
It is possible to search for a keybinding associated to a function, or
a function name from its keybinding, with the menu (Help -> Editing ->
Key to Command / Command to Key) or with C-h followed by a key,
as in Emacs. For example type C-h k then enter a keybinding to
get the command name. See more with C-h ?.
Tweaking the IDE
It is possible to change keybindings. The editor’s state is accessible
from the editor package, and the editor is built with the CAPI
framework, so we can use the capi interface too. Useful functions
include:
`
editor:bind-key
editor:defcommand
editor:current-point
editor:with-point ;; save point location
editor:move-point
editor:*buffer-list*
editor:*in-listener* ;; returns T when we are in the REPL
…
Here’s how you can bind keys:
;; Indent new lines.
;; By default, the point is not indented after a Return.
(editor:bind-key "Indent New Line" #\Return :mode "Lisp")
;; Insert pairs.
(editor:bind-key "Insert Parentheses For Selection" #\( :mode "Lisp") ;;
(editor:bind-key "Insert Double Quotes For Selection" #\" :mode "Lisp")
Here’s how to define a new command. We make the ) key
to go past the next closing parenthesis.
(editor:defcommand "Move Over ()" (p)
"Move past the next close parenthesis.
Any indentation preceeding the parenthesis is deleted."
"Move past the next close parenthesis."
;; thanks to Thomas Hermann
;; https://github.com/ThomasHermann/LispWorks/blob/master/editor.lisp
(declare (ignore p))
(let ((point (editor:current-point)))
(editor:with-point ((m point))
(cond ((editor::forward-up-list m)
(editor:move-point point m)
(editor::point-before point)
(loop (editor:with-point ((back point))
(editor::back-to-indentation back)
(unless (editor:point= back point)
(return)))
(editor::delete-indentation point))
(editor::point-after point))
(t (editor:editor-error))))))
(editor:bind-key "Move Over ()" #\) :mode "Lisp")
And here’s how you can change indentation for special forms:
(editor:setup-indent "if" 1 4 1)
See also:
- a list of LispWork keybindings: https://www.nicklevine.org/declarative/lectures/additional/key-binds.html
The listener
The listener is the REPL.
Its interactive debugger is primarily textual but you can also interact with it with graphical elements. For example, you can use the Abort button of the menu bar, which brings you back to the top level. You can invoke the graphical debugger to see the stacktraces and interact with them. See the Debugger button at the very end of the toolbar.

If you see the name of your function in the stacktraces (you will if you wrote and compiled your code in a file, and not directly wrote it in the REPL), you can double-click on its name to go back to the editor and have it highlight the part of your code that triggered the error.
NB: this is equivalent of pressing
M-v in Slime.
The stepper. Breakpoints.
The stepper is one of the areas where LispWorks shines.
When your are writing code in the editor window, you can set
breakpoints with the big red “Breakpoint” button (or by calling M-x Stepper Breakpoint).
This puts a red mark in your code.
The next time your code is executed, you’ll get a comprehensive Stepper pop-up window showing:
- your source code, with an indicator showing what expression is being evaluated
- a lower pane with two tabs:
- the backtrace, showing the intermediate variables, thus showing their evolution during the execution of the program
- the listener, in the context of this function call, where you can evaluate expressions
- and the menu bar with the stepper controls: you can step into the next expression, step on the next function call, continue execution until the position of the cursor, continue the execution until the next breakpoint, etc.

That’s not all. The non-visual, REPL-oriented stepper is also nice. It shows the forms that are being evaluated and their results.
In this example, we use :s to “step” though the current form and its subforms. We are using the usual listener, we can write any Lisp code after the prompt (the little -> here), and we have access to the local variables (X).
CL-USER 4 > (defun my-abs (x) (cond ((> x 0) x) ((< x 0) (- x)) (t 0)))
CL-USER 5 > (step (my-abs -5))
(MY-ABS -5) -> :s
-5 -> :s
-5
(COND ((> X 0) X) ((< X 0) (- X)) (T 0)) <=> (IF (> X 0) (PROGN X) (IF (< X 0) (- X) (PROGN 0)))
;; Access to the local variables:
(IF (> X 0) (PROGN X) (IF (< X 0) (- X) (PROGN 0))) -> (format t "Is X equal to -5? ~a~&" (if (equal x -5) "yes" "no"))
Is X equal to -5? yes
(IF (> X 0) (PROGN X) (IF (< X 0) (- X) (PROGN 0))) -> :s
(> X 0) -> :s
X -> :s
-5
0 -> :s
0
NIL
(IF (< X 0) (- X) (PROGN 0)) -> :s
(< X 0) -> :s
X -> :s
-5
0 -> :s
0
T
(- X) -> :s
X -> :s
-5
5
5
5
5
Here are the available stepper commands (see :?):
:s Step this form and all of its subforms (optional +ve integer arg)
:st Step this form without stepping its subforms
:si Step this form without stepping its arguments if it is a function call
:su Step up out of this form without stepping its subforms
:sr Return a value to use for this form
:sq Quit from the current stepper level
:bug-form <subject> &key <filename>
Print out a bug report form, optionally to a file.
:get <variable> <command identifier>
Get a previous command (found by its number or a symbol/subform within it) and put it in a variable.
:help Produce this list.
:his &optional <n1> <n2>
List the command history, optionally the last n1 or range n1 to n2.
:redo &optional <command identifier>
Redo a previous command, found by its number or a symbol/subform within it.
:use <new> <old> &optional <command identifier>
Do variant of a previous command, replacing old symbol/subform with new symbol/subform.
The class browser
The class browser allows us to examine a class’s slots, parent classes, available methods, and some more.
Let’s create a simple class:
(defclass person ()
((name :accessor name
:initarg :name
:initform "")
(lisper :accessor lisperp
:initform t)))
Now call the class browser:
- use the “Class” button from the listener,
- or use the menu Expression -> Class,
- or put the cursor on the class and call
M-x Describe class.

It is composed of several panes:
- the class hierarchy, showing the superclasses on the left and the subclasses on the right, with their description to the bottom,
- the superclasses viewer, in the form of a simple schema, and the same for subclasses,
- the slots pane (the default),
- the available initargs,
- the existing generic functions for that class
- and the class precedence list.
The Functions pane lists all methods applicable to that class, so we can discover public methods provided by the CLOS object system: initialize-instance, print-object, shared-initialize, etc. We can double-click on them to go to their source. We can choose not to include the inherited methods too (see the “include inherited” checkbox).
You’ll find buttons on the toolbar (for example, Inspect a generic function) and more actions on the Methods menu, such as a way to see the functions calls, a menu to undefine or trace a function.
See more:
The function call browser
The function call browser allows us to see a graph of the callers and the callees of a function. It provides several ways to filter the displayed information and to further inspect the call stack.
NB: The Slime functions to find such cross-references are
slime-who-[calls, references, binds, sets, depends-on, specializes, macroexpands].
After loading a couple packages, here’s a simple example showing who calls the string-trim function.

It shows functions from all packages, but there is a select box to restrict it further, for example to the “current and used” or only to the current packages.
Double click on a function shown in the graph to go to its source. Again, as in many LispWorks views, the Function menu allows to further manipulate selected functions: trace, undefine, listen (paste the object to the Listener)…
The Text tab shows the same information, but textually, the callers and callees side by side.
We can see cross references for compiled code, and we must ensure the feature is on. When we compile code, LispWorks shows a compilation output likes this:
;;; Safety = 3, Speed = 1, Space = 1, Float = 1, Interruptible = 1
;;; Compilation speed = 1, Debug = 2, Fixnum safety = 3
;;; Source level debugging is on
;;; Source file recording is on
;;; Cross referencing is on
We see that cross referencing is on. Otherwise, activate it with (toggle-source-debugging t).
See more:
The Process Browser
The Process Browser shows us a list of all threads running. The input area allows to filter by name. It accepts regular expressions. Then we can stop, inspect, listen, break into these processes.

See more:
Using LispWorks from Emacs and Slime
To do that, start LispWorks normally, start a Swank server and connect to it from Emacs (Swank is the backend part of Slime).
First, let’s load the dependencies:
(ql:quickload "swank")
;; or
(load "~/.emacs.d/elpa/slime-20xx/swank-loader.lisp")
Start a server:
(swank:create-server :port 9876)
;; Swank started at port: 9876.
9876
From Emacs, run M-x slime-connect, choose localhost and 9876 for the port.
You should be connected. Check with: (lisp-implementation-type). You are now able to use LispWorks’ features:
(setq button
(make-instance 'capi:push-button
:data "Button"))
(capi:contain button)
See also
- LispWorks IDE User Guide (check out the sections we didn’t cover)
- LispWorks on Wikipedia
- the Awesome LispWorks list
And voilà, our review ends here. I’m happy to have this tool under my toolbet, and I want to explore the CAPI toolkit more. But for now I don’t use LispWorks daily, so if you do, don’t hesitate to leave a comment with a tip or to highlight a feature you really like. Thanks!
![]()
For many students, math can be a particularly challenging subject in school. Math is sequential, in that each lesson is part of the foundation for future learning. If students do not have a solid understanding of each concept as they go, it may impac
The post Preview Microsoft Math Solver in Microsoft Edge appeared first on Microsoft Edge Blog.
UPDATE (27/05/21): The Evercade VS Limited Founder Edition is available NOW! Click the link below to pre-order yours UPDATE (27/05/21): Evercade VS Limited Founder Edition Additional Controllers will be available to Pre-Order from May 27, while stocks last. UPDATE (26/05/21): We have added a final exclusive Feature: Your Name in the Credits of the Evercade VS!... View Article
The post Introducing the Evercade VS Founder Edition appeared first on Evercade.
Hoy echamos un vistazo rápido, a la herramienta de copias de seguridad, para sistemas de ficheros VxFS, en sistemas HP-UX, llamada vxdump. Me he tenido que pelear últimamente un poco con ella en este,...
La entrada vxdump: copias de seguridad en HP-UX se publicó primero en ochobitshacenunbyte.
661
Extra Ordinary 19 05 2021
![]()
Arcade Games are Coming to Evercade!
Evercade 18 05 2021
Arcade games are coming to the Evercade with the announcement of four new cartridges! All four Arcade collections will feature arcade versions of the included games, from classic hits to some rediscovered greats. These new cartridges follow the now traditional Evercade formula of providing something everyone loves and something new to discover. In total, there... View Article
The post Arcade Games are Coming to Evercade! appeared first on Evercade.
![]()
![]()
The Right to Link
The History of the Web 18 05 2021
You can link to anything on the web. That's a strength. And yet the right to link has been dragged into court on a regular basis for decades. Why is that?
The post The Right to Link appeared first on The History of the Web.

New Library
MonkeyUser 18 05 2021
Frontend Engineer
Brave Clojure Jobs 17 05 2021
Frontend Engineer
Multis | Europe
remote
About Multis
Multis provides financial services for companies holding euros, dollars, and cryptocurrencies. We are building the best crypto wallet designed for businesses who need to scale, move fast, make the most of their crypto and fiat currencies. We're helping these companies to shape a global and borderless economy through Decentralized Finance (DeFi)!
We're a team of happy and passionate crypto-dreamers: Thibaut (CEO) and Greg (CTO), with backing from world-class US and European investors like Y Combinator, Coinbase Ventures and eFounders. The company is incorporated in San Francisco but we're working from Europe for now.
What's so special about engineering at Multis?
Multis engineering is working at the cutting edge of FinTech and Blockchain with powerful technologies like ClojureScript, Re-frame and Firebase.
Our server-less architecture powered by functional programming is helping us to keep ourselves focused on our core domain and build a delightful experience.
Our engineering principles? Simplicity, quality and a magical UX!
Mission
We are looking for a frontend engineer to work hand-in-hand with the CTO and the engineering, product and design teams to build and maintain our next-gen business banking application in alignment with the different design prototypes.
As a core member, we also expect you to have major impact on shaping our culture and brand, and help us attract top talents!
Responsibilities
- Conduct frontend developments --- from specs to tested production code --- along with the Product and Design teams
- Contribute to Multis technical thought leadership through articles on our blog
- Maintain product and handle company-wide support with the core team
- Help build a world-class engineering team
Requirements
- Based in Europe
- 3+ years of experience as frontend engineer with React
- Acquainted with ClojureScript and re-frame (or strong willingness to learn --- our coding test is in ClojureScript)
- Experience with complex single-page applications
- Ability to lead projects and execute with pragmatism and velocity
- Startup experience
- Cultivate humility and curiosity about all things programming and tech
- Know how to relax 🏝️
Nice to have
- Experience in FinTech or Blockchain
- Experience with a Design System (we use Ant.Design)
- Previous remote experience
- Hawaïan outfit and prior one-pot experience 🍲
Benefits
- Challenging work experience building next-gen financial services with a frontier tech
- Fast-learning environment, entrepreneurial and strong team spirit
- Unique access to the Y Combinator and eFounders network
- Competitive salary & equity
- Remote-friendly company with HQ in Paris downtown (75010)
- Team off-sites every 3 months (last one was in Berlin)
- Possibility to get all or part of your salary in crypto 🤑
If you are interested, you are kindly asked to reach out to us by sending your CV on join@multis.co 😁
To learn more about Multis, our company and our mission check out our vital stats here.
![]()
ASERTIVIDAD Y ESTOICISMO
Diario Estoico 16 05 2021
La web retorna a los 90
República Web 14 05 2021
Empezamos este episodio recordando la página web de la película Space Jam, que desde 1996 llevaba sin actualizarse. Un auténtica cápsula del tiempo en los inicios de la web, que muestra lo lejos que estamos de aquellos años. A pesar de todo, esos primeros años de la web, ayudaron a forjar unas herramientas de enorme utilidad, pero también una forma de producir y consumir los contenidos.
Este episodio parte de un estupendo artículo de Max Böck titulado The return of the 90s web (junio 2020) donde se cuenta cómo la actual web está volviendo a lo que vivimos en esos últimos años del pasado siglo. Como explica el autor, es un buen momento para volver a visitar aquella web para encontrar, si en efecto vuelven tendencias con un aire renovado.
Entre las tendencias que destaca Max y que se reproducen en el podcast nos encontramos:
- Renderizado en el servidor.
- Herramientas no-code.
- Sitios web personales.
- Feeds curados, RSS y descubrimiento de contenido.
- Comunidades y monetización de la web.
Hace 25 años la web era un territorio sin mapas y algo anárquico. Hoy es un lugar que sigue creando oportunidades y propiciando conexiones. Como se comenta en el episodio del podcast, en estos años hemos aprendido mucho y es bueno comprobar que las cosas con valor vuelven (si es que se han ido alguna vez).
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
660
Extra Ordinary 12 05 2021
A Look at Tailwind CSS
Ahmad Shadeed Blog 11 05 2021
Los sitios web estáticos vuelven a estar de moda y hay un generador de sitios estáticos en JavaScript que enamora a la comunidad de developers. Con una apuesta clara por la simplicidad, Eleventy es mucho más que un generador de sitios estáticos. Creado y gestionado por Zach Leatherman, Eleventy es una potente herramienta para producir sitios web optimizados y preparados para el rendimiento.
En este episodio se realiza un análisis de Eleventy explicando qué lo hace tan especial para la comunidad. En poco tiempo Eleventy ha conseguido reunir una vibrante comunidad de desarrolladores, que comparten ingeniosas soluciones basadas en apalancar la formidable librería de JavaScript. Por si fuera poco Eleventy, gracias a servicios como Netlify o Vercel, está entre las herramientas más populares para producir sitios web basados en la arquitectura Jamstack. Entre las ventajas de Eleventy:
- Soporta 11 lenguajes de plantilla.
- Cascada de datos locales, globales y externos.
- Cero configuración (no asume ninguna convención).
- Extensión a través de plugins, shortcodes y transformadores.
- Orientado al rendimiento y a la velocidad.
- Comunidad.
Aunque Eleventy pueda ser usado para crear un sitio estático convencional, la combinación de un servicio como Netlify o Vercel, te ofrece una secuencia perfecta para desarrollar sitios web modernos y orientados al rendimiento y la productividad.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
![]()
We have an update for you on the release date of Cartridges 17 & 18, Indie Heroes Collection 1 and Worms Collection 1, and sadly it is not good news. The release date of these cartridges has unfortunately had to be delayed to July 30th, 2021 due to a supply issue beyond our control. This... View Article
The post Indie Heroes and Worms Delayed to July 30 2021 appeared first on Evercade.
We are delighted to announce another brand new collection that highlights some of the best games in the history of British video game development with The Bitmap Brothers Collection 1 for Evercade devices. This new collection, in partnership with owners Rebellion, features 5 of the best games from the British development team that was dubbed... View Article
The post The Bitmap Brothers Collection 1 Announced appeared first on Evercade.
![]()
Clojure developer
Brave Clojure Jobs 05 05 2021
Clojure developer
Ardoq | flexible remote in/around Oslo. Visa sponsorship is possible
Ardoq is a fast-growing technology company in Norway with offices in London, New York, and Copenhagen. Our Graph platform enables our customers to map dependencies across strategic objectives, projects, applications, processes, and people, allowing them to assess the impact of change and make better and faster decisions.
Our company is backed by a solid commitment from investors and a majority of our employees are also shareholders. We're growing rapidly, and are looking for candidates to help scale our engineering team.
Ardoq's engineering team is a highly skilled group of people who like solving challenging problems, value feedback, continuous delivery, and automation of repetitive tasks. We maintain a high iteration speed through a focus on code quality and incremental change, not artificial deadlines. We believe working closely together and supporting each other is important if we are to achieve a common goal.
Who we're looking for
We're looking for caring, driven, and quality-focused engineers who can collaborate across the organization. You should have a learning and sharing mindset. That is, wanting to learn new things and being open and sharing your knowledge. As the company develops we implement our lessons learned and adapt to change. You should be proactive and take ownership.
We believe in finding people with the right qualities and skills rather than finding a person with the right degree. A BS/MS degree in Computer Science, Engineering, or related subject is always good but it's not a prerequisite.
You should have a good knowledge of web technologies and an interest in working with a functional language, as Clojure is our primary back-end language.
We think it's a plus if you consider yourself a full stack developer and don't mind getting your hands dirty. Since JavaScript/TypeScript and Clojure are quite different, we don't expect you to be an expert in both, but it is good to have an understanding of the other side.
Responsibilities
You'll be an integral part of the engineering team. This means both working with greenfield feature development, finding bugs, and focusing on continuous quality improvement. There's also the possibility of helping on cloud infrastructure, automation, and developer tooling depending on your personal interests.
Our best work is done in an environment of mutual trust and support. We share knowledge and value diversity. We are proactive and volunteer our best effort every day. If we see a problem, we fix a problem.
What we can offer you
Ardoq's values are Bold, Caring and Driven. Living by these values is part of what makes Ardoq a great place to work. We make bold decisions that push the product, ourselves and our customers forward. We voice our opinions, have difficult conversations, disagree, and learn. We take care of both our colleagues and our customers and empathize with the challenges they face every day.
We also offer many benefits including investment opportunities for employees and generous parental leave schemes.
Although we have offices in Oslo, London, New York, and Copenhagen, we embrace remote work and flexible schedules.
If you identify with this, we can offer you a really great place to work.
Work language
English & Clojure. Although 44% of us are based at the Oslo headquarters, we are an international team representing many countries and languages.
659
Extra Ordinary 05 05 2021
![]()
If you're a developer today, you likely take advantage of built in tools for web debugging every day. They came from the smallest places, and it took years to get them where they are today.
The post Checking “Under the Hood” of Code appeared first on The History of the Web.
![]()
LAS VIRTUDES ESTOICAS.
Diario Estoico 02 05 2021
Google anunció que a partir de mayo 2022 su navegador Chrome dejará de permitir la carga de cookies de terceros. Esto se añade a una larga lista de acciones que rematan las cookies de terceros como medio para la identificación y el seguimiento de usuarios para la industria de los anuncios publicitarios (AdTech).
En este episodio se habla sobre las implicaciones que traen el ocaso de las cookies de terceros y la tendencia hacia alternativas que sirvan para reemplazarlas. Teniendo en cuenta que las cookies de terceros han permitido la financiación de muchos servicios en internet, el hecho de que el navegador más usado en el mundo las deje de permitir, genera mucha incertidumbre entre la industria publicitaria y los creadores de contenido.
En la segunda parte del episodio ofrezco una serie de ideas para conciliar un internet abierta y que al mismo tiempo sea económicamente viable. La muerte de las cookies de terceros es la crónica de una muerte anunciada, pero que supone cambios en la forma en la que usamos gran parte de los servicios más populares en internet.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
That’s right, it’s been a few months but we’re finally ready to let you know exactly what is on the upcoming Intellivision Collection 1 Cartridge from Evercade! The Games list is: Astrosmash (Shoot ’em Up) Buzz Bombers (Shoot ’em Up) Frog Bog (Eat ’em Up) Night Stalker (Action) Pinball Princess Quest (Platformer) Shark Shark (Puzzle)... View Article
The post Intellivision Collection 1 Games Announced appeared first on Evercade.
El Desconocido CSS
En Mi Local Funciona 30 04 2021
Clojurescript Engineer (Remote)
Composer | US & Canada
remote
Build, test, and deploy automated trading strategies without any code!
$130000 - $200000
Build the platform that will disrupt the portfolio management industry!
Composer is a no-code platform for automated investment management. Composer allows you to build, test, deploy, and manage automated investing strategies - all without writing a line of code.
As an early frontend engineer at Composer you will:
- Be responsible for everything our clients interact with on our platform - empathy for user experience is a must
- Work closely with the executive team to guide our decisions regarding frontend architecture
- Work closely with our designer to bring the product to life
Projects you will work on:
- Bringing to life our simple yet powerful portfolio manager and strategy creation tool
- Unifying scattered brokerage accounts to create a holistic portfolio view
We're looking for someone who:
- Loves Clojurescript (particularly Reagent & Reframe!)
- Has experience working with designers and translating complex designs into clean, simple code
- Has experience implementing design systems, or has a systems approach to building
- Will be a technical thought leader within the company
What's it like to work at Composer?
- We believe diverse perspectives are necessary if we aim to disrupt finance. To that end, we are an equal opportunity employer and welcome a wide array of backgrounds, experiences, and abilities.
- We believe the simplest solution is most likely the best one
- We encourage self-improvement and learning new skills
- We are venture-backed by top investors
- We are 100% remote :)
- Our Values
Volvemos a la carga con el popular producto de monitoreo de infraestructuras llamado Icinga, en este caso vemos su instalación sobre un servidor con Centos 8. Ya he hablado en varias ocasiones sobre esta...
La entrada Instalación de Icinga 2 e Icinga Web 2 en Centos 8 se publicó primero en ochobitshacenunbyte.
Spotify’s Surprise
Stratechery by Ben Thompson 28 04 2021
658
Extra Ordinary 28 04 2021

Confidence
MonkeyUser 28 04 2021
Os hablo sobre las cinco mejores herramientas de backup de escritorio, para sistemas GNU/Linux. Estas herramientas las he probado en una distribución Ubuntu 20.04, pero entiendo que deben estar disponibles para la mayoría de...
La entrada Cinco herramientas de backup de escritorio en Linux se publicó primero en ochobitshacenunbyte.
![]()
When websites disappear, how do we make sure that our history is preserved?
The post April 2021 Weblog: Holding on to our History appeared first on The History of the Web.

En el anterior post (Cómo montar un SonarQube en cloud que nos sirva de Spike (Parte 1)) se quiso dar una respuesta rápida a la instalación de SonarQube.
En este post, se quiere continuar el ciclo de vida, y explicar de manera abreviada los siguientes temas:
- Cómo se lanza una
Seguramente te habrás dado cuenta, que en las últimas versiones de Ubuntu la configuración de la red ha cambiado. Vamos a ver como configurar la red en Ubuntu 20.04 con la herramienta Netplan. La...
La entrada Netplan: Configurar la red en Ubuntu 20.04 se publicó primero en ochobitshacenunbyte.
Practical SQL for Data Analysis
Haki Benita 25 04 2021
Pandas is by far the most popular tool for data analysis. It's packed with useful features, it's battle tested and widely accepted. However, pandas comes at a cost which is often overlooked. SQL databases has been around since the 1970s. They contain many features that most developers never heard of, and I want to bring some of them to light.
![]()
Tercer episodio de la serie especial sobre testing donde tratamos el testing de extremo a extremo (End-2-End). Se trata del testing que involucra toda la experiencia de uso de una aplicación. El E2E es la técnica testing de más alto nivel dentro del desarrollo web. Ya no tocamos el código sino sus resultados en el navegador, ya que se pretende emular a través de pruebas determinados comportamientos que debe cumplir nuestra aplicación. Pensemos en este testing como un robot que usa nuestra aplicación, simulando acciones y peticiones realizadas desde un «navegador descabezado».
En este episodio Javier Archeni y Andros Fenollosa hablan sobre el testing E2E, dónde encaja y en especial los frameworks que existen para realizar este tipo de tests. En el episodio:
- ¿Qué es E2E?
- ¿Por qué existe?
- ¿Cuándo debería utilizarse?
- ¿Cuáles son sus limitaciones?
- Tipo de usos en escritorio y móviles
- Frameworks de testing E2E
Un episodio de introducción general a este tipo de testing que seguro dará para profundizar más. Os animamos a probar esta metodología como una forma de mejorar vuestro trabajo y al mismo tiempo ofrecer un mejor servicio en vuestros desarrollos.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

Perfect Fit
MonkeyUser 23 04 2021
Os explico en esta entrada cómo configurar un cortafuegos con el producto pfSense, en una red interna de VirtualBox. La idea es instalar y configurar el popular producto pfSense, usando la ISO que nos...
La entrada pfSense cómo cortafuegos en red interna de VirtualBox se publicó primero en ochobitshacenunbyte.
![]()
The web's turn into commercial may have happened quickly—it was largely complete by the end of the 1990's—but that doesn't mean it didn't take a turn into the weird here and there. Case and point: Zima.
The post Trying (and Failing) to be Cool appeared first on The History of the Web.

Si quieres ser un buen desarrollador Web, o simplemente un usuario de Linux competente, defenderte con el terminal es básico. Por suerte gran parte de estos comandos pueden ser utilizados entre diversos sistemas operativos como Linux, BSD, MacOS X y Windows 10 a través de Shell. Son un estándar para profundizar en tareas, trabajar rápidamente y ir directo a una funcionalidad.
Por ello mismo dejo una lista de los comandos que creo esenciales para un Fullstack: manipular documentos, archivos, directorios, búsquedas, trabajar con logs, instalar servicios… etc. A partir de aquí ya puedes ir creciendo.
ls
Lista carpetas y archivos de un directorio.
ls
Muestra más información.
ls -l
Incluye los archivos ocultos.
ls -a
mkdir
Crea carpetas.
mkdir nueva_carpeta
Crea directorios recursivamente.
mkdir -p carpeta1/carpeta2
less
less archivo.txt
touch
Crea un archivo vacío.
touch archivo.txt
cd
Cambia de directorio.
cd carpeta
Subir un nivel
cd ..
Retroceder un directorio (subir al padre)
cd ..
Directorio del usuario
cd ~
Volver al directorio anterior
cd -
Ver información
Muestra información de un archivo o carpeta.
file paris.jpg
Buscar
Buscar archivos o carpetas.
Un fichero
find carpeta-donde-buscar -name feliz.jpg
Solo directorios
find carpeta-donde-buscar -type d -name vacaciones
pwd
Muestra la ruta absoluta del directorio donde nos encontramos.
pwd
mv
Mueve o renombra un archivo o carpeta.
mv fichero_original.txt fichero_nuevo_nombre.txt
cp
Copia un archivo o carpeta.
cp texto.txt texto_copiado.txt
Copia una carpeta
cp -r carpeta carpeta_copiada
rm
Borra un archivo
rm archivo.txt
Borrar carpeta
rm -r carpeta
Fecha
Ver la fecha
date
Convertir tiempo de formato unix a humano
date -r 1619018708
Nombre de usuario
whoami
tar
Comprime o descomprime archivos en formato Linux: tar, gzip y bz2.
grep
Imprime el contenido de un archivo filtrando por un patrón.
Filtrar el resultado de un comando
ls | grep texto
Filtrar un archivo
cat archivo.txt | grep texto
sudo/su
Ejecuta comando con otros permisos, como administrador u otro usuario.
chmod
Cambia los permisos de un archivo o carpeta.
chmod 744 script.sh
Otra forma es utilizado un trio con:
Rol
-
u → usuario
-
g → grupo
-
o → Otros
-
a → Todos
Acción
-
+ → Añadir
-
- → Quitar
Permiso
-
r → Lectura
-
w → Escritura
-
x → Ejecución
Por ejemplo, se le quita el permiso de escritura a todos
chmod a-w first.txt
Al usuario se le da permisos de ejecución
chmod u+x script.sh
chown
Cambia propiedad de un archivo o carpeta.
chmod debian:debian archivo.txt
cat
Concadena archivos.
cat archivo1.txt archivo2.txt
echo
Imprime el contenido de un archivo.
echo archivo.txt
man
Muestra el manual de un comando.
man ls
history
Muestra el historial de comandos.
history
clear
Limpia el terminal.
clear
reboot
Reinicia.
sudo reboot
shutdown
Apaga.
sudo shutdown now
top/htop
Monitor de procesos.
htop
nano
Editor de archivos simple.
nano archivo.txt
vim/nvim/emacs
Editor de archivos avanzado.
emacs -nw archivo.txt
curl
Realiza peticiones HTTP.
curl programadorwebvalencia.com
tail
Muestra el final de un archivo.
tail archivo.txt
ip
Muestra información de tu red.
ip address show eth0
lsof
Muestra que servicio esta utilizando cierto puerto.
lsof -i tcp:80
df
Muestra la información de espacio ocupado en el disco.
df -h
du
Muestra el espacio que ocupa los diferentes elementos de una carpeta.
Solo un nivel y en formato humano
du -d 1 -h
journalctl
Muestra los logs en tiempo real.
journalctl -f
Muestra los logs en tiempo real de un servicio.
journalctl -f -u ssh
Muestra los logs de un servicio.
journalctl -u ssh
Muestra las últimoas 20 líneas de un log.
journalctl -n 20
Limpia los logs hasta alcanzar el peso que indiques.
journalctl --vacuum-size=1G
Borra los logs con más de cierto tiempo.
journalctl --vacuum-time=1years
Ejecutar último comando
!!
Ejecuta último comando con sudo.
sudo !!
![]()
Segundo episodio de esta serie especial sobre testing. En esta ocasión Andros Fenollosa conversa con Antony Goetzschel sobre el testing en el lado de servidor. Entre las cuestiones que discuten en el episodio:
- ¿Qué es un pipeline?
- ¿Dónde se ensambla el código?
- ¿Tienes sentido hacerlo en el CI/CD?
- ¿Cómo se puede empezar con un CI/CD?
- ¿Cuál es la utilidad de hacer testing en el despliegue?
- ¿Qué son las pruebas de estrés?
- ¿Cómo se hacen?
- El monitoreo que se realiza a un servicio… ¿dónde podríamos caracterizarlo?
- ¿Qué técnicas utilizas en tu día a día? ¿Por qué?
Este episodio ofrece una perspectiva muy amplia sobre lo que implica probar nuestro código en la parte del servidor, con recomendaciones de Andros y Antony.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Existen diferentes tipos de programas en GNU/Linux encargados de enviar correo. En el caso de hoy os hablaré de SSMTP, un programa que conozco desde hace no mucho, pero que me consta que en...
La entrada SSMTP: Envío fácil de correo desde la consola de comandos en Linux se publicó primero en ochobitshacenunbyte.
We’re delighted to announce the Mega Cat Studios Collection 2 cartridge which will feature 8 more classic Mega Cat Studios games to the Evercade! The new 8 game collection, due for release on September 29th 2021, will bring more games from the independent publisher. following the great reception of Mega Cat Studios Collection 1 which... View Article
The post Mega Cat Studios Collection 2 is coming to Evercade appeared first on Evercade.
![]()
Meeting
MonkeyUser 15 04 2021
![]()
![]()
![]()
Why My Blog is Closed-Source
Josh Comeau's blog 14 04 2021

Ya sabéis que utilizo la web para mis apuntes personales, así que otra va, en este caso para solventar un problema con YUM, que como sabéis se encarga, en versiones antiguas de RHEL o...
La entrada YUM, solventar fatal error, run database recovery se publicó primero en ochobitshacenunbyte.
Introducción
¿Qué programador no ha soñado con participar en la creación de un videojuego? No sé vosotros, pero a mí siempre me ha gustado la idea de desarrollar un pequeño juego, ya desde los tiempos del Commodore 64 o del Sinclair Spectrum, que me ponía a copiar el código "Basic"

Introduction
MonkeyUser 13 04 2021
![]()
![]()
Estos son todos los pasos que realizo cuando creo un VPS o servidor en Debian. A lo largo del tiempo he ido añadiendo puntos, modificando y quitando elementos innecesarios; por lo que no lo percibáis como “La guía definitiva”. Sino más bien como unos “apuntes de apoyo”. Personalmente ejecuto todo, aunque cada proyecto es un desafío diferente.
1. Actualizar a la última versión y estable
apt update && \
apt upgrade -y && \
apt dist-upgrade
2. Instalar software mínimo
apt install -y build-essential fail2ban iptables-persistent msmtp-mta python3-dev python3-pip libcurl4-openssl-dev libssl-dev htop git neovim wget curl zsh tmux && \
sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)" && \
apt autoremove -y
3. Configurar el cortafuegos
Dejamos pasar 80 y 443 para permitir los protocolos http y https.
iptables -A INPUT -p tcp --dport 80 -j ACCEPT &&
iptables -A INPUT -p tcp --dport 443 -j ACCEPT
4. Cambiar editor por defecto
update-alternatives --config editor
5. Ajustar la hora
En este ejemplo configura la hora a Madrid (España).
ln -fs /usr/share/zoneinfo/Europe/Madrid /etc/localtime && \
dpkg-reconfigure -f noninteractive tzdata
6. Activa las actualizaciones automáticas de seguridad no atendidas
apt install -y unattended-upgrades apt-listchanges && \
echo unattended-upgrades unattended-upgrades/enable_auto_updates boolean true | debconf-set-selections && \
dpkg-reconfigure -f noninteractive unattended-upgrades
7. Crea un usuario
Se llamará debian, aunque puedes llamarlo como desees.
useradd --shell /bin/zsh -m debian
Ahora nos metemos en el usuario.
su debian
Configurarmos las claves ssh y oh-my-zsh.
ssh-keygen -t rsa
exit
Lo añadimos al grupo de sudo.
usermod -a -G sudo debian
Entramos en visudo para permitirle ejecutar sudo.
visudo
Editando la siguente línea.
%sudo ALL=(ALL:ALL) NOPASSWD:ALL
Generamos la keygen de ssh para entrar en un futuro.
Copiamos las autorizaciones actuales asociadas con root.
cp /root/.ssh/authorized_keys /home/debian/.ssh/ && \
chown debian:debian /home/debian/.ssh/authorized_keys
8. Medida de seguridad ante disco lleno
Añadimos una archivo con contenido aleatorio de, por ejemplo, 1Gb. En caso que se llene el disco, podremos borrarlo para tener un margen de acción.
dd if=/dev/urandom of=balloon.txt bs=1MB count=1000
9. Limita el espacio de los logs
Editas
nano /etc/systemd/journald.conf
Descomentas (quitas la #) a la vez que modificas la siguiente línea.
SystemMaxUse=1Gb
Para terminar reinicia el servicio.
systemctl restart systemd-journald
Extras
Instalar docker
apt update && \
apt install -y \
apt-transport-https \
ca-certificates \
curl \
gnupg \
lsb-release && \
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg && \
echo \
"deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/debian \
$(lsb_release -cs) stable" | tee /etc/apt/sources.list.d/docker.list > /dev/null && \
apt update && \
apt -y install docker-ce docker-ce-cli containerd.io docker-compose
Activar Swap
Habilitamos un espacio reservado en el disco en caso de que la RAM se llene.
Instalamos zram.
sudo apt install zram-tools
Editamos su configuración.
sudo nano /etc/default/zramswap
Le marcamos que su capacidad sea la mitad de la RAM.
PERCENTAGE=50
ALLOCATION=4096 #4Mb
ALLOCATION=8192 #8Mb
Instalar snap
sudo apt install snapd
Would Alfred Hitchcock use Emacs?
Manuel Uberti 12 04 2021
First you have to excuse the awful title, but a cinephile cannot resist the temptation of an easy reference when the Emacs package he is going to write about is called Vertico.
Daniel Mendler has become such a prolific contributor to our Emacs world. His
work with Omar Antolín Camarena and Clemens Radermacher (to name a few!) has
been showing me how much can be done with little improvements on Emacs default
completion system. Actually, “little” is a bit unfair to them because they have
been putting a lot of effort in their packages and contributions. What “little”
stands for instead is the amount of code I had to add to my init.el to get a
superb completion UI. I combine Vertico with Orderless and I didn’t have to do
much beside this after the installation via package.el:
(require 'orderless)
(setq completion-styles '(orderless))
(require 'vertico)
(vertico-mode +1)
Well, to be fair I did something more, like binding vertico-exit-input to C-j
and setting orderless-matching-styles to orderless-regexp, plus I am using
Daniel’s consult to extend Vertico capabilities, but I guess you see where I am
going by now. The combination of small packages makes for a modular system that
I can interact with more easily. For instance, Daniel can go berserk and forget
about the lovely 500 lines of code limit he set himself to with Vertico. Why
should I trust this criminal mind, then? I can switch to Selectrum and keep
using Consult and Orderless with it1.
The beauty of Vertico is that it is not about reinventing Emacs completion once again. By sticking to Emacs built-in commands and completion facilities, Vertico succeeds in staying close to the source without losing the chance to improve on it. On the one hand, moving to Vertico means it is up to the user to configure extra niceties. That is what packages like Consult, Orderless, Embark, and Marginalia aim for, but again, the user is in charge of the right setup for their needs, while a solution such as Helm offers a lot of functionalities out of the box. On the other hand, tools such as Helm, Ivy, and Selectrum are more complex than Vertico and may bring in code you do not necessarily need, which is something even Emacs itself doesn’t shy away from2.
I find it amazing that a seemingly simple and yet so central feature in my everyday Emacs such as the completion system has pushed people to create all these amazing packages. It seems to me that Helm has helped pave the way for a more powerful experience when it comes to completion and that by studying Emacs internals carefully one can achieve similar benefits with a different approach. As humble end-users of all this we really are a lucky bunch.
Notes
Would Alfred Hitchcock use Emacs?
Manuel Uberti 12 04 2021
First you have to excuse the awful title, but a cinephile cannot resist the temptation of an easy reference when the Emacs package he is going to write about is called Vertico.
Daniel Mendler has become such a prolific contributor to our Emacs world. His
work with Omar Antolín Camarena and Clemens Radermacher (to name a few!) has
been showing me how much can be done with little improvements on Emacs default
completion system. Actually, “little” is a bit unfair to them because they have
been putting a lot of effort in their packages and contributions. What “little”
stands for instead is the amount of code I had to add to my init.el to get a
superb completion UI. I combine Vertico with Orderless and I didn’t have to do
much beside this after the installation via package.el:
(require 'orderless)
(setq completion-styles '(orderless))
(require 'vertico)
(vertico-mode +1)
Well, to be fair I did something more, like binding vertico-exit-input to C-j
and setting orderless-matching-styles to orderless-regexp, plus I am using
Daniel’s consult to extend Vertico capabilities, but I guess you see where I am
going by now. The combination of small packages makes for a modular system that
I can interact with more easily. For instance, Daniel can go berserk and forget
about the lovely 500 lines of code limit he set himself to with Vertico. Why
should I trust this criminal mind, then? I can switch to Selectrum and keep
using Consult and Orderless with it1.
The beauty of Vertico is that it is not about reinventing Emacs completion once again. By sticking to Emacs built-in commands and completion facilities, Vertico succeeds in staying close to the source without losing the chance to improve on it. On the one hand, moving to Vertico means it is up to the user to configure extra niceties. That is what packages like Consult, Orderless, Embark, and Marginalia aim for, but again, the user is in charge of the right setup for their needs, while a solution such as Helm offers a lot of functionalities out of the box. On the other hand, tools such as Helm, Ivy, and Selectrum are more complex than Vertico and may bring in code you do not necessarily need, which is something even Emacs itself doesn’t shy away from2.
I find it amazing that a seemingly simple and yet so central feature in my everyday Emacs such as the completion system has pushed people to create all these amazing packages. It seems to me that Helm has helped pave the way for a more powerful experience when it comes to completion and that by studying Emacs internals carefully one can achieve similar benefits with a different approach. As humble end-users of all this we really are a lucky bunch.
Notes

Dentro de Linux y MacOS disponemos de una herramientas preinstalada que es fantásticas para comprimir y descomprimir cualquier tipo de archivo: fotos, vídeos, texto, carpetas… Con solo tar ya podremos realizar las tareas básicas.
Conceptos importantes.
tar: Tarro o contenedor. Sirve para agrupar un conjuntos de archivos, no comprime.gzip: Algoritmo de compresión malo pero rápido. Equivalente a unzip.bz2: Algoritmo de compresión bueno pero lento. Equivalente a unrar.
Comprimir
tar
Ejemplo de como crear un grupo o archivador usando tar.
tar -cvf nombre.tar carpetas-o-archivos
c —> Crea un archivador (tar).
v —> Muestra el progreso.
f —> Indicamos que vamos a especificar el nombre final.
gzip
Ejemplo de como comprimir creado un zip equivalente en Linux.
tar -czvf futuro-comprimido.tar.gz carpetas-o-archivos-a-comprimir
c —> Crea un archivador (tar).
z —> Comprime usando gzip (zip)
v —> Muestra el progreso.
f —> Indicamos que vamos a especificar el nombre final.
bz2
Ejemplo de como comprimir creado un rar equivalente en Linux. (sustituye z por j)
tar -cjvf futuro-comprimido.tar.bz2 carpetas-o-archivos-a-comprimir
c —> Crea un archivador (tar).
j —> Comprime usando bzip2 (equivalente a rar)
v —> Muestra el progreso.
f —> Indicamos que usaremos un archivo.
Descomprimir
Ejemplo de como descomprimir cualquier formato: tar, tar.gz o tar.bz2. (sustituye c por x)
tar -xvf comprimido.tar.gz
x —> Extrae.
v —> Muestra el progreso.
f —> Indicamos que usaremos un archivo.
Подкаст DevZen, эпизод 331
tonsky.me 10 04 2021
Back to the roots
Manuel Uberti 08 04 2021
Last time I left straight for the built-in package.el, a choice I have not had
the pleasure to regret so far. Now I am going to reason about a more ambitious
change in my Emacs configuration: I am not using use-package any more.
Before answering your concerned why!? let me just say that if you are happy with
use-package you should stay with it. By wrapping all the settings to a built-in
feature or an external package with use-package you can easily notice what you
are doing wrong when tweaking something, while having control over the
installation and the loading of your favourite library as well. Despite some
unhappiness around the web1, use-package is just a great tool that any serious
Emacs hacker should consider when digging deep into their .emacs.d.
As for my choice to move away from it, it all started as an experiment. I wanted
to see if I could have the same amount of control and readability over my
init.el without an extra package. You see, most of the recent changes to my
setup involved trying to rely on Emacs own facilities to answer my needs, and
I am glad to say vanilla Emacs has been really a surprise in this regard. My
liaisons with project.el and Flymake are nice examples of this.
Removing use-package has meant rethinking the way I install packages, especially
if I want my setup to be ready to go any time I upgrade to a newer version of
Ubuntu. My solution was adding the packages I use to package-selected-packages
and have a check on startup to make sure they are installed. This works very
well combined with package-autoremove: if a package is not listed under
package-selected-packages, Emacs takes care of the mess.
All the use-package blocks have been replaced with a combination of
with-eval-after-load, define-key, and add-hook, which was not as complicated as
it might sound, and more often than not was similar to what I had in my days
before the use-package takeover. True, I lost the nice readability of
use-package with this massive edit. For example, its keywords have the benefit
of grouping settings together and clearly indicate when a new group starts, but
on the other hand now there is less macro-magic masking package-related
operations involved. As a result I have a more detailed insight of what is
really going on with my Emacs Lisp. For instance, I have gained a better
knowledge of what run-with-idle-timer actually does.
Again, it is a matter of personal preferences. By now the beauty of use-package
is well-known in the Emacs world and all the praises are well-deserved. Let me
stress it again: use-package makes your configuration simpler to manage and
easier to read. Those were the main reasons I switched to it years ago, anyway.
However, if you know what you are doing you can achieve a clean and pleasant
init.el with what Emacs already offers. Does it take more effort? Yes, it
probably does. Is it really worth it? It’s up to you, mate. Am I just showing
off? No, come on, don’t be rude.
Notes
Back to the roots
Manuel Uberti 08 04 2021
Last time I left straight for the built-in package.el, a choice I have not had
the pleasure to regret so far. Now I am going to reason about a more ambitious
change in my Emacs configuration: I am not using use-package any more.
Before answering your concerned why!? let me just say that if you are happy with
use-package you should stay with it. By wrapping all the settings to a built-in
feature or an external package with use-package you can easily notice what you
are doing wrong when tweaking something, while having control over the
installation and the loading of your favourite library as well. Despite some
unhappiness around the web1, use-package is just a great tool that any serious
Emacs hacker should consider when digging deep into their .emacs.d.
As for my choice to move away from it, it all started as an experiment. I wanted
to see if I could have the same amount of control and readability over my
init.el without an extra package. You see, most of the recent changes to my
setup involved trying to rely on Emacs own facilities to answer my needs, and
I am glad to say vanilla Emacs has been really a surprise in this regard. My
liaisons with project.el and Flymake are nice examples of this.
Removing use-package has meant rethinking the way I install packages, especially
if I want my setup to be ready to go any time I upgrade to a newer version of
Ubuntu. My solution was adding the packages I use to package-selected-packages
and have a check on startup to make sure they are installed. This works very
well combined with package-autoremove: if a package is not listed under
package-selected-packages, Emacs takes care of the mess.
All the use-package blocks have been replaced with a combination of
with-eval-after-load, define-key, and add-hook, which was not as complicated as
it might sound, and more often than not was similar to what I had in my days
before the use-package takeover. True, I lost the nice readability of
use-package with this massive edit. For example, its keywords have the benefit
of grouping settings together and clearly indicate when a new group starts, but
on the other hand now there is less macro-magic masking package-related
operations involved. As a result I have a more detailed insight of what is
really going on with my Emacs Lisp. For instance, I have gained a better
knowledge of what run-with-idle-timer actually does.
Again, it is a matter of personal preferences. By now the beauty of use-package
is well-known in the Emacs world and all the praises are well-deserved. Let me
stress it again: use-package makes your configuration simpler to manage and
easier to read. Those were the main reasons I switched to it years ago, anyway.
However, if you know what you are doing you can achieve a clean and pleasant
init.el with what Emacs already offers. Does it take more effort? Yes, it
probably does. Is it really worth it? It’s up to you, mate. Am I just showing
off? No, come on, don’t be rude.
Notes
Shy Coder
MonkeyUser 08 04 2021
Мы обречены — Open Source
tonsky.me 07 04 2021
Primer episodio de una serie especial que vamos a dedicar al mundo del testing. Para esta primera parte Andros Fenollosa repasa con David las metodologías de testing, discutiendo además las ventajas y las desventajas de seguir realizar pruebas en nuestro código. Entre las cuestiones habladas:
- Filosofías
- Desarrollo guiado por pruebas (TDD).
- Desarrollo guiado por el comportamiento (BDD).
- Desarrollo guidado a datos (DDD).
- Frameworks de testing
- Pruebas dependiendo de la visibilidad
- Pruebas de caja blanca.
- Pruebas de caja gris.
- Pruebas de caja negra
- Pruebas dependiendo de la ejecución de las aplicaciones
- Pruebas estáticas
- Pruebas dinámicas
- Pruebas Funcionales
- Pruebas de unidad
- Pruebas de integración
- Pruebas de aceptación
- Pruebas de extremo a extremo (E2E)
- Pruebas no Funcionales
- Pruebas de rendimiento
- Pruebas de seguridad
- Pruebas aleatorias (Fuzzing).
- Pruebas según el número de pruebas a realizar
- Pruebas de humo
- Pruebas de sanidad
- Pruebas de regresión/sistema
Se trata de un episodio de introducción al testing, hablando también sobre las consideraciones habituales al tratar esta metodología en los equipos y empresas. También hablan de algunas experiencias relacionadas con el testing.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
La entrada de hoy va dedicada a mosh, que significa Mobile Shell Es una aplicación de línea de comandos, que se utiliza para conectarse al servidor desde una computadora cliente, a través de Internet....
La entrada Mosh, un ssh más eficiente en Linux se publicó primero en ochobitshacenunbyte.
![]()
The Internet Book Baron
The History of the Web 06 04 2021
This week I have something a bit different, written by longtime newsletter author Ernie Smith, best known for his history […]
The post The Internet Book Baron appeared first on The History of the Web.
State of Clojure 2021 Results
Clojure News 06 04 2021
While a challenging year overall, 2020 was another good year for Clojure and its ecosystem. One big newsworthy item was that Cognitect joined Nubank, the world’s largest independent digital bank, to reinvent financial services across Latin America. The news was well received, and the general sentiment is summarized by a comment left by one of the survey respondents:
Great to see the Nubank acquisition of Cognitect. I think this has done wonders to bolster confidence in Clojure and Datomic for the long term. Also the subsequent support of open source developers sends a very positive message, and directly supports a healthy and robust ecosystem.
— anonymous survey respondent
Indeed Ed Wible, the co-founder of Nubank talked about Nubank’s commitment to supporting and growing Clojure (and Datomic) into the future.
In this post I’ll outline a few of the more salient points shown in the 2021 survey. Specifically, I’ll touch on the use of Clojure in production, the use of Clojure for start-ups, and how Clojure helps programmers and organizations to move quickly and confidently. As an added bonus I’ll highlight some of the amazing projects and people making the Clojure community strong.
Clojure in Production
Continuing the trend from last year, Clojure has seen growth in large companies (i.e. those having 100-1000 employees).
Nubank currently employs approximately 700 (at the time of writing) Clojure programmers, and Nubank is just one prominent example of the many banks, mortgage companies, and financial services companies using Clojure today, accounting for 22% (and growing) of the Clojure job market as reported by survey respondents. The survey shows healthy gains in the healthcare and retail markets as well.

Having said all of that, just where are Clojure projects deployed in production systems? Interestingly, the survey shows some nice growth in the way of public cloud and serverless deployments. The trends for AWS indicate that the cloud market is booming and so it’s natural that the general increase for that segment would show specifically for Clojure deployments as well.
Clojure (still) for Start-ups
While more large companies are adopting Clojure than ever, the sweet spot is still the smaller companies of less than 100 employees.

The reasons that start-ups choose Clojure are many and variegated:
-
Leverage - small effort, big result
-
Ready access to large existing ecosystems - Java, JavaScript, .NET
-
Scalable base - grow from PoC, to MVP, to production systems at scale
-
Moving fast - discussed in the next section
One exciting start-up of note in the Clojure ecosystem is Roam Research. Roam’s flagship product is an online note-taking tool that is designed to augment the human mind in building a set of notes that allow deep connectivity and discoverability. The enthusiasm for Roam is palpable and it’ll be fun to watch them grow.
Clojure for Moving Fast
Most survey respondents reported that they came to Clojure from the Java programming language. The fact that both languages run on the same virtual machine certainly helps smooth the path from Java to Clojure. However, many other advantages allow Clojure programmers a greater flexibility and agility in their day to day work lives using Clojure.

First, Clojure programmers value a functional style of programming facilitating a separation of data and process. Coupled with its suite of immutable data structures, Clojure applications are often built as pipelines of data transformation functions that can be composed to implement higher-level business concepts in software. As a dialect of Lisp, Clojure provides an interactive programming environment called the REPL (Read, Eval, Print, Loop). The REPL fosters exploratory programming, allowing Clojure programmers to interactively develop solutions to sticky programming problems using a tight feedback loop. Indeed, the confluence of the REPL, immutable data structures, and functional programming allows for a development process light on ceremony, allowing programmers to focus on the problem at hand rather than the complexities foisted on them by their programming language.
The Clojure Ecosystem
Finally, Clojure would have never grown to its current size without the help of countless developers, technical writers, and big thinkers along the way. The appreciation for the amazing Clojure community is palpable within Nubank and this appreciation is increasingly being expressed as open source project funding. I’d like to close this year’s post by highlighting a number of the community leaders mentioned in the survey responses.
-
Bozhidar Batsov for continuing to improve Clojure tooling ecosystem.
-
Arne Brasseur - Kaocha is superb and his educational skills fantastic.
-
Everything Michiel Borkent aka borkdude touches is awesome!
-
Sean Corfield because he is always helpful and polite, and writes excellent documentation for important libraries.
-
Michael Fikes for being enthusiastic, engaging, and inspirational, and approachable.
-
Thomas Heller has made an amazing tool in shadow-cljs.
-
(Daniel) Higginbotham, because he made me laugh hundreds of times while introducing me to Clojure.
-
Tony Kay and contributors of Fulcro for providing a comprehensive solution to client-server state management.
-
Gene Kim for … unabashed love of the language, and for helping spread the good word.
-
London Clojurians - the online talks in the past year have been amazing.
-
Tiago Luchini, Hodur creator.
-
Carin Meier for her progressiveness: for advancing the state of the art in machine learning, and her contributions to visibility and representation in the community.
-
David Nolen is generous with explanations, direct, genuine, and never condescending or judgmental.
-
Eric Normand, as he provides great content for beginners.
-
Michael Nygard for architecture insights.
-
Dmitri Sotnikov for making web dev in Clojure accessible to the masses.
-
Peter Taoussanis - Nice, simple and complete libraries.
There are so many more who deserve praise and recognition so in the words of one of the survey respondents:
Clojure literally changed my life for the better. I am eternally grateful for the humans behind it.
— anonymous respondent
We too are grateful for everyone involved in the Clojure community and we hope to see a continuance and growth in support for those members of the community who work so hard and devote their valuable time to help Clojure and its ecosystem thrive.

Days
MonkeyUser 06 04 2021
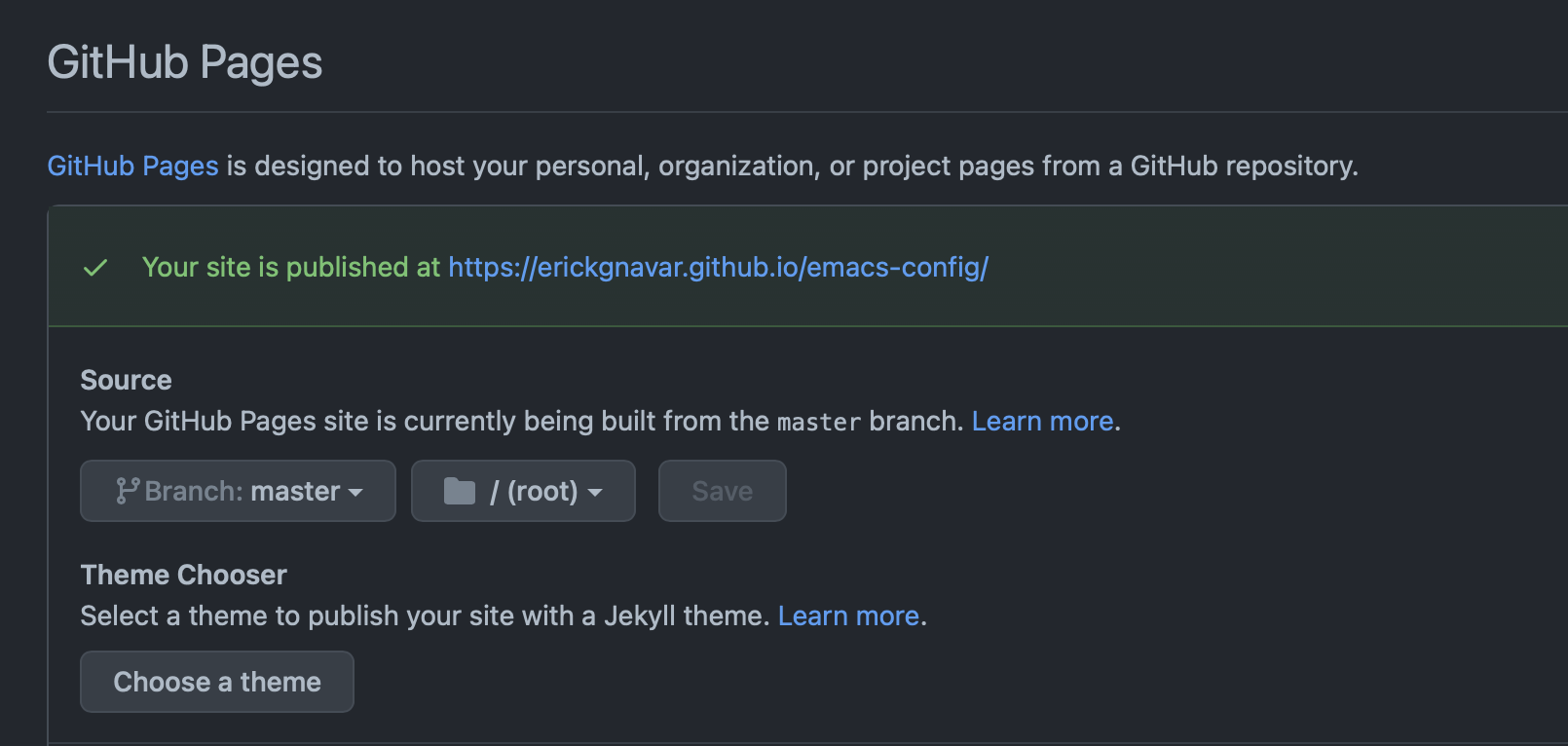
Having our emacs configuration in an org file is great, it allow us to have it more organized and easy to read, but org files have more features and one of them is the ability to be exported to different formats like HTML, PDF, markdown and so on. So what if we export our emacs configuration to HTML and then publish it in a website? 🤯
It probably doesn't have any real utility but it would be nice to have a exclusive web page to show our emacs config to our friends :)
We can do this in two ways:
-
Manually, we can export the org file using the regular exportation feature of
org-modeand then upload the resulting HTML somewhere -
Automatically, our configuration will be rendered and published into a website every time we push some changes to our
dotfilesrepository
Let's define what we need to do to have the automatic way:
-
Have a script that render our org config file
-
Run this script in a CI so it can be run every time we push some changes
-
Push the rendered HTML to an extra repository
-
Activate Github Pages in the extra repository, so we can have an url where we can see the resulting website
Let's assume we have this structure in our dotfiles repository:
├── emacs
│ ├── config.org
│ └── init.el
└── scripts
This is a "regular" structure for a dotfiles repository, the extra scripts folder will be used later. Now let's deep into how it will work.
Automate the org file rendering
We need to create to files and put them inside scripts folder:
-
render-emacs-config-to-html.sh, this will render our config file and place the resulting HTML file insidescripts/output/index.html -
org-render-html-minimal.el, this is a minimal config file to be able to render org into html, it load the required packages and make some basic configuration
Let's explore first scripts/org-render-html-minimal.el
(require 'package)
(setq package-archives '(("gnu" . "https://elpa.gnu.org/packages/")
("melpa" . "https://melpa.org/packages/")))
(package-initialize)
(package-refresh-contents)
;; this is required to highlight code blocks properly
(package-install 'htmlize)
(require 'org)
(require 'htmlize)
;; For some reason the default value `inline-css' doesn't apply syntax highlighting correctly
;; in the resulting html file so we need to change the value to `css'
(setq org-html-htmlize-output-type 'css)
To export code blocks correctly we need the package htmlize, this package is available in MELPA so we need to configure MELPA and then install it from there.
Now let's check scripts/render-emacs-config-to-html.sh
#!/bin/sh
# read the docs based theme
echo "#+SETUPFILE: https://raw.githubusercontent.com/fniessen/org-html-themes/master/org/theme-readtheorg.setup" > index.org
cat ../emacs/config.org >> index.org
emacs index.org --batch -Q --load org-render-html-minimal.el -f org-html-export-to-html --kill
# output will be the directory uploaded to the render repository so we have to put all the resulting files inside that folder
mkdir output
mv index.html output/What are we doing here?
We basically create a new org file called index.org and put a setup configuration file in it. You can avoid this step if you put this line directly in your config file, in this case we're using one of the themes available in this repository, there is more themes available in this other repository so you can choose the one you like the most.
Now we need to run emacs with our previously defined configuration org-render-html-minimal.el and tell it to render our index.org.
And finally we put the resulting index.html inside output folder. This folder will be used later.
Using Github actions to build and publish the rendered config
We're going to use a Github action called push-directory-to-another-repository, this action allow us to commit and push changes in another repository. Some configuration is required to use this action:
Create a extra repository
This extra repository will be used to host our rendered config file, in my case this repository is erickgnavar/emacs-config, we also need to activate Github Pages in this repository and set it up to use master branch
The url generated, erickgnavar.github.io/emacs-config in my case, is where our rendered config file will be published.
Create a personal token
To be able to push changes into the new repository we have to create a personal access token, this can be made in account settings, this token should have the repo scoped activated.

Configure a secret variable in our dotfiles repository
The Github action needs a secret variable called API_TOKEN_GITHUB, this variable allow the action to push changes into the new repository, we can create it by going to repository/settings/secrets/New repository secret

Configure Github action config file
Finally we have to create a file .github/workflows/ci.yml with the following content:
name: CI
on:
push:
branches: [ master ]
jobs:
build-emacs-config-page:
runs-on: ubuntu-latest
container: alpine:3.13.4
steps:
- uses: actions/checkout@v2
- name: Install emacs
run: apk --update add emacs
- name: Render config into html
run: cd scripts && sh render-emacs-config-to-html.sh
- name: Pushes to destination repository
uses: cpina/github-action-push-to-another-repository@cp_instead_of_deleting
env:
API_TOKEN_GITHUB: ${{ secrets.API_TOKEN_GITHUB }}
with:
source-directory: 'scripts/output'
destination-github-username: 'YOUR_GITHUB_USERNAME'
destination-repository-name: 'YOUR_NEW_REPOSITORY_NAME'
user-email: bot@emacs.botThis action config file make some things:
-
Install emacs so we can run it to render our config file
-
Render our config file using the script
render-emacs-config-to-html.shwe previously defined -
Take the content of
scripts/output, commit and push it into our destination repository, this is why we need to move the resulting HTML file intooutputfolder -
And finally it calls
github-action-push-to-another-repositoryaction which will do all thegitstuff required to push the changes
Now every time we push changes to our dotfiles repository this action will push the rendered config file to our destination repository, the commits will look like this:

And when we enter to the url generated from Github pages, erickgnavar.github.io/emacs-config in my case, we can see our configuration rendered:

Enjoy 🎉
Easy deploy of docker based projects
(ノ°Д°)ノ︵ ┻━┻ 03 04 2021
Easy deploy of docker based projects
(ノ°Д°)ノ︵ ┻━┻ 03 04 2021
I have a personal server where I run some projects, some of them written in python, elixir and other technologies so having to deal with specific installation of any of these technologies is not an ideal workflow, to fix this I use docker and all of them are deployed using docker-compose, they're connected to a single PostgreSQL server and they're behind the same web server.
Running all of these projects in this way it's easier to maintain and in case something happens with the server I can re deploy everything in a easy way. Let's take a look to these tools and how they work together.
Let's assume we have the following requirements:
-
Deploy a django application
-
Deploy a phoenix application
-
Each application needs a PostgreSQL database
-
Both applications should be behind a web server and being accessed over HTTPS
-
All of these should run in the same server
To solve this we're going to:
-
Set up a linux server
-
Install PostgreSQL
-
Configure a web server which will handle incoming traffic and SSL termination
-
Run our applications inside Docker containers
Setting up a server
If you already have a server you can skip this section.
We first need a server which can run docker, most linux distros can be used for this but in this case we'll be using Ubuntu Server, if you don't have a server yet you can use any of these referral links to get some credit when you create your account:
-
Digital Ocean this will get you $100 on credits to be used in 2 months
-
Hetzner this will get you 20€ on credits, this provider has cheaper prices than Digital Ocean but it only have data centers in Europe
-
Linode this will get you $100 on credits to be used in 2 months
Once you get a server it's recommended to make some basic configurations like updating packages, setup a firewall, etc. You can follow this Linode guide to secure your server.
After that you need to install docker, to do that you can follow the official documentation, this have specific instructions for you linux distribution.
Once we have docker and docker-compose installed we can follow this guide.
Installing PostgreSQL in our host machine
We're going to use a unique instance of PostgreSQL installed in the host machine, this way we can share the resources used by PostgreSQL with all the applications that we're going to deploy, we just need to create new users and databases for each one of the applications.
First let's install PostgreSQL with:
sudo apt install postgresql-server
We need to login with postgres user so we can be able to enter to a psql session. We can do it with:
sudo su - postgres
Now we can open a psql session and create the databases and users for our applications:
postgres=# CREATE USER django WITH ENCRYPTED PASSWORD 'secret';
postgres=# CREATE DATABASE django WITH OWNER django;And we do the same for our phoenix application:
postgres=# CREATE USER phoenix WITH ENCRYPTED PASSWORD 'secret';
postgres=# CREATE DATABASE phoenix WITH OWNER phoenix;Configuring Caddy as a reverse proxy
Caddy is a "new" web server written in Go that have 2 main features that make it a good option for simpler deployments:
-
Simpler configuration file
-
Free auto configured SSL certificates, using Let's Encrypt service, and automatic renewals
If we were using for example Nginx we have to deal with HTTPS certificates by ourselves, installing certbot, and also have to configure some way to renew the certificates, Let's Encrypt issues certificates that expire after 3 months.
Let's define our domains django.domain.com and phoenix.domain.com which will send traffic to their specific applications.
Our django application needs that Caddy serves the static files so we define file_server option and tell caddy where are our static files, we also tell Caddy to send the traffic to port 8000 where our application is listening.
django.domain.com {
root * /opt/django
@notStatic {
not path /static/*
}
reverse_proxy @notStatic localhost:8000
file_server
}
Our phoenix application will serve static files by itself so we just need to define the reverse_proxy directive to be able to send the traffic to port 4000
phoenix.domain.com {
reverse_proxy localhost:4000
}
Now when we reload our caddy server with sudo systemctl reload caddy it will get the SSL certificates and internally will check if they still valid, otherwise it will renew them.
Running our projects with docker-compose
Docker compose is a tool that allow us to define different docker services in a easier way using a yaml file.
We're going to configure our two projects using docker-compose but we first need their docker images so let's build them.
Let's clone our projects(both are in the same repository, just in different folders), build the images and then publish them on a registry.
This can be made in a separate machine because once the images are pushed to a remote registry they can be downloaded in our server.
cd simple-django-project-with-docker
docker build -t registry.mycompany.com/django:v1 .
docker push registry.mycompany.com/django:v1cd simple-phoenix-project-with-docker
docker build -t registry.mycompany.com/phoenix:v1 .
docker push registry.mycompany.com/phoenix:v1You can use docker hub to push your images or use Gitlab registry in case you want free private images.
Django application
Let's create a folder in /opt/django and put the following code into a docker-compose.yml file.
version: "2"
services:
web:
image: registry.mycompany.com/django:v1
restart: always
network_mode: host
environment:
ALLOWED_HOSTS: "django.domain.com"
DEBUG: "0"
DATABASE_URL: "postgres://django:secret@localhost:5432/django"
DJANGO_SETTINGS_MODULE: "config.settings"
SECRET_KEY: "a 32 long secret key"
volumes:
- ./static:/app/static
ports:
- "127.0.0.1:8000:8000"
The static folder will be used by Caddy to server static files.
Phoenix application
Now for our phoenix application let's create a folder /opt/phoenix and put the following code into a docker-compose.yml file.
version: "2"
services:
web:
image: registry.mycompany.com/phoenix:v1
restart: always
network_mode: host
environment:
DATABASE_URL: "postgres://phoenix:secret@localhost:5432/phoenix"
MIX_ENV: prod
HOST: "phoenix.domain.com"
SECRET_KEY_BASE: "a 32 long secret key"
ports:
- "127.0.0.1:4000:4000"
Because we're running PostgreSQL in our host machine instead of a docker container we have to use network_mode: host, this allow us to access postgres just pointing to localhost.
Deploying our projects
Once we have the docker-compose.yml files configured we can go inside each project folder and run:
docker-compose up -dFor the django application we also have to run these commands, these are specific of django deployment process.
# Run database migrations
docker-compose exec -T web python manage.py migrate
# Collect all static files and place them in our STATIC_ROOT folder which will be served by Caddy
docker-compose exec -T web python manage.py collectstatic --no-inputDeploying new changes
Because we're using docker, when we need to update changes we just need to update their Docker images and restart their services. Some technologies can have differences in their deployment process but the basic idea is the same.
Let's see how it could be for our two example applications.
Django application
When we update a django application we need to run some extra commands like migrate, collectstatic, etc. We can follow these steps to run them inside the docker container:
docker pull NEW_DJANGO_IMAGE
sed -i "s/image.*/image:\ NEW_DJANGO_IMAGE/" docker-compose.yml
docker-compose up -d --force-recreate
docker-compose exec -T web python manage.py migrate
docker-compose exec -T web python manage.py collectstatic --no-input
We're pulling the new image from our registry, updating the image value in our docker-compose.yml file, restart the service (it will use the new image now) and then we can execute migrate and collectstatic commands
Phoenix application
For the phoenix application we're going to follow almost the same process with just one difference, we don't need to run migrations in a separate step because they will run when the application starts, this is defined in the phoenix docker image itself.
So we just need to pull the new image, update it in docker-compose.yml file and then restart the service, the final script will be:
docker pull NEW_PHOENIX_IMAGE
sed -i "s/image.*/image:\ NEW_PHOENIX_IMAGE/" docker-compose.yml
docker-compose up -d --force-recreateConclusion
Having a central PostgreSQL instance and a central web server(Caddy), both in the host machine instead of inside a container allow us to manage them easily and also allow us to share these common services alongside the many applications that we are running in our server.
Advent of Code is an annual event of small programming puzzles for a variety of skill sets and skill levels that can be solved in any programming language.
Last year (AoC 2019), I participated for the first time and used Rust as my language of choice.
This year, albeit a few months after the event actually occurred, I participated again and used C as my weapon of choice. (And yes, I did hurt myself in the process.)
I set out with two goals in mind:
- To finish all challenges within a single month.
- To solve them all in under 1 second of runtime (on a single CPU core).
For this last goal I was inspired by Tim Visee who did a really great write-up of some of the tricks he used to efficiently solve this year’s challenges. It sounded like a really fun thing to do and I was already well underway for such a thing anyway.
Two weeks later, iet ies done! Total runtime is 548 ms on my laptop, so I’m quite pleased with the results.
I could probably squeeze out a few more miliseconds here and there, but I see no options for making the 2 bottlenecks (day 15 and day 23) run any faster (except for throwing more hardware at it).
The code is on GitHub here: dannyvankooten/advent-of-code-2020
To be honest, finishing all challenges was harder than getting them all to run in under a second. I really enjoy optimising code for performance and trying out different algorithms.
Things I learned:
- You can represent a hexagonal grid in a 2D array by simplify shifting every odd column or row (day 24).
- Linear probing is a much simpler way to deal with hash collissions than a linked list and results in less cache misses because the values can reside in contiguous memory locations.
- To check neighbors or directions in a 2D grid, it’s a lot more concise to keep an array of
ΔxandΔyvalues versus writing out all the various directions in a separate loop. - You can’t brute force your way out of everything. Sometimes, math is required to get decent performance. Specifically, Chinese Remainder Theorem for day 13 and any of the algorithms for finding the discrete log for day 25.
- Tooling! I wouldn’t want to write C without Valgrind and Gprof. Cachegrind can be useful too.
- When an array gets really sparse, it can be more efficient to use a hashmap despite the added overhead (day 15).
- In loops, it can be really useful to add a call to
getc(stdin)combined withprintfdebugging to allow stepping through the loop. Especially if you haven’t yet taken the time to learn GDB well enough, like me.
The task was to find the product of the three entries in the puzzle input that sum to 2020. Since most numbers in the input were well over half that, it made sense to first sort the input in ascending order before starting our loops.
Day 2 was fairly straightforward, so I won’t go into any details on it.
The puzzle input is a 2D grid of tree positions. We’re then tasked with counting the number of trees for given slopes. I just looped over the 2D array multiple times, each time incrementing the row- and column indices with the given slopes.
The input consisted of several “passports” with their field names and values in a random order. Each field had restrictions on what a valid value for that field looked like.
My solution iterates over each passport in the input, marks each field (except the one that was to be ignored) as valid (1) or invalid (0) in an array and then uses memcmp to check whether the passport is valid or not.
There is a possible optimization by skipping forward to the next passport whenever any of the required fields is invalid, but since the runtime is already so low I did not find this worth the time.
My solution decodes each input line into a row and column, turns these into a seat ID and finds the highest seat ID. At the same tame it toggles a boolean value in a 2D array to keep track of all occupied seats.
It then iterates over this array while skipping the first few rows to find the first seat that is empty.
For day 6 I create two arrays of size 26 to keep track of user answers and group answers respectively. At the end of each line I AND the two arrays, so I have an array filled with 1’s for the answers that were answered by every user in a group. Counting the 1 values in the group answers array gets us the number of questions answered by everyone in a group.
Day 7 / code / runtime: 4144 μs
Day 7 was the ideal candidate for a hashmap, since we have to do a ton of lookups by the name of a bag. Since I had just read Ben Hoyt’s post on how to implement a hash table in C, I decided to give his implementation a try.
Sadly I don’t have the linear search version in version control, as I would like to see what difference it made, but IIRC it was huge given that there are 594 bags in my input.
Day 8 / code / runtime: 105 μs
Day 8 reminded me of the bytecode interpreter I wrote last year, so I really enjoyed this one. To detect the infinite loop I kept changing a single JUMP instruction to a NOOP until we reached the end of the program without repeating an instruction.
Dynamic programming! It took me a while to realise this though. For part 2 I go over a sorted array of adapter joltages and then count how many of the previous adapters it can connect to, adding the sum of options to get to that previous adapter to the one we’re looking at.
Day 11 / code / runtime: 2163 μs
A 2D square-grid problem where we have to look at all 8 neighbors for every point. I optimized this solution by keeping a list of neighbor indices for each seat, so these do not have to be recomputed on every transmutation.
Another optimization is to keep a list of seats to check and remove a seat from this list once it reached its permanent state:
- If a seat is occupied and has less than 5 occupied neighbors, it is permanently occupied.
- If a seat has a permanently occupied neighboring seat, it is permanently empty.
Day 12 / code / runtime: 61 μs
A ship that moves towards a waypoint positioned relative to the ship, according to directions in the puzzle input. I didn’t optimize this solution that much since the straightforward approach was already plenty fast.
I used sin() and cos() for rotating the waypoint, but since the rotation amount is fixed to a multiple of 90 I could get rid of these.
This day required the Chinese Remainder Theorem to get done in a reasonable amount of time. Sadly I was not able to come up with this myself, but I saw a mention of it after getting stuck on my brute-force approach.
Day 14 / code / runtime: 1334 μs
Updating “memory addresses” with certain values from the puzzle input after applying a (changing) mask to the address. Since addresses were so large and wouldn’t fit in an array, I wrote a simple hashmap with integer keys and values.
To make sure the hashed key value is within the bounds of the backing array, I made sure capacity itself was a power of 2 and then used a bitwise & on the capacity - 1. This is a lot faster than using the modulo operator.
Day 15 / code / runtime: 360147 μs (360 ms)
Today would have made the 1-second goal impossible without good enough hardware and a language that compiles to machine code. The solution is fairly straightforward and doesn’t leave much room for optimization.
For values lower than ~500K, I used an array to look-up the previous position of a number in constant time.
Since values larger than 500K were further apart (sparse), I used an optimized hashmap implementation for these values to store the previous positions. It uses a really limited amount (< 10) of linear probing attempts to prevent spending too much time on values that have not been seen before.
I used a lookup array that stores the previous index of a number. The array was allocated using mmap with 2 MB “huge” page sizes in combination with a bitset that is checked before even indexing into the array. This shaved off another 100ms compared to the array + hashmap approach.
Day 16 / code / runtime: 183 μs
Today we had to parse a bunch of rules and find which values corresponded to which rule. We could deduce the position of each field by first creating a list of possible options and then picking the only available option and removing it from all other fields, repeating that latter part until we know the position for each field.
Today’s optimization was to simply ensure we’re breaking out of each loop or skipping to the next iteration as soon as possible.
Day 17 / code / runtime: 2136 μs
Day 17 was another game of life inspired challenge, but using a 4D grid.
The largest performance gain came from precomputing the neighbor count by looping over the active tiles and then adding 1 to each neighbor. This saves a ton of iterations versus doing it the other way around.
Day 18 / code / runtime: 449 μs
For day 18 we got to write a simple math parser with different operator precedence than what we’re used to in human math. I used what I learned from the interpreterbook.com to implement an operator precedence parser.
Day 19 / code / runtime: 516 μs
I forgot the specifics of day 19. It was about implementing a form of regex and preventing infinite recursion. All I recall is that I did a simple recursion check on the two rules that caused the infinite recursion, and it worked…
Day 20 / code / runtime: 877 μs
Day 20 was about putting together an image from various tiles that had to be rotated and flipped into the correct orientation in order to fit together. This was the challenge that cost me the most time, but also probably the one I enjoyed the most.
My solution simply started with the first tile in the top-left corner in the image and then fitted any of the other tiles on any of its edges until all tiles were in the image. Instead of rotating the entire tile and then checking whether it fit, I only compared the edges of the tile and only rotated or flipped it when a match was found.
If another tile fitted on the northern or western edge of the starting tile, I shifted all the tile in the image. Another option was to first find a corner tile and then work from there, but this approach proved to be faster.
Day 21 / code / runtime: 276 μs
Day 21 resembled day 16 in that we could decude which ingredients contained an allergen by repeatedly picking the only available option until we were done.
Day 22 / code / runtime: 104 μs
Today was fun! A game of cards with recursion.
Pre-allocating enough memory for at most 50 games gave a slight performance increase. The biggest improvement came from not recursing into a sub-game (and all of its descedentants) when the sub-game started with player 1 holding the highest card.
Because of the special rule this meant that player 1 would eventually emerge as the winner, so we could declare him winner right away and save on an awful lot of recursion.
Day 23 / code / runtime: 172981 μs (173 ms)
A slow day today with not much room for making it run faster. I used an array where the value simply contained the next cup, thus resembling a singly linked list. This meant just changing 2 values on every iteration, 10 million times…
Like for day 15, I used 2 MB page sizes again. This resulted in a 22% performance improvement (51 ms faster) than using the default 4 kB page size.
Day 24 / code / runtime: 3102 μs
Another 2D grid problem but using a hexagonal grid, flipping to either black or white based on directions from the puzzle input. Part 2 introduced a form of game of life again. I re-used the same optimizations from before, pre-computing neighbor counts.
One more thing was to allocate a grid large enough to hold our entire “infinite” grid, but only iterating over the values neighboring any black tile.
Whenever a tile was flipped to black, I extended the grid bounds to iterate over and updated the neighbor count for each of that tile’s neighbors.
Day 25 / code / runtime: 58 μs
Day 25 involved finding the discrete log, so I used the Baby-Step-Giant-Step algorithm while re-using my integer hashmap from an earlier day. This turned out to be really fast, clocking it at just 58 microseconds of runtime.

Cómo suavizar un scroll
Programador Web Valencia 01 04 2021
Si queremos que al pulsar en un hipervínculo, o ancla, se desplace de manera suave y lenta, en lugar ser instantáneo, podemos optar por usar algunos de siguientes 3 trucos. Pasando por CSS, JavaScript o JQuery. El artículo no cubre la forma de realizar un ancla, aunque puedes aprender en mi curso gratuito de HTML.
DEMO
Versión solo con CSS
Al añadir el siguiente CSS conseguirás que los movimientos de tus anclas sean suaves en lugar de instantáneos.
body {
scroll-behavior: smooth;
}
En el momento que se escribió este artículo no era compatible con Safari.
Versión solo con JavaScript Vainilla
En caso contrario de que no funcione como esperas podrás usar un poco de JavaScript para conseguir el mismo efecto.
<script>
document.addEventListener('DOMContentLoaded', () => {
//===
// SCROLL SMOOTH
//===
// Variables
const links = document.querySelectorAll('a[href *= "#"]:not([href = "#"])');
/**
* Event scroll
*/
function clickHandler(event) {
event.preventDefault();
const href = this.getAttribute("href");
const offsetTop = document.querySelector(href).offsetTop;
scroll({
top: offsetTop,
behavior: "smooth"
});
}
// Add event all links
links.forEach((link) => link.addEventListener("click", clickHandler));
});
</script>
Versión solo con JQuery
Y por último, en caso de que aún así no funcione; puedes recurrir a un clásico que nunca te va a fallar y ha sido utilizado durante muchos años.
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.6.0/jquery.min.js"></script>
<script>
$(function() {
$('a[href *= "#"]:not([href = "#"])').click(function() {
if (location.pathname.replace(/^\//, '') == this.pathname.replace(/^\//, '') || location.hostname == this.hostname) {
let target = $(this.hash);
target = target.length ? target : $('[name = ' + this.hash.slice(1) + ']');
if (target.length) {
$('html, body').animate({
scrollTop: target.offset().top
}, 1000);
return false;
}
}
});
});
</script>
Obviamente necesitarás que esté presente JQuery en tu proyecto web.
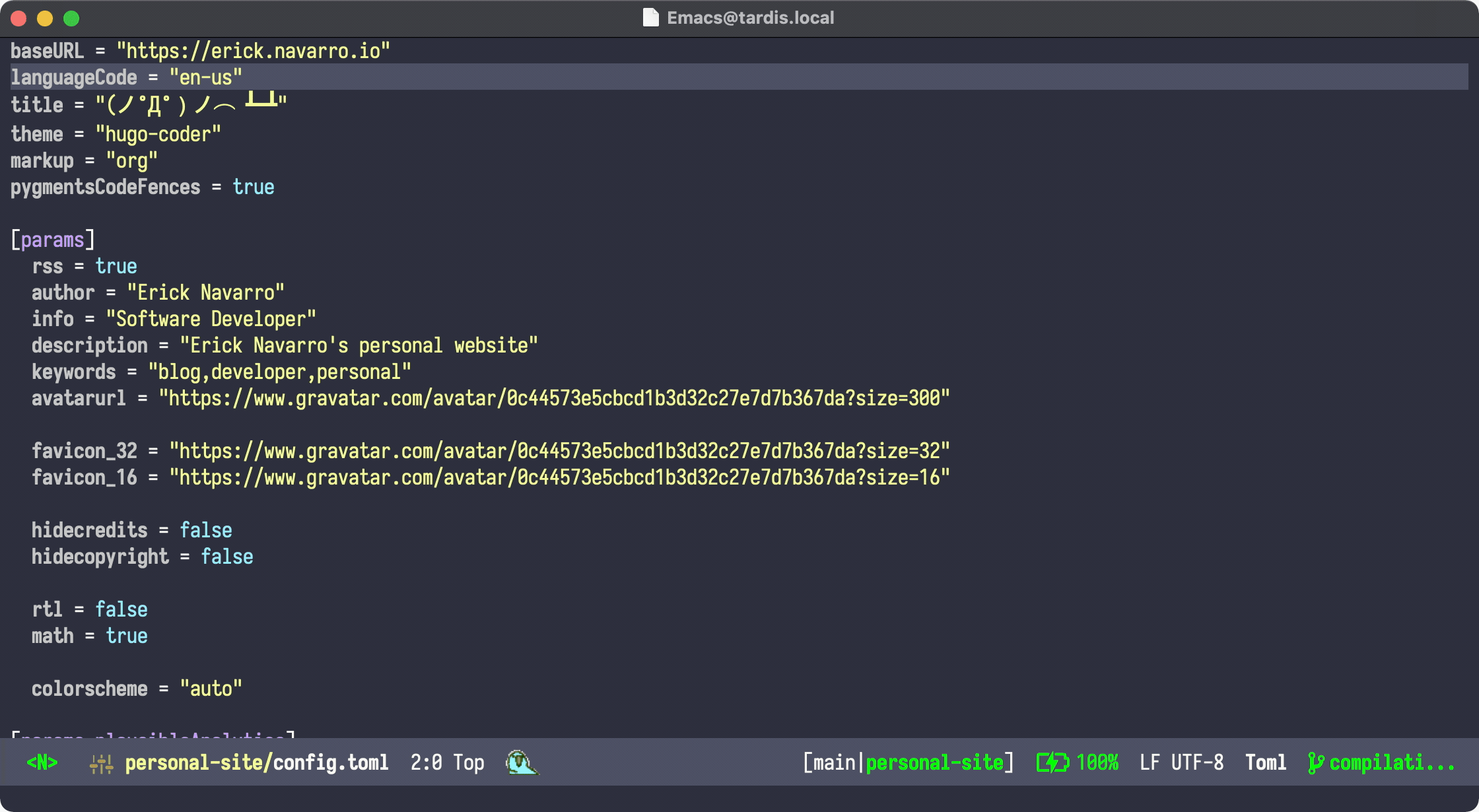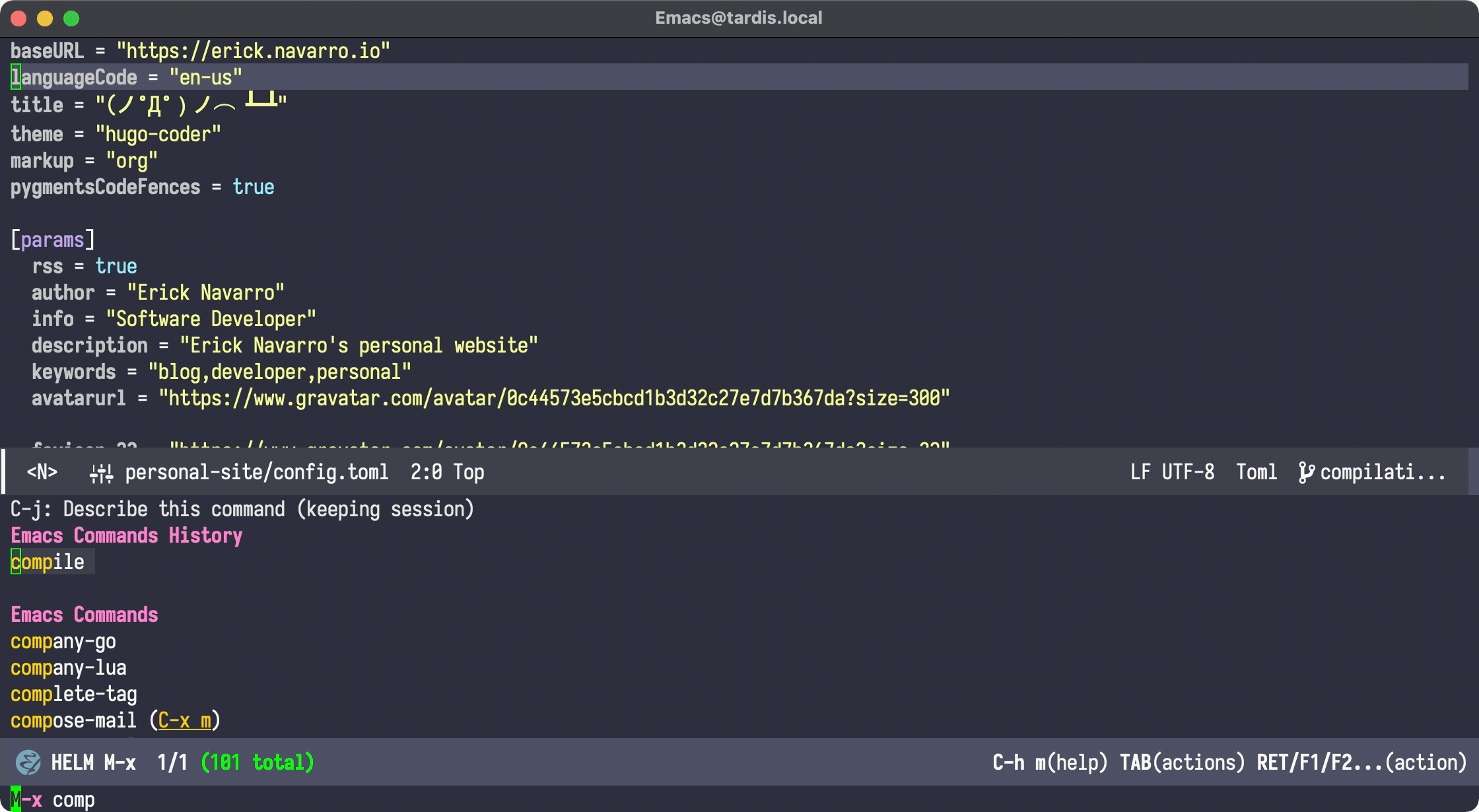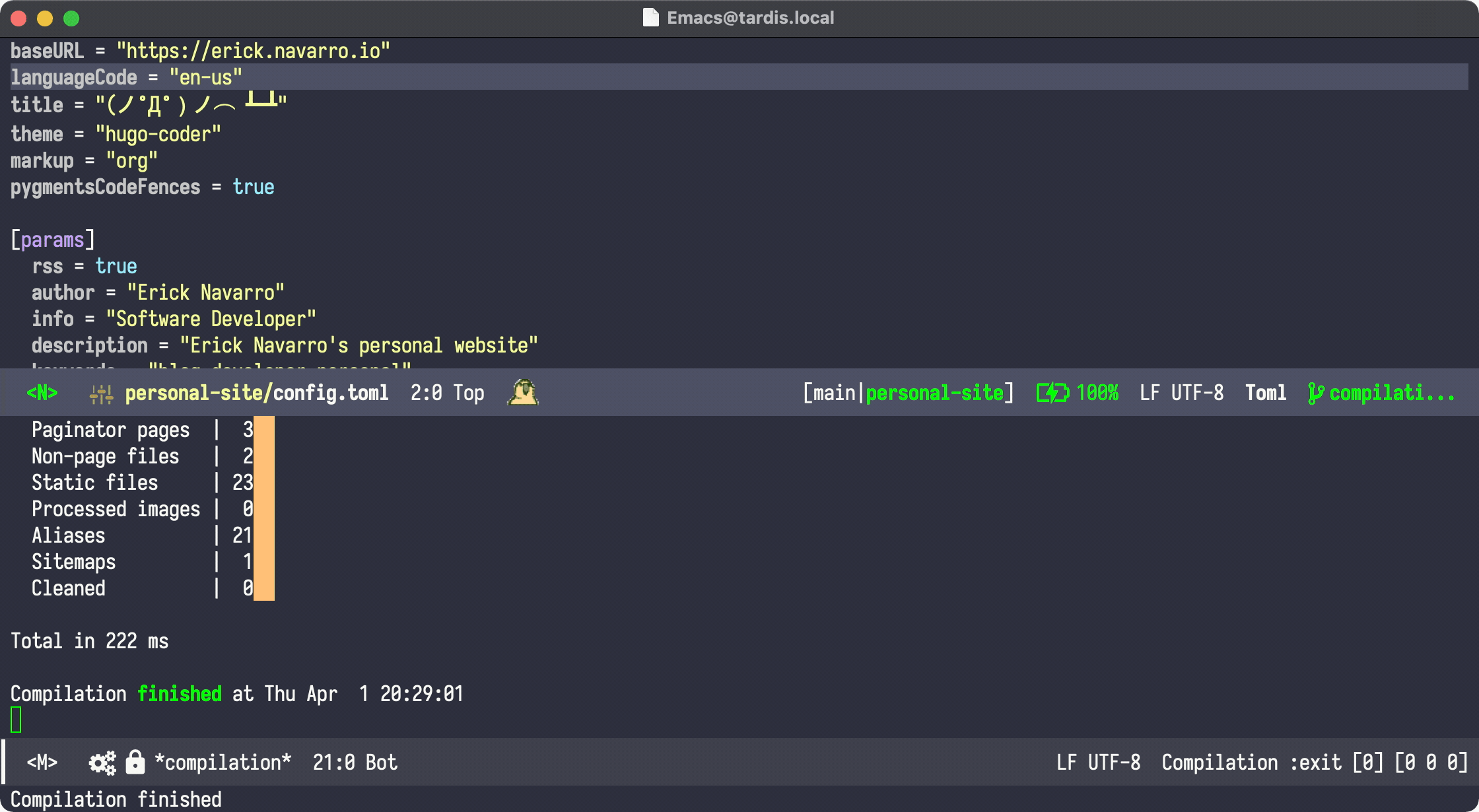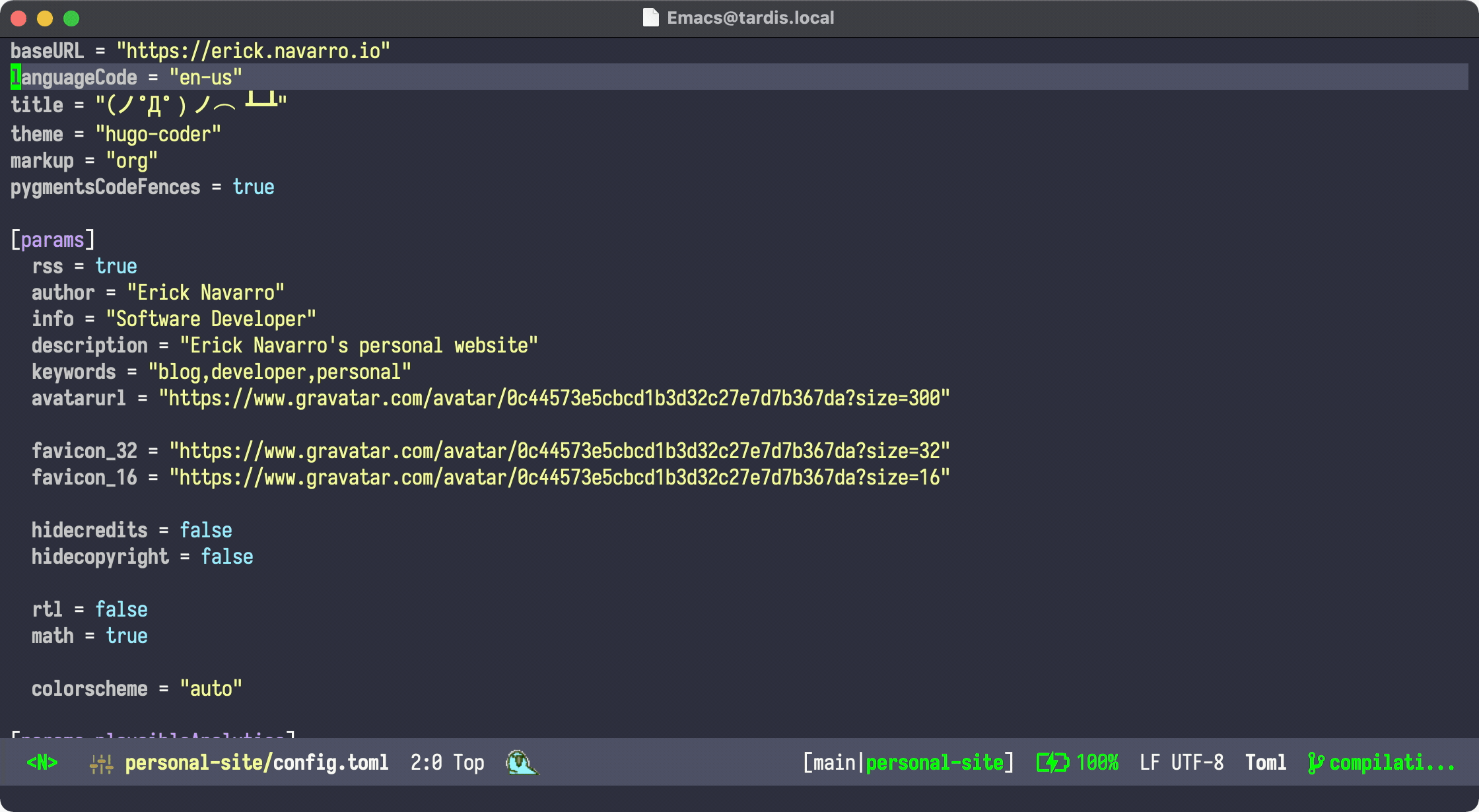
Compilation mode is a major mode that allow us to run a command and see its output result in a special buffer, this resulting buffer show the errors and allow us to navigate through them, you can check the documentation for more details.
It's a "simple mode" but it can be used for many things like compile and run a program, run tests, and so on.
Usage
Interactive
compile is an interactive function so we can call it with M-x compile and enter the command we want to execute.
In the following example we're compiling this blog using hugo binary:
From code
compile is a emacs-lisp function so we call it from our code, we just need to take care about the default-directory when we call it, for example if we call it from lib/hello.ex buffer, default-directory will be lib and in some cases we want to use our project root, or a different directory, to run our command.
To fix this we need to setup default-directory before we call compile, for example let's build a custom function to run hlint in our entire project and then show its results in a compilation buffer:
(defun my/run-hlint ()
"Run hlint over the current project."
(interactive)
(let ((default-directory (projectile-project-root)))
(compile "hlint .")))
In this case we're setting up default-directory with our project root (using projectile to get the root) and then when we call compile it will take default-directory correctly.
Some tweaks
These modifications to default behaviour of compilation-mode should be made after the mode was loaded so we need to use with-eval-after-load otherwise these changes won't be applied correctly.
Evil-mode
The compilation buffer has some preset key bindings that conflict with evil-mode, for example when we press g in a compilation buffer this will re-run the command, but this key binding is also used by evil-mode, to fix this we can disable the default key binding with:
(with-eval-after-load 'compile
(define-key compilation-mode-map (kbd "g") nil)
(define-key compilation-mode-map (kbd "r") 'recompile)
(define-key compilation-mode-map (kbd "h") nil))
In this case h key binding is also disabled (also used by evil) and r is remapped to recompile for easy access now that we disabled g default key binding.
Follow compilation output
By default compilation-mode doesn't follow the output of the command so if our command result has a large output we'll need to scroll manually, to fix this we can change compilation-scroll-output to t
(with-eval-after-load 'compile
;; set cursor to follow compilation output
(setq compilation-scroll-output t))Enable ANSI colors
Some tools show results with colors for easy reading but compilation-mode won't show them by default, you can make them look better with:
(require 'ansi-color)
(defun colorize-compilation-buffer ()
(let ((inhibit-read-only t))
(ansi-color-apply-on-region (point-min) (point-max))))
(add-hook 'compilation-filter-hook 'colorize-compilation-buffer)This was taken from this Stack Overflow answer
Re run compilation from another buffer
When we're making changes in our code we want to re-run our compilation process right after we save the changes but to do this we have to move to the compilation buffer to be able to re-run the compilation, a better approach to do this could be just call recompile by using a key binding, I use evil-leader to make this:
(evil-leader/set-key "R" 'recompile)

But it can be attached to any key binding, for example:
(global-set-key (kbd "C-c C-r") 'recompile)Bonus: run parrot mode animation when a compilation is successful
I configured parrot-mode to animate the little parrot every time the compilation process is a success, to make this we need a small function that check if it was a success and then we need to attach it to 'compilation-finish-functions, this is a variable defined in compilation-mode.
(defun my/parrot-animate-when-compile-success (buffer result)
(if (string-match "^finished" result)
(parrot-start-animation)))
(use-package parrot
:ensure t
:config
(parrot-mode)
(add-to-list 'compilation-finish-functions 'my/parrot-animate-when-compile-success))Conclusion
As we can see compilation-mode is a simple but powerful mode that allow us to build our own tools, we can create an automatic build system in case there is not something already existing for the technology we're using or if we just want to run some tasks in an easier way.
Para este episodio de Informe Nube, David y Antony vuelven con Terraform sobre AWS para explicar tres ejemplos básicos. Este episodio continúa el anterior sobre Terraform en AWS y se puede seguir también desde el canal de YouTube de Cursos de Desarrollo.
- Cómo crear las credenciales y configurar el cli de AWS
- Cómo crear una máquina virtual en AWS EC2 con acceso SSH y Clave SSH
- Cómo crear un servidor Web Nginx en EC2 con soporte de Elastic IP y Volumen de Datos asociad
- ómo crear un Cluster de Kubernetes EKS en AWS
No dudes en conectar con David y con Antony para sugerirles nuevos episodios sobre cloud y tecnologías de servidor.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

Task Description vs Effort
MonkeyUser 30 03 2021
![]()
A look at the work that standards makes possible, and the kinds of hypertext that were never fully realized
The post March 2021 Weblog: Trusting in the Standard appeared first on The History of the Web.
Font size is useless; let’s fix it
tonsky.me 29 03 2021
Updated Debian 10: 10.9 released
Debian News 27 03 2021
buster). This point release mainly adds corrections for security issues, along with a few adjustments for serious problems. Security advisories have already been published separately and are referenced where available.
![]()
MARCO AURELIO Y LA ADVERSIDAD
Diario Estoico 25 03 2021

The Lem editor, which supports Common Lisp as well as other languages, works by default in the terminal with a ncurses frontend (it also has an experimental Electron frontend). It ships a nice Lisp REPL: it has good fuzzy completion, enough keyboard shortcuts, an interactive debugger, a completion menu, etc.
It is now possible to run Lem straight in its Lisp REPL. Run it with:
lem --eval "(lem-lisp-mode:start-lisp-repl t)"
The optional argument (t) was added recently (thanks, @cxxxr) and allows to start the REPL in fullscreen.
Here is it in action:



The other terminal-based REPL alternatives are:
but IMO, they now fall short compared to Lem’s features.
Installation
To install it, see its wiki. In short, do
ros install cxxxr/lem
or use lem-docker.
To install Roswell, do one of
brew install roswell # macos or linuxbrew
yay -S roswell
scoop install roswell # windows
# Debian package:
curl -sOL `curl -s https://api.github.com/repos/roswell/roswell/releases/latest | jq -r '.assets | .[] | select(.name|test("deb$")) | .browser_download_url'`
sudo dpkg -i roswell.deb
See its releases.
Usage (quickref)
Lem has Emacs-like keybindings, as well as a vi emulation (M-x vi-mode). Unfortunately, that is not documented much.
So, to open a file, press C-x C-f (you get the file selection dialog shown above). To save it, it’s C-x C-s.
To switch to the REPL: C-c C-z.
To compile and load a buffer: C-c C-k. To compile a function: C-c C-c.
To switch windows: C-x o. To make a window fullscreen: C-x 1. To split it vertically: C-x 3 and horizontally: C-x 2.
To switch buffers: C-x b.
To run an interactive command: M-x (alt-x).
See this Emacs & Slime cheatsheet to find more: https://lispcookbook.github.io/cl-cookbook/emacs-ide.html#appendix
Lem works out of the box for several programming languages (Python, Rust, Scala…). It also has an HTML mode, a directory mode… Lem needs to be discovered!
Emoji under the hood
tonsky.me 24 03 2021

DENVERCODER9
MonkeyUser 23 03 2021

![]()
Over the past few years, Microsoft has partnered with a group of browser vendors and other industry stakeholders to identify and address the top sources of web developer pain through initiatives like the Joining forces on better browser compatibility in 2021 appeared first on Microsoft Edge Blog.
Se llaman potencias de Fermi-Dirac a los números de la forma \(p^{2^k}\),
ordenados de menor a mayor, donde p es un número primo y k es un número natural.
Vamos a ver cómo crear la sucesión de potencias Fermi-Dirac. Realizaremos las
siguientes comprobaciones:
potencias: list[int]
potencias[:14] == [2,3,4,5,7,9,11,13,16,17,19,23,25,29]
potencias[60] == 241
potencias[10**6] == 15476303
Estudio previo
Si sacamos la lista de potencias en función del exponente k tendríamos las
siguientes sucesiones:
$$
\begin{align*}
P_0 &= 2,3,5,7,11,...\\
P_1 &= 4,9,25,49,121,..\\
P_2 &= 16,81,625,2401,14641,...\\
P_3 &= 256,6561,390625,5764801,214358881,815730721,...
\end{align*}
$$
Necesitamos combinar estas sucesiones en una sola. A priori, no sabemos cuántos elementos vamos a necesitar de cada sucesión. Como máximo, para sacar las primeras 14 potencias nos basta con los primeros 14 números primos y crear 14 secuencias, de \(P_0\) a \(P_{13}\), ordenarlos sus elementos en una única lista y escoger los primeros 14 elementos. Con este proceso habremos calculado 196 potencias para sólo 14 elementos que necesitamos al final.
from primes import primes
potencias = sorted(p**2**k for p in primes[:14] for k in range(0, 14))
print(potencias[:14])
[2, 3, 4, 5, 7, 9, 11, 13, 16, 17, 19, 23, 25, 29]
Aún en el caso de que tuviéramos algún medio de reducir el número de elementos a usar de cada secuencia, seguimos sin saber cuántos números primos serán necesarios. Para sacar los 14 primeros elementos de las potencias de Fermi-Dirac sólo se necesitaban los 10 primeros números primos.
Es evidente que una estrategia por fuerza bruta es complicada y termina por hacer muchos cálculos innecesarios, una complejidad del \(O({n^2})\) no resoluble con un ordenador normal. Veamos cómo nos puede ayudar la evaluación perezosa.
Modelos
Por intentar crear un modelo, intentemos ver las sucesiones como un iterador de iteradores:
from itertools import count
from primes import primes
potencias = ((p**2**k for p in primes) for k in count())
Pero el problema con las expresiones generadora es similar al que tienen las expresiones lambda: carecen de su propia clausura y cualquier variable libre queda alterada por el entorno donde se evalúan.
Se puede comprobar el fallo si intentamos extraer dos iteradores:
p0 = next(potencias)
p1 = next(potencias)
next(p1) # --> 4
next(p0) # --> 4
next(p0) # --> 9
El exponente k ha cambiado de valor con el segundo iterador, lo que afecta a
las potencias del primero. Tenemos que dotar a los iteradores de su propia clausura:
from collections.abc import Iterator
from itertools import count
from primes import primes
def potencias_gen(k: int) -> Iterator[int]:
yield from (p**2**k for p in primes)
potencias = (potencias_gen(k) for k in count())
Para obtener una única secuencia a partir de este iterador de iteradores en un único iterador, operación que se conoce como “aplanar la secuencia”.
Definimos la siguiente función para mezclar dos listas ordenadas:
# tipo para secuencias ordenadas
SortedIterator = Iterator[int]
def zipsort(s1: SortedIterator, s2: SortedIterator) -> SortedIterator:
x = next(s1)
y = next(s2)
while True:
if x <= y:
yield x
x = next(s1)
else:
yield y
y = next(s2)
La función zipsort combina dos listas ordenadas SortedIterator para devolver
otra lista ordenada SortedIterator. Si quisiéramos combinar tres listas,
bastaría con volver repetir con zipsort:
zipsort(zipsort(s1, s2), s3)
En general, podríamos combinar todas las listas de esta manera:
def flat(iterators: Iterator[SortedIterator]) -> SortedIterator:
it1 = next(iterators)
it2 = flat(iterators)
yield from zipsort(it1, it2)
potencias = flat(potencias_gen(k) for k in count())
El problema es que se entra en un bucle infinito de llamadas recursivas a flat
que habrá que evitar.
Si observamos las sucesiones \(P_0\), \(P_1\), \(P_2\),…, el primer elemento de una sucesión es siempre inferior a cualquier elemento de sucesiones posteriores. Usando esta propiedad, podemos redefinir nuestra función aplanadora:
def flat(iterators: Iterator[SortedIterator]) -> SortedIterator:
it1 = next(iterators)
yield next(it1)
yield from zipsort(it1, flat(iterators))
potencias = flat(potencias_gen(k) for k in count())
La función flat devuelve siempre un elemento antes de invocarse por
recursividad, suficiente para frenar la cadena de llamadas recursivas. Visto de
otro modo, se ha convertido la función en perezosa, devolviendo elementos a
medida que sean necesarios. De todos modos, seguimos limitados por el nivel de
recursividad en python (~3000 niveles en CPython), aunque no vamos a superar
este límite en las pruebas1.
Código final
Descarga: potencias.py
from collections.abc import Iterator
from itertools import count
from typing import TypeVar
from lazyseq import LazySortedSequence
from primes import primes
SortedIterator = Iterator[int]
def join(s1: SortedIterator, s2: SortedIterator) -> SortedIterator:
x = next(s1)
y = next(s2)
while True:
if x <= y:
yield x
x = next(s1)
else:
yield y
y = next(s2)
def flat(it: Iterator[SortedIterator]) -> SortedIterator:
s1 = next(it)
yield next(s1)
yield from join(s1, flat(it))
def mkiter(k):
yield from (p ** 2 ** k for p in primes)
potencias = LazySortedSequence(flat(mkiter(k) for k in count()))
Para las comprobaciones:
>>> potencias[:14]
[2, 3, 4, 5, 7, 9, 11, 13, 16, 17, 19, 23, 25, 29]
>>> potencias[60]
241
>>> potencias[10 ** 6]
15476303
>>> primes.size
999432
Para obtener el elemento \(10^6\) tarda bastante al necesitar obtener casi un millón de números primos. Una vez obtenidos, el cálculo es bastante rápido.
Serie Evaluación Perezosa en Python
- Parte 1 - Introducción a la evaluación perezosa
- Parte 2 - Secuencias infinitas
- Parte 3 - Memoización
- Parte 4 - Evaluación perezosa avanzada
- Parte 5 - Formalización de la Secuencia Perezosa
- Parte 6 - Ejemplo práctico: Potencias de Fermi-Dirac
- Apéndice: sobre el tipado de datos utilizado
La serie unificada como Jupyter Notebook en:
ANOTACIONES:
-
Es posible que en posteriores artículos veamos técnicas para superar las limitaciones de la recursivad en python. ↩
Introducción a la Evaluación Perezosa
Podemos definir “Evaluación Perezosa” como aquella evaluación que realiza los mínimos cálculos imprecindibles para obtener el resultado final.
La evaluación perezosa es una de las característica del languaje haskell, aunque vamos a ver que también se puede hacer en otros lenguajes como python.
Por ejemplo, imaginemos que queremos obtener todos los número cuadrados menores de 100:
cuadrados = [x**2 for x in range(1, 100)]
resultado = [y for y in cuadrados if y < 100]
Para obtener el resultado, antes hemos calculado la lista completa
cuadrados, a pesar de que sólo necesitábamos unos 10 elementos.
Una posible mejora sería usar una expresión generadora:
cuadrados = (x**2 for x in range(1, 100))
resultado = [y for y in cuadrados if y < 100]
Aquí los elementos de la lista cuadrados se calculan a medida que son
necesarios, sin gastar memoria para almacenar la secuencia a medida que se
obtiene, algo que pasaba con el ejemplo anterior. Aún así, se vuelven a calcular
los 100 cuadrados, ya que no se corta la iteración en ningún momento.
Necesitamos un modo de limitarnos únicamente a los elementos que vamos a utilizar.
Para quedarnos sólo con los primeros elementos vamos a usar la función
itertools.takewhile:
from itertools import takewhile
cuadrados = (x**2 for x in range(1, 100))
resultado = list(takewhile(lambda y: y<100, cuadrados))
En este caso, obtenemos únicamente los cuadrados necesarios, lo que supone un importante ahorro de tiempo de cálculo.
Si no se tiene cuidado, es muy fácil hacer más cálculos de la cuenta, e incluso acabar en bucles infinitos o agotando los recursos de la máquina. Como veremos en esta serie de artículos, en python se puede tener evaluación perezosa usando correctamente iteradores y generadores.
Tipo Range
Veamos el siguiente código:
>>> r = range(2,100,3)
>>> r[10]
32
Normalmente, se usa la función range para crear bucles sin tener en cuenta que
realmente es un constructor de objetos de tipo Range. Estos objetos responden
a los mismos métodos que una lista, permitiendo obtener un elemento de cualquier
posición de la secuencia sin necesidad de generar la secuencia completa. También
se pueden hacer otras operaciones habituales con listas:
>>> len(r) # obtener el tamaño
33
>>> r[20:30] # obtener un rango
range(62, 92, 3)
>>> r[30:20:-1] # obtener un rango inverso
range(92, 62, -3)
>>> r[::-1] # la misma secuencia invertida
range(98, -1, -3)
>>> r[20:30:-1] # umm, secuencia vacía???
range(62, 92, -3)
>>> r[::2] # una nueva secuencia con distinto paso
range(2, 101, 6)
>>> 3 in r # comprobar si contiene un elemento
False
>>> r.index(65) # buscar la posición de un elemento
21
Como vemos, de algún modo calcula los nuevos rangos y los pasos según necesitemos. Es suficientemente inteligente para cambiar el elemento final por otro que considere más apropiado.
Digamos que un objeto de tipo Range conoce cómo operar con secuencias
aritméticas, pudiendo obtener un elemento cualquiera de la secuencia sin tener
que calcular el resto.
Secuencias con elemento genérico conocido
Probemos a crear algo similar a Range para la secuencia de cuadrados. Derivará
de la clase abstracta Sequence, por lo que tenemos que definir, por lo menos,
los métodos __len__ y _getitem__. Nos apoyaremos en un objeto range para
esta labor (patrón Delegate):
from collections.abc import Sequence
from typing import Union
class SquaresRange(Sequence):
def __init__(self, start=0, stop=None, step=1) -> None:
if stop is None:
start, stop = 0, start
self._range = range(start, stop, step)
@staticmethod
def from_range(rng: range) -> "SquaresRange":
"""
Constructor de SquaresRange a partir de un rango
"""
instance = SquaresRange()
instance._range = rng
return instance
def __len__(self) -> int:
return len(self._range)
def __getitem__(self, idx: Union[int, slice]) -> Union[int, "SquaresRange"]:
i = self._range[idx]
return i ** 2 if isinstance(i, int) else SquaresRange.from_range(i)
def __repr__(self) -> str:
r = self._range
return f"SquaresRange({r.start}, {r.stop}, {r.step})"
Podemos probar su funcionamiento:
>>> for i in SquaresRange(-10, 1, 3):
... print(i)
...
100
49
16
1
>>> list(SquaresRange(-1, 50, 4)[:30:2])
[1, 49, 225, 529, 961, 1521, 2209]
>>> SquaresRange(100)[::-1]
SquaresRange(99, -1, -1)
>>> 16 in SquaresRange(-10, 1, 3)
True
Hay que tener en cuenta que, a diferencia de un iterador, este rango no se “agota” por lo que se puede usar repetidas veces sin ningún problema.
Siguiendo más allá, podemos generalizar esta secuencia para se usar cualquier función. Creamos la siguiente clase abstracta:
from abc import abstractmethod
from collections.abc import Sequence
from typing import Type, Union
class GenericRange(Sequence):
def __init__(self, start=0, stop=None, step=1) -> None:
if stop is None:
start, stop = 0, start
self._range = range(start, stop, step)
@abstractmethod
def getitem(self, pos: int) -> int:
"""
Método abstracto.
Función para calcular un elemento a partir de la posición
"""
return pos
@classmethod
def from_range(cls: Type["GenericRange"], rng: range) -> "GenericRange":
"""
Constructor de un GenericRange a partir de un rango
"""
instance = cls()
instance._range = rng
return instance
def __len__(self) -> int:
return len(self._range)
def __getitem__(self, idx: Union[int, slice]) -> Union[int, "GenericRange"]:
i = self._range[idx]
return self.getitem(i) if isinstance(i, int) else self.from_range(i)
def __repr__(self) -> str:
classname = self.__class__.__name__
r = self._range
return f"{classname}({r.start}, {r.stop}, {r.step})"
Con esta clase abstracta creamos dos clases concretas, definiendo el método
abstracto .getitem() con la función genérica:
class SquaresRange(GenericRange):
def getitem(self, i):
return i ** 2
class CubicsRange(GenericRange):
def getitem(self, i):
return i ** 3
Que podemos emplear de este modo:
>>> for i in SquaresRange(-10, 1, 3):
... print(i)
...
100
49
16
1
>>> for i in CubicsRange(-10, 1, 3):
... print(i)
...
-1000
-343
-64
-1
>>> list(CubicsRange(-1, 50, 4)[:30:2])
[-1, 343, 3375, 12167, 29791, 59319, 103823]
>>> SquaresRange(100)[::-1]
SquaresRange(99, -1, -1)
>>> SquaresRange(100).index(81)
9
Resumen
La Evaluación Perezosa realiza únicamente aquellos cálculos que son necesarios para obtener el resultado final, evitando así malgastar tiempo y recursos en resultados intermedios que no se van a usar.
El tipo Range es algo más que una facilidad para realizar iteraciones. A partir de un objeto range se pueden crear nuevos rangos sin necesidad de generar ningún elementos de la secuencia.
Si conocemos el modo de obtener cualquier elemento de una secuencia a partir de su posición, entonces podemos crear secuencias para operar con ellas igual que haríamos con un rango, sin necesidad de generar sus elementos.
En el próximo artículo veremos cómo podemos ir más lejos para crear y trabajar con secuencias infinitas de elementos.
Serie Evaluación Perezosa en Python
- Parte 1 - Introducción a la evaluación perezosa
- Parte 2 - Secuencias infinitas
- Parte 3 - Memoización
- Parte 4 - Evaluación perezosa avanzada
- Parte 5 - Formalización de la Secuencia Perezosa
- Parte 6 - Ejemplo práctico: Potencias de Fermi-Dirac
- Apéndice: sobre el tipado de datos utilizado
La serie unificada como Jupyter Notebook en:
En este episodio partimos del interesante artículo de Matt E. Patterson llamado «The Future of Web Software Is HTML-over-WebSockets» En el artículo se explica con detalle la evolución de la arquitectura de las aplicaciones web y la aparición de un nuevo enfoque basado en usar WebSockets. Según el autor «este nuevo enfoque basado en WebSockets está llamando la atención de los desarrolladores web. Es un enfoque que reafirma las promesas de los frameworks clásicos de server-rendering (creación rápida de prototipos, gestión del estado del lado servidor, sólido rendimiento de renderizado) y que permite la colaboración multiusuario y los diseños reactivos, sin tener que construir dos aplicaciones separadas».
Este nuevo enfoque de HTML sobre WebSockets es complicado de asimilar cuando venimos de un arquitectura que separa claramente el lado cliente y servidor. Una gran preocupación de muchos desarrolladores es evitar soluciones complejas de lado cliente, evitando esos cientos de KB que se acumulan en el navegador. La solución es sustituir JSON por HTML, en un ciclo donde el encargado de renderizar sea siempre el servidor y envíe de forma inmediata por WebSockets el nuevo HTML a mostrar.
Este episodio surge principalmente de un artículo de Andros Fenollosa acompañado de vídeo, donde explica este concepto de WebSockets. Aquí hablamos sobre la información compartida con Andros sobre HTML sobre WebSockets y al mismo tiempo exploramos ventajas, inconvenientes, conceptos de seguridad y frameworks. También vemos la demo creada por Andros en Django para ver el ejemplo de funcionamiento en un blog de 100 entradas.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Recientemente he tenido que gestionar en un cliente el bloqueo de ciertos usuarios, cuando querían acceder a diferentes servidores de un entorno vía SSH. Esto era debido a que, seguramente, habían puesto de forma...
La entrada Cómo usar Pam_Tally2 para gestionar los intentos fallidos de acceso en SSH se publicó primero en ochobitshacenunbyte.
To date, Clojure’s support for keyword arguments forces programmers to choose between creating APIs that better support people (accepting keyword args) or APIs that better support programs (by taking a map of those args).
Introduced in Clojure 1.11, a function specified to take keyword arguments may be passed a single map instead of or in addition to (and following) the key/value pairs. When a lone map is passed, it is used outright for destructuring, else a trailing map is added to the map built from the preceding key/values via conj. For example, a function that takes a sequence of optional keyword arguments and returns a vector containing the values is defined as:
(defn destr [& {:keys [a b] :as opts}]
[a b opts])
(destr :a 1)
->[1 nil {:a 1}]
(destr {:a 1 :b 2})
->[1 2 {:a 1 :b 2}]In Clojure 1.11 the call to destr accepts a mixture of key/value pairs and/or a lone (or trailing) map benefitting both programmer and program.
This enhancement is available now in org.clojure/clojure "1.11.0-alpha1".
Ready for QA
MonkeyUser 18 03 2021
![]()
![]()
Content Management Systems — software that helps people author and publish websites — likely dates back farther than you think. The problem is, it wasn't quite called that yet.
The post Content Management Made Simple appeared first on The History of the Web.

Trolley Conundrum
MonkeyUser 16 03 2021
Refactorización
Hasta ahora hemos visto cómo crear una secuencia perezosa que va guardando en una caché los resultados de una operación (proceso de memoización). Así mismo, cuando la secuencia es una secuencia ordenada podemos optimizar algunas búsquedas, tal como vimos con la secuencia de números primos.
Vamos a intentar darle una forma a todo esto creando las clases LazySequence y
LazySortedSequence.
El código refactorizado final se puede descargar a continuación:
LazySequence
La clase LazySequence crea una secuencia perezosa a partir de un iterador.
A medida que obtenga elementos del iterador, los va almacenando en una caché:
T = TypeVar("T", covariant=True)
class LazySequence(Iterator[T]):
def __init__(self, iterator: Iterator[T]):
self._cache: list[T] = []
self.iterator = iterator
def __next__(self) -> T:
x = next(self.iterator)
self._cache.append(x)
return x
Cada vez que se calcule un nuevo elemento a través de next(), éste se añadirá
a la caché.
Para que funcione como secuencia, se implementan los métodos __getitem__:
@singledispatchmethod
def __getitem__(self, idx):
return NotImplemented
@__getitem__.register
def __getitem_int__(self, idx: int) -> T:
if idx < 0:
raise OverflowError
elif idx >= self.size:
self._cache.extend(islice(self.iterator, idx - self.size + 1))
return self._cache[idx]
@__getitem__.register
def __getitem_slice__(self, sl: slice) -> list[T]:
rng = range(INFINITE)[sl]
return [self[i] for i in rng]
Y añadimos el método __iter__ para cumplir con el protocolo iterator:
def __iter__(self) -> Iterator[T]:
yield from self._cache
yield from (self[i] for i in range(len(self._cache), INFINITE))
LazySortedSequence
Derivando de LazySequence, se crea la clase LazySortedSequence para cuando
el iterador produzca una secuencia ordenada. Tal como hemos visto, cuando la
secuencia está ordenada podemos realizar búsquedas por bisecciones que
resultan bastante eficiente.
La operación principal será el método insertpos() que nos indica la posición
en la que se insertaría un elemento en la secuencia, manteniendo el orden de los
elementos. Si no son suficientes con los elementos de la caché, se extraerán más
del iterador mediante next(), que irán añadiéndose progresivamente a la caché:
Ord = TypeVar("Ord", bound=int, covariant=True)
class LazySortedSequence(LazySequence[Ord]):
def insertpos(self, x: int) -> int:
if self.size > 0 and x <= self.last:
idx = bisect_left(self._cache, x)
else:
while x > next(self):
pass
idx = self.size - 1
return idx
Con el método insertpos() ya podemos definir los métodos __contains__() e
index() típicos de la secuencias:
def __contains__(self, x: int) -> bool:
idx = self.insertpos(x)
return x == self._cache[idx]
def index(self, x: int) -> int:
idx = self.insertpos(x)
if x == self._cache[idx]:
return idx
raise ValueError(f"{x} is not in {self.__class__.__name__}")
No existe un protocolo para elementos ordenables (Sortable, Ordered). Para
ordenar elementos se usan los métodos de comparación __eq__, __ne__,
__lt__, __le__, __gt__ y __ge__. Pero se suele considerar estos métodos
redundantes ya que basta con definir sólo dos (eg: __eq__ y __lt__) para
establecer una ordenación.
Como no hay una forma mejor, hemos creado el tipo genérico Ord enlazado con
int para que al menos el chequeador de tipos no se queje en la comparaciónes,
aunque no tiene porqué limitarse su aplicación a números enteros.
Números primos
Como caso práctico, veamos cómo se puede redefinir la clase Primes:
@final
class Primes(LazySortedSequence[Prime]):
def __init__(self):
super().__init__(self.__genprimes())
self._cache.extend([2, 3])
def __genprimes(self) -> Iterator[Prime]:
_primes = self._cache
start = 5
top = 1
while True:
stop = _primes[top] ** 2
for n in range(start, stop, 2):
for p in islice(_primes, 1, top):
if n % p == 0:
break
else:
yield n
start = stop + 2
top += 1
Si dejamos así la codificación, la clase Primes usará el método __contains__
de LazySortedSequence. Este método añadirá primos a la caché hasta alcanzar el
argumento solicitado.
Si recordamos de la implementación anterior que teníamos de la clase Primes,
el método __contains__() estaba optimizado para comprobar la pertencia de un
número, sin añadir más elementos a la caché. Vamos a recuperar esta codificación:
def __contains__(self, n: int) -> bool:
if n <= self.last:
return super().__contains__(n)
root = isqrt(n)
_primes = self._cache
top = self.size if root > self.last else self.insertpos(root)
if any(n % prime == 0 for prime in islice(_primes, 1, top)):
return False
# "one-shot" check
if any(n % i == 0 for i in range(self.last + 2, root + 1, 2)):
return False
return True
Serie Evaluación Perezosa en Python
- Parte 1 - Introducción a la evaluación perezosa
- Parte 2 - Secuencias infinitas
- Parte 3 - Memoización
- Parte 4 - Evaluación perezosa avanzada
- Parte 5 - Formalización de la Secuencia Perezosa
- Parte 6 - Ejemplo práctico: Potencias de Fermi-Dirac
- Apéndice: sobre el tipado de datos utilizado
La serie unificada como Jupyter Notebook en:
Apéndice: sobre el tipado de datos utilizado
Durante esta serie de artículos he procurado usar el tipado gradual de python, no sólo para mejorar la compresión, sino porque lo considero buena práctica para detectar algunos problemas en el momento de escribir el código. El intérprete de python realmente no realiza ningún chequeo de estas anotaciones de tipos, dejando por completo su comprobación a alguna otra herramienta que pueda estar usando el desarrollador.
He utilizado las clases abstractas del módulo collections.abc como base para
definir los iterables, secuencias e iteradores. He creído que así quedaba
mejor documentado, además de ser el modo más conocido por programadores de otros
lenguajes. Por derivar de la clase abstracta Sequence, sabemos que
GenericRange implementa varios métodos abstractos como son __len__ y
__getitem__.
Sin embargo, en python se considera supérfluo y poco recomendable este uso de clases abstractas. El modo pythónico consiste en implementar esos métodos sin más indicación. Sólo por el hecho de contar con estos métodos, nuestra clase ya será considerada como secuencia, se podrá usar donde haga falta una secuencia y, en definitiva, se comportará como si fuera una secuencia. Son los llamados duck types o tipos estructurales que tanto caracterizan a python y que, a partir de ahora, nos vamos a tener que acostumbrar a denominar Protocolos.
Por ejemplo, podíamos haber declarado la clase GenericRange sin indicar
ninguna superclase:
class GenericRange:
def __init__(self, start=0, stop=None, step=1) -> None:
...
def __len__(self) -> int:
...
def __getitem__(self, idx: Union[int, slice]) -> Union[int, "GenericRange"]:
...
Al tener el método __len__() se dice que cumple con el protocolo Sized,
algo que se puede comprobar del mismo modo que si fuera una subclase:
>>> from collections.abc import Sized
>>> issubclass(GenericRange, Sized)
True
En cambio, nos puede sorprender que no cumpla con el protocolo Sequence, a
pesar de que se comportaba como tal:
>>> from collections.abc import Sequence
>>> issubclass(GenericRange, Sequence)
False
Resulta que para cumplir con el protocolo Sequence, además de __getitem__(),
debe tener implementados los métodos __iter__(), __reversed__() e
index().
Cuando GenericRange derivaba de Sequence, estos métodos se heredaban de la
superclase como métodos mixin, para cuya implementación básica utiliza
únicamente el método __getitem__(). También implementa otros métodos como
__contains__() (Container) y count() (Countable). Ése era el motivo por
el que sólo hacía falta definir __getitem__() para que funcionara como secuencia.
Como protocolo, estos métodos no se adquieren por herencia y necesitan una implementación para cumplir con el protocolo Sequence. No obstante, algunas funciones, como reversed, admiten objetos con implementaciones parciales del protocolo Sequence, algo que únicamente sabremos si recurrimos a la documentación de la función.
Secuencia de enteros
He empleado el tipo Sequence sin indicar de qué tipo son los elementos. Un
chequeador de tipos asume que se trata de un iterable de elementos de tipo
Any, por lo que no debería dar problemas. Pero siempre podemos ser más
precisos y usar Sequence[int] como tipo de datos para nuestras secuencias de
números enteros.
Referencia forward
En la anotaciones de tipos, a veces necesitamos referenciar una clase antes de que esté definida, las conocidas como referencias forward de tipos. El modo normal de hacer este tipo de referencias es escribir el nombre de la clase entre comillas, como una string.
A partir de python 3.10 no hará falta acudir a este remedio pudiendo usar
referencias forward sin mayor problema. Para las versiones anteriores, se
puede obtener esta funcionalidad del módulo __future__:
from __future__ import annotations
Unión de tipos
En el método __getitem__() de GenericRange he utilizado dos uniones de tipos:
def __getitem__(self, idx: Union[int, slice]) -> Union[int, "GenericRange"]:
i = self._range[idx]
return self.getitem(i) if isinstance(i, int) else self.from_range(i)
La unión idx: Union[int, slice] se puede interpretar como que idx puede ser
de tipo int o de tipo slice. La notación común de expresar esta unión de
tipos en varios lenguajes sería idx: int | slice, nomenclatura que también
será aceptada en python 3.10.
La otra unión, Union[int, "GenericRange"] indica que el resultado será de tipo
int o de tipo GenericRange.
De todos modos, en estas anotaciones no se está reflejando la dependencia que
hay entre tipos. Si idx es entero, el resultado siempre será un entero. Si
idx es slice, el resultado siempre será GenericRange. En lenguajes con
tipado estático, es normal disponer de varias definiciones del mismo métodos,
con diferentes signaturas, que se seleccionan según sean los tipos de los
argumentos y resultados que tengamos.
Python tiene una facilidad para hacer algo similar. Con
functools.singledispathmethod podemos definir varios métodos que se invocarán
según el tipo de dato del primer argumento. De este modo, el método
__getitem__() lo podríamos expresar así:
from functools import singledispatchmethod
class GenericRange(Sequence):
...
@singledispatchmethod
def __getitem__(self, idx):
return NotImplemented
@__getitem__.register
def _(self, idx: int) -> int:
i = self._range[idx]
return self.getitem(i)
@__getitem__.register
def _(self, idx: slice) -> "GenericRange":
i = self._range[idx]
return self.from_range(i)
Lamentablemente nos saldrá un error ya que no existe aún la clase GenericRange
cuando es aplicado el decorador singledispatchmethod. Una solución es sacar el
último registro fuera, una vez que ya se ha definido la clase:
@GenericRange.__getitem__.register
def _(self, idx: slice) -> GenericRange:
i = self._range[idx]
return self.from_range(i)
Código final
Con estos cambios, tendríamos nuestro código corregido de esta manera:
from abc import abstractmethod
from collections.abc import Sequence
from typing import Type, Union
from functools import singledispatchmethod
from __future__ import annotations
class GenericRange(Sequence[int]):
def __init__(self, start=0, stop=None, step=1) -> None:
if stop is None:
start, stop = 0, start
self._range = range(start, stop, step)
@abstractmethod
def getitem(self, pos: int) -> int:
"""
Método abstracto.
Función para calcular un elemento a partir de la posición
"""
return pos
@classmethod
def from_range(cls: Type[GenericRange], rng: range) -> GenericRange:
"""
Constructor de un GenericRange a partir de un rango
"""
instance = cls()
instance._range = rng
return instance
def __len__(self) -> int:
return len(self._range)
@singledispatchmethod
def __getitem__(self, idx):
return NotImplemented
@__getitem__.register
def _(self, idx: int) -> int:
i = self._range[idx]
return self.getitem(i)
def __repr__(self) -> str:
classname = self.__class__.__name__
r = self._range
return f"{classname}({r.start}, {r.stop}, {r.step})"
@GenericRange.__getitem__.register
def _(self, idx: slice) -> GenericRange:
i = self._range[idx]
return self.from_range(i)
Conclusión
Python está realizando un gran esfuerzo en incorporar anotaciones de tipo sin perder con ello sus característicos tipos ducking. De igual modo, vamos a ver cómo se incorporan más elementos de otros lenguajes como las dataclasses, programación asíncrona o los patrones estructurales, aunque tardarán en ser adoptados por la mayor parte de programadores python.
Si algo tiene python es no tener demasiada prisa en que se apliquen sus cambios. Como decía un gran sabio: “Vamos a cambiarlo todo para que todo siga igual”.
Serie Evaluación Perezosa en Python
- Parte 1 - Introducción a la evaluación perezosa
- Parte 2 - Secuencias infinitas
- Parte 3 - Memoización
- Parte 4 - Evaluación perezosa avanzada
- Parte 5 - Formalización de la Secuencia Perezosa
- Parte 6 - Ejemplo práctico: Potencias de Fermi-Dirac
- Apéndice: sobre el tipado de datos utilizado
La serie unificada como Jupyter Notebook en:
Evaluación perezosa avanzada
Haskell tiene una librería, Data.Numbers.Primes, que ofrece tanto una
secuencia con todos los números primos, primes, como la función isprime con
la que chequear si un número es primo. Gracias a la evaluación perezosa,
haskell sólo calcula los elementos de primes que necesite.
Vamos a intentar hacer en python lo que hace sencillo haskell:
> take 100 primes
[2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53,59,61,67,71,73,79,83,89,97,101,103,
107,109,113,127,131,137,139,149,151,157,163,167,173,179,181,191,193,197,199,211,
223,227,229,233,239,241,251,257,263,269,271,277,281,283,293,307,311,313,317,331,
337,347,349,353,359,367,373,379,383,389,397,401,409,419,421,431,433,439,443,449,
457,461,463,467,479,487,491,499,503,509,521,523,541]
> primes!!90000
1159531
> isPrime (2^31-1)
True
Calculo de números primos
Por definición, un número primo sólo es divisible por 1 y por sí mismo:
Prime = int # un alias para números primos
def isprime(n: int) -> bool:
return not any(n % i == 0 for i in range(2, n))
def primes(to: int) -> list[Prime]:
return [i for i in range(2, to+1) if isprime(i)]
Podemos aplicar algunas optimizaciones a estos cálculos:
- Excepto el 2, podemos descartar como primos todos los números pares
- Al comprobar divisores de \(n\), basta con probar hasta \(\sqrt{n}\), y únicamente con aquellos que sean primos
Con estas premisas, podemos ir ya diseñando una estrategia para obtener una secuencia de primos por evaluación perezosa:
import sys
from collections.abc import Generator, Iterable
from itertools import islice
INFINITE = sys.maxsize # una aproximación 'mala' para infinito
Prime = int # un alias para números primos
# lista de números primos que vayamos obteniendo
primes: list[Prime] = [2, 3]
def isdivisible(n: int, divisors: Iterable[int]) -> bool:
"""
Comprobar si 'n' es divisible por
los elementos de un iterable ordenado
"""
divisible = False
for d in divisors:
if n % d == 0:
divisible = True
break
if d * d > n:
break
return divisible
def isprime(n: int) -> bool:
"""Comprobar si 'n' es un número primo"""
if n <= primes[-1]:
return n in primes
# probando primos como divisores
if isdivisible(n, primes):
return False
# seguir con el resto de números impares
start = primes[-1] + 2
return not isdivisible(n, range(start, n, 2))
def genprimes() -> Generator[Prime, None, None]:
"""Generador de números primos"""
start = primes[-1] + 2
for n in range(start, INFINITE, 2):
if not isdivisible(n, primes):
primes.append(n)
yield n
El generador genprimes nos dará un iterador con el que ir obteniendo los
números primos siguientes al último de la lista. A medida que obtiene un primo,
se añade a la lista primes.
La lista primes actua como caché de los números primos obtenidos y la
empleará isprime para sus comprobaciones. Si isprime se queda sin primos,
continua con los siguientes números impares hasta obtener un resultado, sin
pararse a calcular los primos intermedios.
Secuencia de números primos
Vistas estas funciones vamos a armar con ellas la estructura de una clase
secuencia. isprime pasará a ser el método __contains__ y el generador
genprimes lo usaremos para ampliar automáticamente la lista de números primos
según sea necesario:
import sys
from collections.abc import Generator, Iterable
from itertools import islice
from typing import Union
INFINITE = sys.maxsize # una mala aproximación de infinito
Prime = int # un alias para los primos
def isdivisible(n: int, divisors: Iterable[int]) -> bool:
"""
Comprobar si 'n' es divisible por
los elementos de un iterable ordenado
"""
divisible = False
for d in divisors:
if n % d == 0:
divisible = True
break
if d * d > n:
break
return divisible
def nth(it: Iterable, n: int):
"""Obtener de un iterable el elemento en la posición 'n'"""
return next(islice(it, n, None))
class Primes:
"""
Collection of primes numbers
"""
def __init__(self):
self._primes: list[Prime] = [2, 3]
@property
def last(self) -> Prime:
return self._primes[-1]
@property
def size(self) -> int:
return len(self._primes)
def __len__(self) -> int:
return INFINITE
def __contains__(self, n: int) -> bool:
"""Comprobar si 'n' es un número primo"""
if n <= self.last:
return n in self._primes
# probando primos como divisores
if isdivisible(n, self._primes):
return False
# seguir con el resto de números impares
start = self.last + 2
return not isdivisible(n, range(start, n, 2))
def genprimes(self) -> Generator[Prime, None, None]:
"""Generador de números primos"""
start = self.last + 2
for n in range(start, INFINITE, 2):
if not isdivisible(n, self._primes):
self._primes.append(n)
yield n
def __getitem__(self, idx: Union[int, slice]) -> Prime:
if isinstance(idx, int):
if idx < 0:
raise OverflowError
return (
self._primes[idx]
if idx < self.size
else nth(self.genprimes(), idx - self.size)
)
else:
rng = range(INFINITE)[idx]
return [self[i] for i in rng]
# Secuencia de los números primos
primes = Primes()
isprime = primes.__contains__
Como infinito se usa sys.maxsize que es el mayor tamaño que puede tener una
lista para la versión CPython. Si tratamos de usar índices mayores para una
lista nos dará error.
Cuando se solicita un número primo que no está en la lista, el método
__getitem__ invoca automáticamente al iterador que devuelve genprimes hasta
alcanzarlo. A medida que se descubren números primos, se val almacenando para su
posterior uso.
Pruebas de uso:
>>> from primes import primes, isprime
>>> print(primes[:100])
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73,
79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151, 157,
163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229, 233, 239, 241,
251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317, 331, 337, 347,
349, 353, 359, 367, 373, 379, 383, 389, 397, 401, 409, 419, 421, 431, 433, 439,
443, 449, 457, 461, 463, 467, 479, 487, 491, 499, 503, 509, 521, 523, 541]
>>> primes[90000]
1159531
>>> isprime(2**31-1)
True
>>> (2**31-1) in primes._primes
False
>>> primes.last
1159531
Para cumplir con el protocolo Sequence podemos añadir los métodos que nos
faltan, cosa que animo hacer al lector. El método count() es trivial: si es
primo, habrá 1 ocurrencia; si no es primo, 0 ocurrencias. El método index() es
algo más complicado. En cambio el _reversed__() es imposible ya que no se
puede invertir una secuencia infinta. A pesar de ello, la clase Prime se
comportará casi como una secuencia siempre y cuando no itentemos acceder a la
secuencia por el final.
Más optimizaciones
Bisecciones
La lista de primos que vamos generando siempre será una lista ordenada, por lo
que se pueden optimizar mucho las búsquedas usando bisecciones, para lo que
tenemos el módulo bisect (\(O(\log{n})\) en lugar de \(O(n)\)).
Por ejemplo, para comprobar si un elemento está en una lista ordenada:
from bisect import bisect_left
def bs_contains(lst: list, x) -> bool:
idx = bisect_left(lst, x)
return idx < len(lst) and lst[idx] == x
Programación dinámica
En el generador de números primos podemos observar que se están comprobando los
cuadrados de los divisores más veces de las necesarias. Podemos delimitar rangos
en los que se van a usar los mismos divisores. Por ejemplo, si tenemos la
secuencia [2, 3] como divisores podemos chequear números hasta el 23. Para
seguir con el 25 tenemos que añadir un primo más, [2, 3, 5] con los que ya
podemos chequear hasta el 47. Y así sucesivamente. El rango range(start,
INFINITE, 2) lo podemos fraccionar según el grupo de primos que emplearemos
como divisores.
La programación dinámica tiene sus riesgos y es bastante fácil que no funcione bien a la primera, pero mejoran mucho la eficiencia de un algoritmo.
Multiproceso
Como opción de mejora está el uso de técnicas de concurrencia y multiproceso. Como primera medida que podemos pensar sería crear varios workers que chequeen en paralelo la divisibilidad para chequear varios números a la vez. El problema es que estos workers tendrían que tener su copia de la lista de primos y actualizarla conforme se obtenien, algo que es sumamente costoso y poco eficiente.
Una estrategia mejor sería especializar cada worker en un subconjunto de números primos de modo que todos los workers intervengan colaborativamente en el chequeo del mismo número.
En concurrencia, hay muchas estrategias posibles y ninguna mejor. Al final, cada problema tiene su solución particular que no sirve como solución general.
Código final optimizado
El código final optimizado, sin usar concurrencia, se puede obtener del siguiente enlace:
Descarga
Por hacernos una idea, esta sería la comparativa de tiempos de la versiones haskell y python:
| operación | haskell | python | python opt |
|---|---|---|---|
| primo 90000 | 310ms | 1450ms | 860ms |
| es primo \(2^{31}-1\) | 20ms | 10ms | 3ms |
| index 1159531 | 240ms | N/A | 820ms |
Serie Evaluación Perezosa en Python
- Parte 1 - Introducción a la evaluación perezosa
- Parte 2 - Secuencias infinitas
- Parte 3 - Memoización
- Parte 4 - Evaluación perezosa avanzada
- Parte 5 - Formalización de la Secuencia Perezosa
- Parte 6 - Ejemplo práctico: Potencias de Fermi-Dirac
- Apéndice: sobre el tipado de datos utilizado
La serie unificada como Jupyter Notebook en:
Cachés y Memoización
En el pasado artículo vimos que para obtener un elemento de la sucesión fibonacci necesitábamos calcular los anteriores. Veámoslo con más detalle.
Podemos definir la siguiente función para obtener un elemento de esta sucesión:
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n-2)
Esta función tiene un terrible problema de eficacia, puesto que se llama a sí
misma demasiadas veces para calcular el mismo elemento. Por ejemplo, para
calcular fib(10) llama una vez a fib(9) y a fib(8), pero para calcular
fib(9) también llama a fib(8). Si sumamos todas las llamadas, habrá
necesitado llamar:
fib(9)1 vezfib(8)2 vecesfib(7)3 vecesfib(6)5 vecesfib(5)8 vecesfib(4)13 vecesfib(3)21 vecesfib(2)34 vecesfib(1)55 vecesfib(0)34 veces
Para elementos mayores, todavía serán más las llamadas que se habrán repetido.
Un mejora nos la da la propia documentación de python como aplicación de la
función functools.lru_cache:
from functools import lru_cache
@lru_cache(maxsize=None)
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n-2)
Básicamente, lru_cache es un decorador que detecta los argumentos que se
pasa a una función y guarda en un caché el resultado que devuelve. Un caché
LRU (Least Recently Used ) tiene la estrategia de eliminar de la caché los
elementos que hayan sido menos utilizados recientemente. En este caso, con
maxsize=None no se impone ningún límite de tamaño, por lo que guardará todos
los elementos de la caché 1.
A este proceso de guardar los resultados de una evaluación en función de los argumentos de entrada se conoce por “memoize” o “memoización”, y es fundamental para la evaluación perezosa.
Podemos obtener información de la caché:
>>> fib(10)
>>> fib.cache_info()
CacheInfo(hits=8, misses=11, maxsize=None, currsize=11)
Nos dice que la caché tiene 11 elementos (la serie de fib(0) a fib(10)), que
ha fallado 11 veces, una por elemento de la sucesión, pero sí que ha acertado 8.
Una importante mejora de como lo teníamos antes.
Aún así, en python tenemos limitado el número de llamadas recursivas que se pueden hacer, que suele estar en torno a unas 3000 llamadas recursivas 2:
>>> fib(10000)
...
RecursionError: maximum recursion depth exceeded in comparison
Para no tener este problema, en la documentación hacen el truco de ir visitando en orden todos los elementos de la sucesión hasta llegar al que queremos.
>>> [fib(n) for n in range(16)]
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610]
Con este truco se instruye a la caché con todos los elementos de la sucesión hasta llegar al que queremos. Para el cálculo de un elemento sólo se necesitarán los dos elementos anteriores de la sucesión, que ya tendremos en la caché, lo que evita múltiples llamadas recursivas.
Con este mismo propósito, podemos probar a calcular el elemento 10000 aplicando las técnicas ya aprendidas hasta ahora:
from itertools import count, islice
from functools import lru_cache
ℕ = count(0)
suc_fib = (fib(n) for n in ℕ)
fib10k = next(islice(suc_fib, 10000, None))
Esta gestión de la caché es totalmente opaca para nosotros. Si pudiéramos acceder a ella sería un modo de obtener la sucesión de fibonacci hasta el mayor elemento que se haya calculado.
Vamos a itentar crear una caché similar capaz de generar automáticamente los elementos de la sucesión:
def fibcache(f):
cache = []
def wrap(n):
for i in range(len(cache), n + 1):
cache.append(f(i))
return cache[n]
wrap.cache = cache
return wrap
@fibcache
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n-2)
Hemos creado el decorador, fibcache que añade una caché a la función que
decora. Al hacer la llamada fib(n), este decorador se asegura que todos los
elementos anteriores de la sucesión estén en la caché. La caché es accesible
mediante el atributo fib.cache, que no será otra cosa que la sucesión de fibonacci.
>>> fib(10000)
3364476487643178326662161200510754331030214846068006390656476997468008144216....
...
>>> fib.cache[10000]
3364476487643178326662161200510754331030214846068006390656476997468008144216....
...
Lo genial de esta estrategia es que sólo calculamos los mínimos elementos necesarios para obtener el resultado buscado, algo que es el fundamento de lo que conocemos por evaluación perezosa.
Resumen
Aplicando técnicas de memoización, hemos conseguido que una función recursiva almacene los cálculos que hace para así evitar repetirlos, con lo que es posible reducir los niveles de recursividad.
Con un decorador, hemos asociado una caché a una función que se rellena automáticamente, y en orden, con los resultados intermedios hasta llegar al resultado solicitado. Esta caché será una sucesión ordenada de resultados, que crece a medida que se necesite.
A este proceso de realizar cálculos según sea necesario es lo que conocemos por Evaluación Perezosa.
Serie Evaluación Perezosa en Python
- Parte 1 - Introducción a la evaluación perezosa
- Parte 2 - Secuencias infinitas
- Parte 3 - Memoización
- Parte 4 - Evaluación perezosa avanzada
- Parte 5 - Formalización de la Secuencia Perezosa
- Parte 6 - Ejemplo práctico: Potencias de Fermi-Dirac
- Apéndice: sobre el tipado de datos utilizado
La serie unificada como Jupyter Notebook en:
ANOTACIONES:
-
Existe un decorador equivalente,
functools.cache, que también sirve para crear cachés sin límite, pero no contabiliza el número de aciertos. ↩ -
El límite de llamadas recursivas se obtiene con la función
sys.getrecursionlimit()y se podría alterar consys.setrecursionlimit, aunque no es recomendable. ↩
Algunas definiciones
Puede ser interesante dejar claras algunas definiciones para distinguir entre iteradores e iterables (se pueden ver las definiciones completas en el glosario de python):
- Iterable
- cualquier objeto capaz de devolver sus miembros de uno en uno
- Iterador
- iterable que representa un flujo de datos, cuyos elementos se
- obtienen uno detrás de otro
- Secuencia
- iterable con acceso eficiente a sus elementos mediante un índice entero
- Generador
- función que devuelve un iterador
- Expresión generadora
- expresión que devuelve un iterador
Lo importante a tener en cuenta es que tenemos dos grandes grupos de iterables: los iteradores y las secuencias.
Los elementos de una secuencia son accesibles por su posición, mientras que los elementos de un iterador sólo se pueden acceder en serie. Iterable sería el concepto más general que englobaría ambos términos.
En el resto del artículo hablaremos de “secuencias” como término matemático, aunque su implementación podría corresponder con cualquier iterable de los mencionados.
Secuencias infinitas
En python, para crear secuencias infinitas se suelen usar generadores. Por ejemplo, para obtener la secuencia de Números Naturales se podría hacer así:
from collections.abc import Iterable
def ℕ() -> Iterable[int]:
n = 0
while 1:
yield n
n += 1
No podemos tratar las secuencias infinitas del mismo modo que con una lista. Necesitamos las funciones del módulo itertools capaces de operar con iteradores para pasar a una lista en el momento que realmente la necesitemos. Al final de la documentación del módulo se incluyen algunas recetas que dan idea de lo que pueden hacer.
Por ejemplo, podríamos redefinir la secuencia de número naturales con
itertools.count:
from itertools import count
ℕ = count(0)
Para obtener los primeros 100 números naturales
from itertools import islice
print(list(islice(ℕ, 100)))
[100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199]
Emular la función enumerate:
from collections.abc import Iterable, Iterator
def enumerate(it: Iterable) -> Iterator:
ℕ = count(0)
return zip(ℕ, it)
¿Y si quisiéramos obtener la lista de cuadrados en el intérvalo [100, 200).
Veamos (NO PROBAR):
ℕ = count(0)
cuadrados = (n**2 for n in ℕ)
res = [x for x in cuadrados if 100<=x<200]
Si probabos es posible que se quede en un bucle infinito. Necesita comprobar todos los elementos, por lo que se pondrá a calcular todos lo elementos de la sucesión para ver si cumplen la condición.
Como sabemos que la sucesión de cuadrados es creciente, podemos pararla en el momento que se salga de límites:
from itertools import dropwhile, takewhile
ℕ = count(0)
cuadrados = (n ** 2 for n in ℕ)
mayores_100 = dropwhile(lambda x: x < 100, cuadrados)
menores_200 = takewhile(lambda x: x <= 200, mayores_100)
res = list(menores_200)
En definitiva, hemos encadenado varias funciones hasta conseguir el iterador que necesitábamos. En programación funcional, a este encadenado de funciones se denomina como composición de funciones y es bastante utilizado. Lamentablemente, en python no existe este tipo de operaciones.
Ejemplo: sucesión de Fibonacci
La sucesión de Fibonacci se define de la siguiente manera:
$$f_0=1$$
$$f_1=1$$
$$f_n = f_{n-1} + f_{n-2}$$
Operando, podemos obtener la sencuencia:
1
1
1+1 -> 2
1+2 -> 3
2+3 -> 5
...
La lista de los 20 primeros:
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765]
Un modo simple de construir la serie es usar un generador:
from collections.abc import Iterator
from itertools import islice
def fib() -> Iterator[int]:
a, b = 1, 1
while True:
yield a
a, b = b, a+b
# primeros 20 elementos
print(list(islice(fib(), 20)))
Para obtener un elemento en una posición dada tenemos que consumir el iterador, elemento a elemento, hasta llegar a la posición que queremos.
Por ejemplo, para obtener el elemento de la posición 1000:
>>> next(islice(fib(), 1000, None))
70330367711422815821835254877183549770181269836358732742604905087154537118196933
57974224949456261173348775044924176599108818636326545022364710601205337412127386
7339111198139373125598767690091902245245323403501
Ha sido necesario calcular todos los elementos anteriores hasta llegar al que deseamos, algo que hay que repetir para cada uno de los elementos que queramos extraer.
Afortunadamente, la sucesión de fibonacci tiene elemento genérico que se expresa en función de el número áureo \(\varphi\) y que tiene la siguiente formulación:
$$\varphi ={\frac {1+{\sqrt {5}}}{2}}$$
Usando el número áureo, un elemento de la serie fibonacci se puede calcular con la siguiente fórmula de Édouard Lucas,:
$$f_n=\frac{\varphi^n-\left(1-\varphi\right)^{n}}{\sqrt5}$$
Que podemos ajustar el redondeo y expresar como:
$$f_{n}=\operatorname {int} \left({\frac {\varphi ^{n}}{\sqrt {5}}}+{\frac {1}{2}}\right)$$
Así pues, podemos echar mano de la secuencia GenericRange que vimos en el
artículo anterior para definir una secuencia para fibonacci:
class FibRange(GenericRange):
def getitem(self, n):
sqrt5 = 5**(1/2)
φ = (1 + sqrt5) / 2
return int(φ**n/sqrt5 + 1/2)
>>> list(FibRange(100,110))
[354224848179263111168,
573147844013818970112,
927372692193082081280,
1500520536206901248000,
2427893228399983329280,
3928413764606884839424,
6356306993006868692992,
10284720757613753532416,
16641027750620622225408,
26925748508234379952128]
Lamentablemente, aunque al final se obtenga un número entero, para hacer el cálculo hemos recurrido al cálculo numérico de coma flotante, lo que produce desbordamiento cuando trabajamos con números grandes. Tenemos que buscar otros métodos para mantenernos en el dominio de los número enteros. Pero lo dejaremos ya para el próximo artículo, donde veremos las memoizaciones o el modo de guardar los resultados de un función para evitar repetir el mismo cálculo cuando se vuelva a necesitar.
Resumen
Las secuencias numéricas se pueden expresar en forma de iterables, de las que
tenemos dos tipos: iteradores y secuencias.
Normalmente en python, para trabajar con secuencias infinitas se usan
iteradores. Para poder manejar estos iteradores se usan las funciones del módulo
itertools que podemos combinar para obtener como resultado un iterable que ya
podemos manejar mejor.
Si la secuencia tiene definido un elemento genérico, entonces podemos utilizar los rangos que ya habíamos visto anteriormente para crear la secuencia infinita.
Serie Evaluación Perezosa en Python
- Parte 1 - Introducción a la evaluación perezosa
- Parte 2 - Secuencias infinitas
- Parte 3 - Memoización
- Parte 4 - Evaluación perezosa avanzada
- Parte 5 - Formalización de la Secuencia Perezosa
- Parte 6 - Ejemplo práctico: Potencias de Fermi-Dirac
- Apéndice: sobre el tipado de datos utilizado
La serie unificada como Jupyter Notebook en:

HTML sobre WebSockets
Programador Web Valencia 14 03 2021
La forma tradicional de conseguir una SPA (Single-page Application) es dividir las responsabilidades, el Back-End sirve la información y el Front-End la dibuja dinámicamente. Tristemente implica un doble esfuerzo en el desarrollo siendo necesario la creación de 2 aplicaciones con tecnologías diferentes aumentando costes e involucrando a dos perfiles especializados. Aunque, por supuesto, es el precio que debemos pagar si queremos una web en tiempo real y que se renderice en un pestañeo. ¿O hay una alternativa? ¿Con incluso mejor rendimiento? Así es, y además es más fácil de desarrollar al trabajar con un solo lenguaje. Esta arquitectura se denomina: HTML sobre WebSockets.
Chris McCord, creador de Phoenix (el Framework más popular dentro del ecosistema Elixir), presentó en ElixirConf 2019 una tecnología llamada LiveView. En apenas 15 minutos creó un clon de Twitter que funcionaba en tiempo real sin necesidad de incorporar JavaScript renderizador o un framework popular (React, Angular, Vue…) que gestione la Vista, demostrando que era posible quedarse en el Back-End y lograr productividad con una dulce aroma a buen rendimiento. Desde entonces se ha popularizado esta solución, inspirado a otros desarrolladores para crear implementaciones de HTML sobre WebSockets en otros lenguajes. Se puede volver al Back-End pero sin renunciar a lo bueno del Front-End.
¿Cómo funciona?
Disclamer: ¡si se usa JavaScript! Su labor no es renderizar sino crear un canal de comunicación con WebSockets y situar el HTML recibido en el lugar adecuado. Además de otras tareas secundarias como animaciones, gestión de eventos, etc.
La solución de McCord es no enviar al Front-End un JSON, sino HTML que no necesite ser preprocesado. De ese modo trasladamos la carga del dibujado, y toda su lógica, al Back-End. Ya pero… ¿Cómo hacemos que el servidor nos envíe nuevo contenido de forma inmediata y sin realizar una petición? Sencillo: con WebSockets.
Repasemos el sistema tradicional de la introducción. Desde la Web hago una petición HTTP, el navegador inicia la acción, obteniendo en la respuesta un JSON con toda la información en crudo. Lo siguiente es interpretar y crear el HTML correspondiente.

Mientras que HTML sobre WebSockets puede ser el envío de un JSON donde se devuelve HTML/CSS/JS. O incluso puede quitar el propio envío quedando a la escucha.

Veamos el ejemplo donde se renderiza el artículo número 2 de un blog.
1. Conectamos
Partimos con una conexión. Ya hay un tubo de comunicación entre cliente y servidor.

2. Petición de componente
El cliente pide el contenido de la ruta “/articulo/2/” a través del canal.

3. Recepción de HTML/CSS/JS
El servidor genera el HTML/CSS/JS, usando el sistema de plantillas del Back-End, y lo devuelve por el canal.

4. Impresión
Por último, el Front-End lo sitúa en el lugar adecuado o asignado.
¿Dónde puedo ver una demostración?
He creado un prototipo en Django de un Blog con 100 entradas, cada artículo esta relacionado con sus respectivos comentarios. Además existe un apartado para visualizar el artículo completo, un paginador y una sección estática con algunos párrafos.
Aquí puedes ver como los cambios son reflejados en todos los clientes.
Si observáis la url, nunca se cambia de página, y… ¡aun así funciona! ¿Quieres probarlo por ti mismo? Tienes la posibilidad de levantarlo a partir del código fuente en GitHub, esta Docketizado a un comando de distancia para arrancarlo.
¿Cuáles son sus ventajas?
- Solo hay un motor de renderizado, simplificando la tarea.
- Real-time, los clientes reciben los cambios tan rápido como sea posible.
- El protocolo WebSockets es más rápido que HTTP. Fuente: starkoveflow
- Apropiado para conexiones lentas. Fuente: browsee.
- Crear un SPA sin apenas JavaScript.
- Excelente SEO, los motores de búsqueda adorarán la página al encontrarse solo HTML.
¿Cuáles son sus inconvenientes?
- El servidor necesitará más recursos al tener que dejar un WebSocket abierto por cliente.
- Poca documentación al respecto.
- Pocos frameworks.
¿Qué Frameworks existen?
Puedes empezar por los siguientes recursos.
- Elixir/Phoenix: LiveView.
- Python/Django: Sockpuppet y Reactor.
- C#/.NET: Blazor Server.
- JavaScript: Turbo con Stimulus
Apuntes finales
No creo que sea la solución definitiva, pero merece ser escuchada. Es llamativo su creciendo adopción y herramientas que están apareciendo. A nivel personal se sorprendió lo poco conocido que es, posiblemente a causa del poderoso ecosistema de JavaScript. Sin embargo es todo un placer no estar en la carrera de fondo que supone el Front-End para no quedarte desactualizado, y centrarte en el lenguaje de servidor.
En serio, ¿qué puedes perder por probarlo?
Recientemente freeCodeCamp, una de las comunidades de aprendizaje tecnológico más importantes en internet, anunció las versiones en español y en chino de sus contenidos. Este anuncio fue recibido con entusiasmo entre el público hispanohablante, ya que freeCodeCamp es un recurso imprescindible para aprender desarrollo web. Gracias a sus contenidos cada día miles de personas en todo el mundo pueden aprender de manera abierta y sin coste, habilidades relacionadas con las tecnologías de internet y conocimientos técnicos.
Para hablar sobre esta iniciativa de freeCodeCamp, por indicación del propio fundador Quincy Larson, invitamos al podcast a Rafael Hernández, coordinador desde Los Ángeles, del equipo encargado de la comunidad hispanohablante. Con Rafael discutimos entre otras cosas:
- El origen de freeCodeCamp y sus principales objetivos.
- Las perspectivas con respecto al idioma español y a otros idiomas en la comunidad de freeCodeCamp.
- Requisitos y solicitudes para participar como voluntario.
- El trabajo de los voluntarios y su coordinación.
- Financiación de freeCodeCamp y formas de donación.
- Certificaciones de freeCodeCamp y valoraciones a nivel profesional.
- Colaboraciones con empresas tecnológicas y acuerdos de colaboración.
- Edición y gestión de contenidos.
- Futuro y acciones próximas de freeCodeCamp.
En esta charla Rafael Hernández nos cuenta cosas muy relevantes sobre la organización de esta comunidad. Desde su propia historia y la de Quincy Larson, además también de todo lo relacionado con los contenidos y la dirección estratégica de freeCodeCamp en la parte de idiomas.
Agradecer la atención y la disponibilidad de Rafael y Quincy para realizar esta entrevista. Os animamos a visitar los enlaces que nos deja Rafael y a participar en la comunidad de aprendizaje en línea de freeCodeCamp. Por último, animar a todo el mundo a crear contenidos en español o a colaborar con el proyecto con alguna aportación económica.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
![]()
Innovation has been part of Microsoft Edge since day one, whether you’re seamlessly accessing corporate apps online for work or saving money shopping with built-in coupons. As contributors to the Chromium project, we look forward to Serving our customers more effectively with new release cycles for Microsoft Edge appeared first on Microsoft Edge Blog.
Evercade, Codemasters and The Oliver Twins are delighted to share the news of the first donation to the National Videogame Museum. Following the launch of The Oliver Twins Collection cartridge, exclusively for the Evercade Retro Gaming console, it was announced that all profits from this would be donated to the National Videogame Museum in Sheffield.... View Article
The post Evercade and The Oliver Twins raise over £11.000 for the National Videogame Museum appeared first on Evercade.
![]()
Nueva edición de Informe Nube con David Vaquero y Antony Goetzschel. Un episodio dedicado a repasar una colección de noticias recientes sobre las tecnologías cloud, hardware y sistemas.
Entre las noticias:
- 00:03:28 Google Cloud pierde mucha pasta
- 00:13:38 Filtración masiva de contraseñas
- 00:29:12 Precios de los Threadripper Pro y placas base
- 00:52:08 Hackean el dominio de Perl
- 00:57:42 RoadMap de Rocky Linux
- 01:09:53 Almalinux 8.3 beta 1
- 01:13:29 Liberado Longhorn 1.1
- 01:17:43 Comparativa Backups en la nube
- 01:20:07 Rapid API
- 01:22:52 Remotive.io
- 01:31:11 Despedida
Os recordamos que los episodios de Informe Nube también están disponibles en su formato original de vídeo, en el canal de YouTube de Cursos de desarrollo.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
![]()
Our new modern browser, Microsoft Edge, debuted over a year ago and today can be found on hundreds of millions of devices. Last August, Microsoft Edge Legacy desktop application support ends today appeared first on Microsoft Edge Blog.

Masochism
MonkeyUser 09 03 2021
Phil Libin: Find a new way to ski
tonsky.me 09 03 2021
Quick starting is a bendy road
Manuel Uberti 08 03 2021
After more than a year with straight as my package manager, recently I have decided to sit down and look closely at how I handle my Emacs packages.
For all the interesting design choices and splendid documentation straight
offers, I have never used neither its version freezing capabilities nor the
chances to edit the source code of a package to try possible fixes before
sending patches upstream. Two reasons, mainly:
- I update my packages on a daily basis, accepting the risk of breakages in order to signal them to the maintainers and offer some help;
- when I want to send a patch, I have the source code of the package I am working on outside of my Emacs configuration to avoid leaving something messy around.
These are not issues with straight, of course. It all depends on what one needs
from their package manager.
One of the major benefits that straight brought to my setup is a boost in
startup speed. However, why don’t give package-quickstart a try? Setting
package-quickstart to t instructs package.el to pre-compute an autoload
file so that the activation of packages can be done much faster, resulting in a
faster startup1. And indeed it does, resulting in more or less the same 0.4
seconds that I was getting with straight.
One thing to be aware of is that, as the documention of package-quickstart
suggests, “the use of ‘package-quickstart-refresh’ every time the activation
need to be changed, such as when ‘package-load-list’ is modified” is required.
Hence, I added an :after-while advice to package-menu-execute (bound to
x in Package Menu) to make sure package-quickstart-refresh is run
after every upgrade.
Again, mine is not an argument against straight. It’s still a great package
manager and a fantastic alternative to the built-in package.el. However, these
days my Emacs interactions do not need the fine-grained control straight
provides.
Notes
-
See the relevant commit. ↩
Quick starting is a bendy road
Manuel Uberti 08 03 2021
After more than a year with straight as my package manager, recently I have decided to sit down and look closely at how I handle my Emacs packages.
For all the interesting design choices and splendid documentation straight
offers, I have never used neither its version freezing capabilities nor the
chances to edit the source code of a package to try possible fixes before
sending patches upstream. Two reasons, mainly:
- I update my packages on a daily basis, accepting the risk of breakages in order to signal them to the maintainers and offer some help;
- when I want to send a patch, I have the source code of the package I am working on outside of my Emacs configuration to avoid leaving something messy around.
These are not issues with straight, of course. It all depends on what one needs
from their package manager.
One of the major benefits that straight brought to my setup is a boost in
startup speed. However, why don’t give package-quickstart a try? Setting
package-quickstart to t instructs package.el to pre-compute an autoload
file so that the activation of packages can be done much faster, resulting in a
faster startup1. And indeed it does, resulting in more or less the same 0.4
seconds that I was getting with straight.
One thing to be aware of is that, as the documention of package-quickstart
suggests, “the use of ‘package-quickstart-refresh’ every time the activation
need to be changed, such as when ‘package-load-list’ is modified” is required.
Hence, I added an :after-while advice to package-menu-execute (bound to
x in Package Menu) to make sure package-quickstart-refresh is run
after every upgrade.
Again, mine is not an argument against straight. It’s still a great package
manager and a fantastic alternative to the built-in package.el. However, these
days my Emacs interactions do not need the fine-grained control straight
provides.
Notes
-
See the relevant commit. ↩
How the ARPANET Protocols Worked
Two-Bit History 08 03 2021
Justo después de un año desde su participación en otro episodio del podcast, volvemos a hablar con Néstor Angulo de Ugarte. En esta ocasión aprovechamos la sección de seguridad del informe de O’Reilly Media para tratar sobre las amenazas de seguridad en internet, hablamos también de WAF (Web Application Firewall), de educación sobre ciberseguridad y también sobre su trabajo diario en GoDaddy defendiendo aplicaciones y sitios web.
Néstor Angulo es un profesional de la seguridad muy interesado en todo lo relativo a la tecnología. Ofrece charlas con frecuencia sobre seguridad informática y trabaja de manera diaria solucionando problemas de seguridad en sitios web.
Con Néstor hablamos también de certificación en seguridad, discutimos sobre privacidad en internet y sobre hacking ético. Como siempre un auténtico gusto poder compartir con él un rato en este podcast.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
![]()
Note: We’re in the process of deploying features mentioned in this post, starting with Stable 89, so it might be a little while before you see them in your channel and build.
Nowadays, it’s not unusual
The post Microsoft Edge 89: Delivering improved browser performance to get the job done appeared first on Microsoft Edge Blog.
Clojure 1.10.3 release
Clojure News 04 03 2021
Clojure 1.10.3 is a small release with the following changes:
-
Reverted the case error message change from 1.10.2 due to backwards compatibility concerns
-
Added prepl support for reader conditionals
Detailed changelog
See the change log for a complete list of all changes in Clojure 1.10.3.
Terraform en Amazon Web Services
República Web 03 03 2021
David Vaquero y Antony Goetzschel vuelven con su Informe Nube, con una sesión completa sobre Terraform en Amazon Web Services. En este extenso episodio nos cuentan todo lo que debes tener en cuenta para gestionar Terraform en AWS. Explican conceptos básicos como son la gestión de credenciales, la creación de buckets S3, conocer las VPC (redes privadas virtuales en la nube) y el servicio de gestión DNS de AWS Route 53.
Esta primera parte ofrece una buena base para tratar Terraform sobre la tecnología de Amazon Web Services. Recuerda que este episodio es una versión en audio de los vídeos disponibles en el canal de YouTube de Cursos de Desarrollo.
Contenidos del episodio:
00:00:00 Intro
00:00:11 Sumario
00:03:06 Credencias IAM a AWS
00:16:57 Creación de un Bucket S3
00:19:08 Explicación VPC en AWS
00:25:24 Route 53
00:27:49 Seguimos con Bucket S3
00:42:07 Terraform con AWS y S3
00:59:30 Creación de la VPC
01:24:18 Security Groups y Reglas de red
01:29:33 Definición máquina EC2
01:42:07 Manejo de user_data
01:48:11 Alta disponibilidad
01:54:34 Volumen compartido EFS
02:09:14 Fe de Erratas
02:11:08 Despedida y novedades
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Exciting New Features in Django 3.2
Haki Benita 02 03 2021
Django 3.2 is just around the corner and it's packed with new features. Django versions are usually not that exciting (it's a good thing!), but this time many features were added to the ORM, so I find it especially interesting!
Una cosa que está clara y es que para hacer SEO necesitas hacerte con herramientas que te ayuden en la tarea de recopilar datos para analizar y medir resultados, entre otras funciones.
The post La importancia de elegir una herramienta SEO adecuada appeared first on No sin mis cookies.
![]()
There are a near infinite number of sites that have launched that you've never heard about. This is likely one of them. But if not for poor timing, it may have been primed for success.
The post The Most Ill-Timed Website in History appeared first on The History of the Web.

Promotion
MonkeyUser 02 03 2021
These are some things I commonly use in my elixir development workflow that might be interesting for someone.
Managing multiple versions of elixir and erlang
When you have to work in more than one project at time that could probably means you have to handle different elixir and erlang versions so installing the default version that your OS provides won't be helpful. Here is where asdf shines to solves this problem, asdf allow us to have different versions of elixir, erlang and other languages in the same machine so we can easily switch between them.
In macOS you can install it with brew install asdf and then follow the instructions that the installer prints out to set up the PATH, more info in its Github page https://github.com/asdf-vm/asdf
Now we have asdf installed we need to install the plugins to handle erlang and elixir, we can install them with:
asdf plugin add erlang
asdf plugin add elixirOnce we have those installed we need to define which versions we're going to use in our project, there is more than one way to do that:
Using environment variables
We can set up the required versions by defining environment variables with the ASDF_ prefix so if we need version elixir 1.10 we need to define the variable ASDF_ELIXIR_VERSION with the value 1.10 the same applies for erlang or other programming languages as well.
For example we can define variables for elixir and erlang as the example below:
export ASDF_ELIXIR_VERSION=1.10.3-otp-22
export ASDF_ERLANG_VERSION=22.3To handle environment variables in a easy way we can use direnv, it allows to define environment variables in a file
.envrcand it will loaded automatically as soon as we enter to out project folder.
File based config file
asdf allow us to define a .tool-versions file where we can put all the versions needed for our project, we can define one as the example below:
erlang 23.0.2
elixir 1.10.4-otp-23Creating a new project
Because we have first to define the versions used in a project we can't just run mix new my_app because asdf doesn't know yet which versions we want. To do this we have 2 options:
-
Define global versions of elixir and erlang using for example
asdf global elixir 1.9.0and the same for erlangasdf global erlang 22.3and then we can executemix new my_appnormally -
Define the versions just for the
mix newcommand execution, for exampleASDF_ELIXIR_VERSION=1.9.0 ASDF_ERLANG_VERSION=22.3 mix new my_app, this way we don't affect the global scope and then we can define these same versions inside the created project.
I like the second one because I don't have to change the global version each time I want to create a new project and I can easily access to that command from bash history.
Notes about erlang compilation
asdf uses kerl under the hood to handle erlang compilation and when we are installing a new version it will ask for a java installation 😕, to avoid this behaviour we can define the following environment variable:
export KERL_CONFIGURE_OPTIONS="--disable-debug --without-javac"Ecto database url
If we are dealing with databases in our project we will probably be using Ecto. And Ecto allow us to define database credentials in two ways, the first one is define them separately as the example below:
config :my_app, Repo,
database: "ecto_simple",
username: "postgres",
password: "postgres",
hostname: "localhost"And the second one is using a unique parameter:
config :my_app, Repo,
url: "postgres://postgres:postgres@localhost/ecto_simple"This is my favorite option for these reasons:
-
Just one value to maintain
-
This format is also accepted in
psql, for example we can executepsql postgres://postgres:postgres@localhost/ecto_simpleand we're connected to the database. I just discovered this a few weeks ago 😅 -
We can change credentials for example when we're running a mix command just prepending the value
DATABASE_URL=postgres://postgres:postgres@localhost/test_db mix somethingin the case we're loading it from an environment variable
Then if you have the connection url in a variable called DATABASE_URL, using direnv of course 😉, you can just execute psql $DATABASE_URL to database session.
Using iex
Enable shell history
A cool feature of elixir is iex, you can load modules, recompile them and so on, but when sometimes we execute "large" pieces of code or some cases that we're trying out to understand the code or something else and when we have to restart the session we lost all the history 😢, we can avoid this by adding a flag -kernel shell_history enabled in the environment variable ERL_AFLAGS before we start our iex session. I just put following code in my .zshrc to have it enabled for all my projects:
export ERL_AFLAGS="-kernel shell_history enabled"Preload aliases
Another thing than could be annoying to deal with is aliasing a large module name, for example if we have MyApp.Contexts.Authentication.User and we are using this module pretty often it could be easier to have it already loaded when we start a iex session, we can make this by defining a .iex.exs file in the project root with the desired aliases, for example:
alias MyApp.Contexts.Authentication.User
And now when we start a new iex session we will have that module aliased from the beginning so we can use User.whatever without a problem.
Keep in mind that even if we can make an alias(a module name is just an atom) when we starting a session using just
iexwe cannot access to its functions. We need to start ouriexsession usingiex -S mix
Recompiling modules
Within a iex sessions we can recompile a module just writing r module_name and if the want to recompile the whole project we can execute recompile, this is useful when we are making some changes in the code and we need to test it right away with all the values that we already had defined. It's also called "REPL based development" and it's most used with lisp based programming languages but having iex in elixir we can use those nice features as well.
Mix tasks
These are tasks that mix can run, duhh.. But we can create them and use them in our projects. For example maybe we are debugging some code and we don't want to execute a long process(business process) instead of that we can just extract some function calls and execute them from a mix task using existing data. We can create a mix task with the following code:
defmodule Mix.Tasks.Foo do
@moduledoc false
use Mix.Task
def run(_args) do
Application.ensure_all_started(:my_app)
IO.puts("runnning...")
end
end
We have to name this file foo.ex and place it inside lib folder and now we can run mix foo and we'll get a running... message.
I use this many times, actually I have some defined tasks in many projects than I reuse to debug some workflows.
I know that we "should" be defining the cases that we are debugging in a test, run it and then try to fix the code and then run the tests again but this way works for me so I'm OK with that 🙃
Working with local third party libraries
In some cases we could found some weird behaviour, a bug of just want to know a little more deep about how a third party library works. In that case it could be difficult to setup a local version of a library that we use in our project.
I remember using just pip install -e path_to_library in python and just starting to changing the library code.
In elixir when we want to install a local version of a library we can specify the path of it in the mix.exs file, for example:
defmodule MyApp.MixProject do
use Mix.Project
def project() do
[
app: :my_app,
version: "0.0.1",
elixir: "~> 1.0",
deps: deps(),
]
end
def application() do
[]
end
defp deps() do
[
{:ecto, "~> 2.0"},
{:postgrex, "~> 0.8.1"},
{:ecto_sql, path: "ecto_sql_local_path"}
]
end
end
In this case we're telling our project to install ecto_sql from the given path, this will work but just the first time because it will load and compile ecto_sql at the beginning and then when we're making some changes in the code placed in ecto_sql_local_path these changes won't be recompiled automatically because mix is only watching for changes inside our project. In this case we can force to recompile some modules by using for example r Ecto.Migrator from within an iex session but if we are modifying more modules it would be tedious to recompile manually every one of them, for this case we can define a Recompiler module that make this work for us, name it as you want, this will contains:
defmodule Recompiler do
def run do
modules_to_recompile = [
Ecto.Migrator,
Ecto.SomeOtherModule
]
for module <- modules_to_recompile do
IEx.Helpers.r(module)
end
end
end
We can place this module somewhere inside our lib folder and when we call Recompiler.run from within a iex session it will recompile all the defined modules.
direnv is a tool to set up automatically environment variables as soon as we enter in a directory that contains a .envrc file. We can use this feature to activate our virtualenvs as well.
Let's see what happens when we activate manually a virtualenv with source ./env/bin/activate:
-
A new new environment variable called
VIRTUAL_ENVis exported. -
The path is updated to include the
bindirectory inside ourvirtualenvthis is made to allow us to point to the correct python installation and run cli interfaces exposed by the dependencies we have installed.
Because all the "magic" about activating a virtualenv is basically configuring some environment variables we can do it automatically using direnv.
Let's assume we have a virtualenv installed in the path /Users/erick/.virtualenvs/demo, the virtualenv is located inside ~/.environments because I'm using virtualenvwrapper but it can be in any other location. Now we can use this location to configure our .envrc file as the following:
export VIRTUAL_ENV=/Users/erick/.virtualenvs/demo
export PATH=/Users/erick/.virtualenvs/demo/bin:$PATHNow when we enter our project folder the virtualenv will be "activated" automatically and when we leave the project folder it will be "deactivated".
Also when we use this method is easiest for our editor(emacs in my case) to recognize the current python installation and be able to run tests, execute files, etc.
Find file under cursor in emacs
(ノ°Д°)ノ︵ ┻━┻ 27 02 2021
La velocidad de los cambios en el ámbito del front-end, ha generado una sensación de hastío o insatisfacción entre los profesionales del diseño web. No son pocos los profesionales que expresan su descontento con la complejidad o la sobre ingeniería que ha sufrido la capa de presentación de los sitios web. En este episodio nos hacemos eco de este sentimiento, a través de otro acertado artículo de Chris Coyier titulado Front-End Dissatisfaction (and Backing Off), que a su vez hace referencia a otros artículos similares.
Muchos profesionales ven con escepticismo las ventajas de aplicar las últimas tecnologías a su stack de herramientas. A fin de cuentas, como se explica la web sigue funcionando con HTML y CSS, y la progresiva incorporación de frameworks y otras herramientas, diluye la sencillez del medio. Existe una presión en ocasiones infundada, por estar al día en las últimas tendencias, a menudo también debido al temor de no quedarse atrás en la carrera o mercado profesional. En el episodio comentamos este artículo sobre la evolución del front-end y nuestra opinión acerca de cómo afrontar tanto cambio.
En la segunda parte del episodio volvemos (min 36:30) con la sección Backlog, donde contamos recientes experiencias relacionadas con nuestro trabajo. Hablamos sobre una aplicación de citas que le solicitaron desarrollar a Andros y también de lo poco profesional que resulta dejar textos «lorem ipsum» en una web publicada.
Por último vuelve también (min 50:43) la sección Radar al podcast con algunos enlaces de recursos y herramientas de interés, relacionadas con el desarrollo web.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
My Home Office
Blogs on Tom Spencer 27 02 2021
My Home Office
Blogs on Tom Spencer 27 02 2021
DuckDuckGo logo redesign
tonsky.me 26 02 2021
CSS: @media para detectar dispositivo táctil
Bufa 24 02 2021
Embracing modern image formats
Josh Comeau's blog 24 02 2021

Time To Merge
MonkeyUser 23 02 2021
Rust es un lenguaje de programación de sistemas orientado a crear aplicaciones de alto rendimiento. Las principales ventajas de Rust son su enfoque en la velocidad, su entorno seguro de ejecución en memoria y la concurrencia. Usado por las principales empresas de tecnología como Google, Mozilla, Dropbox o Microsoft, Rust sigue apareciendo año tras año entre los lenguajes más apreciados por la comunidad de desarrollo.
Rust ha dado origen a un montón de proyectos innovadores que van desde sistemas operativos, motores para juegos, controladores y bases de datos. Rust soporta WebAssembly, un entorno de ejecución que permite desplegar aplicaciones nativas en el navegador sin necesidad de JavaScript, por cierto creado también en Mozilla. WebAssembly permite compilar y desplegar tus proyectos Rust a servidores, dispositivos IoT, móviles y al navegador.
Aunque Rust sea visto como un lenguaje de sistemas más situado en reemplazar a C y C++, en ámbitos como sistemas operativos o librerías nativas, muchos desarrolladores de Rust están trabajando en gran medida en backends para la creación de aplicaciones web. No es por tanto extraño que frameworks web como Hyper, Actix y Rocket se encuentren entre los proyectos más populares entre los desarrolladores de Rust.
Para este episodio invitamos a Lorenzo Carbonell, más conocido por la comunidad como Atareao. Lorenzo es un gran divulgador de las tecnologías de código abierto y especialista en GNU/Linux y Android. A través de su web atareao.es y su podcast, Lorenzo comparte valiosa información sobre infinidad de tecnología y también sus proyectos. Precisamente no hace mucho, Lorenzo contaba que había decidido aprender Rust, así que nos ofrece una gran excusa para invitarlo al programa para hablar sobre este lenguaje.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

|
|
|
|
|

|
Ante todo, agradecer a Carlos de No sin mis cookies el poder escribir en este blog. Para quien no me conozca, mi nombre es David Ayala y llevo trabajando en el mundo del SEO desde el año 2003. Soy un amante del link building y de los enlaces y por ello hoy he venido a ... Read more
The post Qué es la afinidad en los enlaces y para qué nos sirve en SEO appeared first on No sin mis cookies.
![]()

Adoption
MonkeyUser 16 02 2021
Vuelve el Internet Health Report de Mozilla al podcast en su edición 2020. En este episodio hablamos de los puntos principales que se tratan en este último informe de la Fundación Mozilla. El informe anual compila investigaciones e historias que buscan sugerir cómo internet podría ser más saludable en todo el mundo. En su última edición el informe Mozilla apunta como es ineludible, a la pandemia como uno de los factores que ha influido en el uso de internet. En otros puntos, sigue centrado en la necesidad de garantizar un acceso libre y universal a la red, el poder las grandes tecnológicas, los movimientos sociales y la búsqueda de un equilibrio que ayude a explorar la doble naturaleza de internet, la saludable y la no saludable.
Como en otras ediciones, se trata de un informe largo, con diferentes fuentes y apoyado con ilustrativos gráficos. En el episodio nos limitamos a contar lo que nos ha parecido más destacable, con especial mención a cuestiones educativas, la desinformación y el poder las grandes compañías de internet.
Os animamos a visitar la web de la Fundación Mozilla, donde poder consultar toda la información disponible y explorar los vínculos a las noticias y estudios que complementan este informe 2020. También se puede descargar en formato PDF o ePub.
SORTEO Libro Python ? La editorial @EdicionesENI colabora con el podcast ofreciendo algunos de sus títulos Consigue el libro online Python 3 haciendo RT de esta publicación #sorteoLibroPythonRW y siguiendo a @EdicionesENI @republicawebes Hasta 20/02 12pm https://t.co/gBhCzb3EoN pic.twitter.com/fpB6EehX4w
— Podcast República Web (@republicawebes) February 13, 2021
En este episodio también damos la bienvenida a la editorial de libros informáticos Ediciones ENI, que como colaboración con el podcast ofrece el acceso a algunos de sus libros. Este acceso se brindará a las personas que vayan ganando los concursos que periódicamente realizaremos en el podcast.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
|
|
|
|
|
|
|

CSS: múltiples :not()
Bufa 09 02 2021

This is a description of the Common Lisp ecosystem, as of January, 2021, from the perspective of a user and contributor.
The purpose of this article is both to give an overview of the ecosystem, and to help drive consolidation in each domain.
Each application domain has recommendations for consolidating that part of the ecosystem, and pointers for interesting future work.
This article is derived from Fernando Borretti’s State of the Common Lisp ecosystem from 2015, hence the introduction that sounded familiar. This new one will be an opportunity to look at what was achieved, or what is still lacking.
Disclaimer: This article is not a list of every project or article of interest that came out in the last years. I wrote an overview of 2018 closer to that goal here. More libraries can be discovered on the Awesome-cl list, on GitHub and on Cliki.
Acknowledgements I would like to thank @borodust, @ambrevar and @digikar for their kind feedback.
Table of Contents
Application domains
Command line
There used to be several options to ease building and distribution of command line programs, but now Roswell has gained most momentum, and that’s a good thing. Roswell is an implementation manager, installer and a script runner, and one of its neat features is support for very easily compiling tiny scripts into executables.
Now, GNU Guix has gained many CL libraries, and becomes a contender to Roswell. Guix can be used as a package manager on top of your Unix distribution. It brings reproducible builds, rollbacks, the ability to install exact versions of any library (including system dependencies), contained environments and user profiles. It makes it easy too to install the latest version of a CL implementation and libraries and, to a certain extent, to share scripts. See the article A Lisp REPL as my main shell for insights.
To parse command line arguments, unix-opts shows decent activity. As a reminder, the CLI arguments are stored portably in uiop:command-line-arguments.
Adams is a new UNIX system administration tool, not unlike Chef or Ansible.
Consolidation
More features to the sripting libraries.
Future work
The Lem editor has built a great user interface and REPL on top of ncurses, with the cl-charms library. It would be great to re-use its components, so that Lispers could easily build similar rich terminal-based interfaces.
Databases
Mito is an ORM for Common Lisp with migrations, relationships and PostgreSQL support. It is based on cl-dbi (a uniform interface to the various database server-specific libraries such as cl-postgres and cl-mysql) and SxQL (a DSL for building safe, automatically parameterized SQL queries).
It also has a tutorial in the Cookbook: Cookbook/databases.
There are of course more libraries in that field. Some new ones since 2015 are:
cl-yesql (by the author of Serapeum, Spinneret and other great libraries) is based on Clojure’s Yesql.
vivace-graph is a graph database and Prolog implementation, taking design and inspiration from CouchDB, neo4j and AllegroGraph.
Vsevolod Dyomkin, the author of Rutils, the Programming Algorithms book and other libraries, is writing cl-agraph, a minimal client to Franz Inc’s AllegroGraph. AllegroGraph is a “horizontally distributed, multi-model (document and graph), entity-event knowledge graph technology”. It is proprietary and has a free version with a limit of 5 million triples. Surely one of those Lisp hidden gems we should know more about.
A general migration tool was lacking. We now have cl-migratum, a “system which provides facilities for performing database schema migrations, designed to work with various databases”.
And of course, pgloader is still a Common Lisp success story.
Achievement
Among the emerging ORMs, Mito is the one actively maintained that Lispers seem to have chosen. Good. CLSQL certainly still works, but we don’t hear about it and it looks outdated. So, Mito it is.
Consolidation
Mito has 11 contributors and is actively watched, but it probably should have another(s) core maintainers.
Future work
Bindings for the new databases coming out.
Concurrency
In the last year, Manfred Bergmann developed cl-gserver. It is a “message passing” library/framework with actors similar to Erlang or Akka. It is an important achievement.
Its v1 features:
- actors can use a shared pool of message dispatchers which effectively allows to create millions of actors.
- the possibility to create actor hierarchies. An actor can have child actors. An actor now can also “watch” another actor to get notified about its termination.
Many other libraries exist in this area:
- BordeauxThreads - Portable, shared-state concurrency
- the “de-facto” concurrency library.
- lparallel - A library for parallel programming.
- also solid, battle-tested and popular, aka de-facto.
- calispel - CSP-like channels for common lisp. With blocking, optionally buffered channels and a “CSP select” statement. ISC-style.
- “It is complete, flexible and easy to use. I would recommend Calispel over Lparallel and ChanL.” @Ambrevar. discussion
- ChanL - Portable, channel-based concurrency.
- cl-async - A library for general-purpose, non-blocking programming.
- works atop libuv
- Moira - Monitor and restart background threads. In-lisp process supervisor.
- trivial-monitored-thread - a Common Lisp library offering a way of spawning threads and being informed when one any of them crash and die.
- lfarm - distributing work across machines (on top of lparallel and usocket).
- cl-gearman - a library for the Gearman distributed job system.
- Alexander Artemenko used it instead of lfarm for Ultralisp: https://40ants.com/lisp-project-of-the-day/2020/06/0095-cl-gearman.html, because “lfarm is not well suited to environments where worker hosts can go down and return back later”.
- swank-crew - distributed computation framework implemented using Swank Client.
- cl-coroutine - a coroutine library. It uses the CL-CONT continuations library in its implementation.
- CMTX: high performance transactional memory for Common Lisp.
- In our opinion, a library not well known and under-appreciated.
(see awesome-cl#parallelism-and-concurrency)
Consolidation
Bordeaux-Threads is the “de-facto” library, but there is some choice paralysis between Lparallel, Calispel, Bordeaux-Threads and SBCL’s contribs. Use the libraries in the wild and write about them.
File formats
There exist Common Lisp libraries for all the major file formats:
- XML: Plump (and Lquery), as well as CXML, which can parse large files incrementally.
- JSON: Jonathan, cl-json or more. With utilities:
- json-pointer - A JSON Pointer implementation.
- json-mop - A metaclass for bridging CLOS and JSON objects (remind that JSON libraries can already serialize your own objects).
- json-schema
- YAML: cl-yaml
- CSV: cl-csv
Achievement
New in 2015, Jonathan is now a good first choice for an easy to use and fast JSON encoder and decoder.
Consolidation
There is not a predominant JSON library. This leads to choice paralysis.
They all represent null values differently. We need a library that “does the right thing”. See maybe the massive web-toolkit for its JSON handling ?
It distinguishes null, false and [] from Lisp’s NIL thus supports identical transformation between JSON values. It provides object constructor and accessor to build and access nesting JSON objects.
Give the XPath library some love and documentation.
Future Work
Still valid from 2015:
A YAML parser so that cl-yaml doesn’t depend on the libyaml library would make distribution far simpler.
GUI
A usual complain in Common Lisp land is the lack of a complete, cross-platform GUI solution. Ltk is a very good library, but Tk is limited. Qtools is great, but is only for Qt4.
A lot has happened, and is still happening (if you watch the right repositories, you know that a Qt5 wrapper is in the works (ECL already has Qt5 bindings: EQL5, with an Android port)).
edit: see also EQL5-sailfish for Sailfish OS. Here are two example apps.
Matthew Kennedy wrote excellent FFI bindings to the IUP Portable User Interface library: IUP. IUP is cross-platform (Windows, macOS, GNU/Linux, with new Android, iOS, Cocoa and Web Assembly drivers), has many widgets (but less than Qt), has a small API and is actively developed. IUP was created at the PUC university of Rio de Janeiro.
Nicolas Hafner started Alloy, a new user interface protocol and toolkit implementation, which he uses in his Kandria game.
Very recently, David Botton released CLOG, “the Common Lisp Omnificent GUI”:
CLOG uses web technology to produce graphical user interfaces for applications locally or remotely. CLOG can take the place, or work alongside, most cross-platform GUI frameworks and website frameworks. The CLOG package starts up the connectivity to the browser or other websocket client (often a browser embedded in a native template application.)
It is complete enough for most uses.
There are more GUI libraries and frameworks: https://github.com/CodyReichert/awesome-cl#Gui (and more under the works). In particular, LispWorks’ CAPI is still presented as the best in town by the ones who tried it.
Consolidation
Since roughly October, 2020, Nicolas Hafner works full time on Kandria. Supporting his work, through GitHub sponsors or ko-fi would be 1) a great sign of recognition and 2) useful for the ecosystem, especially for Alloy.
I wrote an introduction to these frameworks in the Cookbook: Cookbook/gui. More examples or demo projects would be welcome.
There are two actively maintained diverged forks of the GTK bindings. A reunification effort is required.
Future work
Write a desktop application with IUP/your toolkit of choice for everyday use and make it a Common Lisp flagship.
Study other approaches to GUI bindings. What about gtk-server? GObject introspection? An effort started for Qt: giqt (in which we recognize @ambrevar from the Nyxt browser).
Machine Learning
It seems that not much changed since 2015, but libraries are still being developed:
used by its author to win the Higgs Boson Machine Learning Challenge
- mgl-mat - a library for working with multi-dimensional arrays which supports efficient interfacing to foreign and CUDA code. BLAS and CUBLAS bindings are available.
Others are less active:
- Antik - a foundation for scientific and engineering computation in Common Lisp. It is designed not only to facilitate numerical computations, but to permit the use of numerical computation libraries and the interchange of data and procedures, whether foreign (non-Lisp) or Lisp libraries.
- more than 2000 commits, last update 2 years ago.
System
To quote Fernando:
UIOP, ASDF’s portable compatibility layer, contains a large set of tools for portably doing everything from querying the hostname to running external programs to manipulating environment variables.
We should not require cl-fad anymore (but we need Osicat, which unlike UIOP is POSIX friendly).
Built on top of UIOP, Paul M. Rodriguez’s cmd brings in short and handy helpers to run and pipe programs.
Web Development
Backend
Common Lisp’s main web servers are Hunchentoot and Clack. Since 2015, Clack’s documentation state barely improved and is still lacking.
Clack is the equivalent of WSGI/Rack. It has existed since 2009. It is an HTTP server abstraction, that allows the user to write web applications (or, more reasonably, web application frameworks) without depending on a particular server. Some web frameworks are built on top of it, for example Caveman2.
The importance of using Clack cannot be understated: If you build an application directly on, say, Hunchentoot, you’re tied to Hunchentoot, and if a new, faster server – like Woo – comes out, you have to rewrite the entire application to use it. If you write a plugin for Clack – like clack-errors – it is automatically usable by all applications, regardless of framework, that are built on Clack, reducing useless duplication of code.
With Clack, switching from Hunchentoot to Woo, and enjoying the incredible speedup, is a simple matter of installing libev and changing a keyword argument.
This still holds true, but the situation didn’t improve much. In comparison, Hunchentoot is very well documented (and you can read its documentation on a better looking readthedocs here), and it is “fast enough”.
About Hunchentoot: Mariano Montone wrote easy-routes, a little but handy route handling facility on top of Hunchentoot. It brings:
- dispatch by HTTP method,
- arguments extraction from the URL path,
- “decorators” to, for example, quickly add authorization checks,
- integration with the Djula framework to generate URLs from route names.
Achievement
Several Clack plugins were written, such as a single-sign on middleware.
Consolidation
Write more documentation for Clack. While Lispers know about it, they don’t necessarily adopt it because of the lack of documentation. We can expand this getting started guide.
Future work
Build a batteries-included framework.
Frontend
Many HTML generators and template libraries exist (see the list below). However, some new and good ones appeared lately:
- TEN, by Djula’s maintainer, brings the completness of Djula with the usability of Eco (by Fernando Borretti), aka: you write Django-like HTML templates but you can interleave any Lisp code.
- markup - a JSX-like templating engine, where HTML tags are Common Lisp code. Comes with an Emacs package.
Other HTML generators and templating engines include:
- spinneret - Common Lisp HTML5 generator.
- cl-who - The venerable HTML generator.
- Djula - A port of Django’s template engine to Common Lisp.
- cl-closure-template - Implementation of Google’s Closure templates. [LLGPL][8].
- clip - An HTML template processor where the templates are written in HTML.
We have nice other building blocks, such as a nice form handling library (cl-forms) and libraries to create Open-API interfaces. An integrated, opinionated all-in-one solution could be a productivity boom.
Consolidation
Djula is easy to work with. It could do with more built-in filters.
As in 2015:
The foundation is finished, now it’s time to write higher-level layers. An extensible administration framework for Clack applications, like Django’s Admin, would be a good example.
JavaScript
The two “historical” Common Lisp to JavaScript compilers are:
- Parenscript, a DSL that compiles a subset of Common Lisp to idiomatic JavaScript, and
- JSCL, a CL-to-JS compiler designed to be self-hosting from day one. JSCL is not complete (yet), it lacks CLOS, format and loop.
Two new are in development:
- Valtan, a CL to JS compiler.
- JACL, JavaScript Assisted Common LispIt has a recording from ELS 2020.
Consolidation
Help develop one of the existing CL-to-JS implementations. Why not have a look at JSCL’s issues?
Bring some new macros to ParenScript for new JavaScript idioms, as Paren6. For example, allow to write async and await.
Isomorphic web frameworks
Weblocks is an already old framework that allows to write dynamic web applications without writing JavaScript (it isn’t as dynamic as modern JS frameworks, there is no “double data binding”). Its server-based components use Ajax if available or fallback to plain HTTP and update the DOM. It is a framework in the vein of Smalltalk’s Seaside.
Weblocks was getting old and unmaintained but Alexander Artemenko greatly updated and refactored it in his Reblocks branch. He uses it for the Ultralisp website, and more apps. You can reach users and developers on Gitter.
Recently, a very new web framework appeared: ISSR, for Interactive Server-Side rendering. It links a client to the server with a websocket connection and updates the DOM selectively. It is thus not unlike Phoenix’s LiveView or Hotwire.
See this todo-app tutorial.
Achievement
Reviving Weblocks and releasing CLOG and ISSR are great achievements. However, work is only started to create a community of users around them.
Languages interop
New solutions arose to interoperate with other runtimes.
APL
April brings the APL programming language (a subset thereof) to Common Lisp. Replace hundreds of lines of number-crunching code with a single line of APL.
C, C++, Objective C
We had CFFI (a portable foreign function interface for CL), C2FFI (Clang-based FFI wrapper generator), then cl-autowrap, a c2ffi-based wrapper generator that makes creating C bindings real quick.
Pavel Korolev is developing CLAW, started as a fork of cl-autowrap, which brings C++ support. For practice he generated bindings to GLM or to the Filament rendering engine.
Achievement
It will be a great achievement when CLAW is officially ready to use. This is not yet the case (though the GLM bindings basically do their hello world on Android, which is an achievement per se).
Clojure
ABCLJ provides a “dead easy Clojure to Common lisp interop”:
instead of rewriting the whole Clojure langugage on CL I’m embedding ABCL in Clojure. Since both are implemented in Java and Clojure has an awesome java interop is easy to have full access on the ABCL Common Lisp environment. This way we have complete support for both Clojure and Common Lisp.
But why?
The reason I wanted to see Clojure and Common Lisp working with each other was to use CL programs/libraries on Clojure, especially Maxima and ACL2. Since ABCL already compiles and runs Maxima it should be possible but we are very far from it 🤷.
There are others of attempts to shorten the gap between clojure and common lisp like Cloture and clclojure. Once they are complete Clojure will benefit from native binaries and excelent compilers like SBCL, however they are far from complete.
On the topic, see this talk by Alan Dipert: “Common Lisp for the curious Clojurian”.
Abstract:
“If I had to be stranded with something other than Clojure, I’d be happiest with a good Common Lisp and its source code.” - Rich Hickey, 2011
Common Lisp (CL) and Clojure are both dialects of Lisp. Rich Hickey, the creator of Clojure, learned CL and used it professionally before creating Clojure.
What can Clojure do that CL can’t, and vice versa? Why would anyone use CL today, when both Clojure and ClojureScript exist?
In this talk, I will try to answer these questions and more, from the perspective of a long-time Clojurian with a growing passion for CL.
Python
py4cl is the new lib in town. It allows Common Lisp code to access Python libraries. It is basically the inverse of cl4py.
See also async-process and, while we’re at it, my comparison of Python VS Common Lisp, where we look at the differences of workflows and ecosystems.
Achievement
Calling to Python and hooking into its ecosystem is easier than ever.
Future work
Improving CL libraries such as Numcl (a Numpy clone) is what’s required to drive Common Lisp forward.
.Net Core
Bike is a cross-platform .Net Core interface.
Development
Implementations
All implementations saw new releases, except CLisp, whose development however continues.
Active implementations include: ABCL, CCL, CLASP, ECL, LispWorks, AllegroCL, SBCL. And to a certain extent, GNU CLisp, SICL (which is the newest one) and Corman Lisp (a CL development environment for Windows) (regenerated here).
ABCL jumped to v1.8.0 to support openjdk15.
SBCL still ships monthly releases. It turned 20 and keeps improving (RISC-V port, M1 port, block compilation, more compile-time type checking…). We can read a blog on the party held in Vienna here. Did you know that Doug Katzman of Google fame contributes to SBCL?
(edit:)
Doug Katzman talked about his work at Google getting SBCL to work with Unix better. For those of you who don’t know, he’s done a lot of work on SBCL over the past couple of years, not only adding a lot of new features to the GC and making it play better with applications which have alien parts to them, but also has done a tremendous amount of cleanup on the internals and has helped SBCL become even more Sanely Bootstrappable. That’s a topic for another time, and I hope Doug or Christophe will have the time to write up about the recent improvements to the process, since it really is quite interesting.
Anyway, what Doug talked about was his work on making SBCL more amenable to external debugging tools, such as gdb and external profilers. It seems like they interface with aliens a lot from Lisp at Google, so it’s nice to have backtraces from alien tools understand Lisp. It turns out a lot of prerequisite work was needed to make SBCL play nice like this, including implementing a non-moving GC runtime, so that Lisp objects and especially Lisp code (which are normally dynamic space objects and move around just like everything else) can’t evade the aliens and will always have known locations.
Editors
Here too, great progress has been made. While a usual complain of non-Lispers was the lack of editor support besides Emacs (and Vim), we now nearly reach choice paralysis:
- Portacle is the easiest way to get started with Emacs. It is portable and multi-platform, ready-to-use in three clicks. It ships Emacs, SBCL, Slime, Quicklisp and git.
- SLIMA is the Atom extension. It is nearly as good as Slime for Emacs.
- VSCode has two extensions: commonlisp-vscode, using the Language Server Protocol, and Alive, more recent, using a Lisp backend (Swank) as traditional extensions.
- Sublime Text got a good extension: Slyblime is an implementation of SLY and it uses the same backend (SLYNK). It ships advanced features including a debugger with stack frame inspection.
- Lem is an editor written in Common Lisp. It allows to start developing in CL at once, and it supports other languages.
- we have a Jupyter kernel for CL.
- the Dandelion Eclipse plugin was re-discovered. While it isn’t as feature-rich as others (no interactive debugger for example), it has its users. It specifically targets beginners.
Last but not least, if you want to play in your iPhone or iPad, the CodePlayground app got Lisp support via CCL.
Consolidation
SLY might need more praise. It has sound features such as SLY stickers and the new SLY stepper.
Developer utilities
Life continues to improve for the developper. We will cite some new tools:
- cl-flamegraph is a wrapper around SBCL’s statistical profiler to generate FlameGraph charts from Common Lisp programs.
- tracer is a tracing profiler for Common Lisp, with output suitable for display in Chrome’s/Chromium’s Tracing Viewer.
- GTFL is a graphical terminal for Lisp, meant for Lisp programmers who want to debug or visualize their own algorithms. It is a graphical trace in the browser.
- Lisp REPL core dumper is a portable wrapper to generate Lisp cores on demand to start a REPL blazingly fast. It can preload provided systems to help build a collection of specialized Lisp cores.
- if you are used to working in different environments that require their own set of libraries, this core dumper (optionally along with SLY’s mrepl) can make switching from one another easier and faster.
Package Management
Quicklisp is the de-facto package manager. However, we now have:
- Ultralisp, a Quicklisp distribution that builds every 5 minutes. We can add our project in two clicks.
- CLPM, a new package manager that is compatible with Quicklisp, that allows to pin exact versions of dependencies, that is usable from the command line and that supports HTTPS.
Not forgetting Qlot, to install Quicklisp libraries relative to a directory.
Last but not least, as said earlier, many CL libraries were packaged for Guix (most notably by Pierre Neidhart of Nyxt).
Achievement
Ultralisp solves the 1-month release schedule of Quicklisp (which is a feature, but not to everyone’s taste) and makes it straightforward and quick to publish a library. CLPM by tackling a different approach solves other Quicklisp limitations. Both are great achievements.
Ultralisp also has a search box that searches a symbol on all its registered libraries. Very useful.
Future work
Alexander is working on allowing every Ultralisp user to create his own Quicklisp dist in a few clicks.
Build System
Same as 2015, ASDF is the de-facto build system.
Every project has an .asd file, called a system definition file, which defines project metadata (author, maintainer, homepage, etc.) and the components.
This, to me, is one of the major selling points of Common Lisp. With languages like Python, every file imports whatever it needs, and your project becomes a massive graph of interdependent files. In ASDF, you basically list the files in your project in the order in which they are defined. Or, you can specify the dependencies between the files, and let ASDF figure out a linear ordering. The point is that dependencies are explicit, and clearly spelled out.
Type system
Quoting Fernando:
There’s not much to say here, except that Common Lisp has a pretty great type system that is not exploited nearly enough.
And to our greatest pleasure, SBCL’s type system continues to improve. For example, SBCL 1.5.9 now gives type warnings when a slot declared type doesn’t match its initform. It continued to improve on SBCL 2.0 and onwards.
Moreover, the Coalton library is bringing a dialect of ML on top of CL, in order to write statically typed programs similar in spirit to Standard ML, OCaml, and Haskell.
Consolidation
Help develop Coalton.
Testing, CI
Fernando cited FiveAM and recommended it along with the much newer Prove. Prove has a couple issues and is now deprecated by its author, and its younger brother Rove is not in par yet.
So, use FiveAM.
Moreover, Common Lisp has good support for the CI/CD services out there.
CL Foundation’s Docker images have integrated best practices over the years and are recommended: https://common-lisp.net/project/cl-docker-images/
CI-Utils regroups utilities for various platforms (Travis, Circle, Gitlab, Github, Appveyor, Bitbucket, Azure) and test frameworks.
We got a comprehensive blog post for GitHub actions: part1 and part2.
For Travis CI, you can also see cl-travis (for ABCL, Allegro CL, SBCL, CMUCL, CCL and ECL).
You will find an example for Gitlab CI on the Cookbook.
Consolidation
Rove or Parachute would be great alternatives if developed a bit further.
Further work
Integration with the CI services’ advanced features such as Gitlab’s auto DevOps.
Community
Online presence
Common Lisp is very well documented through its standard, the Common Lisp Hyper Spec and many books. However, we felt it was lacking good on-line material. Good news is, the situation improved tremendously in the last three or four years.
New common-lisp.net website
https://common-lisp.net was written anew. It looked dated. This is now fixed. Well done!
Cookbook
The Common Lisp Cookbook on GitHub got revived by many new contributors, included myself. It got many new content and a new UI. It is also now available in ePub and PDF, for free or as a “pay what you want” option.
Consolidation
Write content on the Cookbook. Don’t write tutorials on your blog. Everyone can help, even new Lispers (and in fact: mostly new Lispers can write content best suited to the Cookbook’s target audience).
Future work
Make it look world-class with a real and modern theme.
Help revive the minispec ?
awesome-cl
The awesome-cl list saw continuous updates and is now a great solution to have an overview of the ecosystem and choose a library.
One of its goals is to break choice paralysis by recommending libraries, with its “+1” marks.
Consolidation
Help furnish and curate it.
More
A first Common Lisp User survey was run, we can consult its results here on Google docs and read comments on reddit as well as feedback on the questions here.
I agree with /u/defunkydrummer here:
Note that many, many things that people wish to see, are already available, so perhaps we, as a community, are not fully communicating the state of our ecosystem even to our insiders (!)
Several popular libraries have been ported to readthedocs, so the reading experience is more pleasant: https://common-lisp-libraries.readthedocs.io/.
Michal “phoe” Herda organized many online Lisp meetings, and we can find the videos on Youtube: https://www.youtube.com/c/OnlineLispMeetings/videos
Alexander Artemenko started lisp project of the day, a blog to review a library every day for a month, and he is now at post #219. Lately he reviewed many documentation builders for CL.
On a sadder note, Quickdocs closed :(
New books
We got 3 new books on Common Lisp in 2020:
- Programming Algorithms, originally published by Vsevolod Dyomkin on his website, then self-published in paperback and then published by Apress.
- the Common Lisp Condition System, by Michal “phoe” Herda, was also published by himself and then by Apress.
- The Cookbook that was made available in ePub and PDF :)
And also:
- the book Calendrical calculations, 4th edition, by Edward M. Reingold, Nachum Dershowitz, Cambridge Press. It provides Lisp sources.
- Building Problem Solvers, by Kenneth Forbus and Johan de Kleer, MIT Press, was made available.
Companies
We now have a curated list of companies using CL: awesome-cl-companies. Before that list, the situation was embarassing:
Everyone says “Nobody uses Lisp” and Lispers say “Yes they do, there’s ITA, and, um, Autocad, and, uh, oh yeah, Paul Graham wrote Viaweb in Lisp!” Not very helpful for either side. It’s about time there was a better resource.
Peter Christensen in his first list
And see also lisp-lang.org’s success stories.
Some additions of this year include GraphMetrix (automation of document extraction and publishing for construction, property and logistics), Doremir Music Research AB (developing ScoreCloud, a music notation software: you sing, it writes the score), Keepit (a cloud-to-cloud backup service provider), Mind AI (an artificial intelligence engine and ecosystem), Virtual Insurance Products Ltd (insurance MGA with a bespoke business to business web platform) or again the Mimix Company (creators of MSL and Nebula, new tools for working with facts and documents).
Growth
We are able to compare the number of downloads of the 100 most popular Quicklisp libraries between 2015 and 2020:
We can observe a 3x growth in five years. Of course, these figures need to be taken with a grain of salt, what they really represent is subject to interpretation. What is the role of Continuous Integration here?
Check it yourself: snippet, JSFiddle.
Last words
Many things are happening in the CL universe. Stay tuned!
The article source.
The Why of technology
Murilo Pereira 07 02 2021

En qué ando últimamente
Onda Hostil 07 02 2021
The Real Novelty of the ARPANET
Two-Bit History 07 02 2021
Recientemente O’Reilly Media publicó un completo informe titulado Where Programming, Ops, AI, and the Cloud are Headed in 2021. Este informe, escrito por Mike Loukides, responsable de estrategia de contenidos en O’Reilly, ha sido realizado con datos obtenidos en su plataforma de aprendizaje en línea. Tal y como explica el responsable, este estudio está limitado a los usuarios de la plataforma, según las búsquedas realizadas, filtrando y agrupando por categorías. El objetivo consiste en detectar tendencias según el interés por encontrar ciertas materias, ofreciendo información sobre el uso de los materiales formativos, dentro de la plataforma, su crecimiento y las búsquedas realizadas en la misma.
O’Reilly Media es una de las empresa de contenidos tecnológicos más importante a nivel mundial, y un referente para muchos profesionales del ámbito de la programación y las nuevas tecnologías. Para este episodio hemos querido compartir varios apartados del estudio y para ello, también contamos con la compañía de Antony Goetzschel.
Como explican en el artículo, O’Reilly tuvo que cerrar su división de organización de conferencias en marzo y la reemplazó por «superstreams virtuales». O’Reilly ha experimentado un considerable aumento en el uso de la plataforma durante el último año debido a la COVID (en especial el formato de formación en vivo que creció un 96%, los libros subieron un 11% y el vídeo un 24%).
Debido a la extensión del artículo hemos decidido limitarlo a: lenguajes de programación, operaciones, desarrollo web y por último inteligencia artificial. No obstante el artículo también aborda cuestiones como la seguridad, la nube y la privacidad. Es por eso que os recomendamos al 100% su lectura.
Se trata de un valioso documento donde dan buenas pistas acerca de las tendencias más notables en el ámbito tecnológico. El informe contiene interesantes apreciaciones por parte de Mike Loukides, en especial las relacionadas con la IA y sus implicaciones. Aunque este informe esté limitado a los datos obtenidos en la plataforma de O’Reilly Media, su influencia y alcance, le otorga una indudable validez para comprender las tendencias más sólidas en los próximos años.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Updated Debian 10: 10.8 released
Debian News 06 02 2021
buster). This point release mainly adds corrections for security issues, along with a few adjustments for serious problems. Security advisories have already been published separately and are referenced where available.
CSS: efecto Marquee
Bufa 05 02 2021

We’re glad you could make it this week!
With your help, we can make Pony Foo Weekly even more awesome: send tips about cool resources.
|
|
|

|
|
Con este séptimo episodio cerramos esta serie especial sobre programación funcional. En esta ocasión Andros Fenollosa vuelve con una habitual de este podcast: la desarrolladora y diseñadora Valentina Rubane. Ella es compañera de Andros en Sapps, su estudio de aplicaciones web y móviles en Valencia. Valentina viene para hablar del lenguaje Swift, un lenguaje de propósito general, multiparadigma y compilado desarrollado por Apple y la comunidad de código abierto.
Como es habitual con otros invitados en esta serie sobre programación funcional, seguiremos el habitual turno de preguntas para hablar sobre este lenguaje:
- ¿Qué pasó por tu cabeza para meterte en la programación funcional?
- Dime algunas características que te rompieron la cabeza y te enamoraron.
- ¿Qué es Swift y cuál es su origen?
- ¿Por qué hay tanto objeto si es funcional?
- ¿Es open? ¿Quién es el autor? ¿se desarrolla por comunidad?
- ¿Qué lo hace especial respecto al resto?
- ¿Quién lo usa? ¿Para quién está orientado?
- Hablemos de MacOS. Solo podemos usarlo para hacer APP de iOS. ¿Es cierto?
- ¿Cuáles son tus frameworks favoritos?
- ¿Cuál crees que es el futuro del ecosistema?
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

Negligible Error
MonkeyUser 02 02 2021
Este nuevo episodio de Informe Nube, David Vaquero y Antony Goetzschel ofrecen un recorrido de diversas noticias relacionadas con la nube. Para este episodio:
Red Hat presenta nuevos programas para acceder a los programas Enterprise. Más informacion de Red Hat Developer Program.
AMD presenta los microprocedadores Ryzen Threadripper Pro con tres nuevas placas WRX80. Más información.
Amazon libera EKS Distro (EKS-D), una distribución basada en Kubernetes y usada por el servicio Elastic Kubernetes de Amazon para crear confiables y seguros clusters de Kubernetes. Más información en el Github de AWS.
Elastic cambia su licencia. https://www.elastic.co/es/blog/license-change-clarification y el papel que juega AWS.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
![]()
In this article I describe the process we took to identify potential free space, and one surprising find that helped up clear up ~10GB of unused indexed values!
Clojure 1.10.2 release
Clojure News 26 01 2021
Clojure 1.10.2 includes a number of improvements for Java interop/compatibility:
-
Fixes an issue in the
lockingmacro to satisfy more stringent Java verifiers (particularly, Graal) -
Fix for invocation of static interface methods with primitives
-
proxywas incorrectly emitting Java 5 bytecode, now will be Java 8 to match all other code gen -
Spec now compiled to Java 8 bytecode instead of Java 5 bytecode
-
Many fixes for reflection, javadoc urls, Java deprecation warnings, etc
Other important Clojure fixes:
-
Fix
caseexpression branch analysis resulting in compilation error -
Fix
nthwith not-found value on regex matcher -
Improve
vector-ofimpls with equals, hashing, metadata support to match other colls -
Fix printing of some maps with namespace syntax
-
Various doc string and error message fixes
-
Perf improvement - use transients in
zipmap
Detailed changelog
See the change log for a complete list of all changes in Clojure 1.10.2.
Fullstack Adventure
MonkeyUser 26 01 2021
![]()
DESAMOR DESDE EL ESTOICISMO
Diario Estoico 24 01 2021
Sexta entrega de la travesía de descubrimiento por la programación funcional. En esta ocasión Andros invita a Diego Sevilla, profesor en la Universidad de Murcia para hablar de Lisp, uno de los lenguajes de programación más longevos y raíz de otros dialectos como Scheme, Clojure, Common Lisp o Emacs Lisp.
Se puede asegurar que familia de Lisp tiene una larga historia que ha ayudado a modelar a otros lenguajes. Todo un pionero para lenguajes tan conocidos como Perl, Python, Javascript, Lua, Scala, Ruby, R, Elixir, Haskell… entre otros. Y que, a pesar de haber nacido en 1958 continúa gozando de salud juvenil. Lisp se puede utilizar en 10 dialectos diferentes, como por ejemplo Clojure, del que ya hablamos en el primer episodio de la serie programación funcional.
Con Diego Sevilla hablamos mucho sobre GNU Emacs, la situación actual de Lisp, de Common Lisp, del invierno de la IA y su renacimiento, de la perenne habilidad de Lisp para continuar siendo un lenguaje valioso, altamente expresivo, con su particular sintaxis y con unas bases profundamente sólidas en conceptos matemáticos.
Como en anteriores episodios de la serie, conversamos sobre los comienzos de Diego en la programación funcional, su uso actual, recursos de interés para conocer el lenguaje y su comunidad.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Vanilla JS: on load
Bufa 20 01 2021
Vanilla JS: clonar elemento
Bufa 19 01 2021
![]()
I am glad to announce that the Common Lisp Cookbook is now available in ePub and PDF.
It is available for free, and you can pay what you want[1] to say a loud “thank you” and to further support its development. Thanks!
This EPUB represents the work on the span of three years where I have been constantly reading, experimenting, asking, discovering tips, tools, libraries and best-practices, built-in or not, all of which should have been easily accessible but were not. Now they are. Reviving the Cookbook project resonated in the community, as other lispers sent great contributions.
Donate and download the EPUB version
=> https://lispcookbook.github.io/cl-cookbook/ <=
[1]: above 6 USD actually.

Pending Approval
MonkeyUser 19 01 2021
Recientes acontecimientos como la expulsión conjunta en redes sociales del todavía Presidente Trump y el bloqueo global de servicios como Parler en AWS, ofrecen una excelente oportunidad para comprender mejor un aspecto fundamental del funcionamiento de Internet, ¿Quién o quiénes gobiernan internet? ¿Quién decide cómo y de qué forma se accede a la red? ¿Hay límites a lo que las grandes empresas de internet puedan decidir en materia de libertad de expresión?
Para este episodio contamos con la compañía de Eduardo Collado, un gran profesional de las telecomunicaciones, consumado podcaster y todo un evangelista de las tecnologías de internet. Con él hablamos del poder de las operadores para inspeccionar el tráfico y de cómo podemos como usuarios, protegernos del formidable poder de las empresas de internet sobre nuestras comunicaciones.
Con Eduardo Collado hablamos sobre de aspectos técnicos como DNS, VPN, BGP, pero en especial sobre la idoneidad de fiar nuestros datos a empresas de telecomunicaciones y grandes empresas que dominan nuestros destinos en la red.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

We’re glad you could make it this week!
With your help, we can make Pony Foo Weekly even more awesome: send tips about cool resources.
|
|
|

|
|
|
|
|
State of Clojure 2021 Survey
Clojure News 14 01 2021
It’s time for the annual State of Clojure Community Survey!
If you are a user of Clojure or ClojureScript, we are greatly interested in your responses to the following survey:
The survey contains five pages:
-
General info
-
Tool usage
-
Questions specific to JVM Clojure (skip if not applicable)
-
Questions specific to ClojureScript (skip if not applicable)
-
Final comments
Only the first two questions are required, please skip any questions that are not applicable.
The survey will close January 29th, after which all of the data will be released with some analysis. We greatly appreciate your input!
Para este segundo episodio de Informe Nube, David Vaquero y Antony Goetzschel, ofrecen una introducción a Terraform y un despliegue de una infraestructura sobre la plataforma de cloud Digital Ocean.
Terraform es una interfaz de línea de comandos que permite gestionar cientes de servicios en la nube. Terraform codifica las API de los servicios cloud en ficheros de configuración declarativos. Esta introducción permite comprender los aspectos básicos de Terraform y se utilizan como ejemplos los servicios de Digital Ocean.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
A rabbit hole full of Lisp
Murilo Pereira 13 01 2021

Task, Story, Epic, Quest
MonkeyUser 13 01 2021
reCAPTCHA v3: ocultar insignia
Bufa 11 01 2021
There is a type of index you are probably not using, and may have never even heard of. It is wildly unpopular, and until a few PostgreSQL versions ago it was highly discouraged and borderline unusable, but under some circumstances it can out-perform even a B-Tree index.
Ámbitos anidados
La importancia de disponer de clausuras va más allá de saber dónde se evalúa la función. Si fuera posible encapsular una función junto con su propio entorno de ejecución, podríamos conseguir que la función tenga “memoria” o, dicho de otro modo, que sea capaz de conservar sus propios estados entre llamadas a la función. Este empaquetado de función y entorno de ejecución se denomina a veces clausuras verdaderas y suele ser la principal característica de los llamados Lenguajes Funcionales.
En python podemos crear estas clausuras verdaderas con *funciones anidadas, donde una función está definida dentro del ámbito de la otra.
Un ejemplo sencillo:
def incr(n):
def aux(x):
return x + n
return aux
inc5 = incr(5)
print(inc5(10)) # -->15
Como resultado se devuelve la función aux, definida dentro del ámbito de
incr y que emplea de éste la variable n. Internamente, se conserva la
referencia a la variable n, pero no será accesible desde fuera de la función
aux. Hemos podido empaquetar la función junto con el entorno donde se definió.
Pongamos otro ejemplo:
def count():
num = 0
def aux():
num += 1
return num
return aux
c1 = count()
c1() # --> 1
c1() # --> 2
c1() # --> 3
Si pruebas este código te dará error. La función anidada aux intenta modificar
la variable num. Para este caso, la variable se crea dentro del ámbito más
interno, en lugar de usar la variable disponible. Y como se intenta modificar la
variable antes de asignarle un valor, entonces se produce el error.
Como solución, podríamos hacer la variable num global para que fuera accesible
por todos los ámbitos. Pero esta solución no es buena ya que nos abriría el
empaquetado. Para python3 podríamos declarar la variable como nonlocal para
que se busque en los ámbitos superiores:
def count():
num = 0
def aux():
nonlocal num
num += 1
return num
return aux
Como solución para salir del paso, se puede evitar la reasignación de variables. Por ejemplo, usando una lista:
def count():
num = [0]
def aux():
num[0] += 1
return num[0]
return aux
Ya sé que no es muy elegante, pero hay otras formas de hacerlo mejor.
Generadores
Una de las formas más comunes de usar clausuras es a través de generadores.
Básicamente, son funciones que en lugar de usar return utilizan yield para
devolver un valor. Entre invocaciones, se conserva el entorno de ejecución y
continúan desde el punto desde donde estaba. Para el ejemplo anterior:
def count():
num = 0
while True:
num += 1
yield num
c1 = count()
next(c1) # --> 1
next(c1) # --> 2
Objetos funciones
En los ejemplos que hemos visto, podríamos tener varias clausuras de una misma función. Si hemos hecho bien las tareas, la ejecución de estas clausuras son independientes:
c1 = count()
c2 = count()
next(c1) # -->1
next(c1) # -->2
next(c2) # -->1
next(c2) # -->2
next(c1) # -->3
Con ello es posible establecer una analogía con clases y objetos. La definición de la función sería la clase y la clausura la instancia de la clase.
¿Y si lo hacemos posible? En python se denominan callables a todo objeto que
tenga un método __call__, comportándose como si fueran funciones
(Functores). Contruyamos una callable que funcione como una función con clausura:
class Count(object):
def __init__(self):
self.num = 0
def __call__(self):
self.num += 1
return self.num
c1 = Count()
c1() # -->1
c1() # -->2
c1() # -->3
Sin duda es la manera más elegante de usar clausuras que tenemos en python. Evita muchos problemas y nos da una gran potencia a la hora de resolver algunos problemas.
Por ejemplo: imagina que queremos recorrer una lista de números, excluyendo los que sean pares, y siempre que la suma total de los números que ya hemos visitado no supere cierto límite.
En una primera aproximación se podría crear un generador:
def recorr(lista, maximo):
total = 0
for i in lista:
if i % 2 != 0:
if total + i < maximo:
total += i
yield i
else:
break
recorr([3, 6, 7, 8, 11, 23], 30) #-->[3,7,11]
Está bien, pero no es fácil de usar. Aunque sólo necesitemos algunos elementos,
seguramente estemos obligados a crear una lista completa con todos los
valores1. Encima, no tenemos acceso a la variable total para saber cuánto
han sumado el resultado.
Una alternativa con objetos funciones, mucho más elegante:
class RecorrFunc(object):
def __init__(self, maximo):
self.maximo = maximo
self.total = 0
def filter(self, item):
res = item % 2 != 0 and self.total + item < self.maximo
if res:
self.total += item
return res
def __call__(self, lista):
return [x for x in lista if self.filter(x)]
recorr = RecorrFunc(30)
recorr([3, 6, 7, 8, 11, 23]) # -->[3,7,11]
print(recorr.total) # -->21
Las posibilidades de los objetos función son muchas. Del mismo modo que se
devuelve una lista, sería posible devolver un iterador. Empleando las funciones
del módulo itertools, y algunos trucos más, podríamos aplicar los principios
de la programación funcional en python sin problemas.
Pero éso lo veremos en próximos artículos.
-
No sabemos de antemano cuántos items vamos a obtener. Si, por ejemplo, necesitamos sólo los tres primeros, tendremos que iterar elemento a elemento hasta llegar a los tres que necesitamos o, bien, hasta que quede exhausto el iterador. Con la solución con funtores el proceso es mucho más directo y eficiente. ↩
Funciones Lambda
Antes de ver qué son las clausuras (closures), veamos qué tienen las funciones lambda que las hacen tan polémicas algunas veces.
Comencemos con un ejemplo. Te recomiendo que te esfuerces en deducir cómo funciona sin ir a probar cómo funciona. A continuación te pondré algunos valores para que elijas los valores de las tres listas:
i = 1
add_one = lambda x: x + i
lista1 = [add_one(i) for i in [0, 1, 2]]
i = 0
lista2 = [add_one(i) for i in [0, 1, 2]]
i = 2
lista3 = [add_one(i + 1) for i in [0, 1, 2]]
Valores para lista1:
[0, 1, 2][1, 2, 3][0, 2, 4][1, 3, 5]
Valores para lista2:
[0, 1, 2][1, 2, 3][0, 2, 4][1, 3, 5]
Valores para lista3:
[0, 1, 2][1, 2, 3][2, 3, 4][1, 3, 5]
Las soluciones están al final del artículo1, pero puedes probarlo ahora para que lo veas tú mismo.
¿Qué es lo que ha pasado?
Contrariamente a lo que estamos acostrumbrados con las funciones normales, la
evaluación de una función lambda se hace dentro del entorno donde se ejecuta,
independiente del entorno donde se ha definido. Así pués, en la función lambda
lambda x: x+i, la variable i toma el valor de esta variable en el momento de
evaluar la función. Como se usa esta variable para la compresión de la lista,
irá cambiando de valor a medida que se recorre la lista [0,1,2], por lo que la
expresión add_one(i) termina convirtiéndose en la expresión i+i, y la
expresión add_one(i+1) en i+1+i.
Tiene un funcionamiento similar a los macros, donde se sustituye literalmente la llamada a la función por la expresión equivalente. En python3, se hace más evidente al denominarse expresiones lambda en lugar de funciones lambda.
Clausuras
En una función podemos distinguir dos partes:
- Código ejecutable
- Entorno de evaluación, más conocido por Ámbito o Scope
Antes de ejecutar el código de la función, se aumenta el entorno de evaluación con los argumentos de entrada de la función.
Según en qué entorno se evalua la función, tenemos dos ámbitos:
- Clausura, también llamado Ámbito léxico o Ámbito Estático, cuando la función se evalua en el entorno donde se ha definido.
- Ámbito dinámico cuando se evalua en el entorno donde se invoca la función.
Con esta definición, podemos afirmar que en python las funciones tienen ámbito léxico, con excepción de las funciones lambda que tienen ámbito dinámico.
No voy a considerar las ventajas de uno u otro tipo. Por lo general, las clausuras se consideran mejores para desacoplar el código de la función del código donde se invoca, lo que ayuda mucho al mantenimiento y corrección de errores. Es por ello la manera normal de crear funciones en la mayoría de lenguajes de programación.
¿Cómo hacer que una función lambda se comporte como si tuviera clausura?
La forma de hacer que un función lambda se evalue en el entorno donde se define consiste en pasar las variables de ese entorno que necesite en los argumentos de entrada, casi siempre como argumentos por defecto.
En el ejemplo anterior sería:
i = 1
add_one = lambda x, i=i: x + i
que equivaldrá a
add_one = lambda x, i=1: x + i
En este caso i se toma de los argumentos de la función, y tendrá por defecto
el valor de i en el momento de la definición de la función lambda.
No es perfecto, pero es lo mejor que tenemos. Lo recomendable es evitar las funciones lambda complejas si no queremos llevarnos algunas sorpresas.
-
Los valores de las listas son las opciones 3, 3 y 4, respectivamente. ↩
Para el quinto episodio sobre la serie de programación funcional, Andros Fenollosa presenta junto al compañero David Vaquero el lenguaje Scala, otro gran lenguaje que también hace uso de la máquina virtual de Java y es multiparadigma. Esto es una las diferencias con los otros lenguajes funcionales que se han tratado en esta serie. Scala es un lenguaje diseñado por Martin Odersky y que trae juntos dos paradigmas: la orientación a objetos y la programación funcional.
Entre las cuestiones discutidas en el episodio:
- ¿Qué pasó por tu cabeza para meterte en la programación funcional?
- Dime algunas características que te rompieron la cabeza y te enamoraron.
- ¿Qué es Scala?
- ¿Cuál es su origen?
- ¿Qué lo hace especial respecto a Clojure?
- ¿Quién lo usa? ¿Para quién está orientado?
- ¿Cuáles son tus frameworks favoritos?
- Hablemos sobre el Front-End. ¿Existe implementación?
- ¿Cuál crees que es el futuro del ecosistema?
- ¿Existe una comunidad?
- Recursos y consejos para grumetes.
- Anécdotas, ¿qué es lo peor y lo mejor que te has encontrado?
No te pierdas los otros episodios de la serie sobre programación funcional sobre Clojure, Elixir, Haskell y Elm.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

The Hero
MonkeyUser 04 01 2021
2020 Year in Review
Haki Benita 03 01 2021
What I've been up to in 2020...
How to open a file in Emacs
Murilo Pereira 03 01 2021
Re-solutions
Manuel Uberti 03 01 2021
I’ve been studying philosophy at Ca’ Foscari for about a year and half now, devoting most of my spare time to wonderful and wonderfully difficult books, and enjoying every part of this journey. There is still a lot of ground to cover because I see many gaps to fill and thoughts to process, but there is one thing that I am sure of: it’s going to be the journey of a lifetime.
I’ve not been so deeply fascinated and involved with something in a long while. Ask my wife and she is going to tell you that perhaps my love for cinema can match this passion for philosophy. I could agree, but cinema has not really been on my side lately1. Beside few exceptions2, 2020 will not be remembered for the films or the directors that inspired me to write.
The last days of 2020 were dedicated to planning new year’s resolutions. To be perfectly honest, I am not a great fan of new year’s resolutions. Most of the time I forget about them in a couple of months. To circumvent my poor will, I decided to keep the resolutions simple, small, and practical. This is what I wrote down on my BuJo:
- More books and less films
- More philosophy and less fiction
- Running
The first two are easy to adopt side by side. I watched way too many forgettable films last year, leaving the couch with the horrible feeling of time wasted. I do not want to repeat that. If there isn’t a film to watch, I want to turn off the TV, forget about my Blu-ray collection, and grab the book next to me.
As for the kind of book to pick up, I want to avoid contemporary fiction. There is nothing wrong with contemporary fiction, of course, but most of the contemporary books I read in 2020 proved to be little more than decent entertainment. There is so much to read, and it’s not just philosophy. I want more classics on my bedside table, and I want to read more from authors I love. Consider it a sabbatical. I intend to come back to contemporary fiction next year.
Finally, running. Let’s just say I stopped for no good reason and I am waiting for my contact lens to start again. As simple as this resolution looks, it’s also the most necessary one. Between work and studies the time I spend at my desk has become unhealthy, and I know how fresh air and exercise make me feel.
For all the good things in this planning, I see a couple of drawbacks here. If I manage to stick to these resolutions, computing is going to play a different role in my life. I will still be in front of my Emacs five days a week, but that’s about it. Whereas this means less tinkering and less githubbing, it also means less writing for my blogs. Nevertheless, for the sake of my priorities, I am willing to sacrifice writing just as I am willing to put cinema aside.
Happy new year.
Footnotes
-
The small number of articles published last year on my other blog, Films in Words, is telling. ↩
-
See Films in Words. ↩
Re-solutions
Manuel Uberti 03 01 2021
I’ve been studying philosophy at Ca’ Foscari for about a year and half now, devoting most of my spare time to wonderful and wonderfully difficult books, and enjoying every part of this journey. There is still a lot of ground to cover because I see many gaps to fill and thoughts to process, but there is one thing that I am sure of: it’s going to be the journey of a lifetime.
I’ve not been so deeply fascinated and involved with something in a long while. Ask my wife and she is going to tell you that perhaps my love for cinema can match this passion for philosophy. I could agree, but cinema has not really been on my side lately1. Beside few exceptions2, 2020 will not be remembered for the films or the directors that inspired me to write.
The last days of 2020 were dedicated to planning new year’s resolutions. To be perfectly honest, I am not a great fan of new year’s resolutions. Most of the time I forget about them in a couple of months. To circumvent my poor will, I decided to keep the resolutions simple, small, and practical. This is what I wrote down on my BuJo:
- More books and less films
- More philosophy and less fiction
- Running
The first two are easy to adopt side by side. I watched way too many forgettable films last year, leaving the couch with the horrible feeling of time wasted. I do not want to repeat that. If there isn’t a film to watch, I want to turn off the TV, forget about my Blu-ray collection, and grab the book next to me.
As for the kind of book to pick up, I want to avoid contemporary fiction. There is nothing wrong with contemporary fiction, of course, but most of the contemporary books I read in 2020 proved to be little more than decent entertainment. There is so much to read, and it’s not just philosophy. I want more classics on my bedside table, and I want to read more from authors I love. Consider it a sabbatical. I intend to come back to contemporary fiction next year.
Finally, running. Let’s just say I stopped for no good reason and I am waiting for my contact lens to start again. As simple as this resolution looks, it’s also the most necessary one. Between work and studies the time I spend at my desk has become unhealthy, and I know how fresh air and exercise make me feel.
For all the good things in this planning, I see a couple of drawbacks here. If I manage to stick to these resolutions, computing is going to play a different role in my life. I will still be in front of my Emacs five days a week, but that’s about it. Whereas this means less tinkering and less githubbing, it also means less writing for my blogs. Nevertheless, for the sake of my priorities, I am willing to sacrifice writing just as I am willing to put cinema aside.
Happy new year.
Footnotes
-
The small number of articles published last year on my other blog, Films in Words, is telling. ↩
-
See Films in Words. ↩
2020 Blogging Recap
blog.karenying.com 01 01 2021
Cuarto episodio de la serie especial sobre programación funcional dirigida por Andros Fenollosa. En esta ocasión se dedica al lenguaje Elm, algo particular debido a que ha sido diseñado para funcionar solo en el navegador web. Entre otras características podemos destacar que es declarativo, está influenciado por Haskell y diseñado para obtener robustez, usabilidad y rendimiento. Este lenguaje funcional hizo su aparición en el año 2012 gracias a Evan Czaplicki, creador de Elm.
Para este episodio sobre Elm, Andros cuenta con la compañía de David Hernandez, un profesional con más de 10 años programando para empresas de servicios y productos. Aunque principalmente ha estado con PHP, también ha podido tocar Javascript, Node, Python, Java y Elm, lenguaje que le ha traído a nuestro podcast. Sus roles han sido diversos: CTO, development manager y tech lead entre otros.
Entre las cuestiones discutidas en el episodio:
- ¿Cómo te metiste a la programación funcional?
- Origen y características de Elm
- Beneficios y diferencias de Elm
- Desventajas de Elm
- Frontend con Elm
- Futuro, comunidad y recursos
No te pierdas los otros episodios de la serie sobre programación funcional sobre Clojure, Elixir y Haskell.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Blogmas 2020
blog.karenying.com 25 12 2020
What a year this 2020. Beside the pandemic changing our lives in unpredictable
ways, from the perspective of my Emacs usage much was going on in my init.el
until I felt that a temporary break was necessary.
Most of my tinkering concerned the minibuffer and its completion mechanisms. I finished last year and started this one with Helm, but I am about to close 2020 with the built-in minibuffer completion and Embark providing candidates. A solution that Protesilaos Stavrou explored and which has been really suiting me.
Before detailing how I adapted his approach to my preferences, though, let me give you a bit of rationale. First, Helm rocks and it rocks hard. Its power is evident after a couple of hours with it. I briefly used Icomplete tweaked to display its results vertically, but I didn’t find it responsive enough to stick with it. Then I found out about Selectrum, which fixed the responsiveness but eventually was not adding a significant difference compared to Helm. True, Selectrum has a simpler codebase, but were I only to look at my daily interactions with Emacs, only the user interface can tell Helm and Selectrum apart.
Protesilaos took a different path. He wants to understand the code in front of him, so the less changes the better. In this regard Helm, Selectrum, and even Icomplete add a layer of indirection between him and the minibuffer. He is right in this. The minibuffer is more capable than the plethora of completion frameworks may suggest, and one can leverage its strength without forcing it to behave in a totally new way. Protesilaos’ reasoning got me thinking. Once again, am I looking for a solution from the outside before having really understood what lies underneath my beloved text editor?
Following Protesilaos’ steps, I set up the minibuffer to rely only on orderless
and Embark, with Consult chiming in for a some of operations like better history
in shell-mode and an improved apropos. What I added to Protesilaos’ code is the
only thing that I felt was missing: a command to search for the symbol at point
in my project, with the results displayed in an embark-live-occur window in
order to quickly jump to a specific entry. Over at the Consult’s GitHub there
are talks about a consult-rg utility which would serves this purpose, and there
has been suggestions of using project-find-regexp as well.
(defun mu-project-find-refs ()
"Use `project-find-regexp' to search for thing at point."
(interactive)
(if-let (tap (thing-at-point 'symbol))
(project-find-regexp tap)
(message "Nothing at point to search for")))
Easy enough to understand. However, if you, like me, set up Embark like
Protesilaos does you’ll notice that this command doesn’t show any candidate
unless you type something at the Jump to definition prompt. The candidates are
there already, though, so I have to avoid waiting for an input and display the
candidate list immediately.
The solution is straightforward: just remove embark-live-occur-after-input from
minibuffer-setup-hook and use embark-live-occur-after-delay instead. I added a
:before advice on mu-project-find-refs for this. The beauty of this advice is
that it works elsewhere as well. For instance, I have been using it for
consult-flymake and flyspell-correct-at-point too.
Note that this advice requires a little change to the original
minibuffer-setup-hook I have lifted from Protesilaos. Instead of adding
embark-live-occur-after-input to it I am using this to ensure only
embark-live-occur-after-input is present.
(defun mu-embark-live-occur-after-input ()
"Ensure only `embark-live-occur-after-input' is active."
(remove-hook 'minibuffer-setup-hook #'embark-live-occur-after-delay)
(add-hook 'minibuffer-setup-hook #'embark-live-occur-after-input))
Without a dedicated completion framework the minibuffer may feel rather basic at
first, but do not let it deceive you with its frugality. Like project.el, all it
needs is love.
What a year this 2020. Beside the pandemic changing our lives in unpredictable
ways, from the perspective of my Emacs usage much was going on in my init.el
until I felt that a temporary break was necessary.
Most of my tinkering concerned the minibuffer and its completion mechanisms. I finished last year and started this one with Helm, but I am about to close 2020 with the built-in minibuffer completion and Embark providing candidates. A solution that Protesilaos Stavrou explored and which has been really suiting me.
Before detailing how I adapted his approach to my preferences, though, let me give you a bit of rationale. First, Helm rocks and it rocks hard. Its power is evident after a couple of hours with it. I briefly used Icomplete tweaked to display its results vertically, but I didn’t find it responsive enough to stick with it. Then I found out about Selectrum, which fixed the responsiveness but eventually was not adding a significant difference compared to Helm. True, Selectrum has a simpler codebase, but were I only to look at my daily interactions with Emacs, only the user interface can tell Helm and Selectrum apart.
Protesilaos took a different path. He wants to understand the code in front of him, so the less changes the better. In this regard Helm, Selectrum, and even Icomplete add a layer of indirection between him and the minibuffer. He is right in this. The minibuffer is more capable than the plethora of completion frameworks may suggest, and one can leverage its strength without forcing it to behave in a totally new way. Protesilaos’ reasoning got me thinking. Once again, am I looking for a solution from the outside before having really understood what lies underneath my beloved text editor?
Following Protesilaos’ steps, I set up the minibuffer to rely only on orderless
and Embark, with Consult chiming in for a some of operations like better history
in shell-mode and an improved apropos. What I added to Protesilaos’ code is the
only thing that I felt was missing: a command to search for the symbol at point
in my project, with the results displayed in an embark-live-occur window in
order to quickly jump to a specific entry. Over at the Consult’s GitHub there
are talks about a consult-rg utility which would serves this purpose, and there
has been suggestions of using project-find-regexp as well.
(defun mu-project-find-refs ()
"Use `project-find-regexp' to search for thing at point."
(interactive)
(if-let (tap (thing-at-point 'symbol))
(project-find-regexp tap)
(message "Nothing at point to search for")))
Easy enough to understand. However, if you, like me, set up Embark like
Protesilaos does you’ll notice that this command doesn’t show any candidate
unless you type something at the Jump to definition prompt. The candidates are
there already, though, so I have to avoid waiting for an input and display the
candidate list immediately.
The solution is straightforward: just remove embark-live-occur-after-input from
minibuffer-setup-hook and use embark-live-occur-after-delay instead. I added a
:before advice on mu-project-find-refs for this. The beauty of this advice is
that it works elsewhere as well. For instance, I have been using it for
consult-flymake and flyspell-correct-at-point too.
Note that this advice requires a little change to the original
minibuffer-setup-hook I have lifted from Protesilaos. Instead of adding
embark-live-occur-after-input to it I am using this to ensure only
embark-live-occur-after-input is present.
(defun mu-embark-live-occur-after-input ()
"Ensure only `embark-live-occur-after-input' is active."
(remove-hook 'minibuffer-setup-hook #'embark-live-occur-after-delay)
(add-hook 'minibuffer-setup-hook #'embark-live-occur-after-input))
Without a dedicated completion framework the minibuffer may feel rather basic at
first, but do not let it deceive you with its frugality. Like project.el, all it
needs is love.

Seguro que alguna vez nos hemos preguntado por que desde hace unos días nuestra distribución de Linux tarda mas de lo habitual en arrancar, o sencillamente nos hemos planteado hacer un arranque del sistema en tiempo record.
Pues ahora os vamos a presentar una utilidad que nos lo va a poner mas facil que nunca!
Con systemd-analyze vamos a poder identificar a los culpables de esos inicios lentos o que nos causan problemas.
Si lo invocamos sin parametros con systemd-analyze obtendremos la siguiente salida:
No es muy impresionante, pero con esta vista general del firmware, gestor de arranque, kernel y espacio de usuario ya empezamos a tener una noción de donde se nos vá la mayor parte del tiempo.
Si queremos mas detalles y ver los servicios uno a uno, vamos a utilizar el parametro blame: systemd-analyze blame
Esto ya es otra cosa y ya podemos señalar con el dedo a los culpables de nuestros lentos inicios del equipo. Ahora solo quedaría desactivar los servicios que nos estén causando problemas y a volar.
Pero, y si a mi no me gusta todo este ladrillo de texto y se me hace de noche intentando descifrar numeros y servicios?..
No digas más, el parametro plot viene al rescate. Si usamos este parametro y además redirigimos la salida a una imagen tal que así: systemd-analyze plot > analisisgrafico.svg
Obtendremos una gŕafica como esta que nos facilitiará aún mas si cabe el diagnostico e identificación de procesos lentos.
Espero que el conocimiento de esta útil herramienta os sea de ayuda en vuestros diagnosticos!
Episodio dedicado a comentar el estupendo artículo de Werner Vogels, CTO y vicepresidente de Amazon, titulado 8 predicciones sobre como la tecnología continuará cambiando nuestras vidas en el 2021. Este artículo publicado en su blog personal All Things Distributed, es un análisis de gran interés para comprender los cambios que la tecnología producirá no sólo en el 2021, sino también la próxima década.
Werner Vogels demuestra un conocimiento global del impacto de la tecnología y cómo las tecnologías de Amazon Web Services están a la vanguardia de muchas tendencias tecnológicas. Otro punto muy destacable es la absoluta confianza en la capacidad de la tecnología para mejorar nuestras vidas. Al contrario que la visión pesimista de otras personas con respecto a la tecnología, Werner desborda optimismo y un total convencimiento de que el acceso asequible a la tecnología ayudará a que muchas regiones del planeta mejoren su calidad de vida.
Las 8 predicciones de Werner Vogels para el 2021 y más adelante son:
- Predicción 1. La nube estará en todas partes.
- Predicción 2. La internet del aprendizaje automático
- Predicción 3: En el 2021 imágenes, video y audio hablarán más que las palabras.
- Predicción 4: La tecnología transformará nuestros mundos físicos tanto como los mundos digitales.
- Predicción 5. El aprendizaje en remoto se gana su sitio en la educación.
- Predicción 6. Los negocios pequeños se lanzarán a la nube y Sudeste asiático y el áfrica subsahariana liderarán el camino.
- Predicción 7. La computación cuántica comenzará a florecer.
- Predicción 8. La frontera final…
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
2020 In Review
Josh Comeau's blog 23 12 2020

Seguramente os habréis encontrado con que en Linux hay bastantes problemas con el tema del ruido de fondo en las grabaciones con micrófono. Y en las ultimas versiones se ha agrabado el inconveniente, hasta ahora!
Con este sencillo tutorial vamos a crear una nueva entrada de audio filtrada para deshacernos del molesto ruido de fondo del micriófono. Estas indicaciones funcionan para los problemas con Ubuntu, Linux Mint, Debian, etc.
Abriremos una ventana de terminal, y editaremos el fichero /etc/pulse/default.pa para añadir el filtro de cancelación de ruido de pulseaudio al final del fichero donde veremos que se cargan otros módulos similares.
Abriremos un terminal y escribimos:
[code]sudo nano /etc/pulse/default.pa[/code]
Nuestro fichero actual, al final del mimsmo, debería contener algo así, y es ahí donde debemos añadir el filtro de cancelación de ruido:
[code]### Modules to allow autoloading of filters (such as echo cancellation)
### on demand. module-filter-heuristics tries to determine what filters
### make sense, and module-filter-apply does the heavy-lifting of
### loading modules and rerouting streams.
load-module module-filter-heuristics
load-module module-filter-apply[/code]
Añadimos el filtro de cancelación de ruido "load-module module-echo-cancel" al final de esas opciones, quedando algo así:
[code]### Modules to allow autoloading of filters (such as echo cancellation)
### on demand. module-filter-heuristics tries to determine what filters
### make sense, and module-filter-apply does the heavy-lifting of
### loading modules and rerouting streams.
load-module module-filter-heuristics
load-module module-filter-apply
load-module module-echo-cancel[/code]
Una vez añadido, reiniciaremos el servicio de audio con el siguiente comando (Ojo, si conectamos un nuevo micrófono, posiblemente debamos recargar pulseaudio de nuevo este comando):
[code]pulseaudio -k[/code]
Veremos que nos han aparecido nuevos dispositivos de control en los ajustes de sonido de nuestra distribución, seleccionaremos la nueva entrada de micrófono con cancelación de audio activa.
Espero que noteis una mejoría en vuestras grabaciones :)
Seguramente mas de uno habréis querido instalar Fedora en vuestros equipos con potentes tarjetas graficas de Nvidia solo para terminar dejandolo por imposible por la cantidad de trabas y problemas que nos han puesto los de nvidia con su limitado soporte. Pues vamos a acabar con esto de golpe con un tutorial que nos permitirá cambiar el driver de codigo abierto nouveau por el propietario de Nvidia.
Bueno, vamos al lío. Preparaos por que vienen curvas :)
**Este tutorial solo funciona con escritorio x11**
1.- Antes de empezar con la instalación de nuestros drivers NVIDIA, vamos a comprobar que nuestra tarjeta esta soportada.
Para ello vamos a lanzar en nuestra terminal (Ctrl + ALT + T) el siguiente comando:
[code]lspci |grep -E "VGA|3D"[/code]
Nos tiene que aparecer algo como esto:
[code]01:00.0 VGA compatible controller: NVIDIA Corporation TU106 [GeForce RTX 2060 Rev. A] (rev a1)[/code]
Chequea el mejor driver de tu tarjeta grafica en este enlace: lista
Si tienes activado UEFI Secure BOOT, hay que desactivarlo desde la BIOS.
2.- Instalar los drivers propietarios de NVIDIA y desactivar el driver nouveau.
Para descargar el paquete instalador de NVIDIA iremos al siguiente enlace y buscamos la ultima versión del driver de nuestra tarjeta.
Una vez hayamos buscado y descargado nuestro driver vamos a hacer ejecutable el .run que se nos ha descargado. Para ello ejecutamos en la terminal el siguiente comando:
[code]chmod +x /Descargas/NVIDIA-Linux-*.run[/code]
- Cambiamos al usuario root con:
su -## O ##sudo -i
- Asegurate de que tu sistema esta actualizado y estas con el ultimo kernel.
[code]dnf update[/code]
- Después de actualizar reinicia el equipo e inicia con el ultimo kernel.
reboot
- Instalamos las dependencias necesarias:
dnf install kernel-devel kernel-headers gcc make dkms acpid libglvnd-glx libglvnd-opengl libglvnd-devel pkgconfig
- Desactivamos nouveau. Podemos crear o editar etc/modprobe.d/blacklist.conf
Añadimos ‘blacklist nouveau’
[code]echo "blacklist nouveau" >> /etc/modprobe.d/blacklist.conf[/code]
-Editamos etc/default/grub
Añadimos ‘rd.driver.blacklist=nouveau’ al final de ‘GRUB_CMDLINE_LINUX=”…”‘.
## Fedora 34 BTRFS ##GRUB_CMDLINE_LINUX="rhgb quiet rd.driver.blacklist=nouveau"## O CON LVM ##GRUB_CMDLINE_LINUX="rd.lvm.lv=fedora/swap rd.lvm.lv=fedora/root rhgb quiet rd.driver.blacklist=nouveau"
- Actualizamos grub2 conf
## BIOS y UEFI ##grub2-mkconfig -o /boot/grub2/grub.cfg
- Borramos xorg-x11-drv-nouveau
[code]dnf remove xorg-x11-drv-nouveau[/code]
- Generamos initramfs
## Copia de seguridad antigua imagen nouveau ##mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r)-nouveau.img"## Crear nueva imagen initramfs ##dracut /boot/initramfs-$(uname -r).img $(uname -r)"
- Reiniciar en runlevel 3
systemctl set-default multi-user.targetreboot
- Ahora vamos a instalar los drivers propietarios en modo texto. Nos loguearemos y volvemos a entrar como usuario root de la siguiente manera:
su -## O ##sudo -i
-Ejecutamos el instalador del driver que en este caso sera un .run de la siguiente manera:
./NVIDIA-Linux-*.run## O ruta completa ##/home/usuario/Descargas/NVIDIA-Linux-x86_64-xxx.xxx.xx.run
- Registar los módulos fuente del núcleo con DKMS:
- Bibliotecas de compatibilidad de 32 bits:
- Instalando controladores y construyendo el módulo del kernel:
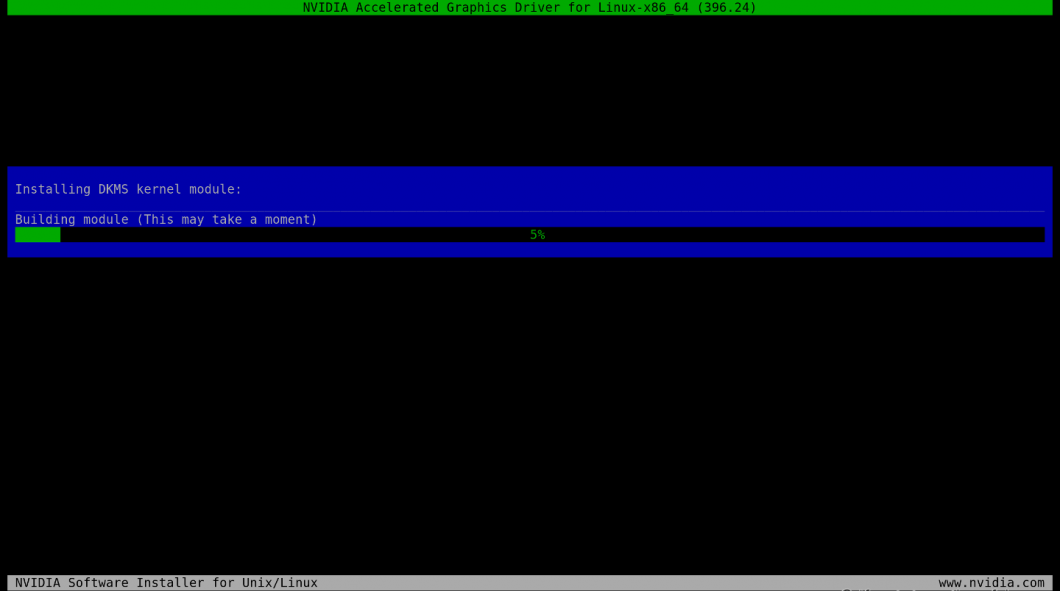
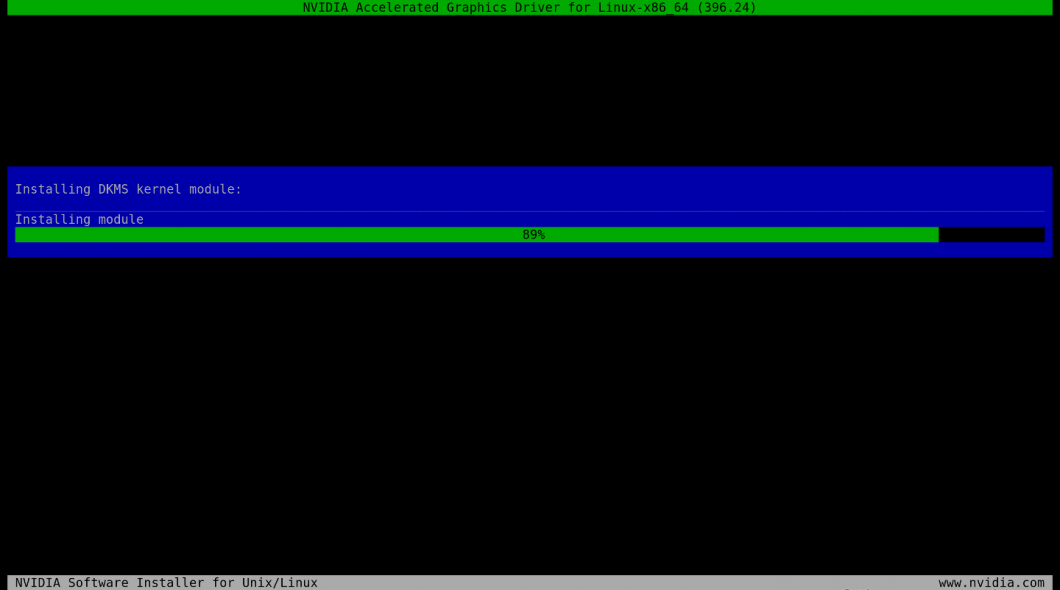
- Instalador automático de configuración y copia de seguridad de Xorg:
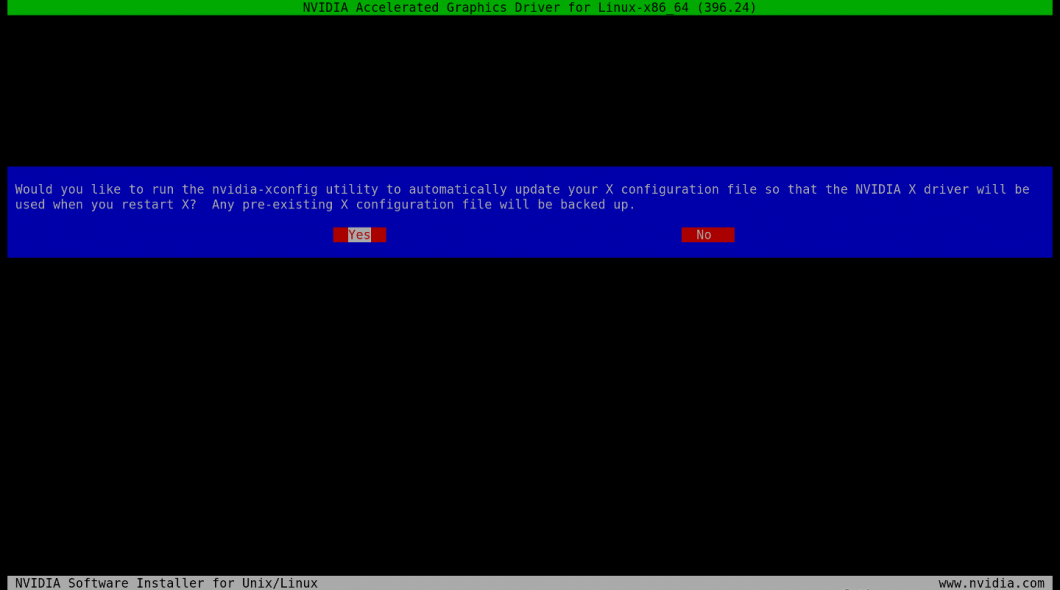
- Instalación de drivers completada:
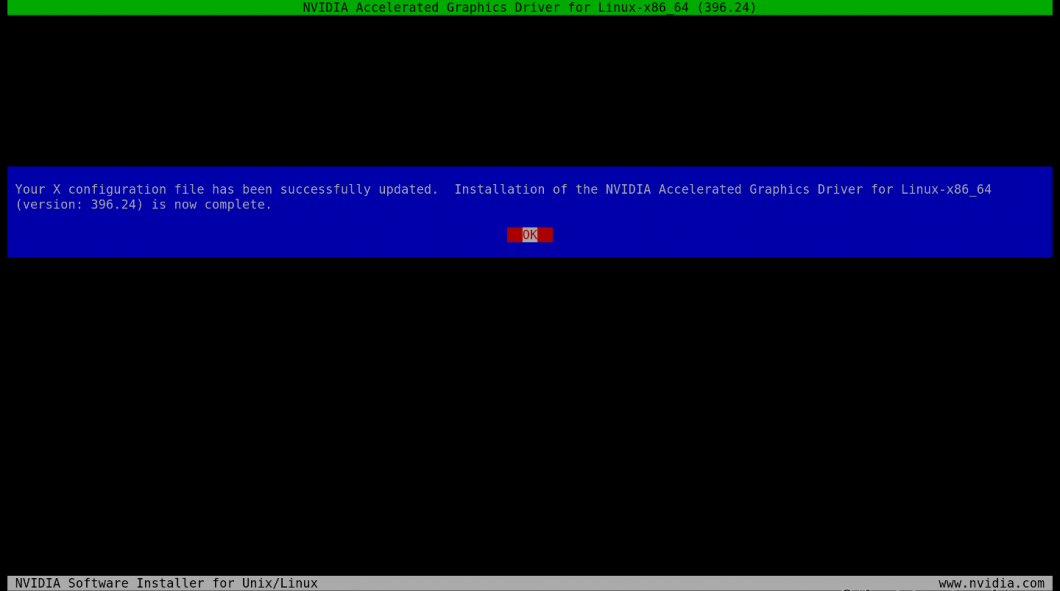
- Ya está todo hecho y reiniciamos de nuevo en runlevel5
systemctl set-default graphical.targetreboot
- Soporte VDPAU/VAAPI
Habilitar el soporte de aceleración de vídeo (Nota: necesitas Geforce 8 o posterior).
[code]sudo dnf install vdpauinfo libva-vdpau-driver libva-utils[/code]
- Para poder abrir nvidia-settings, tienes que hacer lo siguiente:
ALT + F2 y escribir nvidia-settings
3.- Capturas de pantalla usando nvidia settings con kernel 5.11.16
** El driver de nvidia en el kernel 5.11.17 no funciona. Una vez pasas al kernel 5.11.18 vuelve a funcionar sin problemas, por ello mismo hemos bloqueado que suba o baje automáticamente de kernel. No obstante si quieres eliminar el bloqueo y poder escalar de kernel, te dejo el comando para hacerlo.**
[code]sudo dnf versionlock delete kernel-x.x.xx-xx.xxx[/code]
SciCloj #18: Introducing Skija
tonsky.me 23 12 2020
La crisis derivada de la Covid-19 ha marcado un precedente en la economía global y un punto de inflexión en el ecosistema digital, con el consiguiente impacto en la inversión publicitaria como consecuencia del cambio en la forma en la que compramos, consumimos medios y trabajamos.
The post Cómo ha afectado la Covid-19 en la inversión publicitaria appeared first on No sin mis cookies.
Primer episodio de Informe Nube, una nueva serie dedicada a la actualidad de las tecnologías cloud y contenedores. David Vaquero y Antony Göetzschel repasan diferentes noticias relacionadas con la nube, ofreciendo su particular análisis. Este primer episodio de la serie, trae muchas cuestiones de gran interés para los profesionales del cloud.
Para empezar la serie David y Antony comienzan con una de las noticias más controvertidas de los últimos meses: el cambio de dirección en CentOS Linux, la distribución surgida de un fork de Red Hat Entreprise Linux, hacia CentOS Stream. Este cambio deja en el aire muchas instalaciones de CentOS. Para entender este movimiento es importante comprender el flujo del desarrollo de este sistema y también los intereses de IBM como propietaria de Red Hat. Por supuesto, la comunidad de software libre no ha dudado en buscar alternativas.
En la segunda parte del episodio se dedica a hablar sobre como Kubernetes no requiere Docker como entorno de ejecución. Sin duda, un movimiento que muestra la diversidad y velocidad de los cambios que existen en estas tecnologías.
Otro tema de conversación en el episodio consiste en la idoneidad de presentarse a ofertas laborales, aunque no tengas todos los conocimientos que exigen.
Como es un episodio de arranque, David y Antony continúan con más temas. Uno viene a raíz de un vídeo de Pelado Nerd. ¿Cuál es la mejor solución para un cluster de Kubernetes? y el último bloque se dedica a comentar que Rancher presenta Harvester una solución HCI (Hyper-Converged infrastructure).
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Tercera entrega de la serie especial dedicada a la programación funcional presentada por Andros Fenollosa. En este tercer episodio le toca el turno a Haskell de la mano de Héctor Navarro, profesor e investigador en el área de Algoritmos y Lenguajes de Programación. Héctor Navarro actualmente trabaja como Ingeniero de Software en Amazon.com. Desde el año 2000 hasta 2018 ha desempeñado su labor de investigador y profesor en la Universidad Central de Venezuela. A pesar de usar primordialmente Java en trabajo diario, sigue siendo un gran entusiasta de Haskell y de la programación funcional.
Haskell es un lenguaje de programación funcionalmente puro, con tipado estático y evaluación perezosa. Su nombre fue otorgado por Haskell Curry, matemático y lógico estadounidense que aportó el cálculo Lambda (un sistema para definir funciones y recursión creado por el matemático y lógico Alonzo Church), siendo este muy influyente dentro del lenguaje. Con Héctor Navarro tenemos oportunidad de tratar interesantes cuestiones del lenguaje:
- ¿Qué pasó por tu cabeza para meterte en la programación funcional?
- Dime algunas características que te rompieron la cabeza y te enamoraron.
- ¿Qué es Haskell y cuál es su orgien?
- ¿Qué lo hace especial respecto a otros lenguajes?
- ¿Quién usa Haskell y para quién está orientado?
- ¿Qué son las monadas?
- ¿Cuáles son tus frameworks favoritos?
- Hablemos sobre el Front-End. ¿Existe implementación? ¿Tal vez Elm?
- ¿Cuál crees que es el futuro del ecosistema?
- ¿Existe una comunidad?
- Recursos y consejos para grumetes.
En esta interesante conversación Héctor Navarro nos cuenta detalles relevantes sobre Haskell, aplicaciones, usos, herramientas y recursos.
No olvidéis escuchar y visitar los enlaces de los dos primeros episodios de la serie sobre programación funcional:
- Descubriendo la programación funcional – Elixir con Erick Navarro
- Descubriendo la programación funcional – Clojure con Vachi
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Aprende a invertir de forma inteligente en la compra de enlaces para cumplir los objetivos de tu negocio y sin tirar el dinero.
The post Guía para comprar enlaces en blogs y periódicos appeared first on No sin mis cookies.
A quick post to celebrate the birth of another Common Lisp application running in production©. This time, it is not open source, but I can describe it.
It is used by bookshops in France and Belgium to upload there catalogue to online platforms. And no, they don’t know, and don’t need to know, the language it is implemented in!
It is a simple application that reads data from an existing DB, builds a text file with special rules, sends the file to an FTP server, and does it every day. I used cl-dbi with raw SQL queries, cl-ftp (does its job perfectly), and a CRON job. I built a binary that I sent to my server. It is a stand-alone application that reads a DB that is created by a bigger Python/Django web app (that I also develop). I didn’t want to make this one more bloated, so given the goals are complementary but orthogonal, I went with a stand-alone tool.
That’s it. One more!
Another tool I am running connects to a SOAP service, shows data on a website (with Sentry configured in production), sells products with Stripe and sends emails with Sendgrid. And I (generally) update it while it runs by connecting to the Lisp REPL. Just throwing out buzzwords to you.
While I’m at it, let me stress one point, to answer in advance a kind of feedback I already had: no, the resulting application doesn’t use any Lisp superpower and yes, I could have written it in Python. It turns out Lisp is as suited as Python for this task (or then it is more suited, since it is faster), the point is I benefited from Lisp’s superpowers during development (by using the superior REPL, being able to build a binary and all that). In conclusion: there are tons of places where Lisp can be used for professional needs out there.
Oh. In doing it, I built those two utilities:
- progressons, a progress bar that holds on one line and works on the terminal as well as on Slime. It works for me©. My next goal is to make it output a prettier bar with unicode bars.
- termp, a trivial utility that checks if we are on a real or on a dumb terminal (by checking the
TERMenvironment variable). So you canquitorerrorout.
Two more Lisp repositories on Github !
I recently enjoyed this discussion on the pro mailing list. It started with a call of recommendations on music software, and the discussion evolved in discussing parallel garbage collection. By the way, can you site an implementation that has parallel GC?
Pascal Costanza:
«When moving our elPrep software away from Common Lisp, we evaluated C++, Go and Java as potential candidates, and Go turned out to provide the best balance between performance and memory use. We are still using Common Lisp for prototyping, and then translate to Go. These two languages are actually much more similar than it appears at first. […]»
«This was primarily for the lack of good parallel, concurrent garbage collectors in Common Lisp implementations. The CL version of elPrep was actually still a tad faster than any of the C++, Go, or Java versions, but we had to work hard to avoid long GC pauses. elPrep allocates a lot of memory, and the pause time hurts a lot. We solved this by, basically, disabling the garbage collector, and reusing memory manually as much as possible, which turned the program into almost a manually memory-managed affair.»
«Manual memory management became a huge burden because we wanted to add more and more components to the software, and then it becomes almost impossible to predict object lifetimes.»
«We evaluated Go and Java for their concurrent, parallel GCs, and C++ for its reference counting. Interestingly, reference counting is often described as more efficient than GC, but in our case that’s not true: Because there is a huge object graph at some stage that needs to be deallocated, reference counting incurs more or less the same pause that a non-concurrent GC does. That’s why we don’t expect Rust to fare better here either.»
«Again, we’re still prototyping in Common Lisp, which is a huge win, because this makes us much more productive.»
«In my opinion, prototyping in Common Lisp, and then translating to a different programming language for creating the final product, is a perfectly valid professional use of Common Lisp. It’s useful to know which programming languages may be good targets for such an approach. This is, of course, not ideal, because this can easily be misunderstood as a statement that Common Lisp is not fit for purpose. However, I don’t see it that way, and you cannot control people’s perceptions. In our particular case, our manager is on board with this approach, and this allows us to pay for regular licenses for LispWorks. The approach works really well for us.»
Didier Verna:
«I’d be curious to know if there are particularities in CL itself that make this difficult, or if it’s simply because there’s no manpower to improve the GCs we have currently.»
Stelian Ionescu:
«It’s strictly a lack of manpower. Most CL implementations have GCs that were state-of-the-art 25 years ago: they’re either mark-and-sweep or copying & generational, and have to perform all collection while application threads are paused (i.e. stop-the-world), hence the collection pauses that are proportional to the heap size.»
«The newer GCs of Go and the JVM (ZGC and Shenandoah) are not generational and employ techniques such as pointer coloring and store/load barriers by instrumenting all object read/write operations instead of using virtual memory protection (which tends to have a non-indifferent performance penalty), and because they rely heavily on atomic operations to maintain heap consistency the stop-the-world phase is much shorter and only required to update the internal GC metadata. The result is that instead of 99th percentile pauses of 10+ seconds that we see with QPX or other allocation-heavy applications, these newer GCs show 99th percentile pauses of < 10ms, and perhaps medians going from ~500ms to 2ms (YMMV).»
«Here’s a pretty good description of the difference between the two new JVM collectors and how they compare to the older ones: https://www.youtube.com/watch?v=WU_mqNBEacw.»
Martin Cracauer:
«No, it’s as possible as in other languages. Some people don’t want to pay the overall performance penalty for concurrent GC (as in total CPU time/energy spent for any given piece of work).»
«This particularly applies to applications that are query-based, and hence want to be as fast as possible in the non-GC part, and can GC between queries. ITA’s QPX is an example (although they do desire concurrent GC for better monitoring in the production environment).»
«Parallel GC is no problem and implemented.»
Pascal Costanza:
«Which CL implementations have a parallel GC?»
Jeff Caldwell:
«From Franz’s doc on Allegro CL: https://franz.com/support/documentation/10.0/doc/gc.htm#multi-threading-2»
Martin Cracauer:
«Clasp (via Boehm GC and MPS).»
«I thought SBCL was there, but I just checked, not yet. I think Google is pushing for a parallel GC instead, because of response times to their production monitoring.»
«Another untapped source of performance is userfaultfd(2) in the Linux kernel. It allows those GCs that implement a write barrier using page protections SIGSEGV to use the faster userfaultfd interface instead (as opposed to those using a bitmap). This won’t help concurrent GC, but parallel GC would benefit even more than single-thread GC because it uses faster system calls. Proof of concept is here: https://www.cons.org/cracauer/cracauer-userfaultfd.html»
and:
Don’t the latest incarnations of ECL use the Bohem GC?
Daniel Kochmański:
«They do, we plan to resurrect the homegrown gc as an alternative though.»
Refreshing Server-Side Props
Josh Comeau's blog 14 12 2020
GitHub Dark Mode is Too Dark
blog.karenying.com 12 12 2020
Para este episodio vuelve a acompañarnos en el podcast la diseñadora y desarrolladora web Valentina Rubane. Ella trabaja junto a Andros en Sapps, el estudio de desarrollo de aplicaciones móviles y PWA en Valencia. En este episodio hablamos de los motivos por los que Vue.js es la elección de Sapps para estudio para trabajar el desarrollo de sus aplicaciones.
Valentina y Andros nos cuentan entre otras muchas cosas:
- Evolución de Vue.js
- Novedades de Vue.
- Herramientas de desarrollo con Vue.js
- Vue.cli y trabajo con componentes y librerías CSS.
- Aprendizaje y metodologías de uso.
- Trabajos y experiencias con proyectos de clientes.
Sapps es el estudio surgido de Pixel Mouse y está especializados en desarrollo de aplicaciones web, móviles y también PWA. En la actualidad lo forma un grupo de varias personas con experiencia en las diferentes capas de un proyecto en internet.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
We’re glad you could make it this week!
With your help, we can make Pony Foo Weekly even more awesome: send tips about cool resources.
|
|
|

|

|
Hands-Free Coding
Josh Comeau's blog 09 12 2020
Exhaustiveness Checking with Mypy
Haki Benita 07 12 2020
What if mypy could warn you about possible problems at "compile time"? In this article I share a little trick to get mypy to fail when a value in an enumeration type is left unhandled.
Se acerca el final de un año que ha dejado más claro que nunca lo difícil que resulta realizar predicciones. Todavía más en un sector tan endiablado como el desarrollo web. Por eso hemos pensado para este episodio del podcast, tratar más sobre direcciones y tendencias profesionales, en lugar de hacerlo más sobre ciertas tecnologías. Para ello planteamos un episodio con dos cuestiones de gran interés.
¿Qué habilidades o competencias tendrán más valor en el futuro de la profesión de desarrollo web?
En esta primera parte del episodio aportamos nuestra opinión, acerca de las competencias que tendrán más importancia en la profesión del desarrollo web. Entre varias cuestiones que aportamos:
- Trabajo en equipo, distribuido y en remoto.
- Competencia en comunicación y habilidades que impliquen responder mejor y más rápido a las necesidades del cliente.
- Capacidad de adaptación, concentración y flexibilidad mental.
- Herramientas de UI/UX.
- Interactividad con servicios o APIs de terceros.
- Configuración de herramientas No Code para uso final.
- Abuso de la figura de los becarios.
- Arquitectura
- Integración de sistemas.
- Desarrollo de producto.
- Conservación/atracción de equipos y talento
¿Qué tecnologías consideráis que serán absolutamente necesarias en los próximos años?
En este segundo apartado ya intentamos hablar más sobre tecnologías y herramientas que ayudarán al trabajo del desarrollo web. Entre varias hablamos de:
- Frameworks front y back.
- Herramientas todo en uno para computación en la nube (AWS)
- Seguridad.
- Testing.
- CI / CD.
- Web Components.
- Swagger open api
- Entornos desacoplados
- JWT – OAUTH
- Linux
- Docker
- Notion
- Emacs
En este apartado también hablamos sobre cómo los frameworks y las librerías CSS han cubierto gran parte de las necesidades de maquetación y animación que muchos proyectos web requieren.
Por último indicar que estaremos encantados de recibir vuestras aportaciones a esta cuestión del futuro del desarrollo web.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
La memoria del dato
Onda Hostil 05 12 2020
Andros Fenollosa sigue con su serie especial sobre Programación Funcional con Elixir. Para ello cuenta esta vez desde Perú, con el compañero Erick Navarro, un experimentado programador en Python, JavaScript y por supuesto en Elixir.
Elixir, un lenguaje de programación funcional, concurrente, de propósito general que se ejecuta sobre la máquina virtual de Erlang (BEAM). Al funcionar sobre Erlang comparte las mismas abstracciones para desarrollar aplicaciones distribuidas y tolerantes de fallos.
Elixir destacado en el sector con empresas que han confiado es sus capacidades, como Pinterest o Discord. Su comunidad es tan grande que se realizan diferentes encuentros anuales e EEUU, Europa y Japón. Andros conversa con Erick sobre diferentes cuestiones:
- Elixir, origen y diferencias con otros lenguajes.
- Usos y aplicaciones de Elixir.
- Frameworks de Elixir
- Uso en frontend.
- Comunidad y recursos.
- Futuro del lenguaje.
Este episodio es el segundo en una serie especial de Programación Funcional presentada por Andros Fenollosa. Escucha el primer episodio sobre Clojure.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Updated Debian 10: 10.7 released
Debian News 05 12 2020
buster). This point release mainly adds corrections for security issues, along with a few adjustments for serious problems. Security advisories have already been published separately and are referenced where available.

Circle of AI Life
MonkeyUser 04 12 2020
Fusionar commits
Óscar Lijó 03 12 2020
¿Por qué fusionar commits? Fusionar commits es una de las cosas mas chulas que podemos hacer, manipular la historia de nuestro proyecto hace que este sea mucho más legible y que podamos encontrar el cambio que queremos más rápido. A quien no le ha pasado que aunque estaba trabajando en una tarea, ha acabado subiendo…
La entrada Fusionar commits aparece primero en Óscar Lijó.

Instapaper Weekly Sponsorship
Instapaper 03 12 2020
We are excited to announce that we are once again opening up sponsorship slots on the Instapaper Weekly email.
About Instapaper Weekly
Instapaper Weekly is an algorithmically-generated newsletter that goes out every Sunday. The email contains the most popular highlight created by all Instapaper users for the week and a list of the most popular articles saved to Instapaper for each day of the past week.
The Weekly is currently delivered to approximately 3 million Instapaper users. The open rate on the mailer is 7.7 percent, with an average click-to-open rate of 0.8% on advertisements.
Why Sponsorships?
By design, the Instapaper Weekly is a reflection of what our readers consider to be the most important and noteworthy topics for a given week. Sponsoring the Weekly places your content amongst the best content Instapaper has to offer and provides access to a large, engaged audience of tech-oriented and well-read professionals.
Sponsoring
As the Weekly compiles content our users found most compelling, we will be holding our sponsorship choices to the same standards of high quality. Your sponsored content should fit within our existing format for Instapaper Weekly and consist of a link, title, description, and thumbnail image. Ideally, the link would be something that our mobile-centric users can save to Instapaper for later reading.
We will run the sponsorship between the “Top Highlight” and “Most Popular” sections of the weekly email:
We are currently charging a flat rate of $2,500 for advertisements in the Instapaper Weekly, and offer one placement per week.
If you’re interested in sponsoring the Instapaper Weekly, please email us at sponsors@instapaper.com.
– Instapaper Team
Los tiempos han cambiado. El currículum es más que una carta de presentación. Es tu marca, tu identidad, la que te diferenciará respecto a tus competidores. Descubre cómo adaptarlo al mundo digital y enamora a tu futura empresa.
The post Tres claves para hacer un currículum exitoso appeared first on No sin mis cookies.
Con la llegada de la nube hemos tenido que aprender una serie de términos que no estabamos acostumbrados a escuchar. Algunos de ellos son los que aparecen en el título de esta entrada. Aunque pueden parecer un trabalenguas son bastante sencillos de entender ya que todos hacen referencia a lo mismo, al nivel de gestión…
La entrada Diferencias entre IaaS, CaaS, PaaS, FaaS y SaaS aparece primero en Óscar Lijó.
Este es el primer episodio de una serie especial del podcast dirigida a descubrir la programación funcional. Andros Fenollosa charla con diferentes invitados sobre el paradigma de la programación funcional, los lenguajes más destacables, herramientas y el cambio de mentalidad a la hora de afrontar este tipo de programación, especialmente si vienes de la programación orientada a objetos.
Para este primer episodio Andros ha invitado a Vachi, un programador especializado en Clojure y actualmente trabajando en una fintech. Con Vachi habla sobre el lenguaje Clojure, sus características más destacables, principios de programación y lo que hace de Clojure un lenguaje tan atractivo para muchas empresas. También hablan de la comunidad de Clojure y recursos de interés para los que quieran comenzar con Clojure.
Clojure es un lenguaje multiparadigma de propósito general creado por Rich Hickey como un dialecto de Lisp y orientado a trabajar con los datos a través de funciones. A diferencia de otros lenguajes como Python o C, Clojure se ejecuta sobre la JVM (Máquina virtual de Java).
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Tabla de códigos de estado HTTP
Óscar Lijó 27 11 2020
Una tabla de códigos de estado HTTP siempre hace falta, aqui tienes una bastante completa por si ese código no te suena 1×× Informativo Código Estado Descripción 100 Continue El servidor recibe la parte inicial de la solicitud, la da por buena y tiene intención de responder cuando la tenga toda 101 Switching Protocols El…
La entrada Tabla de códigos de estado HTTP aparece primero en Óscar Lijó.

Welcome To Hell
MonkeyUser 27 11 2020
Simple React Router Nav Bar
blog.karenying.com 22 11 2020
Los procesos creativos y el diseño web muy a menudo suelen enfrentarse a la barrera de la codificación y las limitaciones técnicas. Desde aquellos primeros sitios web de aspecto plano y poco atractivo, la tecnología del diseño web ha ido incorporando herramientas que ayuden a expresar de mejor manera la creatividad de los diseñadores. Aunque los creadores de sitios web puedan contar con infinidad de posibilidades para comunicar sus ideas, sigue existiendo esa barrera que impone la disciplina del código.
¿Debes ser programador para realizar tu propia página web o vivir haciendo páginas web para los demás? Son muchas las herramientas que existen para facilitar la construcción visual de sitios web, pero muchas veces los inconvenientes de utilizar esas herramientas exceden con el tiempo a su conveniencia.
Como ya hemos comentado en algún episodio, el auge de las herramientas “no code” está consiguiendo que la barrera de entrada se reduzca y al mismo tiempo, está consiguiendo el acceso a la tecnología web a un público con muchísimo que aportar a la experiencia de los sitios web.
Para este episodio invitamos a Xavi Barrachina, impulsor de la comunidad Webflow Valencia y fundador de la agencia Masflow especializada en diseño web a través de la plataforma de diseño web no code Webflow. Xavi es un emprendedor nato, apasionado del diseño, la innovación y la estrategia creativa. Con él queremos hablar de Webflow y como esta innovadora herramienta puede ayudar a crear sitios web.
Entre las cuestiones que hablamos con Xavi Barrachina:
- ¿Qué es Webflow y qué lo diferencia de otras herramientas de creación web?
- ¿Cómo llegas a trabajar con Webflow y por qué te decides a montar Masflow?
- ¿Cómo te ayuda Webflow en tu proceso creativo?
- ¿Qué herramientas utilizas además de Webflow para crear los sitios web?
- ¿Crees que las tecnologías “no code” son el futuro del diseño web?
- ¿Qué aspectos del diseño web piensas que mejoran usando Webflow (relación con clientes, probar ideas o nuevos planteamientos, velocidad de puesta en funcionamiento)?
- Experiencia con la comunidad de Webflow Valencia y qué tipo de eventos habéis realizado.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Restricting Flymake to my projects
Manuel Uberti 21 11 2020
My recent move from Flycheck to Flymake has proven to be a solid choice because
the Emacs built-in syntax checker has yet to let me down. And since by now I am
sure my love for project.el is absolutely obvious, could I miss the opportunity
to make these two underappreciated gems shine together?
Honestly, though, the credit here goes all to Protesilaos Stavrou. His Flymake setup made me aware of a neat way to limit the use of Flymake to the places I actually need it.
All I had to do was adapt it to my preferences:
(defun mu-flymake-mode-activate ()
"Activate `flymake-mode' only in my projects."
(project--ensure-read-project-list)
(let ((known-projects (project-known-project-roots))
(pr (or (locate-dominating-file "." ".git")
default-directory)))
(if (and (eq buffer-read-only nil)
(member pr known-projects))
(flymake-mode +1)
(flymake-mode -1))))
I then hooked this little function to prog-mode-hook and text-mode-hook and
everything was good to go.
Note that project.el must be required before running mu-flymake-mode-activate,
otherwise Emacs will complain about project--ensure-read-project-list not being
available.
Restricting Flymake to my projects
Manuel Uberti 21 11 2020
My recent move from Flycheck to Flymake has proven to be a solid choice because
the Emacs built-in syntax checker has yet to let me down. And since by now I am
sure my love for project.el is absolutely obvious, could I miss the opportunity
to make these two underappreciated gems shine together?
Honestly, though, the credit here goes all to Protesilaos Stavrou. His Flymake setup made me aware of a neat way to limit the use of Flymake to the places I actually need it.
All I had to do was adapt it to my preferences:
(defun mu-flymake-mode-activate ()
"Activate `flymake-mode' only in my projects."
(project--ensure-read-project-list)
(let ((known-projects (project-known-project-roots))
(pr (or (locate-dominating-file "." ".git")
default-directory)))
(if (and (eq buffer-read-only nil)
(member pr known-projects))
(flymake-mode +1)
(flymake-mode -1))))
I then hooked this little function to prog-mode-hook and text-mode-hook and
everything was good to go.
Note that project.el must be required before running mu-flymake-mode-activate,
otherwise Emacs will complain about project--ensure-read-project-list not being
available.

Feature Complete
MonkeyUser 20 11 2020

We’re glad you could make it this week!
With your help, we can make Pony Foo Weekly even more awesome: send tips about cool resources.
|
|

|
|
|
|

Pixels vs. Bricks
blog.karenying.com 19 11 2020

Acceptance
MonkeyUser 18 11 2020
En este episodio David Vaquero charla con Antony Ricardo Goetzschel CEO y fundador en la empresa alemana ccsolutions.io en Múnich y además, ingeniero DevOps en el grupo FunkeMedien, una de las mayores empresas de medios de comunicación de Alemania. Ricardo es un miembro muy activo en la comunidad Slack en español de Rancher, una plataforma para la administración de cluster de kubernetes, que permite desplegar y administrar clusters de kubernetes en varios proveedores, como Amazon, Azure, Google y OpenStack.
Entre las cuestiones tratadas con Antony:
- Primero hablamos de ti, ¿Cómo llega un venezolano a trabajar en una empresa alemana?
- ¿Cómo fue el proceso de selección?
- ¿Cuáles son las tareas que realizas en la empresa?
- Cuéntanos en qué consiste Kubernetes
- ¿Cuántos clústers tenéis ya en producción?
- ¿Cuáles son las características más destacables?¿Qué ofrece por encima de un despliegue tradicional?
- ¿Qué valoras más hasta la fecha de tu experiencia trabajando con Kubernetes?
- ¿Qué aspectos consideras más débiles de Kubernetes?
- ¿Tenéis una metodología GitOps?
- ¿Qué recursos son interesantes para Kubernetes y Rancher?¿Y en español?
- ¿Qué consejos puedes dar a alguien que quiere ser ingeniero de DevOps?
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Some days ago on reddit/r/lisp, we got to (re)discover CLPM, the Common Lisp Package Manager.
Its author, Eric Timmons aka daewok, was kind enough to give more context, and to answer some more questions of mine, about his use of Common Lisp in his university group.
Below I’ll give an overview of CLPM, stress on how it differs from Quicklisp, and then paste the interview.
/Note/: it’s the same content as on reddit, but saved from oblivion!
Table of Contents
CLPM
Context
CLPM author here. I’m so happy (and shocked!) that people have found CLPM, especially given how little advertising I’ve done for it! I’m a PhD student in a group that does a large amount of our coding in Common Lisp. A big part of why I wrote CLPM, for better or worse, is that my group has not done a great job at versioning or maintaining backward compatibility of our various libraries throughout the years. I’m a very applications focused person and it was incredibly frustrating when I needed to deploy some of our code that had worked in the past but found that it bit rotted. And then when I would eventually get everything rolled back to the correct point in time I had no way to release a fix that was no longer applicable on the master branch (normally because the relevant API no longer existed or had been modified in a non-backward compatible way). So I hoped that encouraging/requiring actual version numbers would help us better communicate and reason about our changes over time (and be able to release minor changes to older versions of the code) and the locking capabilities would help save us in situations like giving a demo on short notice.
I use CLPM as my daily driver as do a couple of the other Lisp-heavy students. It’s been going well so far, but I was planning to convert and get feedback from a few more before attempting to spread CLPM beyond my group. That’s unfortunately taken a lot longer than I wanted due to COVID, my personal life taking more time than normal (no worries, it’s for good reasons!), and just general research related tasks continuing to pop up.
Now that the cat’s out of the bag though, I’d be happy to hear any feedback on it! I’m especially interested in the perspectives of people outside my group since I’ve been holding their hand in getting it set up and explaining my reasoning/goals to them almost every step of the way.
Feature set and comparison to Quicklisp
CLPM’s project page (here’s a non-official GitHub mirror, if that helps you browse the repository) lists the project goals. Here’s my comment and comparison to Quicklisp.
Support and encourage explicitly versioned systems
When a package upgrade introduces regressions, we should be able to use an older version.
But, that is currently not possible with the Quicklisp client, we must refer to other tools (Qlot) or manual workarounds.
CLPM allows to use monthly-based releases, just as Quicklisp and from Quicklisp, but it also started a new source registry for Common Lisp libraries, which would:
- allow to precisely pin dependencies. It is possible to do so in ASDF, but this propriety is not used in Quicklisp (or barely, or not by most of the library authors, because Quicklisp comes as monthly distributions anyways).
- allow to get the library’s home URL, which surprisingly isn’t in Quicklisp’s metadata (last time I checked, I might be wrong). We have to look at the quicklisp-projects repository.
- it would enforce the libraries to be on version control. Currently Quicklisp also accepts source files (as archives).
Support installing multiple package versions, globally and locally
CLPM allows to manage dependencies per project (per directory), and globally. With Quicklisp, it’s only globally. Otherwise we must rely to Qlot, or load projects more manually.
While I personally find the Quicklisp approach great, simple to use, sufficient in most cases and a better default than always pinning dependencies manually, comes a point in a software life when we need project-local dependencies.
Support CI/CD workflows - ship pre-built binaries
CLPM is distributed in both binary and source form. Source for hackers or people who want to use a different feature set and binary for quick and easy installation in other cases.
That’s simpler to install, to use on CI systems, or to make you software’s users install the dependencies.
Currently we can use Roswell to install Quicklisp libraries (and software) from the command line, but its installation isn’t crystal straightforward or super fast either.
Minimize footprint in development images and deployments
When you use CLPM and you build a binary of your program, the binary won’t contain CLPM (or only if you choose to). When we use Quicklisp, the built image contains Quicklisp (which can be very useful, I use it to live-reload running web apps).
Support HTTPS
Quicklisp currently doesn’t download packages through HTTPS.
Cryptographic signature verification is coming.
More questions to Eric Timmons - using Lisp at university for temporal reasoning and risk-bounded planning.
What are you using CL for at your university?
My group’s bread and butter is in temporal reasoning and risk-bounded planning and execution (including both activity and path planning). I’m personally working on a high-level language for specifying robotic information gathering missions and an executive to plan and dispatch the missions. Language wise I think you could say it’s a stripped down Screamer when it comes to non-deterministic programming and constraints, coupled with parallel and sequential operators and the ability to temporally constrain the relative execution time of different events in the program. There’s a few more things, such as support for expressing PDDL-like operators, but that’s the 10,000 foot view.
I mentioned I’m applications focused and a lot of that focus of late has been on mission planning for autonomous underwater vehicles. Unfortunately, most of our code is running off the vehicles, but we’re slowing moving more reasoning onboard.
Do you know other teams in your university that are using CL? (or, a lisp-like language?)
I know other groups do but I’m not sure of the details, unfortunately.
So, why CL? Does it have a killer feature that make your group use it? (it doesn’t have to have one though!)
Ha, we started using CL long before I joined the group. From what I hear, it was originally mostly for practical reasons: it’s the language my group’s PI [Principal Investigator] knows the best and he needed to be able to hop onto any given project as students cycled on and off. But with respect to my personal research, I think CL is the best language for it. You can’t beat its macros for defining DSLs and I have a lot of DSLs both in my high level language (along with some MOP code!) and the planner. Something my advisor said to me about CL that really stuck with me is that it is a fantastic language to let you write a new language for the problem you want to solve, and specifying the problem is more than half the battle in solving it.
Are there downsides, do you have difficulties in certain areas? (formation?)
The biggest downside for us is that students rarely come into the group with CL experience and in rare cases some students refuse to really dive into our Lisp code and stick with something they’re more familiar with (such as Python) and end up reinventing poor facsimiles of things that exist.
Ignoring that particular issue, using CL does add a non-trivial amount of time to on-boarding new students. Then beyond that, we had the aforementioned issues with not versioning correctly and not maintaining backward compatibility. While that’s really, at it’s core, a social issue that would exist regardless of language (and is hard to avoid given the natural turn-over rate of students), the lack of a package manager with features similar to those provided in the languages students come in knowing these days certainly didn’t help.
How did you personally start with CL?
I started with CL when I joined this group. I was given a URL to Practical Common Lisp and off I went. I kind of fell down the rabbit hole at some point and spent more time learning about the language than doing research (oops), but I think that’s paid off by this point as I can make CL do nearly anything I can think of. The first draft (or several…) of my code may not be pretty, but they’ll work, get the job done, and I can continue working on abstractions and mini-DSLs to my heart’s content whenever I need to make things more clear or performant.
Can you tell us more about your software stack? (implementations, most loved libraries, deployment story (docker?), interface with other tools (monitoring?)…)
We largely use SBCL these days. I routinely try to test on the other big Free implementations as well (ABCL, CCL, ECL) both out of a desire to be portable for portability sake and to make the code more widely useful if we ever get around to sharing it beyond our collaborators more (which I am cautiously hopeful will happen). I particularly love Hunchentoot, Drakma, basically anything from Edi Weitz, log4cl, closer-mop, and, of course, CFFI.
We do a lot of our deployment with Docker (which is why I’m currently maintaining a number of CL related Docker images). I occasionally deploy things using Kubernetes (e.g., when we want to deploy our planners as a service for the students in my advisor’s classes to use). I personally love Kubernetes, but I’ve found that it’s difficult to get other students up to speed on it (let alone use it!) because it’s just one more set of things for them to learn when their focus is on graduating.
We’re also working on getting more of our code running on ARM64 processors, since that’s largely what we have available to us for low-power robots. That’s proving to be a bit of a challenge, unfortunately because SBCL is fairly memory hungry and our algorithms are also inherently memory hungry. But in the end I think it’ll be fine as it’s a driving force to get us to do only the necessary reasoning onboard.
We don’t have any great stories with regard to interfaces with other tools, but I have been meaning to pick up prometheus.cl and give it a try.
Anything more to add?
CL is awesome! Nothing else comes to mind right now.
Thanks again Eric.
Extending project.el
Manuel Uberti 14 11 2020
In my first appreciation of project.el I wrote about a patch for
project--files-in-directory. It’s a working solution, I won’t deny that, but
patching code always feels hacky. It’s like a dirty workaround you cannot avoid
to look at every time you visit your Emacs configuration.
By inspecting the code of project.el I noticed that project-files is a generic
function. In Emacs Lisp parlance, a generic function specifies an abstract
operation with the actual implementation provided by methods1. This simply means
that I can devise my own implementation of project-files.
(cl-defmethod project-root ((project (head local)))
(cdr project))
(defun mu--project-files-in-directory (dir)
"Use `fd' to list files in DIR."
(let* ((default-directory dir)
(localdir (file-local-name (expand-file-name dir)))
(command (format "fd -t f -0 . %s" localdir)))
(project--remote-file-names
(sort (split-string (shell-command-to-string command) "\0" t)
#'string<))))
(cl-defmethod project-files ((project (head local)) &optional dirs)
"Override `project-files' to use `fd' in local projects."
(mapcan #'mu--project-files-in-directory
(or dirs (list (project-root project)))))
project.el has to be made aware of my local type now.
(defun mu-project-try-local (dir)
"Determine if DIR is a non-Git project.
DIR must include a .project file to be considered a project."
(let ((root (locate-dominating-file dir ".project")))
(and root (cons 'local root))))
mu-project-try-local just needs to be added to project-find-functions to
make sure my non-Git projects become known and remembered across sessions when
I hit C-x p p. This is way more elegant than the previous patch.
Since I also never use Git submodules, I can push my extensions a little further.
(defun mu--backend (dir)
"Check if DIR is under Git, otherwise return nil."
(when (locate-dominating-file dir ".git")
'Git))
(defun mu-project-try-vc (dir)
"Determine if DIR is a project.
This is a thin variant of `project-try-vc':
- It takes only Git into consideration
- It does not check for submodules"
(let* ((backend (mu--backend dir))
(root
(when (eq backend 'Git)
(or (vc-file-getprop dir 'project-git-root)
(let ((root (vc-call-backend backend 'root dir)))
(vc-file-setprop dir 'project-git-root root))))))
(and root (cons 'vc root))))
mu-project-try-vc now replaces project-try-vc in project-find-functions.
Notes
-
See Generic Functions in the manual. ↩
Extending project.el
Manuel Uberti 14 11 2020
In my first appreciation of project.el I wrote about a patch for
project--files-in-directory. It’s a working solution, I won’t deny that, but
patching code always feels hacky. It’s like a dirty workaround you cannot avoid
to look at every time you visit your Emacs configuration.
By inspecting the code of project.el I noticed that project-files is a generic
function. In Emacs Lisp parlance, a generic function specifies an abstract
operation with the actual implementation provided by methods1. This simply means
that I can devise my own implementation of project-files.
(cl-defmethod project-root ((project (head local)))
(cdr project))
(defun mu--project-files-in-directory (dir)
"Use `fd' to list files in DIR."
(let* ((default-directory dir)
(localdir (file-local-name (expand-file-name dir)))
(command (format "fd -t f -0 . %s" localdir)))
(project--remote-file-names
(sort (split-string (shell-command-to-string command) "\0" t)
#'string<))))
(cl-defmethod project-files ((project (head local)) &optional dirs)
"Override `project-files' to use `fd' in local projects."
(mapcan #'mu--project-files-in-directory
(or dirs (list (project-root project)))))
project.el has to be made aware of my local type now.
(defun mu-project-try-local (dir)
"Determine if DIR is a non-Git project.
DIR must include a .project file to be considered a project."
(let ((root (locate-dominating-file dir ".project")))
(and root (cons 'local root))))
mu-project-try-local just needs to be added to project-find-functions to
make sure my non-Git projects become known and remembered across sessions when
I hit C-x p p. This is way more elegant than the previous patch.
Since I also never use Git submodules, I can push my extensions a little further.
(defun mu--backend (dir)
"Check if DIR is under Git, otherwise return nil."
(when (locate-dominating-file dir ".git")
'Git))
(defun mu-project-try-vc (dir)
"Determine if DIR is a project.
This is a thin variant of `project-try-vc':
- It takes only Git into consideration
- It does not check for submodules"
(let* ((backend (mu--backend dir))
(root
(when (eq backend 'Git)
(or (vc-file-getprop dir 'project-git-root)
(let ((root (vc-call-backend backend 'root dir)))
(vc-file-setprop dir 'project-git-root root))))))
(and root (cons 'vc root))))
mu-project-try-vc now replaces project-try-vc in project-find-functions.
Notes
-
See Generic Functions in the manual. ↩

See here: https://ko-fi.com/s/01fee22a32
Let me try something: I propose you here to buy the ePub, even though it is meant to be available for free.
I contributed quite a lot to the Cookbook and I found since the beginning that having an EPUB and/or a PDF version would be very useful. Some years later, nobody did it, and I finally wrote a script to bundle all the pages together and generate an ePub, and then a PDF. It isn’t finished though, it needs more editing, and it would also be great to write a proper LaTeX style for the PDF. As I have one version on disk, I thought on giving potential supporters the opportunity to read it and fund the remaining work, or simply give a sign of encouragement. It’s also the opportunity for me to try this new Ko-fi feature, and to practice speaking about financial support…
Let’s turn it another way: if you support me, here’s a reward for you, an exclusivity. And in any case, hold on, this ePub will eventually be available for everybody.
Thanks!
ps: About money: yes, it does a difference right now, because I don’t have a fixed, nor big, income. I am trying to live on my free software activities. I have a few clients, but not enough, so I’m trying to diversify and get some earnings from my Lisp work. I even pay lisp contributors to write free software (we are currently adding Stripe payments to a web application. When it’s done, you’ll know everything about it). So, the money has an impact.

Instapaper now available on macOS
Instapaper 11 11 2020
We’re excited to announce that Instapaper is now available on macOS! You can download Instapaper from the App Store on your Mac to read all your articles offline, in full screen mode, and with all the great features from the iOS app.

We customized the interfaces and features to make the app feel interactive and at home on Mac. This includes a side-by-side view of folders and article list, and hover states to highlight content on mouseover.
We also included new features for managing articles like hover actions, which allows you to easily like, move, archive, and delete directly from the list. With drag & drop, you can quickly organize articles directly into folders.

Instapaper for Mac has full keyboard navigation support, so you can navigate, read, and manage your articles using only the keyboard. Here are some of the supported keyboard shortcuts:
Navigation
- ↑: Previous Item
- ↓: Next Item
- ⏎: Select Item
- Space: Page Down
- ⇧Space: Page Up
- ⌘F: Search
- ⇧⌘F: Search All Articles
- ⌘,: Preferences
- ⌘←: Navigate Back
Article Management
- ⌘R: Refresh Articles
- ⇧⌘A: Archive Article
- ⇧⌘D: Delete Article
- ⇧⌘M: Move Article
Appearance
- ⌘1: Light Mode
- ⌘2: Sepia Mode
- ⌘3: Gray Mode
- ⌘4: Dark Mode
All available shortcuts can be found in the app menu bar located at the top of the screen.
Instapaper for macOS supports Intel and Apple Silicon Macs.
Instapaper iOS 8.0
Today we are also announcing the release of Instapaper iOS 8.0. This release contains a number of improvements that laid the foundation for building the macOS app, and also includes a few iOS-specific updates.
We redesigned the share sheet to be faster and easier to use. After saving, simply swipe down to dismiss and return to the app you were using. It’s a small change that makes a big difference in saving speed.

Additionally, we improved the pagination feature so there’s less text clipping in a variety of different situations.
That’s Instapaper 8.0 for iOS and macOS! Instapaper for Mac has been a long standing request from our customers, and we’re really excited to bring all of the great functionality from iOS to macOS.
As always, we want to hear your questions, feature requests, and/or issues. That feedback directly informs our roadmap, and we’d love to hear from you via email to support@help.instapaper.com or @InstapaperHelp on Twitter.
Thank you for using Instapaper!
– Instapaper Team

Effort Splitting
MonkeyUser 10 11 2020
Si bien en la mayoría de los episodios nos centramos en una cuestión o entrevista, para este episodio hemos seleccionado dos artículos y una noticia de interés para la profesión del desarrollo web. Empezamos comentando el artículo de Chris Coyier publicado en lncrement y que lleva por título When frontend means full stack. Continuamos con una noticia reciente aparecida en Valencia Plaza y que hace referencia al descubrimiento de un grave error de seguridad en el acceso a una aplicación móvil. Por último comentamos la columna de opinión publicada en el digital El Confidencial por Eduardo Manchón y que lleva por título Las consultoras están matando al industria: la digitalización ‘made in Spain’ hace agua.
Cuando el frontend quiere decir full stack
El artículo escrito por el conocido desarrollador Chris Coyier dibuja un acertada línea sobre el estado actual de la profesión del desarrollador frontend. Según comenta Coyier en su artículo, «los desarrolladores de frontend se están haciendo preguntas que alguna vez habrían sido respondidas exclusivamente por los desarrolladores de backend». Los artículos de Chris Coyier suelen analizar con bastante certeza, la situación actual de la profesión. En este artículo se muestra cómo ha evolucionado el perfil del desarrollador web, las habilidades que se le piden a una persona encargada de la parte del frontal y cómo hoy en día, las opciones para la construcción de un sitio web, son enormemente complejas y también diversas.
Quizás una de las mejores frases del artículo sea que «el término «full stack» ha llegado a significar en gran medida «un desarrollador de frontend que hace una buena cantidad de las cosas que un desarrollador de backend solía hacer».
App deja al descubierto datos personales de miles de vecinos de Valencia
Andros nos cuenta esta noticia aparecida recientemente en el digital Valencia Plaza, en el que se cuenta como un profesor de la Universidad de Valencia, halló importantes defectos de seguridad en la aplicación de la empresa encargada de la gestión de aguas en Valencia.
Como comenta Andros, en el momento de comprobar él mismo esta información, el acceso a la app de la empresa había sido bloqueado y no se había informado del problema a los usuarios. También comentamos lo sorprendente que resulta que desde la empresa afectada, respondan que «se requieren unos mínimos conocimientos de informática para detectarlos».
Digitalización made in Spain hace agua
Para seguir con el mundo de las consultoras y de las aguas (curiosamente), David comenta la reciente columna de Eduardo Manchón, donde se relata el sistema de desarrollo tecnológico en España, a través de consultoras. Según explica el autor del artículo «las empresas españolas han cometido el error de delegar su digitalización y dejarla en manos de consultoras».
Este artículo pone de manifiesto la necesidad de crear desde dentro de las empresas, una cultura tecnológica liderada por personas que comprendan bien como sea desarrollan los negocios en una economía digital. Como indica muy bien Manchón, «la digitalización es mucho más que crear una web o una ‘app’, es un aprendizaje que implica cambios profundos en las personas y en el funcionamiento de las organizaciones».
En definitiva, un episodio diferente y con diversidad de temas orientados a la profesión del desarrollo y la tecnología en internet.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

Election
MonkeyUser 03 11 2020
Invitamos a un buen amigo de este podcast para hablar sobre Quasar, un completo framework para Vue.js dirigido a crear interfaces de alto rendimiento sobre diferentes tecnologías. Salvador Santander es técnico de desarrollo en la sección de Informática de la Agencia de Vivienda y Rehabilitación de Andalucía (AVRA), donde se encarga del desarrollo de los sitios webs de la empresa, la arquitectura de aplicaciones y el desarrollo de aplicaciones webs.
Salvador nos cuenta las innumerables ventajas que ha encontrado al trabajar con Quasar y como lo está incorporando en los proyectos que desarrolla dentro de AVRA. A diferencia de otros frameworks para Vue.js, Quasar tiene como punto fuerte ser una solución única para la mayoría de necesidades presentes en un proyecto web moderno. Quasar dispone de una completísima colección de componentes basados en Material Design y permite desarrollar proyectos para SPA, SSR, PWA, aplicaciones móviles híbridas, extensiones de navegador y hasta aplicaciones de escritorio a través de Electron.
Entre las cuestiones que hablamos con Salvador:
- En qué consiste Quasar y cómo has llegado a trabajar con este framework Vue.js
- ¿Cuáles son las características más destacables?
- ¿Qué valoras más hasta la fecha de tu experiencia trabajando con Quasar?
- ¿Qué aspectos consideras más débiles de Quasar?
- ¿Qué proyecto/s estáis haciendo con Quasar?
- ¿Qué tecnologías tienes en tu radar?
Salvador Santander es un buen ejemplo de cómo en la Administración Pública se desarrollan proyectos con tecnologías nuevas y cómo se trabaja para mejorar el acceso a la información para los ciudadanos.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

Get Funded
MonkeyUser 27 10 2020

v2.0 Stable Release
blog.karenying.com 25 10 2020
Para este episodio contamos con la compañía de Rubén Ojeda, coordinador de proyectos en Wikimedia España, la asociación sin ánimo de lucro que promueve el conocimiento libre y los proyectos Wikimedia, siendo Wikipedia el más conocido de todos. Pero Wikimedia es mucho más que la Wikipedia, y en este episodio Rubén nos contará todo el trabajo que se realiza desde la asociación y cómo favorecen un mejor acceso a la cultura y el conocimiento libre.
Wikimedia está detrás de proyectos de difusión tan interesantes como Wikidata, Wikimedia Commons, Wikiquote o Wikisource, pero también de otros muchos que constituyen un formidable repositorio de información compartida y libre.
Con Rubén Ojeda hablamos mucho sobre Wikipedia pero también de varias cuestiones sobre Wikimedia y sus proyectos:
- ¿Qué es la Asociación Wikimedia España y cómo se constituye aquí?
- En qué consiste una wiki y cómo se organiza a nivel editorial.
- ¿Cómo pueden participar los ciudadanos de los proyectos Wikimedia?
- ¿Conoce el sector público y las instituciones culturales cómo compartir conocimiento a través de vuestros proyectos?
- ¿Cuáles son las mayores amenazas al conocimiento libre en la era digital?
- ¿Cómo pueden ayudar los proyectos Wikimedia a combatir la desinformación?
En definitiva una conversación muy completa para conocer la labor de Wikimedia, aspectos sobre derechos digitales, contenidos libres y conocer cómo poder colaborar en los proyectos.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Emacs and Emanuele Severino
Manuel Uberti 24 10 2020
The recently available Emacs User Survey made me think, once again, about the
status of the technological world around me. The survey was painstakingly
discussed on the emacs-devel mailing list, and generated some interesting
reactions among people outside the core developing team as well. More
interesting for the perspective of this writing are the reactions to the
discussions on emacs-devel, because they reveal how great the distance between
me and some members of the Emacs community has been getting.
You see, I am a failed Free Software supporter. I stopped campaigning in its favour as soon as my wife’s school closed. There I had set up everything with Free and Open Source software, and watching the teachers effectively do their job with technological solutions they were not accustomed to made me happy. They did not really care about the reasons behind my choices, but they respected my contribution and were willing to overcome the first weeks of adaptation as long as I could guarantee a comfortable working environment. When all of this ended and I went back to software development, Free and Open Source software became only a private concern. While still set on Linux1, I left Debian for Ubuntu because I didn’t want to spend time tinkering with my operative system to get the best out of my Dell XPS. My distro-hopping days had come to an end. I just wanted a system that would let me code, write, and browse the Web. I chose the easy way.
However, I have never stopped paying attention to the world around me and behaving consciously. For instance, I hate wasting technology. The 3-and-a-half-year old Dell XPS where I am writing now replaced my 8-year old Dell Inspiron, and my 7-year old HP server is still rock-solid and here to stay. I have a 4-year old Fairphone, my first and only smartphone, that I intend to keep for as long as possible. Beside gadgets, I’ve been on a vegan diet for almost seven years and I consider it one of the best and most important choices I’ve ever made regarding the ethics of what I eat. Come to think of it, as bad as the Coronavirus crisis is turning out to be, it “fixed” the problem of getting to the office every day, cutting my car usage down to once a week for groceries2 and thus decreasing my impact on the environment.
This is why mixing technocraticism with pragmatism bothers me. The words “pragmatic” and “pragmatism” have been kind of a constant in the IT world I live in since “The Pragmatic Programmer” passed on my shelves. As every word in every language, “pragmatic” and “pragmatism” are complex words and their actual meaning is not trivially describable. Immanuel Kant distinguishes between “practical” and “pragmatic”, but without asking him we can quickly see what the dictionary tells us. According to the Oxford Learner’s Dictionary, “pragmatic” means “solving problems in a practical and sensible way rather than by having fixed ideas or theories”. Treccani, however, is closer to how “pragmatic” is known nowadays: “what is being characterised by the prevailing of practical interests over theoretical ones and ideal values”. I won’t digress on the multiple meanings of “ideal” to keep it simple and because “values” is actually the key word for me here.
“Pragmatic” and “pragmatism”, in common parlance, imply a separation between theoretical thoughts and practical action, but it is actually impossible to draw a line between the two. Every action is informed by a thought and every thought shines a light on the action. We can act automatically without thinking about it, sure, but that has nothing to do with voluntary actions. When we act, we act according to a line of reasoning, and it’s that line of reasoning that determines the value of the action. Take my choice of using Ubuntu on this Dell XPS. A deliberate decision born out of my desire to prefer a comfortable option instead of spending time to value more Free Software-compliant solutions. I acted with a plan just as I acted with a plan when I chose my vegan diet. Which choice is more pragmatic? Which one tells you more about my ethics?
For years now I’ve been seeing the IT world as self-involved and rarely eager to discuss larger issues. Problems such as the environmental crisis become material for self-congratulatory speeches at conferences around the world, while in fact the day after the conference we resume our lives as if nothing other than ourselves mattered. We do that because, as Emanuele Severino says, we are scared of what is beyond ourselves. We have replaced religious myths with the myth of technology to find the immediate answers to deep and life-changing questions that we do not want to investigate any further.
It’s not easy to understand the weight of words like “pragmatism” and “pragmatic” in a technocratic world. We live in an age where we believe that technology is our ultimate saviour. We are driven to accept technology as it is because of the benefits it brings to ourselves. We trust our technology because not doing so would result in the effort of questioning it, which in turns may unveil the details that the technocratic world goes a long distance to hide. More importantly, questioning technology could disclose what we really are and need to be, something that takes will and courage to face. In a time like this, Emanuele Severino’s claim that technique is the dominant power of our time sounds as forceful as ever.
Notes
Emacs and Emanuele Severino
Manuel Uberti 24 10 2020
The recently available Emacs User Survey made me think, once again, about the
status of the technological world around me. The survey was painstakingly
discussed on the emacs-devel mailing list, and generated some interesting
reactions among people outside the core developing team as well. More
interesting for the perspective of this writing are the reactions to the
discussions on emacs-devel, because they reveal how great the distance between
me and some members of the Emacs community has been getting.
You see, I am a failed Free Software supporter. I stopped campaigning in its favour as soon as my wife’s school closed. There I had set up everything with Free and Open Source software, and watching the teachers effectively do their job with technological solutions they were not accustomed to made me happy. They did not really care about the reasons behind my choices, but they respected my contribution and were willing to overcome the first weeks of adaptation as long as I could guarantee a comfortable working environment. When all of this ended and I went back to software development, Free and Open Source software became only a private concern. While still set on Linux1, I left Debian for Ubuntu because I didn’t want to spend time tinkering with my operative system to get the best out of my Dell XPS. My distro-hopping days had come to an end. I just wanted a system that would let me code, write, and browse the Web. I chose the easy way.
However, I have never stopped paying attention to the world around me and behaving consciously. For instance, I hate wasting technology. The 3-and-a-half-year old Dell XPS where I am writing now replaced my 8-year old Dell Inspiron, and my 7-year old HP server is still rock-solid and here to stay. I have a 4-year old Fairphone, my first and only smartphone, that I intend to keep for as long as possible. Beside gadgets, I’ve been on a vegan diet for almost seven years and I consider it one of the best and most important choices I’ve ever made regarding the ethics of what I eat. Come to think of it, as bad as the Coronavirus crisis is turning out to be, it “fixed” the problem of getting to the office every day, cutting my car usage down to once a week for groceries2 and thus decreasing my impact on the environment.
This is why mixing technocraticism with pragmatism bothers me. The words “pragmatic” and “pragmatism” have been kind of a constant in the IT world I live in since “The Pragmatic Programmer” passed on my shelves. As every word in every language, “pragmatic” and “pragmatism” are complex words and their actual meaning is not trivially describable. Immanuel Kant distinguishes between “practical” and “pragmatic”, but without asking him we can quickly see what the dictionary tells us. According to the Oxford Learner’s Dictionary, “pragmatic” means “solving problems in a practical and sensible way rather than by having fixed ideas or theories”. Treccani, however, is closer to how “pragmatic” is known nowadays: “what is being characterised by the prevailing of practical interests over theoretical ones and ideal values”. I won’t digress on the multiple meanings of “ideal” to keep it simple and because “values” is actually the key word for me here.
“Pragmatic” and “pragmatism”, in common parlance, imply a separation between theoretical thoughts and practical action, but it is actually impossible to draw a line between the two. Every action is informed by a thought and every thought shines a light on the action. We can act automatically without thinking about it, sure, but that has nothing to do with voluntary actions. When we act, we act according to a line of reasoning, and it’s that line of reasoning that determines the value of the action. Take my choice of using Ubuntu on this Dell XPS. A deliberate decision born out of my desire to prefer a comfortable option instead of spending time to value more Free Software-compliant solutions. I acted with a plan just as I acted with a plan when I chose my vegan diet. Which choice is more pragmatic? Which one tells you more about my ethics?
For years now I’ve been seeing the IT world as self-involved and rarely eager to discuss larger issues. Problems such as the environmental crisis become material for self-congratulatory speeches at conferences around the world, while in fact the day after the conference we resume our lives as if nothing other than ourselves mattered. We do that because, as Emanuele Severino says, we are scared of what is beyond ourselves. We have replaced religious myths with the myth of technology to find the immediate answers to deep and life-changing questions that we do not want to investigate any further.
It’s not easy to understand the weight of words like “pragmatism” and “pragmatic” in a technocratic world. We live in an age where we believe that technology is our ultimate saviour. We are driven to accept technology as it is because of the benefits it brings to ourselves. We trust our technology because not doing so would result in the effort of questioning it, which in turns may unveil the details that the technocratic world goes a long distance to hide. More importantly, questioning technology could disclose what we really are and need to be, something that takes will and courage to face. In a time like this, Emanuele Severino’s claim that technique is the dominant power of our time sounds as forceful as ever.
Notes

Corporate Solution
MonkeyUser 23 10 2020

Cloudflare Analytics review
Marko Saric 20 10 2020
Any database schema is likely to have plenty of text fields. In this article I demonstrate the surprising impact of medium-size texts on query performance.
Para este episodio contamos con la compañía desde Zaragoza con Sergio López, un desarrollador de software especializado en Sistemas Operativos y Virtualización. Con Sergio queremos trazar a grandes rasgos las diferencias existentes entre la virtualización y los contenedores. Sergio López @slpnix nos cuenta los fundamentos de estas dos tecnologías, que sin duda, han revolucionado el mundo de la computación y son una de las bases de la nube.
Con Sergio tratamos las siguientes cuestiones:
- ¿Qué es la virtualización y cómo ha cambiado esta tecnología el mundo de la informática?
- ¿Qué necesitamos para virtualizar una computadora y qué influye en su rendimiento?
- ¿Qué tipos de virtualización existen y cuáles son sus diferencias? Ejemplos y gestión de hipervisores.
- ¿Qué son los contenedores y cuál es su origen?.
- ¿Qué tipos de tecnología de contenedores existen?.
- Presente y futuro de las tecnologías. Principales empresas y proyectos.
- Referencias y recursos de interés.
Si queréis escuchar a Sergio López, participó también recientemente en el Podcast Entre Devs y Ops hablando sobre Microkernels. De hecho, esta entrevista le sirvió a Andros para invitar a Sergio al programa.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
As a Clojure developer one of the most important packages in my everyday Emacs usage is CIDER. There are many things to love about it, chief among them the great interactive code evaluation and a sweet integration with popular Clojure tools. I still haven’t played with its debugging facilities, but yes, I know I should.
However, there is something that has been bothering me for quite a while: REPL switching and buffer loading. I cannot pinpoint the exact moment when these seemingly simple operations have become so unreliable, but I still remember when switching to the correct REPL buffer according to the file in front of me used to work as expected and loading a buffer didn’t require dealing with sessions first.
Let me give you more details before this writing starts to look like a random
rant. My projects are usually web applications, which means I have to write both
Clojure and ClojureScript. The Clojure side can be backed by leiningen or a
deps.edn file, and we are set on shadow-cljs for ClojureScript. The first thing
I normally do is jack-in with C-c C-x j j and then bring up the dedicated
ClojureScript REPL with C-c C-x j s. Opening the browser and navigate to
something along the lines of localhost:3000 finalises the process of setting up
the ClojureScript REPL. That’s it, another good day of coding can begin. And
soon enough frustration follows.
I tend to move from Clojure to ClojureScript files and vice versa quite a lot, and hitting C-c C-z frequently results in an unpredictable behaviour. Sometimes the REPL of the expected type pops up, sometimes the other one appears, sometimes I get a message about a missing REPL in the current session. Manually linking the current buffer to the correct REPL with C-c C-s b seems to fix the problem, but it’s only a matter of time. It takes a couple of buffer switching operations to bring the issue back. It is as if the link between the buffer and the REPL has vanished. Even worse, without that link I can forget about C-c C-k to load the buffer.
To overcome my frustration, I sat back and looked at how exactly I interact with CIDER:
- I only deal with one project at a time
- I need at most two running REPLs
- I don’t really care about firing up dedicated REPLs for other projects. If I change project, I simply close every buffer of the current one and start afresh
This made me realise that the whole CIDER session management is too much for my basic needs.
(defun mu--cider-repl-regex (type)
"Return the regexp to get the CIDER REPL based on TYPE."
(if (eq type 'clj)
"\`*cider-repl .*clj[*]"
"\`*cider-repl .*cljs"))
(defun mu--cider-repl-buffer-name (type)
"Get buffer from `buffer-list' according to TYPE."
(let ((regex (mu--cider-repl-regex type)))
(car (seq-filter (lambda (s) (string-match-p regex s))
(mapcar #'buffer-name (buffer-list))))))
(defun mu-cider-switch-to-repl (&optional type)
"Open a CIDER REPL for TYPE.
If TYPE is not passed, open a Clojure REPL."
(interactive "P")
(let ((type (or type 'clj)))
(if-let (buffer (mu--cider-repl-buffer-name type))
(pop-to-buffer buffer)
(message "No CIDER REPL available"))))
(defun mu-cider-switch-to-cljs-repl ()
"Open a CIDER REPL for ClojureScript."
(interactive)
(mu-cider-switch-to-repl 'cljs))
Note that I changed the value of nrepl-repl-buffer-name-template to *cider-repl
%j %r:%S*, so you may have to change mu--cider-repl-regex according to the value
in your setup.
C-c C-z is bound to mu-cider-switch-to-repl in clojure-mode-map and
clojurec-mode-map, and to mu-cider-switch-to-cljs-repl in
clojurescript-mode-map. This of course means that in .cljc files I always get to
a Clojure REPL, but that’s fine. The code in there has to be tested on both
REPLs anyway, so it doesn’t matter which one comes up first.
Now, let’s fix C-c C-k as well.
(defun mu--cider-session-by-type (type)
"Return the current CIDER session by TYPE."
(let* ((regex (mu--cider-repl-regex type))
(system (sesman--system))
(sessions (sesman-current-sessions system '(buffer))))
(car
(seq-filter (lambda (s)
(string-match-p regex (buffer-name (cadr s))))
sessions))))
(defun mu--cider-load-buffer (session)
"Load the current buffer according to SESSION."
(if session
(let ((system (sesman--system))
(buf (current-buffer)))
(sesman--clear-links)
(sesman-link-session system session 'buffer buf)
(cider-load-buffer buf))
(message "No CIDER REPL available")))
(defun mu-cider-load-clj-buffer ()
"Load the current Clojure buffer."
(interactive)
(mu--cider-load-buffer (mu--cider-session-by-type 'clj)))
(defun mu-cider-load-cljc-buffer ()
"Load the current ClojureC buffer."
(interactive)
(let ((clj-session (mu--cider-session-by-type 'clj))
(cljs-session (mu--cider-session-by-type 'cljs)))
(if (and (null clj-session)
(null cljs-session))
(message "No CIDER REPL available")
(when clj-session
(mu--cider-load-buffer clj-session))
(when cljs-session
(mu--cider-load-buffer cljs-session)))))
(defun mu-cider-load-cljs-buffer ()
"Load the current ClojureScript buffer."
(interactive)
(mu--cider-load-buffer (mu--cider-session-by-type 'cljs)))
Just like for C-c C-z, C-c C-k is now bound to these commands according to the
mode map. For the sake of completeness, I have also disabled both C-c C-k and
C-c C-z in cider-mode-map in order to avoid any kind of overshadowing by CIDER.
Note that this approach works well with my intended CIDER usage. It may not be what you are looking for if you are experiencing the same problems with REPL switching and buffer loading. Still, I have been using these commands for a while now and I am happy with them. CIDER has become my trusted Clojure IDE again.
As a Clojure developer one of the most important packages in my everyday Emacs usage is CIDER. There are many things to love about it, chief among them the great interactive code evaluation and a sweet integration with popular Clojure tools. I still haven’t played with its debugging facilities, but yes, I know I should.
However, there is something that has been bothering me for quite a while: REPL switching and buffer loading. I cannot pinpoint the exact moment when these seemingly simple operations have become so unreliable, but I still remember when switching to the correct REPL buffer according to the file in front of me used to work as expected and loading a buffer didn’t require dealing with sessions first.
Let me give you more details before this writing starts to look like a random
rant. My projects are usually web applications, which means I have to write both
Clojure and ClojureScript. The Clojure side can be backed by leiningen or a
deps.edn file, and we are set on shadow-cljs for ClojureScript. The first thing
I normally do is jack-in with C-c C-x j j and then bring up the dedicated
ClojureScript REPL with C-c C-x j s. Opening the browser and navigate to
something along the lines of localhost:3000 finalises the process of setting up
the ClojureScript REPL. That’s it, another good day of coding can begin. And
soon enough frustration follows.
I tend to move from Clojure to ClojureScript files and vice versa quite a lot, and hitting C-c C-z frequently results in an unpredictable behaviour. Sometimes the REPL of the expected type pops up, sometimes the other one appears, sometimes I get a message about a missing REPL in the current session. Manually linking the current buffer to the correct REPL with C-c C-s b seems to fix the problem, but it’s only a matter of time. It takes a couple of buffer switching operations to bring the issue back. It is as if the link between the buffer and the REPL has vanished. Even worse, without that link I can forget about C-c C-k to load the buffer.
To overcome my frustration, I sat back and looked at how exactly I interact with CIDER:
- I only deal with one project at a time
- I need at most two running REPLs
- I don’t really care about firing up dedicated REPLs for other projects. If I change project, I simply close every buffer of the current one and start afresh
This made me realise that the whole CIDER session management is too much for my basic needs.
(defun mu--cider-repl-regex (type)
"Return the regexp to get the CIDER REPL based on TYPE."
(if (eq type 'clj)
"\`*cider-repl .*clj[*]"
"\`*cider-repl .*cljs"))
(defun mu--cider-repl-buffer-name (type)
"Get buffer from `buffer-list' according to TYPE."
(let ((regex (mu--cider-repl-regex type)))
(car (seq-filter (lambda (s) (string-match-p regex s))
(mapcar #'buffer-name (buffer-list))))))
(defun mu-cider-switch-to-repl (&optional type)
"Open a CIDER REPL for TYPE.
If TYPE is not passed, open a Clojure REPL."
(interactive "P")
(let ((type (or type 'clj)))
(if-let (buffer (mu--cider-repl-buffer-name type))
(pop-to-buffer buffer)
(message "No CIDER REPL available"))))
(defun mu-cider-switch-to-cljs-repl ()
"Open a CIDER REPL for ClojureScript."
(interactive)
(mu-cider-switch-to-repl 'cljs))
Note that I changed the value of nrepl-repl-buffer-name-template to *cider-repl
%j %r:%S*, so you may have to change mu--cider-repl-regex according to the value
in your setup.
C-c C-z is bound to mu-cider-switch-to-repl in clojure-mode-map and
clojurec-mode-map, and to mu-cider-switch-to-cljs-repl in
clojurescript-mode-map. This of course means that in .cljc files I always get to
a Clojure REPL, but that’s fine. The code in there has to be tested on both
REPLs anyway, so it doesn’t matter which one comes up first.
Now, let’s fix C-c C-k as well.
(defun mu--cider-session-by-type (type)
"Return the current CIDER session by TYPE."
(let* ((regex (mu--cider-repl-regex type))
(system (sesman--system))
(sessions (sesman-current-sessions system '(buffer))))
(car
(seq-filter (lambda (s)
(string-match-p regex (buffer-name (cadr s))))
sessions))))
(defun mu--cider-load-buffer (session)
"Load the current buffer according to SESSION."
(if session
(let ((system (sesman--system))
(buf (current-buffer)))
(sesman--clear-links)
(sesman-link-session system session 'buffer buf)
(cider-load-buffer buf))
(message "No CIDER REPL available")))
(defun mu-cider-load-clj-buffer ()
"Load the current Clojure buffer."
(interactive)
(mu--cider-load-buffer (mu--cider-session-by-type 'clj)))
(defun mu-cider-load-cljc-buffer ()
"Load the current ClojureC buffer."
(interactive)
(let ((clj-session (mu--cider-session-by-type 'clj))
(cljs-session (mu--cider-session-by-type 'cljs)))
(if (and (null clj-session)
(null cljs-session))
(message "No CIDER REPL available")
(when clj-session
(mu--cider-load-buffer clj-session))
(when cljs-session
(mu--cider-load-buffer cljs-session)))))
(defun mu-cider-load-cljs-buffer ()
"Load the current ClojureScript buffer."
(interactive)
(mu--cider-load-buffer (mu--cider-session-by-type 'cljs)))
Just like for C-c C-z, C-c C-k is now bound to these commands according to the
mode map. For the sake of completeness, I have also disabled both C-c C-k and
C-c C-z in cider-mode-map in order to avoid any kind of overshadowing by CIDER.
Note that this approach works well with my intended CIDER usage. It may not be what you are looking for if you are experiencing the same problems with REPL switching and buffer loading. Still, I have been using these commands for a while now and I am happy with them. CIDER has become my trusted Clojure IDE again.

Teamwork
MonkeyUser 16 10 2020
Congreso esLibre y PyConES 2020
República Web 10 10 2020
Dedicamos la mayor parte del episodio a hablar sobre el Congreso esLibre 2020 celebrado el pasado mes de septiembre. La edición de esLibre de este año se celebró finalmente online, transmitiendo desde la Universidad Rey Juan Carlos gracias al interés mostrado por su Oficina de Conocimiento y Cultura Libres (OfiLibre de la URJC).
David Vaquero tuvo la oportunidad de participar como ponente y en este episodio nos acerca la organización de este evento y sus promotores, las soluciones tecnológicas que utilizaron, el proceso de selección abierto de las candidaturas y también los fines que se persiguen conseguir. El Congreso esLibre 2020 reunió en dos jornadas, una variada selección de charlas y conferencias alrededor de varias pistas relacionadas con el software libre.
También hacemos mención del evento 24H24L un evento online de 24 horas de duración que constará de 24 audios sobre el uso de GNU / Linux, experiencias profesionales y personales alrededor de seis categorías: Redes, Empresa, Desarrollo, Hardware, Multimedia y GNU/Linux.
En la segunda parte Andros Fenollosa nos contará su experiencia participando como organizador y ponente en la edición online de la conferencia sobre Python en España PyConES2020 Pandemic Edition. Andros ofreció una charla sobre introducción a la programación funcional, que además colgamos como episodio bonus en el feed del podcast.
Por último, aportamos varios recursos y enlaces recomendados en la sección Radar del episodio.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

Reverse Turing Test
MonkeyUser 09 10 2020
Como episodio bonus os dejamos el audio de la charla que ofreció Andros Fenollosa en la Pycon España 2020, que este año se realizó de manera virtual. En esta charla Andros ofrece una introducción muy interesante para conocer en qué consiste la programación funcional y en qué se diferencia de otros tipos de programación (imperativa y orientada a objetos).
En la web de la PyCon están colgadas todas las charlas y se pueden seguir desde su canal de YouTube.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
En qué ando: desescalando
Onda Hostil 04 10 2020
Meme generator in emacs
(ノ°Д°)ノ︵ ┻━┻ 04 10 2020
Getting started with Tsung
(ノ°Д°)ノ︵ ┻━┻ 03 10 2020
Getting started with Tsung
(ノ°Д°)ノ︵ ┻━┻ 03 10 2020
What is tsung
Tsung is a load testing tool written in erlang, it allow us to perform load testing for web applications, databases, etc. Or as its website says:
Tsung (formerly IDX-Tsunami) is a distributed load testing tool. It is protocol-independent and can currently be used to stress HTTP, WebDAV, SOAP, PostgreSQL, MySQL, AMQP, MQTT, LDAP and Jabber/XMPP servers.
More info is available in its web page http://tsung.erlang-projects.org/user_manual/
In this post we'll cover how to test a web application and at the time of writing this the available version of tsung is 1.7.0.
Installation
DISCLAIMER: All the steps described here are for macOS, there shouldn't be many differences for a linux system.
Tsung is available on homebrew so we can install it using brew install tsung, also we'll need perl for charts generation so we can install it with brew install perl as well.
In order to generate charts correctly we need to install a required dependency, we have to execute cpan template and we're almost ready to go
A last step is change the perl script a little bit, in macOS is located in /usr/local/lib/tsung/bin/tsung_stats.pl. We first need to change its permissions so we can be able to edit it, we can execute chmod 755 =/usr/local/lib/tsung/bin/tsung_stats.pl. Now we can apply the following change:
-#!/usr/bin/perl -w
+#!/usr/local/bin/perl -w
As you can see we changed the location of the perl installation, this was the easiest way I found to make it work properly without the need to make some other changes to perl installation.
Demo project
We're going to use this example project for our tests. We can follow the instructions described in its README.md file.
This project have the following urls:
| route | description | method | content type |
|---|---|---|---|
| / | index page with an html message | GET | text/html |
| /ping | respond a pong message | GET | text/plain |
| /users | respond with a list of users in json | GET | application/json |
| /users | allow to create a new user | POST | application/json |
We're going to write test for each of this routes.
Defining load tests
Tsung load tests are defined in xml, in these xml files we can define the behaviour of the test, how many clients we want to execute, define the the endpoints to be used and so on.
tsung comes with some examples included, in macOS we can find them in /usr/share/doc/tsung/examples and use them as a base for creating new tests.
This a simplified version of the example http_simple.xml example included in the installation folder, let's create a file called demo.xml and put this content on it:
<?xml version="1.0"?>
<!DOCTYPE tsung SYSTEM "/usr/local/Cellar/tsung/1.7.0/share/tsung/tsung-1.0.dtd">
<tsung loglevel="notice" version="1.0">
<clients>
<client host="localhost" use_controller_vm="true"/>
</clients>
<servers>
<server host="localhost" port="4000" type="tcp"></server>
</servers>
<load>
<arrivalphase phase="1" duration="10" unit="minute">
<users arrivalrate="10" unit="second"></users>
</arrivalphase>
<arrivalphase phase="2" duration="5" unit="minute">
<users arrivalrate="20" unit="second"></users>
</arrivalphase>
</load>
<sessions>
<session name="http-example" probability="100" type="ts_http">
<request> <http url="/" method="GET" version="1.1"></http> </request>
<request> <http url="/ping" method="GET" version="1.1"></http> </request>
<request> <http url="/users" method="GET" version="1.1"></http> </request>
<request> <http url="/users" method="POST" contents_from_file="payload.json" content_type="application/json" version="1.1"></http> </request>
</session>
</sessions>
</tsung>
Note that the second line is pointed to a path inside the tsung installation folder, this can be changed, the tsung-1.0.dtd is available in its web page http://tsung.erlang-projects.org/user_manual/dtd.html.
<!DOCTYPE tsung SYSTEM "/usr/local/Cellar/tsung/1.7.0/share/tsung/tsung-1.0.dtd">Let's explain a little bit about the test sections:
Client setup
Tsung is a distributed testing tool so we can execute the client in different hosts, for now we'll be executing the client in our machine so we can define the client in localhost:
<clients>
<client host="localhost" use_controller_vm="true"/>
</clients>Server setup
This is the server who will be serving the incoming requests from tsung, in this case is the same machine and listening at port 4000 using a TCP connection, in a proper test it should a separate machine.
<servers>
<server host="localhost" port="4000" type="tcp"></server>
</servers>Load behaviour
We can define how the test load will behave, in this case we're configuring tsung to have 2 phases:
-
The first phase will run for 10 minutes and create 10 users every second.
-
The second phase will run for 5 minutes and create 20 users every second.
<load>
<arrivalphase phase="1" duration="10" unit="minute">
<users arrivalrate="10" unit="second"></users>
</arrivalphase>
<arrivalphase phase="2" duration="10" unit="minute">
<users arrivalrate="20" unit="second"></users>
</arrivalphase>
</load>For more info about the load configuration we can check http://tsung.erlang-projects.org/user_manual/conf-load.html
HTTP requests
Now we can define what endpoints we're going to test, we can define the url, method used and some other properties that can be found in http://tsung.erlang-projects.org/user_manual/conf-sessions.html#http.
In this case we're defining the 4 routes from our example project:
<sessions>
<session name="http-example" probability="100" type="ts_http">
<request> <http url="/" method="GET" version="1.1"></http> </request>
<request> <http url="/ping" method="GET" version="1.1"></http> </request>
<request> <http url="/users" method="GET" version="1.1"></http> </request>
<request> <http url="/users" method="POST" contents_from_file="payload.json" content_type="application/json" version="1.1"></http> </request>
</session>
</sessions>
Note that in the case of the POST request we're defining a contents_from_file property, this allow us to load the body of the request from an external file, we can define it in the same test but it's easier to have a separate file, the content of the payload.json if the following:
{
"name": "tsung",
"email": "demo@demo.com"
}
This file needs to be in the same folder as demo.xml
Running the load tests
Now we have all the pieces on place so we can execute our tests, we should be in the folder where we create our demo.xml and run the following command:
tsung -f demo.xml startThat should returns something like this:
Starting Tsung
Log directory is: /Users/erick/.tsung/log/20201004-1229
For each execution tsung create a folder under ~/.tsung/log/ where all the data generated by the tests will be saved, tsung also has a embedded web server where we can see the results of the tests, by default it will run on http://localhost:8091/
Reporting
We can see live reporting in the service running at http://localhost:8091/ or we can see more detailed data using the tsung_stats.pl script.
Dynamic reporting
When we enter to http://localhost:8091/ we can see:
-
A status page
-
A report page which shows stats about the load testing
-
A charts page
-
A logs page which shows all the generated log files
Status page
We can see the status of the running tests:
Reports page
We can see stats about the connection time, response times, OS resources usage and so on.

Charts page
This could be the most interesting one, we can see pretty good charts about the behave of the service that we're testing, it has the following sections:
-
Response time
-
Throughput
-
Simultaneous users
-
Server OS monitoring
-
HTTP return code Status (rate)

Static reporting
Once we finish the tests we can go into the log folder, ~.tsung/log/20201004-1229 in this case, and generate more detailed charts, see CSVs with all the resulted data and more.
To generate the chart we have to run the following command inside our log folder
/usr/local/lib/tsung/bin/tsung_stats.plThis will generate a few new folders inside of it:
-
csv_data: a list ofCSVfiles with all the data to be processed in some external tool likeRor ajupyter notebookfor example -
images: a set of more detailed charts
For example in this chart we can see the numbers of users vs the time, and as we can see the quantity was increased after 10 minutes, just like we defined in the config file.

Final thoughts
tsung can be used to test not only http services, it supports sql databases, websocket protocol and many more protocols, so we can use it to perform load test for many parts of our application and because it is based on plain texts configuration files we can version them to keep track of the tests we perform along the time.

Ahead of its time
MonkeyUser 29 09 2020
Ten books which I read this year
Isaak’s Blog 27 09 2020
Los formularios nos acompañan en la mayoría de nuestros proyectos web. Los desarrolladores se afanan en que sus formularios no contengan errores y que reciban la información correcta. También deben asegurarse que se protege a la aplicación, evitando la introducción de datos maliciosos que comprometan la integridad de la aplicación.
También hay un trabajo de interacción y diseño muy importante. Los usuarios deben ser capaces de interactuar con nuestros formularios de una forma precisa y agradable. Todos queremos formularios intuitivos y fáciles de usar, pero huimos de los formularios largos y confusos. Los diseñadores y el equipo de marketing deben ser capaces de generar formularios que consigan los objetivos que se han propuesto con el sitio web.
En este episodio hablamos sobre los formularios y lo que supone su diseño y operativa. Intentaremos tratar algunos de los aspectos esenciales que tenemos que tener en cuenta para trabajar con ellos y el reto que supone crearlos y mantenerlos.
Entre las cuestiones que tratamos:
- ¿Qué tenemos que tener en cuenta a la hora de diseñar un formulario?
- ¿Qué tenemos que tener en cuenta a la hora de programar un formulario?
- Servicios y software dedicado a gestionar formularios.
En la segunda parte del episodio damos resultados de la última encuesta que hemos realizado sobre herramientas para gestionar control de versiones y en la última sección, Radar con enlaces y herramientas de interés.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Updated Debian 10: 10.6 released
Debian News 26 09 2020
buster). This point release mainly adds corrections for security issues, along with a few adjustments for serious problems. Security advisories have already been published separately and are referenced where available.
When I didn’t know Lisp at all, I skimmed at CLSQL’s and Mito’s
documentation and I didn’t find a mention of “lazy”, “querysets” (a
Django term!) nor a mention of any means to compose queries. I had no
idea how I would replace querysets, F and Q objects and the many
functions for DB queries that were being added into newer Django
versions. I concluded that the Lisp ecosystem was lagging behind.
Table of Contents
Then I began to understand. And today I got the chance to rewrite a
Django query involving querysets and Q objects, using regular
Lisp. All you have to know is back-quote and comma.
We implement a simple search into a DB. The user enters one or more
words and we search against the title and the authors fields. We
want to match all words, but each can be either in the title, either
in the authors field.
Considering we have two products:
1 - The Lisp Condition System - phoe
2 - Implementing a blockchain in Lisp - F. Drummer
then searching for “lisp cond” must return one result. DWIM.
In Python, we must use Q objects to “OR” the terms with | (you can’t use | without Q):
products = firstquery()
for word in words:
products = products.objects.filter(Q(title__icontains=word) |
Q(authors__name__icontains=word))\
.distinct()
The promise of filter is to be lazy, so when we chain them the ORM
constructs one single SQL query.
So what does this query yield as SQL? Funnily, I didn’t find a built-in way to get the generated SQL and I had to use a third-party library. Mmh, I could use special logging. The fact is, we are far from SQL here (and, with the experience, it is NOT a good thing).
It looks like this (searching “hommes femmes” in our test DB):
SELECT DISTINCT ... FROM "product" LEFT OUTER JOIN ...
WHERE
(("product"."title" LIKE %hommes% ESCAPE '\'
OR "author"."name" LIKE %hommes% ESCAPE '\')
AND
("product"."title" LIKE %femmes% ESCAPE '\'
OR T5."name" LIKE %femmes% ESCAPE '\'))
ORDER BY "product"."created" DESC
LIMIT 3
Does that look complicated? Does that need alien “Q objects”?! It’s just a AND around two OR:
title like keyword 1 OR author like keyword 1
AND
title like keyword 2 OR author like keyword 2
Mito is the high-level library, and we compose queries with SXQL. I already had a little query that worked with one keyword:
(defun find-product (&key query (order :asc))
(mito:select-dao 'product
(when query
(sxql:where (:or (:like :title (str:concat "%" query "%"))
(:like :authors (str:concat "%" query "%")))))
(sxql:order-by `(,order :created-at))))
If :query is given, we filter the search. If not, the when is not executed and we return all products.
So what we need to do is iterate over the keywords, produce as many OR and wrap them with a AND. We want something like that (we can try in the REPL):
(:AND
(:OR (:LIKE :TITLE "%word1%")
(:LIKE :AUTHORS "%word1%"))
(:OR (:LIKE :TITLE "%word2%")
(:LIKE :AUTHORS "%word2%")))
So:
The solution
(sxql:where
`(:and ;; <-- backquote
,@(loop for word in (str:words query) ;; <-- comma-splice
:collect `(:or (:like :title ,(str:concat "%" word "%")) ;; <-- backquote, comma
(:like :authors ,(str:concat "%" word "%"))))))
(using (ql:quickload "str"))
Pay attention to ,@ (comma-splice). Without it, we get a bad level
of nesting and two parenthesis before the :OR. We would get a list of
clauses, instead of each clause individually. You can try in the REPL.
Note: if you are uneasy with back-quote and comma, see: https://lispcookbook.github.io/cl-cookbook/macros.html
Last words
Django’s filter is similar to using a
When,
which we were already using on the Lisp side without knowing it was
anything special. “Q objects” are easy to replace. So, Python and
Django might be easy to getting started with (or it is your feeling,
because you must learn the special syntax and its limitations, I bet
you had some “WTF?!” moments), but comes a time when your application
grows that you pay the price of being far from SQL (not counting the
maintenance cost).
With Mito and SXQL, it’s all regular Lisp, we are closer to the metal, the only limitation being to know the language, and a bit of SQL.
So we have a great example of why some Common Lisp libraries have a surprisingly low number of commits. You know, that little voice in your head that wonders if a library is finished or active. The author might not need to develop feature X, thanks to Lisp’s expressiveness. Likewise, many questions don’t need to be asked or upvoted on Stack-Overflow. Though I should have asked years ago.
- getting started with a DB: https://lispcookbook.github.io/cl-cookbook/databases.html
- more DB choices: https://github.com/CodyReichert/awesome-cl#database
You like what I'm doing?


Project Setup
MonkeyUser 22 09 2020
Para este episodio redondo 150 contamos con la compañía del colega desarrollador web Jesús Olazagoitia, todo un especialista en CSS y en tecnologías frontend. Jesús es organizador del meetup WordPress Logroño y realiza desarrollos modernos en WordPress basados en frameworks JavaScript.
Recientemente Jesús lanzó un original proyecto personal llamado Heliblocks. Se trata de un plugin para WordPress que te permite construir y reutilizar bloques o snippets de código independientes como si fueran bloques de Gutenberg. Con Heliblocks es posible crear bloques sólo con HTML y CSS, aprovechando las potentes funcionalidades de la edición de Gutenberg.
Con Jesús hablamos de los motivos que le han llevado a desarrollar este proyecto y las soluciones que trata de abordar. Hablamos de su integración con Gutenberg, las posibilidades que ofrece como marketplace de snippers y también la trayectoria futura del proyecto.
Aprovechando su experiencia con CSS para hablar sobre variables CSS, soporte de navegadores para propiedades modernas de CSS. También hablamos de lo que suponen los Headless CMS dentro de entornos CMS como WordPress, con tecnologías como Frontity.
Por último con Jesús hablamos sobre otro proyecto que tiene para realizar un sistema de diseño y además sobre el futuro de WordPress.
En la parte final del podcast volvemos con la sección de Radar, con una aportación variada de herramientas, enlaces y recursos de gran interés para el desarrollo web y creación de contenidos en internet.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Many developers think that having a critical bug in their code is the worse thing that can happen. Well, there is something much worst than that: Having a critical bug in your code and not knowing about it! Using some high school level statistics and a fair knowledge of SQL, I implemented a very simple anomaly detection system.
Tras el parón veraniego, retomamos los episodios del podcast para hablar sobre PHP. Para ello tenemos como invitado a Jesús Amieiro, un gran divulgador del lenguaje, a través de su newsletter / podcast La Semana PHP. Jesús es ingeniero de telecomunicación y desarrollador web, especialista en entornos PHP. Jesús además de su trabajo como director técnico en proyectos tecnológicos, es un gran conocedor del ecosistema PHP y participa en numerosos eventos como WordCamps y meetups.
Por si fuera Jesús saca tiempo para difundir oportunidades de empleo en un canal de Telegram, con ofertas de trabajo en el entorno PHP y reciente ha estrenado la versión podcast de su newsletter.
Entre las cuestiones que comentamos junto a Jesús Amieiro:
- Novedades más destacables de la nueva versión PHP 8.
- Repaso a la actualidad de los principales frameworks y gestores de contenido.
- Perfil profesional detectado a través de su canal de Telegram.
- El trabajo con la newsletter y el podcast La Semana PHP.
- Futuro del lenguaje y recursos interesantes.
En definitiva una charla muy completa con un entusiasta del ecosistema PHP, que nos deja con ganas de un nuevo episodio para tratar más tecnologías.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

Adjustment
MonkeyUser 08 09 2020

New Hire
MonkeyUser 31 08 2020
DebConf20 online closes
Debian News 30 08 2020

Wish 'Granted'
MonkeyUser 25 08 2020

Code Freeze
MonkeyUser 18 08 2020

Regex Explained
MonkeyUser 11 08 2020

Duplicates
MonkeyUser 04 08 2020

Art Overflow
MonkeyUser 28 07 2020
Some SQL Tricks of an Application DBA
Haki Benita 26 07 2020
Some tips and misconceptions about database development I gathered along the way.
Cognitect Joins Nubank!
Clojure News 23 07 2020
We are thrilled to announce that Cognitect is joining the Nubank family of companies. This is the next step in a long relationship, and opens new opportunities for Clojure worldwide. Please read the full story over on the Cognitect blog.
These are some are thoughts to keep in mind when we're contributing to a software project.
Know your tools
Git is maybe the most extended tool to manage version control in software and as a daily tool we should invest some time in knowing how to use it "properly".
Configure your name and email properly
This helps to identify who make a change while we're browsing git log history. Don't use initials or nicknames, in a few months or maybe years eventually you will be looking at the git log and if you see something like this Author: XYZ <xyz@some-random-provider.com> you won't have a clue who make that change. We can setup this information with:
git config --global user.name "name and last name"
git config --global user.email "work-or-personal-email"
We can use it without --global to make these changes only in the current repository.
Commits should have a title and a body
A easy to remember "rule" could be "Put what you did in the title and why you did it in the body". Memory is fragile and it could sound useless now but in a few months when you'll be looking at the log and see a commit and wanted to know why some change was made and the commit message just says "Fix some error" you probably will get angry with your past self.
There is an article that explains this so much better than me, you could read it at https://chris.beams.io/posts/git-commit/
An easy "hack" to force yourself to follow this is create a "commit template", it will be used when you make a commit and it will remind you about this rule. An example one could be:
# If applied, this commit will...
# Explain why this change is being made
# Provide links to any relevant tickets, articles or other resourcesThese lines are comments and won't be added to the final commit message.
Put this in ~/.git_commit_message.txt and then configure you ~/.gitconfig like this:
[commit]
template = ~/.git_commit_message.txt
After configuring this every time you make a commit the content of ~/.git_commit_message.txt will be filled into the commit message so that will remind you how to write a proper message. The editor/IDE you use to write a message will recognize this file.
Review what your staging
Friends don't let friend use
git add .
The tool you use to stage changes and then commit should allow you to stage chunks of code one by one. This way you can review what are you adding. You don't want to commit those debug messages or commented code that you were using while your working on the project. Or even worse you definitively don't want to commit credentials files.
Also if you like to use git from the terminal, you can use git add -p to use an interactive mode, this will go through all the unstaged changes and will ask you one by one if you want to add them.
Conventions and consistency
Most projects already have a CONTRIBUTING.md file. This file has some guidelines and conventions used in the project. Take your time to read and understand it. Those guidelines exist to keep consistency across the project. They're not fixed rules and of course they could be improved but always discuss that with your team.
Submitting a pull request
OK you're done with a feature/fix/whatever your were working on. It's time to submit a pull request. This is a simple checklist that could be followed:
-
Make sure your changes are in sync with the latest changes in
upstream. Maybe you're been working on something for a few days but some new changes were made to the project since the last sync. -
Make sure you ran the whole test suite, run checkers and others pre-commit workflow that your project have.
-
Check the commits you've made. Maybe you can clean a little bit the log, remove some
WIPcommits or improving some messages.
After you submit the pull request be your first reviewer before asking for more reviews. Once the pull request is created go to the pull request page on Github/Gitlab/etc and make a last check of your changes. Then assign the reviewers.
Use tags, this way you are adding extra information that will help to understand and categorize the pull request, by looking at the tags we can know if the pull request is a fix, improvement, documentation, etc.
Link your pull request with an issue. Github|Gitlab|etc have a nice feature to link pull requests with issues, for example if you're fixing a reported issue with number 10 add fixes #10 in the pull request description and this will link it to that issue, this way we can have traceability about the work done and the issues reported.
Improve pull request description, when you open a pull request Github|Gitlab|etc takes the first commit title and message and use them as title and description for the pull request so if we have made good commit messages most of the work is already done. Make review process a little easier by explaining what have you done. Maybe link another issues in different projects or bug reports related the changes you have made. Some extra context is always welcome :)
Code review
Keep in mind that comments made in your pull request are made about the code and not about you.
Don't take a comment as a fact that should be followed immediately, reviewers can make mistakes too, if you think some suggestion doesn't apply, explain your point of view and try to understand what is the reason behind that suggestion.
Don't make changes just to make reviewers happy and get your pull request merged. A code review is an excellent opportunity to get more knowledge about the project and to learn more about the code review process itself.
If someone rewrite or delete some code that you wrote it isn't mean necessary is was "bad code" or something like that, maybe the requirement was different back then. Code has to evolve and at the end what matters the most is that the application does what is supposed to do. Also in some cases you'll be the one who is refactoring or fixing your own code after a while it was made ;)

Side Project Showcase
MonkeyUser 21 07 2020
Mikelevins, https://news.ycombinator.com/item?id=23811382, July 2020
(some more comments on https://www.reddit.com/r/lisp/comments/hqesvp/explaining_the_advantages_of_the_repl/)
(on terminology: we should maybe call Python’s “REPL” a shell, and put emphasis on image-based development, instead of only saying REPL, for Lisp)
I’ve answered similar questions several times over the past few years, but I don’t mind repeating myself. It offers me a glimmer of hope that my preferred way of working may not fade away, after all.
Consider the standard Common Lisp generic function UPDATE-INSTANCE-FOR-REDEFINED-CLASS (http://clhs.lisp.se/Body/f_upda_1.htm). It reinitializes an object when Lisp detects that the object’s class definition has changed.
Ask yourself this: who would call such a function? Why would anyone ever invent it? Not only did someone invent it, a committee of some of the world’s smartest and most experienced Lisp programmers wrote it into the ANSI standard for the language. What were they up to?
UPDATE-INSTANCE-FOR-REDEFINED-CLASS is not a weird anomaly; it’s part of a carefully-considered set of features and protocols designed to support a specific style of programming. The Lisp runtime calls it for you automatically when it touches an object whose class definition has changed.
If you’ve defined a method specialized for it, then Lisp executes that method to rebuild the touched instance as if it had originally been instantiated from the class’s new definition, and then your program goes its merry way. If you didn’t specialize UPDATE-INSTANCE-FOR-REDEFINED-CLASS for this case, then the Lisp drops you into a breakloop.
A breakloop is an interactive repl with full access to all of the runtime’s memory and all of the language’s features, including visibility into the whole call stack that landed you in the breakloop. You can wander up and down the call stack, inspect anything in the runtime, edit bindings, redefine types and functions, and resume execution either at the point of control where the breakloop started, or at any other point for which the breakloop exposes a restart.
UPDATE-INSTANCE-FOR-REDEFINED-CLASS is not the weird fever dream of a confused eccentric. It’s part of a purposeful system design intended to support a style of programming in which you build a program by interacting with a live runtime and teach it, interaction-by-interaction, how to be the program you want, while it runs.
It’s a particular example of a general approach to programming best exemplified by these old systems. That general approach is the answer to your question: “Can someone knowledgeable explain how are lisp REPLs different from Python / Ruby REPLs? What is the differentiating point of REPL driven development?”
The differentiating point is that the entire language and system is thoughtfully designed from the ground up with the assumption that you’re going to be changing your work in progress while it runs, and that you should be able to change absolutely anything about it as it runs and have a reasonable expectation that it will continue to work while you do it.
I like to call this style of programming “programming as teaching”, and distinguish it from the much more widespread “programming as carpentry”, in which the programmer is, metaphorically speaking, at a workbench banging together artifacts and assembling them to see how they turn out.
To be clear, I do not claim that the teaching approach is objectively better than the carpentry approach. I claim only that I, personally, am happier and measurably more productive using the teaching approach. I know that some other programmers report the same thing, and I suspect that if the teaching style of programming were more widely known, then there would be more programmers who prefer it.
There are several sibling comments that assert that any language can be made to support repl-driven programming, or that offer various languages and systems as examples of repl-driven programming. I’m sure that’s all true, for some relatively restricted version of repl-driven programming, but the gold standard in repl-driven programming is programming as teaching in the style of old-fashioned Lisp and Smalltalk systems. These old systems offer amenities that the younger alternatives touted here do not match. I want more people to be aware of what they’re missing.
Starting in the 1980s, I grew accustomed to systems that could start from cold in about a second, presenting to me a complete interactive development environment with all tools preloaded and ready to work, with the whole dynamic environment of my work in progress in the same state it was in the last time I was working with it. Moreover, I was accustomed to being able to take a single file from one machine to another to reproduce that same whole working environment equally quickly and easily on the new machine.
I could save the entire dynamic state of the running system to an image file, a serialized version of the running system’s memory. I could later start up the system with that image file and be exactly where I was when I saved the image, right down to the positions and contents of all the open windows. I could save an image showing some bug or some strange behavior and give it to a colleague so that they could see it, too, and interact with the restored dynamic state to debug it.
I enjoyed comprehensive whole-system reflection that enabled me to view and edit absolutely everything in the running system while it ran. I could inspect absolutely everything, including the development environment and all its tools, interactively change any variable or field value, redefine any type or function, and continue to work with the changed system without stopping and restarting. (Obviously, if I made a bad change I might break the system, but remember, I could kill it and get back to where I started in a second or so).
I could start some process running–perhaps a 3D animation in a game, or a discrete-event simulation, or whatever–and change any values or definitions I liked to see what changed in the running process, without stopping the process to rebuild. For example, I could tell a rotating copper cube to become a glass icosahedron and reasonably expect to see my changes immediately reflected in the running program. This property is invaluable not only in games, simulations, and any kind of work with a visual-design component, but also in any kind of exploratory programming, where you’re constructing data structures and evaluating expressions interactively to test your ideas.
Similarly, I could build some speculative data structure to explore an idea, and define some functions to operate on it. I could evaluate those expressions to see their results or to change the example structure. I could inspect the structure interactively and edit it in place if I think something different would work better. If I think a problem is caused by some structure or value in it, I could use the inspector to change it and see. If I thought one my my functions was doing something I didn’t expect, I could insert a call to break, to activate a repl from inside the function call that would enable me to inspect and edit the data structure, redefine the function, and continue from there.
Anything the development system could do, I could do by typing an expression into the repl. As an example, nowadays you can still rebuild the whole Clozure Common Lisp environment from the ground up by typing (rebuild-ccl :full t).
The point is not that I would want to rebuld my Lisp from the repl all the time. The point is that the repl doesn’t impose any aribtrary boundaries on what I can do. If the language and development environment can do it, I can do it from the repl. This is one of the properties that distinguishes the whole-system interactive design of these old tools from the more limited repls offered by newer ones. In pretty much every repl I’ve used other than old-style Lisps and Smalltalks I’m all the time stumbling over things you can’t do from the repl.
I mentioned breakloops above. Their absence in younger languages and tools seem to me like some sort of sin, like we’re tragically abandoning some of the best lessons of the past. Few newer development systems have them, but they’re incredibly useful–at least if the language runtime is designed to properly support interactive programming.
A breakloop is a repl with all of the same affordances of the normal repl, but extended with all of the dynamic state of the control path that invoked the breakloop. If an error or an intentional call to break triggers a breakloop somewhere deep in a stack of recursive function calls, you get a repl that can see every frame of that stack, and every variable and value lexically accessible from it. You can browse all of that whole, change values, and redefine functions and types. You can resume execution at your leisure, and any changes you made in the breakloop will be visible in the resumed computation just as if that’s how things were originally.
Proper breakloops don’t just improve error messages; they replace them wholesale with an entire species of programming that lays the whole dynamic state of the system out on the table for you to examine and modify while the program continues to run.
Moreover, everything I just described about breakloops can also be automated. These old systems provide not only interactive tools for rummaging through the dynamic state of a suspended computation, but also APIs for handling them under program control. For example, you can wrap an arbitrary function call in condition handlers that will either drop you into a breakloop and enable you to vivisect the program state, or consult the dynamic state and compute which of several restarts to activate in order to transfer control to a path of your choosing.
I’m banging up against HN’s length limit, but the above, I hope, goes some way toward answering to your question.
Vuelve nuestro amigo Antonio Pérez al podcast para otro episodio compartido con su programa Full Stack Podcast. Antonio ya nos acompañó allá por el episodio 78 en un programa titulado Ruby on Rails frente a Python. En ese episodio Antonio nos estuvo contando cosas muy interesantes sobre Ruby on Rails y para este episodio hemos preparado el contenido alrededor del perfil de backend.
¿Qué habilidades clave debería tener un profesional del backend?
Para Antonio Pérez, un desarrollador de backend debe tener un perfil muy completo con unas habilidades muy distintas: Una capacidad alta de abstracción, conocimientos de arquitectura web y un conocimiento amplio de bases de datos.
Para Andros un backend debe tener la capacidad de leer y entender el contexto de lo que está realizando. Por eso es importante acudir a la documentación y a los manuales. Otro aspecto es entender que es normal que no se pueda saber de todo. Por último, Andros también coincide sobre la importancia de conocer de manera sólida las bases de datos.
David Vaquero coincide en la necesidad de tener una base muy sólida del protocolo HTTP. También que el backend entienda bien los datos que está manejando y cómo se mueven. Y también vuelve a coincidir con la gestión de datos, caché y optimización. Por último David hace mención al conocimiento de API y al Server Side Rendering.
Para finalizar Javier comenta que a menudo el perfil de backend se asocia al conocimiento de un lenguaje de programación. Otro aspecto a destacar es el conocimiento de la computación y los bases del sistema operativo, procesos, memoria y red.
Gran parte de los proyectos backend que se están ejecutando implican tareas de mantenimiento, monitorización y mejora. Con independencia del lenguaje, el backend necesita mucha investigación y aprendizaje.
La importancia de la gestión de las bases de datos y la memoria caché
Como comenta Antonio, el backend un última instancia es servir datos: cuando mayor conocimiento y eficacia en la capa de base de datos, mejor funciona la parte de backend. Conocer los motores de bases de datos, profundo conocimiento de SQL y conocer los ORM.
Andros habla sobre lo básico de entender la gestión de bases de datos y pone como ejemplo la aplicación de Notion y lo fundamental que es optimizar en la capa de datos. También incidimos en el conocimiento de los básicos como programación orientada a objetos, computación y redes. Una recomendación que hacemos es el libro The Secret Life of Programs publicado por No Starch Press.
Por último David destaca que el mundo de las bases de datos también incluye las tecnologías NoSQL y que hay que separar la teoría de base de datos con la práctica.
Escribir sentencias SQL vs ORM
Otro de los temas que han surgido en la conversación son los ORM vs la escritura de sentencias SQL. Antonio explica cómo en ciertas ocasiones escribir directamente las sentencias SQL resulta más productivo o eficaz que depender de un ORM. Antonio destaca Active Record de Rails como una herramienta flexible para trabajar con el acceso a datos. También hablamos brevemente algunos de los ORM más habituales.
El back end es la parte más cercana a la lógica de negocio y por tanto debes tener un conocimiento muy preciso y amplio de cómo funciona un negocio a
El papel del cloud en el backend y el serverless
Hay espacio para comentar cómo está evolucionando la computación en el lado de servidor con los servicios en la nube y más específicamente con el serverless tipo AWS Lambda. Con todo, son tecnologías que tienen un espacio determinado y que conviven con diferentes opciones en el lado de servidor. Antonio nos detalla algún ejemplo donde puede encajar este tipo de tecnologías. Otro aspecto a tener en cuenta es la optimización de esas funciones sin servidor porque pueden salir más caras que una arquitectura convencional cliente/servidor.
Tecnologías de backend a tener en el radar
Antonio nos cuenta algunas tecnologías a tener muy en cuenta como la contenerización, micro-servicios, serverless, entornos elásticos en la nube y la asincronía. También reserva un espacio para hablar sobre el papel de JavaScript en el lado servidor y sus reservas con respecto a sus ventajas en materia de asincronía. Por último Antonio nos ha contado sus proyectos futuros, como una web de cursos de desarrollo, estudiando tecnologías como Data Science y NoSQL.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
The idiomatic comparison in Python
Isaak’s Blog 08 07 2020
Nuestro episodio 147 con Manz se alargó tanto que se nos quedaban algunos temas pendientes que no queríamos perder. Por eso le planteamos a Manz un episodio adicional como bonus, dirigido a hablar sobre sus plantillas o chuletas (cheat sheets). Desde hace años Manz distribuye de manera gratuita estos útiles recursos para aprender desarrollo web.
Manz nos cuenta el origen de estos recursos, cómo las diseña y el público que las consume. Manz publica estas plantillas bajo un modelo de donación, pero como descarga libre y gratuita.
En esta conversación también surgen otros temas interesantes como son el papel del idioma inglés en los contenidos, el aprendizaje del desarrollo web y la especialización versus los perfiles generalistas en la profesión.
Como hemos comentado en el podcast con la entrevista, esperamos poder compartir con Manz alguna episodio adicional para tratar más temas sobre diseño y desarrollo web.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
En este episodio tenemos como invitado al divulgador Manz, autor del blog Emezeta y creador de la chuleta (o cheat sheet) HTML/CSS/Javascript más popular de la web. Actualmente Manz compagina su actividad de profesor en la Universidad de La Laguna (Tenerife) con otros proyectos profesionales. Man empezó como profesor en la Oficina de Software Libre impartiendo cursos de formación en temáticas relacionadas con el desarrollo, la programación web, front-end, back-end, cloud computing, marketing digital o temas relacionados con la tecnología de internet.
Manz además mentoriza proyectos y startups en la Escuela de Organización Industrial. También colabora como formador y consultor en programas de emprendimiento de la Fundación INCYDE. Con él hablamos de JavaScript, Web Componentes, CSS, Shadow DOM, gestores de tareas y un montón de cosas interesantes relacionadas con el front-end.
Entre las cuestiones planteadas con Manz:
- Javascript-fatigue, ¿el Front-End es una carrera de fondo sin una meta definida?
- ¿Qué son los Webcomponents? ¿Shadow DOM? ¿Son el futuro? Ejemplos prácticos.
- CSS-in-JS, ¿estamos invadiendo territorios o creando naciones?
- ¿Por qué necesitamos automatizadores? ¿En que se diferencian: Parcel / Webpack / Rollup / Gulp?
Una interesantísima conversación con un divulgador y apasionado de las tecnologías web, con el que además dedicaremos un episodio bonus para contar su trabajo con las plantillas y sus cheat sheets de diferentes lenguajes.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
The beginning of the way
Isaak’s Blog 04 07 2020
50 Shades of Dark Mode Gray
blog.karenying.com 03 07 2020
404: React Page Not Found
blog.karenying.com 02 07 2020
En este podcast hemos tratado en alguna ocasión cuestiones relacionadas con el código abierto y la dificultad que conlleva vivir de los proyectos abiertos. En este programa volvemos con estas cuestiones y hemos invitado al desarrollador especialista en WordPress, José Conti para hablar sobre GPL, o la licencia pública general GNU. Recientemente José Conti publicó un sólido artículo titulado Vivir la GPL o explotar GPL, donde trataba con detalle su vinculación profesional y personal con el software libre, y al mismo tiempo, explicaba la forma en la que muchas personas se aprovechan de ella, buscando exclusivamente un beneficio personal.
Con José Conti discutimos entre varias cuestiones, la finalidad de la licencia GPL, cómo encaja la GPL en el desarrollo y venta del software, su financiación y el día a día de un desarrollador que vive de un proyecto bajo esa licencia.
Entre las preguntas planteadas a José Conti, tenemos:
- ¿Qué fines fundamentales persigue la licencia GPL?
- ¿Es acertado el planteamiento de la licencia GPL a la hora de repercutir valor económico al desarrollador?.
- En tu artículo explicas que se han popularizado los sitios de reventa de plugin con un precio inferior y saltándose al desarrollador. Se amparan en que la GPL permite vender software, aunque sea una de las cuestiones más complicadas de entender de la licencia…¿Cómo explotan estos sitios la filosofía abierta de la GPL?
- ¿Son los usuarios conscientes de lo que cuesta mantener los proyectos de software?
- ¿Qué modelo considerarías más acertado para recompensar a los desarrolladores de software libre?
- ¿Qué visión tiene la comunidad WordPress respecto a la GPL?
- ¿Cómo es tu plugin de RedSys por dentro y qué relación tienes con ellos?
En resumen una animada conversación con un profesional del software vinculado a un proyecto GPL y con una experiencia de gran valor creando soluciones abiertas y libres.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
A Brief Hiatus
Josh Comeau's blog 25 06 2020

Schmuck
MonkeyUser 23 06 2020
El primer aniversario de nuestro compañero David Vaquero en el podcast, nos da pie a realizar un episodio personal donde David nos cuente lo que ha supuesto este primer año. Aunque en este episodio hablemos de la experiencia de David, es un buen episodio para destacar lo que supone participar y producir un podcast. Es una buena oportunidad también para hacer algo de balance del último año y hablar sobre la dirección que puede tomar el programa en el futuro.
Entre las cuestiones que hablamos con David se incluyen:
- ¿Cómo empezaste a escuchar el podcast?
- ¿Qué ha mejorado de tu parte profesional y personal hacer este podcast?
- Te estás encargando de poner videos en tu canal de Youtube …¿Qué tal la experiencia?
- ¿En qué dirección debería progresar el programa?
En la segunda parte del programa tratamos en la sección Radar, la aparición de la nueva versión de Bootstrap en su quinta edición (en alpha), también de Quasar un framework basado en VUEJS para PWA, Cordova/Capacitor y Electron. Por último comentamos un interesante recurso pedagógico para comprender mejor Amazon Web Services.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

Release Cycle
MonkeyUser 16 06 2020
Seguimos en el podcast con los estudios de las tecnologías más utilizadas en la web, basado en el estudio de David Vaquero sobre el millón de páginas web según Alexa. En esta ocasión nos detenemos a analizar los datos de los lenguajes de backend más utilizados. Uno a uno vemos los principales lenguajes y tecnologías web que representan el top del ranking. Entre ellas:
- PHP
- LUA+ OpenResty
- Python
- Asp.NET
- Java + OpenGSE
- Ruby + Ruby on Rails
- Javascript + NodeJS + ExpressJS
Accede al estudio de David Vaquero en su página web. Estudio lenguajes Backend sobre millón de sitios web de Alexa.
En la segunda parte Andros nos trae su último proyecto, un framework web llamado Tadam y que está realizado en Clojure. Se trata de un minimalista framework para crear sitios web dinámicos orientados a la programación funcional. Andros nos cuenta el potencial de Clojure para un desarrollo moderno y más fiable, al depender de un paradigma funcional, más fácil de detectar errores y mucho más predecible.
Para finalizar el episodio traemos en la sección de Radar, unos cuantos recursos de interés, noticias y herramientas que os ayudarán en vuestro desarrollo profesional. También comentamos algunas de las encuestas que Andros ha lanzado en nuestro grupo de Telegram Malditos Webmasters.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

Pair Programming
MonkeyUser 09 06 2020
Dear lispers,
I decided that I can not develop three projects in parallel fast enough, so I’m seeking for a fellow programmer to join the effort.
Disclaimer: this is not a real position, but there is a little budget
I recently presented my online catalogue for bookshops. You will work on something very similar, but bigger. I need help to re-write the existing free software for bookshops in Common Lisp. The existing one is in Python. I have a prototype of the new CL one.
The software specifications are here and are good. We wrote them years ago by consulting people selling books, and we now grow on our experience acquired developing the first Python app as well as on the feedback gathered from clients. The challenge is to build a maintainable, fast, bug-free, easily-deployable application with an user interface that answers the clients’ needs.
I ask you to have some experience in:
- Common Lisp
- the web: HTML, CSS, web browser API
- SQL
You should also have a sufficiently good english to speak with me (a non-native speaker).
I would have tasks for you in June and July, nothing in August, and hopefully more in September and onwards.
Bonus points include, in no particular order:
- acquaintance with JavaScript, with a JS framework (preferably Vuejs)
- good HTML&CSS design skills
- you speak french
- you have a good english, or good communication skills in your mother tongue
- good backend and “devops” experience
- Python experience to install and study an existing project
If this appeals to you, please email me at (reverse
"gro.zliam@leradniv") and indicate roughly how you stand in these
points, your availability in June, during the upcoming two weeks
for a meeting, and we’ll speak further.
Thanks!
Stop Using datetime.now!
Haki Benita 31 05 2020
If you ever had a test that one day just started to fail, unprovoked, or a test that fails once every blue moon for no apparent reason, it's possible your code is relying on something that is not deterministic. In this article I describe a practical approach to dependency injection in Python that when used correctly, can eliminate nondeterminism and make your code easier to maintain and to test.
En qué ando: edición confinamiento
Onda Hostil 31 05 2020
Invitamos a Álex Barredo para hablar sobre el estado de los navegadores web y el ecosistema actual de uso. Además de su faceta de divulgación tecnológica en sus diferentes canales (mixx.io podcasts y newsletters), Álex también siente debilidad por el mundo de los navegadores y hasta tuvo un blog donde contaba las novedades que iban surgiendo en torno a ellos. En este episodio especial hablamos con Álex de la situación actual y del aplastante liderazgo de Google en el ámbito de los navegadores de escritorio y móviles.
Entre las cuestiones que tratamos:
- ¿Seguirá siendo todavía más en el futuro? ¿Se vislumbran planes para limitar con legislación antimonopolio al gigante de Google?
- El año pasado Microsoft Edge se rindió a los pies de Chromium, el software de código abierto que lidera Google, pasando a usar Blink y V8 como motores.¿Ha sido una decisión buena para Microsoft y mala para competencia?.
- Primeros navegadores, orígenes de Internet Explorer y las guerras de los navegadores en el 2000.
- Porcentajes de uso, competencia actual entre navegadores y situación con respecto Europa, América y Asia.
- El papel de la fundación Mozilla y el estado actual de Firefox.
- Modelos de negocio alternativos para los navegadores y caso Brave.
- Apple y su papel en el desarrollo con Safari.
Posiblemente Álex sea una de las personas mejor informadas del panorama tecnológico y es un lujo poder compartir con él un rato para hablar sobre el estado actual de los navegadores web. Sin duda es un tema que seguirá avanzando durante los próximos meses y que ofrece un escenario donde los grandes de internet y la tecnología se disponen a seguir combatiendo en uso y funcionalidades.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
I wrote a free software for bookshops to publish their catalogue online. Clients can now browse the available books and order them. It is enough generic so we can show other products too.
- https://abstock.gitlab.io/#/en/
- sources and bug tracker: https://gitlab.com/vindarel/abstock
- Github mirror: https://github.com/vindarel/ABStock
- the demo
Here’s how a search result looks like:
Features
The website is made generic enough for different clients, and is made totally hackable with pre- and post- configuration files that load your Lisp logic.
By default we get the following pages:
- the welcome screen, with:
- the bookshop’s information,
- the search form. We can search by title, authors, publisher, shelf and ISBN(s).
- a random pre-selection of the books to showcase, if enabled.
- an optional special page to showcase a selection of books or other products.
- in the search results page, visitors can add a book to their shopping basket.
- and in the basket page, they find a confirmation form, which sends the command by email to the shop owner.
There are obvious TODOs, that could be shocking by their absence, but that I actually don’t need yet, so they’ll come right in time :)
- online payment
- admin page
- simple stats (they are brought in with the email provider, and with Matomo statistics)
- i18n, remove a still few hardcoded words
Data
ABStock connects by default to the Abelujo database. Abelujo is a free software for bookshops that I also develop. Booksellers use it for their daily work, registering and selling books.
But we can define our own products. The current possibility is
to use a cards.txt file. Each block expects a title, and that’s
the only mandatory field. Other recognized fields are:
((:|id| integer)
:|title|
:|cover|
:|isbn|
:|price|
:|author|
:|publisher|
:|date_publication|
:|date-publication|
:|shelf|
:|shelf_id|
:|details-url|
:|summary|
:|quantity|
:|repr|
:|repr2|)
We can define other fields, like likes below, which is
actually unused in the application.
[…]
title: Programming Algorithms
author: Vsevolod Domkin
cover: https://d2sofvawe08yqg.cloudfront.net/progalgs/hero?1586867024
details-url: https://leanpub.com/progalgs
shelf: programming
shelf_id: 99
publisher: Leanpub
price: 15
likes: 5
title: Cats
author: mother cat
cover: https://gitlab.com/abstock/abstock.gitlab.io/-/raw/master/logo.png
details-url: https://gitlab.com/abstock/abstock.gitlab.io/-/blob/master/logo.png
shelf: nature
shelf_id: 98
publisher: nature
price: 5
likes: 100
title: Screwdriver
author:
cover: https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Ftse1.mm.bing.net%2Fth%3Fid%3DOIP.jGOb7dVL1oA9VDzNVPDPpwAAAA%26pid%3DApi&f=1
details-url:
shelf: craftmanship
shelf_id: 97
publisher:
price: 10
likes: 1
(yes there’s a little redundancy with shelf and shelf_id to fix)
That gives:
We could very well load a JSON, a CSV or another database when the need arises.
For now, we think the text loader is enough for you to define your products and try the application.
It is also very easy to host, and in doing so one can realize that to live-reload his Lisp web app is straighforward and very convenient.
Context
I shipped the app the second month of our lockdown period for the client I was working for at that moment, and no need to say it turned 100% helpful. Amazon had hell of an activity, and french alternatives for booksellers (such as lalibrairie.com or placedeslibraires.fr) either had stopped, either couldn’t accept new registrations. So we were left alone, and we did that. His clients were happy, they started passing orders, he organized collection schedules. This happened in a small rural village, where the inhabitants are happy to have, at least, a (nice) bookshop in their village.
Paying one’s rent with Lisp
So yes, I paid my rent with Common Lisp again \o/ And you see, the software is a classical web app. I could have made it with Python or another language that has a web server and a templating library. As I defended before, the app doesn’t exist thanks to CL’s super powers. CL had no particular advantages for this kind of web app, but no disavantages either: it has a good web framework, a good templating library that I liked a lot (Djula: defining custom filters was a breeze), a good SQL wrapper, and that’s all I asked. I use CL’s super powers during development and deployment. Clients wouldn’t see the difference… or would they?
Actually, CL has advantages overall: development speed, ease of deployment, ease of hot-reload, ease to use the language features to bypass a library’s limitation (easy-routes had no built-in to translate a route URL, but it turned possible with a reader macro)… not mentioning ease of maintenance in time, speed, etc.
One production bug I had was due to (me apart for not testing enough)
(= 3 nil) throwing an error, so you must had prior checks (or, I
just realize, use equalp?). My Sentry dashboard is empty anyways.
Final words (with bonus)
The Big Plan is to Rewrite It (the other software) In Lisp, and the project just moved from R&D to POW… stay tuned, particularly if you don’t know what to do in june and july, I might have a small budget for a helping hand.
| Become a Patron! |

|
Scraping a website
Posts on James Routley 27 05 2020
Local Testing on an iPhone
Josh Comeau's blog 26 05 2020

Dev's Journey
MonkeyUser 26 05 2020
Hablamos sobre administración y gestión básica de VPS con Manuel Rosa, un inquieto Ingeniero de Telecomunicaciones especializado en electrónica. Manuel lleva varios años dedicándose a diferentes facetas del mundo tecnológico y todavía sigue iniciando diversos proyectos. Actualmente Manuel Rosa trabaja para una empresa de seguridad informática y además saca tiempo para realizar sus propios proyectos de e-commerce, marketing y SEO.
Con Manuel Rosa hablamos sobre la administración esencial de VPS, la tremenda competencia que existe en el mercado de servidores virtuales y sobre las herramientas recomendadas para gestionar tu propio VPS. Con Manuel hablamos de las siguientes cuestiones:
- ¿Qué criterios deberíamos tener en cuenta para escoger un buen proveedor de VPS? ¿Algunas recomendaciones personales?.
- ¿Qué es lo primero que configuras en una VPS a parte de la clave ssh?
- ¿Qué acciones recomiendas realizar para garantizar la seguridad mínima en un VPS? ¿Cuáles son las amenazas más habituales?.
- ¿Qué distribución recomiendas para la VPS?.
- ¿Qué tareas de mantenimiento son necesarias para un correcto funcionamiento de un VPS?
¿Cómo gestionas el backup de una VPS? ¿Algún software recomendado?. - Docker y kubernetes para manejar la infraestructura.
- ¿Cómo ves el futuro de este tipo de productos?.
- ¿Cuándo deberíamos pasar a un servidor dedicado?.
Una interesante charla con Manuel al que emplazamos a otro episodio para que nos cuente otros proyectos y su experiencia a la hora de lanzar proyectos comerciales en internet. Puedes contactar con Manuel a través de su propio LinkedIn.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Animated Sparkles in React
Josh Comeau's blog 19 05 2020

Code Superheroes
MonkeyUser 19 05 2020
Kubernetes cli tool kubectl is pretty useful but when I need to execute some tasks many times during a work day it could be too verbose. So I wrote some bash functions to handle a few common tasks I use often.
I used the power of fzf to create an interactive experience when I run any of these functions. Basically it pipes the output of a kubectl command, make some filtering using sed and awk and then build a final command which will execute what I want.
The common behavior of these functions is first ask for a namespace and then ask for a specific pod to make some action over its.
We can see an example of how it works in the image below:
Open a shell or a custom command inside a pod
If we execute pod_shell without any argument it will connect to the selected pod and run bash, otherwise it will run the given command.
function pod_shell {
local namespace=`kubectl get ns | sed 1d | awk '{print $1}' | fzf`
local pod=`kubectl get pods -n $namespace | sed 1d | awk '{print $1}' | fzf`
echo "Connecting to $pod"
if [ -z $1 ]
then
kubectl -n $namespace exec -ti $pod bash
else
kubectl -n $namespace exec -ti $pod $1
fi
}Run a proxy over a pod
Same as the previous function but this one ask for a port mapping, for example 9999:5432 will map the port 9999 from the host machine to 5432 port on the pod.
function pod_proxy {
local namespace=`kubectl get ns | sed 1d | awk '{print $1}' | fzf`
local pod=`kubectl get pods -n $namespace | sed 1d | awk '{print $1}' | fzf`
local port_mapping
echo "Enter port mapping using the form local_port:pod_port"
read port_mapping
echo "Setting up proxy to $pod on $port_mapping..."
kubectl port-forward -n $namespace $pod $port_mapping
}See realtime logs for a given pod
This one just ask for a pod and attach a kubectl log command.
function pod_logs {
local namespace=`kubectl get ns | sed 1d | awk '{print $1}' | fzf`
local pod=`kubectl get pods -n $namespace | sed 1d | awk '{print $1}' | fzf`
echo "Showing logs for $pod"
kubectl -n $namespace logs -f $pod
}Change context
Switch between configured contexts
function k8s_change_context {
local context=`kubectl config get-contexts --output='name' | fzf`
echo "Changing to $context"
kubectl config use-context $context
}These are some common tasks I need for a day of work but with the same logic we can build some other commands.
Org-mode has a nice feature that allow us to edit source code within an org file, for more info check the docs. But it has a little annoying behavior after we are done editing a source block. It loses the previous window configuration and always closes all the windows except the org window.
In the image below we can see this behavior:
To solve this problem we can use a simple variable to store the current window configuration just before the source code edition buffer is opened and when it's closed we can restore the previous configuration just getting the value from the variable used before. We're defining two functions to accomplish this behavior, one to run before and one after we're done editing the source block.
(defvar my/org-src-block-tmp-window-configuration nil)
(defun my/org-edit-special (&optional arg)
"Save current window configuration before a org-edit buffer is open."
(setq my/org-src-block-tmp-window-configuration (current-window-configuration)))
(defun my/org-edit-src-exit ()
"Restore the window configuration that was saved before org-edit-special was called."
(set-window-configuration my/org-src-block-tmp-window-configuration))Now we need to "attach" these two functions to the default behavior of org-mode, to do this we can use advice-add elisp function, this function allow us to "attach" some functionality to an existing function.
The two functions that we need to advice are:
-
org-edit-special: this function is called when we pressC-c C-'and allow us to edit source block in a dedicated buffer. -
org-edit-src-exit: this function is called when we pressC-c C-'from inside of the opened buffer, it closes the buffer and return us to the org buffer.
my/org-edit-special will run just before org-edit-special is called and my/org-edit-src-exit after org-edit-src-exit is called.
We need to execute this code after org is loaded so we use eval-after-load.
(eval-after-load "org"
`(progn
(advice-add 'org-edit-special :before 'my/org-edit-special)
(advice-add 'org-edit-src-exit :after 'my/org-edit-src-exit)))The full code will be:
(defvar my/org-src-block-tmp-window-configuration nil)
(defun my/org-edit-special (&optional arg)
"Save current window configuration before a org-edit buffer is open."
(setq my/org-src-block-tmp-window-configuration (current-window-configuration)))
(defun my/org-edit-src-exit ()
"Restore the window configuration that was saved before org-edit-special was called."
(set-window-configuration my/org-src-block-tmp-window-configuration))
(eval-after-load "org"
`(progn
(advice-add 'org-edit-special :before 'my/org-edit-special)
(advice-add 'org-edit-src-exit :after 'my/org-edit-src-exit)))After applying the complete code the result will be:

Enjoy!
Dedicamos este episodio a hablar sobre los sitios estáticos y el espectacular crecimiento que está experimentado el ecosistema. Sin duda el auge del JAMstack, está revolucionando la forma de trabajar un sitio web, con flujos de trabajo más sencillos, costes de mantenimiento más bajos y un rendimiento muy superior en tiempos de carga, a los acostumbrados con sistemas dinámicos. Gracias a la gran cantidad y calidad de generadores de sitios estáticos, podemos ofrecer soluciones web que ofrecen un entorno moderno de desarrollo y al mismo tiempo, aprovechan las tecnologías de acceso a datos a través de API. Desde sencillas páginas corporativas hasta blogs y páginas personales, las páginas estáticas resultan una solución ideal para servir proyectos más escalables, sin casi necesidad de mantenimiento.
Las herramientas derivadas del JAMstack están propiciando que servicios como Netlify o Vercel, permitan el despliegue global de complejos proyectos web, a través de su plataforma y con unos costes que se encuentran muy por debajo de soluciones similares. También existen soluciones que permiten desacoplar tu CMS y concentrarte por separado en las capas de presentación y datos (Headless CMS). El futuro de estas herramientas pasa por integrar cada vez más a los usuarios finales (CMS más fluidos y fáciles de editar) y en proporcionar integraciones con otros servicios a través de APIs o servicios externos.
Entre las cuestiones tratadas en el episodio:
- ¿Qué es un sitio estático y qué ventajas ofrecen?
- ¿Deberían ser muchos sitios web estáticos? ¿CMS innecesario?
- Explosión de generadores de sitios estáticos.
- El auge del JAMStack.
- ¿Qué son los flat-file CMS?.
En la segunda parte del episodio ofrecemos interesantes recursos y enlaces relacionados con el desarrollo web. Encuentras todos esos enlaces más abajo y también los discutidos en el episodio.
Versión vídeo con capturas de la sección Radar
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
We all know that we can start a web server in the REPL and develop a
web app as interactively as any other app, we know how to connect to
a remote Lisp
image
by starting a Swank server and how to interact with it from our
favorite editor on our machine, we know we can build a self-contained
binary of the web app and simply run it, but one thing I had not
realized, despite being the basics, is that by starting the web app
with sbcl --load app.lisp, we are dropped into the regular Lisp
REPL, with the web server running in its own thread (as in development
mode, but unlike with the binary), and that we can consequently interact with the running app.
As a demonstration, you can clone this repository and run the example like this:
* rlwrap sbcl --load run.lisp
This is SBCL 1.4.5.debian, an implementation of ANSI Common Lisp.
re information about SBCL is available at <http://www.sbcl.org/>.
[…]
; Loading "web-live-reload"
..................................................
Starting the web server on port 7890
Ready. You can access the application!
*
it will load project.asd, install 3 Quicklisp dependencies (you must
have Quicklisp installed), start Hunchentoot on port 7890, and drop us
into a REPL.
You’ll get this:
The template prints the *config* variable, which you can change in the REPL:
* (in-package :web-live-reload)
* (setf *config*
'((:key "Name"
:val "James")
(:key "phone"
:val "0098 007")
(:key "secret language?"
:val "Lisp")))
refresh, and voilà, your new config is live.
For functions, it is just the same (redefine the function fn that
returns a string, if you want to try).
If a file changes (for example after a git pull), compile it with a
usual load: (load "src/web.lisp").
You can also reload all the app with (ql:quickload :myproject),
which will install the dependencies, without needing to restart the
running image.
I was looking for a way to reload a user’s config and personal data from a running website, and this has proved very practical. I have no downtime, it is pure Lisp, it is the workflow I am used to. I am more cautious on using this to recompile the whole app, even though I did it without glitches so far. The thing to not do is to change the global state manually, aka to develop in production!
That’s all, but that made my day.
Bonus points:
- after a git pull, the (Djula) templates are automatically
updated. No operation is needed to see them live. (you can disable
this by pushing
:djula-prodinto the features set) - you’ll understand and appreciate the difference between
defparameteranddefvar. Imagine you declare a variable with(defparameter *data* nil)and you populate it with some heavy computation at the application startup. Now if youloadthe file this declaration is in, you’ll set the data back tonil. If you declare it withdefvar, you can live-reloadyour app and the data doesn’t go away. You can try both cases with the*config*variable. - the app started a Swank server on port 4006, if you want to try on your VPS.
Nearly one year ago, I received an email that asked me if I was available to do remote Lisp work. It was the day before the end of a contract and I had to tell my team if I wanted to continue or not. I made a virtual offering to the Lisp god and I started the Lisp job.
Disclaimer: this post was written on Lisp Advocates’ reddit. Lisp Advocates is a meme, but it’s sort of serious too.
At this time I had been in Lisp for around two years, contributing a couple simple libraries, writing a lot of documentation, blogging, furnishing the reddits, and being enthusiastic and polite. This is what actually gave me the job. I had tried to contribute to a busy CL repository, but the PR was not good enough and that irritated the maintainer, who answered abruptly. Nothing’s more outrageous than receiving contributions right? But I answered with calm and professionalism, and that got noticed by a repository watcher, who decided he could work with me.
That guy already had contacts and a client, and he formed a team around him. Our work was to build a website that would receive many visitors, that would have a client registration form and would have a rather simple admin dashboard, for a team of half a dozen people. The business already existed in the form of a buggy and slow Wordpress site, so the expectations were clear. We were three, we worked together on the same code (with one guy more on the design). I worked on it in a two-months period, but not full time. I’ve had a decent income paid straight and so I paid my rents for a few months thanks to that experience.
What Lisp was good for
The application had no inherent difficulties. It had forms and an admin backend. It was a website for a team of commercial people, as it exists hundreds of thousands. And yeah, Common Lisp was suited for that task. So we see there’s a good margin of progression, business and remote work wise: those thousands of websites for commercial people can very well be done in CL.
Libraries, deployment and Lisp curse
We picked the Caveman framework, the Mito ORM and the cl-markup templating library, with some tests in FiveAM. There was a little bit of JavaScript, less than a thousand lines. I find Caveman a bit convoluted but it was clear and easy. I like Mito very much and wrote material for it. I liked to play with the web server debugging options: usually I received the stacktraces in the debugger in my editor, but I could choose to display them on the browser (as I’m used with Django or Flask). It is this time that I enjoyed so much being able to change the faulty function, recompile it, choose the “try again” restart and see the operation succeed. Now when I’m back on Python I feel the Lisp curse. I’ll never be the same. I’ll never enjoy Python as much as before. Sigh. Anyways, we deployed the app on DigitalOcean with Fast CGI, as documented on Caveman’s README.
The bug
Our most difficult bug that made us loose millions was due to
(string-downcase nil) to return “NIL”, the string, instead of
nil. Now I use my str library
for string manipulation purposes.
All in all, being able to live-debug the software from the earth proved invaluable.
I got also hit by a config of mine that impacted Mito’s results. I had
set *print-case* to :downcase in my .sbclrc. I was asking Lisp to
DON’T SHOUT AT ME ALL DAY LONG, ‘cause I try to listen to music at the
same time. I fixed the Mito bug, but I don’t use this setting anymore.
Voilà. This is my response to LispAdvocates’ call: https://www.reddit.com/r/lispadvocates/comments/ficdvx/tell_us_you_remote_success_story/.
There are of course lots of situations were CL is ready now to get the (remote) job done. There are people who do web dev for years in CL, but we don’t know their story.
Share yours!
ps: stay tuned, ‘cause I deployed another website in production.
Some comments and answers:
Apart from the programmer experience, were there any inherent advantages to using Common Lisp? (Speed I guess?)
CL had no particular advantages, but no disadvantages either (and it is my point!). As I said, it was a site with basic/easy/HTML&JS requirements, so I believe no language would’ve had any particular advantage. Speed was important, it was one of the main requirements. The website felt responsive, the client was very happy about it. For us, it was also easy and fast to deploy, which turned important and impressed the client.
Do you thinK a more standardized framework (from other languages) could have saved you?
No, not with our requirements. Another framework&language would have make us loose millions at the very beginning (still figuratively)
Dedicamos este episodio al DevOps Tools Report 2020 realizado por Gitkraken. Este informe proporciona una guía sobre las mejores herramientas DevOps, según una comunidad global de 2700 desarrolladores. DevOps se está convirtiendo en el estándar para realizar operaciones y desarrollo de software. Este completo informe hace un recorrido de las herramientas DevOps usadas en la actualidad para dibujar, un ciclo de vida completo del desarrollo de software.
Como indican en la introducción del informe, la transición hacia una cultura de DevOps requiere cambios significativos que incluyen un cambio en la mentalidad del personal, la introducción de las herramientas apropiadas y la adquisición de nuevas habilidades. Sin importar en qué fase te encuentres de tu transformación DevOps, el foco debería estar siempre en la mejora continua. Comienza con las bases y después identifica tus limitaciones propias. Una vez superes esas limitaciones, repite el proceso.
El informe se muestra siguiendo un gráfico en forma de infinito, donde se muestra la condición de continuidad y de iteración en el proceso de DevOps. Las fases corresponden a cada una de las disciplinas del desarrollo moderno de software: Planificación, codificación, Empaquetado / construcción, Testeo, Configuración y lanzamiento, Despliegue, Operaciones y Monitorización.
Cada uno de estas fases incluyen unas herramientas, que a menudo, se van repitiendo en otras fases:
| FASE | Herramientas | Otras |
|---|---|---|
| PLAN | Jira, Trello, Gitkraken Boards, GitKraken Timelines. | BaseCamp, MantisBT. |
| CODE | Hosting: GitHub, Bitbucket, GitLab y Azure DevOps. Git / SCM: GitKraken Git GUI, CLI, GitHub Desktop, Sourcetree. IDE: VS Code, IntelliJ, Visual Studio, Sublime Text. |
Eclipse |
| BUILD | Jenkins, Maven Visual Studio, Gradle | |
| TEST | JUnit, Selenium, Jest, PHPUnit. | Cypress, Postman, Swagger. |
| RELEASE | Ansible, Azure DevOps, Chef, Jenkins, AWS Codebuild. | Puppet, Circle CI. |
| DEPLOY | Jenkins,Azure DevOps, AWS Codebuild, GitLab. | |
| OPERATE | Kubernetes, Docker, AWS | |
| MONITOR | Google Analytics, Grafana, Azure Monitor, AWS CloudWatch | Datadog, New Relic |
En el episodio destacamos el auge imparable en los últimos años de las herramientas cloud y cómo la metodología DevOps irá creando perfiles específicos que gestionen su complejidad.
También dejamos el webinar que realizó la semana pasada David Vaquero para Nextraining y titulado, 4 Herramientas OpenSource Imprescindibles en el Testing Web. En este webinar David explica JUnit, Selenium, JMeter y Jenkins.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
In my latest article for RealPython I cover some exotic migration operations, many of the built-in migration CLI commands and demonstrate important migrations concepts such as reversible migrations, migration plans and introspection.
Accessible Animations in React
Josh Comeau's blog 05 05 2020

Diff
MonkeyUser 05 05 2020
Con las crisis llegan momentos de cambios de rumbo y nuevos horizontes. Los recientes acontecimientos han puesto al sector online en el centro de muchas acciones, encaminadas a la búsqueda de empleo o ampliar actividades relacionadas con internet. En este episodio hablamos sobre cómo afrontar la reconversión de profesionales y negocios al mundo de internet. Tanto en en el sector formativo de nuevas tecnologías como en otras actividades, es innegable que se está experimentado un renovado interés. Por tanto, uno de las grandes discusiones que realizamos en el episodio es ¿Qué le diríamos a las personas que desean ampliar su horizonte en el área digital?
Reservamos la segunda parte del episodio a aportar interesantes enlaces de recursos y herramientas orientadas al desarrollo y programación. Más abajo encontrarás todos los enlaces discutidos en el episodio.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
It can be very challenging to test a system that rely heavily on a third party service such as Twilio. In this article, I show how to organize your code in a way that would isolate your bushiness logic and make it easier for you to test it separately.
Please get your parents off Facebook
Marko Saric 30 04 2020
Incredimental Builds!
Josh Comeau's blog 29 04 2020

Estimates
MonkeyUser 28 04 2020
Dedicamos este episodio a hablar sobre los repositorios Git en la nube, espacios que nos permiten mantener una versión de nuestro código, trabajar de manera colaborativa, ejecutar tests y también realizar despliegues y otras mágicas funcionalidades. Empezamos el episodio tratando sobre en qué consiste un repositorio de código y cómo Git se ha convertido en el estándar a la hora de pensar en control de versiones. Centramos la conversación sobre los dos proveedores más importantes: GitHub y GitLab. El primero está considerado como la red social del código y tras su adquisición por parte de Microsoft está incorporando multitud de funcionalidades en su capa gratuita. Por su parte, GitLab es una soberbia plataforma de código abierto, dirigida a ser la solución integral para DevOps y una aplicación de Integración y Desarrollo Continuo para proyectos de software.
Entre las cuestiones que tratamos en el episodio, tenemos:
- Sistema de control de versiones Git y su uso local.
- Diferencias esenciales entre GitHub y GitLab.
- Clientes GUI: Github Desktop, Gitkraken, SourceTree, Git GUI, Tower, Lazygit, Sublime merge
- Integración con IDE’s: Atom, Brackets, Jetbrains (integración con GitHub, Git), VSCode,
En el episodio también comentamos las cifras de una encuesta que realizamos en el grupo de Telegram Malditos Webmasters sobre el uso de estas herramientas. Las cifras son Github 64%
Gitlab 20% y Bitbucket 13%.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Instapaper Save for macOS v1.1
Instapaper 24 04 2020
Today we updated the Instapaper Save macOS app to include more features including inline saving on Twitter, keyboard shortcut to save (Ctrl + S), and support for pasting credentials from password managers.
We also built a Share Extension for Instapaper Save, which lets you save to Instapaper from apps like Mail, News, and any other apps that support the macOS share sheet. The Share Extension also allows you to right-click links in Safari to save them.
Once you’ve downloaded the update, you can enable the system-level share by opening the share sheet from any macOS app > Going to “More…” > Selecting Instapaper in the Share Menu section of the Extensions menu. If you were doing that from Safari, it would look like this:
Lastly, we also updated our Chrome extension and Firefox add-on to fix inline saving from Twitter, and updated the Firefox shortcut to use Ctrl + S so it no longer interferes with the screenshot tool.
If you have any questions, feature requests, or issues you’d like us to sort out, please let us know at support@instapaper.com or @InstapaperHelp on Twitter.
Thanks for using Instapaper!


Una de las funcionalidades que a muchos les causa confusión es la de usar hooks en React. Los hooks son una característica que nos ayuda a seguir implementando componentes en React.js usando la misma estructura de función. Uno de los hooks más conocidos es el hook de estado
useState().En este tutorial vamos a ver dónde y cuándo debemos utilizar el hook de estado en nuestras aplicaciones con React.
1. Para qué sirve useState()
useState() es la forma de utilizar el estado en componentes basados en funciones. Si nosotros estamos desarrollando nuestros componentes con clases tenemos algo como lo siguiente:class MiComponente extends React.Component{
constructor(props){
super(props);
this.state = {nombre: ''};
}
handleChange = e =>{
this.setState({nombre: e.target.value});
}
render(){
return(
<input onChange={this.handleChange()} value={this.state.nombre} />
);
}
}
this.state y this.setState() para poder manipular los datos en nuestro componente. Si lo queremos ver así es un getter y un setter. Sin embargo, para hacer lo mismo en un componente basado en función necesitamos hacer uso de el hook de estado.2. ¿Cómo funciona el hook de estado?
El mismo ejemplo anterior hecho con clase podemos hacerlo con funciones de la siguiente forma:import {React, useState} from 'react';
function MiComponente(props){
const [nombre, setNombre] = useState('');
function handleChange(e){
setNombre(e.target.value);
}
return(
<input onChange={handleChange()} value={nombre} />
);
}
useState() lo que nos permite hacer es hacer una desestructuración de una variable y una función. en nuestro caso la variable o estado que definimos es nombre y por lo tanto el siguiente parámetro es una función setNombre() para poder cambiar el valor de nombre. De la misma forma que cuando usamos clases tenemos que usar la función setState() para poder modificar el valor de nuestro estado, cuando usamos funciones usamos la función que definimos en la desestructuración para hacer dicho cambio.3. ¿Se pueden declarar más variables usando useState()?
La respuesta es que sí. A diferencia de cuando usamosstate y setState() para almacenar todos los estados de nuestos datos, usando useState() nos permite definir variables de forma independiente, lo cual puede ocasionar una forma más ágil de manipular los estados de los datos al tener una referencia mucho más visual de qué dato estás modificando con el nombre de la función.Conclusiones
Así funciona el hook de estado. Si ven la diferencia en realidad no hay ninguna, más que el mismo hecho de tener una variable y función para sustituir elstate y setState que ocupamos cuando lo hacemos con componentes basados en clases.Bonus
También pueden ver en este video la explicación del hook de estado en React.js y aprovechar para suscribirse a mi canal si no lo han hecho 😊

Startup Struggles
MonkeyUser 21 04 2020

Return of the Weekly
Instapaper 17 04 2020
We’re excited to announce the return of the Instapaper Weekly, a Sunday morning email with the most popular Instapaper articles from the previous week. The articles are chosen based on the Instarank algorithm, which takes into account the number of saves, reads, and likes on articles from each day. The Weekly also includes the most popular highlight from the past week.
The Weekly was initially disabled in 2018 as we worked toward GDPR compliance. Around the same time, our email service changed their business model from volume-based to tier-based. The result was that it would cost more than twice as much to send the weekly email, which we could no longer afford as it would have significantly increased our operating costs.
While the Weekly has been disabled, it’s become one of the most frequently requested Instapaper features. Over the course of the past few months, we’ve done the work to migrate our email service provider from Mailgun to Amazon’s Simple Email Service (SES). SES has a volume-based pricing model, which allows us to send the Weekly in a cost-effective manner.
We wrote a more technical post about the migration from Mailgun to SES, which you can read here if you’re interested, and we open sourced some tools we made during the migration.
If you were previously receiving the Weekly, you should start seeing it in your inbox automatically. If you aren’t sure of your Weekly status or want to modify any email settings, please check your Settings page on web.
If you have any questions, feature requests, or issues you’d like us to sort out, please let us know at support@instapaper.com or @InstapaperHelp on Twitter.
Thanks for using Instapaper!
El e-learning está forzosamente de moda estos días. Aunque muchas organizaciones ya han hecho de la formación a distancia son modelo de negocio, otras han tenido que adaptarse con rapidez. El e-Learning es un concepto tan antiguo como la propia web y existen diferentes opciones para montar tus propios espacios de formación. Para este episodio hemos invitado a Javier Pérez Torres, responsable de la empresa española evolMind, especializada en soluciones de formación online en la nube, bajo un modelo SaaS. Su producto evolCampus es un desarrollo propio orientado a crear una plataforma de e-learning personalizable, integrada con multitud de servicios externos y todo bajo una sencilla interfaz.
Con Javier Pérez hablamos sobre la solución que cubre evolCampus, la situación actual del mundo e-learning y la evolución de este tipo de herramientas. Entre todas las cuestiones tratadas destacamos:
- Origen de la empresa y las tecnologías usadas en el proyecto.
- Tipo de clientes que usan evolCampus.
- Funcionalidades del servicio: SCORM, Integración con FUNDAE/SEPE, Zoom y otras plataformas de videoconferencia, Woocommerce y pagos.
- Tipos de contenidos y actividades.
- Seguimiento de actividades y alumnos.
- Modelo de precios y futuro de software e-Learning.
En definitiva una entrevista muy completa con una empresa española, que íntegramente desde Zaragoza desarrolla una completa solución de e-Learning bajo un modelo SaaS.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

Async
MonkeyUser 14 04 2020
CSS Variables for React Devs
Josh Comeau's blog 13 04 2020
La tendencia hacia servicios que nos permiten desarrollar proyectos web sin necesidad de saber código cada vez más es más fuerte. La etiqueta No Code hace referencia a unas herramientas que nos permiten diseñar y desarrollar soluciones web, sin necesidad de tener conocimientos de programación. Son servicios asequibles, con una interfaz intuitiva y en muchos casos con elevada capacidad de personalización.
En este episodio hablar de algunas de estas herramientas, las ventajas que aportan y los inconvenientes que pueden tener. Entre otras comentamos:
- Webflow, Landen, Notion, WordPress, Squarespace, WIX, Shopify.
- Airtable, integraciones Google Sheets.
- Automizaciones y flujos de trabajo: Zapier, Mautic, IFTTT o Integromat.
- Creación de Apps, Glide App / Dropsource / Adalo
- Voiceflow, crear skills Alexa o Google.
- Typeform, Substack, Pico.
Hablamos sobre las ventajas que nos ofrecen este tipo de servicios y su capacidad de ser integradas a través de sus API. Además también hablamos sobre las desventajas que tiene derivar nuestros proyectos a servicios propietarios y que exigen cierta dependencia a la hora de extender, migrar o combinar servicio. También hablamos de la importancia de conocer el funcionamiento interno de nuestras herramientas y cómo con el tiempo se tiende a tener cierto control de nuestro código.
En la última parte del episodio hablamos de recursos recomendados en diferentes materiales. Enlaces abajo.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
A Static Future
Josh Comeau's blog 08 04 2020
Custom Djula filters
Lisp journey 08 04 2020
Djula is a Common Lisp port of the Django templating language. It’s good, it’s proven (it’s one of the most downloaded Quicklisp packages), it is easy to use and it has good documentation.
It basically looks like this:
{% extends "base.html" %}
{% block title %}Memberlist{% endblock %}
{% block content %}
<ul>
{% for user in users %}
<li><a href="{{ user.url }}">{{ user.username }}</a></li>
{% endfor %}
</ul>
{% endblock %}
What was missing in the documentation was how to create custom filters. Here’s how, and it’s very simple.
def-filter
Use the def-filter macro. Its general form is:
(def-filter :myfilter-name (value arg)
(body))
It always takes the variable’s value as argument, and it can have one required or optional argument. For example, this is how those built-in filters are defined:
(def-filter :capfirst (val)
(string-capitalize (princ-to-string val)))
This is all there is to it. Once written, you can use it in your templates. You can define a filter wherever you want and there is no need to register it or to import it in your templates.
Here’s a filter with a required argument:
(def-filter :add (it n)
(+ it (parse-integer n)))
and with an optional one:
(def-filter :datetime (it &optional format)
(let ((timestamp …))))
When you need to pass a second argument, make your filter return a
lambda function and chain it with the with filter:
(def-filter :replace (it regex)
(lambda (replace)
(ppcre:regex-replace-all regex it replace)))
(def-filter :with (it replace)
(funcall it replace))
Now we can write::
{{ value | replace:foo | with:bar }}
Note: we should most probably be able to define filters with two arguments. There’s an open issue about that.
Error handling
Errors are handled by the macro, but you can handle them and return a
template-error condition:
(def-filter :handle-error-filter (it)
(handler-case
(do-something)
(condition (e)
(template-error "There was an error executing this filter: ~A" e))))
It will be rendered on the browser with a nice stacktrace.
Final words
If you don’t know what template engine to use for your web project,
start with it. My only criticism is that accessing variables is not
totally flexible. The {{ obj.val }} syntax already works to access
objects’ slots, alists, plists, hash-tables and whatnot (it uses the
excellent
Access
library), but it won’t work for some data (like structures), forcing
you to a bit of pre-processing before rendering the template. And you
can’t use much logic with template tags. However, this is by
design. Djula is a port of the Django templating engine after all.
For more flexible templates and still write html (because, you know, we can copy-paste examples easily!), see Eco. See more templates engines in the Awesome-cl list.
Last-minute addition: while I was writing this, Djula’s author released TEN, another templating engine, combining the best of Djula and Eco.
One of the biggest advantages I've found working with Clojure is its data oriented nature. Ultimately, all that code is doing is transform data. A program starts with one piece of data as the input and produces another as its output. Mainstream languages attempt to abstract over that using object oriented semantics. While practical value of such abstraction is not entirely clear, there are some tangible problems associated with this approach. Let's take a look at some drawbacks to structuring programs using OO style.
Traditionally, an object can be thought of as a type of a state machine that contains some data fields representing its internal state and provides some methods for manipulating it. An object represents the smallest compositional unit in OO, and a program is structured as a graphs of such objects that interact with one another by manipulating each others state.
The first problem we have is that each object is an ad hoc DSL. When a developer designs an object they define its API in form of methods and come up with the behaviors the object will have. This makes each object unique, and knowing how one object behaves tells you nothing regarding how the next object might behave. Rich Hickey illustrates this point in detail in his Clojure, Made Simple talk. The more objects you define the more behaviors you have to keep in your head. Thus, cognitive overhead grows proportionally with the size of the program.
Any mutable objects present in the program require the developer to know the state of the objects in order to know how the program will behave. A program that is structured as a graph of interdependent state machines quickly becomes impossible to reason about. The problem stems from objects being implicitly connected via references to each other resulting in shared mutable state. This leads to lack or referential transparency and makes it impossible to do local reasoning about the code. In order to tell what a piece of code is doing you also have to track down all the code that shares references with the code you're reading.
This is one reason why sophisticated debugging tools are needed to work with code effectively in object oriented languages. The only way to tell what's happening in a large program is to run it in a debugger, try to put it in a particular state and then inspect it. Unfortunately, this approach is just a heuristic since there may be many different paths that get you to a particular state, and it's impossible to guarantee that you've covered them all.
Another notable problem with objects is that there is no standard way for serializing them creating additional pain at program boundaries. For example, we can't just take an object graph on from a web server and send it to the client. We must write custom serializers for every object adding complexity and boilerplate to our programs. A related problem occurs when composing libraries that define their own classes leading to prevalence of wrapper and adapter patterns.
All these problems disappear in a data oriented language like Clojure. Modern FP style embraces the fact that programs can be viewed as data transformation pipelines where input data is passed through a series of pure functions to transform it into desired output. Such functions can be reasoned about in isolation without having to consider the rest of the program. Plain data doesn't have any hidden behaviors or state that you have to worry about. Immutable data is both transparent and inert while objects are opaque and stateful.
As a concrete example, Pedestal HTTP server has around 18,000 lines of code, and 96% of it is pure functions. All the IO and side effects are encapsulated in the remaining 4% of the code. This has been a common scenario for the vast majority of Clojure programs I've worked on.
Cognitive overhead associated with reasoning about code is localized as opposed to being directly influenced by the size of the application as often happens with OO. Each function can be thought of as an small individual program, and we simply pipe these programs together to solve bigger problems. Incidentally, this is the exact same approach as advocated by Ken Thompson in Unix philosophy.
Data can also be passed across program boundaries since it's directly serializable. A Clojure web server can send its output directly to the client, and client code can operate on this data without any additional ceremony. I've discussed some of the practical benefits that stem from having standard serialization semantics in this presentation.
Another advantage of separating data from logic is code reuse. A pure function that transforms one piece of data into another can be used in any context. A common set of functions from the standard library can be used to manipulate data regardless where it comes from. Once you learn a few common patterns for transforming data, you can apply these patterns everywhere.
I strongly suspect that data driven APIs are a major reason why Clojure libraries tend to be so stable. When a library is simply transforming data then it's possible to get to a state where it's truly done. Once the API consisting of all the supported transformations has been defined and tested, then the API is complete. The only times the library has to be revisited is when use cases missed by tests are discovered or new features are added. This tends to happen early on during library lifecycle, and hence mature libraries need little attention from their maintainers.
Of course, this is not to say that large software cannot be written effectively using OO languages. Clearly plenty of great software has been produced using these techniques. However, the fact that complex applications can be written in a particular fashion is hardly interesting of itself. Given enough dedication and ingenuity it's possible to write complex software in any language. It's more useful to consider how different approaches impact development style in different languages.
One of the most challenging aspects of writing good tests is maintaining test fixtures. Good test fixtures motivate developers to write better tests, and bad fixtures can cripple a system to a point where developers fear and avoid them all together. The article covers everything from setting up Pytest for a Django project, creating test fixtures and how to create dependency between fixtures.

Err
MonkeyUser 07 04 2020
How to fight back against Google AMP
Marko Saric 05 04 2020
Aprovechando la reciente repercusión del ad blocker realizado por Andros llamado Maza en Hacker News y en blogs de referencia, hablamos en el episodio sobre tecnologías de bloqueo de anuncios. La tendencia a la instalación de soluciones para bloquear anuncios por parte de los usuarios sigue en aumento, en especial en los móviles. Esto también coincide con la incorporación de navegadores con bloqueadores nativos como Brave, extensiones para navegadores, software para móviles y aplicaciones de escritorios, VPN y soluciones basadas en DNS.
Por eso en ese episodio queremos hablar sobre las diferentes alternativas que existen para bloquear anuncios, su funcionamiento y cómo todo esto está influyendo en los proveedores de contenido en internet.
Maza – Local ad blocker. Like Pi-hole but local and using your operating system. Only works on Linux and macOS.https://t.co/bnHlR8DERA
— The Best Linux Blog In the Unixverse (@nixcraft) March 29, 2020
Hablamos de soluciones de bloqueo de anuncios en el navegador con extensiones para el navegador de escritorio como uBlock Origin, navegadores nativos como Brave y otras soluciones a nivel de navegador en Firefox o en Opera. También vemos programas para bloquear los anuncios a nivel de dispositivo con programas como AdGuard o proveedores VPN como Private Internet Access. También soluciones DNS y de hardware como Pi-Hole, NextDNS, Cloudfare o la propia solución de Andros MAZA.
También hablamos de la dinámica en el ecosistema de anuncios online, como los proveedores de programática y soluciones de monetización como Relevant ads. Comentamos también la iniciativa de Firefox Better Web con Scroll, un servicio para remunerar a creadores de contenido asociados, con una membresía mensual.
Por último en la sección de Radar ofrecemos una colección de recursos interesantes para el desarrollo web y profesional.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
As a software developer you probably have to perform actions like copying different pieces of your code from multiple files into different locations of your current Vim session. Using only system clipboard, this can be a cumbersome and time consuming task. Once you master Vim registers, your text editing efficiency will greatly improve. A register... Continue reading
The post Calculator in Vim – The Expression register appeared first on Jovica Ilic.
Using Markdown in Django
Haki Benita 29 03 2020
How we developed a Markdown extension to manage content in Django sites.
In this post, I’ll share with you one of my favorite learning tip. This tip will help you greatly improve your learning skills. It can be also useful for giving more powerful presentations. It comes from the bonus ebook Learning to Learn Effectively from my Premium package of Mastering Vim Quickly. … If you knew you had a... Continue reading
The post Learning to Learn Effectively – Tip #1 appeared first on Jovica Ilic.
Estamos de vuelta con el estudio de David Vaquero sobre el uso de tecnologías web y esta vez tratamos las bases de datos. En su propio estudio David analiza el uso de tecnologías de bases de datos sobre el millón de sitios web proporcionado por Alexa, tomando además dominios españoles. Este trabajo nos sirve para comentar los resultados y explicar las diferencias entre las bases de datos relacionales como MySQL, Percona, MariaDB o PostgreSQL y las basadas en las llamadas noSQL, con MongoDB como principal protagonista y claramente orientadas a soluciones distribuidas y escalables.
En el episodio David explica con detalle las diferencias conceptuales de este tipo de base de datos y los usos a los que va dirigidos. Es una explicación muy útil para tener una idea global sobre estas tecnologías y lo crítico que puede resultar para el rendimiento y la escalabilidad de nuestros proyectos.
Tradicionalmente las bases de datos se han visto como una caja negra, con una abstracción muy elevada para evitar preocuparse en los detalles de acceso y manipulación de los datos. Esta abstracción libera a los profesionales de las complejidades del software, aunque la exigencia y naturaleza de ciertas aplicaciones requieren tener un control más exhaustivo de cómo funcionan, destacando la importancia de contar con profesionales que optimicen los sistemas.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Nuklear is a small immediate-mode GUI toolkit:
Nuklear is a minimal-state, immediate-mode graphical user interface toolkit written in ANSI C and licensed under public domain. It was designed as a simple embeddable user interface for application and does not have any dependencies, a default render backend or OS window/input handling but instead provides a highly modular, library-based approach, with simple input state for input and draw commands describing primitive shapes as output. So instead of providing a layered library that tries to abstract over a number of platform and render backends, it focuses only on the actual UI.
its Lisp binding is Bodge-Nuklear, and its higher level companions bodge-ui and bodge-ui-window.
Unlike traditional UI frameworks, Nuklear allows the developer to take over the rendering loop or the input management. This might require more setup, but it makes Nuklear particularly well suited for games, or for applications where you want to create new controls.
Previous posts of the serie:
This blog post series was initially written for the Common Lisp Cookbook, you can (and should) read it there:
https://lispcookbook.github.io/cl-cookbook/gui.html
- Framework written in: ANSI C, single-header library.
Portability: where C runs. Nuklear doesn’t contain platform-specific code. No direct OS or window handling is done in Nuklear. Instead all input state has to be provided by platform specific code.
Widgets choice: small.
Graphical builder: no.
Other features: fully skinnable and customisable.
Bindings stability: stable
Bindings activity: active
Licence: MIT or Public Domain (unlicence).
Example applications:
- Trivial-gamekit
- Obvius - a resurrected image processing library.
- Notalone - an autumn 2017 Lisp Game Jam entry.
List of widgets
Non-exhaustive list:
buttons, progressbar, image selector, (collapsable) tree, list, grid, range, slider, color picker,
date-picker
Getting started
Disclaimer: as per the author’s words at the time of writing, bodge-ui is in early stages of development and not ready for general use yet. There are some quirks that need to be fixed, which might require some changes in the API.
bodge-ui is not in Quicklisp but in its own Quicklisp distribution. Let’s install it:
(ql-dist:install-dist "http://bodge.borodust.org/dist/org.borodust.bodge.txt" :replace t :prompt nil)
Uncomment and evaluate this line only if you want to enable the OpenGL 2 renderer:
;; (cl:pushnew :bodge-gl2 cl:*features*)
Quickload bodge-ui-window:
(ql:quickload :bodge-ui-window)
We can run the built-in example:
(ql:quickload :bodge-ui-window/examples)
(bodge-ui-window.example.basic:run)
Now let’s define a package to write a simple application.
(cl:defpackage :bodge-ui-window-test
(:use :cl :bodge-ui :bodge-host))
(in-package :bodge-ui-window-test)
(defpanel (main-panel
(:title "Hello Bodge UI")
(:origin 200 50)
(:width 400) (:height 400)
(:options :movable :resizable
:minimizable :scrollable
:closable))
(label :text "Nested widgets:")
(horizontal-layout
(radio-group
(radio :label "Option 1")
(radio :label "Option 2" :activated t))
(vertical-layout
(check-box :label "Check 1" :width 100)
(check-box :label "Check 2"))
(vertical-layout
(label :text "Awesomely" :align :left)
(label :text "Stacked" :align :centered)
(label :text "Labels" :align :right)))
(label :text "Expand by width:")
(horizontal-layout
(button :label "Dynamic")
(button :label "Min-Width" :width 80)
(button :label "Fixed-Width" :expandable nil :width 100))
)
(defun run ()
(bodge-host:open-window (make-instance 'main-window)))
and run it:
(run)
To react to events, use the following signals:
:on-click
:on-hover
:on-leave
:on-change
:on-mouse-press
:on-mouse-release
They take as argument a function with one argument, the panel. But beware: they will be called on each rendering cycle when the widget is on the given state, so potentially a lot of times.
Interactive development
If you ran the example in the REPL, you couldn’t see what’s cool. Put the code in a lisp file and run it, so than you get the window. Now you can change the panel widgets and the layout, and your changes will be immediately applied while the application is running!
Conclusion
Have fun, don’t hesitate to share your experience and your apps… and contribute to the Cookbook!
IUP is a cross-platform GUI toolkit actively developed at the PUC university of Rio de Janeiro, Brazil. It uses native controls: the Windows API for Windows, Gtk3 for GNU/Linux. At the time of writing, it has a Cocoa port in the works (as well as iOS, Android and WASM ones). A particularity of IUP is its small API.
The Lisp bindings are lispnik/iup. They are nicely done in that they are automatically generated from the C sources. They can follow new IUP versions with a minimal work and the required steps are documented. All this gives us good guarantee over the bus factor.
IUP stands as a great solution in between Tk and Gtk or Qt.
Previous posts of the serie:
This blog post series was initially written for the Common Lisp Cookbook, you can (and should) read it there:
https://lispcookbook.github.io/cl-cookbook/gui.html
- Framework written in: C (official API also in Lua and LED)
Portability: Windows and Linux, work started for Cocoa, iOS, Android, WASM.
Widgets choice: medium.
Graphical builder: yes: IupVisualLED
Other features: OpenGL, Web browser (WebKitGTK on GNU/Linux), plotting, Scintilla text editor
Bindings documentation: good examples and good readme, otherwise low.
Bindings stability: alpha (but fully generated and working nicely)
Bindings activity: low
Licence: IUP and the bindings are MIT licenced.
List of widgets
Radio, Tabs, FlatTabs, ScrollBox, DetachBox,
Button, FlatButton, DropButton, Calendar, Canvas, Colorbar, ColorBrowser, DatePick, Dial, Gauge, Label, FlatLabel,
FlatSeparator, Link, List, FlatList, ProgressBar, Spin, Text, Toggle, Tree, Val,
listDialog, Alarm, Color, Message, Font, Scintilla, file-dialog…
Cells, Matrix, MatrixEx, MatrixList,
GLCanvas, Plot, MglPlot, OleControl, WebBrowser (WebKit/Gtk+)…
drag-and-drop
Getting started
Please check the installation instructions upstream. You may need one system dependency on GNU/Linux, and to modify an environment variable on Windows.
Finally, do:
(ql:quickload :iup)
We are not going to :use IUP (it is a bad practice generally after all).
(defpackage :test-iup
(:use :cl))
(in-package :test-iup)
The following snippet creates a dialog frame to display a text label.
(defun hello ()
(iup:with-iup ()
(let* ((label (iup:label :title (format nil "Hello, World!~%IUP ~A~%~A ~A"
(iup:version)
(lisp-implementation-type)
(lisp-implementation-version))))
(dialog (iup:dialog label :title "Hello, World!")))
(iup:show dialog)
(iup:main-loop))))
(hello)
Important note for SBCL: we currently must trap division-by-zero errors (see advancement on this issue). So, run snippets like so:
(defun run-gui-function ()
#-sbcl (gui-function)
#+sbcl
(sb-int:with-float-traps-masked
(:divide-by-zero :invalid)
(gui-function)))
How to run the main loop
As with all the bindings seen so far, widgets are shown inside a
with-iup macro, and with a call to iup:main-loop.
How to create widgets
The constructor function is the name of the widget: iup:label,
iup:dialog.
How to display a widget
Be sure to “show” it: (iup:show dialog).
You can group widgets on frames, and stack them vertically or
horizontally (with vbox or hbox, see the example below).
To allow a widget to be expanded on window resize, use :expand
:yes (or :horizontal and :vertical).
Use also the :alignement properties.
How to get and set a widget’s attributes
Use (iup:attribute widget attribute) to get the attribute’s value,
and use setf on it to set it.
Reacting to events
Most widgets take an :action parameter that takes a lambda function
with one parameter (the handle).
(iup:button :title "Test &1"
:expand :yes
:tip "Callback inline at control creation"
:action (lambda (handle)
(iup:message "title" "button1's action callback")
iup:+default+))
Below we create a label and put a button below it. We display a message dialog when we click on the button.
(defun click-button ()
(iup:with-iup ()
(let* ((label (iup:label :title (format nil "Hello, World!~%IUP ~A~%~A ~A"
(iup:version)
(lisp-implementation-type)
(lisp-implementation-version))))
(button (iup:button :title "Click me"
:expand :yes
:tip "yes, click me"
:action (lambda (handle)
(declare (ignorable handle))
(iup:message "title" "button clicked")
iup:+default+)))
(vbox
(iup:vbox (list label button)
:gap "10"
:margin "10x10"
:alignment :acenter))
(dialog (iup:dialog vbox :title "Hello, World!")))
(iup:show dialog)
(iup:main-loop))))
#+sbcl
(sb-int:with-float-traps-masked
(:divide-by-zero :invalid)
(click-button))
Here’s a similar example to make a counter of clicks. We use a label and its title to hold the count. The title is an integer.
(defun counter ()
(iup:with-iup ()
(let* ((counter (iup:label :title 0))
(label (iup:label :title (format nil "The button was clicked ~a time(s)."
(iup:attribute counter :title))))
(button (iup:button :title "Click me"
:expand :yes
:tip "yes, click me"
:action (lambda (handle)
(declare (ignorable handle))
(setf (iup:attribute counter :title)
(1+ (iup:attribute counter :title 'number)))
(setf (iup:attribute label :title)
(format nil "The button was clicked ~a times."
(iup:attribute counter :title)))
iup:+default+)))
(vbox
(iup:vbox (list label button)
:gap "10"
:margin "10x10"
:alignment :acenter))
(dialog (iup:dialog vbox :title "Counter")))
(iup:show dialog)
(iup:main-loop))))
(defun run-counter ()
#-sbcl
(counter)
#+sbcl
(sb-int:with-float-traps-masked
(:divide-by-zero :invalid)
(counter)))
List widget example
Below we create three list widgets with simple and multiple selection, we set their default value (the pre-selected row) and we place them horizontally side by side.
(defun list-test ()
(iup:with-iup ()
(let* ((list-1 (iup:list :tip "List 1" ;; tooltip
;; multiple selection
:multiple :yes
:expand :yes))
(list-2 (iup:list :value 2 ;; default index of the selected row
:tip "List 2" :expand :yes))
(list-3 (iup:list :value 9 :tip "List 3" :expand :yes))
(frame (iup:frame
(iup:hbox
(progn
;; populate the lists: display integers.
(loop for i from 1 upto 10
do (setf (iup:attribute list-1 i)
(format nil "~A" i))
do (setf (iup:attribute list-2 i)
(format nil "~A" (+ i 10)))
do (setf (iup:attribute list-3 i)
(format nil "~A" (+ i 50))))
;; hbox wants a list of widgets.
(list list-1 list-2 list-3)))
:title "IUP List"))
(dialog (iup:dialog frame :menu "menu" :title "List example")))
(iup:map dialog)
(iup:show dialog)
(iup:main-loop))))
(defun run-list-test ()
#-sbcl (hello)
#+sbcl
(sb-int:with-float-traps-masked
(:divide-by-zero :invalid)
(list-test)))
Next is a different toolkit very well suited for games and that enables fully interactive development: Nuklear.
We continue our tour of GUI toolkits for CL with Gtk+3 and cl-cffi-gtk.
The previosu posts are:
This blog post series was initially written for the Common Lisp Cookbook, you can (and should) read it there:
https://lispcookbook.github.io/cl-cookbook/gui.html
Gtk+3 (cl-cffi-gtk)
Gtk+3 is the primary library used to build GNOME applications. Its (currently most advanced) lisp bindings is cl-cffi-gtk. While primarily created for GNU/Linux, Gtk works fine under macOS and can now also be used on Windows.
- Framework written in: C
Portability: GNU/Linux and macOS, also Windows.
Widgets choice: large.
Graphical builder: yes: Glade.
Other features: web browser (WebKitGTK)
Bindings documentation: very good: http://www.crategus.com/books/cl-gtk/gtk-tutorial.html
Bindings stability: stable
Bindings activity: low activity, active development.
Licence: LGPL
Example applications:
- an Atmosphere Calculator, built with Glade.
Getting started
The documentation is exceptionally good, including for beginners.
The library to quickload is cl-cffi-gtk. It is made of numerous
ones, that we have to :use for our package.
(ql:quickload :cl-cffi-gtk)
(defpackage :gtk-tutorial
(:use :gtk :gdk :gdk-pixbuf :gobject
:glib :gio :pango :cairo :common-lisp))
(in-package :gtk-tutorial)
How to run the main loop
As with the other libraries, everything happens inside the main loop
wrapper, here with-main-loop.
How to create a window
(make-instance 'gtk-window :type :toplevel :title "hello" ...).
How to create a widget
All widgets have a corresponding class. We can create them with
make-instance 'widget-class, but we preferably use the constructors.
The constructors end with (or contain) “new”:
(gtk-label-new)
(gtk-button-new-with-label "Label")
How to create a layout
(let ((box (make-instance 'gtk-box :orientation :horizontal :spacing 6))) ...)
then pack a widget onto the box:
(gtk-box-pack-start box mybutton-1)
and add the box to the window:
(gtk-container-add window box)
and display them all:
(gtk-widget-show-all window)
Reacting to events
Use g-signal-connect + the concerned widget + the event name (as a
string) + a lambda, that takes the widget as argument:
(g-signal-connect window "destroy"
(lambda (widget)
(declare (ignore widget))
(leave-gtk-main)))
Or again:
(g-signal-connect button "clicked"
(lambda (widget)
(declare (ignore widget))
(format t "Button was pressed.~%")))
Full example
(defun hello-world ()
;; in the docs, this is example-upgraded-hello-world-2.
(within-main-loop
(let ((window (make-instance 'gtk-window
:type :toplevel
:title "Hello Buttons"
:default-width 250
:default-height 75
:border-width 12))
(box (make-instance 'gtk-box
:orientation :horizontal
:spacing 6)))
(g-signal-connect window "destroy"
(lambda (widget)
(declare (ignore widget))
(leave-gtk-main)))
(let ((button (gtk-button-new-with-label "Button 1")))
(g-signal-connect button "clicked"
(lambda (widget)
(declare (ignore widget))
(format t "Button 1 was pressed.~%")))
(gtk-box-pack-start box button))
(let ((button (gtk-button-new-with-label "Button 2")))
(g-signal-connect button "clicked"
(lambda (widget)
(declare (ignore widget))
(format t "Button 2 was pressed.~%")))
(gtk-box-pack-start box button))
(gtk-container-add window box)
(gtk-widget-show-all window))))
Next is IUP, a not very famous but really great toolkit!
Here’s the second part of our exploration of GUI toolkits for Common Lisp.
The first part and introduction is accessible here:
This blog post series was initially written for the Common Lisp Cookbook, you can (and should) read it there:
https://lispcookbook.github.io/cl-cookbook/gui.html
Qt4 (Qtools)
Do we need to present Qt and Qt4? Qt is huge and contains everything and the kitchen sink. Qt not only provides UI widgets, but numerous other layers (networking, D-BUS…).
Qt is free for open-source software, however you’ll want to check the conditions to ship proprietary ones.
The Qtools bindings target Qt4. The Qt5 Lisp bindings are yet to be created.
- Framework written in: C++
- Framework Portability: multi-platform, Android, embedded systems, WASM.
Bindings Portability: Qtools runs on x86 desktop platforms on Windows, macOS and GNU/Linux.
Widgets choice: large.
Graphical builder: yes.
Other features: Web browser, a lot more.
Bindings documentation: lengthy explanations, a few examples. Prior Qt knowledge is required.
Bindings stability: stable
Bindings activity: active
Qt Licence: both commercial and open source licences.
Example applications:
Getting started
(ql:quickload '(:qtools :qtcore :qtgui))
(defpackage #:qtools-test
(:use #:cl+qt)
(:export #:main))
(in-package :qtools-test)
(in-readtable :qtools)
We create our main widget that will contain the rest:
(define-widget main-window (QWidget)
())
We create an input field and a button inside this main widget:
(define-subwidget (main-window name) (q+:make-qlineedit main-window)
(setf (q+:placeholder-text name) "Your name please."))
(define-subwidget (main-window go-button) (q+:make-qpushbutton "Go!" main-window))
We stack them horizontally:
(define-subwidget (main-window layout) (q+:make-qhboxlayout main-window)
(q+:add-widget layout name)
(q+:add-widget layout go-button))
and we show them:
(with-main-window
(window 'main-window))
That’s cool, but we don’t react to the click event yet.
Reacting to events
Reacting to events in Qt happens through signals and slots. Slots are functions that receive or “connect to” signals, and signals are event carriers.
Widgets already send their own signals: for example, a button sends a “pressed” event. So, most of the time, we only need to connect to them.
However, had we extra needs, we can create our own set of signals.
Built-in events
We want to connect our go-button to the pressed and
return-pressed events and display a message box.
- we need to do this inside a
define-slotfunction, - where we establish the connection to those events,
- and where we create the message box. We grab the text of the
nameinput field with(q+:text name).
(define-slot (main-window go-button) ()
(declare (connected go-button (pressed)))
(declare (connected name (return-pressed)))
(q+:qmessagebox-information main-window
"Greetings" ;; title
(format NIL "Good day to you, ~a!" (q+:text name))))
And voilà. Run it with
(with-main-window (window 'main-window))
Custom events
We’ll implement the same functionality as above, but for demonstration
purposes we’ll create our own signal named name-set to throw when
the button is clicked.
We start by defining the signal, which happens inside the
main-window, and which is of type string:
(define-signal (main-window name-set) (string))
We create a first slot to make our button react to the pressed
and return-pressed events. But instead of creating the message box
here, as above, we send the name-set signal, with the value of our
input field..
(define-slot (main-window go-button) ()
(declare (connected go-button (pressed)))
(declare (connected name (return-pressed)))
(signal! main-window (name-set string) (q+:text name)))
So far, nobody reacts to name-set. We create a second slot that
connects to it, and displays our message. Here again, we precise the
parameter type.
(define-slot (main-window name-set) ((new-name string))
(declare (connected main-window (name-set string)))
(q+:qmessagebox-information main-window "Greetings" (format NIL "Good day to you, ~a!" new-name)))
and run it:
(with-main-window (window 'main-window))
Building and deployment
It is possible to build a binary and bundle it together with all the necessary shared libraries.
Please read https://github.com/Shinmera/qtools#deployment.
You might also like this Travis CI script to build a self-contained binary for the three OSes.
Next, we’ll have a look at Gtk+3.
Lisp has a long and rich history and so does the development of Graphical User Interfaces in Lisp. In fact, the first GUI builder was written in Lisp (and sold to Apple. It is now Interface Builder).
Lisp is also famous and unrivaled for its interactive development capabilities, a feature even more worth having to develop GUI applications. Can you imagine compiling one function and seeing your GUI update instantly? We can do this with many GUI frameworks today, even though the details differ from one to another.
Finally, a key part in building software is how to build it and ship it to users. Here also, we can build self-contained binaries, for the three main operating systems, that users can run with a double click.
We aim here to give you the relevant information to help you choose the right GUI framework and to put you on tracks. Don’t hesitate to contribute, to send more examples and to furnish the upstream documentations.
This blog post series was initially written for the Common Lisp Cookbook, you can (and should) read it there:
https://lispcookbook.github.io/cl-cookbook/gui.html
Introduction
In this article series, we’ll present the following GUI toolkits:
- Tk with Ltk
- Qt4 with Qtools
- IUP with lispnik/iup
- Gtk3 with cl-cffi-gtk
- Nuklear with Bodge-Nuklear
In addition, you might want to have a look to:
- the CAPI toolkit (Common Application Programming Interface), which is proprietary and made by LispWorks. It is a complete and cross-platform toolkit (Windows, Gtk+, Cocoa), very praised by its users. LispWorks also has iOS and Android runtimes. Example software built with CAPI include Opusmodus or again ScoreCloud. It is possible to try it with the LispWorks free demo.
- CocoaInterface, a Cocoa interface for Clozure Common Lisp. Build Cocoa user interface windows dynamically using Lisp code and bypass the typical Xcode processes.
- McCLIM, a toolkit in 100% Common Lisp.
- Alloy, another very new toolkit in 100% Common Lisp, used for example in the Kandria game.
- nodgui, a fork of Ltk, with syntax sugar and additional widgets.
- eql, eql5, eql5-android, embedded Qt4 and Qt5 Lisp, embedded in ECL, embeddable in Qt. Port of EQL5 to the Android platform.
- this demo using Java Swing from ABCL
- and, last but not least, Ceramic, to ship a cross-platform web app with Electron.
as well as the other ones listed on awesome-cl#gui and Cliki.
Tk (Ltk)
Tk (or Tcl/Tk, where Tcl is the programming language) has the infamous reputation of having an outdated look. This is not (so) true anymore since its version 8 of 1997 (!). It is probably better than you think:
Tk doesn’t have a great choice of widgets, but it has a useful canvas, and it has a couple of unique features: we can develop a graphical interface fully interactively and we can run the GUI remotely from the core app.
So, Tk isn’t fancy, but it is an used and proven GUI toolkit (and programming language) still used in the industry. It can be a great choice to quickly create simple GUIs, to leverage its ease of deployment, or when stability is required.
The Lisp binding is Ltk.
- Written in: Tcl
Portability: cross-platform (Windows, macOS, Linux).
Widgets: this is not the fort of Tk. It has a small set of default widgets, and misses important ones, for example a calendar. We can find some in extensions (such as in Nodgui), but they don’t feel native, at all.
Interactive development: very much.
Graphical builder: no
Other features:
- remote execution: the connection between Lisp and Tcl/Tk is done via a stream. It is thus possible to run the Lisp program on one computer, and to display the GUI on another one. The only thing required on the client computer is tcl/tk installed and the remote.tcl script. See Ltk-remote.
Bindings documentation: short but complete. Nodgui too.
Bindings stability: very stable
Bindings activity: low to non-existent.
Licence: Tcl/Tk is BSD-style, Ltk is LGPL.
Example applications:
- Fulci - a program to organize your movie collections.
- Ltk small games - snake and tic-tac-toe.
- cl-torrents - searching torrents on popular trackers. CLI, readline and a simple Tk GUI.
List of widgets
(please don’t suppose the list exhaustive)
Button Canvas Check-button Entry Frame Label Labelframe Listbox
Menu Menubutton Message
Paned-window
Radio-button Scale
Scrollbar Spinbox Text
Toplevel Widget Canvas
Ltk-megawidgets:
progress
history-entry
menu-entry
Nodgui adds:
treelist tooltip searchable-listbox date-picker calendar autocomplete-listbox
password-entry progress-bar-star notify-window
dot-plot bar-chart equalizer-bar
swap-list
Getting started
Ltk is quick and easy to grasp.
(ql:quickload :ltk)
(in-package :ltk-user)
How to create widgets
All widgets are created with a regular make-instance and the widget name:
(make-instance 'button)
(make-instance 'treeview)
This makes Ltk explorable with the default symbol completion.
How to start the main loop
As with most bindings, the GUI-related code must be started inside a macro that
handles the main loop, here with-ltk:
(with-ltk ()
(let ((frame (make-instance 'frame)))
…))
How to display widgets
After we created some widgets, we must place them on the layout. There
are a few Tk systems for that, but the most recent one and the one we
should start with is the grid. grid is a function that takes as
arguments the widget, its column, its row, and a few optional
parameters.
As with any Lisp code in a regular environment, the functions’ signatures are indicated by the editor. It makes Ltk explorable.
Here’s how to display a button:
(with-ltk ()
(let ((button (make-instance 'button :text "hello")))
(grid button 0 0)))
That’s all there is to it.
Reacting to events
Many widgets have a :command argument that accept a lambda which is
executed when the widget’s event is started. In the case of a button,
that will be on a click:
(make-instance 'button
:text "Hello"
:command (lambda ()
(format t "clicked")))
Interactive development
When we start the Tk process in the background with (start-wish), we
can create widgets and place them on the grid interactively.
See the documentation.
Once we’re done, we can (exit-wish).
Nodgui
To try the Nodgui demo, do:
(ql:quickload :nodgui)
(nodgui.demo:demo)
Next, we’ll have a look at a very different beast, Qt4, with Qtools.

Acquisition
MonkeyUser 24 03 2020
Erudite is a Common Lisp library to write literate programs. The latest release (march, 2020) brings cool new features, amongst which the ability to capture and print code output.
This page was created with Erudite. You can follow along with its source here. Blogging about a programming language in the language itself is pretty awesome and convenient (no more copy-pasting of code snippets and manual adjustements of the indentation, yay!). It brings us closer to an interactive notebook, even if it isn’t the first goal.
Basic usage
You write a lisp program, as usual. There is no extra step to produce the program sources, since we are inside the sources. This is different than the Org-mode approach for example.
The comments will be the documentation. Comments inside a function are also extracted and cut the function in two.
Erudite can export to Latex, RestructuredText, Markdown, HTML… and actually to and from any format by using a “pass-through” directive.
Top level comments are shown like this. Here’s code:
(defun fibonacci (n &aux (f0 0) (f1 1))
"docstring"
(case n
(0 f0)
(1 f1)
this is an inline comment (there might be settings to control how it is rendered)
(t (loop for n from 2 to n
for a = f0 then b and b = f1 then result
for result = (+ a b)
finally (return result)))))
Erudite defines directives to play with the output, such as ignore and eval. Note that directives start with a @ sign, which I cannot use here.
With ignore, we can write lisp code but hide it from the output. And with eval, Erudite connects to a Swank server, captures and prints the output.
There’s also the handy code, to write a snippet inside comments (so it is not part of
the Lisp source) and make it appear in the generated document.
For the text markup, we can use Erudite’s syntax (“link”, “section”, “subsection”, “emph”…), or the markup of the output file format.
Evaluating code
With the latest Erudite, we can evaluate code. Note that it’s a work in progress.
The code snippet must be inside the comments too.
Here I call Fibonacci defined above: Fibonacci of 10 is…
55
You might need to create a Swank server first with
(swank:create-server :dont-close t)
and tell Erudite its port if it isn’t 4005.
(setf erudite::*swank-port* 4005)
Rendering the document
Call Erudite like so:
(erudite:erudite #p"literal.md" "literal-erudite.lisp" :output-type :markdown)
We can also use a binary from the shell.
Live rendering
I don’t want to re-run this command everytime I want to see the generated document. I use this snippet to automatically export my document when I save the Lisp source:
(ql:quickload :cl-inotify)
(bt:make-thread
(lambda ()
(cl-inotify:with-inotify (inotify t ("literal-erudite.lisp" :close-write))
(cl-inotify:do-events (event inotify :blocking-p t)
(format t "~a~&" event)
(erudite:erudite #p"literal.md" "literal-erudite.lisp" :output-type :markdown))))
:name "inotify-erudite")
And then I make the markdown file to be live-rendered in the browser.
I used impatient-mode for Emacs (see Wikemacs) with the help of M-x auto-revert-mode.
Kuddos to Mariano Montone!
Queremos dedicar este episodio a todas las personas que están enfrentándose a esta emergencia en primera línea. Son tiempos complicados que exigen unión y sólo nuestra determinación por hacer las cosas juntos nos hará superar esta situación. Mucho ánimo para todos.
En este episodio hablamos sobre cómo internet está ayudando a sobrellevar esta crisis global y también la forma en la que el acceso a la red supone un alivio en la parte personal y profesional. El avance espectacular del virus ha obligado a aplicar restricciones sin precedentes y en este escenario de aislamiento social, internet está jugando un papel fundamental. Aspectos tan cotidianos como trabajar, estudiar o dedicar tiempo al ocio están siendo posibles gracias a nuestras conexiones a la red.
Entre las cuestiones que discutimos en el episodio:
- Cómo estamos llevando estos días en la parte profesional.
- Servicios que estamos usando más en la parte de trabajo en remoto.
- Lo que nos sugiere que en muchos guiones apocalípticos se apuntaba a un fallo de la tecnología o de internet, como el fin de una era.¿No debería ser un derecho el acceso?.
- Gestos de solidaridad por parte de muchas empresas que ponen a su disposición sus productos digitales.
- ¿Supone esta crisis un cambio cultural definitivo con respecto al trabajo en remoto?.
- Cómo pensamos que esta crisis va a afectar a nuestro trabajo.
¿Algún caso que os gustaría reseñar?
Por últimos dos grandes oyentes del podcast Cristóbal y Carlos nos han mandado su opinión acerca de las cuestiones hemos tratado en el episodio. Como siempre encantados de contar con vuestras aportaciones al podcast.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

Levels Of Satisfaction
MonkeyUser 17 03 2020
Tras varias entrevistas y episodios temáticos aprovechamos este episodio del podcast para hacer un radar extendido con recursos y herramientas de interés para el desarrollo web. Recopilamos algunos de los recursos que teníamos apuntados para aportar entre los tres, una lista extendida de nuestra frecuente sección Radar. Cada uno de nosotros se ha preparado unos cuantos enlaces para discutir en este episodio.
Es inevitable que en este episodio hagamos mención de la crisis del Coronavirus, y hablamos sobre como estamos afrontando los próximos días tanto a nivel personal como profesional. Esta crisis está poniendo a prueba gran parte de los aspectos más esenciales de nuestra vida y casi nadie se escapará de sus efectos en el ámbito profesional.
Recursos web discutidos en el episodio
Alpine.js: A Tiny JavaScript Framework (Caleb Porzio)
Diminuta librería para generar interacciones de usuario listas para usar, sin necesidad de otras opciones más completas. Artículo de Alpine.js en Smashing Magazine.
TailwindUI: Completa colección de snippets de HTML listos para integrar en tu proyecto hecho con TailwindCSS.
Libro Comerciantes de Atención por Tim Wu, publicado en español por Capitán Swing, un ensayo fundamental para comprender como las empresas de comunicación y publicidad comercian con nuestra atención. Tim Wu es profesor de la Universidad de Columbia y columnista habitual del New York Times.
Podcast Tribucasters de Pol Rodríguez y José Carlos Cortizo, un podcast para podcasters con un enfoque especial en todo lo relacionado con producir y captar audiencia en el mundo del podcast.
Place Image, una aplicación de Andros para facilitar una colección de imágenes aleatorias y en diferentes tamaños, destinado a facilitar el trabajo del desarrollo y diseño web.
LocalWP por Flywheel, ofrece un entorno de trabajo local con soporte SSL, dominios locales, Mailhog, instalación en un clic, refresco automático, wp cli, acceso SSH, últimas versiones de MySQL y PHP, configurar entorno de desarrollo o producción, extensiones….
Retool, una aplicación que promete recortar el tiempo que lleva construir herramientas internas.
Libro Algoritmos, Guía ilustrada para programadores y curiosos por Aditya Y. Bhargava. Una guía muy bien ilustrada que enseña cómo aplicar algoritmos comunes a problemas prácticos que enfrentan a diario los programadores.
Podcast de formación por David Vaquero y José Jiménez, Formadores en tiempos revueltos iVoox, Anchor.fm.
anchor.fm https://anchor.fm/s/13cc5df4/podcast/rss
Gadgets para freelance itinerantes o nómadas digitales
Artículo de David Vaquero sobre Angular 9 nueva release
Artículo de David Vaquero sobre Ionic 5 nueva release
Muchísimas gracias a nuestra querida Sonia Sánchez por hacernos la presentación de este episodio.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Para este episodio especial compartimos micrófono con nuestro colega podcaster Daniel Primo de Web Reactiva. Aunque alguno ya hemos compartido con Daniel micrófono tanto en su podcast, como en el nuestro, es la primera vez que podemos hablar los cuatro juntos en un episodio. Con Dani aprovechamos para compartir nuestras experiencias profesionales, hablando de cuestiones aprendidas con los años, alguno de nuestros logros recientes y la percepción que tenemos de nuestra profesión.
Se trata de un episodio que publicará Dani en su programa Web Reactiva y que nosotros hemos decidido publicar como bonus en nuestro feed oficial. En este episodio también hay espacio para hablar sobre proyectos de futuro y lo que tenemos cada uno entre manos. Un episodio en modo tertulia entre amigos y colegas, y que pensamos puede resultar de interés a nuestros respectivos oyentes.
Entre las cuestiones que tratamos en el episodio se encuentran:
- ¿Qué es lo mejor que habéis hecho a nivel profesional los últimos 2 ó 3 años?
- ¿De qué tecnología, hábito o disciplina profesional estás más orgulloso?
- ¿De qué forma ha cambiado vuestra percepción de la profesión con los años?
- Un buen consejo que os hayan dado a nivel profesional y que se haya demostrado efectivo.
- Objetivos y proyectos de futuro.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

Early Contributor
MonkeyUser 10 03 2020
Para este episodio David Vaquero habla con Iván Expósito de Dinahosting, uno de los proveedores de infraestructura de alojamiento, dominios y servicios web más importantes de España. David aprovecha que es cliente de larga trayectoria de Dinahosting para conversar sobre los servicios que ofrecen, sus puntos de diferenciales y los nuevos proyectos que tienen para el futuro.
Dinahosting ofrece desde el año 2001 un catálogo amplísimo de servicios que van desde el registro de dominios, el hosting web y servidores VPS / dedicados. Con sedes en Santiago de Compostela y Madrid (datacenter), Dinahosting ofrece todo lo necesario para lanzar proyectos web y garantizar su crecimiento, desde alojamientos compartidos y soluciones más avanzadas. Con Iván Expósito hablamos de la personalidad de Dinahosting y su cultura de atención al cliente.
También hay espacio para hablar de proyectos paralelos dentro de la empresa, migraciones a VPS, código abierto, cloud privadas y requerimientos para lanzar proyectos y soporte personalizado a clientes. Dinahosting es una solución perfecta para poder crecer proyectos web con todo lo necesario para garantizar el acceso a nuestros servicios, sin contar con un personal técnico en las empresas.
Por último también hablamos de DinaIP, una solución desarrollada por Dinahosting para configurar direcciones dinámicas.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Some time during 2016 I got my hands on the book Writing an interpreter in Go by Thorsten Ball. I skimmed through the first few chapters, liked what I read and then… life happened and I never actually got around to building an interpreter. :(
Until last month, that is. I cleared out my schedule and finally started going through the book.
For double the fun, I picked C as my programming language of choice instead of Go. This turned out to be a great decision as it really forced me to understand what was going on, instead of always having the easy option of just copying the author’s code.
I codenamed my implementation Monkey-C Monkey-Do.
The book takes you through all the stages to get an interpreter for the Monkey programming language up and running:
- Tokenize the input
- Parse the tokens into an Abstract Syntax Tree (AST)
- Evaluate the tree
This tree-walking evaluator needs about 6 seconds to calculate the 35th fibonacci number using a very sub-optimal algorithm with lots of recursion. That is certainly not bad, but it’s also not great compared to any of today’s production-grade interpreted languages.
For comparison, on the same machine Python 3.7 needs 2.3 seconds for that exact same algorithm and Node 15 only needs a whopping 200 miliseconds (due to its JIT compilation).
Can we do better, without talking to the hardware directly?
Writing a bytecode compiler and virtual machine
Luckily, the author of the book didn’t stop there. In his second book (Writing a compiler in Go) the author walks you through the steps of building a bytecode interpreter.
Reusing the AST from the first book, it shows you how to build a compiler outputting bytecode. Simultaneously, you start building a virtual machine capable of executing that bytecode.
After getting the virtual machine up and running, calculating the 35th fibonacci number now only takes 0.82 seconds. That’s much closer or even faster than some other interpreted languages already.
I wholeheartedly recommend the two books. Not only is it a lot of fun to write your own interpreter, it also cleared up a lot of the magic for me surrounding how interpreters actually work and what happens behind the scene when a program is evaluated by an interpreter.
Programming in C
This was my first experience programming in C and it surprised me to discover that I really enjoyed using it. Because of the small language specification very little time was spent reading documentation.
That’s not to say I did not shoot myself in the foot a good few times or struggled with memory management. Using C really cemented my understanding of some of the languages that came after it though. And what problems they attempt to solve or improve upon over C.
Given the right tooling, I’ve grown quite fond of C… Sorry, not sorry.
Resources
- Book: The C Programming Language by Kernighan & Ritchie. Still the best resource for learning C.
- Tools: Valgrind, Gprof, GNU make, GNU Debugger
- This comment in the CPython source explaining the use of computed GOTO’s in the VM for a performance gain due to better CPU branch prediction over using a switch statement.
- Memory allocation strategies by Ginger Bill.
February 2020 Update
News on Clojurists Together 04 03 2020
I have recently edited and somewhat expanded the macros page on the Common Lisp Cookbook. I find it may more legible and reader friendly, so I reproduce it below (however, I cut two parts so than you get the essential).
You’d better read it on the Cookbook: https://lispcookbook.github.io/cl-cookbook/macros.html
The word macro is used generally in computer science to mean a syntactic extension to a programming language. (Note: The name comes from the word “macro-instruction,” which was a useful feature of many second-generation assembly languages. A macro-instruction looked like a single instruction, but expanded into a sequence of actual instructions. The basic idea has since been used many times, notably in the C preprocessor. The name “macro” is perhaps not ideal, since it connotes nothing relevant to what it names, but we’re stuck with it.) Although many languages have a macro facility, none of them are as powerful as Lisp’s. The basic mechanism of Lisp macros is simple, but has subtle complexities, so learning your way around it takes a bit of practice.
How Macros Work
A macro is an ordinary piece of Lisp code that operates on another piece of putative Lisp code, translating it into (a version closer to) executable Lisp. That may sound a bit complicated, so let’s give a simple example. Suppose you want a version of setq that sets two variables to the same value. So if you write
(setq2 x y (+ z 3))
when z=8 then both x and y are set to 11. (I can’t think of any use for this, but it’s just an example.)
It should be obvious that we can’t define setq2 as a function. If x=50 and y=-5, this function would receive the values 50, -5, and 11; it would have no knowledge of what variables were supposed to be set. What we really want to say is, When you (the Lisp system) see:
(setq2 v1 v2 e)
then treat it as equivalent to:
(progn
(setq v1 e)
(setq v2 e))
Actually, this isn’t quite right, but it will do for now. A macro allows us to do precisely this, by specifying a program for transforming the input pattern (setq2 v1 v2 e) into the output pattern (progn ...).
Quote
Here’s how we could define the setq2 macro:
(defmacro setq2 (v1 v2 e)
(list 'progn (list 'setq v1 e) (list 'setq v2 e)))
It takes as parameters two variables and one expression.
Then it returns a piece of code. In Lisp, because code is represented as lists, we can simply return a list that represents code.
We also use the quote: each quoted symbol evaluates to itself, aka it is returned as is:
(quote foo bar baz)returns(foo bar baz)- the quote character,
', is a shortcut forquote, a special operator (not a function nor a macro, but one of a few special operators forming the core of Lisp). - so,
'fooevaluates tofoo.
So, our macro retourns the following bits:
- the symbol
progn, - a second list, that contains
- the symbol
setq - the variable
v1: note that the variable is not evaluated inside the macro! - the expression
e: it is not evaluated either!
- the symbol
- a second list, with
v2.
We can use it like this:
(defparameter v1 1)
(defparameter v2 2)
(setq2 v1 v2 3)
;; 3
We can check, v1 and v2 were set to 3.
Macroexpand
We must start writing a macro when we know what code we want to
generate. Once we’ve begun writing one, it becomes very useful to
check effectively what code does the macro generate. The function for
that is macroexpand. It is a function, and we give it some code, as
a list (so, we quote the code snippet we give it):
(macroexpand '(setq2 v1 v2 3))
;; (PROGN (SETQ V1 3) (SETQ V2 3))
;; T
Yay, our macro expands to the code we wanted!
More interestingly:
(macroexpand '(setq2 v1 v2 (+ z 3)))
;; (PROGN (SETQ V1 (+ z 3)) (SETQ V2 (+ z 3)))
;; T
We can confirm that our expression e, here (+ z 3), was not
evaluated. We will see how to control the evaluation of arguments with
the comma: ,.
Note: with Slime, you can call macroexpand by putting the cursor at
the left of the parenthesis of the s-expr to expand and call the functionM-x
slime-macroexpand-[1,all], or C-c M-m:
[|](setq2 v1 v2 3)
;^ cursor
; C-c M-m
; =>
; (PROGN (SETQ V1 3) (SETQ V2 3))
Macros VS functions
Our macro is very close to the following function definition:
(defun setq2-function (v1 v2 e)
(list 'progn (list 'setq v1 e) (list 'setq v2 e)))
If we evaluated (setq2-function 'x 'y '(+ z 3)) (note that each
argument is quoted, so it isn’t evaluated when we call the
function), we would get
(progn (setq x (+ z 3)) (setq y (+ z 3)))
This is a perfectly ordinary Lisp computation, whose sole point of interest is that its output is a piece of executable Lisp code. What defmacro does is create this function implicitly and make sure that whenever an expression of the form (setq2 x y (+ z 3)) is seen, setq2-function is called with the pieces of the form as arguments, namely x, y, and (+ z 3). The resulting piece of code then replaces the call to setq2, and execution resumes as if the new piece of code had occurred in the first place. The macro form is said to expand into the new piece of code.
Evaluation context
This is all there is to it, except, of course, for the myriad subtle consequences. The main consequence is that run time for the setq2 macro is compile time for its context. That is, suppose the Lisp system is compiling a function, and midway through it finds the expression (setq2 x y (+ z 3)). The job of the compiler is, of course, to translate source code into something executable, such as machine language or perhaps byte code. Hence it doesn’t execute the source code, but operates on it in various mysterious ways. However, once the compiler sees the setq2 expression, it must suddenly switch to executing the body of the setq2 macro. As I said, this is an ordinary piece of Lisp code, which can in principle do anything any other piece of Lisp code can do. That means that when the compiler is running, the entire Lisp (run-time) system must be present.
We’ll stress this once more: at compile-time, you have the full language at your disposal.
Novices often make the following sort of mistake. Suppose that the setq2 macro needs to do some complex transformation on its e argument before plugging it into the result. Suppose this transformation can be written as a Lisp procedure some-computation. The novice will often write:
(defmacro setq2 (v1 v2 e)
(let ((e1 (some-computation e)))
(list 'progn (list 'setq v1 e1) (list 'setq v2 e1))))
(defmacro some-computation (exp) ...) ;; _Wrong!_
The mistake is to suppose that once a macro is called, the Lisp system enters a “macro world,” so naturally everything in that world must be defined using defmacro. This is the wrong picture. The right picture is that defmacro enables a step into the ordinary Lisp world, but in which the principal object of manipulation is Lisp code. Once that step is taken, one uses ordinary Lisp function definitions:
(defmacro setq2 (v1 v2 e)
(let ((e1 (some-computation e)))
(list 'progn (list 'setq v1 e1) (list 'setq v2 e1))))
(defun some-computation (exp) ...) ;; _Right!_
One possible explanation for this mistake may be that in other languages, such as C, invoking a preprocessor macro does get you into a different world; you can’t run an arbitrary C program. It might be worth pausing to think about what it might mean to be able to.
Another subtle consequence is that we must spell out how the arguments to the macro get distributed to the hypothetical behind-the-scenes function (called setq2-function in my example). In most cases, it is easy to do so: In defining a macro, we use all the usual lambda-list syntax, such as &optional, &rest, &key, but what gets bound to the formal parameters are pieces of the macro form, not their values (which are mostly unknown, this being compile time for the macro form). So if we defined a macro thus:
(defmacro foo (x &optional y &key (cxt 'null)) ...)
then
| If we call it thus … | The parameters’ values are … |
|---|---|
(foo a) |
x=a, y=nil, cxt=null |
(foo (+ a 1) (- y 1)) |
x=(+ a 1), y=(- y 1), cxt=null |
(foo a b :cxt (zap zip)) |
x=a, y=b, cxt=(zap zip) |
Note that the values of the variables are the actual expressions (+ a 1) and (zap zip). There is no requirement that these expressions’ values be known, or even that they have values. The macro can do anything it likes with them. For instance, here’s an even more useless variant of setq: (setq-reversible e1 e2 d) behaves like (setq e1 e2) if d=:normal, and behaves like (setq e2 e1) if d=:backward. It could be defined thus:
(defmacro setq-reversible (e1 e2 direction)
(case direction
(:normal (list 'setq e1 e2))
(:backward (list 'setq e2 e1))
(t (error "Unknown direction: ~a" direction))))
Here’s how it expands:
(macroexpand '(setq-reversible x y :normal))
(SETQ X Y)
T
(macroexpand '(setq-reversible x y :backward))
(SETQ Y X)
T
And with a wrong direction:
(macroexpand '(setq-reversible x y :other-way-around))
We get an error and are prompted into the debugger!
We’ll see the backquote and comma mechanism in the next section, but here’s a fix:
(defmacro setq-reversible (v1 v2 direction)
(case direction
(:normal (list 'setq v1 v2))
(:backward (list 'setq v2 v1))
(t `(error "Unknown direction: ~a" ,direction))))
;; ^^ backquote ^^ comma: get the value inside the backquote.
(macroexpand '(SETQ-REVERSIBLE v1 v2 :other-way-around))
;; (ERROR "Unknown direction: ~a" :OTHER-WAY-AROUND)
;; T
Now when we call (setq-reversible v1 v2 :other-way-around) we still get the
error and the debugger, but at least not when using macroexpand.
Backquote and comma
Before taking another step, we need to introduce a piece of Lisp notation that is indispensable to defining macros, even though technically it is quite independent of macros. This is the backquote facility. As we saw above, the main job of a macro, when all is said and done, is to define a piece of Lisp code, and that means evaluating expressions such as (list 'prog (list 'setq ...) ...). As these expressions grow in complexity, it becomes hard to read them and write them. What we find ourselves wanting is a notation that provides the skeleton of an expression, with some of the pieces filled in with new expressions. That’s what backquote provides. Instead of the the list expression given above, one writes
`(progn (setq ,v1 ,e) (setq ,v2 ,e))
;;^ backquote ^ ^ ^ ^ commas
The backquote (`) character signals that in the expression that follows, every subexpression not preceded by a comma is to be quoted, and every subexpression preceded by a comma is to be evaluated.
You can think of it, and use it, as data interpolation:
`(v1 = ,v1) ;; => (V1 = 3)
That’s mostly all there is to backquote. There are just two extra items to point out.
Comma-splice ,@
First, if you write “,@e” instead of “,e” then the value of e is spliced (or “joined”, “combined”, “interleaved”) into the result. So if v equals (oh boy), then
(zap ,@v ,v)
evaluates to
(zap oh boy (oh boy))
;; ^^^^^ elements of v (two elements), spliced.
;; ^^ v itself (a list)
The second occurrence of v is replaced by its value. The first is replaced by the elements of its value. If v had had value (), it would have disappeared entirely: the value of (zap ,@v ,v) would have been (zap ()), which is the same as (zap nil).
Quote-comma ‘,
When we are inside a backquote context and we want to print an expression literally, we have no choice but to use the combination of quote and comma:
(defmacro explain-exp (exp)
`(format t "~S = ~S" ',exp ,exp))
;; ^^
(explain-exp (+ 2 3))
;; (+ 2 3) = 5
See by yourself:
;; Defmacro with no quote at all:
(defmacro explain-exp (exp)
(format t "~a = ~a" exp exp))
(explain-exp v1)
;; V1 = V1
;; OK, with a backquote and a comma to get the value of exp:
(defmacro explain-exp (exp)
;; WRONG example
`(format t "~a = ~a" exp ,exp))
(explain-exp v1)
;; => error: The variable EXP is unbound.
;; We then must use quote-comma:
(defmacro explain-exp (exp)
`(format t "~a = ~a" ',exp ,exp))
(explain-exp (+ 1 2))
;; (+ 1 2) = 3
Nested backquotes
Second, one might wonder what happens if a backquote expression occurs inside another backquote. The answer is that the backquote becomes essentially unreadable and unwriteable; using nested backquote is usually a tedious debugging exercise. The reason, in my not-so-humble opinion, is that backquote is defined wrong. A comma pairs up with the innermost backquote when the default should be that it pairs up with the outermost. But this is not the place for a rant; consult your favorite Lisp reference for the exact behavior of nested backquote plus some examples.
Building lists with backquote
[…]
Getting Macros Right
I said in the first section that my definition of setq2 wasn’t quite right, and now it’s time to fix it.
Suppose we write (setq2 x y (+ x 2)), when x=8. Then according to the definition given above, this form will expand into
(progn
(setq x (+ x 2))
(setq y (+ x 2)))
so that x will have value 10 and y will have value 12. Indeed, here’s its macroexpansion:
(macroexpand '(setq2 x y (+ x 2)))
;;(PROGN (SETQ X (+ X 2)) (SETQ Y (+ X 2)))
Chances are that isn’t what the macro is expected to do (although you never know). Another problematic case is (setq2 x y (pop l)), which causes l to be popped twice; again, probably not right.
The solution is to evaluate the expression e just once, save it in a temporary variable, and then set v1 and v2 to it.
Gensym
To make temporary variables, we use the gensym function, which returns a fresh variable guaranteed to appear nowhere else. Here is what the macro should look like:
(defmacro setq2 (v1 v2 e)
(let ((tempvar (gensym)))
`(let ((,tempvar ,e))
(progn (setq ,v1 ,tempvar)
(setq ,v2 ,tempvar)))))
Now (setq2 x y (+ x 2)) expands to
(let ((#:g2003 (+ x 2)))
(progn (setq x #:g2003) (setq y #:g2003)))
Here gensym has returned the symbol #:g2003, which prints in this funny way because it won’t be recognized by the reader. (Nor is there any need for the reader to recognize it, since it exists only long enough for the code that contains it to be compiled.)
Exercise: Verify that this new version works correctly for the case (setq2 x y (pop l1)).
Exercise: Try writing the new version of the macro without using backquote. If you can’t do it, you have done the exercise correctly, and learned what backquote is for!
The moral of this section is to think carefully about which expressions in a macro get evaluated and when. Be on the lookout for situations where the same expression gets plugged into the output twice (as e was in my original macro design). For complex macros, watch out for cases where the order that expressions are evaluated differs from the order in which they are written. This is sure to trip up some user of the macro - even if you are the only user.
What Macros are For
[…]
See also
A gentle introduction to Compile-Time Computing — Part 1
The following video, from the series “Little bits of Lisp” by cbaggers, is a two hours long talk on macros, showing simple to advanced concepts such as compiler macros: https://www.youtube.com/watch?v=ygKXeLKhiTI It also shows how to manipulate macros (and their expansion) in Emacs.
ITA Software, owned by Google, the airfare search and pricing system that is still used by companies such as Kayak.com or Orbitz, is a well-known example of a successful industrial and large Common Lisp software.
We’re legitimate to wonder if they still run it (they do), if Google develops more CL software (I don’t know), or if they put resources to improve a CL implementation: they do.
According to https://mstmetent.blogspot.com/2020/01/sbcl20-in-vienna-last-month-i-attended.html:
Doug Katzman talked about his work at Google getting SBCL to work with Unix better. For those of you who don’t know, he’s done a lot of work on SBCL over the past couple of years, not only adding a lot of new features to the GC and making it play better with applications which have alien parts to them, but also has done a tremendous amount of cleanup on the internals and has helped SBCL become even more Sanely Bootstrappable. That’s a topic for another time, and I hope Doug or Christophe will have the time to write up about the recent improvements to the process, since it really is quite interesting.
Anyway, what Doug talked about was his work on making SBCL more amenable to external debugging tools, such as gdb and external profilers. It seems like they interface with aliens a lot from Lisp at Google, so it’s nice to have backtraces from alien tools understand Lisp. It turns out a lot of prerequisite work was needed to make SBCL play nice like this, including implementing a non-moving GC runtime, so that Lisp objects and especially Lisp code (which are normally dynamic space objects and move around just like everything else) can’t evade the aliens and will always have known locations.
So now that’s in the wild, Common Lisp can go trendy again: Google uses and dedicates resources for Common Lisp!

Nos acompañan para este episodio Javier Hernández y Vicent Sanchis, dos profesionales del mundo web y especialistas en accesibilidad y web inclusiva. Aunque sobre el papel muchos profesionales simpatizan, son pocos los que le prestan una atención especial y tiempo. En su origen uno de los objetivos de la web era conseguir un acceso universal a la información por cualquier persona, sin que sus dificultades físicas o cognitivas se lo impidan. No obstante, por desconocimiento o falta de empatía, la accesibilidad pasa por ser un asunto menor, al que ni siquiera muchos proyectos dedican atención.
La experiencia de Javier Hernández en Estudio Inclusivo
Javier es socio fundador de Estudio Inclusivo, un singular estudio de diseño web especializado en accesibilidad web. Su equipo cuenta con personas con diversas discapacidades y ha desarrollado multitud de proyectos web, con la accesibilidad como objetivo fundamental. El equipo de Estudio Inclusivo también ha desarrollado un plugin para WordPress que ayuda a implantar soluciones de accesibilidad en los sitios web. En esta entrevista Javier nos habla de su experiencia, de la actualidad del mundo de la accesibilidad y su visión acerca de cómo llevarla a cabo.
Vicent Sanchis, un especialista en visión y desarrollo accesible
Vicent Sanchis es especialista en visión y Doctorado en Ciencias de la Visión. Además combina su actividad profesional como desarrollador web y técnico en accesibilidad. Vicent es un ponente habitual en los meetups de WordPress, donde suele ofrecer información de interés sobre accesibilidad. Vicent nos cuenta unos detalles de gran interés y que nos ayudan a entender mejor las necesidades de las personas con dificultades de acceso a los contenidos.
Entre las cuestiones que discutimos con ellos:
- ¿Qué porcentaje de usuarios de internet se calcula que pueden tener necesidades especiales de accesibilidad y qué tipo de dificultades existen para acceder a la información? ¿Qué tipos de minusvalías afectan a la navegación?
- ¿Cuál es la mejor forma de afrontar un proyecto web accesible?.
- ¿Cómo está actualmente la legislación en materia de accesibilidad web y qué se le puede exigir al propietario de un sitio web?.
- ¿Qué buenas prácticas le recomendarías a un desarrollador web para tener un sitio web mínimamente accesible?
Agradecimiento a nuestra amiga Iga Kurowska por grabarnos la intro del episodio y darle un toque más femenino a este programa.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
En que ando: febrero
Onda Hostil 29 02 2020
Clojure Homebrew Tap
Clojure News 28 02 2020
For Mac or Linux users using Homebrew, Clojure now has its own Homebrew tap, clojure/tools. Creating an official Clojure tap has the following advantages:
-
Clojure team controls formula contents
-
Clojure team controls release timing
-
Freedom to keep an archive of older versioned releases that would be too much for the core tap
-
Easier to automate releases
Dependencies
Clojure requires Java. Clojure officially supports Java LTS releases (currently Java 8 and Java 11), but also tries to ensure interim versions work as well. You can use any Java installation, whether it’s a commercial release from Oracle or an open source version based on OpenJDK (like adoptopenjdk).
The Clojure tools require that either the java command is on the path or that the JAVA_HOME environment variable is set.
How do I use it?
Using an external homebrew tap just requires combining the tap location and the formula name:
brew install clojure/tools/clojurefor a new install or:
brew upgrade clojure/tools/clojureto upgrade your current install. For more detailed information, see the docs at the tap. Other pages on the Clojure site have been updated appropriately.
Development, stable, and archived releases
As those docs describe, there are now three flavors of release available:
-
Stable releases (obtained with the commands above) - this is what most people should use and we expect to update these on the frequency of every 1-3 months.
-
Development releases (using the --devel flag) - the latest bits, probably best for tools developers and those evaluating new bug fixes or functionality. New development releases may come out as frequently as multiple times per week during active periods.
-
Archived version releases - occasionally, it may be useful to install a specific older release, and there will now be an archive of these release formulas available. See the tap docs for how to use.
What about the core tap?
The Homebrew core tap still has a clojure formula for the Clojure tools. You should now consider that unofficial and likely to lag behind the Clojure tap, which should be preferred. Anyone can update it, or we may periodically bump it for big releases, but we will not be actively updating it as of now.

Planned vs Budgeted
MonkeyUser 25 02 2020

Seguimos con la racha de invitados en el podcast y esta semana contamos con Néstor Angulo de Ugarte, especialista en seguridad web de la empresa Sucuri, integrada ahora en la compañía GoDaddy. Néstor trabaja en remoto para Sucuri investigando casos de hackeo en entornos web y dando respuesta a los problemas de seguridad de los clientes.
Como nuestro último invitado, Guillermo, Néstor también estuvo en la WordCamp con Andros como ponente donde ofreció una charla sobre seguridad en WordPress. Con Néstor queremos hablar precisamente de esto de seguridad WordPress, o más específicamente de la forma en la que se puede comprometer una instalación de WordPress y las cuestiones a tener en cuenta para ofrecer más seguridad. Además tenemos la suerte de haber contado con él para grabar en las instalaciones de Idecrea y eso ha hecho si cabe más amena la entrevista.
Entre las cuestiones que hablamos con Néstor:
- Motivaciones más habituales de un atacante a un sitio web con WordPress.
- Los ataques más comunes en sitios web con WordPress.
- Medidas básicas para proteger nuestro WordPress.
- Limpiar correctamente un WordPress infectado.
- Soporte y mantenimiento de sitios web.
- Fuentes y medios de información para estar al día.
- Certificados y auditorias de seguridad para plugins y temas.
Descuentos para licencias de JetBrains.
David Vaquero ofrece una clave para aprovecharse del 20% de descuento en licencias de productos de JetBrains. Es válido hasta 10 licencias de uso, con lo que los primeros que compren, son las que se lo llevan.
Código: MGLGX-9Y9J9-LX3XZ-YCQU6-UTYED
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!


State of Clojure 2020 Results
Clojure News 20 02 2020
Ten years ago, Chas Emerick ran the first State of Clojure survey. In 2010, most users had been using Clojure for just weeks or months, and few were using it as a language for serious work. This year, we see consistent and growing use for work, steady interest in the key value propositions of Clojure, and an ever-evolving community of users.
Clojure at Work
One of the questions we have been asking since 2010 is whether respondents are using Clojure for work, hobby projects, tinkering, or studies. This year, we saw the highest percentage yet of Clojure use at work:
Additionally, we saw a small shift in company size to bigger companies - an increase of 3% in companies of size 1000+ (and reduction in companies size 1-10).

We also asked respondents for the first time how many people were using Clojure at their organization. As expected, many Clojure teams are small. As a high-leverage tool, Clojure is a great fit for small highly-productive teams. However, it was also great to see many respondents at companies with 40 or even 100+ Clojure developers.

A question we’ve been asking since 2010 (with some variation in wording and choices), is in what domains Clojure is being used. The top results have not changed too much over the years but we did see a noticeable increase this year in "enterprise applications", to its highest level ever.

Feedback comments indicate Clojure is a tool yielding high leverage for both companies and teams:
-
"Clojure continues to be a force multiplier and a vital enabler for our production system."
-
"Clojure enables our small team to do more with less."
-
"Clojure is by far the best language I have to use at work, and it is a pleasure to solve problems using it. It is almost perfect."
-
"Clojure is powering our data driven insurance ERP. I cannot think of a better approach. Many thanks!"
-
"Hard to find too many complaints about Clojure: it’s a wonderful language with a great community. I plan to stay with this language + community for a long time. We have basically bet the company’s technical strategy on it."
-
"I love using Clojure and ClojureScript and have moved all our development projects using various different languages (PHP, Python, C#, Javascript) to only using Clojure and ClojureScript"
-
"Our startup is built solely on Clojure and Clojurescript and we are very happy with it."
Clojure’s use continues to grow at hundreds of companies, with an ever higher percentage of developers using it at work for their core business.
Values
Since 2015, we have asked a question about which aspects of Clojure users valued the most. The weighted ranking of those answers has remained virtually identical since 2015. The most important things to Clojure users are: functional programming, the REPL, immutable data, ease of development, and host interop. Indeed these are all things intrinsic to the Clojure experience and align strongly with the reasons Clojure exists.
The open feedback comments often praised the steady arc of Clojure’s development and tradition for growing without breaking:
-
"Clojure is an awesome lisp, lovingly created with taste and refinement. It is a pleasure to think and implement in the abstractions provided."
-
"Great work, team! This is the most stable technology I’ve used in my many years doing software development."
-
"I love what you are doing with the language and community. In the world of churn and constantly pumping changes just to create 'buzz' clojure is like a safe zone where my sanity is kept alive."
-
"I really like the simplicity of Clojure and the functional nature of it. I also like the fact that the team doesn’t slap on a ton of features like every other language out there."
-
"Thanks for sticking to the principles: lean, conservative, essential, no frills, production grade software that brought back Lisp to the mainstream."
Community
Again this year we surveyed the most popular forums where Clojurists interact with each other. Some new and/or rising entries included in-person Clojure conferences (we saw many new ones this year!), the new Ask Clojure site, Telegram chats, and Discord.

We also collect information on how users are involved in the Clojure ecosystem. The response this year were very similar to last year but we did see mild upticks in helping new Clojure users, advocating for Clojure in their organization, and maintaining open source libraries, all great contributions!

In feedback comments, many people enjoyed the kind and responsive Clojure community:
-
"The Clojure community is absolutely fantastic. Being able to post a question and get thoughtful & insightful answers quickly is immensely valuable. Thank you for fostering such an incredible community."
-
"Clojure (Script) is a great, well-thought out language that has helped me tremendously in my work. However, it also exposed me to a wonderful community of thoughtful developers who have given me wonderful new insights, while remaining a friendly and welcoming community"
-
"Wonderful language and a uniquely insightful community. It has helped me rediscover my love for programming."
Deep Dives
Clojure developers will be particularly interested in the version and tooling related questions in the survey.
One new question we asked this year was about the primary developer operating system to give us better guidance about tool-related work. As expected, MacOS was the leader (55%), followed by Linux (35%) and Windows (9%):

For primary development tool, there were only minor updates this year. Emacs dropped slightly to 43%, IntelliJ/Cursive rose slightly to 32%, and VS Code with Calva had the biggest increase to 10%.

Clojure users have a wealth of fine development environments, each suited to different communities and tastes, and we’re glad to see them all getting better day by day.
For many years, the survey has included a question about "build tools", but this idea of a single monolithic tool has become increasingly less reflective of how people are managing Clojure projects, where they may use multiple tools for different parts of their process, particularly in mixed Clojure/ClojureScript projects. In response to this, we tailored this question more tightly to dependency management and made it multi-select this year:

Looking at previous years, we continue to see strong (but slightly reduced) use of Leiningen, and a steady increase in use of clj/deps.edn. For ClojureScript work, shadow-cljs has made big strides over the last couple years, with big support from Clojurists Together.
In the greater world of Java and the JVM, Java has migrated to a new release strategy where releases come out every spring and fall, and every 3 years there is a "long term support" (LTS) release - 8, 11, and (presumably) 17. Java 9 introduced a major change with the module system and in all JVM communities this has caused a significant user base to remain on Java 8. Clojure reflects this as well (although probably shows more shift to Java 11 than other language communities):

Releases like Java 9, 10, 12, and soon 13 are effectively dead when the next release comes out and we would recommend sticking primarily to the LTS releases and maybe the latest release, if it’s not an LTS release.
One aspect of Java 11 that is underappreciated is significant work to make Java work better in containers like Docker. If you are deploying in containerized environments with Java 8, you should really be looking closely at the changes in Java 11 and considering an upgrade.
Clojure itself has been using Java 8 as the baseline JVM for a couple years and will continue to do so (while also supporting newer versions of Java). When running Clojure, we recommend Java 8 or 11 right now.
Since last year, we’ve seen strong uptake of Clojure 1.10.0 and 1.10.1. The latter was a maintenance release this year with error handling improvements building on the changes in Clojure 1.10.0 and mitigations for some Java performance regressions in their service releases after Java 8u201. Use of Clojure 1.8 and earlier continues to dwindle:

In addition to the prior dependency management question, we also added a new question on how respondents are starting their apps in production. Based on feedback, it’s likely the wording and answer choices will need some fine-tuning next year, but there is some interesting feedback in the results:

The majority of users are using launchers like Leiningen or clj to start their production apps, more so than by building jars or uberjars and launching them directly with Java. We do see a small group also experimenting with Graal native images (particularly common with smaller scripting apps).

Presale
MonkeyUser 18 02 2020
Home server and Pi-hole
Posts on James Routley 17 02 2020
Analytics server
Posts on James Routley 16 02 2020
Para este episodio contamos con la compañía de Guillermo Tamborero, desarrollador y socio fundador de la empresa iproject.cat, especialistas en desarrollo proyectos web a medida, Progressive Web Apps y soluciones basadas en PHP, WordPress, Laravel y VueJS. Con Guillermo hablamos de las Aplicaciones Web Progresivas (PWA), en qué consisten y cómo encajan en el ecosistema de desarrollo web. Hablamos de las ventajas que ofrecen, cómo empezar tu propia PWA y también los inconvenientes que puedes tener en su desarrollo.
En el episodio hablamos sobre el escaso interés de Apple en desarrollar junto con Google, soluciones estándar para PWA. Y es que Apple a pesar de ser una de las primeras compañías en apoyar la tecnología, ha decidido desmarcarse ofreciéndole un soporte limitado. Trabajar con una Aplicación Web Progresiva ofrece una experiencia muy similar a realizarlo con una aplicación nativa, pero con la ventaja de estar en un entorno idéntico al del navegador web. Como explica Guillermo, empezar a realizar tu propia PWA es tan fácil como instalar un plugin de WordPress. Otra característica de las PWA es que es posible instalarlas en casi cualquier dispositivo que admita un navegador web (en especial los basados en Chromium).
Por último hablamos de las diferentes opciones que tenemos para desarrollar una aplicación móvil, con soluciones que van desde las opciones nativas para Android y iOS, a soluciones híbridas (Cordova, Ionic… Capacitor) o «pseudo nativas» como Xamarin, React Native, Flutter o NativeScript.
Andros tuvo la oportunidad de coincidir con Guillermo en la pasada WordCamp de Zaragoza donde ofreció una charla sobre la edición con bloques en WordPress usando BlockLab.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Mobile viewports
Posts on James Routley 15 02 2020
How do .epubs work?
Posts on James Routley 13 02 2020
El audio de este episodio está extraído de una clase que realizó David Vaquero en un curso sobre Python. En la clase se ofrece una introducción a la teoría del testing y herramientas que se utilizan para probar el código de un sitio web. Es un contenido que te ayudará a entender en qué consiste el testing y cómo encaja en el desarrollo web.
Puedes ver la charla en el canal de YouTube de Cursos de Desarrollo y acceder a más contenido incluyendo cursos gratuitos, en la página web de David Vaquero https://cursosdedesarrollo.com/
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
A gratitude journal design
Posts on James Routley 12 02 2020
Last year my team and I worked on a very challenging IVR system. After almost a year in production and thousands of processed transactions, I teamed up with the great people over at the Twilio blog to write an introductory tutorial for developing IVR systems using Django and Twilio IVR.

Minor Change
MonkeyUser 11 02 2020
Understand GROUP BY in Django ORM by comparing QuerySets and SQL side by side. If SQL is where you are most comfortable, this is the Django GROUP BY tutorial for you.

Nos trasladamos a las instalaciones de la empresa valenciana Slimbook, fabricante de excelentes ordenadores personales especializados en GNU/Linux. Para ello nos recibe Alejandro López, CEO de Slimbook para explicarnos con detalle la filosofía de la empresa, basada en ofrecer productos de excelente calidad, combinados con un soporte cercano y profesional. A pesar de su juventud, Slimbook cuenta con un catálogo muy completo de productos, que incluyen portátiles ultrabooks, equipos de escritorio y compactos. Slimbook proporciona un cuidado montaje de los componentes y trabaja con marcas líderes como Intel y Samsung para la fabricación de sus equipos.
Con Alejandro hablamos también de la vocación de comunidad de la empresa y su Linux Center, una aula dedicada a fomentar el código abierto y el entorno GNU/Linux. Slimbook ofrece una combinación excelente de software y hardware, lo que garantiza que sus equipos tengan una experiencia de usuario muy elevada. Finalmente nos cuentan sus planes de futuro, las mejoras que tienen en mente y alguna colaboración que pactamos para el futuro.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Writing daily, one week in
Posts on James Routley 08 02 2020
Breadcrumbs
Posts on James Routley 07 02 2020
Blog UI updates
Posts on James Routley 06 02 2020
Vim diff
Posts on James Routley 05 02 2020
![]()
El mundo de las redes sociales está dominado por grandes empresas tecnológicas, con audiencias de millones de personas y presupuestos gigantes. Estas redes sociales están diseñadas para explotar la atención, los datos y el tiempo de los usuarios. En este escenario ha surgido hace poco una red social llamada Launchyoo y que se presenta como una red social alternativa y pensada con el usuario en el centro.
![]()
Hablamos con Vicente Pechuán, un valenciano que tras pasar por el mundo del motociclismo, decidió crear desde cero la red social que le gustaría. Vicente nos cuenta en esta entrevista los orígenes de Launchyoo, sus motivaciones y lo que le hace diferente a las redes sociales existentes. Con Vicente hablamos de la dificultad de lanzar un proyecto en un mercado tan maduro y también de cómo han orientado la aplicación de una forma integral, integrando originales funcionalidades y pensando en nuevas formas de organizar tu contenido.
Launchyoo es otro ejemplo de empresa con base tecnológica que puede lanzar su producto gracias a las tecnologías en la nube, que facilitan el despliegue y la flexibilidad de recursos. También de una empresa distribuida en un equipo en remoto.
Con Vicente también hablamos del futuro de Launchyoo y cómo afrontan los próximos meses. Launchyoo es una red social con un equipo distribuido y orientado al mercado hispanohablante, aunque también está disponible en varios idiomas. Dispone de un soporte para varios tipo de contenido, grupos, páginas de marcas y empresas y también permite diferenciar entre contactos.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
CO2 emissions on the web
Danny van Kooten 03 02 2020
I’ve spent the last month trying to reduce the carbon footprint of the websites I have (some) control over. When talking about this with other people they often look at me blankly before asking “aren’t you taking this a little too far?”.
The simple answer is no. In fact, it is probably the most effective use of my time when it comes to reducing carbon dioxide emissions.
Just last week I reduced global emissions by an estimated 59.000 kg CO2 per month by removing a 20 kB JavaScript dependency in Mailchimp for WordPress. There’s no way I can have that kind of effect in other areas of my life.
CO2 emissions from distributed code
All of my WordPress plugins combined run on well over 2 million different websites, each website receiving who knows how many visitors.
At an average energy expenditure of 0,5 kWh per GB 1 of data transfer this means that every kB equals 0,5 kWh / 1.000.000 kB * 2.000.000 websites = 1 kWh if each of these websites received exactly 1 visitor.
Let’s assume the average website receives about 10.000 unique visitors per month and serves files from cache for returning visitors. The total amount of energy saved by shaving off a single kilobyte is then 1 kWh * 10.000 visitors = 10.000 kWh.
10.000 kWh of energy produced by the current European electricity grid equals about 10.000 * 0,295 = 2950 kg of CO2.
Shaving off a single kilobyte in a file that is being loaded on 2 million websites reduces CO2 emissions by an estimated 2950 kg per month.
To put this into perspective, that is the same amount of CO2 saved each month as:
- Driving my Toyota Yaris for 18.670 kilometers. (158 g CO2 per km)
- 5 flights from Amsterdam to New York. (679 kg CO2 per flight)
- Eating 118 kg of beef (25 kg CO2 per kg of beef)
I already work from home, am a vegetarian and didn’t take any flights in the last 3 years so it seems I am stuck trying to make the web more efficient.
What can we do?
According to httparchive.org, the average website on desktop is about 4 times as large as in 2010. On mobile, where data transfer is way more expensive in terms of energy usage, the numbers look even worse: from 200 kB up to a whopping 1,9 MB!
As web developers we have a responsibility to stop this madness. Did websites really get 4 times as good? Is this motherfuckingwebsite.com clocking in at 5 kB in total really that bad in comparison? I don’t think so.
Whenever you are adding to a website, ask yourself: is this necessary? If not, consider leaving it out.
Your content site probably doesn’t need JavaScript. You probably don’t need a CSS framework. You probably don’t need a custom font. Use responsive images. Extend your HTTP cache lifetimes. Use a static site generator or wp2static.com instead of dynamically generating each page on the fly, despite never changing. Consider ditching that third-party analytics service that you never look at anyway, especially if they also happen to sell ads. Run your website through websitecarbon.com. Choose a green web host.
I’m sorry if that turned into a bit of a rambling, but I hope you see where I am going with this.
Personally I constrained myself to not use more than 1 kB of CSS for the website you are reading this on. And I really liked making that work, it sparked creativity.
Let’s do our share as web developers and stop bloating the web.
Energy costs of data transfer varies a lot depending on the type of network that is used. The range seems to be from 0,08 kWh per GB for fixed broadband connections to 37 kWh per GB for 2G networks.
I initially went with a global estimate of 2,9 kWh per GB in this post (the average cost per GB for 3G networks), but later changed it to 0,50 kWh per GB as I believe that is a better estimate for 2020 2. It’s hard to come up with a good estimate that works globally, but I didn’t mean for this post to be about exact numbers anyway.
The most important thing I attempted to convey is that the choices we make in developing for the web have consequences that really add up at scale.
References
1 Pihkola, H., Hongisto, M., Apilo, O., & Lasanen, M. (2018). Evaluating the energy consumption of mobile data transfer-from technology development to consumer behaviour and life cycle thinking. https://doi.org/10.3390/su10072494
2 Aslan, Joshua & Mayers, Kieren & Koomey, Jonathan & France, Chris. (2017). Electricity Intensity of Internet Data Transmission: Untangling the Estimates: Electricity Intensity of Data Transmission. Journal of Industrial Ecology. https://doi.org/10.1111/jiec.12630
How I make coffee
Posts on James Routley 03 02 2020
En qué ando: enero
Onda Hostil 02 02 2020

Los foros y las comunidades virtuales forman parte de internet desde casi sus inicios. La capacidad de formar parte de un grupo de manera virtual, con o sin tu nombre real, ha propiciado la interacción y el intercambio de ideas de una forma antes desconocida. Si bien internet, por su facilidad y conveniencia, es una herramienta ideal para crear comunidades, la cosa se complica cuando se desea trasladar ese dinamismo digital al mundo físico.
En este episodio queremos hablar de experiencias creando y desvirtualizando comunidades en internet. Para ello nos acompaña de nuevo en el podcast Juan Simón García, consultor y formador en nuevas tecnologías y presidente de la Asociación Valenciana de Realidad Extendida (AVRE).
Juan lanzó hace un tiempo una comunidad alrededor de la realidad virtual en Valenccia, con un grupo de meetup y Telegram . Con él hablaremos de esto de desvirtualizar comunidades creadas en internet, algunas experiencias y por supuesto nuestra opinión alrededor de este tema. Juan comparte los puntos positivos de crear comunidades pero tampoco oculta, la responsabilidad personal que involucra dedicarte a proyectos abiertos.
Entre las cuestiones discutidas en el episodio del podcast se incluyen:
- Experiencia de Juan con el grupo de Valencia Virtual. Puntos positivos y negativos.
- Dificultad de llevar a la gente hacia planos presenciales y formas de hacerlo mejor.
- Organización de eventos presenciales (trabajo personal y dedicación).
- Motivaciones de la gente para unirse a grupos y si son conscientes de lo que implica.
- ¿Se debería cobrar por las membresías o establecer límites?.
- ¿Deben las empresas mantenerse al margen de ciertas comunidades?
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

El comando top es conocido por muchos, por listarnos los procesos activos y la carga del sistema, y su primo el comando htop, es aún más completo.
Si deseas instalarlo:
[code]sudo apt install htop[/code]
Vía codeahoy os dejamos 2 imagenes que valen más que mil palabras:
Writing daily
Posts on James Routley 01 02 2020

Open Space
MonkeyUser 28 01 2020

Next Level
MonkeyUser 28 01 2020
Volvemos a contar de nuevo para este episodio con el «indie hacker» Miguel Piedrafita, que ya estuvo con nosotros en un episodio y que hoy vuelve para contarnos su último proyecto, Sitesauce. Este innovador servicio web que permite transformar un sitio dinámico basada en servidor, como por ejemplo un CMS hecho con WordPress, en un servicio estático. Esto permite aprovechar las ventajas de velocidad y seguridad que ofrecen los sitios estáticos, pero al mismo tiempo manteniendo el panel de control y la organización de los sitios basados en gestores de contenido.
El SSR o server side rendering consiste en alojar archivos estáticos listos para servir y sin intervención de base de datos o una lógica de procesamiento. Miguel viene a contarnos más sobre su proyecto, cómo se le ocurrió este servicio y los casos específicos donde su solución puede ser más interesante. Miguel habla de las tecnologías usadas y además nos cuenta detalles sobre el proyecto. También le preguntamos consejos sobre como arrancar tu propio proyecto en internet.
En la segunda parte del podcast volvemos con la sección Radar donde hablamos de recursos, herramientas y tecnologías interesantes en el mundo del desarrollo web.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
En el evento de WordPress WordCamp Zaragoza nuestro compañero Andros Fenollosa tuvo la oportunidad de participar con dos charlas. En esta charla Andros demuestra las bondades del API REST de WordPress para agilizar la ejecución de proyectos web. En este caso Andros cuenta como la API de WordPress le ayudó a alimentar una APP que tuvo que realizar en su estudio en poco tiempo.
En la charla Andros también cuenta como se ayudó de VueJS y de las herramientas que incorpora, además de detalles sobre como construir la aplicación.
Audio extraído del vídeo de la charla disponible WordPress.tv.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

User Story
MonkeyUser 21 01 2020
El cloud sigue imparable y cada vez son más los proveedores que ofrecen soluciones de calidad con grandes prestaciones a un precio muy competitivo. Clouding.io es una empresa que ofrece servidores cloud vps con sello español desde su centro de datos en Barcelona. Para este episodio contamos con Patricia Armesto, del equipo de comunicación, marketing y comunicación con el cliente de Clouding.io. Con Patricia hablamos sobre lo que ofrece desde España clouding.io en el mercado del cloud, sus características más destacables y cuestiones como el tipo de proyectos que se lanzan desde su infraestructura.
El nombre de Clouding ya ha surgido en alguno de nuestros episodios y hay que destacar los excelentes resultados que obtiene en rendimiento. Clouding se caracteriza por un acento especial en la atención al cliente y en una infraestructura de primer nivel 100% en Barcelona. A destacar también su facilidad de uso y la opción de comenzar gratuitamente con un acceso abierto para probar su servicio con 5 euros de crédito. Además clouding.io no sólo opera con clientes en España, sino que sus servicios también son contratados por clientes internacionales.
Con Patricia Armesto tratamos las siguientes cuestiones:
- Orígenes de clouding.io
- Como están viviendo el auge del cloud en la empresa española.
- Características más destacables que ofrece clouding a sus clientes.
- Tipo de cliente que confía en sus servicios y qué tipo de proyectos suelen montar.
- Su servicio de administración y soporte Cloud Pro.
- Planes de futuro.
Estamos agradecidos al equipo de clouding.io por la atención prestada desde el primer momento y como se comenta en la entrevista, les emplazamos a nuevas colaboraciones que ayuden a conocer las posibilidades del cloud español para los desarrolladores y proyectos empresariales.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Como episodio especial del podcast, subimos la grabación de la intervención de Javier Archeni en el Meetup de WordPress Valencia celebrado este miércoles 15 de enero en las instalaciones de IEM Business School. La charla tuvo como objetivo presentar las oportunidades que ofrece el podcasting y cómo garantizar la independencia de tus contenidos, sin renunciar a la exposición que ofrecen las plataformas de streaming.
En la charla se destacó el crecimiento sostenido que ha venido experimentando el podcasting y los diferentes actores que protagonizan al medio. Debido a que se trata de una presentación en el Meetup de WordPress Valencia, se explica los puntos básicos a tener en cuenta para crear tu podcast con este software. Además se ofrece una visión del futuro del podcasting y el escenario que afrontamos como productores de contenido.
Descargar presentación en formato PPTX editable (Mega).
Desde aquí agradecer al equipo de organización del evento, con Ricardo Vilar a la cabeza la oportunidad para participar en el encuentro. También a los patrocinadores del evento por el apoyo brindado para su celebración (Siteground, Weglot) Confiamos poder seguir colaborando con nuevos eventos que acerquen la tecnología a los profesionales de los contenidos y el desarrollo web.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

¿Qué consejo le darías a un desarrollador web? seguramente si tienes ya un poco de experiencia sabrás que hoy en día un developer no solo debe centrarse en el tema del código como tal, hay varias habilidades adicionales que se necesitan para tener en cuenta que un desarrollador web tiene un perfil más completo.
En este video les comparto 32 consejos para web developers, consejos muy rápidos y sencillos de seguir si tu ruta de carrera conlleva tener un puesto de este tipo, pues temas de colaboración, de apoyo a la comunidad, de tener presencia en internet y de estar constantemente actualizándose con las nuevas tecnologías son temas importantes que necesitas cumplir para tener un perfil completo.

Fix
MonkeyUser 14 01 2020


Hace tiempo que no comparto diseños de sitios web. En esta ocasión les comparto una galería de diseños de sitios web con estilo enfocado a la música. Muchos de estos sitios obviamente tienen que ver con artistas o la fuente hace referencia mucho al tipo de música que vas a encontrar. Sitios que se enfocan en colecciones de música o servicios de streaming están enfocados en dar a conocer los éxitos más populares alrededor del mundo, por lo que son varios los tips que pueden tomar como referencia si su próximo proyecto va a ir enfocado a la música.

2. Slide:
3. Mixtape:
4. Milando:
5. BeatsWave:
6. SoundFlare:

7. Bepop:
8. Mousiqua:
9. Bridge:
10. Kentha:
Magical Rainbow Gradients
Josh Comeau's blog 13 01 2020
Para este primer episodio del año, queremos continuar hablando del estudio de tecnologías web realizado por David Vaquero. En esta ocasión vamos a detenernos en los datos que ha conseguido David en relación a los frameworks de front-end. Veamos si hay sorpresas en las tecnologías más usadas y si podemos ver alguna tendencia clara en los datos que ha obtenido David.
Antes de empezar el episodio 123, hablamos de la creación del grupo Malditos Webmasters en Telegram. Se trata de un espacio para todas aquellas personas interesadas en la creación y mantenimiento de un sitio web. También hablamos de nuestras próximas charlas en meetup WordPress Valencia y WordCamp Zaragoza. Por último también comentamos nuestras expectativas y propósitos para el año que comenzamos.
Con respecto a las tecnologías de front-end, poca sorpresa al encontrarnos a jQuery como el dominador absoluto en este terreno. Una cuestión importante es advertir que son datos obtenidos de vistas públicas procedentes de dominios facilitados por Alexa. No se muestran los datos procedentes de sitios web protegidos por contraseña o que pueden estar detrás de algún proxy o cortafuegos. Hablamos sobre React, Vue y también sobre Angular. Ofrecemos también unos datos sobre las demandas laborales en este terreno.
En la segunda parte del episodio volvemos con la sección Radar, con interesantes recursos propios y de terceros. Disponibles los enlaces en la sección inferior.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

AVISO IMPORTANTE: Las distintas distribuciones de GNU/Linux han quitado la opción de hibernar, porque genera muchos problemas. tanto de incompatibilidad con mucho ordenadores, como fallos puntuales. Nosotros hemos probado y ahora mismo funciona, pero no sabemos si después de una actualización de tu distribución linux, mañana por ejemplo, dejará de funcionar. Es por ello que deberás asegurarte cuando hibernes, que el ordenador está completamente apagado, antes de meterlo en un maletín y que se sobre-caliente.
Para poder activar la hibernación en tu portátil, lo primero que debes saber es que has de tener en la bios desactivado el Secure Boot, y has de haber instalado así el sisetma operativo, no se puede cambiar a las bravas. Y lo segundo que has de saber es que vas a perder un trozo de disco duro, ya que has de reservar el espacio. Aunque desde Ubuntu 18 ya no hay partición swap, si no un fichero pequeño y dinámico, ahora has de fijarle un tamaño, concretamente el tamaño de tu memoria RAM (o algo más por precaución).
Puedes mirar gráficamente cuanta RAM tiene tu ordenador, o puedes comprobarlo via terminal con:
[code]free[/code]
Del comando de arriba quedarte con el primer valor de memoria, o si quieres usa este otro comando:
[code]vmstat -s | awk '{print int(($1 / 1024 / 1024)+0.51)}' | head -1[/code]
Si tuvieras la swap ya activa, primero hemos de detenerla, para poder luego redimensionarla. Detenla con este comando:
[code]sudo swapoff -a[/code]
Crea el fichero de swap con el tamañao de tu ram, yo pongo en mi ejemplo 16 GB, pero cambia el número por tu RAM o un poco más:
[code]sudo fallocate -l 16g /swapfile[/code]
Dale permisos y añadelo al fichero fstab con:
[code]sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile[/code]
Mira si ya tienes el el fichero /etc/fstab una linea que empiece por /swapfile, si no la tienes añadela con esto:
[code]echo '/swapfile swap swap defaults 0 0' | sudo tee -a /etc/fstab[/code]
Montamos y verificamos:
[code]sudo findmnt -no SOURCE,UUID -T /swapfile[/code]
Nos mostrará algo como esto: /dev/sda1 0c233fbb-f72e-470f-8460-4f2521bf3569
La segunda parte después de sda1 (o nvme0n1p1 o tu lvm) es el UUID de la partición y tienes que apuntártela, o copiarla.
Ahora instalamos y configuramos uswsusp:
[code]sudo apt install uswsusp
sudo dpkg-reconfigure -pmedium uswsusp[/code]
Te preguntará si quieres continuar sin valeidar swap, respondes "Sí".
Luego te dirá que selecciones la partición, y NO has de elegir /swapfile, y SÍ el UUID que has apuntado antes.
En cifrar la partición hibernada diremos NO para que no nos pide una contraseña adicional para desbloquarlo, con cerrar sesión que lo hace, es suficiente.
Por si acaso ahora:
[code]sudo update-initramfs -u[/code]
Es hora de probar si la hibernación funciona con este comando (espera un minuto):
[code]sudo s2disk[/code]
Estos pasos son solo para Linux Mint:
Si no ha vuelto a tu sesión después de hibernar, haz estos pasos, pero si ha ido bien, no lo hagas:
[code]sudo nano /etc/default/grub[/code]
y añadir en la linea GRUB_CMDLINE_LINUX_DEFAULT="quiet splash", antes de cerrar las comillas resume=UUID= con el identificador de tu partición que hemos copiado antes, o sea en nuestro caso quedaría así:
[code]GRUB_CMDLINE_LINUX_DEFAULT="quiet splash resume=UUID=0c233fbb-f72e-470f-8460-4f2521bf3569"[/code]
[code]sudo update-grub[/code]
[code]reboot[/code]
Fin de los pasos para Linux Mint
Ahora tenemos que editar el servicio de hibernación para que utilice el nuevo métido:
[code]sudo systemctl edit systemd-hibernate.service[/code]
Y dentro pegamos:
[code][Service]
ExecStart=
ExecStart=/usr/sbin/s2disk
ExecStartPost=/bin/run-parts -a post /lib/systemd/system-sleep[/code]
Volvemos a probar la hibernación, pero ahora con el servicio:
[code]systemctl hibernate[/code]
Si no funciona puedes ver el estado y ver los errores que muestra:
[code]systemctl status systemd-hibernate.service[/code]
Ahora que todo funciona correctamente, sólo tenemos que al apagar el ordenador, aparezca la opción de hibernar junto a la de reiniciar o suspender.
Vamos a crear un fichero nuevo con:
[code]sudo nano /etc/polkit-1/localauthority/50-local.d/com.ubuntu.enable-hibernate.pkla[/code]
y dentro pagamos a pegar esto y guardar:
[code][Re-enable hibernate by default in upower]
Identity=unix-user:*
Action=org.freedesktop.upower.hibernate
ResultActive=yes
[Re-enable hibernate by default in logind]
Identity=unix-user:*
Action=org.freedesktop.login1.hibernate;org.freedesktop.login1.hibernate-multiple-sessions
ResultActive=yes[/code]
Ahora reiniciamos el ordenador y ya estará listo :)
Adicionalmente en Gnome Shell existen extensiones como esta para que el botón esté más accesible.
State of Clojure 2020 Survey
Clojure News 07 01 2020
It’s time for the annual State of Clojure Community Survey!
If you are a user of Clojure or ClojureScript, we are greatly interested in your responses to the following survey:
The survey contains five pages:
-
General info
-
Tool usage
-
Questions specific to JVM Clojure (skip if not applicable)
-
Questions specific to ClojureScript (skip if not applicable)
-
Final comments
The survey will close January 23rd, after which all of the data will be released with some analysis. We greatly appreciate your input!

CORS significa Cross-Origin Resource Sharing, y es una política a nivel de navegador web que se aplica para prevenir que el dominio A evite acceder a recursos del dominio B usando solicitudes del tipo AJAX como cuando usamos
fetch() o XMLHttpRequest.Un ejemplo básico de este comportamiento es cuando creas un archivo html y tratas de hacer una llamada AJAX a cualquier sitio en internet o servidor en tu equipo o red local. Vas a obtener un error como el siguiente:

Puedes encontrar toda la información detallada en el sitio de Mozilla pero en este tutorial vamos a ver cómo manejar este comportamiento con Node.js
Lo primero que necesitamos saber es que si tenemos dos dominios: posco.com y contaro.com en principio no pueden comunicarse. Si nosotros queremos que por ejemplo contaro.com pueda permitir a otros dominios acceder a sus recursos, podemos hacerlo a través del módulo de cors. Lo primero es instalarlo
$ npm install cors
Después, vamos a incluirlo en nuestro archivo de Node.js
var express = require('express')
var cors = require('cors')
var app = express()
app.use(cors())
app.get('/products/:id', function (req, res, next) {
res.json({msg: 'This is CORS-enabled for all origins!'})
})
app.listen(80, function () {
console.log('CORS-enabled web server listening on port 80')
})
var whitelist = ['http://example1.com', 'http://example2.com']
var corsOptions = {
origin: function (origin, callback) {
if (whitelist.indexOf(origin) !== -1) {
callback(null, true)
} else {
callback(new Error('Not allowed by CORS'))
}
}
}
...
app.get('/products/:id', cors(corsOptions), function (req, res, next) {
res.json({msg: 'This is CORS-enabled for a whitelisted domain.'})
})

Features
MonkeyUser 07 01 2020
Feliz 2070
Sección Materia | Ciencia en EL PAÍS 03 01 2020
En qué ando: diciembre
Onda Hostil 01 01 2020

Personal goals for 2020
Danny van Kooten 30 12 2019
My last blog post where I defined goals for the upcoming year was back in 2013.
It’s fun to go through that post. In a way I feel some shame of where I was back then (which is silly, but I feel it nonetheless). At the same time it’s a testament of how far I’ve come, so there is some proud as well.
Since this will be another post in which I will be defining my goals for the upcoming year, I hope to be looking at this post a few years from now with the same mix of feelings.
For the last few years I have been drifting, just taking life as it happened. Caring for my daughter (now daughters!), keeping the business running, trying to stay healthy while attempting to enjoy life at the same time.
But I miss having clear and measurable goals. I like the feeling of moving closer to a set target each and every day, even if just a tiny bit. That’s why I came up with this list of what I would like to achieve in 2020.
Hire a WordPress developer
I’ve postponed this for years, only hiring to help reduce the burden of daily support.
Despite it being justified financially to bring on another WordPress developer to help me out with more advanced support questions and possibly some development, I’ve yet to take the plunge.
For 7 straight years I have been answering emails for the Mailchimp for WordPress plugin each and every day, with at most 48 hours of rest in between. This has certainly taken its toll, so I would like to get some help in this area or alternatively sell off the product in its entirety.
Learn Rust
After learning Go (and open-sourcing Browserpass) in 2016 and some C in 2019, I would like to gain a basic understanding of Rust in 2020.
This goal is a little vague as it is, so I will need to rephrase this goal by setting out to create a specific tool in Rust instead. More on that later.
Lead climb in nature
In the spring of 2020 I will be taking lessons in lead climbing. The plan is to use our summer holiday to go lead climbing in nature. Slovenia is tempting, but I am not sure whether we are ready to make the 12-hour drive with 2 young kids aboard.
There are so many spots in Europe to go lead climbing that finding a beautiful place closer to home shouldn’t be an issue though.
Send a bouldering route graded 6C (V6)
Another climbing related goal is to send an indoor bouldering route graded 6C. After just a few months of climbing I’m currently climbing 6B on a good day, so this should not be an issue if I put in consistent sessions and do not injure myself.
Get my chess ELO rating up to 1600
I have been slacking when it comes to chess lately, not playing any games at all for months. Perhaps having a clear goal will help.
My current ELO rating is about 1400, I would like to get this up to 1600 in 2020.
Not buying a new laptop
My current laptop is a 2013 Macbook Pro, which is still running great. Despite that I have been feeling the urge to replace it lately, even though it is not even my daily driver.
I gave in to the urge last month and bought a Dell XPS 15”, only to return it a week later because I realised it was an unnecessary purchase. So for 2020 (and beyond) the goal is to hold on to the Macbook Pro until it literally falls apart.
If you’re still reading this far (and even if not), here’s to a wonderful 2020 for you and your loved ones.
Send me a tweet if you have written goals you would like me to remind you of as the year progresses, it would be good to keep each other accountable!
Para finalizar el año proponemos un episodio clásico sobre tendencias para el año que entra. En esta ocasión en lugar de hacer un recorrido por las principales tendencias, vamos a hacerlo colocando a una tecnología en auge en relación a una que, por los motivos que sean, se encuentre en declive o en bajada. Cada uno de nosotros ha preparado una clasificación en dos categorías: ganadores y perdedores.
| ? Winners | ? Losers |
|---|---|
| Python / Adobe | AMP |
| Infraestructura Cloud | Regulación de acceso a internet y privacidad |
| HTTP3 / Microservicios | MySQL / Chrome |
Personajes del año 2019 en la web
En la segunda parte del programa destacaremos a los que para nosotros han sido los personajes del año, para lo bueno y para lo malo en esto del mundo de la web y de internet.
| ? Héroes del 2019 | ? Villanos |
|---|---|
| Guido Van Rossum | Project Manager de Safari |
| Quincy Larson | Mark Zuckerberg |
| Fernando Acero y Rasmus Lerdorf | Project Managers de IE6/Edge |
Seguro que muchos tenéis vuestra propia lista de ganadores y perdedores para el 2019. Nos encantará conocerla y que la compartáis con nosotros.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!
Finding your first remote job
Josh Comeau's blog 19 12 2019
Dedicamos este episodio a discutir sobre las tecnologías que triunfan en internet, y en especial hacerlo en el mundo del desarrollo web. Son muchas las tecnologías que están de moda, tanto en los eventos, como en la mayor parte de las empresas tecnológicas. Por eso nos gustaría hablar sobre cuál es la situación actual de la utilización de las tecnologías que se utilizan a día de hoy para que seamos conscientes de uso real en los principales sitios de internet.
Para ello nuestro compañero David ha estado realizando un extenso estudio (datos disponibles en su sitio web) durante el último mes, utilizando la base de los principales sitios web según Alexa, en el que analiza hasta 1.400.000 sitios web para saber qué tecnologías utilizan. En este episodio del podcast David nos explica la metodología que ha usado en su estudio, las herramientas usadas y cómo ha organizado la información en su informe.
En el episodio hablamos de tecnologías consolidadas, pero también nos han sorprendido ciertas librerías y tecnologías. Al final se trata un episodio de análisis de tecnologías web y su influencia en nuestro trabajo.
Visita la web del podcast donde encontrarás los enlaces de interés discutidos en el episodio. Estaremos encantados de recibir vuestros comentarios y reacciones.
Nos podéis encontrar en:
- Web: republicaweb.es
- Canal Telegram: t.me/republicaweb
- Grupo Telegram Malditos Webmasters
- Twitter: @republicawebes
- Facebook: https://www.facebook.com/republicaweb
¡Contribuye a este podcast!. A través de la plataforma Buy me a coffee puedes realizar una mínima aportación desde 3€ que ayude a sostener a este podcast. Tú eliges el importe y si deseas un pago único o recurrente. ¡Muchas gracias!

We’re glad you could make it this week!
With your help, we can make Pony Foo Weekly even more awesome: send tips about cool resources.
ECMAScript Modules!
|
|
|
Just React Things
|

|
|
|
|
|
...rest
...rest
|
|
|
|
![]()
Improving Cookie Consent
WhoTracksMe blog 27 11 2019

I Am Inevitable
MonkeyUser 26 11 2019
SQL is used by analysts, data scientists, product managers, designers and many others. These professionals have access to databases, but they don't always have the intuition and understanding to write efficient queries. In an effort to make my team write better SQL, I went over reports written by non-developers and code reviews, and gathered common mistakes and missed optimization opportunities in SQL.

New World
MonkeyUser 19 11 2019


Se acerca el fin del año 2019 y con ello la oportunidad de planear la próxima aplicación móvil para tu empresa, para tu negocio propio, o como parte de iniciativas para seguir aprendiendo. En este post les comparto algunas ideas de apps móviles que de acuerdo a las últimas tendencias en torno a desarrollo deberías aprender y/o implementar en 2020.
Apps móviles enfocas a VR
Las aplicaciones con virtual reality o realidad virtual son aquellas en donde con el uso de gafas o dispositivos inmersivos puedes ofrecer una experiencia 360 grados. Hoy en día para dispositivos Android hay muchas gafas de realidad virtual que no son necesariamente caras y que puedes usarlas para probar tus aplicaciones. Principalmente esta tecnología se ha usado para construir juegos que permitan tener esa nueva experiencia interactiva donde recreas un entorno virtual completo.Apps con bots
Los bots se volvieron un boom el año pasado y su uso se empezó a expandir desde entonces. Los bots como una herramienta de comunicación pueden ayudar mucho si por ejemplo, eres un negocio que desea tener para sus usuarios un apoyo constante de comunicación, sin necesariamente tener a una persona escribiendo los mensajes.Lo que me gusta de los bots es que puedes hacerlo tan inteligente como tu lo necesites, desde que solo tengas que seguir un flujo de comunicación seleccionando opciones, hasta que puedas entablar diálogos más complejos en voz o texto.
Apps para el cuidado de la salud
Las aplicaciones para medir el pulso, los pasos y distancia son hoy en día muy fáciles de construir. La mayoría de los smartphones modernos ya tienen incluidos algunos sensores que pueden ayudarte a monitorear diferentes aspectos del cuerpo, y si lo añades con las funcionalidades de un smartwatch el resultado puede ser mucho más interesante.Todas las apps enfocadas a salud tienen como objetivo que puedas activarte físicamente con recordatorios, juegos o metas para incentivarte de una forma divertida, por lo que para tener un diferenciador es necesario hacerlo lo más amigable y llamativo posible.
Apps con blockchain
Esta tecnología si bien empezó como una forma inteligente y segura para poder usar cripto monedas, hoy en día muchos proveedores hacen uso de esta tecnología para que tu puedas crear servicios y aplicaciones en donde la integridad de la información se mantenga a pesar de los cambios futuros que tenga. Si necesitas que los datos no se modifiquen o que no haya duplicidad en los mismos, la tecnología de blockchain puede ayudar perfecto a cumplir con esa premisa, y hoy ya es relativamente más fácil construir desarrollos sobre ella.Apps Realidad aumentada
Una simple aplicación de realidad aumentada que puedes ir haciendo es la del metro como instrumento de medida. Este ejemplo hace referencia a cómo integras elementos a un entorno físico para realizar alguna actividad. Muchos utilizan la realidad aumentada para juegos, pero así como el ejemplo del metro, podrías constuir apps enfocadas a brindar una herramienta que te ayude a combinar objetos físicos con virtuales.Conclusión
Estas son 5 tendencias que esperamos ver en 2020 enfocadas al desarrollo de aplicaciones móviles. Cada una representa sus retos y oportunidades, pero lo cierto es que hace un año que algunas de ellas apenas estaban siendo presentadas, era muy difícil poder construir aplicaciones reales, ya que teníamos falta de hardware o software en forma de SDKs que nos permitieran explotar estas tecnologías. En estos momentos que estamos por concluir el 2019 podemos confirmar que ya mucha de la tecnología para hacer estas apps no solo existe en tu teléfono, sino que ya hay muchísimas formas de aplicarlas para tener una app diferente con una interacción y tecnología moderna.

AI Training Datasets
MonkeyUser 12 11 2019

Introducing Koko Analytics
Danny van Kooten 06 11 2019
After stepping down from Fathom earlier this year, I was happy working on Mailchimp for WordPress for a good few months before realising that I was still thinking about how to make web analytics more private.
It dawned on me that part of why I was building Fathom in Go was because I wanted a break from WordPress and because I deemed it necessary to achieve good enough performance.
That last part might still hold true, but when choosing not to keep track of bounce rates and the time a visitor spends on a page, things become much simpler.
Add to that the following facts and an idea was born:
- Adding a third-party service to your site to keep track of your visitors will never be as private as a self-hosted service.
- The majority of WordPress users will never self-host their analytics if it’s not as easy as installing and activating a plugin.
- WordPress powers 34.9% of the internet. That’s 34.9% of the internet owning their data, despite usually not being a developer themselves.
That’s why I set out to built Koko Analytics, a privacy-friendly analytics plugin for WordPress that does not use any external services.
Metrics
Koko Analytics currently keeps track of the following metrics:
- Total site visitors
- Total site pageviews
- (Unique) pageviews for posts, pages, products, etc.
- Referrers (including a built-in blacklist to filter referrer spam)
The nice thing about running inside of WordPress is that it gives the software first-hand knowledge about what’s being tracked and allows it to offer seamless integrations, like built-in event tracking for leaving comments or any of the popular form plugins.
Performance
Most likely, you won’t even notice that Koko Analytics is there. Even when your site is getting hammered by a sudden burst of traffic.
To achieve this, the plugin uses an append-only buffer file in which pageviews are temporarily stored until they are aggregated using a background process that runs every 60 seconds.
In my tests it was able to handle well over 15.000 requests per second, meaning you don’t have to worry about being on the first page of Hacker News. PHP has really come a long way in the last few years.
Downloading the plugin
To make sure as many people as possible have access to Koko Analytics and any improvements made by me or others, the plugin is GPLv3 licensed and available for free download.
As of yesterday, you can download Koko Analytics from WordPress.org or contribute to it on GitHub.
If you’re running Koko Analytics on your WordPress site then please don’t hesitate to let me know and share your thoughts on how we can make it better.
And definitely consider leaving a plugin review on WordPress.org, because as you can see we desperately need some.
please see Python VS Common Lisp (it’s a static page you can find in the menu).

Burnout
MonkeyUser 05 11 2019
I just discovered clawk, that seems to originate from lispbuilder-clawk. Its last commit dates from 2011, typical from Lisp and that’s OK, libraries have the right to be done, it has no useful README nor documentation, but we can see its use in the tests, and the library is easily discoverable.
This library seems perfect to manipulate data in rows and columns.
Let’s have a quick look with this dummy txt file:
1 Alice 40 40
2 Bob 39 50
I had a conflict when use-ing clawk, which I resolved by not
accepting the change in the debugger.
We parse all lines, give a name to the space-delimited fields, and print them back:
(for-file-lines ("test.txt")
(with-fields ((a b c d))
($print a b c d)))
1 Alice 40 40
2 Bob 39 50
NIL
Let’s multiply the two last fields. If we use the regular * operator, we get a
type error because fields are extracted as strings by default. We then
use $*:
(for-file-lines ("test.txt")
(with-fields ((id name payrate hrsworked))
(declare (ignore id))
($print name ($* payrate hrsworked))))
Alice 1600
Bob 1950
NIL
We can change the field separator with a string or a regexp, with the
no surprising clawk:*fs* variable (FS in awk):
(for-file-lines ("test.txt")
(let ((clawk:*fs* "-"))
(with-fields ((a b c))
($print a))))
And… that’s all folks. Another tool to keep in our toolbelt.
- more about awk: https://www.gnu.org/software/gawk/manual/html_node/

I learned Java and C at school, I learned Python by myself and it was a relief. After 8 years working and doing side projects in Python and JavaScript (mostly web dev, Django/Flask/AngularJS/Vuejs), I am not satisfied anymore by the overall experience so I’m making Common Lisp my language of choice.
I am not here to compare languages themselves, but their inherent workflow and their ecosystem. This is the article I wish I had read earlier, when I was interested in Lisp but was a bit puzzled, because the Lisp way always seemed different, and I couldn’t find many voices to explain it. The Python way may not be the most practical or effective, Common Lisp might not be a dead language. I find many “workflow fixes”, overall improvements and hackerish possibilities on the CL side, even if sometimes the Python tooling is superior.
Let’s dive in.
and thanks to the proofreaders.
Table of Contents
Development process
Interactivity
In Python, we typically restart everything at each code change, we use
breakpoints: this takes some time, I find it too repetitive and boring, it requires to
re-manipulate data to re-reach the state we were at to analyze and
debug our program. We might figure out a non-standard,
more interactive way, but still: a web server needs to restart,
object instances don’t get updated after a class definition. We can get a prompt on an error (-m pdb), some tools include it (Werkzeug): a sign that it is a good thing to have. Unfortunately, it is not built-in, as in CL.
In Common Lisp, everything is much more interactive in the REPL. Even
developing web apps. On an error, we get an interactive debugger with
the stacktrace in our editor, we press v and voilà, we are at the
problematic line. We can of course catch errors to avoid the debugger, or disable it with global settings. We can resume the program execution from any stackframe. No process needs to restart. The variables
that we define on the REPL stay here. If we change a class definition
(say, we remove a field), existing instances get (lazily) updated.
The Lisp REPL is part of the development process, it is not only used for exploration and debugging. It’s fun, it’s a productive boost, and it allows to catch errors earlier, both because we try functions earlier, and because we get type warnings when we compile the file or the current function (yes, we can compile a single function).
Now, the cost is that one must learn to play with this live data. We might come to a state that doesn’t reflect the code anymore, so we’ll write our own “reset” functions or just restart the lisp image.
Here’s a video where the developer defines a dummy interface, makes it fail, develops it, and tests it, all quickly by interacting with the REPL.
Editing code
Python: we edit code line by line, paragraph by paragraph. We can try out half-backed editor plugins to edit code by semantic units. Sometimes we must even pay attention to add a couple whitespace there, remove one there. We are far from the immediate interactive feedback of the hacker’s vision “Inventing on Principles”.
Common Lisp: we edit code by semantic units. I love emacs’ lispy mode, which is weird at first of course, but so convenient. We can navigate to expressions back and forth, we can delete a whole “if” expression with a keypress, indentation is automatic, etc. There are other emacs plugins. Parinfer is appreciated in other editors too.
Actually, we edit code by parenthesis units, which doesn’t carry as much meaning as an Abstract Syntax Tree. For a real AST, we’d need a code walker (like Concrete-Syntax-Tree). But since Lisp’s syntax is based on parenthesis, in practice the experience is similar.
I had a try on writing a little plugin to help editing Python code by manipulating the AST (red4e). We first need an AST parser. There was a couple for Python 2, another one for Python 3 without type annotations, eventually one emerged a couple years later: these are signs of an unstable language and ecosystem, and it is more work required by the developer. I went the simple way by calling each function into a new Python process, which is of course too slow. traad is a better project, it can do much more but still, it’s difficult to answer questions like cross-referencing: “who calls this function” or “who does this function call”, which are built-in in SLIME. SLIME is like the Language Server Protocol for Common Lisp in Emacs, its backend Swank being editor-agnostic.
Maybe other editors and proprietary ones come with a better experience, at the cost of freedom, money, configuration time and memory and CPU resources. If I have the choice, I prefer to not go this route, and choose a better platform from the start.
Traad is built around a client-http server approach, this is the idea behind LSP… this reminds me of the architecture of SLIME! It has a backend, Swank, and a client (SLIME for Emacs, SLIMA for Atom,…). It thus has a modern architecture since its inception :) It is moreover based on a stable language whose syntax can not rot and has decades of development behind it, so we can be confident about the tool. Saying this because it’s hard to grasp what SLIME is at the beginning.
SLIME itself is tied to Emacs, and thus a newcomer can find the UI unpractical. Swank though can be used outside of Emacs, and it is for example for Atom’s SLIMA, which now has all the most important SLIME features: REPL, integrated debugger, jump to definition, autocompletion, interactive object inspection, and more.
- more: https://lispcookbook.github.io/cl-cookbook/editor-support.html (Eclipse, Lem, Jupyter Notebook,…)

Running, testing programs
Python: the default workflow is to run commands in the
terminal. Scroll, read the output, copy-paste manually (or use the
non-UX-optimal termux or a terminal inside emacs), go back to your
editor. Type commands without completion, type the whole path to a
single unit test (pytest path/to/test.py::foo), or configure your
editor and find a good plugin that is compatible with your test runner (I
can’t use the excellent nose-mode :( ).
Common Lisp: the default workflow is to do everything interactively into the REPL, but some people still use a write-compile-run approach. Consequently there is built-in completion for everything. We don’t have to use the shell (except from once in a while to run global tests or build the system) and that’s a good thing. There is an interactive debugger. We can interactively fix and re-run code and tests.
Here’s a quick demo on how to interactively fix failing tests:
Running and debugging on a remote server: in Python, we usually rsync
sources and run tests manually, or start vim/emacs under tmux on the
server. We have to kill the app to reload it. In Common Lisp, we can
connect to the running, remote instance, write changes from the
comfort of our editor locally, hit C-c C-c on a function to compile it
and see changes on the remote image. CL has more hackerish capacities
here, no doubt, and I find it attractive :)
- more information on (remote) debugging: https://lispcookbook.github.io/cl-cookbook/debugging.html
- a demo with a web app: https://lisp-journey.gitlab.io/blog/i-realized-that-to-live-reload-my-web-app-is-easy-and-convenient/
- watch Baggers working with OpenGL: https://www.youtube.com/watch?v=a2tTpjGOhjw&index=20&list=RDxzTH_ZqaFKI
- a Minecraft game engine that you can change while playing: https://github.com/gmasching/sucle
Typing
Python: we catch a lot of type errors in production, and/or we have to write a lot more unit tests. Hope we agree on this.
Now we can improve the situation somehow with type annotations, however it has the cons of being an after-thought: it is not stable (differences between Python versions), not well integrated (we have to run another command, choose between mypy, the new typing module, pyre), it is not interactive, we need to configure our IDE, it adds a start-up penalty (which might or might not be important).
In Common Lisp, particularly with SBCL, we get a lot of type errors or warnings at compile time. We can compile a single function, and thus have an immediate feedback. We’re closer (not there, just closer) to the “if it compiles, it works” situation (we know it runs, since we constantly compile and try the functions). We can also create our compound types and add type declarations to variables and functions. It’s great, though it doesn’t do as much static checks as a real typed language.
Adding type declarations in well chosen places such as inner loops also allows to gradually speed up the program where needed.
- https://lispcookbook.github.io/cl-cookbook/type.html
- Compile-time type checking in the programmable programming language Lisp
- will ML embedded into CL help even more ?
Refactoring
Python: we can’t refactor code as we want. Decorators, context managers: they have an interface and they are limited to what they offer. You can’t do things a bit differently, you must comply to the interface. That might be a feature, but I prefer not being restricted. In my experience, this leads to code repetition whereas in CL, we can refactor how we want, and we get a cleaner code.
Common Lisp: there are similar patterns than in Python, but we can escape them. We can use macros, be concise and do what we want. We can have the decorator syntax with the cl-annot library, and any other by writing our reader macros (they can bring triply-quoted docstrings, string interpolation, infix notation, C syntax…). It’s not only macros though. The polymorphism of the object system (or generic dispatch) helps, and Lisp’s “moldability” in a whole allows us to refactor code exactly how we want, to build a “Domain Specific Language” to express what we want. Other language features than macros help here, like closures or multiple values (which are different, and safer for refactoring, than returning a tuple).
Now, speaking about refactoring tools, they are better Python side. I
don’t know of a Lisp tool that allows to change all the code-base
according to the AST, maybe in a proprietary editor. There are
utilities to make local transformations, like “extract this expression
into a let variable at the top of the function”, “transform a
function to a lambda equivalent” or the contrary, etc.
(edit January, 2020: the language-agnostic tool Comby will be useful here. I used it for syntactic manipulation, for example to replace a (if (…) (progn …)) by a (when (…) …)). See Colisper (a POC).
Libraries
Library management
pip: use virtual environments (virtualenv, virtualenvwrapper, tox, anaconda,… or install per-user), pin dependencies (pip-tools, pipenv, poetry, pyupdate,…). Debug problems due to a third party library that didn’t pin its dependencies strictly enough (happens at the wrong moment).
quicklisp: think of it like Debian’s apt, shipping releases that
work together (that load together), and that we upgrade together, when we
want. If needed, we can still clone projects into
~/quicklisp/local-projects/ for a system-wide installation, or have
project-local dependencies with
Qlot.
Quicklisp is very slick. Libraries are installed at runtime, during
our REPL session. We don’t have to reload the Lisp process.
We are not even limited to Quicklisp any more (it can be limiting because of its one month release cycle). The Ultralisp distribution builds every 5 minutes. clpm is a package manager with a traditional approach. One can publish his own Quicklisp distribution, to provide a set of packages that are known to work together.
State of the libraries
CL might have more libraries than you think, see the Awesome CL list, http://quickdocs.org/ or do a quick search on the net. I know I am constantly surprised.
But sure, the Python ecosystem is huge. A few remarks on the differences:
- Quicklisp has around 1500 packages, PyPI over than 170 000. It’s hard to imagine that there are a hundred times more useful libraries :D Even in CL we have duplication of libraries with a dozen of test frameworks.
- Quicklisp is a curated distribution, PyPI is not. That means that libraries that don’t compile anymore are rejected (after a notice to the maintainers), and that orphan projects’ URL can be updated to point to a community maintained one.
- Anybody can easily publish a library to PyPI on its own. Less so with Quicklisp, one must open an issue (Ultralisp doesn’t have this limitation).
- numcl is a Numpy clone.
- if needed, you can use py4cl and more to interface with Python.
An important remark, is that Common Lisp is a stable language, and that the libraries play this game (I saw a deprecation feature staying for 12 years). We can still run code that was written in the early 90’s.
Lisp’s simpler, non-rotting syntax plays a good role on stability. Caution: that doesn’t mean the implementations don’t evolve, quite the contrary.
In his appreciated article A Road to Common Lisp, the author writes:
as you learn Common Lisp and look for libraries, try to suppress the voice in the back of your head that says “This project was last updated six years ago? That’s probably abandoned and broken.” The stability of Common Lisp means that sometimes libraries can just be done, not abandoned, so don’t dismiss them out of hand.
Templates
Ever had headaches with Jinja ? Ever fought against Django templates ? Ever abandoned to clean up a big mess of html and templating code ? Used Jinja macros to factorize code ? Maybe you turned to the good looking Jade (Pug). So you read another documentation, you install tools to integrate it into your project. And now damn, no more cross-files macros. You edit blocks of code whitespace by whitespace. And in the end, your html may still not be valid…
You might use Mako templates, but there’s something you can’t do.
In CL, we can also use a Django-like templating engine, Djula templates (despite its modest number of stars, it is one of the most downloaded projects on Quicklisp). The Mako equivalent would be Ten. However, we can alternatively just use plain old Lisp, for example with Spinneret. As a consequence, we can factorize code as we always do (with spinneret functions or lisp macros). We manipulate code as we always do. It even warns on malformed html and has some neat features (it is clever about headers levels, it can embed markdown, etc).
Stuff like this is less possible with Python, because the language is less flexible. The components libraries I have seen use strings inside Python code.
Deployment, Shipping
Shipping an app, even more a web app, in Python (and JS) is tedious. There are no default way to ship a self-contained executable. Current projects aiming at fixing that can work… and may not.
So the current solution is to turn to containers. They’re the Big Thing, but we still need to spend hours on reading resources, building the Docker file, the deployment pipeline, fixing bugs, updating the stack, accepting security holes, etc. Hours we could put on our app. With Docker though, users still can’t download a binary.
In Common Lisp: we (re)discover the joy of a compiled language. We compile our program to machine code, the binary embeds the run-time, the debugger, the web server, the static assets, and we ship it. We run it on the server and we can access it from the outside straight away.
An SBCL image of a non-trivial web project will weight ± 20 to 30MB (with core compression). For a lighter binary (not that I care personally), we could try ECL (that compiles to C), or use tree-shakers of proprietary implementations (LispWorks, Allegro).
We can still benefit from Docker if needed, of course.
Deployment process in Python: install Python and pip, install pip dependencies and their system requirements and be prepared for errors (or try non-standard tools, like Platter), configure a server for static files (nginx, whitenoise), run a WSGI web server,…
Deployment in CL: build your binary, send it to the server, run it. Configure nginx eventually. We can compile and include assets into the image (see Rock).
Performance
Python is notoriously slow, and passed the hobby project you quickly realize that.
Python has a Global Interpreter Lock.
SBCL compiles to machine code and is garbage collected [1].
We can fine-tune the types in our Lisp programs for the compiler to make the consequent optimizations. We can run in “debugging first” or in “speed first” modes. We can inline code to gain in the cost of function calls.
As a consequence, you may not need memcached in your Lisp project yet.
- https://lispcookbook.github.io/cl-cookbook/performance.html
- CL can be tuned to be faster than C
- interesting stuff: Petalisp - an attempt to generate high performance code for parallel computers by JIT-compiling array definitions. It works on a more fundamental level than NumPy, by providing even more powerful N-dimensional arrays, but just a few building blocks for working on them.
- pgloader was re-written from Python to Common Lisp for a 30x speed gain.
[1]: and rest assured, Google improves the GC
Conclusion
I hope I killed some FUD and showed you new ways to make stuff. May that inspire you!
Appendix: FAQ
Some info every Python programmer will come across eventually. Saves you some googling.
Are there no iterators ?
In practice, we mostly rely on closures, but there are libraries to create iterators.
Can I define my own + operator like in an OO language ?
By default, no, because the Common Lisp Object System (CLOS) came after the language specification and thus everything isn’t object-based. However there are libraries like generic-cl and, in practice, we quickly forget about this. Different operators is also a means for performance, good type inference and error messages.
To which extent can Lisp be compiled, with all its dynamic nature, garbage collection, macros and what else ?
Many Lisp compilers compile to machine code (SBCL, CCL, CMUCL,…).
Full answer: https://stackoverflow.com/questions/913671/are-there-lisp-native-code-compilers/914383#914383
But what is Common Lisp good for, really ?
We have a ready-to-use citation :)
Please don’t assume Lisp is only useful for Animation and Graphics, AI, Bio-informatics, B2B and Ecommerce, Data Mining, EDA/Semiconductor applications, Expert Systems, Finance, Intelligent Agents, Knowledge Management, Mechanical CAD, Modeling and Simulation, Natural Language, Optimization, Research, Risk Analysis, Scheduling, Telecom, and Web Authoring just because these are the only things they happened to list. – Kent Pitman
Kent Pitman
http://www.nhplace.com/kent/quoted.html
See also http://random-state.net/features-of-common-lisp.html
So why is CL not more popular ?
First, some reminders:
- popularity doesn’t equal quality, and popularity is hard to measure.
- some success stories: http://lisp-lang.org/success/ Aircraft analysis suits, Missile defense, ICAD, music composition, algebra systems, bulk importer for PostgreSQL, grammar checking, 3D editor, knowledge graphs,…
- did you know that pgloader was re-written from Python to Common Lisp? (for a x30 speed gain, among other benefits)
- CL was used in a spacecraft (and the REPL was used to debug the system live from the earth)
- some companies still use and pick CL: https://github.com/azzamsa/awesome-lisp-companies, companies provide professional support (Platform.sh).
- Google’s ITA Software still powers airfare search on Orbitz or Kaya.com,
- reddit v1 was written in CL! JavaScript was
writtensketched in CL! (see here, with lisp code still visible in the repository: here) - CL was number 2 on the Tiobe index for years in the 80s!
That being said, my 2 cents since you ask:
- I think the CL world missed the web bandwagon for some time (common-lisp.net was horrible for some years), but that’s been fixed.
- an enormous code-base existed before GitHub.
- we missed visually nice, practical content on the web, even though there are many books. It’s a bit better now.
- CL missed a package manager for some time behind other languages, that’s now fixed.
- I reckon CL is still quite hard for the web, it doesn’t have a killer web framework (though maybe Weblocks, CLOG or ISSR soon©, all isomorphic web frameworks), hence no hype.
- CL seems to be used for big, non-trivial projects, hence it gets no easy hype.
- CL has no entity doing marketing today. We saw the Common Lisp foundation pairing with sponsors recently. It did receive a lot of financial and institutional support from the MIT, the NASA, Xerox, Carnegie Mellon University (CMUCL), Lisp vendors (Symbolics, Lucid, Franz…),…
- CL worked well with Emacs, Vim, CCL’s built-in editor on macOs, LispWorks’ editor (which has a free version), but this doesn’t satisfy the masses. We now have more options, including Atom (very good support), VSCode (okay support) and Eclipse (basic support).
- other reasons: it may be hard (or harder than the concurrence) to grasp and getting started with, Lisp isn’t for everyone, it gets a lot of FUD, and has a so-called Lisp curse!
but that’s all debatable, I wouldn’t focus much on this. Times are good for implementations, that’s what counts.
Replic v0.12
Lisp journey 29 10 2019
We recently pushed our replic
library version 0.12, adding a couple of expected features, thanks to
the input of our users user:
- we can TAB-complete sentences (strings inside quotes)
- we can define a different completion method for each arguments of a command.
- we added a declarative way to automatically print a function’s result. The default function can be overriden by users (in order too, for example, color output).
So we can do something like this: we create a function (that will become a command on the readline command line):
(defun say (verb name)
(format t "~a, ~a !~&" verb name))
We define how to TAB-complete its arguments:
(replic.completion:add-completion "say"
(list "greetings" "\"nice to see you\"")
(lambda () *names*))
Now if you type say TAB you get the two greeting choices. After you
pick one and press TAB again, you get the names that were given to
hello.
What’s beginning to be wanted now is fuzzy completion.
Hope you enjoy.
What is replic’s goal ?
Building a readline application is cool, but readline gives you the basics and you must still build a REPL around it: loop and read commands, catch a =C-c=, a =C-d=, ask confirmation to quit, print the general help, the help of a command, setup the completion of commands, the completion of their arguments, load an init file, colorize output,… =replic= does this for you.
Replic’s goal is that when you have a lisp library, with lisp functions, it should be straightforward to create a terminal application out of it.
Here’s an example in the wild. The lyrics library is cool. It is a lisp library, it must be used on the Lisp REPL. This is the amount of code that was needed to create a terminal application out of it: https://github.com/mihaiolteanu/lyrics/pull/1/files
We often hear that Common Lisp is dynamically typed, which is not wrong, but that leads to the belief that Lisp is as bad as Python concerning types, which is plainly wrong. We don’t hear enough that CL is a compiled language, that we can add type annotations, and that SBCL does thorough type checking. Hence, what we have at hand is awesome: we can compile a whole program or compile a single function and get type warnings. Once again, the feedback is immediate. We can define our own types and get compile-time type warnings.
You use a paramater that must be a list of list of strings of length 3 ? Ok, define the type:
(defun list-of-3tuples-strings-p (list)
"Return t if LIST is a list composed of 3-tuples, made only of strings."
(and (consp list)
(every (lambda (it)
(and
(= 3 (length it))
(every #'stringp it)))
list)))
(deftype alist-of-3tuples-strings ()
`(satisfies list-of-3tuples-strings-p))
and type the variable as explained below.
It’s useful for development, it’s also great to catch errors in a
user’s configuration file. Checks are done when we load a file, and
error messages are explicit. We use this now in the Next browser.
We don’t hear a lot about all that, maybe because the information was hard to find, maybe because SBCL was not there at the time Lisp books were written. The following was published to the Common Lisp Cookbook /type.html, so hopefully the issue is solved!
On the topic, don’t miss these:
- the article Static type checking in SBCL, by Martin Cracauer
- the article Typed List, a Primer - let’s explore Lisp’s fine-grained type hierarchy! with a shallow comparison to Haskell.
- the Coalton library (pre-alpha): adding Hindley-Milner type checking to Common Lisp which allows for gradual adoption, in the same way Typed Racket or Hack allows for. It is as an embedded DSL in Lisp that resembles Standard ML or OCaml, but lets you seamlessly interoperate with non-statically-typed Lisp code (and vice versa).
Compile-time type checking
You may provide type information for variables, function arguments
etc via the macros declare and declaim.
However, similar to the :type slot
introduced in CLOS section, the effects of type declarations are
undefined in Lisp standard and are implementation specific. So there is no
guarantee that the Lisp compiler will perform compile-time type checking.
However, it is possible, and SBCL is an implementation that does thorough type checking.
Let’s recall first that Lisp already warns about simple type warnings. The following function wrongly wants to concatenate a string and a number. When we compile it, we get a type warning.
(defconstant +foo+ 3)
(defun bar ()
(concatenate 'string "+" +foo+))
; caught WARNING:
; Constant 3 conflicts with its asserted type SEQUENCE.
; See also:
; The SBCL Manual, Node "Handling of Types"
The example is simple, but it already shows a capacity some other languages don’t have, and it is actually useful during development ;) Now, we’ll do better.
Declaring the type of variables
Use the macro declaim.
Let’s declare that our global variable *name* is a string (you can
type the following in any order in the REPL):
(declaim (type (string) *name*))
(defparameter *name* "book")
Now if we try to set it with a bad type, we get a simple-type-error:
(setf *name* :me)
Value of :ME in (THE STRING :ME) is :ME, not a STRING.
[Condition of type SIMPLE-TYPE-ERROR]
We can do the same with our custom types. Let’s quickly declare the type list-of-strings:
(defun list-of-strings-p (list)
"Return t if LIST is non nil and contains only strings."
(and (consp list)
(every #'stringp list)))
(deftype list-of-strings ()
`(satisfies list-of-strings-p))
Now let’s declare that our *all-names* variables is a list of strings:
(declaim (type (list-of-strings) *all-names*))
(defparameter *all-names* "")
We can compose types:
(declaim (type (or null list-of-strings) *all-names*))
Declaring the input and output types of functions
We use again the declaim macro, with ftype (function …) instead of just type:
(declaim (ftype (function (fixnum) fixnum) add))
;; ^^input ^^output [optional]
(defun add (n)
(+ n 1))
With this we get nice type warnings at compile time.
If we change the function to erroneously return a string instead of a fixnum, we get a warning:
(defun add (n)
(format nil "~a" (+ n 1)))
; caught WARNING:
; Derived type of ((GET-OUTPUT-STREAM-STRING STREAM)) is
; (VALUES SIMPLE-STRING &OPTIONAL),
; conflicting with the declared function return type
; (VALUES FIXNUM &REST T).
If we use add inside another function, to a place that expects a
string, we get a warning:
(defun bad-concat (n)
(concatenate 'string (add n)))
; caught WARNING:
; Derived type of (ADD N) is
; (VALUES FIXNUM &REST T),
; conflicting with its asserted type
; SEQUENCE.
If we use add inside another function, and that function declares
its argument types which appear to be incompatible with those of
add, we get a warning:
(declaim (ftype (function (string)) bad-arg))
(defun bad-arg (n)
(add n))
; caught WARNING:
; Derived type of N is
; (VALUES STRING &OPTIONAL),
; conflicting with its asserted type
; FIXNUM.
This all happens indeed at compile time, either in the REPL,
either with a simple C-c C-c in Slime, or when we load a file.

Cleanup
MonkeyUser 29 10 2019
When we're developing some application we frequently interact with APIs.
There are applications like postman, httpie, insomnia and so on to accomplish this task but having an external application only to test a few endpoints or even a complex API is a little overkill.
Using emacs and a great package called restclient.el we can have a very complete tool to handle API requests without leaving our favorite editor.
Installation
Put these lines of code in your emacs configuration and you'll be ready to go.
(use-package restclient
:ensure t
:mode (("\\.http\\'" . restclient-mode)))
Here we're using use-package to install restclient.el and also we're configuring restclient to use extension .http to enable its features.
Now if we open a file with .http extension restclient will be enabled automatically.
Example api
We'll be using a example API to test the features of restclient so I prepared a little API in flask with a few endpoints to allow us to check the features of restclient.
This is the code of the application in case you are curious
from uuid import uuid4
from flask import Flask, escape, jsonify, make_response, request
app = Flask(__name__)
items = [{"uid": uuid4().hex, "name": f"item {i + 1}"} for i in range(3)]
SECRET = "password"
@app.route("/")
def index():
name = request.args.get("name", "World")
return f"Hello, {escape(name)}!"
@app.route("/api")
def api():
return jsonify({"version": 1.0})
@app.route("/api/items")
def list_items():
return jsonify({"data": items})
@app.route("/api/items", methods=["post"])
def create_item():
if authenticated(request):
new_item = {"uid": uuid4().hex, "name": request.json.get("name")}
items.append(new_item)
return make_response(jsonify({"data": new_item}), 201)
else:
return make_response(jsonify({"error": "please provide credentiales"}), 401)
def authenticated(req):
token = req.headers.get("authorization")
return token is not None and token == SECRETIf you don't want to install any other software to test this API you can use a docker image that contains this application.
Just run the following command and you'll have an API running on port 5000.
docker run -p 5000:5000 erickgnavar/restclient-api-example:0.1Now we're ready to test out API using restclient.
Usage
Let's see some examples of how can we use restclient from within emacs but first lets create a file called api.http and open it from emacs.
Make a GET request
We can execute this code using C-c C-c to show the results in the current buffer or use C-c C-v to show them in a new buffer.
GET http://localhost:5000/?name=guest
Content-Type: application/jsonResult:
Hello, guest!
<!-- GET http://localhost:5000/?name=guest -->
<!-- HTTP/1.0 200 OK -->
<!-- Content-Type: text/html; charset=utf-8 -->
<!-- Content-Length: 13 -->
<!-- Server: Werkzeug/0.16.0 Python/3.6.9 -->
<!-- Date: Tue, 29 Oct 2019 05:34:44 GMT -->
<!-- Request duration: 0.023261s -->As we can see we can define a http request in plain text. We just need to define the method and the URL of our API. In this case we're querying the root of the API. Also the response is presented in plain text including some useful data like http headers and the request duration. We can define the http request headers as well.
In this case the response use an html format as we can see in the Content-Type response header.
Note: when you create a file with many requests in it make sure you split them using a comment
#, for example:GET http://localhost:5000/?name=foo # a split GET http://localhost:5000/?name=bar # a split GET http://localhost:5000/?name=bazIf you don't add a separator an error will be raised when you try to execute the request.
JSON responses
Now lets try to fetch a json type endpoint. Restclient identifies the content-type of the response and use an emacs mode that fits with the content-type. In this case the response is a json object so restclient enable js-mode to present the response.
GET http://localhost:5000/api
Content-Type: application/jsonResult:
{
"version": 1.0
}
// GET http://localhost:5000/api
// HTTP/1.0 200 OK
// Content-Type: application/json
// Content-Length: 16
// Server: Werkzeug/0.16.0 Python/3.6.9
// Date: Tue, 29 Oct 2019 05:42:01 GMT
// Request duration: 0.025286s
Let's try with another endpoint that has more interesting information.
GET http://localhost:5000/api/items
Content-Type: application/jsonResult:
{
"data": [
{
"name": "item 1",
"uid": "931d90b493e944d9816061f46b57ce92"
},
{
"name": "item 2",
"uid": "edf9c8dda1ed4e8da205c53d9978ede2"
},
{
"name": "item 3",
"uid": "57a5146e3c98479785374f38e9e4c056"
}
]
}
// GET http://localhost:5000/api/items
// HTTP/1.0 200 OK
// Content-Type: application/json
// Content-Length: 188
// Server: Werkzeug/0.16.0 Python/3.6.9
// Date: Tue, 29 Oct 2019 05:42:33 GMT
// Request duration: 0.026217s
Variables and dynamic content
What happen if we need to pass some extra information to make an http request? In restclient we can have variables and we use them in the definition of the request. In this case we'll define a password variable which contains the required Authorization value to be able access to this endpoint. Also we can define the payload of the request, in this case a json object.
First let's try a wrong password to see what happen.
:password = wrong-password
POST http://localhost:5000/api/items
Content-Type: application/json
Authorization: :password
{
"name": "new item"
}Result:
{
"error": "please provide credentiales"
}
// POST http://localhost:5000/api/items
// HTTP/1.0 401 UNAUTHORIZED
// Content-Type: application/json
// Content-Length: 40
// Server: Werkzeug/0.16.0 Python/3.6.9
// Date: Tue, 29 Oct 2019 05:47:24 GMT
// Request duration: 0.036553s
We received a 401 response because the credentiales we used are not correct. Now let's try it again but now with the correct credentials.
:password = password
POST http://localhost:5000/api/items
Content-Type: application/json
Authorization: :password
{
"name": "new item"
}Result:
{
"data": {
"name": "new item",
"uid": "f1ede16e39754b3eb735627e78d26146"
}
}
// POST http://localhost:5000/api/items
// HTTP/1.0 201 CREATED
// Content-Type: application/json
// Content-Length: 70
// Server: Werkzeug/0.16.0 Python/3.6.9
// Date: Tue, 29 Oct 2019 05:48:15 GMT
// Request duration: 0.034962s
As we can see the request was made successfully. Variables in restclient are evaluated at the time the request is made so we can define a variable and use it in as many requests as we want. This is useful when we're working with APIs that need some authentication to allow us to access to their endpoints. We can request a token then save it and use it for the rest of the request we've defined in our file.
Other useful features
Convert request to curl format
If we need to pass a request with its data to some friend who doesn't use emacs we can pass the request definition(it's just plain text after all) but we can also generate a curl command so it's going to be easy for anyone to test the request.
We can use C-c C-u from within out request to generate a curl command. After we execute this keybinding the curl command will be copied to the clipboard.
If we use this in our previous example we'll get the following curl command:
curl -i -H Authorization\:\ password -H Content-Type\:\ application/json -XPOST http\://localhost\:5000/api/items -d \{'
'\ \ \ \ \"name\"\:\ \"new\ item\"'
'\}Now we can paste this in a terminal and the request will be made.
Navigate through the available requests
From the same author we have restclient-helm this package allow us to jump easily to a specific request using the combination C-c C-g. This is useful if we are working with an extensive API and we want to find some request quickly.
This package use helm to present the available options and when we chose one the cursor will jump to the selection.
Formatting payload
If we are using json as the request body we'll need to have it formatted in some way. We can use json-mode for accomplish this.
Now our installation code will be:
(use-package json-mode
:ensure t)
(use-package restclient
:ensure t
:defer t
:mode (("\\.http\\'" . restclient-mode))
:bind (:map restclient-mode-map
("C-c C-f" . json-mode-beautify)))
We're adding a new keybinding to restclient-mode-map so we can use C-c C-f to format the request body.
Conclusion
Having our requests defined in plain text allow us to use it even as documentation and we don't depend of some external app that use a custom format to store these requests. We can freely pass this .http file to anyone and they will be able to read it and understanding it without the need to install an application.

Everyday Excuses
MonkeyUser 22 10 2019
I've been working professionally with Elixir for 7 months, obviously using emacs as my daily editor. In this post we'll see some packages that could be useful for Elixir development.
I'm not using LSP (yet), so the goal here is just to have a minimal setup for Elixir development.
We're going to use use-package to install all the needed packages.
Syntax highlighting
We'll use Elixir-mode. This package give us syntax highlighting support and some useful features like mix-format which let us format our code using mix format task, which is available since Elixir 1.6
(use-package elixir-mode
:ensure t
:bind (:map elixir-mode-map
("C-c C-f" . elixir-format)))Go to definition
A LSP backed package like elixir-lsp could be way more accurate for this functionality but now we're going to use dumb-jump.
This package give us "go to definition" functionality just using regex. It has support for Elixir out the box and it works pretty well.
We'll use helm to show the different options when dumb-jump finds more than one definition for the same term.
(use-package dumb-jump
:ensure t
:init
(setq dumb-jump-selector 'helm))Snippets
Using snippets can improve the speed of writing code. I'm using yasnippet, a snippets template system, and also a set of snippets(for many languages including Elixir) called yasnippet-snippets.
We can install these packages with the following code. Notice that we're enabling yasnippet only for a few modes. If you want to you can enable it globally using (yas-global-mode 1).
(use-package yasnippet
:ensure t
:hook ((prog-mode . yas-minor-mode)
(conf-mode . yas-minor-mode)
(text-mode . yas-minor-mode)
(snippet-mode . yas-minor-mode)))
(use-package yasnippet-snippets
:ensure t
:after (yasnippet))Running tests
Running tests without leaving our editor is a nice feature to have in any editor/IDE. Unfortunately I haven't found any package that does this, so I wrote some elisp code to accomplish it.
To make this happen we're going to use feature called compile. Compile allows us to execute a shell command and print the resulting output in a "compilation" buffer so we can see the results.
We can run tests using mix test in different ways
-
mix test: run all the tests within our project. -
mix test path_to_test_file.exs: run the given test file. -
mix test path_to_test_file.exs:line_number: run the test defined around the given line number.
There are some other ways but these are the ones we're going to use.
(defun my/mix-run-test (&optional at-point)
"If AT-POINT is true it will pass the line number to mix test."
(interactive)
(let* ((current-file (buffer-file-name))
(current-line (line-number-at-pos))
(mix-file (concat (projectile-project-root) "mix.exs"))
(default-directory (file-name-directory mix-file))
(mix-env (concat "MIX_ENV=test ")))
(if at-point
(compile (format "%s mix test %s:%s" mix-env current-file current-line))
(compile (format "%s mix test %s" mix-env current-file)))))
(defun my/mix-run-test-file ()
"Run mix test over the current file."
(interactive)
(my/mix-run-test nil))
(defun my/mix-run-test-at-point ()
"Run mix test at point."
(interactive)
(my/mix-run-test t))
We have three functions, a "private" function called my/mix-run-test which will do all the "magic", this function will get some data about the context where it was called.
We got the current-file and current-line from where the function was called, and now we'll use this to build our shell command and then use this shell command to call compile.
Now we can create two more functions to expose two different behaviors, running an entire test file or just the test our cursor is placed on. We're going to use the latest to have a keybinding a run the test quickest.
Now we can add this to our previous code:
(use-package elixir-mode
:ensure t
:bind (:map elixir-mode-map
("C-c C-f" . elixir-format)
("C-c C-t" . my/mix-run-test-at-point)))
Now if we press C-c C-t in a file(my_test.exs) where our cursor is on line 10, emacs will build the command mix test my_test.exs:10 and run it in a compilation buffer.
Others useful packages
-
Projectile: It's a package to handle many projects. It allows us to switch between projects easily.
-
Magit: The best interface so far for use git. If you haven't use it you definitively should give it a try.
-
direnv-mode: It's a package to load environment variables using a
.envrcfile. It's useful to load all the environment variables you need for a project.
Conclusion
I use this setup with a few tweaks in my daily work and it works pretty well for my needs.

We’re glad you could make it this week!
With your help, we can make Pony Foo Weekly even more awesome: send tips about cool resources.
Expert Advice
|
|
|
|
A Mixed Bag
|
Code Things
|
|

Edge Cases
MonkeyUser 15 10 2019
![]()
We’re glad you could make it this week!
With your help, we can make Pony Foo Weekly even more awesome: send tips about cool resources.
Bleeding Edge
|
|
|
|

|
Web of Bits
|
|
|
|
Just React Things
|
|
|
|

 |
Hace tiempo que no hablamos de diseño. En este post les voy a platicar sobre 10 principios básicos que todo diseño debe tener, independientemente de donde lo veamos, creemos o imprimamos, estos 10 principios deben estar siempre visibles y saber representarse en una obra como dibujo, interfaz web, diseño web, etc. Así que comencemos 👍🏼
1. Balance
El balance se entiende como la armonía de elementos, tanto gráficos como de fuentes, colores, ilustraciones, etc. Incluso un diseño super saturado puede tener balance. Incluso el diseño más minimalista y sobrio puede tener balance, y eso depende de qué tan bien acomodamos los elementos, para que exista armonía y estructura.No significa que todos los elementos deban estar alineados o milimétricamente separados por la misma distancia, sino que a simple vista no piensen que a un diseño le faltó color, o algún elemento para rellenar, o que hay un espacio de más que no encaja.
2. Proximidad
La proximidad ayuda a crear relación entre elementos de un diseño. No se vería bien tener un campo de búsqueda en un extremo de la pantalla y el botón para buscar al otro lado, porque no tendrían proximidad.Ese ejemplo básico sirve para ejemplificar que los elementos en un diseño deben estar juntos y separados dependiendo del significado y la intención que queremos dar. Ni todo super junto, ni todo separado si no existe un significado que explique por qué tiene que ser así.
3. Alineación
Muchos diseñadores que empiezan creen que por alineación tiene que ser todo al centro o distribuido, como si pusieras tus elementos en una caja donde no pueden salir, y no hay nada más erróneo que eso. Alineación significa orden y se combina con proximidad. Hay elementos que en conjunto dan un significado y necesitan una alineación, y hay otros que no.Un ejemplo de esto es cuando en una aplicación tenemos un menú lateral. Los elementos que están relacionados estarán alineados y agrupados; aquellos que no tendrán otra alineación, posición y distribución, y no necesariamente tienen que estar desalineados.
4. Jerarquía visual
Este es uno de los elementos más importantes, ya que permite a los usuarios dirigir la mirada en lo más importante primero, y en lo secundario al final. La jerarquía implica que usen fuentes más grandes en los textos que quieres resaltar, imágenes más llamativas en donde la imagen es la principal, y todos los demás elementos como secundarios, pequeños, no tan llamativos y que aún así complemente tu diseño.5. Repetición
¿Alguna vez han visto que empiezan a definir estilos CSS para ciertos campos y al final terminando aplicando otros? este es un problema de repetición, ya que sin un estilo de colores a lo largo de un proyecto se pierde el sentido de marca.Usar la misma paleta de colores en todo el diseño, o en un sitio web es primordial para mantener consistencia, de tal forma que ese botón azul con borde redondeado lo identifiques en todas las páginas de tu sitio, y no te confundas con otro que tiene otra forma y color.
6. Contraste
Hemos hablado mucho del contraste en el blog. Sin contraste no sabríamos diferenciar elementos del fondo, texto como cabecera de texto de párrafo, o de ilustraciones entre sí. Siempre recuerda tener contraste, no solo a nivel de blanco-negro, sino de diferentes colores, formas y fuentes que permita que no exista un resalte, una duda o una interpretación que implique gastar la vista.7. Color
En colores hay toda una ciencia de cómo escoger una gama de colores. No es tema de este post pero los puntos importantes son:- no uses más de dos o tres colores para un diseño
- usa tonos de grises
- usa una paleta de colores usando alguna aplicación de combinación de colores
- trata de ver combinaciones nuevas, no uses siempre las mismas
8. Espacio negativo
El espacio negativo se usa cuando jugamos con las siluetas de otros elementos para crear más elementos. No es un recurso que deberíamos explotar demasiado pero sí lo suficiente para que el usuario se sorprenda al identificar por sí mismo la figura escondida9. Tipografía
La tipografía es super importante para cada diseño, y por lo tanto necesita una tipografía específica para ello. Evitemos usar las que vienen por defecto en nuestra computadora. Las fuentes que puedes encontrar en internet de forma gratuita son ideales para crear textos llamativos pero no muy originales, y las que tienes que pagar son las que son perfectas para crear toda una colección e identidad para el diseño.10. Estilo propio
Ya que conoces todos estos principios, entonces ya puedes buscar tu propio estilo, combinando, creando y ajustando todos los principios anteriores a algo que siga manteniendo un diseño bueno. El estilo propio es lo que eventualmente muchos lanzan como lenguaje de diseño, estilos, temas, y todo lo que puedas relacionar a nivel de diseño para un sitio, aplicación, campaña de publicidad, y muchas cosas más.

S3cur1ty
MonkeyUser 08 10 2019

Today we’re launching Instapaper Save for Safari on Mac. You can download it now from the Mac App Store.

Once you’ve downloaded the app, you can set up the Safari extension as follows:
- Open the app
- Login with your account
- After you’re logged in, click “Open Safari Preferences”
- Enable “Instapaper 1.0” in the Extensions tab of Safari Preferences
In order to make the updated Safari extension available as soon as possible, this version of the extension only supports saving by clicking the Instapaper toolbar icon in Safari. In future versions we plan to add:
- Inline Twitter link saving.
- Right-click to save links or pages.
- Keyboard shortcut to save.
- An extension to save links from other macOS apps.
If you have any questions, feature requests, or issues you’d like us to sort out, please let us know at support@instapaper.com or @InstapaperHelp on Twitter. Thanks for using Instapaper!

Product Description
MonkeyUser 01 10 2019
SQL injection attacks are constantly ranked among the most common attacks against systems. While binding values is very common, I often find my self needing to being table and column names as well. This article will walk you through everything you need to know about SQL injections in Python.

Es difícil escribir un script de python que no interaccione con el sistema de ficheros de un modo u otro, por lo que python dispone de varios módulos para tal fin: os, os.path (submódulo de os), shutil, stats, glob,…En la intención estaba ser multiplataforma, lo que ha sido fuente de muchos mayores quebraderos de cabeza con las distintas codificaciones de caracteres y distintas formas de expresar rutas de ficheros que existen.
El objeto Path viene a poner orden entre tantos módulos y funciones para manejo de ficheros. La librería estándar se ha reescrito para aceptar estos objetos Path. Se puede decir sin duda que usar Path se ha convertido en la forma más pythónica de manipular ficheros y directorios.
Empecemos por un ejemplo traído de la documentación oficial:
>>> from pathlib import Path
>>> p = Path('/etc')
>>> q = p / 'init.d' / 'reboot'
>>> q
PosixPath('/etc/init.d/reboot')
>>> q.resolve()
PosixPath('/etc/rc.d/init.d/halt')
Paso por paso: importa el constructor Path del módulo pathlib. Con él construye un objeto con la ruta /etc y, usando el operador /, genera otro objeto que representa la ruta /etc/init.d/reboot. Automáticamente, estos objetos se construyen como instancias de PosixPath, que es una subclase especializada de Path para manejos de ficheros en sistemas Posix. La ruta /etc/init.d/reboot apunta a un enlace simbólico, por lo que se usa el método resolve para obtener la ruta absoluta del fichero al que apunta.
Nota
Observa que las operaciones con objetos Path generan objetos Path con lo que podemos encadenar operaciones para navegar a través de una jerarquía de directorios.
Módulos a los que sustituye o no sustituye
Obviamtente, el módulo clásico os.path, utilizado para manipulación de rutas, es reemplazado totalmente por pathlib.
Del módulo os reemplaza muchas de sus funciones para manipular ficheros y directorios. Aún así, el módulo os contiene otras muchas funciones para el manejo de entornos o lanzamiento de procesos que no cambian. Así mismo, hay algunas operaciones especializadas con ficheros y directorios (eg: os.walk) que no han sido reempladas. De hecho son más eficientes que si se hicieran con objetos Path.
Otro módulo que ya no es necesario es glob, utilizado para buscar ficheros mediante patrones de búsqueda.
Rutas puras y concretas
Según si tienen acceso al sistema de ficheros, podemos distingure entre:
- Ruta pura: rutas que no requieren acceso al sistema de ficheros (
PurePath,PurePosixPath,PureWindowsPath) - Ruta concreta: rutas con acceso al sistema de ficheros (
Path,PosixPath,WindowsPath)
Las rutas puras son superclases de las rutas concretas. Mejor verlo gráficamente como jerarquía de clases:
Ejemplos
Voy a poner algunos ejemplos de uso de pathlib para que compares con el modo como lo estabas haciendo hasta ahora. Recomiendo revisar la documentación del módulo pathlib ante cualquier duda.
Para escribir en un fichero, usamos el método open de modo similar a como se hacía con la función open del mismo nombre:
from pathlib import Path
path = Path('.config')
with path.open(mode='w') as config:
config.write('# config goes here')
Si sólo vamos a escribir una línea, también se podría hacer de un modo más directo:
Path('.config').write_text('# config goes here')
Pongamos un ejemplo más complejo: queremos localizar los scripts de python dentro de la carpeta proyectos que tengan una frase. Lo habitual para recorrer un directorio era usar alguna función como os.walk o os.scandir para ir navegando a través de la jerarquía de directorios e ir leyendo los ficheros python hasta localizar los que buscamos.
Veamos cómo se hace con Path:
from pathlib import Path
proyectos = Path.home() / 'proyectos' # carpeta en el directorio HOME
palabra = "pathlib"
ficheros = [p for p in proyectos.rglob("*.py")
if palabra in p.read_text()]
Partimos del Path.home(), el directorio de usuario, y creamos la ruta del directorio proyectos. Invocando el método .rglob() obtenemos, recursivamente, todos los ficheros que cumplan con el patrón dado. Bastante simple.
La lista resultante es una lista de objetos Path, lo que nos facilita cualquier manipulación posterior que deseemos hacer sobre estos ficheros. Por ejemplo, vamos a calcular el tamaño total que ocupan:
size = sum(p.stat().st_size for p ficheros)
Si se prefiere, se puede seguir usando el viejo os.path.getsize. Ahora también acepta objetos Path:
import os.path
size = sum(os.path.getsize(p) for p ficheros)


Today we launched Instapaper 7.8 for iOS 13. In the new version, dark mode will automatically turn on when you enable dark mode at the system level through iOS Settings > Display & Brightness > Dark mode. Disabling dark mode will return Instapaper to your non-dark mode theme. If you set your device to automatically go into dark mode, Instapaper will mirror the transition.
Additionally, we rewrote the article list to improve scroll performance, especially during large volume syncs. You should now see smoother scrolling in general, and especially while content is downloading.
Lastly, we’ve expanded the “Tweet Shot” feature to be compatible with apps beyond Twitter. With the new “Share Image” option, you can now share an image of your highlight or text selection to any app (including Twitter, of course).

If you have any questions, feature requests, or issues you’d like us to sort out, please let us know at support@instapaper.com or @InstapaperHelp on Twitter. We love hearing from you and we thank you for using Instapaper!
We’re glad you could make it this week!
With your help, we can make Pony Foo Weekly even more awesome: send tips about cool resources.
Raw Performance
|
|
|
Perf Profiling
|

|
|
|
|
Even more stuff
|
|

v2.0.1
MonkeyUser 24 09 2019
Reddit: ABCL Common Lisp vs Clojure
Lisp journey 22 09 2019
Not that I’m interested in using the Java platform :D but relevant comparisons between ABCL (Common Lisp on Java) and Clojure are rare. We just had a nice feedback on reddit, so here it is. The question was:
After looking at the quite old benchmarks, ABCL seems to perform alright. Can anyone share their experience with ABCL in terms of performance, stability and memory usage?
I wish I could give you more concrete numbers with an application you could test and see for yourself. Since I can’t do that, I will tell you about my recent work with ABCL. I ported a small Clojure server-side utility to ABCL and can qualitatively tell you that the performance was close to Clojure. After profiling the ABCL version, I believe I can attribute the differences to ABCL’s use of Java reflection for its Java FFI.
I’ve already been successfully deploying Clojure-based applications professionally, and as I’ve gotten more into Common Lisp, I’d like to start deploying Common Lisp based applications as well. I recently posted a patch to the ABCL mailing list and got a very quick response from the maintainer. I really like the quality of the ABCL code base. The compiler itself was very approachable and easy to understand.
I think ABCL really is a worthwhile target in the Common Lisp world because:
- Painless Java FFI. You avoid all the instability and signaling issues that crop up when using the JVM combined with SBCL or CCL. If you make a lot of calls, native Java is always going to be faster anyhow than calls over JNI (which is more comparable to reflection).
- Use large heaps without worry. Part of the benefit of the JVM is its proven ability to have huge heaps (I’ve been part of projects that had 64GB+ heaps (though honestly I’d rather stay small)).
- JVM platform is well supported and tested on a number of OS and hardware platforms
SBCL uses conservative garbage collection and I’m curious how well it would handle really large heaps. CCL uses precise garbage collection but again, I’d like to know how it handles really large heaps. In general, I want all my applications to run with heaps that are naturally in CCL’s or SBCL’s sweet spot, but I’d love to know I could use ABCL if I really ever needed huge heaps. I’m really getting into Common Lisp because I really like the implementation choices. Having a solid Java FFI unfortunately is usually a requirement in my workplace.
To me, ABCL will be /better/ than using Clojure if ABCL’s Java FFI moves away from reflection (when possible). This will close any performance gap with Clojure for most applications. I think this can be done relatively easily in the current ABCL implementation, and I have an idea of how to do it but unfortunately have had no time lately to devote to it. The reason I say “better than Clojure” is that I can write applications that target both ABCL and SBCL/CCL – I can abstract away my Java APIs if I really have to have them (or use LispWorks with a solid Java FFI if I don’t need a ton of Java interoperability). Then when I need fast startup time or low memory footprint, I can use these other CL implementations which are much better suited to it.
The main benefit where I still see Clojure having an edge is if you need a heavy JS-based web interface. I’m not a JS developer, but I was able to successfully use Clojurescript and make a nice looking web application that had pretty seamless interoperability with my Clojure-based server.
Anyhow, I hope this helps you. ABCL is great, I have been very impressed with it and I encourage you to try it out.
by the user somewhat-functional on reddit, september 2019

Tribalism
MonkeyUser 17 09 2019
Inspired by an actual incident we had in one of our systems caused by an "Export to Excel" functionality implemented in Python, we go through the process of identifying the problem, experimenting and benchmarking different solutions.


Cuando se trata de programación no hay una forma o estándar a seguir para poder desarrollarse y madurar. Solo la experiencia te da más herramientas dentro de este mundo de programación, pero también hay actividades que puedes realizar para poder ir ganando más experiencia y seguir mejorando como desarrollador, y en este post te los voy a compartir.
Experimentar en varios proyectos
Puede sonar lógico que para poder ser un mejor desarrollador lo primero que tienes que ahcer s practicar, desarrollar proyectos, estar involucrado en varios, de tal forma que en cada uno aprendas algo diferente. Sin embargo aquí hay algunos puntos que deberías estar teniendo en cuenta al momento de tener proyectos para poder ser un mejor desarrollador
- Tienes que fallar para aprender: el terminar un proyecto sencillo no te da ningún aprendizaje. Aprende con el error y sabiendo tus capacidades técnicas
- Aprender significa tener creatividad: programar de la misma forma y haciendo las mismas aplicaciones no te dejan ninguna experiencia. Juega a hacer las cosas de diferentes formas para saber si lo que actualmente haces es la forma más adecuada o hay alguna mejor.
- Aplica los métodos paso a paso: ¿cuándo fue la última vez que seguiste todo un ciclo de desarrollo para una aplicación? cosas tan sencillas como esas las obviamos y nos vamos directo a programar y ver en el camino qué nos falta. Intenta ir lento, siguiendo la teoría, y verás que de la misma forma que buscas soluciones a tu código, vas a querer soluciones a situiaciones en las etapas.
Planea antes de programar
Como lo mencionaba anteriormente, solemos emepezar a programar sin siqueira estar seguros de lo que queremos lograr. La planeación es una etapa en la que tienes que poner bien los alcances de lo que vas a hacer, y el resultado que quieres obtener. Si solo empiezas a programar no vas a saber cuándo terminar, o al final no vas a recordar por qué empezaste ese prioyecto.
Sé duro con tu código
La mejor forma para mejorar como programador o desarrollador es siempre ser auto críticos con nuestro código. Si le presentaras tu código a algún desarrollador experto o con muchos años de experiencia, reconocido entre una comunidad ¿qué crees que diría de él? ¿qué es código de calidad? ¿o que es código de principiantes?
Siempre debemos buscar los patrones o mejores prácticas para nuestro código. Hay muchas metodologías y dependiendo del lenguaje irás aprendiendo si la técnica de programación que tienes es buena o mala, y a partir de ahí ver cómo la puedes mejorar.
Lee código de desarrolladores respetados
Es un punto adicional a lo que comentaba anteriormente. No hay nada mejor que ponerte al tú por tú contra un desarrollador que sea realmente bueno. Basta incluso con ver las librerías de organizaciones o comunidades Open Source y ver si entendemos el código que muestran, y después, validar si nuestro código es de la misma calidad.
En Github puedes encontrar desarrolladores que postean sus proyectos personales o de colaboración con otros, y medirte para ver qué tan bueno eres comparado con ellos.
Aprende a 'debuggear' código que no es tuyo
Si trabajas para una empresa que desarrolla proyectos a clientes esta es una de las situaciones más comunes que vas a vivir, y es la de heredar proyectos que alguien más hizo. Los más novatos dirán que ahorras tiempo si vuelves a hacer todo desde cero, pero lo cierto es que es al revés. Aprender a leer, debuggear y probar código de alguien más es una de las mejores experiencias (dolorosas, lo sé) que te puede ayudar para ser un mejor desarrollador, porque ahí pones en práctica qué tan bien lo harías tu, o qué tan mal dejaron ese código heredado.
Siempre trata de romper tu código
Los que empezamos a programar nos preocupamos más porque nuestro código funcione en el escenario ideal, a probar los escenarios donde no. Un código de calidad no es el que cumple su funcionamiento, sino que también responde ante entradas de datos erróneas, ante desbordamientos, ante escenarios extremos o nulos de datos, etc.
Conclusiones
Estos son algunos tips que puedes poner en práctica en tu día a día sin tener que invertir tiempo en cosas que no sean tareas comunes de cualquier desarrollador, solo necesitas la actitud y disposición para poder ejercerlas.


He estado jugando con Docker para crear algunos servicios, y sobre todo, evitar tener que descargar e instalar plataformas que solo quiero usar de prueba. En mi último demo estuve jugando con MongoDB y se me ocurrió hacer un tutorial para enseñarles a configurar MondoDB en Docker para crear una conexión con NodeJS y ExpressJS.
Prerequisitos
Para poder seguir este tutorial se necesitan tener bases de cómo funciona NodeJS y ExpressJS, así como algo muy introductorio a Docker y Dockerfile, pero ya lo iré explicando.1. Creación de Dockerfile
Una de las maravillas que ofrece Docker es la posibilidad de preparar todos los componentes que necesitas para tu desarrollo en un editor de texto y de ahí ejecutarlo. Yo para poder montar MongoDB voy a necesitar dos servicios:- El motor de bases de datos de MongoDB
- Una interfaz web para administrar visualmente mis bases de datos. En este caso uso Mongo Express
version: '3.1'
services:
mongo:
image: mongo
container_name: mongodb
restart: always
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: example
MONGO_INITDB_DATABASE: ejemplodb
ports:
- 27017:27017
mongo-express:
image: mongo-express
restart: always
container_name: mongodb-ui
ports:
- 8081:8081
environment:
ME_CONFIG_MONGODB_ADMINUSERNAME: root
ME_CONFIG_MONGODB_ADMINPASSWORD: example
Una vez hecho eso procedemos a correr el comando
docker-compose up
2. Configurar aplicación de NodeJS y ExpressJS
Ahora vamos a crear nuestra conexión desde nuestra aplicación de NodeJS usando Express. Lo primero es installar Expressnpm install express
npm install mongoose
const express = require('express');
const bodyParser = require('body-parser');
const cors = require('cors');
const mongoose = require('mongoose');
const PORT = 3000;
const app = express();
app.use(cors());
app.use(bodyParser.json());
app.get('/', (req, res) =>{
res.send('Index');
});
app.listen(PORT, () =>{
console.log('Servidor backend listo...');
});
- Incluir los módulos que vamos a ocupar
- Inicializar nuestro middleware, el cual puedes o no ocupar para tu aplicación
- inicializar un ruteo para cargar nuestro index
- configurar el puerto para escuchar peticiones
3. Conexión a MongoDB
Vamos a empezar con la conexión a nuestra base de datos:mongoose.connect('mongodb://localhost/basededatos', {useNewUrlParser: true, useUnifiedTopology: true});
const connection = mongoose.connection;
connection.once('open', () =>{
console.log('Conectado a la BD');
});
Algunos errores comunes
Al menos a mi en un principio traté de usar la conexión de este formamongoose.connect('mongodb://user:pass@localhost/db', {useNewUrlParser: true, useUnifiedTopology: true});
UnhandledPromiseRejectionWarning: MongoError: Authentication failed
Para ello nos conectamos a nuestra consola de mongo en Docker
docker exec -it mongodb mongo -u root
Ya dentro de nuestra consola de Mongo, vamos a ir a ejecutar la siguiente función para crear un nuevo usuario
use tu-base-de-datos
db.createUser({
user: 'user',
pwd: 'pass',
roles: [
{ role: 'readWrite', db: 'tu-base-de-datos' }
]
})
mongoose.connect('mongodb://user:pass@localhost/db', {useNewUrlParser: true, useUnifiedTopology: true});

Determinism
MonkeyUser 10 09 2019


Hoy en día manejar promesas es una de las actividades que necesitas hacer para poder programar aplicaciones mucho más robustas y limpias visualmente. En este tutorial vamos a ver una introducción a las promesas, para qué sirven y cómo nos ayudan en nuestro día a día como programadores.
¿Qué son las promesas?
Las promesas son una forma de poder implementar código, el cual se ejecute después de evaluar si una condición esperada es verdadera o salió algo mal. Muchas de las operaciones donde vamos a implementar promesas es en operaciones asíncronas, donde no sabemos cuando va a terminar una actividad, y por eso las promesas nos ayudan a evaluar si dicha operación asíncrona fue exitosa o falló.¿Cómo se implementan?
En Javascript vamos a usar la siguiente notación para crear una nueva promesa:Al definir una promesa debemos tomar en cuenta los dos parámetros que aparecen ahí, ya que son los que vamos a usar posteriormente en la implementación para mandar a llamarlos. Esos dos parámetros actúan como placeholders que van a invocarse cuando nosotros programemos que nuestra promesa tuvo éxito al ejecutar su actividad, o cuando hubo algún error.
Para un ejemplo muy sencillo podemos evaluar el valor de una variable. Si la variable cumple nuestra condición vamos a invocar a resolve() como función. Dentro de ella podemos colocar valores que queramos pasar para cuando se invoque nuestra promesa.
Por último, para mandar a llamar a nuestra promesa basta con ejecutar el método .then(), una vez hecho esto dentro podemos hacer referencia al valor que pasamos en la función de resolve() y con ello implementar una función. Si llegase a fallar nuestra promesa podemos usar el método .catch() para poder implementar una función de error
Al final, nuestro código completo se vería así:
Conclusiones
Las promesas en su mínima expresión son una forma muy poderosa de sustitución a los callbacks, además de que nos permiten definir la promesa y luego implementarla de forma muy ordenada sintácticamente. Más adelante vamos a ver otros usos más completos y avanzados ya poniendo en práctica otros temas de Javascript

Gut Feeling
MonkeyUser 02 09 2019

Applied Scrum
MonkeyUser 27 08 2019
Slime Tips
Lisp journey 26 08 2019
Recently on reddit there was a reminder about lisptips.com and slime-tips. I already knew the two, but this time I fully enjoyed the Slime tips. I copy my favourites.
As usual, I enhanced the Cookbook/emacs-ide.html at the same time.
The Slime documentation is here: https://common-lisp.net/project/slime/doc/html/
Documentation lookup
- C-c C-d h looks up documentation in CLHS. But it works only on symbols, so there are two more bindings:
- C-c C-d # for reader macros
- C-c C-d ~ for format directives
Other bindings which may be useful:
- C-c C-d d describes a symbol using
describe - C-c C-d f describes a function using
describe
Synchronizing packages
C-c ~ (slime-sync-package-and-default-directory): When run in a buffer with a lisp file it will change the current package of the REPL to the package of that file and also set the current directory of the REPL to the parent directory of the file.
Calling code
C-c C-y (slime-call-defun): When the point is inside a defun and C-c C-y is pressed,
(I’ll use [] as an indication where the cursor is)
(defun foo ()
nil[])
then (foo []) will be inserted into the REPL, so that you can write
additional arguments and run it.
If foo was in a different package than the package of the REPL,
(package:foo ) or (package::foo ) will be inserted.
This feature is very useful for testing a function you just wrote.
That works not only for defun, but also for defgeneric, defmethod, defmacro, and define-compiler-macro in the same fashion as for defun.
For defvar, defparameter, defconstant: [] *foo* will be inserted
(the cursor is positioned before the symbol so that you can easily
wrap it into a function call).
For defclass: (make-instance ‘class-name ).
Inserting calls to frames in the debugger
C-y in SLDB on a frame will insert a call to that frame into the REPL, e.g.,
(/ 0) =>
…
1: (CCL::INTEGER-/-INTEGER 1 0)
…
C-y will insert (CCL::INTEGER-/-INTEGER 1 0).
(thanks to Slime tips)
Exporting symbols
C-c x (slime-export-symbol-at-point) from the slime-package-fu
contrib: takes the symbol at point and modifies the :export clause of
the corresponding defpackage form. It also exports the symbol. When
called with a negative argument (C-u C-c x) it will remove the symbol
from :export and unexport it.
M-x slime-export-class does the same but with symbols defined by a structure or a class, like accesors, constructors, and so on. It works on structures only on SBCL and Clozure CL so far. Classes should work everywhere with MOP.
Customization
There are different styles of how symbols are presented in
defpackage, the default is to use uninterned symbols (#:foo).
This can be changed:
to use keywords:
(setq slime-export-symbol-representation-function
(lambda (n) (format ":%s" n)))
or strings:
(setq slime-export-symbol-representation-function
(lambda (n) (format "\"%s\"" (upcase n))))
Crossreferencing: find who’s calling, referencing, setting a symbol
Slime has a nice cross referencing facility, for example, you can see what calls a particular function or expands a macro. It presents a list of places which reference a particular entity, from there you can recompile the thing which references by pressing C-c C-c on that line. C-c C-k will recompile all the references. This is useful when modifying macros, inline functions, or constants.
The following bindings are also shown in Slime’s menu:
- C-c C-w c slime-who-calls callers of a function
- C-c C-w m slime-who-macroexpands places where a macro is expanded
- C-c C-w r slime-who-references global variable references
- C-c C-w b slime-who-bind global variable bindings
- C-c C-w s slime-who-sets global variable setters
- C-c C-w a slime-who-specializes methods specialized on a symbol
And when the slime-asdf contrib is enabled,
C-c C-w d slime-who-depends-on lists dependent ASDF systems
And a general binding: M-? or M-_ *slime-edit-uses** combines all of the above, it lists every kind of references.
Monitoring and controlling threads with Slime
M-x slime-list-threads (you can also access it through the slime-selector, shortcut t) will list running threads by their names, and their statuses.
The thread on the current line can be killed with k, or if there’s a lot of threads to kill, several lines can be selected and k will kill all the threads in the selected region.
g will update the thread list, but when you have a lot of threads
starting and stopping it may be too cumbersome to always press g, so
there’s a variable slime-threads-update-interval, when set to a number
X the thread list will be automatically updated each X seconds, a
reasonable value would be 0.5.

Platypuscorn
MonkeyUser 20 08 2019

Brittle
MonkeyUser 13 08 2019
Getting the last value of a group in an aggregated query in PostgreSQL is a challenging task. In this article we present a simple way to get the first or last value of a group using group by.


1. Resalta atributos importantes
Este es el primer consejo. Cuando construimos sitios interactivos es fundamental saber qué atributos debemos resaltar como por ejemplo el precio de la opción que más recomendamos a los usuarios, o características que no tienen las demás opciones. Esto es para que el usuario tenga presente esas cualidades y que al momento de tomar su decisión siempre recuerde las características resaltadas.
2. El problema del contenido
Las tablas comparativas no deberían tener mucho contenido por celda, pero tampoco debería haber celdas sin contenido, ya que esto hace ver a la tabla vacía. Lo importante es siempre acotar el contenido con características puntuales, y si es posible poner un link a otra sección para explicar mejor. Las opciones donde no haya contenido que poner, ya sea porque esa opción o columna no tiene características de los demás niveles, siempre es preferible poner que no existe, no aplica, o alguna marca que indique que ese campo es vacío. Este tema afecta mucho al usuario ya que si no ve nada en la celda pensará que faltó ponerle contenido o lo dejará con la duda de si aplica o no.
3. Agrupa atributos
Una forma visual de poder navegar en una tabla comparativa es con el uso de grupos, o cabeceras, para que si tu tabla va a tener muchas filas de contenido, mejor las agrupes y el usuario pueda consultar aquellos atributos que le son más interesantes en ese momento.
4. Resalta de acuerdo a la necesidad
Una forma más dinámica para una tabla comparativa puede ser resaltar atributos que busque el cliente, por ejemplo, el producto más barato, o el que tiene más beneficios, o el más popular. No hagamos solo estático el resaltado de atributos, sino que también démosle al usuario la oportunidad de tener varios resaltados.
5. Mantén un balance en el diseño
Lo más simple siempre va a ser mejor. Las tablas comparativas no deberían tener simbologías complejas, detalles o links adicionales, solo los atributos importantes, las imágenes y resaltados fundamentales para que haya un balance entre la tabla y el contenido. Recuerda que al final el usuario solo quiere comparar de un vistazo dos productos o servicios, no hace falta complicar mucho el diseño.
6. Haz tu tabla fácil de compartir
Sobre todo en productos donde el precio es considerable siempre ten en mente que alguien va a sacar un screenshot en su computadora o pantalla, por lo que trata de mantener una tabla libre de scrolls, de paneles colapsables o de tablas muy grandes que no permitan tener en una pantalla mediana o pequeña la comparación. Si es posible trata de tener esa misma tabla en formato de imagen para que peuda ser compartida en las redes sociales.
7. No uses muchos colores para resaltar
Basta con tener un solo color para resaltar los puntos importantes de una tabla comparativa. El uso exagerado de colores para resaltar, o un esquema complejo para identificar similitudes y diferencias solo hará que el usuario busque comparar en otro sitio o simplemente la decisión de comparar tus productos y servicios se extinga.
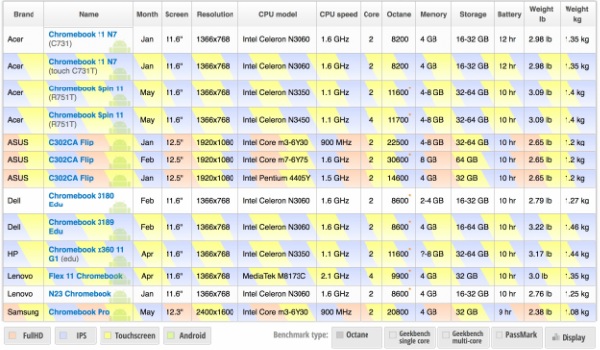
Vía line25

_
MonkeyUser 06 08 2019
Have you ever stopped to think what staff user can do in your Django admin site? Did you know staff users with misconfigured permissions on the user model can make themselves superusers? Permissive permissions to staff users can cause disastrous human errors at best, and lead to major data leaks and at worst.

The Superficial High
MonkeyUser 30 07 2019


Entrar al mundo de la programación puede ser sencillo o muy difícil dependiendo del contexto de la persona. De hecho, creo que aunque hoy hay muchísma más información que hace cinco años, la dificultad todavía es un poco elevada para alguien que nunca ha estado en contacto con el mundo de la programación, especialmente si se adentra directo en ella. En este post les voy a compartir algunas ideas de lo que me hubiera gustado conocer cuando empecé con la programación, que tal vez a ti si te sirvan y con eso puedas tener una curva de aprendizaje mucho más rápida en menos tiempo.
- No necesitas un grado universitario para ser desarrollador, pero sí necesitas tener conocimientos de ingeniería
- La programación no solo es resolver problemas, sino también usar la creatividad para poder encontrar diferentes formas de resolver problemas
- No puedes aprender todo sobre programación, es imposible, pero sí puedes aprender cosas básicas que te pueden servir en cualquier momento, todas las áreas de la programación comparten cosas similares, y cada una ofrece algo más específico.
- Date un descanso en la programación, no es cierto que tengas que estar horas en la computadora para ser mejor, requiere esfuerzo pero no dejar tu vida personal
- Programar es acerca de entender conceptos y aplicarlos, no de memorizar código, nadie que intente memorizar código puede ser considerado un programador
- Siempre habrá alguien que sepa más que tu, y es normal, pasa con todas las áreas de estudio, lo importante es que tu sepas lo que necesitas aprender y lo aprendas.
- No seas adicto a la programación, sal, juega, ten una relación; que ser programador no sea lo primero, sino lo que te complementa después de tener una vida propia
- Aprenderás a programar si te pones retos contigo mismo, es decir, si te pones objetivos de programas, funciones, o ciertas cosas que necesitas hacer en un determinado tiempo (y que sea técnicamente realista)
- Al contrario de lo que dicen, no es 100% cierto que necesites saber matemáticas para ser buen programador, como lo dije antes, hay diferentes áreas de aplicación, y no todas requieren que seas bueno, pero sí que conozcas las operaciones básicas de suma, resta, multiplicación y división.
- No necesitas ponerte un estereotipo de novato en programación, hay mucha gente que puede saber otros lenguajes y no uno específico, y no por eso se considera novato, simplemente estás aprendiendo.
- Trata de terminar tus proyectos, porque de esa forma podrás llegar a un objetivo inicial, que es terminar algo.
- Te traumarás eventualmente por encontrar el error que evita que funcione tu programa correctamente, y es algo normal
- Es normal que busques en internet cómo se hace determinada cosa para tu programa, como dije, no es buen programador el que memoriza, sino el que usa lo sabe para programar mejor, y buscar es una buena habilidad
- Necesitas no solo programar sino también guiarte en prácticas recomendadas, inicia tu vida de programador también aprendiendo los consejos de patrones de diseño de programación
- Una obsesión más será el poner nombres correctos a tus variables y funciones, es totalmente normal y siempre pensarás que pueden llamarse de otra forma
- Un trauma común es programar con nombres en inglés o español, o si es deEstaForma o de_esta_otra_forma, cualquiera de las opciones es válida, lo importante es que tu código sea entendible
- Es bueno darse por vencido, porque en algún proyecto puede que veas que necesitas otros conocimientos para terminar esa parte que te faltaba. De aquí en adelante si lo que deseas es seguir aprendiendo, hazlo y vuelve a interntarlo
- Si ves que un programa ya se hizo muy elaborado o complicado vuelve a empezar desde cero, eso te dará la oportunidad de volverlo a hacer de otra forma, y no tratar de arreglar algo que quizá ya no tiene solución
- Cuando estés programando te empezarás a preguntar si lo que haces es la mejor forma de hacerlo, no pierdas esa curiosidad
- Programar por gusto no es lo mismo que trabajar en programar. Lo primero te va a encantar, y lo segundo no, pero es algo que tienes que identificar para no odiar la programación
- Es completamente normal no pasar una entrevista técnica de programación, mas si nunca has practicado problemas de lógica realmente difíciles
- Siempre creete que eres bueno, pero no lo suficiente para perder el piso y creer que nadie puede contra ti
- Habrá quien te diga que lo que haces está mal, pero si no te ayuda a mejorar puedes hacer caso omiso de esos comentarios
- Trata de buscar programadores que admires, porque de esa forma querrás tener una visión de ti mismo en un futuro
- Siempre es difícil trabajar en equipo para un proyecto, porque no es la misma técnica para todos, pero trata siempre de demostrar por qué deberían hacer las cosas de cierta forma
- Si revisas después de un año el código de algún proyecto, te vas a dar cuenta que pudo haber sido mejor, toma ese feedback y aplícalo en el siguiente proyecto que hagas
- Siempre tenemos un momentum, ese instante donde a pesar de que ya quieres terminar algo no te deja descansar. Si te pasa eso es que realmente te gusta la programación, pero evita que pase seguido
- Odiarás y amarás los hackatones porque te permite ponerte a prueba contra el tiempo, pero te dolerá si lo tuyo no es la presión
- No todo va a ser copiar código de páginas como Stack overflow, también necesitas entender el por qué de una solución que buscas
- La programación con música es mucho mejor, inténtalo
Clojure Forum
Clojure News 25 07 2019
We are pleased to announce today a new forum for Clojure and ClojureScript users: https://ask.clojure.org. You can ask questions, discuss possible problems, request enhancements, and vote on questions and answers.
The new forum was seeded with all of the open JIRA issues, one question per issue with JIRA comments turned into answers. Over time, we expect this site to serve as a persistent store of common questions, answers, etc - it is open for web indexing and has both search and "similar question" functionality to help you find previous related discussions. This addresses one of the biggest issues with current places to ask questions about Clojure - the ability to search and find similar prior discussions.
For problems and enhancements, we have been using JIRA for years (and will continue to do so). However, there are naturally two audiences for issues, users and developers, who have different needs. The new forum will serve as the primary place for users to ask questions about potential problems or request possible enhancments. Authentication occurs via GitHub (other auth providers may be added in the future). No contributor agreement is needed.
Developers on Clojure, ClojureScript, etc will monitor these forums and create JIRAs when necessary. Any user may vote on questions in the forum and the dev teams can use this information when prioritizing fixes and enhancements. This capability has been available in JIRA for many years, but it was too much of a barrier to receive feedback from casual users. The new forum greatly reduces this friction. JIRA will still be used by developers submitting and working on patches, but not for initial problem reporting.
For more information see the forum usage details.

PTSD
MonkeyUser 23 07 2019
In CLOS, a slot can have a :type option, but it doesn’t inforce type
checking. It is good practice to use it, for documentation and for
compiler optimizations and warnings sometimes (with CCL and SBCL when
safety is high), but one shouldn’t rely on it. To comply this need, we
can simply create our own constructor functions.
However, the sanity-clause library can do it since a couple of days. The validation error messages are pretty good. Demonstration.
Sanity clause is a data validation/contract library. You might use it for configuration data, validating an api response, or documents from a datastore. In a dynamically typed langauge, it helps you define clearly defined areas of doubt and uncertainty. We should love our users, but we should never blindly trust their inputs.
To make use of it, you define schemas, which can be property lists with symbols for keys and instances of :class:sanity-clause.field:field
We define a class person with slot options from sanity-clause:
:field-type, type :members, :required:
(defclass person ()
((favorite-dog :type symbol
:field-type :member
:members (:wedge :walter)
:initarg :favorite-dog
:required t)
(age :type (integer 0)
:initarg :age
:required t)
(potato :type string
:initarg :potato
:required t))
(:metaclass sanity-clause.metaclass:validated-metaclass))
Now we try to create a person with make-instance, but we give a bad dog name:
(make-instance 'person :favorite-dog :nope)
; Evaluation aborted on Error converting value for field #<MEMBER-FIELD {1004BFA973}>:
Value "NOPE" couldn't be found in set (WEDGE WALTER)
Now with a bad age:
(make-instance 'person :age -1 :favorite-dog :walter)
; Evaluation aborted on Error validating value -1 in field #<INTEGER-FIELD {1004BFF103}>:
* Value -1 didn't satisfy condition "must be larger than 0"
When a required field is missing:
(make-instance 'person :age 7 :favorite-dog :walter)
; Evaluation aborted on A value for field POTATO is required but none was provided..
And well, it works when all is OK :]
(make-instance 'person :age 1 :favorite-dog :walter :potato "patate")
#<PERSON {10060371E3}>
The usual warnings apply: it’s a new library, we must try it and use it with caution. It however opens up more possibilities. It would be awesome to couple it with an ORM like Mito. This is an open issue.
Resources:

Bug Fixing Ways
MonkeyUser 09 07 2019
Explore the best way to import messy data from remote source into PostgreSQL using Python and Psycopg2. The data is big, fetched from a remote source, and needs to be cleaned and transformed.
Little Known Vim Command – Join
Jovica Ilic 08 07 2019
As the author of Mastering Vim Quickly I sometimes get various Vim related questions from my readers. Much more often I get emails from my subscribers at masteringvim.com where I share free Vim tips. Although this command is very simple, my experience showed that a lot of people are not aware of it. So it’s... Continue reading
The post Little Known Vim Command – Join appeared first on Jovica Ilic.
We just published a long overdue page on the Cookbook: web development in Common Lisp. We have an ambivalent feeling about it since it isn’t really a recipe as in the other pages. Yet it is valuable content that required a certain amount of digging and tryouts. Indeed, it took us about two years to discover and advertise many projects, to learn, try and put a tutorial together. We also wrote a commercial application. During that time, we were taking notes on our web-dev/ page.
We present Hunchentoot, Clack (briefly), we have an overview of other web frameworks, of templating libraries, we introduce Weblocks, we give recipes for common tasks (such as checking if a user is logged in, encrypting passwords), and we speak about deployment.
Some topics still need to be adressed, so check for updates on the Cookbook !
Prior notice:
Some people sell ten pages long ebooks or publish their tutorial on Gitbook to have a purchase option. I prefer to enhance the collaborative Cookbook (I am by far the main contributor). You can tip me on liberapay if you like: https://liberapay.com/vindarel/. Thanks !
For web development as for any other task, one can leverage Common
Lisp’s advantages: the unmatched REPL and exception handling system,
performance, the ability to build a self-contained executable,
stability, good threads story, strong typing, etc. We can, say, define
a new route and try it right away, there is no need to restart any
running server. We can change and compile one function at a time
(the usual C-c C-c in Slime) and try it. The feedback is
immediate. We can choose the degree of interactivity: the web server
can catch exceptions and fire the interactive debugger, or print lisp
backtraces on the browser, or display a 404 error page and print logs
on standard output. The ability to build self-contained executables eases
deployment tremendously (compared to, for example, npm-based apps), in
that we just copy the executable to a server and run it.
We’ll present here some established web frameworks and other common libraries to help you getting started in developing a web application. We do not aim to be exhaustive nor to replace the upstream documentation. Your feedback and contributions are appreciated.
Table of Contents
- Overview
- Installation
- Simple webserver
- Access your server from the internet
- Routing
- Error handling
- Weblocks - solving the “JavaScript problem”©
- Templates
- Connecting to a database
- Building
- Deployment
- Credits
Overview
Hunchentoot and Clack are two projects that you’ll often hear about.
Hunchentoot is
a web server and at the same time a toolkit for building dynamic websites. As a stand-alone web server, Hunchentoot is capable of HTTP/1.1 chunking (both directions), persistent connections (keep-alive), and SSL. It provides facilities like automatic session handling (with and without cookies), logging, customizable error handling, and easy access to GET and POST parameters sent by the client.
It is a software written by Edi Weitz (“Common Lisp Recipes”,
cl-ppcre and much more), it’s used and
proven solid. One can achieve a lot with it, but sometimes with more
friction than with a traditional web framework. For example,
dispatching a route by the HTTP method is a bit convoluted, one must
write a function for the :uri parameter that does the check, when it
is a built-in keyword in other frameworks like Caveman.
Clack is
a web application environment for Common Lisp inspired by Python’s WSGI and Ruby’s Rack.
Also written by a prolific lisper (E. Fukamachi), it actually uses Hunchentoot by default as the server, but thanks to its pluggable architecture one can use another web server, like the asynchronous Woo, built on the libev event loop, maybe “the fastest web server written in any programming language”.
We’ll cite also Wookie, an asynchronous HTTP server, and its companion library cl-async, for general purpose, non-blocking programming in Common Lisp, built on libuv, the backend library in Node.js.
Clack being more recent and less documented, and Hunchentoot a de-facto standard, we’ll concentrate on the latter for this recipe. Your contributions are of course welcome.
Web frameworks build upon web servers and can provide facilities for common activities in web development, like a templating system, access to a database, session management, or facilities to build a REST api.
Some web frameworks include:
- Caveman, by E. Fukamachi. It provides, out of the box, database management, a templating engine (Djula), a project skeleton generator, a routing system à la Flask or Sinatra, deployment options (mod_lisp or FastCGI), support for Roswell on the command line, etc.
- Radiance, by Shinmera (Qtools, Portacle, lquery, …), is a web application environment, more general than usual web frameworks. It lets us write and tie websites and applications together, easing their deployment as a whole. It has thorough documentation, a tutorial, modules, pre-written applications such as an image board or a blogging platform, and more. For example websites, see https://shinmera.com/, reader.tymoon.eu and events.tymoon.eu.
- Snooze, by João Távora (Sly, Emacs’ Yasnippet, Eglot, …), is “an URL router designed around REST web services”. It is different because in Snooze, routes are just functions and HTTP conditions are just Lisp conditions.
- cl-rest-server is a library for writing REST web APIs. It features validation with schemas, annotations for logging, caching, permissions or authentication, documentation via OpenAPI (Swagger), etc.
- last but not least, Weblocks is a venerable Common Lisp web framework that permits to write ajax-based dynamic web applications without writing any JavaScript, nor writing some lisp that would transpile to JavaScript. It is seeing an extensive rewrite and update since 2017. We present it in more details below.
For a full list of libraries for the web, please see the awesome-cl list #network-and-internet and Cliki. If you are looking for a featureful static site generator, see Coleslaw.
Installation
Let’s install the libraries we’ll use:
(ql:quickload '("hunchentoot" "caveman" "spinneret" "djula"))
To try Weblocks, please see its documentation. The Weblocks in Quicklisp is not yet, as of writing, the one we are interested in.
We’ll start by serving local files and we’ll run more than one local server in the running image.
Simple webserver
Serve local files
Hunchentoot
Create and start a webserver like this:
(defvar *acceptor* (make-instance 'hunchentoot:easy-acceptor :port 4242))
(hunchentoot:start *acceptor*)
We create an instance of easy-acceptor on port 4242 and we start
it. We can now access http://127.0.0.1:4242/. You should get a welcome
screen with a link to the documentation and logs to the console.
By default, Hunchentoot serves the files from the www/ directory in
its source tree. Thus, if you go to the source of
easy-acceptor (M-. in Slime), which is probably
~/quicklisp/dists/quicklisp/software/hunchentoot-v1.2.38/, you’ll
find the root/ directory. It contains:
- an
errors/directory, with the error templates404.htmland500.html, - an
img/directory, - an
index.htmlfile.
To serve another directory, we give the option document-root to
easy-acceptor. We can also set the slot with its accessor:
(setf (hunchentoot:acceptor-document-root *acceptor*) #p"path/to/www")
Let’s create our index.html first. Put this in a new
www/index.html at the current directory (of the lisp repl):
<html>
<head>
<title>Hello!</title>
</head>
<body>
<h1>Hello local server!</h1>
<p>
We just served our own files.
</p>
</body>
</html>
Let’s start a new acceptor on a new port:
(defvar *my-acceptor* (make-instance 'hunchentoot:easy-acceptor :port 4444
:document-root #p"www/"))
(hunchentoot:start *my-acceptor*)
go to p://127.0.0.1:4444/ and see the difference.
Note that we just created another acceptor on a different port on the same lisp image. This is already pretty cool.
Access your server from the internet
Hunchentoot
With Hunchentoot we have nothing to do, we can see the server from the internet right away.
If you evaluate this on your VPS:
(hunchentoot:start (make-instance 'hunchentoot:easy-acceptor :port 4242))
You can see it right away on your server’s IP.
Stop it with (hunchentoot:stop *).
Routing
Simple routes
Hunchentoot
To bind an existing function to a route, we create a “prefix dispatch”
that we push onto the *dispatch-table* list:
(defun hello ()
(format nil "Hello, it works!"))
(push
(hunchentoot:create-prefix-dispatcher "/hello.html" #'hello)
hunchentoot:*dispatch-table*)
To create a route with a regexp, we use create-regex-dispatcher, where
the url-as-regexp can be a string, an s-expression or a cl-ppcre scanner.
If you didn’t yet, create an acceptor and start the server:
(defvar *server* (make-instance 'hunchentoot:easy-acceptor :port 4242))
(hunchentoot:start *server*)
and access it on [http://localhost:4242/hello.html]http://localhost:4242/hello.html).
We can see logs on the REPL:
127.0.0.1 - [2018-10-27 23:50:09] "get / http/1.1" 200 393 "-" "Mozilla/5.0 (X11; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0"
127.0.0.1 - [2018-10-27 23:50:10] "get /img/made-with-lisp-logo.jpg http/1.1" 200 12583 "http://localhost:4242/" "Mozilla/5.0 (X11; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0"
127.0.0.1 - [2018-10-27 23:50:10] "get /favicon.ico http/1.1" 200 1406 "-" "Mozilla/5.0 (X11; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0"
127.0.0.1 - [2018-10-27 23:50:19] "get /hello.html http/1.1" 200 20 "-" "Mozilla/5.0 (X11; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0"
define-easy-handler allows to create a function and to bind it to an uri at once.
Its form follows
define-easy-handler (function-name :uri <uri> …) (lambda list parameters)
where <uri> can be a string or a function.
Example:
(hunchentoot:define-easy-handler (say-yo :uri "/yo") (name)
(setf (hunchentoot:content-type*) "text/plain")
(format nil "Hey~@[ ~A~]!" name))
Visit it at p://localhost:4242/yo and add parameters on the url: http://localhost:4242/yo?name=Alice.
Just a thought… we didn’t explicitely ask Hunchentoot to add this
route to our first acceptor of the port 4242. Let’s try another acceptor (see
previous section), on port 4444: http://localhost:4444/yo?name=Bob It
works too ! In fact, define-easy-handler accepts an acceptor-names
parameter:
acceptor-names (which is evaluated) can be a list of symbols which means that the handler will only be returned by DISPATCH-EASY-HANDLERS in acceptors which have one of these names (see ACCEPTOR-NAME). acceptor-names can also be the symbol T which means that the handler will be returned by DISPATCH-EASY-HANDLERS in every acceptor.
So, define-easy-handler has the following signature:
define-easy-handler (function-name &key uri acceptor-names default-request-type) (lambda list parameters)
It also has a default-parameter-type which we’ll use in a minute to get url parameters.
There are also keys to know for the lambda list. Please see the documentation.
Caveman
Caveman provides two ways to
define a route: the defroute macro and the @route pythonic
annotation:
(defroute "/welcome" (&key (|name| "Guest"))
(format nil "Welcome, ~A" |name|))
@route GET "/welcome"
(lambda (&key (|name| "Guest"))
(format nil "Welcome, ~A" |name|))
A route with an url parameter (note :name in the url):
(defroute "/hello/:name" (&key name)
(format nil "Hello, ~A" name))
It is also possible to define “wildcards” parameters. It works with
the splat key:
(defroute "/say/*/to/*" (&key splat)
; matches /say/hello/to/world
(format nil "~A" splat))
;=> (hello world)
We must enable regexps with :regexp t:
(defroute ("/hello/([\\w]+)" :regexp t) (&key captures)
(format nil "Hello, ~A!" (first captures)))
Accessing GET and POST parameters
Hunchentoot
First of all, note that we can access query parameters anytime with
(hunchentoot:parameter "my-param")
It acts on the default *request* object which is passed to all handlers.
There is also get-paramater and post-parameter.
Earlier we saw some key parameters to define-easy-handler. We now
introduce default-parameter-type.
We defined the following handler:
(hunchentoot:define-easy-handler (say-yo :uri "/yo") (name)
(setf (hunchentoot:content-type*) "text/plain")
(format nil "Hey~@[ ~A~]!" name))
The variable name is a string by default. Let’s check it out:
(hunchentoot:define-easy-handler (say-yo :uri "/yo") (name)
(setf (hunchentoot:content-type*) "text/plain")
(format nil "Hey~@[ ~A~] you are of type ~a" name (type-of name)))
Going to http://localhost:4242/yo?name=Alice returns
Hey Alice you are of type (SIMPLE-ARRAY CHARACTER (5))
To automatically bind it to another type, we use default-parameter-type. It can be
one of those simple types:
'string(default),'integer,'character(accepting strings of length 1 only, otherwise it is nil)- or
'boolean
or a compound list:
'(:list <type>)'(:array <type>)'(:hash-table <type>)
where <type> is a simple type.
Error handling
In all frameworks, we can choose the level of interactivity. The web framework can return a 404 page and print output on the repl, it can catch errors and invoke the interactive lisp debugger, or it can show the lisp backtrace on the html page.
Hunchentoot
The global variables to set are *catch-errors-p*,
*show-lisp-errors-p* and *show-lisp-backtraces-p*.
Hunchentoot also defines condition classes.
See the documentation: https://edicl.github.io/hunchentoot/#conditions.
Clack
Clack users might make a good use of plugins, like the clack-errors middleware: https://github.com/CodyReichert/awesome-cl#clack-plugins.
Weblocks - solving the “JavaScript problem”©
Weblocks is a widgets-based and server-based framework with a built-in ajax update mechanism. It allows to write dynamic web applications without the need to write JavaScript or to write lisp code that would transpile to JavaScript.
Weblocks is an old framework developed by Slava Akhmechet, Stephen Compall and Leslie Polzer. After nine calm years, it is seeing a very active update, refactoring and rewrite effort by Alexander Artemenko.
It was initially based on continuations (they were removed to date) and thus a lispy cousin of Smalltalk’s Seaside. We can also relate it to Haskell’s Haste, OCaml’s Eliom, Elixir’s Phoenix LiveView and others.
The Ultralisp website is an example Weblocks website in production known in the CL community.
Weblock’s unit of work is the widget. They look like a class definition:
(defwidget task ()
((title
:initarg :title
:accessor title)
(done
:initarg :done
:initform nil
:accessor done)))
Then all we have to do is to define the render method for this widget:
(defmethod render ((task task))
"Render a task."
(with-html
(:span (if (done task)
(with-html
(:s (title task)))
(title task)))))
It uses the Spinneret template engine by default, but we can bind any other one of our choice.
To trigger an ajax event, we write lambdas in full Common Lisp:
...
(with-html
(:p (:input :type "checkbox"
:checked (done task)
:onclick (make-js-action
(lambda (&key &allow-other-keys)
(toggle task))))
...
The function make-js-action creates a simple javascript function
that calls the lisp one on the server, and automatically refreshes the
HTML of the widgets that need it. In our example, it re-renders one
task only.
Is it appealing ? Carry on this quickstart guide here: http://40ants.com/weblocks/quickstart.html.
Templates
Djula - HTML markup
Djula is a port of Python’s Django template engine to Common Lisp. It has excellent documentation.
Caveman uses it by default, but otherwise it is not difficult to setup. We must declare where our templates are with something like
(djula:add-template-directory (asdf:system-relative-pathname "webapp" "templates/"))
A Djula template looks like this, no surprises (forgive the antislash
in \%, this is a Jekyll limitation):
{\% extends "base.html" \%}
{\% block title %}Memberlist{\% endblock \%}
{\% block content \%}
<ul>
{\% for user in users \%}
<li><a href="{{ user.url }}">{{ user.username }}</a></li>
{\% endfor \%}
</ul>
{\% endblock \%}
Djula compiles the templates before rendering them.
It is, along with its companion access library, one of the most downloaded libraries of Quicklisp.
Spinneret - lispy templates
Spinneret is a “lispy” HTML5 generator. It looks like this:
(with-page (:title "Home page")
(:header
(:h1 "Home page"))
(:section
("~A, here is *your* shopping list: " *user-name*)
(:ol (dolist (item *shopping-list*)
(:li (1+ (random 10)) item))))
(:footer ("Last login: ~A" *last-login*)))
The author finds it is easier to compose the HTML in separate functions and macros than with the more famous cl-who. But it has more features under it sleeves:
- it warns on invalid tags and attributes
- it can automatically number headers, given their depth
- it pretty prints html per default, with control over line breaks
- it understands embedded markdown
- it can tell where in the document a generator function is (see
get-html-tag)
Connecting to a database
Please see the databases section. The Mito ORM supports SQLite3, PostgreSQL, MySQL, it has migrations and db schema versioning, etc.
In Caveman, a database connection is alive during the Lisp session and is reused in each HTTP requests.
Checking a user is logged-in
A framework will provide a way to work with sessions. We’ll create a little macro to wrap our routes to check if the user is logged in.
In Caveman, *session* is a hash table that represents the session’s
data. Here are our login and logout functions:
(defun login (user)
"Log the user into the session"
(setf (gethash :user *session*) user))
(defun logout ()
"Log the user out of the session."
(setf (gethash :user *session*) nil))
We define a simple predicate:
(defun logged-in-p ()
(gethash :user cm:*session*))
and we define our with-logged-in macro:
(defmacro with-logged-in (&body body)
`(if (logged-in-p)
(progn ,@body)
(render #p"login.html"
'(:message "Please log-in to access this page."))))
If the user isn’t logged in, there will nothing in the session store, and we render the login page. When all is well, we execute the macro’s body. We use it like this:
(defroute "/account/logout" ()
"Show the log-out page, only if the user is logged in."
(with-logged-in
(logout)
(render #p"logout.html")))
(defroute ("/account/review" :method :get) ()
(with-logged-in
(render #p"review.html"
(list :review (get-review (gethash :user *session*))))))
and so on.
Encrypting passwords
In this recipe we use the de-facto standard Ironclad cryptographic toolkit and the Babel charset encoding/decoding library.
This snippet creates the password hash that should be stored in your database. Note that Ironclad expects a byte-vector, not a string.
(defun password-hash (password)
(ironclad:pbkdf2-hash-password-to-combined-string
(babel:string-to-octets password)))
pbkdf2 is defined in RFC2898.
It uses a pseudorandom function to derive a secure encryption key
based on the password.
The following function checks if a user is active and verifies the entered password. It returns the user-id if active and verified and nil in all other cases even if an error occurs. Adapt it to your application.
(defun check-user-password (user password)
(handler-case
(let* ((data (my-get-user-data user))
(hash (my-get-user-hash data))
(active (my-get-user-active data)))
(when (and active (ironclad:pbkdf2-check-password (babel:string-to-octets password)
hash))
(my-get-user-id data)))
(condition () nil)))
And the following is an example on how to set the password on the
database. Note that we use (password-hash password) to save the
password. The rest is specific to the web framework and to the DB
library.
(defun set-password (user password)
(with-connection (db)
(execute
(make-statement :update :web_user
(set= :hash (password-hash password))
(make-clause :where
(make-op := (if (integerp user)
:id_user
:email)
user))))))
Credit: /u/arvid on /r/learnlisp.
Building
Building a self-contained executable
As for all Common Lisp applications, we can bundle our web app in one single executable, including the assets. It makes deployment very easy: copy it to your server and run it.
$ ./my-web-app
Hunchentoot server is started.
Listening on localhost:9003.
See this recipe on scripting#for-web-apps.
Continuous delivery with Travis CI or Gitlab CI
Please see the section on testing#continuous-integration.
Multiplatform delivery with Electron
Ceramic makes all the work for us.
It is as simple as this:
;; Load Ceramic and our app
(ql:quickload '(:ceramic :our-app))
;; Ensure Ceramic is set up
(ceramic:setup)
(ceramic:interactive)
;; Start our app (here based on the Lucerne framework)
(lucerne:start our-app.views:app :port 8000)
;; Open a browser window to it
(defvar window (ceramic:make-window :url "http://localhost:8000/"))
;; start Ceramic
(ceramic:show-window window)
and we can ship this on Linux, Mac and Windows.
There is more:
Ceramic applications are compiled down to native code, ensuring both performance and enabling you to deliver closed-source, commercial applications.
Thus, no need to minify our JS.
Deployment
Deploying manually
We can start our executable in a shell and send it to the bakcground (C-z bg), or run it inside a tmux session. These are not the best but hey, it works©.
Daemonizing, restarting in case of crashes, handling logs with Systemd
This is actually a system-specific task. See how to do that on your system.
Most GNU/Linux distros now come with Systemd, so here’s a little example.
Deploying an app with Systemd is as simple as writing a configuration file:
$ emacs -nw /etc/systemd/system/my-app.service
[Unit]
Description=stupid simple example
[Service]
WorkingDirectory=/path/to/your/app
ExecStart=/usr/local/bin/sthg sthg
Type=simple
Restart=always
RestartSec=10
Then we have a command to start it:
sudo systemctl start my-app.service
a command to check its status:
systemctl status my-app.service
and Systemd can handle logging (we write to stdout or stderr, it writes logs):
journalctl -f -u my-app.service
and it handles crashes and restarts the app:
Restart=always
and it can start the app after a reboot:
[Install]
WantedBy=basic.target
to enable it:
sudo systemctl enable my-app.service
With Docker
There are several Docker images for Common Lisp. For example:
- 40ants/base-lisp-image is based on Ubuntu LTS and includes SBCL, CCL, Quicklisp, Qlot and Roswell.
- container-lisp/s2i-lisp is CentOs based and contains the source for building a Quicklisp based Common Lisp application as a reproducible docker image using OpenShift’s source-to-image.
With Guix
GNU Guix is a transactional package manager, that can be installed on top of an existing OS, and a whole distro that supports declarative system configuration. It allows to ship self-contained tarballs, which also contain system dependencies. For an example, see the Next browser.
Deploying on Heroku and other services
See heroku-buildpack-common-lisp and the Awesome CL#deploy section for interface libraries for Kubernetes, OpenShift, AWS, etc.
Monitoring
See Prometheus.cl for a Grafana dashboard for SBCL and Hunchentoot metrics (memory, threads, requests per second,…).
Connecting to a remote Lisp image
This this section: debugging#remote-debugging.
Hot reload
This is an example from Quickutil. It is actually an automated version of the precedent section.
It has a Makefile target:
hot_deploy:
$(call $(LISP), \
(ql:quickload :quickutil-server) (ql:quickload :swank-client), \
(swank-client:with-slime-connection (conn "localhost" $(SWANK_PORT)) \
(swank-client:slime-eval (quote (handler-bind ((error (function continue))) \
(ql:quickload :quickutil-utilities) (ql:quickload :quickutil-server) \
(funcall (symbol-function (intern "STOP" :quickutil-server))) \
(funcall (symbol-function (intern "START" :quickutil-server)) $(start_args)))) conn)) \
$($(LISP)-quit))
It has to be run on the server (a simple fabfile command can call this
through ssh). Beforehand, a fab update has run git pull on the
server, so new code is present but not running. It connects to the
local swank server, loads the new code, stops and starts the app in a
row.
Credits

Flexclip es un servicio que encontré y me pareció de lo más interesante para realizar videos rápidos pero bonitos. Uno de los problemas más grandes que a veces tengo es que si quiero hacer un video rápido, sin necesidad de tener mucha edición, opciones como Adobe Premiere no cumplen su cometido, porque añaden muchísima complejidad a una cinemática con imágenes y texto.
Encontré a Flexclip y creo que de cualquier opción que hayas visto en internet, diría que es la más sencilla de usar con grandes resultados.

Para empezar podemos elegir una temática de un template para no partir desde cero. La ventaja de usar estas opciones es que ya no necesitas nada más que cambiar el texto y las imágenes, por lo que ya te ahorras al menos la mitad del trabajo.

Cuando llegamos a la interfaz no pude estar más impresionado de lo minimalista y funcional que puede ser tener dos o tres herramientas para trabajar. Como les digo, esto es para cuando necesitamos algo rápido, tenemos videos, imágenes y música, y no queremos perder el tiempo en acomodarlos pixel por pixel a ver si queda bien.

Los cuadros de control son muy rápidos de editar, no hace falta gran complejidad para poder meter un texto en un formato ya definido para que puedas ver luego luego el resultado.
Si al contrario, no tenemos ningún contenido para empezar a trabajar, podemos agregar de la galería de Flexclip imágenes y música que sorpresivamente tienen una calidad muy buena.
Al final tu video se presenta como la composición de varias escenas, donde si quieres acomodarlas solo necesitas moverlas de lugar y ya, a previsualizar el video y si te gustó lo puedes exportar.
Conclusiones
Este servicio en línea me recordó mucho a cuando usaba Windows Movie Maker para hacer videos cortos o que por la urgencia necesitaba tener en unos cuantos minutos. No ha vuelto a existir un programa igual, pero me sorprende que los servicios web ahora estén tomando esa responsabilidad de seguir ofreciendo hacer videos como lo hace Flexclip, sin la necesidad de ser un experto en edición para crear un contenido de calidad de forma muy rápida.

MVP
MonkeyUser 02 07 2019

Obvious
MonkeyUser 25 06 2019


1. Aprende a leer el código de los demás
Poder leer código escrito de alguien más te dará más visión sobre si el código que haces es bueno o malo. También es bueno de vez en cuando aprender a entender el código de alguien más porque podrías adoptar técnicas y formas de programar que quizá ni sabías que existían, y de la misma forma hacer que los demás aprendan.
2. La sensación de malos proyectos
¿Les ha pasado que antes de empezar un proyecto pueden empezar a estructurar el futuro del mismo? eso se aprende con la experiencia, con los retrasos o la dificultad de los proyectos cuando no se planean bien. Este punto de aprender a identificar buenos y malos proyectos ayuda mucho porque al final un desarrollador debería ser capaz de determinar la viabilidad de un proyecto, y más cuando no tiene futuro.
3. Evitar las reuniones
Todos odiamos las reuniones largas en un proyecto. Dar estatus, explicaciones y en general, invertir tiempo en explicarle a los demás qué es lo que pasa con un proyecto es algo que siempre deberíamos evitar. No es estar en contra de tener reuniones, pero para dar avances no es necesario tener una reunión diario, con una a la semana, con correos, y con herramientas como Github se puede reemplazar el tener que invertir tiempo innecesario.
4. Uso de Github
Github y Git son de las herramientas indispensables hoy en día para cualquier desarrollador. Ya sea que trabajes de forma local o colaborativa tener un sistema de versionamiento permite tener eficiencia en los cambios que se hacen a un proyecto, especialmente si es grande. El otro plus es que tener un sistema como Github permite que otros vean tu código sin tener que perder tiempo tratando de mostrarles avances a los líderes del proyecto.
5. Escribir código que pueda ser mantenido
Para ser efectivo como programador, uno de los primeros pasos es programar correctamente. De nada sirve tener los puntos anteriores, si cuando inicia otro proyecto no puedas reusar código que podría servirte de nuevo. Hay que aprender a crear código que pueda ser extendido y mantenido, es decir, que puedas quitar, adaptar y volver a usar en n número de proyectos. Cuando logres hacer lo anterior, habrás ahorrado muchísimo tiempo de programación.
6. Aprende a decir no y prioriza
No todo vas a poder hacer, por eso tienes que priorizar las actividades que sí puedes hacer excelente. La parte del éxito de los programadores es poder ejecutar lo que está en su alcance, compartir responsabilidad con un equipo cuando así se necesita, y decir que no cuando no agrega valor la actividad al proyecto. Si sigues ese mismo principio de desechar lo que te puede hacer perder tiempo y no agregar valor a un proyecto de programación puedes entonces priorizar de forma correcta.
7. Pensamiento de diseño operacional
Siempre que trabajamos en un proyecto de programación creemos que con probar los escenarios más obvios, nuestro proyecto ya va a funcionar correctamente. Desde la modificación del código hasta el lanzamiento hay muchísimas variables que podrían afectar el funcionamiento del producto final, por eso un hábito muy identificado en programadores efectivos es que prueban y prueban de todas las formas posibles el software para poder identificar cualquier error posible durante la programación y la liberación. La simple modificación de una línea de código podría afectar otras partes del sistema que probablemente no estemos notando.Conclusiones
Estos son algunos consejos de programadores que no solo programan bien, sino que tienen un panorama mucho más amplio de cómo contribuir a un proyecto con calidad y acertividad cuando se colabora con otros.

A QA walks into the office
MonkeyUser 18 06 2019
![]()

Exit Condition
MonkeyUser 11 06 2019
Validando un API rest asíncrono con Cerberus
El artículo lo pueden leer en el siguiente enlace
Visiten el blog www.seraph.to
Pueden leer el artículo en el siguiente enlace
Cómo usar el API de Wikipedia desde Python
When a developer chooses Python, Django, or Django Rest Framework, it's usually not because of its blazing fast performance. All of this doesn't mean performance is not important. As this story taught us, major performance boosts can be gained with just a little attention, and a few small changes.
Clojure 1.10.1 release
Clojure News 06 06 2019
Clojure 1.10.1 is a small release focusing on two issues: working around a Java performance regression and improving error reporting from clojure.main.
Java performance regression
Recent builds of Java 8 (u202), 11 (11.0.2), 12, and 13 included some changes that drastically affect optimization performance of calls from static initializers to static fields. Clojure provides support for loading code on startup from a user.clj file and this occurred in the static initializer of the Clojure runtime (RT) class and was thus affected.
This issue may eventually be resolved in Java, but in Clojure we have modified runtime initialization to avoid loading user.clj in a static initializer, which mitigates the case where this caused a performance degradation.
clojure.main error reporting
clojure.main is frequently used as a Clojure program launcher by external tools. Previously, uncaught exceptions would be automatically printed by the JVM, which would also print the stack trace.
This release will now catch exceptions and use the same error triage and printing functionality as the Clojure repl. The full stack trace, ex-info, and other information will be printed to a target specified by the configuration. See clojure.main docs for configuration details.
Changelog
See the change log for a complete list of all changes in Clojure 1.10.1.

UI vs UX
MonkeyUser 04 06 2019


¿Has asistido a presentaciones técnicas en público? muchas de ellas aunque por los temas suenas interesantes, la forma en que son expuestas hacen que en ocasiones aburran, se hagan tediosas o largas, o simplemente no aprendas lo que en un principio te están vendiendo que vas a conocer. Estos son algunos tips si vas a hacer una presentación de este tipo, donde debemos cuidar ciertos puntos específicos para atraer al público y que una plática técnica sea una buena experiencia de aprendizaje.
- Explicar antes de empezar de qué va a tratar la presentación
- Asegúrate de entender el lenguaje que maneja tu audiencia
- Explica los acrónimos que uses para poner contexto
- Si necesitas que el público aprenda un concepto específico, repítelo 3 veces de diferentes maneras
- Usa imágenes en tu presentación, evita texto que haga que la gente lo lea primero antes de ponerte atención
- Preséntate y di tu nombre con claridad
- Hila las recomendaciones con historias que argumenten el por qué de la recomendación
- No te limites a un slide
- Si vas a colocar código en una presentación, asegúrate de que tenga el tamaño adecuado para ser leído a la distancia
- Recuerda que tu público es inteligente, pero no es especialista en el tema que tu hablas, procura explicar todos tus puntos claramente
- Pon un resumen al final de tu charla, para volver a recordar los puntos más importantes
- Usa ejemplos y metáforas para explicar conceptos difíciles
- Trata de explicar a tu audiencia por qué a nivel técnico hay mejoras o no, por qué se están haciendo las cosas de otra forma y el beneficio que ellos obtendrán de hacerlo.
- Practica para tener el tiempo suficiente de dar tu plática y tener espacio de preguntas y respuestas
- Haz pausas entre cada explicación de puntos importantes, para que la audiencia pueda entenderlas.
- Haz bromas para llamar la atención de las personas que están distrayéndose, solo si puedes hacerlo.
- Trata de orientar al público no solo en lo que está pasando ahora, sino lo que vendrá en el futuro.
- Usa un tono de voz dinámico, para evitar que la gente se canse o se duerma por un tono de voz bajo y lento.
- Evita dar contexto muy largo del tema que hablas, usa 10 o menos minutos para darle y a continuación entra de lleno en lo más importante que vienes a platicar.
- Crea suspenso y curiosidad desde el inicio de tu plática
- Pon información adicional a videos, posts o lecturas sugeridas para que la gente pueda encontrar más información relacionada.
- Al final de la presentación da las gracias y espera que la gente aplauda. Cuando el presentador no planea espacios para que el público aplauda se crea un momento muy incómodo.
- Practica con alguien que confíes y te pueda dar retroalimentación para que puedas mejorarlo.
Veamos cuales son las diferencias entre == y === cuando programamos en Javascript. Mientras que al == se le considera igualdad débil o abstracta, al === se le conoce como igualdad estricta, fuerte o también se le llama identidad. La diferencia es que mientras que con el == antes de hacer la comparación se convierten…
La entrada Diferencias entre == y === en Javascript aparece primero en Óscar Lijó.

Hack Slash Revert
MonkeyUser 28 05 2019
Pattern Matching in Common Lisp
Lisp journey 26 05 2019
New page on the Cookbook: https://lispcookbook.github.io/cl-cookbook/pattern_matching.html All examples come from Trivia’s wiki.
The ANSI Common Lisp standard does not include facilities for pattern matching, but libraries existed for this task and Trivia became a community standard.
Table of Contents
For an introduction to the concepts of pattern matching, see Trivia’s wiki.
Trivia matches against a lot of lisp objects and is extensible.
The library is in Quicklisp:
(ql:quickload "trivia")
For the following examples, let’s use the library:
(use-package :trivia)
Common destructuring patterns
cons
(match '(1 2 3)
((cons x y)
; ^^ pattern
(print x)
(print y)))
;; |-> 1
;; |-> (2 3)
list, list*
(match '(something #(0 1 2))
((list a (vector 0 _ b))
(values a b)))
SOMETHING
2
list* pattern:
(match '(1 2 . 3)
((list* _ _ x)
x))
3
Note that using list would match nothing.
vector, vector*
vector checks if the object is a vector, if the lengths are the
same, and if the contents matches against each subpatterns.
vector* is similar, but called a soft-match variant that allows if
the length is larger-than-equal to the length of subpatterns.
(match #(1 2 3)
((vector _ x _)
x))
;; -> 2
(match #(1 2 3 4)
((vector _ x _)
x))
;; -> NIL : does not match
(match #(1 2 3 4)
((vector* _ x _)
x))
;; -> 2 : soft match.
<vector-pattern> : vector | simple-vector
bit-vector | simple-bit-vector
string | simple-string
base-string | simple-base-string | sequence
(<vector-pattern> &rest subpatterns)
Class and structure pattern
There are three styles that are equivalent:
(defstruct foo bar baz)
(defvar *x* (make-foo :bar 0 :baz 1)
(match *x*
;; make-instance style
((foo :bar a :baz b)
(values a b))
;; with-slots style
((foo (bar a) (baz b))
(values a b))
;; slot name style
((foo bar baz)
(values bar baz)))
type, satisfies
The type pattern matches if the object is of type. satisfies matches
if the predicate returns true for the object. A lambda form is
acceptable.
assoc, property, alist, plist
All these patterns first check if the pattern is a list. If that is satisfied, then they obtain the contents, and the value is matched against the subpattern.
Array, simple-array, row-major-array patterns
Logic based patterns
and, or
(match x
((or (list 1 a)
(cons a 3))
a))
matches against both (1 2) and (4 . 3) and returns 2 and 4, respectively.
not
It does not match when subpattern matches. The variables used in the subpattern are not visible in the body.
guards
The syntax is guard + subpattern + a test form, and the body.
(match (list 2 5)
((guard (list x y) ; subpattern
(= 10 (* x y)) ; test-form
(- x y) (satisfies evenp)) ; generator1, subpattern1
t))
If the subpattern is true, the test form is evaluated, and if it is true it is matched against subpattern1.
The above returns nil, since (- x y) == 3 does not satisfies evenp.
Nesting patterns
Patterns can be nested:
(match '(:a (3 4) 5)
((list :a (list _ c) _)
c))
returns 4.
See more
See special patterns: place, bind and access.
Here’s an enhanced page for the Cookbook: https://lispcookbook.github.io/cl-cookbook/functions.html
Only the Currying part was untouched (we enhanced it already), the higher-order functions part existed and was rewritten. The rest is new, and it should help you start writing Common Lisp quicker than ever.
Happy lisping !
Table of Contents
- Named functions:
defun - Arguments
Named functions: defun
Creating named functions is done with the defun keyword. It follows this model:
(defun <name> (list of arguments)
"docstring"
(function body))
The return value is the value returned by the last expression of the body (see below for more). There is no “return xx” statement.
So, for example:
(defun hello-world ()
;; ^^ no arguments
(print "hello world!"))
Call it:
(hello-world)
;; "hello world!" <-- output
;; "hello world!" <-- a string is returned.
Arguments
Base case: required arguments
Add in arguments like this:
(defun hello (name)
"Say hello to `name'."
(format t "hello ~a !~&" name))
;; HELLO
(where ~a is the most used format directive to print a variable
aesthetically and ~& prints a newline)
Call the function:
(hello "me")
;; hello me ! <-- this is printed by `format`
;; NIL <-- return value: `format t` prints a string to standard output and returns nil.
If you don’t specify the right amount of arguments, you’ll be trapped into the interactive debugger with an explicit error message:
(hello)
invalid number of arguments: 0
Optional arguments: &optional
Optional arguments are declared after the &optional keyword in the
lambda list. They are ordered, they must appear one after another.
This function:
(defun hello (name &optional age gender) …)
must be called like this:
(hello "me") ;; a value for the required argument, zero optional arguments
(hello "me" "7") ;; a value for age
(hello "me" 7 :h) ;; a value for age and gender
Named parameters: &key
It is not always convenient to remember the order of the arguments. It
is thus possible to supply arguments by name: we declare them using
&key <name>, we set them with :name <value> in the function call,
and we use name as a regular variable in the function body. They are
nil by default.
(defun hello (name &key happy)
"If `happy' is `t', print a smiley"
(format t "hello ~a " name)
(when happy
(format t ":)~&"))
The following calls are possible:
(hello "me")
(hello "me" :happy t)
(hello "me" :happy nil) ;; useless, equivalent to (hello "me")
and this is not valid: (hello "me" :happy):
odd number of &KEY arguments
A similar example of a function declaration, with several key parameters:
(defun hello (name &key happy lisper cookbook-contributor-p) …)
it can be called with zero or more key parameters, in any order:
(hello "me" :lisper t)
(hello "me" :lisper t :happy t)
(hello "me" :cookbook-contributor-p t :happy t)
Mixing optional and key parameters
It is generally a style warning, but it is possible.
(defun hello (&optional name &key happy)
(format t "hello ~a " name)
(when happy
(format t ":)~&")))
In SBCL, this yields:
; in: DEFUN HELLO
; (SB-INT:NAMED-LAMBDA HELLO
; (&OPTIONAL NAME &KEY HAPPY)
; (BLOCK HELLO (FORMAT T "hello ~a " NAME) (WHEN HAPPY (FORMAT T ":)~&"))))
;
; caught STYLE-WARNING:
; &OPTIONAL and &KEY found in the same lambda list: (&OPTIONAL (NAME "John") &KEY
; HAPPY)
;
; compilation unit finished
; caught 1 STYLE-WARNING condition
We can call it:
(hello "me" :happy t)
;; hello me :)
;; NIL
Default values
In the lambda list, use pairs to give a default value to an optional or a key argument, like (happy t) below:
(defun hello (name &key (happy t))
Now happy is true by default.
Variable number of arguments: &rest
Sometimes you want a function to accept a variable number of
arguments. Use &rest <variable>, where <variable> will be a list.
(defun mean (x &rest numbers)
(/ (apply #'+ x numbers)
(1+ (length numbers))))
(mean 1)
(mean 1 2)
(mean 1 2 3 4 5)
&allow-other-keys
Observe:
(defun hello (name &key happy)
(format t "hello ~a~&" name))
(hello "me" :lisper t)
;; => Error: unknown keyword argument
whereas
(defun hello (name &key happy &allow-other-keys)
(format t "hello ~a~&" name))
(hello "me" :lisper t)
;; hello me
We might need &allow-other-keys when passing around arguments or
with higher level manipulation of functions.
Return values
The return value of the function is the value returned by the last executed form of the body.
There are ways for non-local exits (return-from <function name> <value>), but they are usually not needed.
Common Lisp has also the concept of multiple return values.
Multiple return values: values and multiple-value-bind
Returning multiple values is not like returning a tuple or a list of results ;) This is a common misconception.
Multiple values are specially useful and powerful because a change in them needs little to no refactoring.
(defun foo (a b c)
a)
This function returns a.
(defvar *res* (foo :a :b :c))
;; :A
We use values to return multiple values:
(defun foo (a b c)
(values a b c))
(setf *res* (foo :a :b :c))
;; :A
Observe here that *res* is still :A.
All functions that use the return value of foo need no change, they
still work. If we had returned a list or an array, this would be
different.
We destructure multiple values with multiple-value-bind (or
mvb+TAB in Slime for short):
(multiple-value-bind (res1 res2 res3)
(foo :a :b :c)
(format t "res1 is ~a, res2 is ~a, res2 is ~a~&" res1 res2 res3))
;; res1 is A, res2 is B, res2 is C
;; NIL
Its general form is
(multiple-value-bind (var-1 .. var-n) expr
body)
The variables var-n are not available outside the scope of multiple-value-bind.
Last but not least: note that (values) with no values returns… no values at all.
See also multiple-value-call.
Anonymous functions: lambda
Anonymous functions are created with lambda:
(lambda (x) (print x))
We can call a lambda with funcall or apply (see below).
If the first element of an unquoted list is a lambda expression, the lambda is called:
((lambda (x) (print x)) "hello")
;; hello
Calling functions programatically: funcall and apply
funcall is to be used with a known number of arguments, when apply
can be used on a list, for example from &rest:
(funcall #'+ 1 2)
(apply #'+ '(1 2))
Higher order functions: functions that return functions
Writing functions that return functions is simple enough:
(defun adder (n)
(lambda (x) (+ x n)))
;; ADDER
Here we have defined the function adder which returns an object of type function.
To call the resulting function, we must use funcall or apply:
(adder 5)
;; #<CLOSURE (LAMBDA (X) :IN ADDER) {100994ACDB}>
(funcall (adder 5) 3)
;; 8
Trying to call it right away leads to an illegal function call:
((adder 3) 5)
In: (ADDER 3) 5
((ADDER 3) 5)
Error: Illegal function call.
Indeed, CL has different namespaces for functions and variables, i.e. the same name can refer to different things depending on its position in a form that’s evaluated.
;; The symbol foo is bound to nothing:
CL-USER> (boundp 'foo)
NIL
CL-USER> (fboundp 'foo)
NIL
;; We create a variable:
CL-USER> (defparameter foo 42)
FOO
* foo
42
;; Now foo is "bound":
CL-USER> (boundp 'foo)
T
;; but still not as a function:
CL-USER> (fboundp 'foo)
NIL
;; So let's define a function:
CL-USER> (defun foo (x) (* x x))
FOO
;; Now the symbol foo is bound as a function too:
CL-USER> (fboundp 'foo)
T
;; Get the function:
CL-USER> (function foo)
#<FUNCTION FOO>
;; and the shorthand notation:
* #'foo
#<FUNCTION FOO>
;; We call it:
(funcall (function adder) 5)
#<CLOSURE (LAMBDA (X) :IN ADDER) {100991761B}>
;; and call the lambda:
(funcall (funcall (function adder) 5) 3)
8
To simplify a bit, you can think of each symbol in CL having (at least) two “cells” in which information is stored. One cell - sometimes referred to as its value cell - can hold a value that is bound to this symbol, and you can use boundp to test whether the symbol is bound to a value (in the global environment). You can access the value cell of a symbol with symbol-value.
The other cell - sometimes referred to as its function cell - can hold the definition of the symbol’s (global) function binding. In this case, the symbol is said to be fbound to this definition. You can use fboundp to test whether a symbol is fbound. You can access the function cell of a symbol (in the global environment) with symbol-function.
Now, if a symbol is evaluated, it is treated as a variable in that its value cell is returned (just foo). If a compound form, i.e. a cons, is evaluated and its car is a symbol, then the function cell of this symbol is used (as in (foo 3)).
In Common Lisp, as opposed to Scheme, it is not possible that the car of the compound form to be evaluated is an arbitrary form. If it is not a symbol, it must be a lambda expression, which looks like (lambdalambda-list form*).
This explains the error message we got above - (adder 3) is neither a symbol nor a lambda expression.
If we want to be able to use the symbol *my-fun* in the car of a compound form, we have to explicitely store something in its function cell (which is normally done for us by the macro defun):
;;; continued from above
CL-USER> (fboundp '*my-fun*)
NIL
CL-USER> (setf (symbol-function '*my-fun*) (adder 3))
#<CLOSURE (LAMBDA (X) :IN ADDER) {10099A5EFB}>
CL-USER> (fboundp '*my-fun*)
T
CL-USER> (*my-fun* 5)
8
Read the CLHS section about form evaluation for more.
Closures
Closures allow to capture lexical bindings:
(let ((limit 3)
(counter -1))
(defun my-counter ()
(if (< counter limit)
(incf counter)
(setf counter 0))))
(my-counter)
0
(my-counter)
1
(my-counter)
2
(my-counter)
3
(my-counter)
0
Or similarly:
(defun repeater (n)
(let ((counter -1))
(lambda ()
(if (< counter n)
(incf counter)
(setf counter 0)))))
(defparameter *my-repeater* (repeater 3))
;; *MY-REPEATER*
(funcall *my-repeater*)
0
(funcall *my-repeater*)
1
(funcall *my-repeater*)
2
(funcall *my-repeater*)
3
(funcall *my-repeater*)
0
See more on Practical Common Lisp.
setf functions
A function name can also be a list of two symbols with setf as the
first one, and where the first argument is the new value:
(defun (setf <name>) (new-value <other arguments>)
body)
This mechanism is particularly used for CLOS methods.
A silly example:
(defparameter *current-name* ""
"A global name.")
(defun hello (name)
(format t "hello ~a~&" name))
(defun (setf hello) (new-value)
(hello new-value)
(setf *current-name* new-value)
(format t "current name is now ~a~&" new-value))
(setf (hello) "Alice")
;; hello Alice
;; current name is now Alice
;; NIL
Currying
Concept
A related concept is that of currying which you might be familiar with if you’re coming from a functional language. After we’ve read the last section that’s rather easy to implement:
CL-USER> (declaim (ftype (function (function &rest t) function) curry) (inline curry))
NIL
CL-USER> (defun curry (function &rest args)
(lambda (&rest more-args)
(apply function (append args more-args))))
CURRY
CL-USER> (funcall (curry #'+ 3) 5)
8
CL-USER> (funcall (curry #'+ 3) 6)
9
CL-USER> (setf (symbol-function 'power-of-ten) (curry #'expt 10))
#<Interpreted Function "LAMBDA (FUNCTION &REST ARGS)" {482DB969}>
CL-USER> (power-of-ten 3)
1000
Note that the declaim statement above is just a hint for the compiler so it can produce more efficient code if it so wishes. Leaving it out won’t change the semantics of the function.
With the Alexandria library
Now that you know how to do it, you may appreciate using the implementation of the Alexandria library (in Quicklisp).
(ql:quickload :alexandria)
(defun adder (foo bar)
"Add the two arguments."
(+ foo bar))
(defvar add-one (alexandria:curry #'adder 1) "Add 1 to the argument.")
(funcall add-one 10) ;; => 11
(setf (symbol-function 'add-one) add-one)
(add-one 10) ;; => 11
Documentation
- functions: http://www.lispworks.com/documentation/HyperSpec/Body/t_fn.htm#function
- ordinary lambda lists: http://www.lispworks.com/documentation/HyperSpec/Body/03_da.htm
- multiple-value-bind: http://clhs.lisp.se/Body/m_multip.htm
Some weeks ago I discovered a really nice package for emacs called reformatter.el. This package allows to define reformat functions in a easy way.
Most languages have a reformat tool. Elixir has mix format, Elm has elm format, python has black and so on. These formatters are convenient because they give uniformity to the code, but this is a topic for another post.
Having these formatters integrated within our favorite editor is great. These are enough(at least for me) reasons to use reformatter.el so let's get into the code:
reformatter.el has a simple macro that allows us to define a formatter with just a few lines.
For this example we'll create a formatter for haskell using hindent 1.
(reformatter-define haskell-format
:program "hindent")
We just need to define the command that will be used to format the code. In this case hindent. This will create some useful functions:
-
haskell-format
-
haskell-format-buffer
-
haskell-format-region
-
haskell-format-on-save-mode
These functions can be used with a key-binding:
(define-key haskell-mode-map (kbd "C-c C-f") 'haskell-format-buffer)
Also we can setup emacs to run the formatter when the file is saved, for example put this code in your .dir-locals.el and it will do the work.
(haskell-mode (mode . haskell-format-on-save))
The program used to format our code needs to be able to read from stdin and return the formatted code to stdout. In this case hindent does it by default.
In some cases the formatter doesn't do this by default. For those cases we can pass extra arguments to the command using :args key in the formatter macro. For example elixir format receive a file or a pattern by default but we can change that using mix format -, now it will read from stdin, so we need to pass these parameters to our formatter. The code should be:
(reformatter-define elixir-format
:program "mix"
:args '("format" "-"))Now it will work properly.
This package is very useful if you don't want to install a external package just for formatting. I replaced hindent-mode (haskell formatter) and a custom elixir formatter with this package. Also this package is used in elm-mode package.
I’ve been paid to work on Common Lisp projects for a company for three months already. I didn’t expect it :) And we did hire !
My Github profile shows a good part of what my experience is. I am a regular “full stack developper”, with 7 years of professional experience. I worked on diverse Python and Javascript projects for huge to small companies, private and public. When I re-discovered Common Lisp, I saw it solved a lot of problems I had developing and deploying medium to large software, and it promised to solve all of them (we’re nearly there :D ). I started to write about my experience on this blog and I contributed to open source projects, of which a lot of documentation effort. It is this public activity that drew the attention of the guys at Atlas, who contacted me, without a job announce. We developed and we maintain a proprietary and successful web application that paid the bills, in Common Lisp of course, and we work hard on other projects, such as the Next browser.
So, I can only encourage you to start a Common Lisp project, to come enhance libraries and documentation and to write about it ! There are few official job announces, some are posted on reddit, and some jobs just won’t have a public announce. You’d better be ready.
For the curious, our web app is rather classic, it uses the Caveman web framework and is deployed on DigitalOcean. We do deploy with zero downtime, as CL permits, for trivial updates (we are more cautious otherwise). I’ll post its name in the comments if/when I know I can.
Happy lisping.
Folding the DOM
Josh Comeau's blog 19 05 2019
JIRA Migration
Clojure News 16 05 2019
Clojure has been very fortunate to receive infrastructure support from Atlassian (for JIRA and Confluence) and Contegix (for hosting) for many years. The Confluence and JIRA instances were not kept up to date, and have grown increasingly hard to maintain. Recently, we decided to shut down Confluence (content was either moved to clojure.org or archived) and we are now preparing to migrate from our old JIRA instance into a new cloud-hosted instance. Many thanks to Atlassian again for supporting our efforts in this.
User migration
Due to the large number of users, it is not feasible for us to move everyone, and we’ve decided to migrate all users that have edited tickets in the past (changed a description, added a patch, etc) - this will move user names and emails, not passwords. When the import happens, email invites will go out for users in the new system based on the email address in the old system. Initially these users will not have access to projects.
Users that created or commented on tickets in the past (but did not edit) will not automatically be migrated. We are planning to leverage JIRA Service Desk to create a new path for language users to file tickets without needing an account. These incoming tickets can be triaged and turned into JIRA tickets as needed. We are also looking at a new process to obtain a contributor account and gain access to the system for commenting or other work. Stay tuned for more on that.
Backup and import
After users have been loaded, a backup of the old system and import into the new system will occur. All projects, issues, attachments, comments, etc will be preserved. This will be done on a per-project basis until the migration is complete and might take a while to fully import and verify.
After that, there will be some work to enable access for different project administrators and users before the system is fully available.
We will put the old system into a read-only mode once the backup and import has started. Once the import is complete, the old system will be shut down. Redirect rules will be set up for the old Confluence and JIRA urls to point to the new Confluence archive and new JIRA system so that old links will continue to work.
Please be patient as we make the transition. Thanks!

Java no es gratuito
Blog de Diseño Web Vida MRR 14 05 2019

Java ha evolucionado a un paso siempre desigual con cada versión, lo que hace que sea odiado y amado por la comunidad de desarrolladores. El otro tema que tiene Java es que Oracle es el dueño del lenguaje, y aunque sigue siendo Open Source, tiene sus propias restricciones para poder usarlo. En este video les explico por qué Java no es gratuito en una parte importante de sus componentes, ya que es importante saberlo para poder crear aplicaciones con otras necesidades y aplicaciones.

everythingyoudosuckscon.io
MonkeyUser 14 05 2019

 |
Si estás buscando razones para poder empezar con un lenguaje de programación, este post te va a interesar. Te voy a comentar algunas razones por las cuales es mejor empezar en el mundo del desarrollo con algunos lenguajes y después con otros.
Lenguajes de propósito común
Los lenguajes de propósito común son aquellos que no están orientados a un tema específico. Los puedes usar para hacer aplicaciones web, sistemas, aplicaciones con interfaz gráfica, etc, por lo que aprender uno de estos facilita la aplicación a varias utilidades.
Python: es uno de los lenguajes más fáciles para empezar con programación. Su sintaxis también es muy simple, por lo que puedes entender bien cómo va funcionando el código y las estructuras, además de que Python poco a poco se convierte en el lenguaje preferido para la gente que empieza con programación.
Javascript: es un real competidor a sentarse en el trono de los lenguajes favoritos para empezar. Javascript ha evolucionado de forma impresionante en unos pocos años para poder ser utilizado en cualquier plataforma y ecosistema presente hoy en día. No hay nada que no se pueda hacer con Javscript, y como menciono, su evolución va avanzando de forma increíblemente rápida, pero obviamente si lo que quieres es tener un enfoque un poco más web, este lenguaje te puede ayudar mucho.
Ruby: es un lenguaje con la característica de que tiene soporte de muchos paradigmas de programación, como la lineal, la orientada a objetos y funcional. Su sintaxis es más parecido a una estructura de conversación que los anteriores, y te dejará compilar el código aunque tenga errores, por lo que es bastante amigable para poder empezar.
Java: es el lenguaje que más gustos divide a los programadores. Para muchos ya es un lenguaje que no ha evolucionado de la misma forma que los demás, pero otros creen que es de los lenguajes más maduros. La realidad es que si quieres iniciar con un lenguaje que te explique de forma muy visual la programación orientada a objetos este es el mejor. Aprender Java es fácil, quizá verás que tiene mucho código para hacer cosas sencillas, pero también hay una razón para ello, y si logras entender ese concepto prácticamente Java lo dominas en unas cuentas semanas.
Lenguajes de propósito específico
Si queremos aprender algo específico podemos usar de referencia algunos de los siguientes lenguajes para empezar por ese camino:
Machine Learning: los dos más populares son Python y R, lenguajes que por su simpleza en el código son más eficientes para realizar cálculos estadísticos.
Desarrollo móvil: para desarrollar aplicaciones móviles nativas tenemos Swift para iOS y Java y Kotlin para Android. Kotlin especialmente toma mucha referencia de Java y le quita el código que no es necesario, por lo que también es buen candidato para hacer apps sin siquiera saber programar.
Startups: si tu enfoque es construir algo rápido y funcional Ruby tiene esa ventaja. Ruby es muy usado en empresas que empiezan por la flexibilidad de construir aplicaciones de forma muy rápida y que pueden seguir programando sobre la marcha.
Lenguajes que tienes que evitar al empezar
Si bien hay lenguajes muy populares hoy en día, mi recomendación es evitarlos ya que o cumplen un propósito demasiado específico, que quizá ni siquiera te interese usar, o tienen una complejidad más elevada para aprender, por lo que puede que te desilusionen si decides elegir uno de ellos.
Entre los ejemplos está Go, Scala, Perl, Typescript, C++. Typescript especialmente le agrega complejidad a Javascript, y se entiende que para llegar ahí, entiendes cómo funciona Javascript y las deficiencias que tiene por las que tienes que cubrir con Typescript. C++ es en definitiva la opción si lo que quieres es administrar memoria y objetos de forma detallada y completa en un lenguaje de programación.
Hacer una PWA con Angular
Óscar Lijó 08 05 2019
Hoy en día se hace mucho hincapié en las aplicaciones web progresivas o PWA, hoy voy a explicar como hacer una PWA con Angular. En primer lugar, por si no has escuchado hablar nunca de lo que son las PWA y las ventajas que tienen, voy a hablar un poco de ellas. ¿Qué es una…
La entrada Hacer una PWA con Angular aparece primero en Óscar Lijó.

Deja vu
MonkeyUser 07 05 2019
If you have a public facing Django site in multiple languages, you probably want to let Google and other search engines know about it.

En este post les comparto los 10 principios de diseño para la programación orientada a objetos, esperando que les sirva para mejorar la forma en que hacen código y lo usan.
1. DRY (Don't repeat yourself)
El principio de la POO es la de no repetir el código, hacer código reusable y abstracto, para que puedas usarlo de nuevo sin necesidad de volver a escribir desde cero. Si tu código es imposible de reusarlo en otra aplicación, o tienes que programar ciertas partes de nuevo porque no se puede adecuar, es un síntoma de que necesitas hacer funciones más abstractas, más genéricas para que puedan ser extendidas con requerimientos más puntuales.
2. Encapusla
No hay mucha gente que entienda la importancia de la encapsulación, pero es muy simple. Aprende a encapsular el alcance de tus clases. La forma más fácil de hacerlo es poniendo privadas las variables y métodos que son exclusivos de tu clase, y poniendo públicos los métodos que pueden ser usados por otros objetos. Hay más formas de encapsular el código, pero esos dos son los básicos.
3. Principio de diseño abierto-cerrado
Este principio dice que las clases, métodos y funciones deben estar abiertos para extender su funcionalidad, pero cerrados para ser modificados. Esto significa que tu código debería ser modificado casi nunca pero sí debería servir como base para extenderlo, es decir, para usar herencia, para usar interfaces, para ser la base de nuevas clases, a fin de que nunca llegues a modificar tu código existente para crear nuevo, sino crear código sobre la base que ya tienes.
Esto podemos verlo como si fuera una caja negra, donde tu debes hacer que tu código sea imposible de modificar y solo pueda ser usado desde sus métodos públicos para poder ser extendido.
4. Principio de responsabilidad única
Este principio hace referencia a que nuestras clases y métodos deben tener una sola tarea o actividad. Una clase que se encarga de operar datos no debería administrar componentes gráficos, ni un método que tiene que mandar un correo electrónico debería manejar funciones adicionales. Esto hace que tus funciones cumplan un solo propósito y hace más fácil que las puedas utilizar más adelante.
5. Inyección de dependencias
Las dependencias es cuando en una clase necesitas otra para poder trabajar. Piensa en una clase que toma como base otra para mandar un mensaje de texto. La clase original tiene una dependencia y si quisieras usar esa clase pero no quisieras mandar un mensaje de texto hace que tengas que modificar el código para ello. La mejor forma de resolver un problema así es a través de la inyección de dependencias en donde en vez que que la clase original mande a llamar a la segunda clase, se le inyecte a través del uso de frameworks o interfaces para mandar a llamar a algo que después tiene que ser completado, y de esa forma no dependa de otras clases.
6. Composición sobre herencia
La composición es justamente lo opuesto a la herencia, que es mandar a llamar objetos en vez de heredarlos. Esto es bueno en la medida en que a partir de una misma relación en vez de estar heredando clases y hacer una jerarquía grande, muchas veces para simplificar trabajar con objetos de una misma base en mejor hacerlo a través de la composición o creación de objetos. Para saber más sobre composición y asociación pueden leer este artículo.
7. Principio de sustitución Liskov
Este principio dice que si tienes un objeto de subtipo S que deriva de un tipo T deberías tener la posibilidad de usar el objeto de tipo T de la misma forma que uses al subtipo S. Como ejemplo, tenemos que un objeto de tipo Perro deriva de un objeto de tipo Animal, y si tienes una función que necesita un tipo Perro como parámetro, si colocas un objeto de tipo Animal debería funcionar la clase de la misma forma, sin errores.
8. Principio de segregación de interfaces
Este principio refiere a que no incluyamos métodos que no va a utilizar el programador en una interfaz. Cuando creamos interfaces podemos colorcar métodos que queremos que el programador use para extender su código, pero si metemos funciones que no va a usar o no siempre va a usar, estamos cayendo en este error de POO.
9. Programación de interfaces no implementaciones
Tu código siempre debe estar enfocado a definir interfaces, no implementación de las mismas. Las interfaces ya nos dan una forma abstracta de poder hacer funciones genéricas que puedan ser usadas en muchos escenarios. Hay que mantener esa estrategia para crear código que puedas reusar.
10. Principios de delegación
Este último principio dice que no hay que hacer todo el código nosotros, ya hay clases a las que le podemos delegar esa tarea, como por ejemplo comparar dos objetos. Todos los objetos tienen la clase equals() por lo cual es innecesario implementar un nuevo método para esa funcionalidad. Es un ejemplo básico pero nos dice que hay que conocer los métodos de los objetos para saber qué ya hay código hecho que podemos usar y no todo a fuerza lo tenemos que implementar desde cero.
End of Year Review 2018-19
Blogs on Tom Spencer 04 05 2019
End of Year Review 2018-19
Blogs on Tom Spencer 04 05 2019

Bug Free
MonkeyUser 30 04 2019
![]()
A quantum bug in Firefox Quantum
WhoTracksMe blog 29 04 2019

Curiosity
MonkeyUser 23 04 2019


Parte 1: No olvides los fundamentos
- Conoce tu marca: siempre recuerda que el logotipo debe representar a tu marca, identificarse y ser único. Al final tu marca y logotipo deben transmitir el mismo mensaje
- Obten inspiración: busca nuevas formas, colores y mensajes, no te bases solo en las tendencias o en lo que todos están implementando justo ahora. Crea algo que sea moderno sin tener que ser repetitivo o parecido a algo que ya se ha visto antes.
- Inicia un tablero de humor: usa servicios como Pinterest para empezar a ver imágenes de diferentes logotipos, tratando de identificar lo que te gusta de cada uno de ellos, y de ahí partir para crear algo adecuado para ti.
- Investiga tu audiencia: identifica para quién es ese logotipo. No todos los logotipos funcionan para todas las personas, así que identifica qué tipo de personas verían tu logo y sentirían lo mismo que tu, y que otras a lo mejor pueden interpretar otro mensaje que quizá necesites corregir.
Parte 2: 7 tips para crear logotipos excelente
- Identifica el tipo de logo: los hay desde solo poner tipografía, hasta colocar mascotas o formas identificables
- Escoge una esquema de colores: usa colores que coincidan con tu marca y las sensaciones que transmite. No todos deben ser colores vivos, también puedes usar esquema de grises o blanco y negro.
- Identifica un tipo de fuente: tanto las serifas o sin serifas o las personalizadas son importantes para dar más elegancia o más soltura al mensaje que das en el logo
- Haz un logo único: es imposible crear un logo que no se base en algo ya existente, pero trata que incluso tomando elementos que ya se han visto antes parezca nuevo.
- ¿Cómo están desempeñándose otros diseños?: hay logotipos con doble mensaje en el diseño, o que tienen un toque característico que los diferencia muy claramente. Aprende a identificar qué es lo que caracteriza a un buen logo existente y de ahí parte para darle autenticidad al tuyo.
- Manténlo simple y flexible: no te enredes tanto, siempre lo más simple va a ser lo mejor, pero trata de que se pueda adaptar a nuevos formatos y se vea fresco con el paso de los años.
- Publica tu trabajo pero no esperes un éxito instantáneo: el éxito de un logo no depende de que sea admirado al instante, sino que empiece a ser reconocido a lo largo del tiempo, así que no te limites en medir el éxito de tu logo al instante.

Conflict Management
MonkeyUser 16 04 2019


Me encuentro este interesantísimo artículo de FreeCodeCamp, en el cual comparan la velocidad y tamaño de algunos de los frameworks más famosos que hay para front-end. Si bien cada uno de ellos está enfocado en dar un resultado más o menos parecido, creo que muchos se han preguntado si estos frameworks son realmente un alivio para la gente que diseña aplicaciones web, o solo es un sobre costo que se añade por el hecho de tener un código más ordenado y con posibilidades de mantenerlo mejor.
El análisis que les presento muestra algunas estadísticas que el autor tomó para medir el impacto de cada framework. En primer lugar el construyó la misma aplicación para los siguientes frameworks:

Después de eso empezó con sus métricas.
Rendimiento
Es quizá el punto más importante para todos. De nada sirve tener un framework si el rendimiento del mismo se ve afectado. Siempre hay que tener en cuenta que el rendimiento más óptimo debería ser el poder crear nuestras aplicaciones sin necesidad de un framework. Si acudimos a ellos es porque deberíamos suponer que mucho del tunning de ese rendimiento ya lo trabaja ese framework. El resultado es como sigue:

La mayoría de los frameworks corren por arriba de los 90 puntos, eso quiere decir que prácticamente en cuanto carga tu sitio o aplicación web, también lo hace el framework y sus componentes, a excepción de AngularJS que tiene el desempeño más bajo.
Tamaño
El tamaño es la cantidad de kb que tiene que transferirse para poder cargar tu aplicación web. Entre más grande sea mayor va a ser el tiempo de carga.


Mientras que hay frameworks que solo tienen 9kb de transferencia, hay otros como AngularJS que transfieren hasta 300kb. Esto en perspectiva podría parecer muchísimo, pero también dependiendo de la calidad de la conexión a internet es que se afecta mucho más esa transferencia.
Líneas de código
Las líneas de código es de los parámetros más importantes para un desarrollador. No tiene sentido que tengas que tener más líneas de código solo por usar un framework, si el objetivo inicial es justo simplificar ese proceso de creación con menos líneas.


En la imagen podemos ver que mientras para re-frame un proyecto requirió de 968 líneas de código, el mismo en Angular con ngrx y nx requirió 4,210 líneas de código, es decir, poco más de 4 veces, entonces aunque mucho código lo podrías generar y otro hacerlo tu, la realidad es que se entiende que más líneas de código podría aumentar el tamaño de tu proyecto, y en consecuencia hacerlo un poco más pesado.
Conclusión
Como mencionan en el artículo, no es muy fácil hacer comparaciones de peras con peras y manzanas con manzanas. Es importante notar que podría haber un sesgo pero los datos nos revelan mucha información. Lo que más me sorprende de esas gráficas es que por ejemplo, Vue, React y Angular, a pesar de que son los frameworks más usados, no son ni los más rápidos ni los más pequeños. Hay frameworks que son más ligeros, y si te interesa usar uno pero te interesa cuidar estas tres métricas la respuesta es que puedes optar por utilizar uno diferente a los 3 más populares.
If you ever had to maintain a traffic heavy Django site, you probably had to deal with graceful migrations. In the article I explain what atomic and reversible migrations are, how to execute "raw" SQL in migrations the right way, and how using a little known migration command we can completely alter the Django migrations built-in behavior.
Lazy loading nativo
Óscar Lijó 09 04 2019
Haciéndome eco de la reciente publicación de Addy Osmani en su blog, nos encontramos con que dentro de poco el Chrome va a implementar una manera de conseguir hacer lazy loading nativo. Esta es una noticia fantástica. Pero el notición sería que el atributo que van a usar fuera recogido por el estándar de HTML…
La entrada Lazy loading nativo aparece primero en Óscar Lijó.

Code Review
MonkeyUser 09 04 2019

|
La consola de Google Chrome tiene muchas funcionalidades que nos pueden ayudar de forma muy interesante en nuestro debugging. En este post les presento algunos de los trucos más interesantes que seguramente les van a servir la próxima vez que tengan que desarrollar una aplicación con Javascript.
Estilizar mensajes de consola

Por defecto en la consola de Chrome los mensajes aparecen sin formato, pero si lo que necesitas es tener estilos para diferenciar ciertos mensajes basta con ingresar '%c' al inicio del mensaje de un console.log y colocar como un parámetro adicional los estilos CSS que quieres poner.
Mostrar JSON como tabla

De forma sencilla podemos mostrar un JSON en formato de tabla con el siguiente script:
Obtener las llaves de un arreglo

Dado un arreglo se pueden extraer las llaves o claves de la siguiente forma:
Obtener el elemento seleccionado
Podemos hacer referencia al elemento HTML seleccionado con el símbolo $0, y poder navegar por el historico de elementos seleccionados con $1, $2,etc
Referenciar objetos HTML
Tradicionalmente usamos document.getElementById() o querySelector() para hacer referencia a objetos. En la consola de Chrome podemos hacer referencia usando la simbología de $('selector'), muy parecido a como se hace con jQuery, pero esta es una forma nativa de hacerlo en la consola de Chrome.
Obtener eventos configurados en elemento HTML

Se pueden ver de forma sencilla los eventos configurados en un elemento HTML así:
Monitorear todos los eventos sobre un elemento HTML

Se pueden monitorear todos los eventos sobre un elemento específico, usando dos comandos: monitorEvents() y unmonitorEvents()
Medir tiempo de ejecución de un procedimiento

Puedes calcular el tiempo que tarda un procedimiento en ejecutarse usando dos funciones: console.time() y console.timeEnd()
Mostrar todas las propiedades de un elemento HTML

Usando la función dir(selector) se puede mostrar todo lo que contiene un elemento HTML
Hacer referencia a la última expresión resultante

La última expresión en la consola también puede asignarse a una variable $_ la cual siempre tendrá el valor más reciente calculado dentro de la misma.
Info
Puedes visionar este artículo y descargártelo como notebook ipython en http://nbviewer.jupyter.org/5177340
Mucha gente, cuando se enfrenta por primera vez al lenguaje python, no entiende bien el concepto de “inmutabilidad” que tanto repite la documentación al tratar de diferenciar algunos tipos contenedores como tuplas, listas, conjuntos y diccionarios.
Por lo general, la gente formada en lenguajes de programación clásicos tiene la idea de que las variables son porciones de memoria donde colocar valores. Que una variable no se éso, variable, resulta un contrasentido. Han visto constantes, pero sólo sirven para inicializar variables y poco más. Si en su carrera hubieran sido formados en algún lenguaje funcional se darían cuenta que hay quienes piensan que las variables que cambian de valor son las raras, que lo más natural es que una variable conserve su valor inicial, o sea, que sea inmutable.
Por poner un ejemplo, el siguiente código está basado en una pregunta reciente en la lista python-es. Tenemos una lista de pares y queremos quitar las parejas repetidas con orden cambiado:
def quitar_dup(lista):
for item in lista:
item.reverse()
if item in lista:
lista.remove(item)
return lista
L=[[1, 2], [1, 3], [2, 1], [3, 1]]
print quitar_dup(L) #res: [[1, 3], [3, 1]]
A simple vista, el código parece correcto, pero tenemos dos operaciones que pueden mutar listas: .reverse() y .remove(). De hecho, el resultado es incorrecto: [[1, 3], [3, 1]]
A medida que recorremos la lista en el bucle for, la lista se va modificando, lo que da lugar a resultados inesperados. Si no lo ves bien, basta añadir algunos prints en lugares estratégicos para que comprobar lo que pasa. De hecho, sólo existen dos iteraciones para cuatro elementos que tiene la lista.
Otro tipo de casos son cuando pasamos listas a funciones:
>>> def add(a, l):
... if a not in l:
... l += [a]
... return l
...
>>> L = [1, 2, 3]
>>> add(1, L)
[1, 2, 3]
>>> add(4, L)
[1, 2, 3, 4]
>>> L
[1, 2, 3, 4]
Como efecto colateral, la función ha modificado la lista pasada como argumento, algo que no es siempre deseable. El problema se agrava más si empleamos listas en valores por defecto:
>>> def add(a, l=[]):
... if a not in l:
... l += [a]
... return l
...
>>> add(1)
[1]
>>> add(2)
[1, 2]
>>> add(3, [])
[3]
>>> add(4)
[1, 2, 4]
Como se puede ver, aunque intentemos resetear el valor por defecto, la función tiene un efecto memoria que es imposible de eliminar. Este efecto es a veces buscado, pero en general debe ser siempre evitado ya que desvirtúa el sentido que tiene dar valores por defecto.
Estos efectos son todavía más perniciosos con la funciones lambda. Al carecer de una clausura como las funciones, la evaluación de una función lambda depende del scope donde han sido definidas. Por ejemplo, observa esta creación de una lista de funciones:
fns = []
for i in range(5):
fns.append( lambda x: x + i)
print fns[1](10)
print fns[2](10)
Siempre añade 4 al argumento, que es el valor de i al acabar el bucle, independientemente de qué valor tenía esta variable en el momento de crear la función lambda. No es de extrañar que se recomiende dejar de usar estas funciones.
Por último, otro efecto funesto de la mutabilidad de las listas aparece en la creación de listas multidimensionales (aka matrices). Una forma rápida de crear una matriz de 2x2 es: [[0]*2]*2. El problema aquí está en que cuando clonamos listas, en lugar de copiar los elementos, los enlaza entre sí. Quizás se vea mejor si hacemos alguna operación:
>>> l = [[0]*2]*2
[[0, 0], [0, 0]]
>>> l[0][0]
0
>>> l[0][0] = 1
>>> l
[[1, 0], [1, 0]]
>>> l[0] is l[1]
True
Los elementos l[0] y l[1] son el mismo elemento. Que los elementos de una lista puedan estar entrelazados resulta muy interante para algunos algoritmos de búsquedas. Pero hay que conocer bien lo que estamos haciendo si no queremos llevarnos alguna sorpresa.
Recomendaciones para hacer código funcional
Copia de listas
En funciones y métodos, si recibimos una lista como argumento, la primera acción defensiva que deberíamos hacer es copiar la lista en una variable local y trabajar solo con la variable local desde ese momento. Con una asignación directa no se realiza una copia, más bien estaríamos enlazando una nueva referenciasin solucionar nada.
La forma consensuada entre programadores python de copiar una lista es con la operación de spliting L[:], aunque sirven otras operaciones idempotentes como L*1 ó L+[]1. Para listas de elementos entrelazados tendremos que acudir a otros mecanismos de copia como los que ofrece el módulo copy, aunque no será frecuente que lo necesitemos.
def add(a, lista):
l = lista[:]
if a not in l:
l += [a]
return l
En cuanto a los argumentos por defecto, lo mejor es no usar nunca una lista para tal cosa. Una buena estrategia defensiva consiste en usar None de esta forma:
def add(a, lista=None):
l = [] if lista is None else lista[:]
if a not in l:
l += [a]
return l
Operaciones inmutables con listas
En cuanto a evitar las operaciones que mutan listas, siempre hay alternativas inmutables de todas estas operaciones. El siguiente cuadro puede servir como referencia:
| Mutable | Inmutable |
|---|---|
L.append(item) |
L+[item] |
L.extend(sequence) |
L + list(sequence) |
L.insert(index, item) |
L[:index] + [item] + L[index:] |
L.reverse() |
L[::-1] |
L.sort() |
sorted(L) |
item = L.pop() |
item,L = L[-1],L[:-1] |
item = L.pop(0) |
item,L = L[0],L[1:] |
item = L.pop(index) |
item, L = L[item], L[:item]+L[item+1:] |
L.remove(item) |
L=L[:item]+L[item+1:] |
L[i:j] = K |
L[:i] + K + L[j:] |
A la hora de decidir qué versión usar, la versión inmutable es más apropiada para programación funcional y resulta incluos más intuitiva de interpretar. No es extraño ver errores de código donde se espera resultados de las operaciones .sort() o .reverse(), que siempre devuelven None. Para el intérprete de python no hay error, pero a veces nos será difícil darnos cuenta de estos errores:
MODO ERRÓNEO: machacamos la lista con None
>>> l = [3, 5, 1, 2, 4]
>>> l_2 = [x*x for x in l.sort()]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'NoneType' object is not iterable
MODO CORRECTO
>>> l = [3, 5, 1, 2, 4]
>>> l_2 = [x*x for x in sorted(l)]
>>> l_2
[1, 4, 9, 16, 25]
-
De hecho, la operación
L*1es más eficiente queL[:]. ↩
Eliminar elementos de un array en Javascript es una tarea habitual para los que desarrollamos en este lenguaje. De hecho, para hacerlo existen una gran cantidad de maneras distintas, según cual sea la necesidad. Seguramente algunas te sonarán y otras no tanto. Pero al final de este post tendrás un cuadro completo de los métodos…
La entrada Eliminar elementos de un array en Javascript aparece primero en Óscar Lijó.

Gradient Banner
The HR Manifesto

Grabient Landing Page
D25/Video Production

Centexus Landing Page
Ninety Nine Seconds Game Prototype
DIY Course Landing Page
Natoni Landing Page

Bitframemedia Logo

TinyMind Landing Page
Mindfulness App Onboarding Screens



Para aquellos que empiezan su carrera de freelancer y no saben cómo iniciar su proceso de venta de proyectos, este es el video perfecto para ustedes. No es que sea un arte, pero sí se necesita cierta habilidad para poder vender nuestros proyectos, empezando con buscar a clientes potenciales.
Una vez que sepas a qué tipo de clientes les vas a vender, necesitas saber tu modelo de negocios. En este video les comparto uno de ellos, que es de los más populares actualmente, que es el modelo de servicios. Si te quieres iniciar a vender proyectos la mejor forma es con un esquema de servicios, en donde distribuyes tus costos a lo largo de suscripciones con tus clientes, de tal forma que en vez de que te paguen una sola vez, te paguen constantemente para que tu les sigas ayudando de forma indefinida, o al menos hasta que ya no necesite tus servicios.
El modelo de suscripciones es usado por muchísimos servicios como Netflix o Spotify, y te permite a ti como desarrollador tener presencia con tus clientes de forma constante, a través de seguimiento de proyectos, de soporte o de otros beneficios que harán que te paguen también una cantidad pequeña mensualmente, y que al final para ti es un ingreso que solamente se distribuye a lo largo del tiempo.

End of the line
MonkeyUser 02 04 2019


La escuela nos enseña ciertas habilidades y tecnologías que nos deben servir en nuestra vida, sin embargo, queda en nosotros seguir el aprendizaje necesario para seguir conociendo lo más nuevo en nuestro entorno. Para un estudiante de ingeniería que desea tener un trabajo como desarrollador o ingeniero en sistemas la cosa no es diferente. Hay habilidades y tecnologías que no aprenderá en la escuela, y es importante desarrollarlas y aprenderlas, porque van a servir de una forma u otra.
Vamos a aprender cuáles son esas habilidades que no nos enseñan en la escuela, pero de todas formas necesitamos aprender.
Git

Git es una de las tecnologías que deberías conocer sin importar si te la enseñan o no en la escuela. Desarrollar la habilidad de versionar tu código, hacer modificaciones y darle un mantenimiento adecuado por medio de branches es una habilidad que, aunque pareciera sorprendente, no todos los desarrolladores saber hacer. Conocer Git te va a dar no una ventaja, sino te va a dar lo indispensable que se necesita en cualquier rol de desarrollo y que no te dicen que lo necesitas hasta que lo tienes que ocupar.
Comunicación

Aprender a comunicarse es una habilidad que no nos enseñan en ningún lado. Cada persona, organización y yo diría que hasta región donde estemos tiene su propia forma de comunicarse, pero es indispensable saber hacerlo para poder obtener resultados. Un problema común de comunicación es saber pedir las cosas, quizá que algún colaborador nos ayude con nuestro código. Algo tan simple como eso puede ser interpretado como que no tienes los conocimientos, o tienes flojera, o quieres que alguien más haga tu trabajo.
Un ejemplo de comunicación efectiva para pedir apoyo en el ejemplo anterior es que se maneje un mensaje de contexto. Si en vez de ir directo a pedir apoyo, se explica todo lo que ya hiciste para llegar al punto donde no puedes avanzar, quizá la otra persona en vez de negarte el apoyo pueda entender que no estás pidiendo ayuda por flojo, sino porque ya recorriste una serie de pasos y nada funcionó. Esto le da un incentivo de poder serte útil y a la vez no crea que está haciendo tu trabajo.
Escribir

Para muchos escribir es plasmar sus pensamientos en un correo o una carta, y la realidad es que no. Escribir correctamente tiene que ver con saber transmitir un mensaje a un grupo de personas, y que esas personas tengan el mismo significado al leer tu mensaje. No todos podemos tener las estructuras gramaticales para elaborar textos complejos, pero sí deberíamos tener la capacidad de redactar un mensaje de tal forma que la intención que tenga se pueda transmitir, y nosotros obtengamos una respuesta.
A nivel de código es importante saber documentar nuestros proyectos, saber documentar errores y poder pedir apoyo usando la técnica de comunicación que mencioné en el punto anterior. Dar mensajes claros en pocas palabras siempre va a ser el objetivo al momento de escribir, ya que la gente no perderá tiempo leyendo un texto sin saber qué es lo que estás queriendo decir o pedir.
Codecademy vs. The BBC Micro
Two-Bit History 31 03 2019
Para hacer una redirección en Javascript tenemos diferentes métodos. Y prácticamente todos hacen lo mismo, pero hay matices. Veamos las dos maneras clásicas de hacerlo. La primera es usando window.location.replace(...) y es la manera más correcta de hacerlo. La razón es sencilla estamos hablando de hacer una redirección en Javascript, no de hacer una navegación.…
La entrada Como hacer una redirección en Javascript aparece primero en Óscar Lijó.

Possible Code Contents
MonkeyUser 26 03 2019

Hace unos pocos días Angel, en uGeek, publicó un interesante artículo sobre como crear un bot de telegram con Bash. Igualmente, por mi parte, la semana anterior había publicado un artículo sobre como podías crear tu propio bot con PHP. En este contexto y en el grupo de telegram de uGeek, comenté que se podía hacer de forma similar, un bot en Python para Telegram. Fue justo en ese momento, donde Pedro, MosqueteroWeb, nos propuso un duelo.
Y es que no lo puedo evitar. Ya lo comenté en el capítulo número 1 del podcast titulado el peligro de las apuestas. Y es que no puedo resistirme a un reto. Y esta es la razón de este nuevo artículo, que irá encasillado en el tutorial sobre bots para Telegram.
En este nuevo capítulo del tutorial, te explicaré como puedes utilizar Python para enviar mensajes, imágenes y audios, de forma relativamente sencilla a un canal o grupo de Telegram. Eso si, el objetivo de este capítulo es hacerlo sin ninguna librería extra.

Un bot en Python para Telegram
Tal y como te he comentado en la introducción, el objetivo de este nuevo capítulo del tutorial es implementar un bot en Python, sin necesidad de utilizar ninguna librería externa. Me refiero claramente a una librería cuyo objetivo sea facilitar el acceso a la API de bots de Telegram. Comento este punto, porque si que utilizaré una librería para realizar las llamadas GET y POST, me refiero a Requests.
Por otro lado, lo que verás en este capítulo no es un bot en si. Se trata de llamadas a la API. Implementar un bot, considero que es algo mas complejo que una simple llamada. Un bot, debería permitir interactuar con el usuario. Es decir, el bot debe ser capaz de responder ante las acciones del usuario. Incluso, implementar botones, para facilitar esa interrelación entre bot y usuario.
Ahora bien, esto último, esta interrelación no es mas que seguir el capítulo 10 de este tutorial en el que te explico lo relacionado con bots, Flask y Nginx.
Requests
Requests es una librería para HTTP, liberada bajo licencia Apache2, que tal y como la definen sus propios desarrolladores, escrita en Python para seres humanos. La ventaja de utilizar esta librería es que evita las complicaciones de trabajar con HTTP, haciendo que una llamada sea muy, pero que muy, sencilla.
Esta librería está disponible tanto para las versiones 2 y 3 de Python. Sin embargo, lo recomendable es utilizar Python 3, y en este sentido, utilizaré esta versión.
Instalar Requests para Python 3 en Ubuntu, y en derivadas de Debian, es tan sencillo como ejecutar,
sudo apt install python3-requestsAunque dependiendo de lo que quieras hacer, es posible que lo recomendable sea crearte un entorno virtual en Python, lo que te permitirá olvidarte del sistema en el que estés trabajando.
Pasos previos
Con independencia del lenguaje de programación o si utilizas librería o no, es necesario crear el bot. Con este objetivo, Telegram dispone de un bot para crer bots. Se trata de BotFather. Te recomiendo que leas el primer capítulo del tutorial sobre crear tu propio bot para Telegram.
Enviar mensajes a Telegram con tu bot en Python
Una vez te he comentado los puntos de partida, y ya has creado tu bot con BotFather, ya puedes enviar tu mensaje. En python es tan sencillo como crear un archivo de texto, que puede ser mensaje.py, con el siguiente contenido,
#!/usr/bin/env python3
import requests
requests.post('https://api.telegram.org/bot<TOKEN>/sendMessage',
data={'chat_id': '<CHAT_ID>', 'text': '<TEXTO>'})Donde,
<TOKEN>token que te ha propocionado BotFather.<CHAT_ID>identificador del canal o grupo donde envías el mensaje.<TEXTO>texto del mensaje que quieres enviar.
Como ves, el compromiso lo he cumplido, en una línea he conseguido enviar un mensaje sin necesidad de librerías externas, a excepción de Requests. Si, es realmente sencillo.
Si quieres ver la respuesta de Telegram, hay que modificar ligeramente el script, tal y como te indico a continuación,
#!/usr/bin/env python3
import requests
r = requests.post('https://api.telegram.org/bot<TOKEN>/sendMessage',
data={'chat_id': '<CHAT_ID>', 'text': '<TEXTO>'})
print(r.text)Dado que lo que nos devuelve es un json, si quieres aprovechar las facilidades que te da Python, puedes utilizar directamente el módulo json para conocer si la respuesta es correcta. Así, de nuevo, modificamos el script, añadiendo estas matizaciones,
#!/usr/bin/env python3
import requests
import json
r = requests.post('https://api.telegram.org/bot<TOKEN>/sendMessage',
data={'chat_id': '<CHAT_ID>', 'text': '<TEXTO>'})
data = json.loads(r.text)
print(data['ok'])Parámetros opcionales
Además del parámetro text también se pueden enviar algunos parámetros opcionales que te van a permitir adaptar el mensaje a tus necesidades. Estos parámetros, comunes a otros métodos, son los siguientes,
parse_modese refiere al formato del mensaje. Aquí tienes dos opciones oMarkdownoHTML. Mi consejo es que utilicesHTMLporque en mi caso he tenido algunos problemas con el guión bajo del markdown.disable_web_page_preview. Cuando se ponen enlaces en los mensajes, Telegram por defecto te muestra una previsualización de la página correspondiente. Con esta opción puedes habilitar o deshabilitar esa previsualización.disable_notification. Cada vez que recibes un mensaje en un grupo un canal, como bien sabes, recibes una notificación, salvo que lo hayas limitado temporal o definitivamente. Sin embargo, tu puedes con este parámetro que no se envie notificación.reply_to_message_id. Esto parámetro lo puedes utilizar para el caso de que estés respondiendo a otro mensaje. Por ejemplo, te puede ser de utilidad para una cadena de mensajes.reply_markup. En esta opción puedes introducir parámetros adicionales, como puede ser un teclado en línea. Esto lo veremos en un capítulo posterior.
Pasando argumentos
Esta solución para enviar siempre el mismo mensaje no está mal. Sin embargo, si lo que queremos es enviar diferentes mensajes a diferentes canales, lo suyo es que pasemos, tanto el identificador del canal o grupo, como el mensaje al script. Igualmente esto es muy sencillo. Tan solo tenemos que introducir algunas ligeras modificaciones en nuestro script.
#!/usr/bin/env python3
import requests
import sys
if __name__ == '__main__':
if len(sys.argv) > 2:
requests.post('https://api.telegram.org/bot<TOKEN>/sendMessage',
data={'chat_id': sys.argv[1], 'text': sys.argv[2]})Como primer parámetro pasaremos el identificador del chat, mientras que como segundo parámetro el texto. En este caso el texto debe ir entre comillas.
Enviar imágenes a Telegram con tu bot en Python
Una vez que ya has visto lo sencillo que es enviar un mensaje de texto utilizando Python, vamos a algo ligeramente mas complicado. Vamos a enviar una imagen. En este caso tenemos dos opciones, o bien, enviamos la url de la imagen, en el caso de que ya esté en subida a algún servidor, o como segunda opción la subimos. Esto, con requests es realmente sencillo.
- Primer caso. Utilizamos una imagen disponible en algún alojamiento web,
requests.post('https://api.telegram.org/bot<TOKEN>/sendPhoto',
data={'chat_id': <CHAT_ID>, 'photo': <PHOTO_URL>, 'caption': <TEXT>})En este caso debes indicar la ruta donde está alojada la imagen, así como el título o un texto que acompañe la imagen. Esto último es opcional, si no le quieres añadir un texto, simplemente, no pongas ese último parámetro.
- Segundo caso. Subimos nuestra propia imagen,
requests.post('https://api.telegram.org/bot<TOKEN>/sendPhoto',
files={'photo': (<ARCHIVO>, open(<ARCHIVO>, 'rb'))},
data={'chat_id': <CHAT_ID>, 'caption': <TEXT>})Aquí <ARCHIVO> se corresponde con la ruta donde se encuentra el archivo de la imagen que queremos subir a Telegram.
¿Fácil verdad?
Enviar audio y voz a Telegram con tu bot en Python
Una vez hemos superado las opciones para enviar mensajes e imágenes, vamos al siguiente paso, de este artículo, que es enviar audio.
En este caso, también tienes dos opciones para enviar audio. La primera de las opciones es enviarla como un mensaje de voz, mientras que la segunda es como un archivo de audio. Así, en el primer caso, como mensaje de voz sería tal y como ves a continuación,
requests.post('https://api.telegram.org/bot<TOKEN>/sendVoice',
files={'voice': (<ARCHIVO>, open(<ARCHIVO>, 'rb')),
'thumb': (<ARCHIVO2>, open(<ARCHIVO2>, 'rb'))},
data={'chat_id': <CHAT_ID>, 'caption': <TEXT>})En este caso, también es posible añadir un parámetro extra que es la duración del mensaje de voz en segundos. Para esto utiliza duration.
Mientras que el segundo, como archivo de audio, será de la siguiente forma,
requests.post('https://api.telegram.org/bot<TOKEN>/sendAudio',
files={'audio': (<ARCHIVO>, open(<ARCHIVO>, 'rb')),
'thumb': (<ARCHIVO2>, open(<ARCHIVO2>, 'rb'))},
data={'chat_id': <CHAT_ID>, 'caption': <TEXT>})Además de los parámetros anteriores, es posible enviar un nuevo un nuevo archivo. Este tipo de archivo es lo que se conoce como una miniatura o en inglés thumbnail. Y es la típica imagen que acompaña al mensaje de voz. Aunque lo cierto es que lo he visto en pocas ocasiones.
La parte de la miniatura es completamente opcional, y por tanto la puede omitir. Al igual que en otros casos, también se puede utilizar un enlace a una imagen que ya esté disponible desde un servidor. Así, en ese caso, el método tendría el siguiente aspecto,
requests.post('https://api.telegram.org/bot<TOKEN>/sendAudio',
files={'voice': (<ARCHIVO>, open(<ARCHIVO>, 'rb'))},
data={'chat_id': <CHAT_ID>, 'caption': <TEXT>, 'thumb': <THUMB>})Indicarte que las características de las miniaturas están fijadas. En este sentido el archivo tiene que ser en formato JPEG y tener un peso máximo de 200 kB, y unas dimensiones iguales o inferiores a 90 px.
En ambos casos la parte del título es opcional, con lo que de nuevo, la puedes omitir. Además es posible, añadir algunos parámetros opcionales, como puede ser el formato del texto. En cualquier caso, te recomiendo una visita a la documentación de la API de bots, para tener siempre la última documentación.
Enviar una video nota
Desde hace recientemente poco, en referencia a la publicación de este capítulo del tutorial, es posible enviar vídeos desde Telegram con una duración inferior a un minuto. El método que tienes que utilizar será el siguiente,
requests.post('https://api.telegram.org/bot<TOKEN>/sendVideoNote',
files={'video_note': (<ARCHIVO>, open(<ARCHIVO>, 'rb')),
'thumb': (<ARCHIVO2>, open(<ARCHIVO2>, 'rb'))},
data={'chat_id': <CHAT_ID>, 'caption': <TEXT>,
'duration': <DURATION>, 'length': <LENGTH>})Los únicos parámetros obligatorios son el archivo de vídeo y el identificador del chat. El resto de parámetros son totalmente opcionales. Como ves, aquí he incluido dos nuevos. Por un lado la duración del vídeo y la dimensión del vídeo. Este caso se corresponde con el diámetro.
Enviar cualquier tipo de archivo a Telegram con tu bot en Python
Si en lugar de una imagen o un audio quieres enviar cualquier otro tipo de documento, existe un método específico para ello. El uso es el siguiente,
requests.post('https://api.telegram.org/bot<TOKEN>/sendDocument',
files={'document': (<ARCHIVO>, open(<ARCHIVO>, 'rb')),
'thumb': (<ARCHIVO2>, open(<ARCHIVO2>, 'rb'))},
data={'chat_id': <CHAT_ID>, 'caption': <TEXT>})Al igual que en el caso de enviar un archivo de audio, también es posible mostrar una pequeña miniatura que se corresponda con el documento que estamos enviando. De nuevo, esto es completamente opcional.
Conclusiones
Como puedes ver, en una sóla línea de código, o casi, es posible enviar un mensaje utilizando los bots de Telegram. La cuestión es que poco a poco, esto se va complicando a medida que quieres enviar otro tipo de archivos y documento. Aunque tampoco en exceso, como tu mismo has visto.
Dado lo extenso de los métodos del API de bots de Telegram, dejo para un nuevo capítulo otros métodos, que seguro te serán de utilidad. Y para un tercer capítulo dentro de esta mini serie, el uso de teclados en línea.
La entrada Un bot en Python para Telegram (y en una sola línea) aparece primero en El atareao.
Mezclar colores con CSS
Óscar Lijó 21 03 2019
Mezclar colores con CSS es un tema del que no se suele hablar mucho. Y eso que seguro que todos tenemos claros que mezclando colores obtenemos colores nuevos.Ya desde pequeños en el colegio jugábamos a mezclar colores con ceras o lápices. Luego fuimos aprendiendo que si mezclamos todos los colores de la paleta obtenemos negro…
La entrada Mezclar colores con CSS aparece primero en Óscar Lijó.
Hypermedia REST
Óscar Lijó 20 03 2019
Hypermedia REST es una manera de enfocar nuestras API REST. Actualmente existe un gran debate acerca cual es la mejor manera de construir una API. Entre las distintas tecnologías que existen podemos destacar SOAP y REST como las más conocidas tradicionalmente. Y posiblemente GraphQL como la especificación moderna mas prometedora. De hecho si quieres saber…
La entrada Hypermedia REST aparece primero en Óscar Lijó.

Sprint
MonkeyUser 19 03 2019

Stepping down from Fathom
Danny van Kooten 17 03 2019
I have an announcement to make. Less than a year ago, Paul Jarvis and I started working on Fathom (simple and transparent website analytics).
We managed to make a lot of progress during our first year and I’m more than a little proud of what Fathom is today. I’m running it on most of my sites and I’d say it’s very much a viable alternative for Google Analytics for a lot of websites already.
The open-source community around Fathom is very much alive and kicking. The GitHub repository for Fathom currently boosts over 5.000 GitHub stars and Fathom has been a trending Go project for pretty much every week over the last year!
And the Docker image has been pulled over a million times, even though Fathom is already a single (embedded) binary that is super easy to deploy to your infrastructure of choice. There’s even a one-click installer if you’re on DigitalOcean.
The software we built itself proved very effective in terms of performance. A single $5 VPS can easily handle tens of millions of pageviews per month, as proved by some of the bigger customers on Fathom’s PRO plans.
Stepping down
To think that Fathom would be so well received and grow so rapidly during its first year is amazing and I’m super proud to have been a part of that.
Have been, because going forward, I will not be actively involved with Fathom anymore. Fathom itself is not going anywhere though. Paul is now joined by Jack Ellis with whom he will be continuing the project. Having seen them work together during the handover phase, I completely trust in their abilities to keep making Fathom better.
I am a little sad to leave Fathom behind but juggling its responsibilities with being a newbie dad and running Mailchimp for WordPress while also wanting to spend less time behind a computer proved way harder than anticipated.
At the same time, I’m stoked to see their plans unfold over the next few months. I’m confident they will take good care of what we managed to build over the past year.
I knew it was possible, but I got to try it recently.
Here I run a test with fiveam. It fails. I tell fiveam to enter
the debugger on failures with
(setf 5am:*on-error* :debug)
so we have an immediate feedback and we can re-run the test from where it left off by choosing the appropriate restart.
Other test frameworks like Parachute allow that.
This is one of the things that make development in Common Lisp enjoyable and faster than with other workflows. Also, it’s built-in, there is no fancy editor plugin or configuration.
In the debugger:
<enter>on a backtrace shows more of itvon a backtrace goes to the corresponding line or function.- more options with the menu.
How to Use Grouping Sets in Django
Haki Benita 09 03 2019
How we cut a heavy admin dashboard response time in half with advanced SQL and some Django hackery. I recently had the pleasure of optimizing an old dashboard. The solution we came up with required some advanced SQL that Django does not support out of the box. In this article I present the solution, how we got to it, and a word of caution.


Github deja de dar soporte a jQuery, con lo que pasa a ser otro servicio que empezó a usar jQuery para poder dar servicio a todos sus usuarios y repositorios, pero ahora ya está dejando de lado la librería para poder usar frameworks modernos que no dependan tanto de una sola implementación.
En este video les explico las ventajas de migrar de jQuery, y los retos a los que se está enfrentando el equipo de desarrollo de Github al querer modernizar su sitio.
No olviden suscribirse a mi canal de Youtube para ver todo el contenido adicional que se genera para los desarrolladores y diseñadores web


Se pueden hacer diferentes tipos de animaciones en un sitio web, desde las básicas con CSS, las complejas usando Javascript, pero los sitios web que les presento llevan a otro nivel este tema. Les presento 10 sitios web con animaciones impresionantes, donde combinan CSS, SVG, WebGL y otras técnicas de animación para crear estos increíbles efectos de navegación en los sitios web










New Model
MonkeyUser 05 03 2019
These Years in Common Lisp 2018
Lisp journey 28 02 2019
It’s been already a little more than a year that I began my Lisp journey. I made quaterly news digests, mainly from reddit’s feed:
Time has come for a yearly overview ! What happened in the Common Lisp world ? Are there (or groundbreaking promising useful fun) projects, articles, discussions, tutorials ?
No need to say, I won’t reference everything we find in the quaterly posts, which don’t list all new projects appearing on Quicklisp (we can find these in the monthly Quicklisp releases) or Github.
I hope this overview will sharpen your interest on what is in my opinion an under-sold and still very promising language and plateform, that I happen to like more and more (and sooo more than Python ;) ).
Happy discoveries.
Table of Contents
Documentation
Common Lisp’s online documentation could be more thorough and welcoming. Fortunately, a few of us revived some projects and work on it -my favourite project being the Common Lisp Coobook. This year, we got tutorials on:
- Datastructures
- Debugging, including how to interactively debug a spacecraft,
- the Common Lisp Object System (CLOS)
- Loop, iteration, mapping
- Database access and persistence
- Error and condition handling
- Numbers and multidimensional arrays
- Scripting and building self-contained executables
- Working with types
along with many improvements on other pages, like on getting started and editor support.
Which brings me to it: the editors situation is much more open than you think:
- The editor of choice is still Emacs with Slime (or Sly),
- However, we can get started with Emacs and Lisp in 3 clicks with Portacle, a self-contained batteries-included sbcl-included portable Emacs tailored for CL,
- For Vim and NeoVim we have SLIMV, VLIME, and plugins can be written for NeoVim using cl-neovim.
- Or if we want an editor written in cl, there’s the self-contained Lem editor, which also works for Python, Go, Rust, Nim, Scheme, HTML, JSX, along with a directory mode, an experimental LSP mode, calc-mode, and more,
- Not to forget that Mac Os X users can use the Clozure Common Lisp IDE
- All editions of LispWorks (including the free) include the LW IDE
- For users of Eclipse IDE, there is the Dandelion plugin
- For popular editors, the experience is getting very good on Atom and the popular Visual Studio Code can be made to work with CL using cl-lsp.
- We have an ipython-like REPL (cl-repl),
- and for interactive notebooks, we have Jupyter kernels and yet another notebook (Darkmatter).
A very welcome improvement is the Common Lisp fundation’s website: https://common-lisp.net/ It got a massive update and is now attractive. We had http://lisp-lang.org/ (don’t miss its success stories section (did you know that pgloader was re-written from Python to CL ? :) )), but common-lisp.net was a googlers’ honey pot.
This website uses two “awesome” lists that were created or massively furnished last year:
- the Awesome-CL list, updated with hundreds of commits, which hopefully makes for a more discoverable and appealing ecosystem, and
- Awesome Lisp Companies: it was needed because Lispers didn’t know a lot of companies using CL appart from IRobot, Google’s ITA (powering Kayak, Orbitz and others), Grammatech, YCombinator, Siscog or other dead ones.
Other places to learn Common Lisp include:
- cl-exercise: a Common Lisp Learning System running on browsers
- coding schools, like Kattis
- and competitive Programming websites like CodeForces, HackerEarth, HackerRank, and CodeChef.
- lastly, Peter Norvig’s book Paradigms of Artificial Intelligence Programming is available on Github
We also regularly have new screencasts to enjoy:
- a lot being from Baggers: he does the following and he streams live nearly weekly
- little bits of Lisp: short videos to learn Lisp basics
- lots of bits of Lisp: long videos to dive deep in advanced subjects (macros, CFFI,…)
- Pushing pixels with Lisp: mostly working with OpenGL
- and more !
- Shinmera has lots of videos too, we can see him working on game engines, games, his libraries, Qt applications and more,
- the CL study group (here, an introduction to Screamer, a non-deterministic programming library)
Implementations
Time is good for Common Lisp implementations. Most date back from
decades and already proved what they can do (remember, SBCL is a
descendant of the Lisp that went to space). Hence the lack of hype,
IMO. Yet, many are in active development, and keep improving. As
/u/defunkydrummer observed:
We are lucky to live in a time where Lisp development is still ongoing, many teams carrying the flag of open-source Lisp:
- SBCL (new release today)
- SICL (last commit 2 hours ago)
- ECL (last commit, yesterday),
- CLASP (last commit 2 days ago)
- CCL (last commit 7 days ago),
- CLISP (two weeks ago),
- CMUCL (1 month ago)
- ABCL (3 months ago)
SBCL has monthly releases. If you read the release notes, you might worry:
the amount of changes in each release is decreasing these years
but, as /u/baggers notes:
I think the commits tell a slightly different tale though. There is always a lot of background ‘making stuff better’ work than won’t appear as the explanation would either be ultra internal and specific or would be super vague and very similar each month (for example ‘stuff is slightly faster’).
For one that would be overly specific this one might make for a good example. It’s grand work, but doesn’t surface in any specific lisp feature, stuff is just better.
Furthermore, a maintainer:
Or the developers are too lazy to describe their changes.
which isn’t a good reason ;)
We got a new release of Corman Lisp, a high performance Windows/32bit specific implementation with a built in IDE,
we have CLASP, targetting C++ through LLVM (see “Lessons Learned Implementing Common Lisp with LLVM”), built with the Cleavir compiler, part of SICL, a very new implementation of Common Lisp with fresh ideas,
we have ABCL targetting the JVM, Embedable Common Lisp, without forgetting active commercial ones, like LispWorks and AllegroCL. While I’m at it, you might want to have a look at MOCL for IOs, Android and OSx.
We got a nice talk by Clozure Common Lisp’s maintainer: this Old Lisp (this one may be the second most used implementation, particularly good for development – super fast compilation times (I heard it compiles itself in seconds), advising, watched objects, its own IDE).
Last note, a SBCL maintainer started a RISC-V port: First RISCy Steps – Porting SBCL to the RISC-V
So: welcome to this new world. It’s bigger than I thought, for sure.
Projects
I only list some projects that can be of interest to anybody. For the full stuff see the quaterly posts !
New projects
- Next browser 1.2.0 is out!: a browser exposing all its internals to CL. Be productive.
- CANDO - A Computational Chemistry programming environment integrating Common Lisp and C++ based on the Jupyter notebook
- Coalton, a dialect of ML embedded in Common Lisp (alpha)
- Voxel game engine (Minecraft) - a Minecraft engine. Allows for interactive changes.
- Emotiq - blockchain in Common Lisp
- Temperance - logic programming (in development, reached v1.0.0)
- MAGICL: Matrix Algebra proGrams In Common Lisp - Rigetti Computing (quantum computing)
- SHCL: An Unholy Union of POSIX Shell and Common Lisp (reddit)
- JSCL 0.7.0 now supports CLOS thanks to the work of vlad-km
- cl-torrents 0.9 - readline interface and 1337x.to scraper - a simple tool to search for torrents on popular trackers. My first CL app. Web and GUI interfaces in the making.
- Introducing Seed: An Interactive Software Environment in Common Lisp
- Tovero is a 3D modeling system for Common Lisp
- RMSBolt: See what your compiler is going inside of Emacs (has minimal support for Common Lisp)
- pngload: A PNG (Portable Network Graphics) image format decoder
- cl-vep: a video effects processor
- algebraic-data-library
- Petalisp: Elegant High Performance Computing
- wiki-lang-detect: Text language identification using Wikipedia data
- Dufy, a color library
- ppath, a path manipulation library
- cl-statistics.lisp
- Powerlisp: A simple tool to automate your work with dmenu/rofi
- json-mop: A metaclass for bridging CLOS and JSON objects
- clsh: a set of Lispy bindings for running and composing *nix processes
- filtered-functions - enables the use of arbitrary predicates for selecting and applying methods.
Web
- Weblocks’ new quickstart - Weblocks is an isomorphic web frameworks that allows to write interactive web apps without writing Javascript (nor writing code that transpiles to JS). It is seeing a massive update right now. Being Lisp, we can build a self-contained executable of our web app, send it to the server, run it and see it from the outside.
- three email libraries
- reddit1.0 source code (comments), then Reddit’s code runs on SBCL. See also reddit.
- Interactive Common Lisp code snippets in any web page
- arboreta-wasm - Common Lisp tooling for WebAssembly
For web libraries, see https://github.com/CodyReichert/awesome-cl#network-and-internet
GUI
- nodgui - yet another Tcl/Tk-based GUI package for Common Lisp (based on Ltk, with syntax sugar and more meta-widgets)
- IUP bindings GUI stuff (in the works)
- YstokWidgets Professional Edition
- MIDGETS - A collection of CAPI widgets and utilities
- subtext: A mostly-text-based UI bridges Common Lisp objects and runs of text. Minimal text-based user interface
- ftw: Common Lisp Win32 GUI library
- Cocoa interface code written in Lisp for use with Clozure Common Lisp
- McCLIM 0.9.7 “Imbolc” release
- Demo SBCL script using Gtk
- Demo ABCL script using Java Swing
for GUI libraries: https://github.com/CodyReichert/awesome-cl#gui
Package management
Quicklisp is the de facto package manager, but new projects come to complement it and bypass its limitations:
- the second version of Ultralisp is available - Ultralisp is an important project that fills a gap. It is a quicklisp distribution which updates every 5 minutes. It is also a Weblocks application!
- quicksys - installs systems from multiple Quicklisp distributions.
For more options, see Qlot (install and pin libraries locally, like Python’s virtualenv) and Roswell.
Deployment
- Apache Thrift gains CL support
- s2i-lisp: Common Lisp + Quicklisp OpenShift Build Image
- lisp-images: Docker images for common lisp development (with some others, see the awesome-list)
- A docker container for CL development (also lisp-devel, CI on CL Cookbook)
- Kubernetes Client Library for Common Lisp
- Heroku buildpack for Common Lisp
- cl-aws-custom-runtime - An example of using Common Lisp (SBCL) as a custom runtime on AWS lambda.
- prometheus.cl - Prometheus.io client. Grafana dashboard for SBCL and Hunchentoot metrics (memory, threads, requests per second,…).
We can also deploy apps on Digital Ocean, and no need to say that deploying a self-contained executable is easy, connecting to a remote instance too.
Music
- Music: Music framework for musical expression in Common Lisp with a focus on music theory (built from scratch, on development)
- Composing in Lisp with Csound
- Shuffletron, a Common Lisp Music Player for the terminal
see also audio and music composition software
(re)Discoveries
- lfarm - a library for distributing work across machines (on top of lparallel and usocket)
- Screamer - nondeterministic programming. Augment Common Lisp with practically all of the functionality of both Prolog and constraint logic programming languages (10 yo, Nikodemus)
- quid-pro-quo: a contract programming library in the style of Eiffel’s Design by Contract
- Cells, spreadsheet-like expressiveness for CLOS
- cl-bibtex: A compatible re-implementation of the BibTeX program in Common Lisp, with a BST-to-CL compiler
- C language syntax embedded in Common Lisp
- gendl - Generative Programming and Knowledge-based Engineering (KBE) system embedded in Common Lisp
- Cognitive Robot Abstract Machine = Common Lisp + ROS
- Esrap - a packrat parser for Common Lisp
- C-Mera, a Common Lisp source-to-source compiler to generate C/C++
- cl-bench - Common Lisp benchmarking suite
- QGAME: Quantum and Gate Measurement Emulator
Articles
- A Road to Common Lisp (hacker news comments). You should read this one.
- How the strengths of Lisp-family languages facilitate building complex and flexible bioinformatics applications
- Writing a natural language date and time parser - internals of the Common Lisp library Chronicity
- Implementing Hunchentoot custom sessions
- Overview of Documentation Generators (codex, coo, declt, staple, cldomain)
- Converter of maps from Reflex Arena to QuakeWorld. cl-yacc, 3d-matrices
- Debugging Common Lisp in Slime
- Packages in Common Lisp, a tutorial (pdf)
- How to write test fixtures for FiveAM - Dark Chestnut
- Franz and Semantic Web Co. Partner to Create a Noam Chomsky Knowledge Graph
- Compiler basics: lisp to assembly
- Marvin Minsky - Scientist - The beauty of the Lisp language
- Excavating a Common Treasure: Common Lisp
- Fun with Macros: If-Let and When-Let / Steve Losh
- Extempore - The design, implementation and application of a cyber-physical programming language, Andrew Sorensen, Thesis, 2018 (PDF)
- Uniform Structured Syntax, Metaprogramming and Run-time Compilation
- Simple expression evaluator comparison between Haskell, Rust, and Common Lisp
- Lisping at JPL
and also
- Lisp, Jazz, Aikido: Three Expressions of a Single Essence
- Why lisp - biolisp
- Fun with Macros: Gathering / Steve Losh
- Experience writing a full featured livejournal blog client in Common Lisp. Part 2: client logic
- The (Un)common Lisp approach to Operations Research (2012)
- Alien: Return of Alien Technology to Classical Planning
- Emacs + ECL on Android
- Generic, consistent and dotted access of data structures with Access - lisp-journey (reddit)
- LLVM’s garbage collection facilities and SBCL’s generational GC
- A bunch of utilities from (again) sjl: higher order functions, sequences, debugging, profiling.
- The return of cl-notebook
- Testing the SERIES package
On games:
- About Making Games in Lisp - Gamedev
- Creating a (Non-Trivial) Lisp Game in 2018 (they just launched a Crowdfunding)
- A Story of (defun games ())
- Getting Started With trivial-gamekit
Other screencasts
- Lisp, The Quantum Programmer’s Choice - Computerphile episode 2
- McCLIM + Maxima: plot manipulation
- McCLIM + Maxima: vector demo
- Comfy Lisp Programming - Project “Wikify” | Episode 2 @ 10am PST
- Common lisp and C++17 Live coding stream | TinyCDN CFFI Interop | Episode 13
- Growing a Lisp compiler - Amsterdam Lisp
- Web Development in Emacs, Common Lisp and Clojurescript - Potato (Slack-like)
Discussion
- Lisp and the remote agent - aka Lisp in a spacecraft - with an AMA of Ron Garret
- How to make (Common) Lisp popular?
- Feedback from a new LispWorks user (how is LispWorks the company going ?)
- How do you normally use a program once written ?
- Structs vs Parametric Polymorphism (an answer to the “switching from Common Lisp to Julia - thoughts ?” post) also this discussion
- How to work on a project and make sure dependencies are tracked correctly?
- Does anyone else hate LOOP?
- What does it take to understand the true power of Lisp?
- How did Lisp make your life easier ?
- Should local variables be avoided when possible when doing functional programming?
- Is ABCL an active project and does it support JRE 1.11?
- Has the Gnu Coreutils ever been implemented in Lisp? If not, would that be a worthwhile project?
- Common Lisp and Machine Learning these days
- Has anyone considered or started a project to write a CL implementation in WebAssembly?
- What do you recommend to work with SQL databases ? What’s your experience with Mito ? and sqlite only interface: cl-sqlite or cl-dbi ? and is there an ORM that generates classes from table definitions ?
Learning Lisp
- I want to try Lisp, how should I begin?
- What lisp dialect for “real world” applications?
- What do commercial Lisps offer that frees don’t?
- Which (non-Clojure) Lisp to learn first?
- Can CL implement Clojure’s keyword as function syntax?
- Why did you decide to learn Lisp?
- How do you go about starting a Common Lisp Project? A beginner looking for pointers.
- As a newbie, what I will miss if I choose Racket over Common Lisp? Or if I happen to learn both at somepoint in future, choosing Racket/Common Lisp now would make sense?
- What can other languages do that Lisp can’t ?
Common Lisp VS …
- How did the Common Lisp community survived without the equivalent of clojure.spec ?
- Is there a Lisp that is considered “excellent” about error handling ?
- Lisp Dialect survey
- the Julia challenge
- Python pitfalls ?
- How a Common Lisp programmer views users of other languages (humor)
- Miller School Researchers Help Push the Limits of Programming Languages in Biology
- Lisp vs Java (thought you guys might find this humorous)
- What other languages besides Lisp do you enjoy programming in?
Enjoy the material, and see you soon !
thanks to /u/defunkydrummer for proofreading.
fix or improve this article on Gitlab.

YAGNI
MonkeyUser 26 02 2019
Community request (with bugs)

![]()

9 to 5
MonkeyUser 19 02 2019
![]()
Adblockers Performance Study
WhoTracksMe blog 14 02 2019

Quick Fix
MonkeyUser 12 02 2019

Pivoting
MonkeyUser 05 02 2019
State of Clojure 2019 Results
Clojure News 04 02 2019
Welcome to the annual State of Clojure survey results! Every year we survey Clojure and ClojureScript developers to evaluate the state of the language and its users. Thank you to everyone that took the time to complete the survey and provide your input. This year, we had 2461 respondents. Some highlights:
-
Clojure is used by many companies for web development, commercial services, and enterprise apps in a broad set of domains including financial services, enterprise software, retail, advertising, health care, and more.
-
Clojure is valued for its idiomatic support for functional programming, immutable data, interactive REPL, and ease of development.
-
Clojure and its community are active and vibrant, as seen in the many thriving discussion forums, conferences, and user groups, with active involvement in community library development.
For more details and the full results, see below.
A Language for Work
In the first Clojure survey in 2010, 27% of respondents reported using Clojure for work and 33% for serious hobby projects. This number has steadily grown over the years and we now see 66% using it at work and 54% using it for serious hobby projects.
Clojure is being used in a wide variety of domains - web development (81%) and open source (48%) of course, but also building and delivering commercial services (31%) and enterprise apps (22%). This work occurs in a wide variety of industries - financial services, enterprise software, consumer software, retail, media/advertising, healthcare, education, and many more.
For the last four years, the percentage of Clojure developers in 1-10 person companies has fallen, this year to 35% (compared to 44% 3 years ago). We saw increases in developers working at companies sized 1000+ and 11-100. We also saw the number of consumers of these Clojure projects as less "in team" and more "outside team" or "outside the organization".
We added a new question this year to gauge the general experience level of Clojure developers. Almost half of Clojure users (49%) had 11 or more years of experience with 21% having 21 years or more. A recent JVM ecosystem survey asked a similar question and for comparison saw 42% had 11 or more years of experience and only 3% had 21 or more years. Clojure developers tend to be more experienced on average than other JVM developers.
Survey comments said:
-
"Thanks to Clojure and ClojureScript I can make a living building and maintaining large systems and delivering complex solutions on time. Thank you!"
-
"Clojure is thoughtfully designed and stable. It’s a dynamic, functional lisp that can actually be sold to the bosses. (A sentence I never thought I would write)."
-
"There is no way my team could pull all the rabbits out of hats that we do working in any other language. The only thing I ever seriously worry about, about Clojure, is how to ensure I get to work in Clojure and with Clojurists again should my current gig come to an end."
Hundreds of companies and tens of thousands of Clojure developers are working in Clojure or ClojureScript every day, using it as the foundation of their business. The survey indicates that Clojure developers are increasingly using it more for work, at bigger companies, impacting ever larger groups of users.
Strengths of Clojure
For years we have asked people what aspects of Clojure were most important to them. These answers are remarkably consistent and this year was no different. However it is good to reexamine these strengths to see why developers value Clojure. The big four that are always at the top of the list are: functional programming, immutability, the REPL, and ease of development. These traits are interrelated. Language support for immutable persistent data structures makes functional programming idiomatic and effective. A REPL on a live, growing system, with data loaded, is a great way for developers to try their new code in context as it is written, improving quality.
Other important features include host compatibility / interop (allowing us to take full advantage of the underlying platform and its libraries, whether that’s the JVM or JavaScript), the community, runtime performance, expressive syntax, concurrency support, and a shared language across tiers.
Some comments about the language:
-
"Quality permeates Clojure. Language design, library design, interactive development, community architecture experience, all top notch."
-
"Clojure/script is allowing me to create things that would be impossible in other languages."
-
"Clojure is beautiful, functional and concise. It really rejuvenated my love for programming."
-
"I really appreciate the well thought out design of Clojure. We feel that Clojure gives us distinct advantages while providing a language with minimum disruption."
Vibrant Community
The Clojure community is active, growing, and always helpful. Over the years, the primary communication mechanisms have changed along with the industry varying from IRC to the mailing lists to in recent years, Slack. We’ve been tracking this for a couple years now. Slack continues to be strong with 64% of respondents using it (note that this may be biased by where we advertised the survey!). The Clojure subreddit continued its strong rise to 55% use. ClojureTV on YouTube was a new answer this year but almost half are using it to watch Clojure videos. The official Clojure mailing lists had another drop this year as people shift away from "old school" mailing lists. And the original place where communication happened for Clojure is IRC which continued to fall out of use, now at only 7%.
We also added a new question to gauge how users of Clojure interact with the ecosystem. 96% reported being happy users of the language and libraries, 65% were building services or products, 51% were advocating for Clojure in their organization. More than a quarter (28%) were active in helping new users (something very common to see on Slack, Reddit, or the mailing lists). And 25% reported creating or maintaining open source libraries, filing issues on libraries (17%), or providing pull requests for fixes (15%).
Some quotes from users:
-
"It’s been great watching the ecosystem converge on excellence these past years, thanks so much for all the work and careful design!"
-
"I love how the community continues to improve, and people generally are friendly."
-
"Thanks for a great language, a steady hand at the wheel, and a passionate community!"

Moving from Go to PHP again
Danny van Kooten 03 02 2019
Remember when I ditched Laravel for Golang?
Well, after 2 years on Go, our shop applications are powered by PHP again.
Why?! You already said it was probably a bad business decision, and then you spend even more time on it?! Well, yeah, several reasons actually.
PHP improved a lot
PHP improved a lot during the last 3 years. It added scalar argument type declarations, return type declarations, multi-catch exceptions, impressive performance improvements and many more general improvements.
Symfony4 is a game changer
I’ve always been a big fan of Symfony’s compatibility promise and their impressive 13-year track record proves they mean it.
So when Symfony4 was released and I heard good things about it, I took it for a test drive by implementing a tiny part of our application in it.
Conclusion: it’s great. Really, really great.
A lot of effort went into simplifying the setup, making it a lot faster to bootstrap a Symfony application with much less work required configuring bundles. It’s now rivaling Laravel’s rapid development while at the same time encouraging decent development practices to ensure you don’t shoot yourself in the foot. And it performs really well.
It was relatively easy to port our old Laravel application to Symfony, implement some new features the Go version of our application offered and undo some of the shortcuts I took earlier (most of them because of Laravel’s global helpers).
A nice side effect is that I’ve managed to substantially increase our test coverage in the process. Writing the same application in terms of functionality for a second third time really helps in that regard.
Symfony’s debug bar is an amazing tool. It shows you what happened during the journey from request to response, notifies you of warnings & deprecations and comes with a built-in profiler that you can easily hook into to benchmark parts of your own code.

After learning Symfony’s Form component, I’d rather not go without it again. It makes it trivial to render an accessible form that can be re-used in several places, validating the form upon submit and then populating a PHP object from the form data safely.
$user = $this->getUser();
$form = $this->createForm(UserBillingInfoType::class, $user)
->handleRequest($request);
if ($form->isSubmitted() && $form->isValid()) {
// $user is already populated with the form values at this point
// it's valid, so we can update the database and redirect the user now
}
Doctrine is another piece of software that really improved our overall application. Your models (entities) are normal PHP classes and relations (associations) are normal references, making it easy to test your domain logic without having to worry about the database implementation.
$user = new User();
$user->addLicense(new License());
$manager->persist($user); // both user and its license will be saved
In Doctrine all operations are wrapped in a SQL transaction by default. That’s a big plus for me as it guarantees atomicity, which involved more work to get right in Eloquent.
Go is (still) great
Honestly, Go is great. Its simplicity is refreshing and you can’t get anywhere near that kind of performance using PHP 1. I would still pick it if we need a small API or something that requires high throughput.
Our shops however are more monolithic with a lot of server-side rendering. While that’s certainly doable in Go (as the last 2 years proved), it’s more maintainable for us to do it in PHP right now.
Side note: without the experience gained from our years on Go, I probably wouldn’t have started Fathom. So perhaps it wasn’t such a bad business decision after all?
Making the correct business decision
One reason not mentioned so far is that over the last year or so, I’ve been approached by several companies interested to take over one of our products.
They were a little surprised to hear our stack involved Golang and some flat out told us they’d prefer PHP, because that’s what most of our products (mc4wp.com, boxzillaplugin.com and htmlformsplugin.com) rely upon. And I don’t blame them.
1 Just for fun, I compared apples and oranges again by benchmarking the login page (which doesn't hit any database) for both application versions using Siege.
The Symfony application (PHP 7.3, OPcache enabled, optimized autoloader) handles about 1470 req/s. The Go application (compiled using Go v1.11) averages about 18600 req/s.
OOP Before OOP with Simula
Two-Bit History 31 01 2019

Code Entropy
MonkeyUser 29 01 2019
Intro This is the first part of a post which will guide you through the entire process of writing and self publishing a book for the first time. It’s about my book called Mastering Vim Quickly: From WTF to OMG in no time. The idea Vim is a very powerful text editor, used mainly by sysadmins,... Continue reading
The post My Story: How to Accidentally Self-Publish a Book appeared first on Jovica Ilic.
Gray streams
Lisp journey 22 01 2019
This is a copy of http://www.nhplace.com/kent/CL/Issues/stream-definition-by-user.html with syntax highlighting.
FAILED Issue STREAM-DEFINITION-BY-USER (“Gray Streams”)
This is the writeup of failed issue STREAM-DEFINITION-BY-USER. Because it did not pass, it has no official standing other than as a historical document.
NOTES:
Several vendors have implemented this proposal anyway, so if you’d like to use this facility, you might check to see if it’s available in your implementation of choice in spite of not being part the “official” standard.
The facility described here is commonly referred to as “Gray Streams”, after David Gray, who wrote the proposal—please do not write this as “Grey Streams”!
Another facility of note that came later and may be available in some implementations is Franz’s “Simple Streams”. It is newer and addresses a broader range of issues, but its availability in this or that implementation may be different.
Click here to see my personal notes on this issue. –Kent Pitman (10-Mar-2001)
Issue: STREAM-DEFINITION-BY-USER
References: CLtL pages 329-332, 378-381, and 384-385.
Related issues: STREAM-INFO, CLOSED-STREAM-FUNCTIONS, STREAM-ACCESS, STREAM-CAPABILITIES
Category: ADDITION
Edit history: Version 1, 22-Mar-89 by David N. Gray
Status: For discussion and evaluation; not proposed for inclusion in the standard at this time.
Table of Contents
- Problem description
- Proposal
stream-definition-by-user:generic-functions - Rationale
- Current practice
- Examples
- Cost to Implementors
- Cost to Users
- Cost of non-adoption
- Performance impact
- Benefits
- Esthetics
- Discussion
Problem description
Common Lisp does not provide a standard way for users to define their own streams for use by the standard I/O functions. This impedes the development of window systems for Common Lisp because, while there are standard Common Lisp I/O functions and there are beginning to be standard window systems, there is no portable way to connect them together to make a portable Common Lisp window system.
There are also many applications where users might want to define their own filter streams for doing things like printer device control, report formatting, character code translation, or encryption/decryption.
Proposal stream-definition-by-user:generic-functions
Overview
Define a set of generic functions for performing I/O. These functions will have methods that specialize on the stream argument; they would be used by the existing I/O functions. Users could write additional methods for them in order to support their own stream classes.
Define a set of classes to be used as the superclass of a stream class in order to provide some default methods.
## Classes
The following classes are to be used as super classes of user-defined stream classes. They are not intended to be directly instantiated; they just provide places to hang default methods.
fundamental-stream [Class]
This class is a subclass of `stream` and of `standard-object`. `streamp`
will return true for an instance of any class that includes this. (It
may return true for some other things also.)
fundamental-input-stream [Class]
A subclass of `fundamental-stream`. Its inclusion causes `input-stream-p`
to return true.
fundamental-output-stream [Class]
A subclass of `fundamental-stream`. Its inclusion causes `output-stream-p`
to return true. Bi-direction streams may be formed by including both
`fundamental-output-stream` and `fundamental-input-stream`.
fundamental-character-stream [Class]
A subclass of `fundamental-stream`. It provides a method for
`stream-element-type` which returns `character`.
fundamental-binary-stream [Class]
A subclass of `fundamental-stream`. Any instantiable class that
includes this needs to define a method for `stream-element-type`.
fundamental-character-input-stream [Class]
Includes `fundamental-input-stream` and `fundamental-character-stream`.
It provides default methods for several generic functions used for
character input.
fundamental-character-output-stream [Class]
Includes `fundamental-output-stream` and `fundamental-character-stream`.
It provides default methods for several generic functions used for
character output.
fundamental-binary-input-stream [Class]
Includes `fundamental-input-stream` and `fundamental-binary-stream`.
fundamental-binary-output-stream [Class]
Includes `fundamental-output-stream` and `fundamental-binary-stream`.
Character input
A character input stream can be created by defining a class that
includes fundamental-character-input-stream and defining methods for the
generic functions below.
stream-read-char stream [Generic Function]
This reads one character from the stream. It returns either a
character object, or the symbol :EOF if the stream is at end-of-file.
Every subclass of `fundamental-character-input-stream` must define a
method for this function.
Note that for all of these generic functions, the stream argument
must be a stream object, not T or NIL.
stream-unread-char stream character [Generic Function]
Un-does the last call to `stream-read-char`, as in `unread-char`. Returns
NIL. Every subclass of `fundamental-character-input-stream` must define
a method for this function.
stream-read-char-no-hang stream [Generic Function]
This is used to implement `read-char-no-hang`. It returns either a
character, or NIL if no input is currently available, or :EOF if
end-of-file is reached. The default method provided by
`fundamental-character-input-stream` simply calls `stream-read-char`; this
is sufficient for file streams, but interactive streams should define
their own method.
stream-peek-char stream [Generic Function]
Used to implement `peek-char`; this corresponds to peek-type of NIL.
It returns either a character or :EOF. The default method
calls `stream-read-char` and `stream-unread-char`.
stream-listen stream [Generic Function]
Used by `listen`. Returns true or false. The default method uses
`stream-read-char-no-hang` and `stream-unread-char`. Most streams should
define their own method since it will usually be trivial and will
always be more efficient than the default method.
stream-read-line stream [Generic Function]
Used by `read-line`. A string is returned as the first value. The
second value is true if the string was terminated by end-of-file
instead of the end of a line. The default method uses repeated
calls to `stream-read-char`.
stream-clear-input stream [Generic Function]
Implements `clear-input` for the stream, returning NIL. The default
method does nothing.
Character output
A character output stream can be created by defining a class that
includes fundamental-character-output-stream and defining methods for the
generic functions below.
stream-write-char stream character [Generic Function]
Writes character to the stream and returns the character. Every
subclass of `fundamental-character-output-stream` must have a method
defined for this function.
stream-line-column stream [Generic Function]
This function returns the column number where the next character
will be written, or NIL if that is not meaningful for this stream.
The first column on a line is numbered 0. This function is used in
the implementation of `pprint` and the FORMAT ~T directive. For every
character output stream class that is defined, a method must be
defined for this function, although it is permissible for it to
always return NIL.
stream-start-line-p stream [Generic Function]
This is a predicate which returns T if the stream is positioned at the
beginning of a line, else NIL. It is permissible to always return
NIL. This is used in the implementation of `fresh-line`. Note that
while a value of 0 from `stream-line-column` also indicates the
beginning of a line, there are cases where `stream-start-line-p` can be
meaningfully implemented although `stream-line-column` can't be. For
example, for a window using variable-width characters, the column
number isn't very meaningful, but the beginning of the line does have
a clear meaning. The default method for `stream-start-line-p` on class
`fundamental-character-output-stream` uses `stream-line-column`, so if
that is defined to return `nil`, then a method should be provided for
either `stream-start-line-p` or `stream-fresh-line`.
stream-write-string stream string &optional start end [Generic Function]
This is used by `write-string`. It writes the string to the stream,
optionally delimited by start and end, which default to 0 and NIL.
The string argument is returned. The default method provided by
`fundamental-character-output-stream` uses repeated calls to
`stream-write-char`.
stream-terpri stream [Generic Function]
Writes an end of line, as for `terpri`. Returns NIL. The default
method does (`stream-write-char` stream #\NEWLINE).
stream-fresh-line stream [Generic Function]
Used by `fresh-line`. The default method uses `stream-start-line-p` and
`stream-terpri`.
stream-finish-output stream [Generic Function]
Implements `finish-output`. The default method does nothing.
stream-force-output stream [Generic Function]
Implements `force-output`. The default method does nothing.
stream-clear-output stream [Generic Function]
Implements `clear-output`. The default method does nothing.
stream-advance-to-column stream column [Generic Function]
Writes enough blank space so that the next character will be written
at the specified column. Returns true if the operation is
successful, or NIL if it is not supported for this stream.
This is intended for use by by `pprint` and FORMAT ~T. The default
method uses `stream-line-column` and repeated calls to
`stream-write-char` with a #\SPACE character; it returns NIL if
`stream-line-column` returns NIL.
## Other functions
close stream &key abort [Generic Function]
The existing function `close` is redefined to be a generic function, but
otherwise behaves the same. The default method provided by class
`fundamental-stream` sets a flag for `open-stream-p`. The value returned
by `close` will be as specified by the issue `closed-stream-operations`.
open-stream-p stream [Generic Function]
This function [from proposal `stream-access]` is made generic. A
default method is provided by class `fundamental-stream` which returns
true if `close` has not been called on the stream.
streamp object [Generic Function]
input-stream-p stream [Generic Function]
output-stream-p stream [Generic Function]
These three existing predicates may optionally be implemented as
generic functions for implementations that want to permit users to
define streams that are not `standard-object`s. Normally, the default
methods provided by classes `fundamental-input-stream` and
`fundamental-output-stream` are sufficient. Note that, for example,
(INPUT-STREAM-P x) is not equivalent to (TYPEP x
'FUNDAMENTAL-INPUT-STREAM) because implementations may have
additional ways of defining their own streams even if they don't
make that visible by making these predicates generic.
stream-element-type stream [Generic Function]
This existing function is made generic, but otherwise behaves the
same. Class `fundamental-character-stream` provides a default method
which returns `character`.
pathname and truename are also permitted to be implemented as generic
functions. There is no default method since these are not valid for
all streams.
## Binary streams:
Binary streams can be created by defining a class that includes either
`fundamental-binary-input-stream` or `fundamental-binary-output-stream`
(or both) and defining a method for `stream-element-type` and for one or
both of the following generic functions.
stream-read-byte stream [Generic Function]
Used by `read-byte`; returns either an integer, or the symbol :EOF if the
stream is at end-of-file.
stream-write-byte stream integer [Generic Function]
Implements `write-byte`; writes the integer to the stream and returns
the integer as the result.
Rationale
The existing I/O functions cannot be made generic because, in nearly
every case, the stream argument is optional, and therefore cannot be
specialized. Therefore, it is necessary to define a lower-level
generic function to be used by the existing function. It also isn’t
appropriate to specialize on the second argument of print-object because
it is a higher-level function – even when the first argument is a
character or a string, it needs to format it in accordance with
*PRINT-ESCAPE*.
In order to make the meaning as obvious as possible, the names of the
generic functions have been formed by prefixing “stream-” to the
corresponding non-generic function.
Having the generic input functions just return :EOF at end-of-file, with the higher-level functions handling the eof-error-p and eof-value arguments, simplifies the generic function interface and makes it more efficient by not needing to pass through those arguments. Note that the functions that use this convention can only return a character or integer as a stream element, so there is no possibility of ambiguity.
Functions stream-line-column, stream-start-line-p, and
stream-advance-to-column may appear to be a reincarnation of the
defeated proposal stream-info, but the motivation here is different.
This interface needs to be defined if user-defined streams are to be
able to be used by pprint and FORMAT ~T, which could be viewed as a
separate question from whether the user can call then on
system-defined streams.
Current practice
No one currently supports exactly this proposal, but this is very
similar to the stream interface used in clue.
On descendants of the MIT Lisp Machine, streams can be implemented by users as either flavors, with methods to accept the various messages corresponding to the I/O operations, or as functions, which take a message keyword as their first argument.
Examples
;;;; Here is an example of how the default methods could be
;;;; implemented (omitting the most trivial ones):
(defmethod STREAM-PEEK-CHAR ((stream fundamental-character-input-stream))
(let ((character (stream-read-char stream)))
(unless (eq character :eof)
(stream-unread-char stream character))
character))
(defmethod STREAM-LISTEN ((stream fundamental-character-input-stream))
(let ((char (stream-read-char-no-hang stream)))
(and (not (null char))
(not (eq char :eof))
(progn (stream-unread-char stream char) t))))
(defmethod STREAM-READ-LINE ((stream fundamental-character-input-stream))
(let ((line (make-array 64 :element-type 'string-char
:fill-pointer 0 :adjustable t)))
(loop (let ((character (stream-read-char stream)))
(if (eq character :eof)
(return (values line t))
(if (eql character #\newline)
(return (values line nil))
(vector-push-extend character line)))))))
(defmethod STREAM-START-LINE-P ((stream fundamental-character-output-stream))
(equal (stream-line-column stream) 0))
(defmethod STREAM-WRITE-STRING ((stream fundamental-character-output-stream)
string &optional (start 0)
(end (length string)))
(do ((i start (1+ i)))
((>= i end) string)
(stream-write-char stream (char string i))))
(defmethod STREAM-TERPRI ((stream fundamental-character-output-stream))
(stream-write-char stream #\newline)
nil)
(defmethod STREAM-FRESH-LINE ((stream fundamental-character-output-stream))
(if (stream-start-line-p stream)
nil
(progn (stream-terpri stream) t)))
(defmethod STREAM-ADVANCE-TO-COLUMN ((stream fundamental-character-output-stream)
column)
(let ((current (stream-line-column stream)))
(unless (null current)
(dotimes (i (- current column) t)
(stream-write-char stream #\space)))))
(defmethod INPUT-STREAM-P ((stream fundamental-input-stream)) t)
(defmethod INPUT-STREAM-P ((stream fundamental-output-stream))
;; allow the two classes to be mixed in either order
(typep stream 'fundamental-input-stream))
(defmethod OUTPUT-STREAM-P ((stream fundamental-output-stream)) t)
(defmethod OUTPUT-STREAM-P ((stream fundamental-input-stream))
(typep stream 'fundamental-output-stream))
;;;; Following is an example of how the existing I/O functions could
;;;; be implemented using standard Common Lisp and the generic
;;;; functions specified above. The standard functions being defined
;;;; are in upper case.
;; Internal helper functions
(proclaim '(inline decode-read-arg decode-print-arg check-for-eof))
(defun decode-read-arg (arg)
(cond ((null arg) *standard-input*)
((eq arg t) *terminal-io*)
(t arg)))
(defun decode-print-arg (arg)
(cond ((null arg) *standard-output*)
((eq arg t) *terminal-io*)
(t arg)))
(defun check-for-eof (value stream eof-errorp eof-value)
(if (eq value :eof)
(report-eof stream eof-errorp eof-value)
value))
(defun report-eof (stream eof-errorp eof-value)
(if eof-errorp
(error 'end-of-file :stream stream)
eof-value))
;;; Common Lisp input functions
(defun READ-CHAR (&optional input-stream (eof-errorp t) eof-value recursive-p)
(declare (ignore recursive-p)) ; a mistake in CLtL?
(let ((stream (decode-read-arg input-stream)))
(check-for-eof (stream-read-char stream) stream eof-errorp eof-value)))
(defun PEEK-CHAR (&optional peek-type input-stream (eof-errorp t)
eof-value recursive-p)
(declare (ignore recursive-p))
(let ((stream (decode-read-arg input-stream)))
(if (null peek-type)
(check-for-eof (stream-peek-char stream) stream eof-errorp eof-value)
(loop
(let ((value (stream-peek-char stream)))
(if (eq value :eof)
(return (report-eof stream eof-errorp eof-value))
(if (if (eq peek-type t)
(not (member value '(#\space #\tab #\newline
#\page #\return #\linefeed)))
(char= peek-type value))
(return value)
(stream-read-char stream))))))))
(defun UNREAD-CHAR (character &optional input-stream)
(stream-unread-char (decode-read-arg input-stream) character))
(defun LISTEN (&optional input-stream)
(stream-listen (decode-read-arg input-stream)))
(defun READ-LINE (&optional input-stream (eof-error-p t)
eof-value recursive-p)
(declare (ignore recursive-p))
(let ((stream (decode-read-arg input-stream)))
(multiple-value-bind (string eofp)
(stream-read-line stream)
(if eofp
(if (= (length string) 0)
(report-eof stream eof-error-p eof-value)
(values string t))
(values string nil)))))
(defun CLEAR-INPUT (&optional input-stream)
(stream-clear-input (decode-read-arg input-stream)))
(defun READ-CHAR-NO-HANG (&optional input-stream (eof-errorp t)
eof-value recursive-p)
(declare (ignore recursive-p))
(let ((stream (decode-read-arg input-stream)))
(check-for-eof (stream-read-char-no-hang stream)
stream eof-errorp eof-value)))
;;; Common Lisp output functions
(defun WRITE-CHAR (character &optional output-stream)
(stream-write-char (decode-print-arg output-stream) character))
(defun FRESH-LINE (&optional output-stream)
(stream-fresh-line (decode-print-arg output-stream)))
(defun TERPRI (&optional output-stream)
(stream-terpri (decode-print-arg output-stream)))
(defun WRITE-STRING (string &optional output-stream &key (start 0) end)
(stream-write-string (decode-print-arg output-stream) string start end))
(defun WRITE-LINE (string &optional output-stream &key (start 0) end)
(let ((stream (decode-print-arg output-stream)))
(stream-write-string stream string start end)
(stream-terpri stream)
string))
(defun FORCE-OUTPUT (&optional stream)
(stream-force-output (decode-print-arg stream)))
(defun FINISH-OUTPUT (&optional stream)
(stream-finish-output (decode-print-arg stream)))
(defun CLEAR-OUTPUT (&optional stream)
(stream-clear-output (decode-print-arg stream)))
;;; Binary streams
(defun READ-BYTE (binary-input-stream &optional (eof-errorp t) eof-value)
(check-for-eof (stream-read-byte binary-input-stream)
binary-input-stream eof-errorp eof-value))
(defun WRITE-BYTE (integer binary-output-stream)
(stream-write-byte binary-output-stream integer))
;;; String streams
(defclass string-input-stream (fundamental-character-input-stream)
((string :initarg :string :type string)
(index :initarg :start :type fixnum)
(end :initarg :end :type fixnum)
))
(defun MAKE-STRING-INPUT-STREAM (string &optional (start 0) end)
(make-instance 'string-input-stream :string string
:start start :end (or end (length string))))
(defmethod stream-read-char ((stream string-input-stream))
(with-slots (index end string) stream
(if (>= index end)
:eof
(prog1 (char string index)
(incf index)))))
(defmethod stream-unread-char ((stream string-input-stream) character)
(with-slots (index end string) stream
(decf index)
(assert (eql (char string index) character))
nil))
(defmethod stream-read-line ((stream string-input-stream))
(with-slots (index end string) stream
(let* ((endline (position #\newline string :start index :end end))
(line (subseq string index endline)))
(if endline
(progn (setq index (1+ endline))
(values line nil))
(progn (setq index end)
(values line t))))))
(defclass string-output-stream (fundamental-character-output-stream)
((string :initform nil :initarg :string)))
(defun MAKE-STRING-OUTPUT-STREAM ()
(make-instance 'string-output-stream))
(defun GET-OUTPUT-STREAM-STRING (stream)
(with-slots (string) stream
(if (null string)
""
(prog1 string (setq string nil)))))
(defmethod stream-write-char ((stream string-output-stream) character)
(with-slots (string) stream
(when (null string)
(setq string (make-array 64. :element-type 'string-char
:fill-pointer 0 :adjustable t)))
(vector-push-extend character string)
character))
(defmethod stream-line-column ((stream string-output-stream))
(with-slots (string) stream
(if (null string)
0
(let ((nx (position #\newline string :from-end t)))
(if (null nx)
(length string)
(- (length string) nx 1))
))))
Cost to Implementors
Given that CLOS is supported, adding the above generic functions and methods is easy, since most of the code is included in the examples above. The hard part would be re-writing existing I/O functionality in terms of methods on these new generic functions. That could be simplified if methods can be defined to forward the operations to the old representation of streams. For a new implementation, the cost could be zero since an approach similar to this would likely be used anyway.
Cost to Users
None; this is an upward-compatible addition. Users won’t even need to know anything about this unless they actually need this feature.
Cost of non-adoption
Development of portable I/O extensions will be discouraged.
Performance impact
This shouldn’t affect performance of new implementations (assuming an efficient CLOS implementation), but it could slow down I/O if it were clumsily grafted on top of an existing implementation.
Benefits
A broader domain of programs that can be written portably.
Esthetics
This seems to be a simple, straight-forward approach.
Discussion
This proposal incorporates suggestions made by several people in
response to an earlier outline. So far, no one has expressed opposition
to the concept. There are some differences of opinion about whether
certain operations should have default methods or required methods:
stream-listen, stream-read-char-no-hang, stream-line-column,
and stream-start-line-p.
An experimental prototype of this has been successfully implemented on the Explorer.
This proposal does not provide sufficient capability to implement
forwarding streams such as for make-synonym-stream,
make-broadcast-stream, make-concatenated-stream, make-two-way-stream, or
make-echo-stream. The generic function approach does not lend itself as
well to that as a message passing model where the intermediary does not
need to know what all the possible messages are. A possible way of
extending it for that would be to define a class
(defclass stream-generic-function (standard-generic-function) ())
to be used as the :generic-function-class option for all of the I/O generic functions. This would then permit doing something like
(defmethod no-applicable-method ((gfun stream-generic-function) &rest args)
(if (streamp (first args))
(apply #'stream-operation-not-handled (first args) gfun (rest args))
(call-next-method)))
where stream-operation-not-handled is a generic function whose default
method signals an error, but forwarding streams can define methods that
will create a method to handle the unexpected operation. (Perhaps
no-applicable-method should be changed to take two required arguments
since all generic functions need at least one required argument, and
that would make it unnecessary to define a new generic function class
just to be able to write this one method.)
Another thing that is not addressed here is a way to cause an instance
of a user-defined stream class to be created from a call to the open
function. That should be part of a separate issue for generic functions
on pathnames. If that capability were available, then pathname and
truename should be required to be generic functions.
An earlier draft defined just two classes, fundamental-input-stream and
fundamental-output-stream, that were used for both character and binary
streams. It isn’t clear whether that simple approach is sufficient or
whether the larger set of classes is really needed.

Meeting
MonkeyUser 22 01 2019
Running Luminus on Dokku
(iterate think thoughts) 19 01 2019
Luminus provides a great way to get up and running with a Clojure web application. However, building your app is only half the work. Once you've got your app working, the next step is to host it somewhere so that the users can access it.
Cloud platforms, such as AWS, are a popular choice for deploying large scale solutions. On the other hand, VPS services like Digital Ocean and Linode provide a more economical alternative for small scale applications. The downside of running your own VPS is that managing it can be labor intensive. This is where Dokku comes in. It's a private PaaS modelled on Heroku that you can use to provision a VPS.
Let's take a look at what's involved in provisioning a Digital Ocean droplet with Dokku and deploying a Luminus web app to it.
Set up the server
Let's create a droplet with Ubuntu LTS (18.0.4 at the time of writing) and SSH into it. We'll need to add new APT repositories before we install Dokku.
- add the universe repository
sudo add-apt-repository universe - add the key
wget -nv -O - https://packagecloud.io/dokku/dokku/gpgkey | apt-key add - - add the Dokku repo
echo "deb https://packagecloud.io/dokku/dokku/ubuntu/ bionic main" > /etc/apt/sources.list.d/dokku.list
Once the repositories are added, we'll need to update the dependencies and install Dokku.
- update dependencies
sudo apt-get update && sudo apt-get upgrade - install dokku
apt-get install dokku
Once Dokku is installed, we'll create an application and a Postgres database instance.
- create the app
dokku apps:create myapp - install dokku-postgres plugin
sudo dokku plugin:install https://github.com/dokku/dokku-postgres.git - create the db
dokku postgres:create mydb - link the db to the app
dokku postgres:link mydb myapp
We're now ready to deploy the app.
Create a new Luminus application
Let's create a Luminus application on your local machine.
lein new luminus myapp +postgrescd myapp
Let's update the app to run migrations on startup by updating the myapp.core/start-app function to run the migrations.
(defn start-app [args]
(doseq [component (-> args
(parse-opts cli-options)
mount/start-with-args
:started)]
(log/info component "started"))
;;run migrations
(migrations/migrate ["migrate"] (select-keys env [:database-url]))
(.addShutdownHook (Runtime/getRuntime) (Thread. stop-app)))
Next, we need to update env/prod/resources/logback.xml to use STDOUT for the logs:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<statusListener class="ch.qos.logback.core.status.NopStatusListener" />
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!-- encoders are assigned the type
ch.qos.logback.classic.encoder.PatternLayoutEncoder by default -->
<encoder>
<charset>UTF-8</charset>
<pattern>%date{ISO8601} [%thread] %-5level %logger{36} - %msg %n</pattern>
</encoder>
</appender>
<logger name="org.apache.http" level="warn" />
<logger name="org.xnio.nio" level="warn" />
<logger name="com.zaxxer.hikari" level="warn" />
<root level="INFO">
<appender-ref ref="STDOUT" />
</root>
</configuration>
Deploy the application to Dokku
We're now ready to deploy the app. First, we'll need to create a Git repo and add the app contents to it.
git initgit add .gitignore Procfile project.clj README.md src/* env/* test/* resources/*git commit -a -m "initial commit"
Note that you do not want to check in Dockerfile that's generated by the template. Dokku will use it as the preferred strategy for creating the container.
Next, we'll add the remote for the Dokku repository on the server and push the project to the remote. Dokku will automatically build the project once it's pushed, and deploy the application when the build is successful.
git remote add dokku dokku@<server name>:myappgit push dokku master
The app will be pushed to the server where it will be compiled and run. If everything went well you should see output that looks something like the following:
...
-----> Building with Leiningen
Running: lein uberjar
Compiling sample.app
2019-01-18 01:10:30.857:INFO::main: Logging initialized @6674ms to org.eclipse.jetty.util.log.StdErrLog
Created /tmp/build/target/myapp-1.0.1.jar
Created /tmp/build/target/myapp.jar
...
=====> web=1
...
-----> Waiting for 10 seconds ...
-----> Default container check successful!
-----> Running post-deploy
-----> Configuring myapp.<server name>...(using built-in template)
-----> Creating http nginx.conf
-----> Running nginx-pre-reload
Reloading nginx
-----> Setting config vars
DOKKU_APP_RESTORE: 1
=====> 8dc31ac11011111117f71e4311111ca5962cf316411d5f0125e87bbac26
=====> Application deployed:
http://myapp.<server name>
To http://<server name>:myapp
6dcab39..1c0c8b7 master -> master
We can check the status of the application in the logs by running dokku logs myapp command on the server. The output should looks something like the following.
Picked up JAVA_TOOL_OPTIONS: -Xmx300m -Xss512k -XX:CICompilerCount=2 -Dfile.encoding=UTF-8
2019-01-19 19:09:48,258 [main] INFO myapp.env -
-=[myapp started successfully]=-
2019-01-19 19:09:50,490 [main] INFO luminus.http-server - starting HTTP server on port 5000
2019-01-19 19:09:50,628 [main] INFO org.xnio - XNIO version 3.3.6.Final
2019-01-19 19:09:51,236 [main] INFO org.projectodd.wunderboss.web.Web - Registered web context /
2019-01-19 19:09:51,242 [main] INFO myapp.core - #'myapp.config/env started
2019-01-19 19:09:51,243 [main] INFO myapp.core - #'myapp.db.core/*db* started
2019-01-19 19:09:51,243 [main] INFO myapp.core - #'myapp.handler/init-app started
2019-01-19 19:09:51,244 [main] INFO myapp.core - #'myapp.handler/app started
2019-01-19 19:09:51,249 [main] INFO myapp.core - #'myapp.core/http-server started
2019-01-19 19:09:51,249 [main] INFO myapp.core - #'myapp.core/repl-server started
2019-01-19 19:09:51,250 [main] INFO myapp.core - running migrations
2019-01-19 19:09:51,257 [main] INFO migratus.core - Starting migrations
2019-01-19 19:09:51,418 [main] INFO migratus.database - creating migration table 'schema_migrations'
2019-01-19 19:09:51,992 [main] INFO migratus.core - Running up for [20190118214013]
2019-01-19 19:09:51,997 [main] INFO migratus.core - Up 20190118214013-add-users-table
2019-01-19 19:09:52,099 [main] INFO migratus.core - Ending migrations
You should now be able to check your application in the browser by navigating to http://<server name>.
Troubleshooting the database
The startup logs for the application indicate that it was able to connect to the database and run the migrations successfully. Let's confirm this is the case by connecting a psql shell to the database container on the server.
dokku postgres:connect mydb
mydb=# \d
List of relations
Schema | Name | Type | Owner
--------+-------------------+-------+----------
public | schema_migrations | table | postgres
public | users | table | postgres
(2 rows)
We can see that the database contains the schema_migrations table and the users table that were created when the app migrations ran.
Sometimes it might be useful to connect a more advanced client such as DBeaver. This can done by exposing the database on the server using the following command.
sudo dokku postgres:expose mydb 5000
Next, we'll enter the container for the application to get the database connection details.
dokku enter myapp web
echo $DATABASE_URL
The DATABASE_URL environment variable in the container will contain the connection string that looks as follows.
postgres://postgres:<password>@dokku-postgres-mydb:5432/mydb
We can now map the port to the local machine using SSH, and connect to the database as if it was running on the local machine using the connection settings above.
ssh -L 5432:localhost:5000 <server name>
Set up HTTPS using Let's Encrypt
As the last step we'll set up HTTPS for the application using dokku-letsencrypt plugin. We'll set the app to run on the root domain on the server.
- add the root domain to the app
dokku domains:add myapp <server name> - remove the subdomain from the app
dokku domains:remove myapp myapp.<server name> - install the plugin
sudo dokku plugin:install https://github.com/dokku/dokku-letsencrypt.git - set the email for renewal warnings
dokku config:set --no-restart myapp DOKKU_LETSENCRYPT_EMAIL=<your email> - add HTTPS to the app
sudo dokku letsencrypt myapp - set up auto-renew for the certificate
dokku letsencrypt:auto-renew
That's all there is to it. The application is now deployed to the droplet, it's hooked up to the database, and it's using Let's Encrypt SSL/TLS Certificates.
Any further updates to the application simply involve committing the changes to the local Git repo and pushing them to the server as we did with our initial deploy.
I recommend taking look at the official documentation on the Dokku site for more information about Dokku. I think it provides an excellent solution for running your VPS. If you're evaluating different options for deploying your Clojure apps give Dokku a look.
These Months in Common Lisp Q4 2018
Lisp journey 15 01 2019
I wanted to do this for a year and here we are ! I don’t think I’ll carry on, with this format at least.
If I missed anything crucial: you have comments and PRs: https://gitlab.com/lisp-journey/lisp-journey.gitlab.io/
Happy (re)discoveries !
Documentation
- Debugging – the Common Lisp Cookbook
- Loop, iteration, mapping – the Common Lisp Cookbook
- cl-exercise: Common Lisp Learning System running on browsers
Announcements
- various SBCL releases (from 1.4.13 to 1.4.15) (not many changes you think ?)
- Release of Corman Lisp 3.1 (Windows), with personal notes (also this thread)
- European Lisp Symposium 2019 - Call for Papers
- Dandelion, Eclipse IDE plugin, updated for SBCL 1.4.10
- December Quicklisp update, october
- Common Lisp is now available to use at Kattis
Projects
- CANDO - A Computational Chemistry programming environment integrating Common Lisp and C++ based on the Jupyter notebook
- Coalton, a dialect of ML embedded in Common Lisp (alpha)
- Ulubis - A Wayland compositor written in Common Lisp
- ISO 8601 date/time library
- Voxel game engine (Minecraft)
- magrathea: chaotic-neutral web security for Hunchentoot
- schannel: Common Lisp Windows SChannel API
- qbase64: A fast and flexible base64 encoder/decoder in Lisp
- Beautify Practical Common Lisp, Firefox extension
- static-dispatch: Static generic function dispatch. The purpose is to provide an optimization in cases where the usual dynamic dispatch is too slow, and the dynamic features are not required
- cl-http2-protocol: HTTP/2 interop library in Common Lisp
- cl-punch: Scala-like and CL21-like anonymous lambda literal See other lambda shorthands.
- Scheme macros for Common Lisp
- The INVAL plan validator, and other PDDL tools
- Australian Government statistics collection library
- Easy local bindings
- cl-fm - a file manager using cl-cffi-gtk (seems staling. “not ready for prime time”)
- cl-intervals: Intervals and interval trees for Common Lisp
GUI:
- nodgui - yet another Tcl/Tk-based GUI package for Common Lisp
- YstokWidgets Professional Edition
- MIDGETS - A collection of CAPI widgets and utilities
- subtext: A mostly-text-based UI bridges Common Lisp objects and runs of text. Minimal text-based user interface
Developer utilities:
- s2i-lisp: Common Lisp + Quicklisp OpenShift Build Image
- lisp-images: Docker images for common lisp development (with some others, see the awesome-list)
- Quicklisp.nvim - Common Lisp package management within Neovim
New releases:
- JSCL 0.7.0 now supports CLOS thanks to the work of vlad-km
- Next browser 1.2.0 is out!
- Lem editor 1.5 released with executables, rust-mode, nim-mode, html-mode, jsx, calc-mode, ncurses for windows, experimental lsp-mode, support for async processes, python and scheme repl and more
(re)discoveries:
- cl-rest-server: Serve REST APIs from Common Lisp, Swagger support
- lfarm - a library for distributing work across machines (on top of lparallel and usocket)
- cl-docutils: implementation of Docutils. Includes a parser for the reStructured format, writers to html and latex
- formulador: render math formulas in 2D in your terminal!
- cl-bibtex: A compatible re-implementation of the BibTeX program in Common Lisp, with a BST-to-CL compiler
- clcon - a Common Lisp editor (tcl/tk, mostly russian)
- C language syntax embedded in Common Lisp
Articles
- This Old Lisp (on CCL)
- How the strengths of Lisp-family languages facilitate building complex and flexible bioinformatics applications
- Writing a natural language date and time parser - internals of the Common Lisp library Chronicity
- validate-superclass explained
- CFFI arrays versus STATIC-VECTORS: a comparison
- Dumping Common Lisp streams
- Killing Common Lisp methods and classes
- Funny method combinations
- Implementing Hunchentoot custom sessions
- Overview of Documentation Generators (codex, coo, declt, staple, cldomain)
- Challenging myself to learn Common Lisp in one month
- Converter of maps from Reflex Arena to QuakeWorld. cl-yacc, 3d-matrices
- Debugging Common Lisp in Slime
- Packages in Common Lisp, a tutorial (pdf)
- How to write test fixtures for FiveAM - Dark Chestnut
- Franz and Semantic Web Co. Partner to Create a Noam Chomsky Knowledge Graph
- Composing in Lisp with Csound (see also audio and music composition software)
- Blogging with Lisp
- Compiler basics: lisp to assembly
- Marvin Minsky - Scientist - The beauty of the Lisp language
GUIs:
On games:
- Baggers responds to ‘Reasons why Lisp games suffer’
- About Making Games in Lisp - Gamedev
- Creating a (Non-Trivial) Lisp Game in 2018
Discussion
- Lisp and the remote agent - with an AMA of Ron Garret
- How to make (Common) Lisp popular?
- Feedback from a new LispWorks user (how is LispWorks the company going ?)
- How do you normally use a program once written ?
- How does Common Lisp implement hot code reloading?
- Structs vs Parametric Polymorphism (an answer to the “switching from Common Lisp to Julia - thoughts ?” post) also this discussion
- How to work on a project and make sure dependencies are tracked correctly?
- Does anyone else hate LOOP?
- What does it take to understand the true power of Lisp?
- How did Lisp make your life easier ?
- Should local variables be avoided when possible when doing functional programming?
- Is ABCL an active project and does it support JRE 1.11?
- Has the Gnu Coreutils ever been implemented in Lisp? If not, would that be a worthwhile project?
- “Classes are not interactions!” by shka
Screencasts
- 2018 LLVM Developers’ Meeting: C. Schafmeister “Lessons Learned Implementing Common Lisp with LLVM”
- A pile of parens
- Pushing Pixels with Lisp - 61 - Stenciling (Failed attempt)
Common Lisp VS …

Great Expectations
MonkeyUser 15 01 2019
It's Time to Own My Own Content
Haki Benita 13 01 2019
I started writing about two years ago. Back then, I used to read a lot on Medium. When I finally felt the urge to write something, it made sense to publish there as well. Medium provided me with a platform, an audience, and constant reinforcements in the form of stats, likes and comments. It motivated me to keep writing. Despite it's many advantages, I feel Medium is lacking in some areas.
Why Deftask Chose Common Lisp
Lisp journey 11 01 2019
We heard about Deftask, a task management app for teams, a few days ago, in an article about the internals of the Chronicity library. Deftask uses Common Lisp for its backend and its command-line app. This reasonates with the fact that Turtl doesn’t use CL anymore. So I asked Deftask’s author: why did you go with CL ?
More than anything else, I think its down to fun and productivity. I feel that I am at my most productive when I writing CL in Emacs+SLIME. It is probably down to the edit-compile-debug cycle which is much shorter in CL compared to other languages. I originally worked on CL way back in 2006-08 when I was with Cleartrip. Since then, I have worked on a number of platforms (frontend js, node, iOS, C, Java, etc.) but always wanted to go back to writing CL full time.
So when I left my last job a little over a year back, I had already made up my mind that the next thing I build would be in CL.
The lack of libraries (or rather, well supported libraries) is a problem, but honestly after over eight years of not working on Lisp, it doesn’t bother me much.
Did you already build software/services in CL, apart the libraries we can see on your github profile ?
As I mentioned I worked at Cleartrip for a little over two years. I was part of the team that managed the flight search engine, Unfortunately most of what we did there is gone forever. A small sliver of our work there resulted in https://lisper.in/restarts (backstory: https://www.reddit.com/r/lisp/comments/7k85sf/a_tutorial_on_conditions_and_restarts/).
Did you have enough libraries to build your service ? How’s deployment and maintenance going ?
Well you could say I had enough libraries. Although I still ended up writing a mini web framework on top of Hunchentoot. Another thing I wrote is my own Lisp-to-SQL converter. Hope to open source both of these one day. Apart from that I use drakma, postmodern, djula, plump, lparallel, cl-json to name a few (alongwith the usual suspects like alexandria and local-time).
Deployment and maintenance is extremely simple - I just update the relevant git branch and restart the service. At some point when the restarts become costly I might add the ability to reload changed code in the running service.
Thanks to him !
Below the backstory from reddit:
Hey that was written by me! (Aside: I redirected the page to point to the latest version of this post on my new blog)
Fun fact: I wrote this post way back in 2008 while working for an online travel portal. This was based on some actual work we’d done there. At that time, flight travel in India had started to boom. This I think went hand in hand with a bunch of online travel companies (including ours) gaining a lot of momentum.
To be more competitive, a couple of airlines decided that they wanted to introduce new discounted fares much more frequently than they were doing earlier. The only problem was that they were unable to upload their wonky fare rules in the GDS properly, so they started distributing excel sheets to travel agents with manual instructions on how to apply them.
So our business team starts sending these sheets over to us, and initially, the frequency was low so we just manually hard coded these rules. However then they started sending these sheets every week or so which made our life hell. So we asked asked our business team to “translate” the airline’s excel sheets and instructions into a csv, which was subsequently interpreted by a simple rules engine that we wrote.
The only problem? Well, as anyone who’s dealt with manually created CSVs will tell you, there were a lot of errors. This didn’t really help matters much. We then added a couple of restarts to our CSV parser which allowed us to correct these issues interactively. This made life much better for us – it was a lot easier than, say, getting a list of errors in a terminal and switching back and forth between the terminal window and the editor to correct them.
Later on we plonked the CSV parser behind hunchentoot and asked our bizdev guy to upload the file there. A handle-bind around the parser collected all the errors in one go and showed them in a nicely formatted way in the browser (see the last section of the post). And so it was no longer our problem :-)
Eventually these airlines decided they wanted to update fare rules daily. Thankfully our “business rules engine” was upto the task. Due to automatic feedback, our friend in bizdev became an expert at uploading the fare rules as soon as they came in. And for quite some time, we were the only ones who could show these cheap fares within minutes of them coming in (if I remember correctly, other portals would take hours to upload the same rules).
Ours was a small team, and we had to manage this in addition to a lot of other things. If it weren’t for CL’s condition system, I doubt we could have solved this as smoothly as we did. In particular, interactive restarts allowed us (devs) to correct CSV errors without wasting a lot of our own time, and without needing to build a full-fledged UI for a non-dev. And when the time did come for a UI, it was dead easy to write a web fontend on top of it.
Q: Did you ever work or need an optimal solution to the Tavelling Salesman Problem?
Nope. Domestic flight travel in India is simple… point to point or max over two legs. For international flights we used QPX.
(QPX was ITA software’s flight search engine. Probably among the biggest software systems written in Lisp. It now powers Google Flights (I think).)
Why Turtl Switched From CL to Js
Lisp journey 11 01 2019
Turtl is a very well done, secure collaborative notebook web app.
Its api backend is built in Common Lisp:
It is based on many async libraries the developer wrote for Turtl, like the Wookie async HTTP server.
“is” ? No, was :/ Even though this repository is still maintained (latest commit: 2nd of december 2018), it is deprecated and the new server is written in NodeJS. I asked Andrew for the reasons behind this, here’s his answer.
(in a hurry to spread FUD ? Don’t miss this posts’s twin, Why Deftask chose Common Lisp ;) See also some companies using Common Lisp)
It was not an easy decision to replace CL with javascript. I find CL to be elegant, fast, stable, and above all else, easy to debug (having the ability to rewrite the program as it’s running is insanely useful). In fact, I still miss lisp and ask myself all the time if I made the right choice.
I think I did, though.
The path I went with CL was a hard one. I wanted to be able to use asynchronous programming because for the type of work I do (a lot of making APIs that talk to other services with very little CPU work) it’s hard to get much more performant. So I embarked on creating cl-async/cl-libuv (originally cl-libevent) and wookie, along with a few other drivers. Everything I built worked great (and still works great, as far as I can tell) however when things did go wrong, there was nobody to run ideas by and nobody to really help me…I had built all these things myself, and I also had to be responsible for fixing them when they broke. On top of having to maintain everything (and it did break from time to time) there is not much in the way of packages to help me out. For instance, there’s a package to upload files to S3, but it’s not async at all…I had to build this from scratch. There are more cases of this as well.
With CL, it felt like I was constantly fighting the tide. I was constantly battling just to get basic things working that are already solved problems in other languages (Node).
There was help and support from the community along the way, but I was mostly fighting it alone. I think the straw that broke the camel’s back was when a few people started making copycat projects that added no real value (other than benchmarking fast) but stole mindshare from all the work I had put in. It was the “well, that project is not exactly what I want so I’ll make my own from scratch” mindset that everyone always warned about when I was starting with CL (but I ignored). I had really hoped the community would have helped propel the async ecosystem I was building forward, but I just don’t think there’s enough people using CL for that to happen.
So between having to maintain everything myself and people putting out worthless copycat projects that ended up going nowhere, I didn’t have the energy anymore.
Honestly, it took me about a week of work, just nights and weekends, to reprogram the server in javascript. Granted, most of the “how should this work?” architecture stuff was already done so it was more of a rewrite than a build-from-scratch situation, but Node is fast to build APIs in. I’m decently fluent in javascript and the amount packages available is so immense that it just made sense.
On top of being fast to build in, it’s a well-traveled road. I don’t have people emailing me six times a day asking how to install the server like I did with CL. I don’t have to make weird custom loaders to run the app on any hosting providers…everyone supports Node. I don’t have to deal with weird FFI errors or libuv nuances. I don’t have to deal with quicklisp’s “all or nothing” packaging that doesn’t support version pinning. I don’t have to restart the server every 20 days because of some memory leak I have yet to track down somewhere between cl-libuv, cl-async, wookie, and turtl. There’s a whole set of bullshit I just don’t have to deal with anymore.
So I do miss lisp. I’d eventually like to build more things in it (like games). But I don’t think I’ll ever touch web stuff in CL again, and the whole journey left a bitter taste in my mouth. Sure I could have dropped the async thing and just done a threaded server in hunchentoot and cl-postgres. But once I decided I was going to reprogram everything anyway, it just made sense to go with Node.
I took on more work than I could realistically manage, and hoped that the community would help…but the CL community is small enough that it was a losing bet and I got burned out.
Hopefully none of this discourages you. CL is a great language. The community is a mix though. Some of the people in the community are smart and dedicated, and work on cool projects at a pace they can maintain. You won’t see articles about these projects, and many will only have a handful of stars on Github (don’t measure CL projects by stars). Seek these projects and these people out, and build things with them. There is a quiet corner of the internet, with a handful of people building amazing things in lisp.
Before commenting on this, I think we must realize what he achieved, and that he went the hard way.
Now don’t miss Why Deftask chose Common Lisp !
When I started dabbling in CL, I tried to build a readline application to see how it goes. I found cl-readline (I’m only the new maintainer) and it went smoothly. So I built a second and a third app, and found many things to refactor and provide out of the box: now comes replic.
It comes as a library (now in Quicklisp, since 2018-01) and as an executable. The library does the following for you:
- it builds the repl loop, catches a C-c, a C-d, errors,
- it asks confirmation to quit,
- it asks depending on a .conf and a lispy config file,
- it reads parameters from a config file,
- it prints the help of all or one command (with optional highlighting),
- and more importantly it handles the completion of commands and of their arguments.
For example, instead of this “repl” loop:
(handler-case
(do ((i 0 (1+ i))
(text "")
(verb "")
(function nil)
(variable nil)
(args ""))
((string= "quit" (str:trim text)))
(handler-case
(setf text
(rl:readline :prompt (prompt)
:add-history t))
(#+sbcl sb-sys:interactive-interrupt ()
(progn
(when (confirm)
(uiop:quit)))))
(if (string= text "NIL")
;; that's a C-d, a blank input is just "".
(when (confirm)
(uiop:quit)))
(unless (str:blank? text)
(setf verb (first (str:words text)))
(setf function (if (replic.completion:is-function verb)
;; might do better than this or.
(replic.completion:get-function verb)))
(setf variable (if (replic.completion:is-variable verb)
(replic.completion:get-variable verb)))
(setf args (rest (str:words text)))
(if (and verb function)
(handler-case
;; Call the function.
(apply function args)
(#+sbcl sb-sys:interactive-interrupt (c)
(declare (ignore c))
(terpri))
(error (c) (format t "Error: ~a~&" c)))
(if variable
(format t "~a~&" (symbol-value variable))
(format t "No command or variable bound to ~a~&" verb)))
(finish-output)
(when (and *history*
*write-history*)
(rl:write-history "/tmp/readline_history"))
))
(error (c)
(format t "~&Unknown error: ~&~a~&" c)))
you call:
(replic:repl)
To turn all exported functions of a package into commands, use
(replic:functions-to-commands :my-package)
and you can find them into the readline app.
Setting the completion of commands is easy, we use
(replic.completion:add-completion "my-function" <list-or-lambda>. For example:
(in-package :replic.user)
(defparameter *names* '()
"List of names (string) given to `hello`. Will be autocompleted by `goodbye`.")
(defun hello (name)
"Takes only one argument. Adds the given name to the global
`*names*` variable, used to complete arguments of `goodbye`.
"
(format t "hello ~a~&" name)
(push name *names*))
(defun goodbye (name)
"Says goodbye to name, where `name` should be completed from what was given to `hello`."
(format t "goodbye ~a~&" name))
(replic.completion:add-completion "goodbye" (lambda () *names*))
(export '(hello goodbye))
This example can be used with the executable. What it does is read
your code from a lisp file (~/.replic.lisp or an argument on the
command line) and it turns the exported functions into commands, for
which we can specify custom completion.
For more details, see the readme.
I use this currently in three apps of mine (like cl-torrents). It’s simple. It could be more: it could infer the arguments’ type, do fuzzy completion, maybe integrate a Lisp editor (Lem) or a lispy shell (shcl), separate the commands in apps, expose hooks, have a set of built-in shell related utilities, highlight the input line, it could be web-based,…
For now it’s going smoothly.
I’ll finish by recalling that it’s amazing to be able to ship self-contained executables to users !

Library Unboxing
MonkeyUser 08 01 2019
State of Clojure 2019 Survey
Clojure News 07 01 2019
It’s time for the annual State of Clojure Community Survey!
If you are a user of Clojure or ClojureScript, we are greatly interested in your responses to the following survey:
The survey contains four pages:
-
General questions applicable to any user of Clojure or ClojureScript
-
Questions specific to JVM Clojure (skip if not applicable)
-
Questions specific to ClojureScript (skip if not applicable)
-
Final comments
The survey will close January 22nd, after which all of the data will be released with some analysis. We greatly appreciate your input!
Modeling Polymorphism in Django
Haki Benita 01 01 2019
Modeling polymorphism in relational databases is a challenging task. In this article, we present several modeling techniques to represent polymorphic objects in a relational database using the Django object-relational mapping (ORM).
When we are using emacs sometimes we often open many buffers in different windows at the same time, for example we can have a buffer for a opened file, another for seeing test results and so on.
There are some tools to manage "sessions" but I wanted something simple and I also wanted to learn a little bit more of elisp so here is the result.
(defvar window-snapshots '())
(defun save-window-snapshot ()
"Save the current window configuration into `window-snapshots` alist."
(interactive)
(let ((key (read-string "Enter a name for the snapshot: ")))
(setf (alist-get key window-snapshots) (current-window-configuration))
(message "%s window snapshot saved!" key)))
(defun get-window-snapshot (key)
"Given a KEY return the saved value in `window-snapshots` alist."
(let ((value (assoc key window-snapshots)))
(cdr value)))
(defun restore-window-snapshot ()
"Restore a window snapshot from the window-snapshots alist."
(interactive)
(let* ((snapshot-name (completing-read "Choose snapshot: " (mapcar #'car window-snapshots)))
(snapshot (get-window-snapshot snapshot-name)))
(if snapshot
(set-window-configuration snapshot)
(message "Snapshot %s not found" snapshot-name))))The code basically do 3 things:
-
Define an
alistwhere window configurations will be saved -
Save the current window configuration using a name to be identified later.
-
Restore any of the saved configurations by selecting it from a list
Now let's get into the details:
Save the current window configuration
We will use the function current-window-configuration to get the current state of the windows and put this value in an alist called window-snapshots. Also it should asks for a name so we can search for it later.
(defvar window-snapshots '())
(defun save-window-snapshot ()
"Save the current window configuration into `window-snapshots` alist."
(interactive)
(let ((key (read-string "Enter a name for the snapshot: ")))
(setf (alist-get key window-snapshots) (current-window-configuration))
(message "%s window snapshot saved!" key)))Restore a window configuration
We will use completing-read to select one of the saved snapshots from an interactive list. It will use helm 1 or ivy 2 if any of those are installed otherwise it will show the options in the minibuffer.
This will show the name used before and retrieve the value of the window configuration. Then it will apply the configuration using set-window-configuration.
(defun get-window-snapshot (key)
"Given a KEY return the saved value in `window-snapshots` alist."
(let ((value (assoc key window-snapshots)))
(cdr value)))
(defun restore-window-snapshot ()
"Restore a window snapshot from the window-snapshots alist."
(interactive)
(let* ((snapshot-name (completing-read "Choose snapshot: " (mapcar #'car window-snapshots)))
(snapshot (get-window-snapshot snapshot-name)))
(if snapshot
(set-window-configuration snapshot)
(message "Snapshot %s not found" snapshot-name))))

Si nuestro volumen del sistema es muy bajo incluso aunque pongamos los altavoces al 100% existe la posibilidad de forzar al sistema a aumentar el volumen por encima del máximo. Para ello primero tenemos que instalar el programa que se comunica con el hardware de nuestro equipo.
[code]sudo apt install pulseaudio-utils[/code]
Después de instalar el programa debemos reiniciar el sistema para que los cambios surjan efecto. Para forzar el volumen del sistema por encima del 100% usaremos el siguiente comando:
[code]pactl set-sink-volume 0 175%[/code]
Con esto el volumen de nuestro sistema estará configurado al 175% (por encima de este valor se distorsiona mucho el sonido). El "0" es el indice de la tarjeta de sonido sobre la que estamos aplicando los cambios, para ver las tarjetas de sonido disponibles para nuestro sistema solo tenemos que introducir el siguiente comando:
[code]pacmd list-sinks | grep -e 'name:' -e 'index'[/code]
Una vez dentro de la BIOS (Si no sabes como entrar a la BIOS puedes ver este tutorial):
Para activar/desactivar el arranque UEFI iremos hacia la pestaña "Boot" usando las flechas, dentro de Boot seleccionaremos "UEFI Setting".
Una vez dentro podemos activar/desactivar el UEFI Boot.
Luego nos iremos a la pestaña "Save & Exit" y pulsaremos en "Save Changes and Exit" o pulsaremos directamente la tecla"F10" para guardar y salir.
Una vez dentro de la BIOS (Si no sabes como entrar a la BIOS puedes ver este tutorial):
Para activar/desactivar el arranque UEFI iremos hacia la pestaña "Chipset" usando las flechas, dentro de Chipset seleccionaremos "CSM Configuration".
Una vez dentro podemos cambiar el Boot option filter.
Luego nos iremos a la pestaña "Save & Exit" y pulsaremos en "Save Changes and Exit" o pulsaremos directamente la tecla"F10" para guardar y salir.
Projects
(ノ°Д°)ノ︵ ┻━┻ 24 12 2018
A while back we started getting alerts in the middle of the night on low disk space. A quick investigation led us to one of our ETL tasks. Every night the task was fired to eliminate duplicate dumps, and free up some space. This is a short story about how we found our silver bullet and solved the issue without adding a single byte of storage.
Escape The Office (The Game)
MonkeyUser 21 12 2018
Escape the office. Merry X-Mas everybody

Debugging in Common Lisp
Lisp journey 20 12 2018
You entered this new world of Lisp and now wonder: how can we debug what’s going on ? How is it more interactive than in other platforms ? What does bring the interactive debugger appart from stacktraces ?
note: this tutorial is available on the Common Lisp Cookbook and it will receive updates there.
If you want step-by-step examples of interactive debugging with nice screenshots and gifs, see the blog posts in the References section below.
Table of Contents
- Print debugging
- Logging
- Using the powerful REPL
- Inspect and describe
- The interactive debugger
- Trace
- Step
- Break
- Advise and watch
- Unit tests
- References
Print debugging
Well of course we can use the famous technique of “print debugging”. Let’s just recap a few print functions.
print works, it prints a READable representation of its argument,
which means what is printed can be read back in by the Lisp
reader.
princ focuses on an aesthetic representation.
format t "~a" …), with the aesthetic directive, prints a string (in t, the standard output
stream) and returns nil, whereas format nil … doesn’t print anything
and returns a string. With many format controls we can print several
variables at once.
Logging
Logging is a good evolution from print debugging ;)
log4cl is the popular, de-facto logging library but it isn’t the only one. Download it:
(ql:quickload :log4cl)
and let’s have a dummy variable:
(defvar *foo* '(:a :b :c))
We can use log4cl with its log nickname, then it is as simple to use as:
(log:info *foo*)
;; <INFO> [13:36:49] cl-user () - *FOO*: (:A :B :C)
We can interleave strings and expressions, with or without format
control strings:
(log:info "foo is " *foo*)
;; <INFO> [13:37:22] cl-user () - foo is *FOO*: (:A :B :C)
(log:info "foo is ~{~a~}" *foo*)
;; <INFO> [13:39:05] cl-user () - foo is ABC
With its companion library log4slime, we can interactively change
the log level:
- globally,
- per package,
- per function,
- and by CLOS methods and CLOS hierarchy (before and after methods).
It is very handy, when we have a lot of output, to turn off the logging of functions or packages we know to work, and thus narrowing our search to the right area. We can even save this configuration and re-use it in another image, be it on another machine.
We can do all this through commands, keyboard shortcuts and also through a menu or mouse clicks.
We invite you to read log4cl’s readme.
Using the powerful REPL
Part of the joy of Lisp is the excellent REPL. Its existence usually delays the need to use other debugging tools, if it doesn’t annihilate them for the usual routine.
As soon as we define a function, we can try it in the REPL. In Slime,
compile a function with C-c C-c (the whole buffer with C-c C-k),
switch to the REPL with C-c C-z and try it. Eventually enter the
package you are working on with (in-package :your-package).
The feedback is immediate. There is no need to recompile everything, nor to restart any process, nor to create a main function and define command line arguments for use in the shell (we can do this later on when needed).
We usually need to create some data to test our function(s). This is a
subsequent art of the REPL existence and it may be a new discipline
for newcomers. A trick is to write the test data alongside your
functions but inside a #+nil declaration so that only you can
manually compile them:
#+nil
(progn
(defvar *test-data* nil)
(setf *test-data* (make-instance 'foo …)))
When you load this file, *test-data* won’t exist, but you can
manually create it with a C-c C-c away.
We can define tests functions like this.
Some do similarly inside #| … |# comments.
All that being said, keep in mind to write unit tests when time comes ;)
Inspect and describe
These two commands share the same goal, printing a description of an
object, inspect being the interactive one.
(inspect *foo*)
The object is a proper list of length 3.
0. 0: :A
1. 1: :B
2. 2: :C
> q
We can also, in editors that support it, right-click on any object in
the REPL and inspect them. We are presented a screen where we can
dive deep inside the data structure and even change it.
Let’s have a quick look with a more interesting structure, an object:
(defclass foo ()
((a :accessor foo-a :initform '(:a :b :c))
(b :accessor foo-b :initform :b)))
;; #<STANDARD-CLASS FOO>
(make-instance 'foo)
;; #<FOO {100F2B6183}>
We right-click on the #<FOO object and choose “inspect”. We are
presented an interactive pane (in Slime):
#<FOO {100F2B6183}>
--------------------
Class: #<STANDARD-CLASS FOO>
--------------------
Group slots by inheritance [ ]
Sort slots alphabetically [X]
All Slots:
[ ] A = (:A :B :C)
[ ] B = :B
[set value] [make unbound]
When we click or press enter on the line of slot A, we inspect it further:
#<CONS {100F5E2A07}>
--------------------
A proper list:
0: :A
1: :B
2: :C
The interactive debugger
Whenever an exceptional situation happens (see error handling), the interactive debugger pops up.
It presents the error message, available actions (restarts), and the backtrace. A few remarks:
- the restarts are programmable, we can create our owns,
- in Slime, press
von a stacktrace to be redirected to the source file at the right line, - hit enter on a frame for more details,
- we can explore the functionnality with the menu that should appear in our editor. See below in “break” section for a few more commands (eval in frame, etc).
Usually your compiler will optimize things out and this will reduce
the amount of information available to the debugger. For example
sometimes we can’t see intermediate variables of computations. You might
want to print a function argument (with e to “eval in frame”, see
below), but you keep getting a Variable XYZ is unbound error.
To fix this, we have to change the optimization choices with declaim, at the beginning of the file:
(declaim (optimize (speed 0) (space 0) (debug 3)))
or with declare, inside a defun:
(defun my-fun (xyz)
(declare (optimize (debug 3)))
…)
and recompile the code. Now you should be able to see local variables such asxyz.
Trace
trace allows us to see when a function was called, what arguments it received, and the value it returned.
(defun factorial (n)
(if (plusp n)
(* n (factorial (1- n)))
1))
(trace factorial)
(factorial 2)
0: (FACTORIAL 3)
1: (FACTORIAL 2)
2: (FACTORIAL 1)
3: (FACTORIAL 0)
3: FACTORIAL returned 1
2: FACTORIAL returned 1
1: FACTORIAL returned 2
0: FACTORIAL returned 6
6
(untrace factorial)
To untrace all functions, just evaluate (untrace).
In Slime we also have the shortcut C-c M-t to trace or untrace a
function.
If you don’t see recursive calls, that may be because of the compiler’s optimizations. Try this before defining the function to be traced:
(declaim (optimize (debug 3)))
The output is printed to *trace-output* (see the CLHS).
In Slime, we also have an interactive trace dialog with M-x
slime-trace-dialog bound to C-c T.
Tracing method invocation
In SBCL, we can use (trace foo :methods t) to trace the execution order of method combination (before, after, around methods). For example:
(trace foo :methods t)
(foo 2.0d0)
0: (FOO 2.0d0)
1: ((SB-PCL::COMBINED-METHOD FOO) 2.0d0)
2: ((METHOD FOO (FLOAT)) 2.0d0)
3: ((METHOD FOO (T)) 2.0d0)
3: (METHOD FOO (T)) returned 3
2: (METHOD FOO (FLOAT)) returned 9
2: ((METHOD FOO :AFTER (DOUBLE-FLOAT)) 2.0d0)
2: (METHOD FOO :AFTER (DOUBLE-FLOAT)) returned DOUBLE
1: (SB-PCL::COMBINED-METHOD FOO) returned 9
0: FOO returned 9
9
See the CLOS section for a tad more information.
Step
step is an interactive command with
similar scope than trace. This:
(step (factorial 2))
gives an interactive pane with the available restarts:
Evaluating call:
(FACTORIAL 2)
With arguments:
2
[Condition of type SB-EXT:STEP-FORM-CONDITION]
Restarts:
0: [STEP-CONTINUE] Resume normal execution
1: [STEP-OUT] Resume stepping after returning from this function
2: [STEP-NEXT] Step over call
3: [STEP-INTO] Step into call
4: [RETRY] Retry SLIME REPL evaluation request.
5: [*ABORT] Return to SLIME's top level.
--more--
Backtrace:
0: ((LAMBDA ()))
1: (SB-INT:SIMPLE-EVAL-IN-LEXENV (LET ((SB-IMPL::*STEP-OUT* :MAYBE)) (UNWIND-PROTECT (SB-IMPL::WITH-STEPPING-ENABLED #))) #S(SB-KERNEL:LEXENV :FUNS NIL :VARS NIL :BLOCKS NIL :TAGS NIL :TYPE-RESTRICTIONS ..
2: (SB-INT:SIMPLE-EVAL-IN-LEXENV (STEP (FACTORIAL 2)) #<NULL-LEXENV>)
3: (EVAL (STEP (FACTORIAL 2)))
Stepping is useful, however it may be a sign that you need to simplify your function.
Break
A call to break makes the program enter the debugger, from which we can inspect the call stack.
Breakpoints in Slime
Look at the SLDB menu, it shows navigation keys and available
actions. Of which:
e(sldb-eval-in-frame) prompts for an expression and evaluates it in the selected frame. This is how we can explore our intermediate variables.dis similar with the addition of pretty printing the result.
Once we are in a frame and detect a suspicious behavior, we can even re-compile a function at runtime and resume the program execution from where it stopped (using the “step-continue” restart).
Advise and watch
advise and
watch are available in some vendor
implementations, like LispWorks. They are not available in
SBCL. advise allows to modify a function without changing its
source, or to do something before or after its execution, like CLOS’
method combination (befor, after around methods).
watch allows to specify variables to be displayed in some GUI during
the program execution.
Unit tests
Last but not least, automatic testing of functions in isolation might be what you’re looking for ! See the testing section and a list of test frameworks and libraries.
References
- “How to understand and use Common Lisp”, chap. 30, David Lamkins (book download from author’s site)
- Malisper: debugging Lisp series
- Two Wrongs: debugging Common Lisp in Slime
Clojure 1.10 release
Clojure News 17 12 2018
Clojure 1.10 focuses on two major areas: improved error reporting and Java compatibility.
Error reporting at the REPL now categorizes errors based on their phase of execution (read, macroexpand, compile, etc). Errors carry additional information about location and context as data, and present phase-specific error messages with better location reporting. This functionality is built into the clojure.main REPL, but the functionality is also available to other REPLs and tools with the ability to use and/or modify the data to produce better error messages.
Clojure 1.10 now requires Java 8 or above and has been updated particularly for compatibility with Java 8 and Java 11. Changes included bytecode-related bug fixes, removed use of deprecated APIs, and updates related to the module system introduced in Java 9.
See the change log for a complete list of all fixes, enhancements, and new features in Clojure 1.10.
Contributors
Thanks to all of the community members who contributed patches to Clojure 1.10 (first time contributors in bold):
-
Alexander Kiel
-
Ben Bader
-
Bruce Adams
-
Cezary Kosko
-
Erik Assum
-
Eugene Kostenko
-
Ghadi Shayban
-
Gijs Stuurman
-
Jozef Wagner
-
Kwang Yul Seo
-
Matthew Gilliard
-
Michał Marczyk
-
Nicola Mometto
-
Nikita Prokopov
-
Sean Corfield
-
Sebastien Martel
-
Shogo Ohta
-
Stuart Sierra

Replace All
MonkeyUser 12 12 2018

Instapaper 7.7 is now live in the iOS App Store with support for iPad Pro, Smart Keyboard shortcuts, and a True Black theme for iPhone X devices.
For Smart Keyboards, Instapaper now supports the following shortcuts:
- ▲ and ▼ to navigate through articles in list view, ◀ and ▶ to navigate through articles in grid view
- ↩ to open article from list
- ⌘+A to archive an article
- ⌘+M to move an article
- ⌘+D to delete an article
- ⌘+◀ to navigate back
- ⌘+F to perform a local, title-based search
- ⌘+⇧+ F to trigger full-text search for Premium users
- Esc to leave search
- Space and ⇧+space to page up and down in list or from inside article
In case you forget, holding ⌘ will bring up the list of shortcuts available on the current screen.
It took a considerable amount of work to get basic navigational support for Smart Keyboards, so we created an open source library called IPShortcut that provides Smart Keyboard shortcuts for table views, collection views, and scroll views.
The new True Black theme takes advantage of the OLED screens for iPhone X, iPhone XS, and iPhone XS Max to offer an even better experience when reading in dark mode. Screens on these devices display black by turning those pixels off on the screen, which is particularly great for reading at night. To get started, just switch to the dark mode theme on one of these devices.
If you have any questions, feature requests, or issues you’d like us to sort out, please let us know at support@instapaper.com or @InstapaperHelp on Twitter. We love hearing from you and we thank you for using Instapaper!
- Instapaper Team
Hey, pardon this very short post, it’s just for the pleasure of blogging, and to balance the usual lengthy ones.
I wanted to commit, one by one, every file of the current directory (it’s useless, don’t ask).
I use legit as the interface to Git, and this one-liner:
(dolist (file (uiop:directory-files "./"))
(legit:git-add :paths (pathname file))
(legit:git-commit :files (pathname file) :message (format nil "add ~a" (file-namestring file))))
I guessed the :paths and :files arguments with Slime’s command
argument list which appears in the modline, I wanted a function to
convert a /full/path/file.cl to a name file.cl and tried the
completion for file-… and found the right thing without effort. I
saw on the complete documentation that legit:commit wanted a
repository object as first argument, which makes sense, but
legit:git-commit doesn’t and I just iterate on the current working
directory (btw change it in Slime with the ,cd command) so it was
shorter for me.
Just a one liner.
Oh my god, I didn’t know we can do this in Lisp !
Of course we can :p

Trial And
MonkeyUser 04 12 2018

Luego de un tiempo sin escribir, retomo los artículos sobre Ciencia de Datos, ahora con visualización de datos. Para ello se usará la estadística de un repositorio de datos sobre los pokemon.
El gráfico radar es un gráfico que consiste en una secuencia de radios equi-angulares, llamados radios, y cada radio representa una de las variables. La longitud de los datos de un radio es proporcional a la magnitud de la variable para el punto de datos en relación con la longitud máxima de la variable en todos los puntos de datos. Se dibuja una línea que conecta con los valores de los datos para cada radio. Esto le da a la trama una apariencia de estrella (wikipedia). Pueden ver un ejemplo en la siguiente figura:
La idea es mostrar multiples variables sobre la información que se tiene de los pokemons. El repositorio de datos de donde se obtiene los datos para trabajar es el sitio de kaggle.
La librería de Python que se usará en este artículo para visualizar los datos usando la gráfica radar se llama plotly, en el siguiente enlace podrán ver una galería de gráficas usando python, ya que dicha librería se puede usar también en el Lenguaje R y en Javascript. Lo bueno de plotly es que maneja más interactividad o dinamismo a las gráficas, no son simples gráficas estáticas. Plotly se puede usar en línea o desconectado.
La idea de hacer este artículo sobre visualizando estadísticas de pokemon usando plotly fue de un artículo donde usan la gráfica radar pero con matplotlib.
El tutoral básico de como usar la gráfica radar en plotly lo pueden ver en el siguiente enlace.
Este artículo se basa en un notebook que se encuentra en kaggle.
La información que contiene el repositorio es la siguiente:
- #: ID de cada pokemon.
- Name: Nombre de cada pokemon.
- Type 1: Cada pokemon tiene un tipo, esto determina su debilidad/resistencia a ataques.
- Type 2: Algunos pokemon tienen dos tipos.
- Total: Suma de todas las estadísticas.
- HP: Hit point, o health.
- Defense: Nivel de resistencia a los ataques.
- SP Atk: ataque especial.
- SP Def: Resistencia contra ataques especiales.
- Speed: Velocidad en el ataque.
Visualización de estadística de pokemon usando gráfica de radar¶
Enlaces de interés¶
https://typewind.github.io/2017/09/29/radar-chart/https://www.kaggle.com/abcsds/pokemon/data
https://plot.ly/python/radar-chart/
https://www.kaggle.com/thebrownviking20/intermediate-visualization-tutorial-using-plotly
Se importa las librerías necesarias¶
In [1]:
import pandas as pd
import numpy as np
import plotly.plotly as py
import plotly.graph_objs as go
import plotly
import matplotlib.pyplot as plt
from plotly import tools
from plotly.offline import init_notebook_mode, iplot
init_notebook_mode(connected=True)
import plotly.figure_factory as ff
from IPython.display import HTML, Image
Se lee y convierte el archivo csv de los datos de pokemon en un dataframe¶
In [2]:
df=pd.read_csv("./datos/Pokemon.csv")
Se muestra las 5 primeras filas de datos¶
In [3]:
df.head()
Out[3]:
Se muestra el tipo de dato de cada columna que maneja el dataframe.¶
In [4]:
df.info()
Se visualiza los datos de un sólo pokemon¶
In [5]:
#Se busca los datos del pokemon Charizard
x = df[df["Name"] == "Charizard"]
#Se crea la grafica scatterpolar donde se le pasa las variables que se quiere graficar. HP, Ataque, defensa, SP atk,
#Sp def, velocidad y se define los nombres de los ejes.
data = [go.Scatterpolar(
r = [x['HP'].values[0],x['Attack'].values[0],x['Defense'].values[0],x['Sp. Atk'].values[0],x['Sp. Def'].values[0],x['Speed'].values[0],x["HP"].values[0]],
theta = ['HP','Attack','Defense','Sp. Atk','Sp. Def','Speed','HP'],
fill = 'toself'
)]
# se crea el layout, donde se le pasa un diccionario donde se define los ejes de los radios, que son visibles y
#su rango en este caso desde 0 a 250, no se muestra legenda, y el título de la gráfica.
layout = go.Layout(
polar = dict(
radialaxis = dict(
visible = True,
range = [0, 250]
)
),
showlegend = False,
title = "Stats of {}".format(x.Name.values[0])
)
#Se crea la instancia fig donde se pasa los datos y el layout.
fig = go.Figure(data=data, layout=layout)
#Se gràfica la gráfica
iplot(fig, filename = "Single Pokemon stats")
Comparación de 2 pokemons¶
In [6]:
# Se crea una función donde se hace la comparación vía gráfica de la estadística de dos pokemons.
def compare2pokemon(x,y):
#Se captura los datos de los dos pokemons
x = df[df["Name"] == x]
y = df[df["Name"] == y]
#Se define lo que se quiere gráficar del primer y segundo pokemon.
trace0 = go.Scatterpolar(
r = [x['HP'].values[0],x['Attack'].values[0],x['Defense'].values[0],x['Sp. Atk'].values[0],x['Sp. Def'].values[0],x['Speed'].values[0],x["HP"].values[0]],
theta = ['HP','Attack','Defense','Sp. Atk','Sp. Def','Speed','HP'],
fill = 'toself',
name = x.Name.values[0]
)
trace1 = go.Scatterpolar(
r = [y['HP'].values[0],y['Attack'].values[0],y['Defense'].values[0],y['Sp. Atk'].values[0],y['Sp. Def'].values[0],y['Speed'].values[0],y["HP"].values[0]],
theta = ['HP','Attack','Defense','Sp. Atk','Sp. Def','Speed','HP'],
fill = 'toself',
name = y.Name.values[0]
)
#se define data como una lista que contiene los datos de los dos pokemon
data = [trace0, trace1]
#Se define el layout como en la gráfica anterior.
layout = go.Layout(
polar = dict(
radialaxis = dict(
visible = True,
range = [0, 200]
)
),
showlegend = True,
title = "{} vs {}".format(x.Name.values[0],y.Name.values[0])
)
#Se crea la instancia donde se pasa los datos y el layout
fig = go.Figure(data=data, layout=layout)
#Se crea la grafica.
iplot(fig, filename = "Two Pokemon stats")
In [7]:
# Se compara primeape y muk
compare2pokemon("Primeape", "Muk")

En siguientes artículos se seguirá mostrando ejemplos de usos de la galería de gráficas de plotly.
![]()
The Trackers Who Steal
WhoTracksMe blog 22 11 2018

Opinions
MonkeyUser 14 11 2018

Overview of Documentation Generators
Lisp journey 07 11 2018
I have a simple need: I’d like to generate an html documentation from my code. What options do we have ?
I searched for “documentation tool” on Quickdocs: http://quickdocs.org/search?q=documentation%20tool, from which I remove old ones (clod, qbook, manifest).
I had two pure Lisp solutions working out of the box, two more are of interest, and there’s another non-Lisp of interest.
update: just found out that qbook (github mirror)is used for the documentation of Fiveam, which is pretty nice: https://common-lisp.net/project/fiveam/docs/index.html It can produce html and latex. It uses docstrings and comments that start with 4 commas to structure the page (exple in source that gives this). Running it has a lot of asdf deprecation warnings and it did not work out of the box for me (“The slot IT.BESE.QBOOK::GENERATOR is unbound in the object”).
Codex
Codex produces nice html but isn’t automatic.
- https://github.com/CommonDoc/codex (by @eudoxia)
- example: https://commondoc.github.io/codex/docs/tutorial.html
- input fromat: scriba by default. No more format it seems.
- output: multiple html files.
- rendering: modern, colored, light, TOC on the side
- granularity: good
- link to CLHS: yes
- totally automatic: no (one needs to create the documentation structure in
manual.lisp, AFAIU). - used in the wild: yes
Getting started: write a simple docs/manifest.lisp and docs/manual.lisp.
Am I mistaking ? It’s exclusively manual. We must supply every
function/generic function/method/class/macro to document in
manual.lisp.
Coo
Coo is a new tool in town, it works out of the box and it is actively developed !
- https://github.com/fisxoj/coo
- https://fisxoj.github.io/coo/
- input: docstrings in
rst - output: multiple html
- rendering: black & white, no TOC (active development)
- links to CLHS: yes, since yesterday :)
- granularity: doesn’t show class slots, doesn’t show generic functions.
- used in the wild: coo no, more probably cl-docutils.
Based on cl-docutils.
Displays the functions’ documentation following their order in source (or not ? I saw exceptions).
It’s straightforward:
(coo:document-system :my-system)
and it produces html into docs/.
Staple (doesn’t work on Debian’s SBCL 1.2.4)
You may be familiar with Staple since it’s used by Shinmera in all his projects.
- https://github.com/Shinmera/staple
- output: html. The documentation string is plain text (no markup, rendered in a
<pre>tag). - cross-references
- can use a template.
- more features than listed here.
It doesn’t support SBCL 1.2.4, so my tests fell short (upgrading isn’t 100% smooth here). If you’re on SBCL >= 1.4.8 Staple is a good option.
Declt
Declt has higher goals than “quick and easy” documentation generator.
- https://github.com/didierverna/declt
- https://www.lrde.epita.fr/~didier/software/lisp/declt/
- output: a
.texifile, that we can render into other formats (html, pdf). - cross-references: yes
It didn’t work out of the box (and had no explicit error information) and it’s also too involved for my use case.
Documentation-tool (not for general use)
It’s the template used for Edi Weitz software, like Hunchentoot.
- https://edicl.github.io/documentation-template/
- output: one html file
It works, but it thinks you publish an edicl software and has some hardcoded “http://weitz.de/files/…" urls.
Tinaa (unmaintained)
I liked the output, but it didn’t work (asdf-related error), and it’s unmaintained (authors’ words).
- https://github.com/gwkkwg/tinaa
- https://common-lisp.net/project/tinaa/documentation/index.html
- output: html
See also
cl-domain (Sphinx)
Another excellent option is 40ants’ cldomain, which builds on Python’s proven Sphinx:
CLDomain is an extension for the Sphinx documentation generation tool that allow sphinx to generate documentation for Common Lisp libraries. Documentation is extracted from the various entity’s documentation strings, loaded from ASDF systems and associated internal packages.
They use it for they new projects since around 3 years now.
- https://github.com/40ants/cldomain
- http://40ants.com/cldomain/
- input: rst
- output: many html
- HyperSpec links: yes
- requirements: Python, pip
udate 2019-01-22: extended example.
An example from cl-hamcrest:
- we reference Lisp functions/methods/macros with RST directives:
Object matchers
===============
This kind of matchers checks some sort of properties on an object, etc.
.. cl:package:: hamcrest/matchers
.. cl:macro:: has-plist-entries
- they have RST docstrings, also with RST directives to include code blocks:
(def-has-macro
has-plist-entries
"Matches plist entries:
.. code-block:: common-lisp-repl
TEST> (let ((obj '(:foo :bar)))
(assert-that obj
(has-plist-entries :foo \"bar\"
:blah \"minor\")))
× Key :FOO has :BAR value, but \"bar\" was expected
This way you can test any number of plist's entries."
:check-obj-type (check-if-list object)
:get-key-value (let ((key-value (getf object key 'absent)))
(when (eql key-value 'absent)
…
- this produces a nice output (here):
I’ll use and watch Coo !

Last Push
MonkeyUser 06 11 2018
Optimizing the Django Admin Paginator
Haki Benita 05 11 2018
I often talk about making Django scale but what does it actually mean? It means getting consistent performance regardless of the amount of data. In this article we tackle The last nail in Django admin's scalability coffin - the paginator.

Reminiscing
MonkeyUser 30 10 2018
We just installed a comment system, and it isn’t Disqus ! We just discovered https://utteranc.es/, a lightweight widget based on Github issues. If it doesn’t find an issue corresponding to the current article, it will create one and post your comment there. Simple :) You dreamed of it ? They did it.

Test Optimization
MonkeyUser 24 10 2018

Priorities
MonkeyUser 17 10 2018
Continuando con los artículos sobre ciencia de datos, esta vez se analizará datos sobre información del clima global y por países, así como los niveles de CO2.
Estos datos y proyecto los encontré en el sitio kaggle, este sitio es para publicar proyectos de ciencia de datos. Los datos para este artículo lo encuentran en el siguiente enlace.
El código de este artículo se basa en el artículo que se encuentra en kaggle sobre el tema en inglés Climate Change and CO2 levels in atmosphere.
En este artículo se explora los cambios globales de la temperatura media y el incremento de la concentración del CO2 en la atmosfera.
Los datos se obtienen de los siguientes archivos:
- GlobalLandTemperaturesByCountry.csv: Contiene la información de la temperatura por país.
- GlobalTemperatures.csv: Contiene la información global de la temperatura.
- archive.csv: Contiene la información de los niveles de CO2 en la atmosfera.
A continuación se muestra el notebook:
Se importa las librerías de pantas, matplotlib y seaborn.¶
In [1]:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
Se crea los dataframes a partir de los archivos csv.¶
In [2]:
# Se crea el dataframe data_pais, data_vzla, data_global y co2_ppm
data_pais = pd.read_csv("./datos/GlobalLandTemperaturesByCountry.csv")
#Se crea una copia del dataframe obteniendo solo la información de Venezuela.
data_vzla = data_pais[data_pais["Country"] == "Venezuela"].copy()
data_vzla["dt"] = pd.to_datetime(data_vzla["dt"])
#Se crea una copia del dataframe obteniendo solo la información de Argentina.
data_arg = data_pais[data_pais["Country"] == "Argentina"].copy()
data_arg["dt"] = pd.to_datetime(data_arg["dt"])
#Se crea una copia del dataframe obteniendo solo la información de USA.
data_canada = data_pais[data_pais["Country"] == "Canada"].copy()
data_canada["dt"] = pd.to_datetime(data_canada["dt"])
#Se crea una copia del dataframe obteniendo solo la información de Mexico.
data_mexico = data_pais[data_pais["Country"] == "Mexico"].copy()
data_mexico["dt"] = pd.to_datetime(data_mexico["dt"])
#Se crea una copia del dataframe obteniendo solo la información de Brasil.
data_brasil = data_pais[data_pais["Country"] == "Brazil"].copy()
data_brasil["dt"] = pd.to_datetime(data_brasil["dt"])
#Se crea una copia del dataframe obteniendo solo la información de Venezuela.
data_chile = data_pais[data_pais["Country"] == "Chile"].copy()
data_chile["dt"] = pd.to_datetime(data_chile["dt"])
#Se crea el dataframe de la temperatura global.
data_global = pd.read_csv("./datos/GlobalTemperatures.csv")
#Se modifica la fecha y hora como datetime.
data_global["dt"] = pd.to_datetime(data_global["dt"])
#Se crea el dataframe del co2.
co2_ppm = pd.read_csv("./datos/archive.csv")
Los dataframes creados.¶
In [3]:
data_pais.head()
Out[3]:
Como se puede observar, se tiene la fecha, la temperatura promedio, la temperatura promedio de incertidumbre y país.
In [4]:
data_pais.info()
Los tipos de datos de las columnas son dt objeto, temperatura promedio y temperatura promedio de incertidumbre son float64 y country como objeto
Venezuela¶
In [5]:
data_vzla.head()
Out[5]:
Se tiene la misma información anterior pero sólo de Venezuela.
In [6]:
data_vzla.describe().T
Out[6]:
Se tiene 2086 datos, los cuales la temperatura promedio es 25.025 grados, y la incertidumbre es de 0.586, la desviación de la temperatura promedio es de 0.703, y de la incertidumbre es de 0.398, la mínima temperatura fue de 22.77, la máxima de 27.807.
In [7]:
data_vzla.corr()
Out[7]:
Las dos variables tienen una correlación contraria en cierta manera.
Argentina¶
In [8]:
data_arg.head()
Out[8]:
In [9]:
data_arg.describe().T
Out[9]:
Brasil¶
In [10]:
data_brasil.head()
Out[10]:
In [11]:
data_brasil.describe().T
Out[11]:
Chile¶
In [12]:
data_chile.head()
Out[12]:
In [13]:
data_chile.describe().T
Out[13]:
Mexico¶
In [14]:
data_mexico.head()
Out[14]:
In [15]:
data_mexico.describe().T
Out[15]:
Canadá¶
In [16]:
data_canada.head()
Out[16]:
In [17]:
data_canada.describe().T
Out[17]:
Se nota que las variaciones de la temperatura promedio de incertidumbre es mayor en Brasil, Venezuela, Mexico y Canadá en ese orden, con respecto a Chile y Argentina.
Incremento anual de la temperatura promedio global¶
In [18]:
annual_mean_global = data_global.groupby(data_global["dt"].dt.year).mean()
reference_temperature_global = annual_mean_global.loc[1951:1980].mean()["LandAndOceanAverageTemperature"]
annual_mean_global["Anomaly"] = annual_mean_global["LandAndOceanAverageTemperature"] - reference_temperature_global
In [19]:
plt.figure()
plt.style.use("fivethirtyeight")
annual_mean_global.loc[1960:2015]["Anomaly"].plot(figsize = (10,5), grid=True, legend=True)
plt.title("Anomalia anual de la temperatura promedio global")
plt.xlabel('')
plt.ylabel('Anomalia de la temperatura')
plt.show()
Se nota que anualmente el incremento de la temperatura tiene una tendencia ascendente que ha aumentado en los últimos años, este incremento en el año 2015 fue de 0.75 grados que es conscistente con el cambio climático.
Venezuela.¶
Se hace el mismo cálculo para el caso de Venezuela.In [20]:
annual_mean_vzla = data_vzla.groupby(data_vzla["dt"].dt.year).mean()
reference_temperature_vzla = annual_mean_vzla.loc[1951:1980].mean()["AverageTemperature"]
annual_mean_vzla["Anomaly"] = annual_mean_vzla["AverageTemperature"] - reference_temperature_vzla
In [21]:
annual_mean_vzla.head()
Out[21]:
In [22]:
annual_mean_vzla.tail()
Out[22]:
El último registro es del año 2013, el cual el incremento fue de 0.595 grados, hubo un pico en el año 2010 de 0.8332 grados.
In [23]:
plt.figure()
plt.style.use("fivethirtyeight")
annual_mean_vzla.loc[1960:2012]["Anomaly"].plot(figsize = (10,5), grid=True, legend=True)
plt.title("Variación promedio anual de la temperatura de Venezuela")
plt.xlabel('')
plt.ylabel('Incremento de la temperatura')
plt.show()
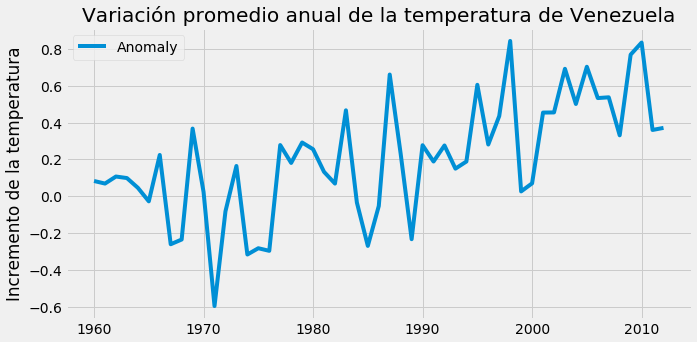
Argentina¶
In [24]:
annual_mean_arg = data_arg.groupby(data_arg["dt"].dt.year).mean()
reference_temperature_arg = annual_mean_arg.loc[1951:1980].mean()["AverageTemperature"]
annual_mean_arg["Anomaly"] = annual_mean_arg["AverageTemperature"] - reference_temperature_arg
In [25]:
annual_mean_arg.head()
Out[25]:
In [26]:
annual_mean_arg.tail()
Out[26]:
In [27]:
plt.figure()
plt.style.use("fivethirtyeight")
annual_mean_arg.loc[1960:2012]["Anomaly"].plot(figsize = (10,5), grid=True, legend=True)
plt.title("Variación promedio anual de la temperatura de Argentina")
plt.xlabel('')
plt.ylabel('Incremento de la temperatura')
plt.show()
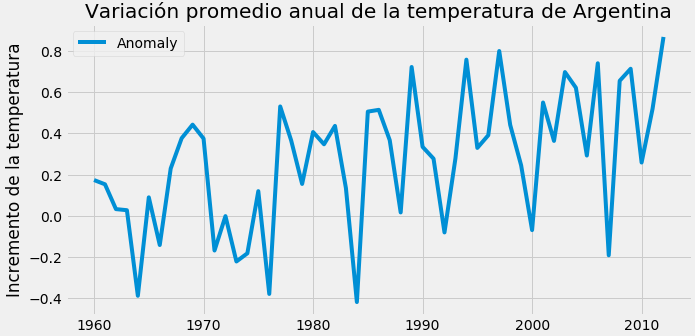
Para el caso de Argentina la pendiente de la tendencia de incremento de la temperatura es menos pronunciada.
Brasil¶
In [28]:
annual_mean_brasil = data_brasil.groupby(data_brasil["dt"].dt.year).mean()
reference_temperature_brasil = annual_mean_brasil.loc[1951:1980].mean()["AverageTemperature"]
annual_mean_brasil["Anomaly"] = annual_mean_brasil["AverageTemperature"] - reference_temperature_brasil
In [29]:
annual_mean_brasil.head()
Out[29]:
In [30]:
annual_mean_brasil.tail()
Out[30]:
In [31]:
plt.figure()
plt.style.use("fivethirtyeight")
annual_mean_brasil.loc[1960:2012]["Anomaly"].plot(figsize = (10,5), grid=True, legend=True)
plt.title("Variación promedio anual de la temperatura de Brasil")
plt.xlabel('')
plt.ylabel('Incremento de la temperatura')
plt.show()
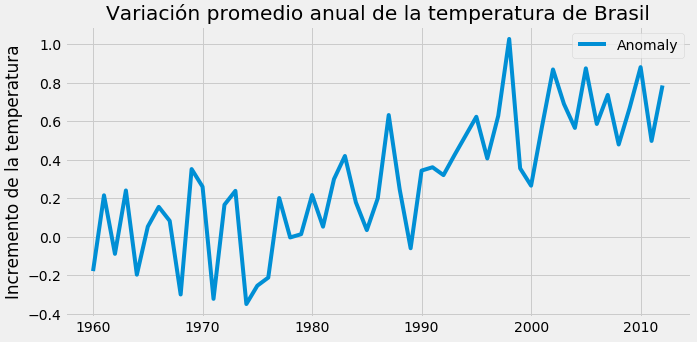
En el caso de Brasil se nota un fuerte incremento en la decada de los 90s con un pico de más de 1 grado, luego la tendencia se ha estabilizado en 0.79 grados.
Chile¶
In [32]:
annual_mean_chile = data_chile.groupby(data_chile["dt"].dt.year).mean()
reference_temperature_chile = annual_mean_chile.loc[1951:1980].mean()["AverageTemperature"]
annual_mean_chile["Anomaly"] = annual_mean_chile["AverageTemperature"] - reference_temperature_chile
In [33]:
annual_mean_chile.head()
Out[33]:
In [34]:
annual_mean_chile.tail()
Out[34]:
In [35]:
plt.figure()
plt.style.use("fivethirtyeight")
annual_mean_chile.loc[1960:2012]["Anomaly"].plot(figsize = (10,5), grid=True, legend=True)
plt.title("Variación promedio anual de la temperatura de Chile")
plt.xlabel('')
plt.ylabel('Incremento de la temperatura')
plt.show()
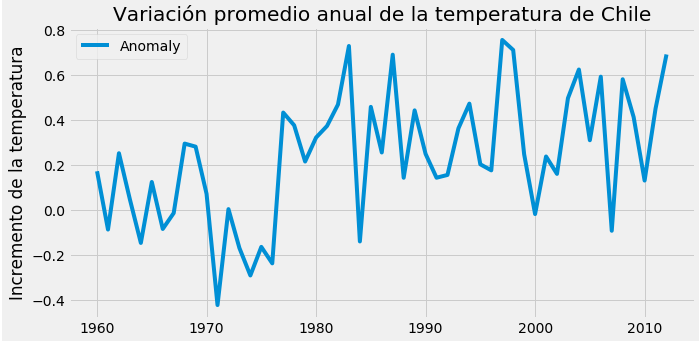
La variación no supera el 0.8 grados de temperatura, con un aumento fuerte entre los 70s y 80s y luego un pico en los 90s.
Mexico¶
In [36]:
annual_mean_mexico = data_mexico.groupby(data_mexico["dt"].dt.year).mean()
reference_temperature_mexico = annual_mean_mexico.loc[1951:1980].mean()["AverageTemperature"]
annual_mean_mexico["Anomaly"] = annual_mean_mexico["AverageTemperature"] - reference_temperature_mexico
In [37]:
annual_mean_mexico.head()
Out[37]:
In [38]:
annual_mean_mexico.tail()
Out[38]:
In [39]:
plt.figure()
plt.style.use("fivethirtyeight")
annual_mean_mexico.loc[1960:2012]["Anomaly"].plot(figsize = (10,5), grid=True, legend=True)
plt.title("Variación promedio anual de la temperatura de Mexico")
plt.xlabel('')
plt.ylabel('Incremento de la temperatura')
plt.show()
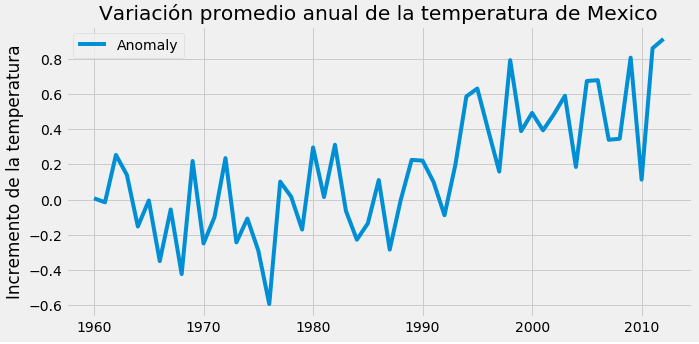
Se nota la tendencia al alsa de la temperatura en Mexico pasando el año 2013 a estar por 1.48 grados por encima del promedio.
Canadá¶
In [40]:
annual_mean_canada = data_canada.groupby(data_canada["dt"].dt.year).mean()
reference_temperature_canada = annual_mean_canada.loc[1951:1980].mean()["AverageTemperature"]
annual_mean_canada["Anomaly"] = annual_mean_canada["AverageTemperature"] - reference_temperature_canada
In [41]:
annual_mean_canada.head()
Out[41]:
In [42]:
annual_mean_canada.tail()
Out[42]:
In [43]:
plt.figure()
plt.style.use("fivethirtyeight")
annual_mean_canada.loc[1960:2012]["Anomaly"].plot(figsize = (10,5), grid=True, legend=True)
plt.title("Variación promedio anual de la temperatura de Canadá")
plt.xlabel('')
plt.ylabel('Incremento de la temperatura')
plt.show()
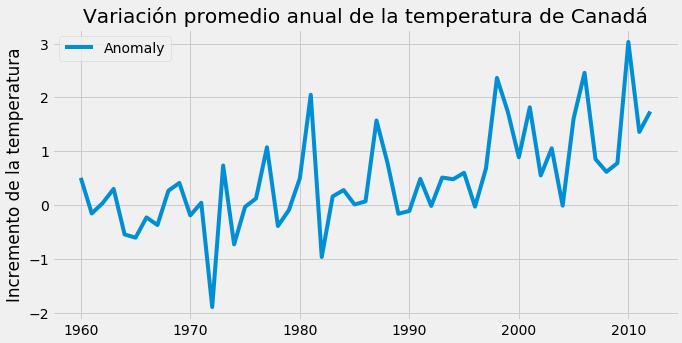
Se nota la tendencia al alsa de la temperatura en Canadá y lo preocupante es que la variación pase los 3 grados de temperatura en el año 2013.
Niveles anuales de CO2 en la Atmosfera¶
In [44]:
plt.figure()
plt.style.use("fivethirtyeight")
annual_co2_ppm = co2_ppm.groupby(co2_ppm["Year"]).mean()
annual_co2_ppm.loc[1960:2015]["Carbon Dioxide (ppm)"].plot(figsize = (10,5), grid=True, legend=True)
plt.title("Nivel anual global de CO2 en la Atmosfera")
plt.ylabel("CO2 partes por millón")
plt.show()
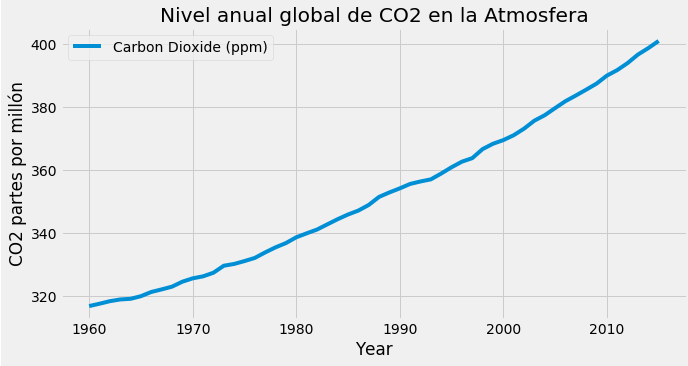
Se nota el incremento anual con tendencia al alza.
Se cálcula la relación del CO2 con la temperatura.¶
In [45]:
annual_co2_temp = pd.merge(annual_mean_global.loc[1960:2015], annual_co2_ppm.loc[1960:2015], left_index=True, right_index=True)
annual_co2_temp = annual_co2_temp[["LandAndOceanAverageTemperature", "Anomaly", "Carbon Dioxide (ppm)"]].copy()
annual_co2_temp.corr()
Out[45]:
In [46]:
sns.heatmap(annual_co2_temp.corr())
Out[46]:
<matplotlib.axes._subplots.AxesSubplot at 0x7fcacea9cdd8>
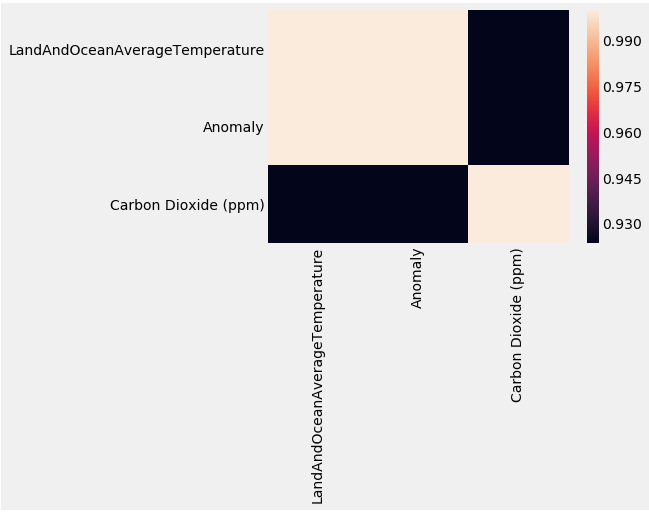
In [47]:
plt.figure(figsize=(10,8))
sns.scatterplot(x="Anomaly",y="Carbon Dioxide (ppm)", data=annual_co2_temp)
Out[47]:
<matplotlib.axes._subplots.AxesSubplot at 0x7fcace8d6c50>

Con la gráfica de calor y la scatter, se nota la relación practicamente lineal del incremento de la temperatura y del Dioxido de Carbono. Ambas están relacionadas en el Cambio climático.
In [ ]:
En el sitio donde se almacenan los datos hay más archivos, temperatura por ciudad por ejemplo para ir más a detalle de la situación por ciudad. También pueden seguir buscando info de otros países, en el artículo original se hizo el de Grecia, y acá probé con Argentina, Brasil, Chile, Canadá, México y Venezuela.

Architecture
MonkeyUser 10 10 2018
![]()
Government websites
WhoTracksMe blog 09 10 2018

En febrero de 2013 creé un artículo sobre cómo hacer gráficos de burbujas con matplotlib, la idea era ver como se generaba una gráfica al estilo de la presentación de Hans Rosling (por cierto, murió en Febrero de 2017).
A continuación el vídeo que explica la historia de 200 países en 200 años, la experanza de vida y calida de vida.
O su charla TED sobre sobre las mejores estadísticas que nunca haz visto:
En el artículo que menciono se uso el conjunto de datos de la rata de criminalidad por estado de Estados Unidos del año 2005. Pero sólo mostraba la información y no la variación en el tiempo.
Este artículo se basa en el siguiente tutorial Python Gapminer Animation.
A continuación se muestra el código del script vía notebook de jupyter:
In [1]:
#Se importa las librerias matplitlib, numpy, pandas, seaborn
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
sns.set_style("white")
import pandas as pd
my_dpi=96
In [2]:
# Se obtiene los datos en formato csv y se convierte en un dataframe
url = 'https://python-graph-gallery.com/wp-content/uploads/gapminderData.csv'
data = pd.read_csv(url)
In [3]:
#Se muestra el data frame
data.head()
Out[3]:
Tiene las columnas países, año, población, contienen, experanza de vida y pib percapita
In [4]:
#Se revisa los tipos de datos de las columnas
data.info()
Se observa que la columna continente es del tipo objeto. Se necesita convertir en un tipo categoria.
In [5]:
# Transformar los datos de la columna continente a categoria.
data['continent']=pd.Categorical(data['continent'])
data.head()
Out[5]:
In [6]:
#Se vuelve a revisar los tipos de las columnas y ahora se tiene que contienen es categoria
data.info()
Ahora se generará las gráficas por año de experanza de vida y PIB por año, cada gráfica se almacena con su nombre y año a fin de que luego con Image Magick se convierta en un gif animado
In [7]:
# Por cada año
for i in data.year.unique():
# inicializa la figura
fig = plt.figure(figsize=(680/my_dpi, 480/my_dpi), dpi=my_dpi)
# se cambia de color con c y alpha, se mapea el color del eje X.
tmp=data[ data.year == i ]
plt.scatter(tmp['lifeExp'], tmp['gdpPercap'] , s=tmp['pop']/200000 , c=tmp['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2)
# Se agrega el título, y los ejes.
plt.yscale('log')
plt.xlabel("Experanza de vida")
plt.ylabel("PIB per capita")
plt.title("Año: "+str(i) )
plt.ylim(0,100000)
plt.xlim(30, 90)
# Se salva el archivo como png, cada archivo por año.
filename='Gapminder_step'+str(i)+'.png'
plt.savefig(filename, dpi=96)
plt.gca()
Se muestra una imagen de las generadas:
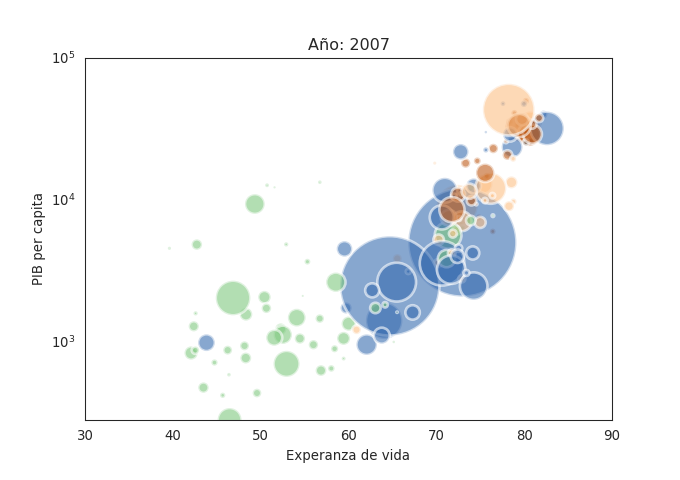
Para convertir las imágenes generadas en gif se ejecuta el siguiente comando de image magick:
convert -delay 80 Gapminder*.png animated_gapminder.gif
El gif resultante se muestra a continuación:
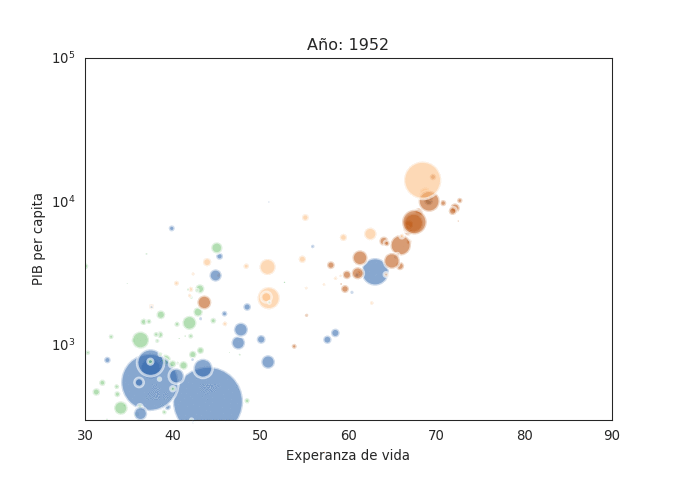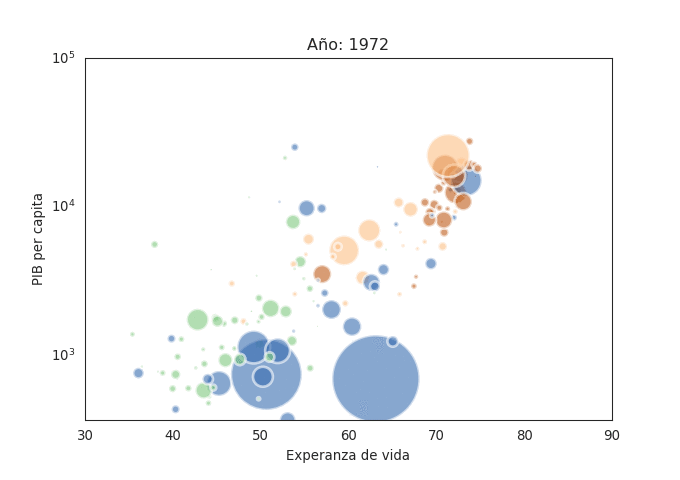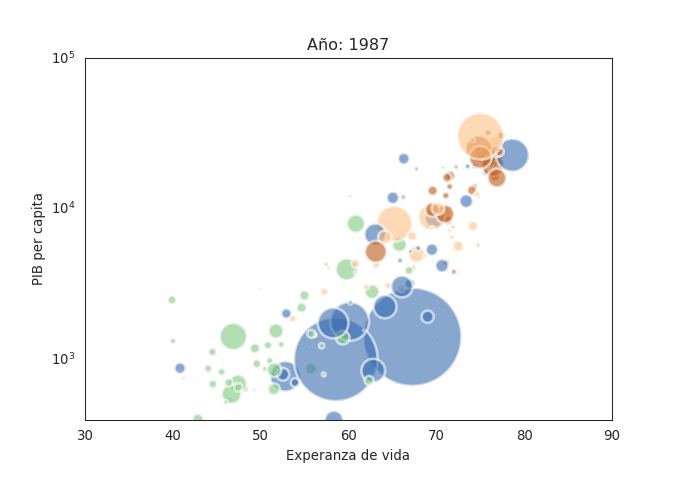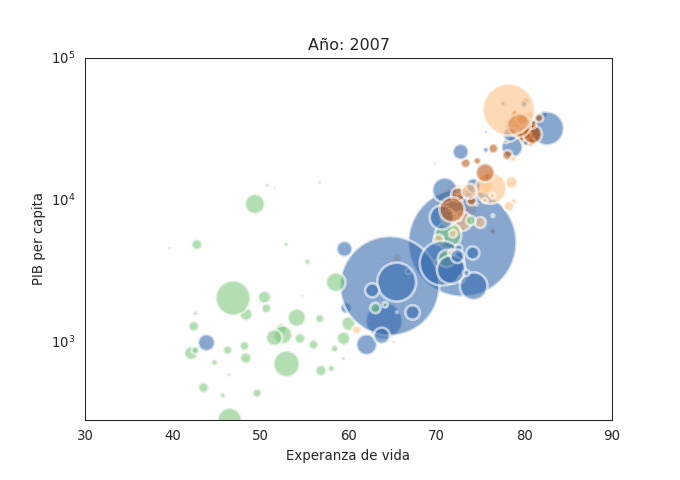
En próximo artículo espero encontrar el conjunto de datos del artículo mencionado al inicio para hacerle una animación como el realizado en este artículo.
These Months in Common Lisp: Q3 2018
Lisp journey 06 10 2018
Documentation
- CLOS – the Common Lisp Cookbook (extensive rewrite)
- Advanced Use of Lisp’s FORMAT Function (2004)
- Book: Luger/Stubblefield, 2009; AI Algorithms, Data Structures, and Idioms in Prolog, Lisp, and Java (PDF)
- GitHub - DalekBaldwin/on-lisp: A modernized and annotated code companion to Paul Graham’s “On Lisp”
- SLY User Manual, version 1.0.0-beta-2
Announcements
- A new version of Common-Lisp.net has been launched!
- A new quickdist distribution – Ultralisp.org
- Autumn Lisp Game Jam
- SBCL 1.4.12 Released
- Next Browser Linux Port Campaign
- awesome-cl.com (the website)
Jobs
Projects
- Introducing Seed: An Interactive Software Environment in Common Lisp
- Live reload prototype for clack
- Mastodon Bot in Common Lisp
- slack-client: Slack Real Time Messaging API Client
- cl-progress-bar: Progress bars, just like in quicklisp!
- Shinmera/oxenfurt: A Common Lisp client library for the Oxford dictionary API
- flight-recorder - a robust REPL logging facility
- Music: Music framework for musical expression in Common Lisp with a focus on music theory (built from scratch, on development)
- Tovero is a 3D modeling system for Common Lisp
- RMSBolt: See what your compiler is going inside of Emacs (has minimal support for Common Lisp)
- ftw: Common Lisp Win32 GUI library
- pngload: A PNG (Portable Network Graphics) image format decoder
- mel-base - forked and actively updated versatile mail library for common lisp
- wordnet: Common Lisp interface to WordNet
- cl-vep: a video effects processor
- CLiCC - The Common Lisp to C Compiler
- LIST-NAMED-CLASS - name your CLOS classes with lists, not just symbols
- GUERRA-ESPACIAL: an implementation of the spacewar computer game in Common Lisp
- Clive is a Common Lisp binding to Open Inventor with extensions
- Lorem ipsum generator in portable Common Lisp
- tlikonen/cl-decimals: Decimal number parser and formatter package
- tlikonen/cl-enchant: Common Lisp bindings for the Enchant spell-checker library
- tlikonen/cl-general-accumulator: General-purpose, extensible value accumulator library
- Drawing UML diagram with Common Lisp
- slurm-cl - a web application framework for Common Lisp and single page applications.
new releases:
- Lem v1.4 has been released with paredit-mode
- Common Lisp OS Mezzano – Demo 4
- Mito ORM: new deftable shortcut to create default initargs, accessors and metaclass
- Quickref open-sourced - Didier Verna’s Sci-Blog
(re)discoveries:
- Shuffletron, a Common Lisp Music Player for the terminal
- quid-pro-quo: a contract programming library in the style of Eiffel’s Design by Contract
- Successful Lisp: How to Understand and Use Common Lisp (Book download from Author’s site)
- Cognitive Robot Abstract Machine = Common Lisp + ROS
- cl-yaclyaml - a YaML processor (loader, not dumper)
- Esrap - a packrat parser for Common Lisp
- gendl - Generative Programming and Knowledge-based Engineering (KBE) system embedded in Common Lisp
- pcostanza/filtered-functions: an extension of CLOS generic function invocation that enables the use of arbitrary predicates for selecting and applying methods.
Articles
- A Road to Common Lisp / Steve Losh
- Excavating a Common Treasure: Common Lisp
- First RISCy Steps – Porting SBCL to the RISC-V
- My pattern to write a web application in Common Lisp (3)
- A new way of blogging about Common Lisp
- Going Serverless: From Common LISP and CGI to AWS Lambda and API Gateway
- Fun with Macros: If-Let and When-Let / Steve Losh
- How to enable reader macros throughout a project with ASDF’s package-inferred-system (E. Fukamachi)
- Extempore - The design, implementation and application of a cyber-physical programming language, Andrew Sorensen, Thesis, 2018 (PDF)
- https://www.ifosslr.org/ojs/ifosslr/article/view/75
- Uniform Structured Syntax, Metaprogramming and Run-time Compilation
- Simple expression evaluator comparison between Haskell, Rust, and Common Lisp
- Lisping at JPL
- A Clon guide
- Common LISP as Simulation Program (CLASP) of Electronic Circuits (2011) (pdf)
- Lisp code for Christopher Riesbeck’s cs325 AI course.
- A Story of (defun games ())
Discussion
Learning Lisp:
- I want to try Lisp, how should I begin?
- What lisp dialect for “real world” applications?
- What do commercial Lisps offer that frees don’t?
- Which (non-Clojure) Lisp to learn first?
- Can CL implement Clojure’s keyword as function syntax?
- Why cons cells?
Screencasts
- Little bits of Lisp - cl-autowrap
- Lots of bits of Lisp - Generating Bindings to C Libraries
- Lots of bits of Lisp - Macros (2 hr episode)
- Pushing Pixels with Lisp - Episode 59 - Basic Disolve Shaders (and more episodes !)
- Common Lisp Study Group - Introduction to Screamer
- Common Lisp Study Group: An Intro to SERIES
- Daniel G Bobrow: Common LISP Object Standard 1987 (video 53min)
Common Lisp VS …
CLOS Tutorial
Lisp journey 05 10 2018
We just updated the CLOS page on the Common Lisp Cookbook. You should refer to it for updates.
CLOS is the “Common Lisp Object System”, arguably one of the most powerful object systems available in any language.
Some of its features include:
- it is dynamic, making it a joy to work with in a Lisp REPL. For example, changing a class definition will update the existing objects, given certain rules which we have control upon.
- it supports multiple dispatch and multiple inheritance,
- it is different from most object systems in that class and method definitions are not tied together,
- it has excellent introspection capabilities,
- it is provided by a meta-object protocol, which provides a standard interface to the CLOS, and can be used to create new object systems.
The functionality belonging to this name was added to the Common Lisp language between the publication of Steele’s first edition of “Common Lisp, the Language” in 1984 and the formalization of the language as an ANSI standard ten years later.
This page aims to give a good understanding of how to use CLOS, but only a brief introduction to the MOP.
To learn the subjects in depth, you will need two books:
- Object-Oriented Programming in Common Lisp: a Programmer’s Guide to CLOS, by Sonya Keene,
- the Art of the Metaobject Protocol, by Gregor Kiczales, Jim des Rivières et al.
But see also
- the introduction in Practical Common Lisp (online), by Peter Seibel.
- Common Lisp, the Language
- and for reference, the complete CLOS-MOP specifications.
Table of Contents
- Classes and instances
- Methods
- MOP
Classes and instances
Diving in
Let’s dive in with an example showing class definition, creation of objects, slot access, methods specialized for a given class, and inheritance.
(defclass person ()
((name
:initarg :name
:accessor name)
(lisper
:initform nil
:accessor lisper)))
;; => #<STANDARD-CLASS PERSON>
(defvar p1 (make-instance 'person :name "me" ))
;; ^^^^ initarg
;; => #<PERSON {1006234593}>
(name p1)
;;^^^ accessor
;; => "me"
(lisper p1)
;; => nil
;; ^^ initform (slot unbound by default)
(setf (lisper p1) t)
(defclass child (person)
())
(defclass child (person)
((can-walk-p
:accessor can-walk-p
:initform t)))
;; #<STANDARD-CLASS CHILD>
(can-walk-p (make-instance 'child))
;; T
Defining classes (defclass)
The macro used for defining new data types in CLOS is defclass.
We used it like this:
(defclass person ()
((name
:initarg :name
:accessor name)
(lisper
:initform nil
:accessor lisper)))
This gives us a CLOS type (or class) called person and two slots,
named name and lisper.
(class-of p1)
#<STANDARD-CLASS PERSON>
(type-of p1)
PERSON
The general form of defclass is:
(defclass <class-name> (list of super classes)
((slot-1
:slot-option slot-argument)
(slot-2, etc))
(:optional-class-option
:another-optional-class-option))
So, our person class doesn’t explicitely inherit from another class
(it gets the empty parentheses ()). However it still inherits by default from
the class t and from standard-object. See below under
“inheritance”.
We could write a minimal class definition without slots options like this:
(defclass point ()
(x y z))
or even without slots specificiers: (defclass point () ()).
Creating objects (make-instance)
We create instances of a class with make-instance:
(defvar p1 (make-instance 'person :name "me" ))
It is generally good practice to define a constructor:
(defun make-person (name &key lisper)
(make-instance 'person :name name :lisper lisper))
This has the direct advantage that you can control the required arguments. You should now export the constructor from your package and not the class itself.
Slots
A function that always works (slot-value)
The function to access any slot anytime is (slot-value <object> <slot-name>).
Given our point class above, which didn’t define any slot accessors:
(defvar pt (make-instance 'point))
(inspect pt)
The object is a STANDARD-OBJECT of type POINT.
0. X: "unbound"
1. Y: "unbound"
2. Z: "unbound"
We got an object of type POINT, but slots are unbound by
default: trying to access them will raise an UNBOUND-SLOT
condition:
(slot-value pt 'x) ;; => condition: the slot is unbound
slot-value is setf-able:
(setf (slot-value pt 'x) 1)
(slot-value pt 'x) ;; => 1
Initial and default values (initarg, initform)
:initarg :foois the keyword we can pass tomake-instanceto give a value to this slot:
(make-instance 'person :name "me")
(again: slots are unbound by default)
:initform <val>is the default value in case we didn’t specify an initarg. This form is evaluated each time it’s needed, in the lexical environment of thedefclass.
Sometimes we see the following trick to clearly require a slot:
(defclass foo ()
((a
:initarg :a
:initform (error "you didn't supply an initial value for slot a"))))
;; #<STANDARD-CLASS FOO>
(make-instance 'foo) ;; => enters the debugger.
Getters and setters (accessor, reader, writer)
:accessor foo: an accessor is both a getter and a setter. Its argument is a name that will become a generic function.
(name p1) ;; => "me"
(type-of #'name)
STANDARD-GENERIC-FUNCTION
:readerand:writerdo what you expect. Only the:writerissetf-able.
If you don’t specify any of these, you can still use slot-value.
You can give a slot more than one :accessor, :reader or :initarg.
We introduce two macros to make the access to slots shorter in some situations:
1- with-slots allows to abbreviate several calls to slot-value. The
first argument is a list of slot names. The second argument evaluates
to a CLOS instance. This is followed by optional declarations and an
implicit progn. Lexically during the evaluation of the body, an
access to any of these names as a variable is equivalent to accessing
the corresponding slot of the instance with slot-value.
(with-slots (name lisper)
c1
(format t "got ~a, ~a~&" name lisper))
or
(with-slots ((n name)
(l lisper))
c1
(format t "got ~a, ~a~&" n l))
2- with-accessors is equivalent, but instead of a list of slots it
takes a list of accessor functions. Any reference to the variable
inside the macro is equivalent to a call to the accessor function.
(with-accessors ((name name)
^^variable ^^accessor
(lisper lisper))
p1
(format t "name: ~a, lisper: ~a" name lisper))
Class VS instance slots
:allocation specifies whether this slot is local or shared.
a slot is local by default, that means it can be different for each instance of the class. In that case
:allocationequals:instance.a shared slot will always be equal for all instances of the class. We set it with
:allocation :class.
In the following example, note how changing the value of the class
slot species of p2 affects all instances of the
class (whether or not those instances exist yet).
(defclass person ()
((name :initarg :name :accessor name)
(species
:initform 'homo-sapiens
:accessor species
:allocation :class)))
;; Note that the slot "lisper" was removed in existing instances.
(inspect p1)
;; The object is a STANDARD-OBJECT of type PERSON.
;; 0. NAME: "me"
;; 1. SPECIES: HOMO-SAPIENS
;; > q
(defvar p2 (make-instance 'person))
(species p1)
(species p2)
;; HOMO-SAPIENS
(setf (species p2) 'homo-numericus)
;; HOMO-NUMERICUS
(species p1)
;; HOMO-NUMERICUS
(species (make-instance 'person))
;; HOMO-NUMERICUS
(let ((temp (make-instance 'person)))
(setf (species temp) 'homo-lisper))
;; HOMO-LISPER
(species (make-instance 'person))
;; HOMO-LISPER
Slot documentation
Each slot accepts one :documentation option.
Slot type
The :type slot option may not do the job you expect it does. If you
are new to the CLOS, we suggest you skip this section and use your own
constructors to manually check slot types.
Indeed, whether slot types are being checked or not is undefined. See the Hyperspec.
Few implementations will do it. Clozure CL does it, SBCL does it when
safety is high ((declaim (optimize safety))).
To do it otherwise, see this Stack-Overflow answer, and see also quid-pro-quo, a contract programming library.
find-class, class-name, class-of
(find-class 'point)
;; #<STANDARD-CLASS POINT 275B78DC>
(class-name (find-class 'point))
;; POINT
(class-of my-point)
;; #<STANDARD-CLASS POINT 275B78DC>
(typep my-point (class-of my-point))
;; T
CLOS classes are also instances of a CLOS class, and we can find out what that class is, as in the example below:
(class-of (class-of my-point))
;; #<STANDARD-CLASS STANDARD-CLASS 20306534>
Note: this is your first introduction to the MOP. You don’t need that to get started !
The object my-point is an instance of the class named point, and the
class named point is itself an instance of the class named
standard-class. We say that the class named standard-class is
the metaclass (i.e. the class of the class) of
my-point. We can make good uses of metaclasses, as we’ll see later.
Subclasses and inheritance
As illustrated above, child is a subclass of person.
All objects inherit from the class standard-object and t.
Every child instance is also an instance of person.
(type-of c1)
;; CHILD
(subtypep (type-of c1) 'person)
;; T
(ql:quickload "closer-mop")
;; ...
(closer-mop:subclassp (class-of c1) 'person)
;; T
The closer-mop library is the portable way to do CLOS/MOP operations.
A subclass inherits all of its parents slots, and it can override any of their slot options. Common Lisp makes this process dynamic, great for REPL session, and we can even control parts of it (like, do something when a given slot is removed/updated/added, etc).
The class precedence list of a child is thus:
child <- person <-- standard-object <- t
Which we can get with:
(closer-mop:class-precedence-list (class-of c1))
;; (#<standard-class child>
;; #<standard-class person>
;; #<standard-class standard-object>
;; #<sb-pcl::slot-class sb-pcl::slot-object>
;; #<sb-pcl:system-class t>)
However, the direct superclass of a child is only:
(closer-mop:class-direct-superclasses (class-of c1))
;; (#<standard-class person>)
We can further inspect our classes with
class-direct-[subclasses, slots, default-initargs] and many more functions.
How slots are combined follows some rules:
:accessorand:readerare combined by the union of accessors and readers from all the inherited slots.:initarg: the union of initialization arguments from all the inherited slots.:initform: we get the most specific default initial value form, i.e. the first:initformfor that slot in the precedence list.:allocationis not inherited. It is controlled solely by the class being defined and defaults to:instance.
Last but not least, be warned that inheritance is fairly easy to
misuse, and multiple inheritance is multiply so, so please take a
little care. Ask yourself whether foo really wants to inherit from
bar, or whether instances of foo want a slot containing a bar. A
good general guide is that if foo and bar are “same sort of thing”
then it’s correct to mix them together by inheritance, but if they’re
really separate concepts then you should use slots to keep them apart.
Multiple inheritance
CLOS supports multiple inheritance.
(defun baby (child person)
())
The first class on the list of parent classes is the most specific
one, child’s slots will take precedence over the person’s
TODO (but remember how slots are merged).
Redefining and changing a class
This section briefly covers two topics:
- redefinition of an existing class, which you might already have done by following our code snippets, and what we do naturally during development, and
- changing an instance of one class into an instance of another, a powerful feature of CLOS that you’ll probably won’t use very often.
We’ll gloss over the details. Suffice it to say that everything’s configurable by implementing methods exposed by the MOP.
To redefine a class, simply evaluate a new defclass form. This then
takes the place of the old definition, the existing class object is
updated, and all instances of the class (and, recursively, its
subclasses) are lazily updated to reflect the new definition. You don’t
have to recompile anything other than the new defclass, nor to
invalidate any of your objects. Think about it for a second: this is awesome !
For example, with our person class:
(defclass person ()
((name
:initarg :name
:accessor name)
(lisper
:initform nil
:accessor lisper)))
(setf p1 (make-instance 'person :name "me" ))
Changing, adding, removing slots,…
(lisper p1)
;; NIL
(defclass person ()
((name
:initarg :name
:accessor name)
(lisper
:initform t ;; <-- from nil to t
:accessor lisper)))
(lisper p1)
;; NIL (of course!)
(lisper (make-instance 'person :name "You"))
;; T
(defclass person ()
((name
:initarg :name
:accessor name)
(lisper
:initform nil
:accessor lisper)
(age
:initarg :arg
:initform 18
:accessor age)))
(age p1)
;; => slot unbound error. This is different from "slot missing":
(slot-value p1 'bwarf)
;; => "the slot bwarf is missing from the object #<person…>"
(setf (age p1) 30)
(age p1) ;; => 30
(defclass person ()
((name
:initarg :name
:accessor name)))
(slot-value p1 'lisper) ;; => slot lisper is missing.
(lisper p1) ;; => there is no applicable method for the generic function lisper when called with arguments #(lisper).
To change the class of an instance, use change-class:
(change-class p1 'child)
;; we can also set slots of the new class:
(change-class p1 'child :can-walk-p nil)
(class-of p1)
;; #<STANDARD-CLASS CHILD>
(can-walk-p p1)
;; T
In the above example, I became a child, and I inherited the can-walk-p slot, which is true by default.
Pretty printing
Everytime we printed an object so far we got an output like
#<PERSON {1006234593}>
which doesn’t say much.
What if we want to show more information ? Something like
#<PERSON me lisper: t>
Pretty printing is done by specializing the generic print-object method for this class:
(defmethod print-object ((obj person) stream)
(print-unreadable-object (obj stream :type t)
(with-accessors ((name name)
(lisper lisper))
obj
(format stream "~a, lisper: ~a" name lisper))))
It gives:
p1
;; #<PERSON me, lisper: T>
print-unreadable-object prints the #<...>, that says to the reader
that this object can not be read back in. Its :type t argument asks
to print the object-type prefix, that is, PERSON. Without it, we get
#<me, lisper: T>.
We used the with-accessors macro, but of course for simple cases this is enough:
(defmethod print-object ((obj person) stream)
(print-unreadable-object (obj stream :type t)
(format stream "~a, lisper: ~a" (name obj) (lisper obj))))
Caution: trying to access a slot that is not bound by default will
lead to an error. Use slot-boundp.
For reference, the following reproduces the default behaviour:
(defmethod print-object ((obj person) stream)
(print-unreadable-object (obj stream :type t :identity t)))
Here, :identity to t prints the {1006234593} address.
Classes of traditional lisp types
Where we approach that we don’t need CLOS objects to use CLOS.
Generously, the functions introduced in the last section also work on lisp objects which are not CLOS instances:
(find-class 'symbol)
;; #<BUILT-IN-CLASS SYMBOL>
(class-name *)
;; SYMBOL
(eq ** (class-of 'symbol))
;; T
(class-of ***)
;; #<STANDARD-CLASS BUILT-IN-CLASS>
We see here that symbols are instances of the system class
symbol. This is one of 75 cases in which the language requires a
class to exist with the same name as the corresponding lisp
type. Many of these cases are concerned with CLOS itself (for
example, the correspondence between the type standard-class and
the CLOS class of that name) or with the condition system (which
might or might not be built using CLOS classes in any given
implementation). However, 33 correspondences remain relating to
“traditional” lisp types:
|array|hash-table|readtable|
|bit-vector|integer|real|
|broadcast-stream|list|sequence|
|character|logical-pathname|stream|
|complex|null|string|
|concatenated-stream|number|string-stream|
|cons|package|symbol|
|echo-stream|pathname|synonym-stream|
|file-stream|random-state|t|
|float|ratio|two-way-stream|
|function|rational|vector|
Note that not all “traditional” lisp types are included in this
list. (Consider: atom, fixnum, short-float, and any type not
denoted by a symbol.)
The presence of t is interesting. Just as every lisp
object is of type t, every lisp object is also a member
of the class named t. This is a simple example of
membership of more then one class at a time, and it brings into
question the issue of inheritance, which we will consider
in some detail later.
(find-class t)
;; #<BUILT-IN-CLASS T 20305AEC>
In addition to classes corresponding to lisp types, there is also a CLOS class for every structure type you define:
(defstruct foo)
FOO
(class-of (make-foo))
;; #<STRUCTURE-CLASS FOO 21DE8714>
The metaclass of a structure-object is the class
structure-class. It is implementation-dependent whether
the metaclass of a “traditional” lisp object is
standard-class, structure-class, or
built-in-class. Restrictions:
|built-in-class| May not use make-instance, may not use slot-value, may not use defclass to modify, may not create subclasses.|
|structure-class| May not use make-instance, might work with slot-value (implementation-dependent). Use defstruct to subclass application structure types. Consequences of modifying an existing structure-class are undefined: full recompilation may be necessary.|
|standard-class|None of these restrictions.|
Introspection
we already saw some introspection functions.
Your best option is to discover the closer-mop libray and to keep the CLOS & MOP specifications at hand.
More functions:
closer-mop:class-default-initargs
closer-mop:class-direct-default-initargs
closer-mop:class-direct-slots
closer-mop:class-direct-subclasses
closer-mop:class-direct-superclasses
closer-mop:class-precedence-list
closer-mop:class-slots
closer-mop:classp
closer-mop:extract-lambda-list
closer-mop:extract-specializer-names
closer-mop:generic-function-argument-precedence-order
closer-mop:generic-function-declarations
closer-mop:generic-function-lambda-list
closer-mop:generic-function-method-class
closer-mop:generic-function-method-combination
closer-mop:generic-function-methods
closer-mop:generic-function-name
closer-mop:method-combination
closer-mop:method-function
closer-mop:method-generic-function
closer-mop:method-lambda-list
closer-mop:method-specializers
closer-mop:slot-definition
closer-mop:slot-definition-allocation
closer-mop:slot-definition-initargs
closer-mop:slot-definition-initform
closer-mop:slot-definition-initfunction
closer-mop:slot-definition-location
closer-mop:slot-definition-name
closer-mop:slot-definition-readers
closer-mop:slot-definition-type
closer-mop:slot-definition-writers
closer-mop:specializer-direct-generic-functions
closer-mop:specializer-direct-methods
closer-mop:standard-accessor-method
See also
defclass/std: write shorter classes
The library defclass/std
provides a macro to write shorter defclass forms.
By default, it adds an accessor, an initarg and an initform to nil to your slots definition:
This:
(defclass/std example ()
((slot1 slot2 slot3)))
expands to:
(defclass example ()
((slot1
:accessor slot1
:initarg :slot1
:initform nil)
(slot2
:accessor slot2
:initarg :slot2
:initform nil)
(slot3
:accessor slot3
:initarg :slot3
:initform nil)))
It does much more and it is very flexible, however it is seldom used by the Common Lisp community: use at your own risks©.
Methods
Diving in
Recalling our person and child classes from the beginning:
(defclass person ()
((name
:initarg :name
:accessor name)))
;; => #<STANDARD-CLASS PERSON>
(defclass child (person)
())
;; #<STANDARD-CLASS CHILD>
(setf p1 (make-instance 'person :name "me"))
(setf c1 (make-instance 'child :name "Alice"))
Below we create methods, we specialize them, we use method combination (before, after, around), and qualifiers.
(defmethod greet (obj)
(format t "Are you a person ? You are a ~a.~&" (type-of obj)))
;; style-warning: Implicitly creating new generic function common-lisp-user::greet.
;; #<STANDARD-METHOD GREET (t) {1008EE4603}>
(greet :anything)
;; Are you a person ? You are a KEYWORD.
;; NIL
(greet p1)
;; Are you a person ? You are a PERSON.
(defgeneric greet (obj)
(:documentation "say hello"))
;; STYLE-WARNING: redefining COMMON-LISP-USER::GREET in DEFGENERIC
;; #<STANDARD-GENERIC-FUNCTION GREET (2)>
(defmethod greet ((obj person))
(format t "Hello ~a !~&" (name obj)))
;; #<STANDARD-METHOD GREET (PERSON) {1007C26743}>
(greet p1) ;; => "Hello me !"
(greet c1) ;; => "Hello Alice !"
(defmethod greet ((obj child))
(format t "ur so cute~&"))
;; #<STANDARD-METHOD GREET (CHILD) {1008F3C1C3}>
(greet p1) ;; => "Hello me !"
(greet c1) ;; => "ur so cute"
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;;; Method combination: before, after, around.
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defmethod greet :before ((obj person))
(format t "-- before person~&"))
#<STANDARD-METHOD GREET :BEFORE (PERSON) {100C94A013}>
(greet p1)
;; -- before person
;; Hello me
(defmethod greet :before ((obj child))
(format t "-- before child~&"))
;; #<STANDARD-METHOD GREET :BEFORE (CHILD) {100AD32A43}>
(greet c1)
;; -- before child
;; -- before person
;; ur so cute
(defmethod greet :after ((obj person))
(format t "-- after person~&"))
;; #<STANDARD-METHOD GREET :AFTER (PERSON) {100CA2E1A3}>
(greet p1)
;; -- before person
;; Hello me
;; -- after person
(defmethod greet :after ((obj child))
(format t "-- after child~&"))
;; #<STANDARD-METHOD GREET :AFTER (CHILD) {10075B71F3}>
(greet c1)
;; -- before child
;; -- before person
;; ur so cute
;; -- after person
;; -- after child
(defmethod greet :around ((obj child))
(format t "Hello my dear~&"))
;; #<STANDARD-METHOD GREET :AROUND (CHILD) {10076658E3}>
(greet c1) ;; Hello my dear
;; call-next-method
(defmethod greet :around ((obj child))
(format t "Hello my dear~&")
(when (next-method-p)
(call-next-method)))
;; #<standard-method greet :around (child) {100AF76863}>
(greet c1)
;; Hello my dear
;; -- before child
;; -- before person
;; ur so cute
;; -- after person
;; -- after child
;;;;;;;;;;;;;;;;;
;; Adding in &key
;;;;;;;;;;;;;;;;;
;; In order to add "&key" to our generic method, we need to remove its definition first.
(fmakunbound 'greet) ;; with Slime: C-c C-u (slime-undefine-function)
(defmethod greet ((obj person) &key talkative)
(format t "Hello ~a~&" (name obj))
(when talkative
(format t "blah")))
(defgeneric greet (obj &key &allow-other-keys)
(:documentation "say hi"))
(defmethod greet (obj &key &allow-other-keys)
(format t "Are you a person ? You are a ~a.~&" (type-of obj)))
(defmethod greet ((obj person) &key talkative &allow-other-keys)
(format t "Hello ~a !~&" (name obj))
(when talkative
(format t "blah")))
(greet p1 :talkative t) ;; ok
(greet p1 :foo t) ;; still ok
;;;;;;;;;;;;;;;;;;;;;;;
(defgeneric greet (obj)
(:documentation "say hello")
(:method (obj)
(format t "Are you a person ? You are a ~a~&." (type-of obj)))
(:method ((obj person))
(format t "Hello ~a !~&" (name obj)))
(:method ((obj child))
(format t "ur so cute~&")))
;;;;;;;;;;;;;;;;
;;; Specializers
;;;;;;;;;;;;;;;;
(defgeneric feed (obj meal-type)
(:method (obj meal-type)
(declare (ignorable meal-type))
(format t "eating~&")))
(defmethod feed (obj (meal-type (eql :dessert)))
(declare (ignorable meal-type))
(format t "mmh, dessert !~&"))
(feed c1 :dessert)
;; mmh, dessert !
(defmethod feed ((obj child) (meal-type (eql :soup)))
(declare (ignorable meal-type))
(format t "bwark~&"))
(feed p1 :soup)
;; eating
(feed c1 :soup)
;; bwark
Generic functions (defgeneric, defmethod)
A generic function is a lisp function which is associated
with a set of methods and dispatches them when it’s invoked. All
the methods with the same function name belong to the same generic
function.
The defmethod form is similar to a defun. It associates a body of
code with a function name, but that body may only be executed if the
types of the arguments match the pattern declared by the lambda list.
They can have optional, keyword and &rest arguments.
The defgeneric form defines the generic function. If we write a
defmethod without a corresponding defgeneric, a generic function
is automatically created (see examples).
It is generally a good idea to write the defgenerics. We can add a
default implementation and even some documentation.
(defgeneric greet (obj)
(:documentation "says hi")
(:method (obj)
(format t "Hi")))
The required parameters in the method’s lambda list may take one of the following three forms:
1- a simple variable:
(defmethod greet (foo)
...)
This method can take any argument, it is always applicable.
The variable foo is bound to the corresponding argument value, as
usual.
2- a variable and a specializer, as in:
(defmethod greet ((foo person))
...)
In this case, the variable foo is bound to the corresponding
argument only if that argument is of specializer class person or a subclass,
like child (indeed, a “child” is also a “person”).
If any argument fails to match its specializer then the method is not applicable and it cannot be executed with those arguments.We’ll get an error message like “there is no applicable method for the generic function xxx when called with arguments yyy”.
Only required parameters can be specialized. We can’t specialize on optional &key arguments.
3- a variable and an eql specializer
(defmethod feed ((obj child) (meal-type (eql :soup)))
(declare (ignorable meal-type))
(format t "bwark~&"))
(feed c1 :soup)
;; "bwark"
In place of a simple symbol (:soup), the eql specializer can be any
lisp form. It is evaluated at the same time of the defmethod.
You can define any number of methods with the same function name but
with different specializers, as long as the form of the lambda list is
congruent with the shape of the generic function. The system chooses
the most specific applicable method and executes its body. The most
specific method is the one whose specializers are nearest to the head
of the class-precedence-list of the argument (classes on the left of
the lambda list are more specific). A method with specializers is more
specific to one without any.
Notes:
It is an error to define a method with the same function name as an ordinary function. If you really want to do that, use the shadowing mechanism.
To add or remove
keysorrestarguments to an existing generic method’s lambda list, you will need to delete its declaration withfmakunbound(orC-c C-u(slime-undefine-function) with the cursor on the function in Slime) and start again. Otherwise, you’ll see:
attempt to add the method
#<STANDARD-METHOD NIL (#<STANDARD-CLASS CHILD>) {1009504233}>
to the generic function
#<STANDARD-GENERIC-FUNCTION GREET (2)>;
but the method and generic function differ in whether they accept
&REST or &KEY arguments.
Methods can be redefined (exactly as for ordinary functions).
The order in which methods are defined is irrelevant, although any classes on which they specialize must already exist.
An unspecialized argument is more or less equivalent to being specialized on the class
t. The only difference is that all specialized arguments are implicitly taken to be “referred to” (in the sense ofdeclare ignore.)Each
defmethodform generates (and returns) a CLOS instance, of classstandard-method.An
eqlspecializer won’t work as is with strings. Indeed, strings needequalorequalpto be compared. But, we can assign our string to a variable and use the variable both in theeqlspecializer and for the function call.All the methods with the same function name belong to the same generic function.
All slot accessors and readers defined by
defclassare methods. They can override or be overridden by other methods on the same generic function.
See more about defmethod on the CLHS.
Multimethods
Multimethods explicitly specialize more than one of the generic function’s required parameters.
They don’t belong to a particular class. Meaning, we don’t have to decide on the class that would be best to host this method, as we might have to in other languages.
(defgeneric hug (a b)
(:documentation "Hug between two persons."))
;; #<STANDARD-GENERIC-FUNCTION HUG (0)>
(defmethod hug ((a person) (b person))
:person-person-hug)
(defmethod hug ((a person) (b child))
:person-child-hug)
Read more on Practical Common Lisp.
Controlling setters (setf-ing methods)
In Lisp, we can define setf counterparts of functions or methods. We
might want this to have more control on how to update an object.
(defmethod (setf name) (new-val (obj person))
(if (equalp new-val "james bond")
(format t "Dude that's not possible.~&")
(setf (slot-value obj 'name) new-val)))
(setf (name p1) "james bond") ;; -> no rename
If you know Python, this behaviour is provided by the @property decorator.
Dispatch mechanism and next methods
When a generic function is invoked, the application cannot directly invoke a method. The dispatch mechanism proceeds as follows:
- compute the list of applicable methods
- if no method is applicable then signal an error
- sort the applicable methods in order of specificity
- invoke the most specific method.
Our greet generic function has three applicable methods:
(closer-mop:generic-function-methods #'greet)
(#<STANDARD-METHOD GREET (CHILD) {10098406A3}>
#<STANDARD-METHOD GREET (PERSON) {1009008EC3}>
#<STANDARD-METHOD GREET (T) {1008E6EBB3}>)
During the execution of a method, the remaining applicable methods
are still accessible, via the local function
call-next-method. This function has lexical scope within
the body of a method but indefinite extent. It invokes the next most
specific method, and returns whatever value that method returned. It
can be called with either:
no arguments, in which case the next method will receive exactly the same arguments as this method did, or
explicit arguments, in which case it is required that the sorted set of methods applicable to the new arguments must be the same as that computed when the generic function was first called.
For example:
(defmethod greet ((obj child))
(format t "ur so cute~&")
(when (next-method-p)
(call-next-method)))
;; STYLE-WARNING: REDEFINING GREET (#<STANDARD-CLASS CHILD>) in DEFMETHOD
;; #<STANDARD-METHOD GREET (child) {1003D3DB43}>
(greet c1)
;; ur so cute
;; Hello Alice !
Calling call-next-method when there is no next method
signals an error. You can find out whether a next method exists by
calling the local function next-method-p (which also has
has lexical scope and indefinite extent).
Note finally that the body of every method establishes a block with the same name as the method’s generic function. If you return-from that name you are exiting the current method, not the call to the enclosing generic function.
Method qualifiers (before, after, around)
In our “Diving in” examples, we saw some use of the :before, :after and :around qualifiers:
(defmethod foo :before (obj) (...))(defmethod foo :after (obj) (...))(defmethod foo :around (obj) (...))
By default, in the standard method combination framework provided by CLOS, we can only use one of those three qualifiers, and the flow of control is as follows:
- a before-method is called, well, before the applicable primary method. If they are many before-methods, all are called. The most specific before-method is called first (child before person).
- the most specific applicable primary method (a method without qualifiers) is called (only one).
- all applicable after-methods are called. The most specific one is called last (after-method of person, then after-method of child).
The generic function returns the value of the primary method. Any values of the before or after methods are ignored. They are used for their side effects.
And then we have around-methods. They are wrappers around the core mechanism we just described. They can be useful to catch return values or to set up an environment around the primary method (set up a catch, a lock, timing an execution,…).
If the dispatch mechanism finds an around-method, it calls it and
returns its result. If the around-method has a call-next-method, it
calls the next most applicable around-method. It is only when we reach
the primary method that we start calling the before and after-methods.
Thus, the full dispatch mechanism for generic functions is as follows:
- compute the applicable methods, and partition them into separate lists according to their qualifier;
- if there is no applicable primary method then signal an error;
- sort each of the lists into order of specificity;
- execute the most specific
:aroundmethod and return whatever that returns; - if an
:aroundmethod invokescall-next-method, execute the next most specific:aroundmethod; if there were no
:aroundmethods in the first place, or if an:aroundmethod invokescall-next-methodbut there are no further:aroundmethods to call, then proceed as follows:a. run all the
:beforemethods, in order, ignoring any return values and not permitting calls tocall-next-methodornext-method-p;b. execute the most specific primary method and return whatever that returns;
c. if a primary method invokes
call-next-method, execute the next most specific primary method;d. if a primary method invokes
call-next-methodbut there are no further primary methods to call then signal an error;e. after the primary method(s) have completed, run all the
:aftermethods, in reverse order, ignoring any return values and not permitting calls tocall-next-methodornext-method-p.
Think of it as an onion, with all the :around
methods in the outermost layer, :before and
:after methods in the middle layer, and primary methods
on the inside.
Other method combinations
The default method combination type we just saw is named standard,
but other method combination types are available, and no need to say
that you can define your own.
The built-in types are:
progn + list nconc and max or append min
You notice that these types are named after a lisp operator. Indeed,
what they do is they define a framework that combines the applicable
primary methods inside a call to the lisp operator of that name. For
example, using the progn combination type is equivalent to calling all
the primary methods one after the other:
(progn
(method-1 args)
(method-2 args)
(method-3 args))
Here, unlike the standard mechanism, all the primary methods applicable for a given object are called, the most specific first.
To change the combination type, we set the :method-combination
option of defgeneric and we use it as the methods’ qualifier:
(defgeneric foo (obj)
(:method-combination progn))
(defmethod foo progn ((obj obj))
(...))
An example with progn:
(defgeneric dishes (obj)
(:method-combination progn)
(:method progn (obj)
(format t "- clean and dry.~&"))
(:method progn ((obj person))
(format t "- bring a person's dishes~&"))
(:method progn ((obj child))
(format t "- bring the baby dishes~&")))
;; #<STANDARD-GENERIC-FUNCTION DISHES (3)>
(dishes c1)
;; - bring the baby dishes
;; - bring a person's dishes
;; - clean and dry.
(greet c1)
;; ur so cute --> only the most applicable method was called.
Similarly, using the list type is equivalent to returning the list
of the values of the methods.
(list
(method-1 args)
(method-2 args)
(method-3 args))
(defgeneric tidy (obj)
(:method-combination list)
(:method list (obj)
:foo)
(:method list ((obj person))
:books)
(:method list ((obj child))
:toys))
;; #<STANDARD-GENERIC-FUNCTION TIDY (3)>
(tidy c1)
;; (:toys :books :foo)
Around methods are accepted:
(defmethod tidy :around (obj)
(let ((res (call-next-method)))
(format t "I'm going to clean up ~a~&" res)
(when (> (length res)
1)
(format t "that's too much !~&"))))
(tidy c1)
;; I'm going to clean up (toys book foo)
;; that's too much !
Note that these operators don’t support before, after and around
methods (indeed, there is no room for them anymore). They do support
around methods, where call-next-method is allowed, but they don’t
support calling call-next-method in the primary methods (it would
indeed be redundant since all primary methods are called, or clunky to
not call one).
CLOS allows us to define a new operator as a method combination type, be it a lisp function, macro or special form. We’ll let you refer to the books if you feel the need.
Debugging: tracing method combination
It is possible to trace the method combination, but this is implementation dependent.
In SBCL, we can use (trace foo :methods t). See this post by an SBCL core developer.
For example, given a generic:
(defgeneric foo (x)
(:method (x) 3))
(defmethod foo :around ((x fixnum))
(1+ (call-next-method)))
(defmethod foo ((x integer))
(* 2 (call-next-method)))
(defmethod foo ((x float))
(* 3 (call-next-method)))
(defmethod foo :before ((x single-float))
'single)
(defmethod foo :after ((x double-float))
'double)
Let’s trace it:
(trace foo :methods t)
(foo 2.0d0)
0: (FOO 2.0d0)
1: ((SB-PCL::COMBINED-METHOD FOO) 2.0d0)
2: ((METHOD FOO (FLOAT)) 2.0d0)
3: ((METHOD FOO (T)) 2.0d0)
3: (METHOD FOO (T)) returned 3
2: (METHOD FOO (FLOAT)) returned 9
2: ((METHOD FOO :AFTER (DOUBLE-FLOAT)) 2.0d0)
2: (METHOD FOO :AFTER (DOUBLE-FLOAT)) returned DOUBLE
1: (SB-PCL::COMBINED-METHOD FOO) returned 9
0: FOO returned 9
9
MOP
We gather here some examples that make use of the framework provided by the meta-object protocol, the configurable object system that rules Lisp’s object system. We touch advanced concepts so, new reader, don’t worry: you don’t need to understand this section to start using the Common Lisp Object System.
We won’t explain much about the MOP here, but hopefully sufficiently to make you see its possibilities or to help you understand how some CL libraries are built. We invite you to read the books referenced in the introduction.
Metaclasses
Metaclasses are needed to control the behaviour of other classes.
As announced, we won’t talk much. See also Wikipedia for metaclasses or CLOS.
The standard metaclass is standard-class:
(class-of p1) ;; #<STANDARD-CLASS PERSON>
But we’ll change it to one of our own, so that we’ll be able to count the creation of instances. This same mechanism could be used to auto increment the primary key of a database system (this is how the Postmodern or Mito libraries do), to log the creation of objects, etc.
Our metaclass inherits from standard-class:
(defclass counted-class (standard-class)
((counter :initform 0)))
#<STANDARD-CLASS COUNTED-CLASS>
(unintern 'person)
;; this is necessary to change the metaclass of person.
;; or (setf (find-class 'person) nil)
;; https://stackoverflow.com/questions/38811931/how-to-change-classs-metaclass#38812140
(defclass person ()
((name
:initarg :name
:accessor name)
(:metaclass counted-class))) ;; <- metaclass
;; #<COUNTED-CLASS PERSON>
;; ^^^ not standard-class anymore.
The :metaclass class option can appear only once.
Actually you should have gotten a message asking to implement
validate-superclass. So, still with the closer-mop library:
(defmethod closer-mop:validate-superclass ((class counted-class)
(superclass standard-class))
t)
Now we can control the creation of new person instances:
(defmethod make-instance :after ((class counted-class) &key)
(incf (slot-value class 'counter)))
;; #<STANDARD-METHOD MAKE-INSTANCE :AFTER (COUNTED-CLASS) {1007718473}>
See that an :after qualifier is the safest choice, we let the
standard method run as usual and return a new instance.
The &key is necessary, remember that make-instance is given initargs.
Now testing:
(defvar p3 (make-instance 'person :name "adam"))
#<PERSON {1007A8F5B3}>
(slot-value p3 'counter)
;; => error. No, our new slot isn't on the person class.
(slot-value (find-class 'person) 'counter)
;; 1
(make-instance 'person :name "eve")
;; #<PERSON {1007AD5773}>
(slot-value (find-class 'person) 'counter)
;; 2
It’s working.
Controlling the initialization of instances (initialize-instance)
To further customize the creation of instances by specializing
initialize-instance, which is called by make-instance, just after
it has created a new instance but didn’t initialize it yet with the
default initargs and initforms.
It is recommended (Keene) to create an after method, since creating a primary method would prevent slots’ initialization.
(defmethod initialize-instance :after ((obj person) &key)
(do something with obj))
Another rational. The CLOS implementation of
make-instance is in two stages: allocate the new object,
and then pass it along with all the make-instance keyword
arguments, to the generic function
initialize-instance. Implementors and application writers
define :after methods on
initialize-instance, to initialize the slots of the
instance. The system-supplied primary method does this with regard to
(a) :initform and :initarg values supplied
with the class was defined and (b) the keywords passed through from
make-instance. Other methods can extend this behaviour as
they see fit. For example, they might accept an additional keyword
which invokes a database access to fill certain slots. The lambda list
for initialize-instance is:
initialize-instance instance &rest initargs &key &allow-other-keys
See more in the books !

Applied TDD
MonkeyUser 02 10 2018

Tech Debt
MonkeyUser 25 09 2018
Setting Up Hugo on Netlify
(ノ°Д°)ノ︵ ┻━┻ 24 09 2018
Setting Up Hugo on Netlify
(ノ°Д°)ノ︵ ┻━┻ 24 09 2018
Hugo is a static site generator that just like another alternatives(Nicola, Jekyll, etc) allows to write in plain text and generate html, js, css files.
Hugo is so much simpler to use because it's a simple binary file, called hugo, that allows to develop and prepare the site to be published. Some of its features are:
-
Generate a new site
-
Run a development server
-
Generate static files
-
Generate new pages for the site
So let's start to build a site from scratch and publish it automatically using Netlify
Creating the new site
First we'll need to install hugo. You need to install the single binary using the package manager you prefer. In mac OS you can install it using Homebrew with the following command:
brew install hugo
You can check the version with hugo version, at the time I'm writing this post the latest version available is 0.48.
Now we need to generate an new empty site so we'll use the command hugo new site myblog. Once the command finished you'll have a new folder called myblog
The structure of the new folder should be:
├── archetypes
│ └── default.md
├── config.toml
├── content
├── data
├── layouts
├── static
└── themes
For now we have to pay attention to only one file config.toml this file contains the configuration of the new site. We can define stuff like the title of the blog, menus structure, theme parameters, etc.
The contents of config.toml should be like this:
baseURL = "http://example.org/"
languageCode = "en-us"
title = "My New Hugo Site"
We have to change baseURL to / to avoid error with broken links(we'll see these possible errors later). So the result config.toml will be:
baseURL = "/"
languageCode = "en-us"
title = "My New Hugo Site"Adding a theme
Now we have to install a theme. There are many awesome themes available for Hugo. You can check and pick one in Hugo themes.
For this example we'll use Beautiful Hugo
We have 2 options to include the theme in the new site:
-
Clone the theme repository and add it to our folder. This will copy all the files inside our folder.
-
Use git sub modules to create a reference to the theme repository. This way we don't need to copy all the files.
We'll use the second option this time.
First we need to initialize a git repository inside our myblog folder using the following command git init. Now we have a git repository created.
Now we have to run the following commands to add the theme:
cd themes
git submodule add https://github.com/halogenica/beautifulhugo.git
cd ..
This will clone the theme repository and add it to our repository as a submodule. We can see that now we have a beautifulhugo folder inside themes folder and also there is a new file in the root of myblog called .gitmodules with the following content:
[submodule "themes/beautifulhugo"]
path = themes/beautifulhugo
url = https://github.com/halogenica/beautifulhugo.git
Now we have to tell hugo we want to use this theme in the new site, we'll do this adding the following lines to the config.toml file:
theme = "beautifulhugo"Running the development server
To see the new site running before publish it we'll use the embedded development server. We run it with hugo server -D -p 9000.
After that we'll an output similar to this:
| EN
+------------------+----+
Pages | 7
Paginator pages | 0
Non-page files | 0
Static files | 33
Processed images | 0
Aliases | 1
Sitemaps | 1
Cleaned | 0
Total in 46 ms
Watching for changes in /Users/erick/Code/hugo/myblog/{content,data,layouts,static,themes}
Watching for config changes in /Users/erick/Code/hugo/myblog/config.toml
Serving pages from memory
Running in Fast Render Mode. For full rebuilds on change: hugo server --disableFastRender
Web Server is available at http://localhost:9000/ (bind address 127.0.0.1)
Press Ctrl+C to stopNow we can open the browser and enter http://localhost:9000 and we'll see the new site with the chosen theme.
The server is watching for changes to be compiled so we leave it running.
Writing content
At this point we don't have any content to show up so let's create some.
Hugo by default can render Markdown and Org-mode files. For this example we'll create a new post using markdown format.
Run hugo new post/hello-world.md to create a new file called hello-world.md in content/post/, Hugo will create a new file with the following content:
---
title: "Hello World"
date: 2018-09-22T15:05:47-05:00
draft: true
---These lines are used by Hugo to show details about the content in the result file.
Let's add the lines below to hello-world.md
# This is a heading with level 1
## This is a heading with level 2
This is a paragraph
This is some python code
This is a list:
- item 1
- item 2
Now if we go to the browser we'll see the home page with a summary of the content of hello-world.md
By default Hugo show a list of the posts created in content/post in the homepage. Now we can enter to the post to see the full content.
Once we finished with the post it's necessary remove draft: true from hello-world.md file otherwise the file won't show up when we publish the site.
Publishing the site
Uploading the site to a remote repository
We can use Github, Gitlab or Bitbucket to do this. These are the services supported by Netlify. For this example I've uploaded the repository to Github and it's available in https://github.com/erickgnavar/hugo-demo-site.
Creating an account in Netlify
Now we have to create an account in Netlify, there is a free plan that we can use to host the new site.
Deploying site
Once we have the Netlify account and the site uploaded in a external repository we can proceed with the deploy.
Now we can log in and start the process clicking in "New site from Git".
Then there are 3 steps to follow:
Connect to git provider
We have to log in using the service where we uploaded the site.

Pick a repository
Now we have access an a list of our repositories. We can search for the one where the site is in.

Build options
Once we chosen the repository we can specify the build options. Netlify recognize that the site is made with Hugo so these options are already configured.
To proceed we click in "Deploy site".

Deploy result
Netlify will pull the repository and compile the site with the given build options and then it will generate a url to access the deployed site.

Now we can go to the url that Netlify generated for the site and we'll see the resulting site.
Useful Netlify configuration
By default Netlify only will build the site when we push changes to master. We can change this going to "Deploy settings" and changing "Branch deploys" options to "All" like the following image:

With this configuration we can push changes to a different branch than master and Netlify will generate a new url to see the changes. This is useful to test changes before publish them to production site.
It's also possible configure different kind of notifications(Slack, email, etc) to receive the result of the deploy.
About me
(ノ°Д°)ノ︵ ┻━┻ 22 09 2018

Compromise
MonkeyUser 18 09 2018
Be Careful With CTE in PostgreSQL
Haki Benita 16 09 2018
Common table expressions, also known as the WITH clause, are a very useful feature. They help break down big queries into smaller pieces which makes it easier to read and understand. But, when used incorrectly they can cause a significant performance hit.

Shuffletron is a nice music player for the terminal written in Common Lisp, “based on search and tagging”, that seduced me with its attention to details. Moreover, its author was very responsive to fix a couple issues.
The first time you launch it, it will ask for a music repository and
will propose to scan it for id3 tags with the scanid3 command. It
is optional, but it allows to print colored information:
The basic commands to know are the following:
search with
/followed by your search terms. You’ll notice that your prompt changed fromlibrarytoxy matches. You can refine the results by searching again. To enter a new query we have to go back to the library, with as many successive “enters” as needed.to play songs:
play. We can select which songs to play, using their index:- comma-separated indexes of songs:
1,3,10 - a selection with a dash and an optional end:
1-10,0- - a combination of the two:
1,3-10.
- comma-separated indexes of songs:
there are the obvious
pause,shuffle,skip,next,seek,repeat,…nowto show the currently playing song.
There is also a queue, id3 tags management, profiles to
use an alternate library (./shuffletron --help), and even an alarm
clock feature which allows to program music with something like:
alarm at 7:45 am # \"at\" is optional and doesn't change the meaning
alarm 7:45 am
alarm 9 pm
alarm 7 # If AM/PM not specified, assumes AM
alarm in 5 minutes # Relative alarm times, in minutes or hours
alarm in 10m # minutes, minute, mins, min, , m are synonyms
alarm in 7 hours # hours, hour, hr, h are synonyms
alarm in 8h
alarm in 7:29 # h:mm format - seven hours, twenty-nine minutes
alarm reset # off/never/delete/disable/cancel/clear/reset
I can see a use for a pomodoro-like technic :)
I’ll list the complete set of commands below (available on the sources), but first a note on installation.
Installation
Shuffletron doesn’t provide executables (yet ?). The procedure is now documented in the readme so you just have to
make shuffletron-bin # sbcl
sudo make install
./shuffletron
This last line calls a script and it is actually important to use it,
to link dependencies and to use rlwrap. There is room for
improvement here.
To read Flac and Ogg files, you need those system dependencies:
apt install libflac-dev
apt install libvorbis-dev
Finally, scanning my library failed for the first time, because of badly manually encoded ogg files coming from youtube. The mixalot library prefered to fail instead of showing error messages. If you encounter a similar problem, see this PR.
All commands
In the application, type help, and help commands to get this list:
Command list:
/[query] Search library for [query].
show Print search matches, highlighting songs in queue.
back Undo last search.
[songs] Play list of songs.
all Play all songs in selection (equivalent to \"0-\")
+[songs] Append list of songs to queue.
pre[songs] Prepend list of songs to queue.
random Play a random song from the current selection.
random QUERY Play a random song matching QUERY
shuffle SONGS Play songs in random order.
queue Print queue contents and current song playing.
shuffle Randomize order of songs in queue.
clear Clear the queue (current song continues playing)
loop Toggle loop mode (loop through songs in queue)
qdrop Remove last song from queue
qdrop RANGES Remove songs from queue
qtag TAGS Apply tags to all songs in queue
fromqueue Transfer queue to selection
toqueue Replace queue with selection
now Print name of song currently playing.
play Resume playing
stop Stop playing (current song pushed to head of queue)
pause Toggle paused/unpaused.
skip Skip currently playing song. If looping is enabled, this
song won't played again.
next Advance to next song. If looping is enabled, the current
song will be enqueued.
repeat N Add N repetitions of currently playing song to head of queue.
seek TIME Seek to time (in [h:]m:ss format, or a number in seconds)
seek +TIME Seek forward
seek -TIME Seek backward
startat TIME Always start playback at a given time (to skip long intros)
tag List tags of currently playing song.
tag TAGS Add one or more textual tags to the current song.
untag TAGS Remove the given tags from the currently playing song.
tagged TAGS Search for files having any of specified tags.
tags List all tags (and # occurrences) within current query.
killtag TAGS Remove all occurances of the given tags
tagall TAGS Apply tags to all selected songs
untagall TAGS Remove given tags from all selected songs
time Print current time
alarm Set alarm (see \"help alarms\")
scanid3 Scan new files for ID3 tags
prescan Toggle file prescanning (useful if file IO is slow)
exit Exit the program.
help [topic] Help
See also
- mpd, an interface to Music Player Daemon in CL.
other music players:
- cmus
- Emacs’ media players http://wikemacs.org/wiki/Media_player

Final Patch
MonkeyUser 11 09 2018
Freak Spot: Subprocesos en Python
Python Hispano 04 09 2018
Los subprocesos o hilos de ejecución nos permiten realizar tareas concurrentemente. En Python podemos utilizar el módulo threading, aunque hay muchos otros.
Vamos a crear varios subprocesos (threads) sencillos.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import threading
import time
import random
def sleeper(name, s_time):
print('{} iniciado a las {}.'.format(
name, time.strftime('%H:%M:%S', time.gmtime())))
time.sleep(s_time)
print('{} finalizado a las {}.'.format(
name, time.strftime('%H:%M:%S', time.gmtime())))
for i in range(5):
thread = threading.Thread(target=sleeper, args=(
'Proceso ' + str(i + 1), random.randint(1, 9)))
thread.start()
print('Yo he terminado, pero los otros subprocesos no.')
Primero, hemos importado los modulos necesarios: time, random y
threading. Para crear threads solo necesitamos el último. time lo
hemos utilizado para simular una tarea y obtener su tiempo de inicio y
fin; random, para hacer que nuestro proceso tenga una duración
aleatoria.
La función sleeper «duerme» (no hace nada) durante el tiempo que le especifiquemos, nos dice cuándo ha empezado a «dormir» y cuando ha terminado de «dormir». Como parámetros le pasamos el nombre que le queremos dar al subproceso y el tiempo que va a «dormir» la función.
Luego, creamos un bucle for que crea 5 subprocesos que ejecutan la
función sleeper. En el constructor (threading.Thread), debemos
indicar la función a ejecutar (target=sleeper) y los parámetros que
queremos pasarle
(args=('Proceso ' + str(i + 1), random.randint(1, 9)).
Proceso 1 iniciado a las 21:19:23.
Proceso 2 iniciado a las 21:19:23.
Proceso 3 iniciado a las 21:19:23.
Proceso 4 iniciado a las 21:19:23.
Proceso 5 iniciado a las 21:19:23.
Yo he terminado, pero los otros subprocesos no.
Proceso 1 finalizado a las 21:19:25.
Proceso 5 finalizado a las 21:19:26.
Proceso 4 finalizado a las 21:19:27.
Proceso 2 finalizado a las 21:19:32.
Proceso 3 finalizado a las 21:19:32.
El resultado de la ejecución es aleatorio: no sabemos cuál proceso finalizará primero.
![]()
GDPR - What happened?
WhoTracksMe blog 02 09 2018

Building a raft
MonkeyUser 28 08 2018
![]()

Implementation
MonkeyUser 21 08 2018

Macro
MonkeyUser 14 08 2018

Join me on Mastodon
Danny van Kooten 13 08 2018
Summary: Join me on Mastodon. It’s like Twitter, but less angry and more decentralized.
I’ve been a happy Twitter user for years and got a lot of value out of it over the last decade. Even so, I find myself using the service very little these days.
While I can’t say for certain what is the cause of that, the non-chronological timeline and algorithms that seem to excel at showing me rage-inducing tweets come to mind. An extensive mute list helped for a little while, but even that is falling short nowadays.
That’s part of why I was happily surprised when revisiting Mastodon a few weeks ago.
A lot had improved since I last checked in early 2017. I connected to a few people that seemed to be sharing interesting content, found some I already knew and had a really good time exploring the “fediverse” since then.
Why Mastodon?
Here’s a few things that make Mastodon great for me:
- It’s open-source and you can host it yourself, while still participating in the global network and following users on other instances.
- Your feed is chronological, ad-free and there are no algorithms deciding what you actually end up seeing.
- You get 500 characters per “toot” and can hide things behind spoiler warnings.
A sample of what it could look like (although there are many different clients)
I’m enthusiastic about the direction that Mastodon is heading in and am really enjoying myself on there already. If you’re looking for a place that feels a bit like Twitter in the early days, give Mastodon a proper try.
To further promote decentralization, I decided to run my own instance: mastodon.dvk.co (which was super easy to set up, by the way).
Useful Mastodon tools
If you’re new to Mastodon, you’ll have to put in some effort to turn it into something useful. It’s not much fun logging in to an empty feed after all.
Here are some of the tools that helped me:
The next ten years of Instapaper
Instapaper 07 08 2018
This year Instapaper celebrated its tenth birthday and, now that we are an independent company, we’ve been thinking a lot about the next ten years of Instapaper and beyond.
To ensure Instapaper can continue for the foreseeable future, it’s essential that the product generates enough revenue to cover its costs. In order to do so, we’re relaunching Instapaper Premium today.
As a reminder, Instapaper Premium is a subscription for $2.99/month or $29.99/year that offers the following features:
- Full-text search for all articles in your account
- Unlimited Notes
- Text-to-Speech playlists on mobile
- Speed reading to get through all of your articles up to 3x faster
- An ad-free Instapaper website
- “Send to Kindle” using a bookmarklet or our mobile apps
In addition to getting access to Premium features, your Instapaper Premium subscription will help ensure that we can continue developing and operating Instapaper. Our goal is to build a long-term sustainable product and business, without venture capital, and we need your help to achieve that goal.
If you decide to not subscribe to Instapaper Premium, you will continue with a standard free account without access to Premium features.
Additionally, today we are bringing back Instapaper to European Union users. Over the past two months we have taken a number of actions to address the General Data Protection Regulation, and we are happy to announce our return to the European Union.
We are very sorry for the extended downtime and, as a token of our apology, we are giving six months of Instapaper Premium to all EU users affected by the outage.
We’ve updated our privacy policy to include the rights afforded to EU users under the General Data Protection Regulation (GDPR). Additionally, in the interest of transparency, we are posting our privacy policy to GitHub where you can view a versioned history of all the changes to our privacy policy.
Thanks again for your support. If you have any questions, comments or concerns please let us know by sending an email to support@help.instapaper.com.
– Brian Donohue & Rodion Gusev

Blame
MonkeyUser 07 08 2018

Pull Request
MonkeyUser 31 07 2018

Define Madness
MonkeyUser 25 07 2018
Tengo que hacer algunas correcciones a la serie de artículos sobre descriptores, en concreto sobre el método __delete__ del protocolo descriptor.
Primero, aclaremos cómo funciona el método __delete__ y en qué se diferencia de __del__. No se trata de métodos destructores tal y como se entiende en otros lenguajes de programación orientados a objeto. En python, todo objeto está vivo mientras esté referenciado. Sólo cuando se pierda la última referencia se procederá a la destrucción y borrado del objeto en memoria por parte del recolector de basura.
Por ejemplo, veamos el siguiente código:
class Miclase(object):
def __del__(self):
print "instance deleted"
a = Miclase()
b = a
del a
print b
print "Come on"
b = 1
print "END"
De su ejecución, podemos comprobar que el método __del__ no se invoca justo en el momento de hacer del a, si no cuando se pierde la última referencia al asignar otro valor a la variable b. La sentencia del a no destruye el objeto, tan sólo desliga el objeto de la etiqueta a que lo referenciaba. Por ese motivo, es inexacto hablar en python de “variable de memoria”, como se entiende en otro lenguajes. Tan sólo cambiamos de una referencia de un objeto a otro, sin destruir su valor anterior.
Revisión del protocolo descriptor
En un anterior artículo distinguía entre descriptores de datos y de no-datos. Hay que aclarar que un descriptor de datos “es también el que sólo tiene definido un método __delete__, aunque no tenga método __set__“. ¿Para qué puede sernos útil tener uno sin el otro?
Un descriptor de datos sin método __set__ no tiene forma de impedir que el atributo/método que implementa sea sustituído por otro objeto (por ejemplo, por otro descriptor). El método __delete__ nos daría la última opción de liberar recursos que ya no vayamos a usar antes de desaparecer el descriptor. Pero, independiemente de lo que haga, el método __delete__ indicaría que el descriptor puede ser sustituido. En definitiva, se comportaría como un descriptor de no-datos, pero con las diferencias en la invocación entre estos dos tipos de descriptor1.
Para aclarar las cosas, veamos qué estaba mal en el ejemplo que puse en su momento sobre el uso de __delete__ (he cambiado algunos nombres para que se vea más claro):
class Desc(object):
def __init__(self, mul):
self.mul = mul
def __get__(self, obj, cls=None):
return obj.value * self.mul
def __set__(self, obj, value):
raise AttributeError
def __delete__(self, obj):
del self
class Miclase(object):
a12 = Desc(12)
a200 = Desc(200)
def __init__(self, value):
self.value = value
c = Miclase(2)
print c.a12 #--> 24
c.a12 = 100 # ERROR: AttributeError
del Miclase.a12
c.a12=100
print c.a12 #--> 100 (no descriptor)
La idea era que se pudiera borrar el descriptor de datos para sustuirlo por otro valor. Tal como señalaba Cristian en un comentario al respecto, este ejemplo parece funcionar con o sin el método __delete__ en el descriptor.
Funciona siempre debido a que con 'del Miclase.a12' estamos borrando la referencia al descriptor que tiene la clase, sin pasar por el protocolo descriptor. La particularidad de los descriptores es que viven en la clase, pero se invocan desde la instancia. Con 'del Miclase.a12' estamos saltándonos el protocolo descriptor para acceder directamente al atributo de la clase2.
Además, este código no funcionaría nunca:
def __delete__(self, obj):
del self
Si la idea era borrar el objeto self, referencia al descriptor, podemos quitarnos esa idea ya que el comando del borra la referencia del scope local donde se encuentra. ¡No es un destructor! En realidad, todas las variables locales son borradas al finalizar el método. En este caso en concreto, también la variable local obj será borrada aunque no se indique explícitamente.
Otra cuestión a tener en cuenta es que los atributos de clase son compartidos por todas sus instancias. Si en algún momento alteramos un descriptor (por ejemplo, borrándolo), entonces todas las instancias sufririan el mismo cambio. No parece que sea el efecto buscado.
La gran pregunta es entonces, ¿cómo podemos aprovecharnos del método __delete__?
Para sacarle algún partido, el descriptor debería comportarse de forma distinta según sea la instancia que lo invoca. Definido así el descriptoor, entonces podríamos usar el método __delete__ para simular el borrado del atributo para esa instancia, sin que el descriptor pierda su funcionalidad.
Un ejemplo para ilustrar ésto sería:
from weakref import WeakKeyDictionary
class Desc(object):
def __init__(self):
self.data = WeakKeyDictionary()
def __get__(self, obj, cls=None):
if obj not in self.data:
raise AttributeError
total = sum(x for x in self.data.values())
return (self.data.get(obj), total)
def __set__(self, obj, value):
if obj in self.data:
raise AttributeError
self.data[obj] = value
def __delete__(self, obj):
del self.data[obj]
class Miclase(object):
value = Desc()
a = Miclase()
b = Miclase()
a.value = 2
b.value = 5
print a.value #--> (2, 7)
print b.value #--> (5, 7)
a.value = 100 # ERROR: AttributeError
del a.value
a.value = 11
print a.value #--> (11, 16)
print b.value #--> (5, 16)
del b
print a.value #--> (11, 11)
El descriptor mantiene un diccionario weak con valores asignados para cada instancia de la clase. Usamos para ello un WeakKeyDictionary que tiene la particularidad de relajar la referencia al objeto, de modo que si todas las referencias al objeto son borradas en el programa, también es borrada la referencia que conservaba el diccionario.
En este ejemplo, el método __get__ devuelve el valor del atributo si el objeto está en el diccionario, si no da error. El método __set__ asigna un valor al atributo sólo si el objeto no existe. Para ver mejor el funcionamiento, el método __get__ devuelve una tupla con el valor del atributo y la suma de todos los atributos.
Ejecuntado el ejemplo, creamos dos instancias y les asignamos un valor al atributo controlado por el descriptor. Una vez asignado un valor, ya no podemos cambiarlo. La única opción será borrar el atributo y volverlo a asignar.
También se puede comprobar que, cuando borramos el objeto b, la suma de todos los atributos se actualiza a las instancias que aún quedan vivas.
En el borrado del atributo se usa el método __delete__ del descriptor; en el borrado de la instancia, el método __del__ (si existiera).
Referencia
No quisiera acabar este artículo sin añadir una referencia sobre este tema que os recomiendo leer, con algunas recetas para aprovechar el uso de los descriptores:
“Python Descriptors Demystified” by Chris Beaumont
-
Comentado en los anteriores artículos sobre descriptores. ↩
-
Un modo de impedir el borrado de atributos de una clase sería aplicando el protocolo descriptor con metaclases, pero pienso que estaríamos complicándolo todo demasiado para el beneficio que pudiera obtenerse a cambio. ↩
Info
Disponible también como ipynb
Quien se enfrenta a la documentación de python por primera vez se pregunta porqué esa insistencia en mantener tipos de datos duplicados en versiones mutables e inmutables. Tenemos listas y tuplas que casi hacen lo mismo. En python3, tenemos el tipo inmutable bytes y el mutable bytearray. ¿Qué sentido tiene tener “duplicados” algunos tipos en sus dos versiones? La única explicación que se puede encontrar en la documentación es que los tipos inmutables son más apropiados para usarlos como índices en diccionarios. No parece mucha ventaja para la complejidad que aporta.
En este artículo veremos qué implica la mutabilidad de un tipo de dato y en qué puede sernos útil usar un tipo mutable u otro inmutable.
¿Qué es lo que cambia?
Antes de explicar nada, veamos si somos capaces de saber qué está cambiando. Veamos dos códigos muy similares:
>>> a = (1, 2, 3, 4)
>>> a += (5, 6, 7)
>>> print(a)
(1, 2, 3, 4, 5, 6, 7)
>>> a = [1, 2, 3, 4]
>>> a += [5, 6, 7]
>>> print( a )
Parece que ambos códigos hagan lo mismo: añadir un fragmento, en sus versiones tupla y lista, respectivamente. Vamos a analizarlo mejor. Para saber qué pasa, usemos la función id(). Esta función devuelve un identificador de un objeto de tal modo que si dos objetos tienen el mismo identificador, entonces son el mismo objeto.
>>> a = (1, 2, 3, 4)
>>> print(id(a))
192021604
>>> a += (5, 6, 7)
>>> print(id(a))
189519828
>>> a = [1, 2, 3, 4]
>>> print(id(a))
189780876
>>> a += [5, 6, 7]
>>> print(id(a))
189780876
En la versión tupla, se ha creado una nueva tupla para realizar la operación, mientras que en la versión lista se ha usado la misma lista, modificándose con el resultado. Si cambiamos el operador += por una versión más explícita tal vez se vea mejor:
>>> a = (1, 2, 3, 4)
>>> a = a + (5, 6, 7)
>>> a = [1, 2, 3, 4]
>>> a.extend([5, 6, 7])
Al operar con tuplas, los operandos no cambian de valor, creándose una nueva tupla como resultado de la operación. Podríamos sustituir toda la operación por el resultado final y el código funcionaría igual. En el caso de las listas, la lista se modifica “in situ” durante la operación. En estos casos, cambiar la expresión por el resultado final no garantiza que el programa funcione igual. Se necesita pasar por todos y cada uno de los estados intermedios para asegurar que todo funcione igual.
Esta propiedad de poder cambiar una expresión por su resultado final es conocida por Transparencia referencial en programación funcional. Por lo general, los tipos inmutables se adecúan mejor a operaciones de cálculo donde el resultado final depende únicamente de los argumentos de entrada. Por otro lado, los tipos mutables son útiles para salvaguardar estados intermedios necesarios para la toma de decisiones durante la ejecución de un programa.
Por lo general, se saber elegir un tipo mutable o su homólogo inmutable es todo un arte. Ante la duda, los tipos inmutables son más fáciles de rastrear. Así mismo, veremos en próximos artículos que los tipos inmutables ayudan bastante en programación concurrente, por si estás pensando en programación multiproceso.
Ejemplos de tipos propios
La mutabilidad e inmutabilidad va más allá de los tipos estándar de python. Nosotros mismos podemos hacer nuestras propias clases mutables o inmutables, según nuestras necesidades.
Pongamos que creamos una clase Point para definir puntos, junto con unas sencillas operaciones para sumar, restar y desplazar. Nuestra idea es poder usar estos objetos en expresiones, por lo que es práctica común que toda operación devuelva el resultado como un punto para seguir encadenando operaciones.
Una versión “mutable” del objeto sería así:
class PointMutable(object):
def __init__(self, x, y):
self.x=x
self.y=y
def __repr__(self):
return "<Point(%d,%d)>" % (self.x, self.y)
def __sub__(self, other):
self.x -= other.x
self.y -= other.y
return self
def __add__(self, other):
self.x += other.x
self.y += other.y
return self
def move(self, dx, dy):
self.x += dx
self.y += dy
return self
En todas las operaciones, operamos el objeto consigo mismo y lo retornamos como resultados. Si probamos, vemos que no funciona tal como se esperaba:
>>> p1=PointMutable(1, 1)
>>> p2=PointMutable(-1, 1)
>>> print p1.move(1, 1) - (p1 + p2).move(2, 2)
<Point(0,0)>
Devuelve <Point<0,0> independientemente de los valores iniciales y de los desplazamientos que demos. Al ser nuestro objeto mutable, cada operación lo va cambiando. Al final, toda la expresión se reduce a una simple resta p1-p1, que sería la última operación y que da siempre <Point(0,0)>. No parece que sea el resultado esperado.
Debemos adoptar una táctica más defensiva: el objeto nunca debe cambiar durante el cálculo. Como resultado de cada operación deberemos devolver una nueva instancia y que el estado de ésta, o sea, sus atributos, no se alteren a lo largo del cálculo:
class PointInmutable(object):
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return "<Point(%d,%d)>" % (self.x, self.y)
def __sub__(self, other):
return PointInmutable(self.x - other.x, self.y - other.y)
def __add__(self, other):
return PointInmutable(self.x + other.x, self.y + other.y)
def move(self, dx, dy):
return PointInmutable(self.x + dx, self.y + dy)
>>> p1=PointInmutable(1, 1)
>>> p2=PointInmutable(-1, 1)
>>> print p1.move(1, 1) - (p1 + p2).move(2, 2)
<Point(0,-2)>
Siendo perfeccionistas, deberíamos blindar mejor los atributos de la clase para hacerlos de sólo lectura mediante properties.
En este ejemplo hemos podido ver los resultados imprevisibles que podemos tener si abusamos de la mutabilidad. Estos problemas se ven incrementados si hubiera varios hilos de ejecución y cada hilo estuviera modificando las mismas variables comunes. Lamentablemente, es un caso bastante común debido a una mala previsión a la hora de iniciar un proyecto de desarrollo. Pero ésto lo veremos en un próximo artículo.

Production Ready
MonkeyUser 17 07 2018
Instapaper is going independent
Instapaper 16 07 2018
Today, we’re announcing that Pinterest has entered into an agreement to transfer ownership of Instapaper to Instant Paper, Inc., a new company owned and operated by the same people who’ve been working on Instapaper since it was sold to betaworks by Marco Arment in 2013. The ownership transfer will occur after a 21 day waiting period designed to give our users fair notice about the change of control with respect to their personal information.
We want to emphasize that not much is changing for the Instapaper product outside the new ownership. The product will continue to be built and maintained by the same people who’ve been working on Instapaper for the past five years. We plan to continue offering a robust service that focuses on readers and the reading experience for the foreseeable future.
Lastly, we want to express our deepest gratitude to Pinterest for being such great stewards of the product over the past two years. With their support, we rebuilt search, introduced an extension for Firefox, made a variety of optimizations for the latest mobile operating systems and more. Our focus is providing a great reading application to our users, we appreciated the opportunity to do that at Pinterest, and are excited to continue our work.
If you have any questions, comments or concerns please let us know by sending an email to support@help.instapaper.com or replying directly to this email.
– Instapaper Team

En el episodio 69 de República Web, Podcast dirigido y escrito por Javier Archeni (@javierarcheni), he tenido el placer de ser invitado para mantener una tertulia animada sobre Python. Entre muchos temas se tocaron:
- Libros interesantes.
- El origen del lenguaje.
- Virtudes.
- Consejos para novatos.
- Actualidad sobre el lenguaje.
- Frameworks como Django o Flask.
- Usos académicos y empresariales.
Si es un lenguaje que siempre te ha llamado la atención y sientes curiosidad por ver sus posibilidades, escucha el episodio con mucha atención. No te dejará indiferente. Y no olvides dejar un comentario.

Zeno's Progress
MonkeyUser 10 07 2018
![]()
![]()
Python es un lenguaje sencillo y rápido de aprender. Su sintaxis es parecida a escribir cualquier texto en inglés, pero con la potencia de sus principales competidores en el BackEnd.
Es un placer de leer y redactar. Python predica que un código debe ser escrito por humanos para humanos. Después de todo lo que programas va a ser leído por ti y por el resto del equipo. Si escribes para máquinas, solo te entenderán máquinas.
Además viene con “Pilas incluidas”. Eso quiere decir que posee su propio gestor de paquetes, sin necesidad de instalar aplicaciones externas. Simplificando tareas de instalación o actualización.
Otro punto a su favor es que no necesita un ecosistema para ejecutarse, como puede ser Xampp, Vangrant, Docker… Python solo requieres Python. Lanzando un comando en el terminal estará ejecutándose su propio servidor Web, consiguiendo que su puesta en producción sea sorprendentemente rápida.
Y por si fuera poco, es el segundo lenguajes que mejor esta pagado por las empresas. Por detrás de Ruby.
¿Donde nació Python?
En una navidad de 1989 un programador fue enviado a casa. Sus oficinas iban a estar cerradas durante unas semanas. Esta persona de 33 años, llamada Guido van Rossum, se encontró que solo tenía un solo aparato para entretenerse hasta que acabaran las navidades: un ordenador. Para matar el rato decidió distraerse programando un interprete para un nuevo lenguaje de programación de scripting que había estado teorizando en sus ratos libres. Un heredero de ABC. Sin mucho interés, casi por formalidad, lo bautizó con un nombre sencillo. Él era muy fan de los Monty Python, por lo que lo llamó: Python.
Y aquí es donde nació uno de los lenguajes más expresivos y buque insignia del Código Abierto.
Frameworks Web
Entre sus numerosos y fantásticos Frameworks, nos podemos encontrar unas bestias: Django y Flask (que no confundir que el zombie Adobe Flash).
Django sería lo más cercano a Laravel en PHP o Ruby on Rails para Ruby. Un marco de trabajo completo y eficiente para desarrollar Aplicaciones Web de una gran complejidad con un mínimo esfuerzo. Casi cualquier cosa que necesites posiblemente estará integrado.
Para desarrollos altamente personalizados o con unos tiempos cortos, nos encontramos a Flask. Autodenominado microframework, pero con funcionalidades sencillas e inteligentes para construir cualquier sitio que se te pase por la cabeza.
Uno no sustituye al otro. Merece la pena experimentarlos y ver sus diferentes enfoques.
Comunidad
La comunidad de Python es una de las más sanas y activas que te podrás encontrar. Los usuarios organizan espontáneamente charlas mensuales y talleres gratuitos en torno al lenguaje. Anualmente se celebra diversos congresos. El más popular se conoce como PyCon y este año en España se celebra la 6ª edición en Málaga entre el 5 y 7 de Octubre. Pero también hay grupos especiales como las Django Girls, un grupo femenino para animar a que otras mujeres den el paso de aprender a programar.
Su gran apoyo por la comunidad se debe en parte por la gran variedad de profesiones que usan Python, como puede ser: el análisis de datos, la inteligencia artificial, la creación de aplicaciones para escritorio, desarrollo de micro dispositivos, etc… Las librerías no dejan de crecer y suelen estar cuidadosamente documentadas, promoviendo un entorno agradable.
Competidores
En cuanto a la competencia, es amplia y con mucha experiencia. Hecho que no es malo de por sí. Los más destacables son: PHP, Ruby, Node.js, Java y Go. Aunque Ruby podría considerarse un primo hermano por sus similitudes. Ambos se encuentras muy equilibrados, aunque Python no deja de subir año tras año entre los lenguajes más utilizados.
Recomendaciones para el primerizo
Si quieres iniciarte en este lenguaje interpretado, y en concreto en el universo Web, te aconsejo que le des una oportunidad a Flask. Puedes crear pequeños proyectos como una web sencilla, un REST API o un panel administrativo. Poco después sería aconsejable dar el salto a Django, y vivir en tus propias carnes una de las experiencias más completas de Python. Sumérgete en proyectos con una gran densidad de trabajo, como puede ser un blog, un e-commerce o una red social. Descubre cada uno de sus detalles, visita los ejemplos de la documentación, diseña bases de datos relacionales de gran solidez… no te decepcionará el ORM de Django (gestor para realizar consultas en la base de datos) ni su motor de plantillas.
Futuro
Las previsiones son muy buenas. Las versiones son constantes y compatibles con todas las plataforma. Su creador, Guido van Rossum, es denominado como “Benevolente dictador vitalicio” por dejar que la comunidad tomen las decisiones. Tan solo dejó 4 directrices:
- Python debería ser fácil, intuitivo y tan potente como sus principales competidores.
- El proyecto sería de Código Abierto para que cualquiera pudiera colaborar.
- El código escrito en Python sería tan comprensible como cualquier texto en inglés.
- Python debería ser apto para las actividades diarias permitiendo la construcción de prototipos en poco tiempo.
Y por ahora la comunidad lo cumple todo.
Ahora ya conoces los riesgos y beneficios, ¿te atreves a cruzar la frontera?
En el artículo anterior se explicó el procedimiento de instalación de Spark usando Docker. En este artículo se usará un texto tomado de la página de la ONU, de ahí se extrae las líneas y se cuentan las palabras.
A continuación el texto que se va a utilizar (lo pueden bajar desde el repositorio gitlab):
1942: La Declaración de las Naciones Unidas
Representantes de 26 Estados que lucharon contra las potencias del Eje Roma-Berlín-Tokio manifestaron su apoyo a la Carta del Atlántico mediante su firma de la « Declaración de las Naciones Unidas ». En este trascendental documento, los signatarios se comprometían a poner su máximo empeño en la guerra y a no firmar una paz por separado.
Declaración de las Naciones Unidas prometiendo "emplear todos sus recursos, militares o económicos" en "la lucha por la victoria sobre el hitlerismo".
El día de año nuevo de 1942, el señor presidente Roosevelt y los señores Winston Churchill, Maxim Litvinov, de la Unión Soviética, y T. V. Soong, de China, firmaron un breve documento que luego se conocería como la Declaración de las Naciones Unidas. Al día siguiente se sumaron los representantes de otras 22 naciones más. En este trascendental documento, los signatarios se comprometían a poner su máximo empeño en la guerra y a no firmar una paz por separado.
La Declaración de las Naciones Unidas
La alianza completa a que se llegó en esta forma concordaba con los principios enunciados en la Carta del Atlántico, y la primera cláusula de la declaración de las Naciones Unidas reza que los países signatarios
« . . . han suscrito un programa común de propósitos y principios enunciados en la declaración conjunta del presidente de los Estados Unidos de América y del primer ministro del Reino Unido de la Gran Bretaña e Irlanda del Norte, fechada el 14 de agosto de 1941, y conocida como la Carta del Atlántico. ».
Cuando tres años después se iniciaban los preparativos para la conferencia de San Francisco, únicamente se invitó a participar a aquellos estados que, en marzo de 1945, habían declarado la guerra a Alemania y al Japón y que habían firmado la Declaración de las Naciones Unidas.
Signatarios Originales de la Declaración de la ONU
Los 26 signatarios originales fueron: Los Estados Unidos de América, el Reino Unido de la Gran Bretaña e Irlanda del Norte, la Unión de Repúblicas Socialistas Soviéticas, China, Australia, Bélgica, Canadá, Costa Rica, Checoeslovaquia, El Salvador, Grecia, Guatemala, Haití, Honduras, India, Luxemburgo, Nicaragua, Noruega, Nueva Zelandia, Países Bajos, Panamá, Polonia, República Dominicana, Unión Sudafricana, Yugoeslavia .
Los firmantes posteriores
Más tarde se adhirieron a la Declaración los siguientes países (en el orden de las firmas): México, Colombia, Iraq, Irán, Liberia, Paraguay, Chile, Uruguay, Egipto, Siria, Francia, Filipinas, Brasil, Bolivia, Etiopía, Ecuador, Perú, Venezuela, Turquía, Arabia Saudita, Líbano.
A continuación se muestra la ejecución del código (si quieren bajar el archivo jupyter notebook lo pueden descargar desde gitlab):
In [1]:
#Se importa SparkContext y SparkConf
from pyspark import SparkContext, SparkConf
In [2]:
#Se crea la instancia de la configuración con el nombre de la aplicación contador
conf1 = SparkConf().setAppName("contador").setMaster("local[3]")
In [3]:
#Se crea el contexto pasando la instancia de la configuración
sc = SparkContext(conf = conf1)
In [4]:
#Se extrae las líneas del texto
lineas = sc.textFile("data/declaracion_onut.text")
In [6]:
#Se extrae las palabras del texto y se cuentan
contarPalabras = lineas.flatMap(lambda linea: linea.split(" ")).countByValue()
In [7]:
#Se muestra las palabras con la cantidad de veces que tiene su aparición
for palabra, contador in contarPalabras.items():
print("{} : {}".format(palabra, contador))
Como se puede ver, se logra obtener la cantidad de veces que aparecen las palabras en el texto.

Unfinished Work
MonkeyUser 03 07 2018
These Months in Common Lisp: Q2 2018
Lisp journey 02 07 2018
Documentation
- Paradigms of Artificial Intelligence Programming epub
- Models and Databases, with Mito and SxQL - the Common Lisp Cookbook
- Awesome Common Lisp learning list
Announcements
- ELS2018 proceedings (PDF)
- SBCL 1.4.6 released
- SBCL 1.4.7 Released
- LispWorks 7.1.1 - Patches
- SBCL method-combination fixes
- SBCL method tracing
- $500 Bounty on Clozure/ccl
Jobs
- Junior Lisp Developer, RavenPack, Marbella, Spain
- 3E : Lisp Developer - development, maintenance, design and unit testing of SynaptiQ’s real-time aggregation and alerting engine that processes time-series and events. This data engine is Common Lisp based.
- Lisp Engineer - AI (Natural Language Reasoning)
Projects
Quicklisp dist update, march 2018
- SHCL: An Unholy Union of POSIX Shell and Common Lisp (reddit)
- cl-notebook
- Heroku buildpack for Common Lisp
- Kubernetes Client Library for Common Lisp
- Interactive Common Lisp code snippets in any web page
- rove - small testing framework (Fukamachi’s successor to Prove)
- can - a role-based access right control library
- house - custom asynchronous HTTP server for the Deal project.
- oxenfurt - A Common Lisp client library for the Oxford dictionary API.
- algebraic-data-library
- Lisp Interface to Federal Reserve Economic Data (FRED®)
- reddit1.0 source code (comments), then Reddit’s code runs on SBCL. See also reddit.
- Petalisp: Elegant High Performance Computing
- Code Golf Site with Common Lisp Support!
- vseloved/wiki-lang-detect: Text language identification using Wikipedia data
- ppath, a path manipulation library
- CRAM: Cognitive Robot Abstract Machine - a toolbox for designing, implementing and deploying software on autonomous robots
- cl-statistics.lisp
- Pseudoscheme - An implementation of Scheme embedded in Common Lisp (“with minor changes it runs in ABCL, CCL, ECL and LispWorks. But not in SBCL…”)
- Powerlisp: A simple tool to automate your work with dmenu/rofi
- curry-compose-reader-macros - concise function partial application and composition
- json-mop: A metaclass for bridging CLOS and JSON objects
- clsh: a set of Lispy bindings for running and composing *nix processes
- snakes - Python style generators for Common Lisp. (Includes a port of itertools.)
new releases:
(re)discoveries:
- Cocoa interface code written in Lisp for use with Clozure Common Lisp
- cl-bench - Common Lisp benchmarking suite
- Eclipse Common Lisp (Howard Stearns / Elwood Corp)
- Arboreta/arboreta-wasm - Common Lisp tooling for WebAssembly
- QGAME: Quantum and Gate Measurement Emulator
- Trivia: Pattern Matching
From the Lisp Game Jam 2018:
all results
Articles
- Lisp, Jazz, Aikido: Three Expressions of a Single Essence
- Creating a CL-Rivescript Interpreter (Part 1) and part 10
- Why lisp - biolisp
- Scripting in Common Lisp with buildapp’s multi-call binaries and fare’s cl-scripting
- Fun with Macros: Gathering / Steve Losh
- Calling Go Functions from Lisp
- Lispology - Printing floating-point numbers
- Prolog to Lisp
- How do you design with Prolog in Lisp?
- When to use type specifiers in CL code?
- Jeff Massung: Common Lisp libraries that I made over the course of a few years and have consistenly returned to, always found useful, and kept up-to-date.
- Experience writing a full featured livejournal blog client in Common Lisp. Part 2: client logic
- My Lisp Journey #1: Getting Started With trivial-gamekit
- The (Un)common Lisp approach to Operations Research (2012)
- Alien: Return of Alien Technology to Classical Planning
Discussion
- What Common Lisp web library should I use?, and Lisp for building a web app, options?
- How to collect all asdf dependencies for package-inferred-system?
- SBCL on Raspberry Pi
- Please, join the cl-telegram-bot refactoring effort!
- GUI development done in Lisp (2013 comment) (reddit)
- Question: trying to generalize posix ‘stat-’ functions
- Package Name and Nickname Collisions in Quicklisp
- Common Lisp and Machine Learning these days
- Is cl-autowrap the preferred way to generate FFI bindings these days?
- Want to make it so Common Lisp understands GeoJSON data
- How to send and receive data over UDP asynchronously in common lisp?
- Fun with Macros: Gathering / Steve Losh
Learning Lisp:
- One package per (or file project something-else)?
- Small executables in LISP ?
- What can Sly do out-of-the-metaphorical-box that slime+slime-company+
can’t? - TIL that I can create CLOS constructors for conditions
- Macro question from a Clojure programmer
- Why did you decide to learn Lisp?
- How do you go about starting a Common Lisp Project? A beginner looking for pointers.
Screencasts
- Lots of bits of lisp - CFFI
- Lots of bits of Lisp - Macros (2 hr episode)
- MIT OpenCourseWare
- Lisp, The Quantum Programmer’s Choice - Computerphile episode 2
- McCLIM + Maxima: plot manipulation
- McCLIM + Maxima: vector demo
- Comfy Lisp Programming - Project “Wikify” | Episode 2 @ 10am PST
- Pushing Pixels with Lisp - Episode 45 - World space shenanigans & Vignette
- Common lisp and C++17 Live coding stream | TinyCDN CFFI Interop | Episode 13
- Growing a Lisp compiler - Amsterdam Lisp
- Web Development in Emacs, Common Lisp and Clojurescript - Potato (Slack-like)
- Any news on the ELS videos? (answer: no)
Common Lisp VS …
New Weblocks tutorial: widgets
Lisp journey 25 06 2018
Weblocks is a web framework, created circa 2007, that allows to write dynamic web applications in full Lisp, without a line of Javascript. It is based on so called widgets, that are rendered server-side and updated on the client, and it was also based on continuations (they were removed in this fork, at least for now). It was quietly being forgotten but it is being fixed, refactored, documented and simplified by Alexander “svetlyak40wt” since a year or so.
I rewrote the quickstart to show the use of widgets, the heart of Weblocks, Alexander proof-read and here we are:
http://40ants.com/weblocks/quickstart.html (and reddit comments)
I copy it below, of course check the official website for updates.
The old Weblocks website is at https://common-lisp.net/project/cl-weblocks/
Btw, other isomorphic web frameworks I know are Haskell’s Haste, Nim’s Karax, Ocaml’s Heliom, Python’s Nagare, of course Smalltalk’s Seaside and a couple more.
Weblocks is now the easiest to get started with, the one “really isomorphic” (bluring the line between server and client code), the most elegant (to me) and one of the two, with Seaside, that allow for REPL-driven development.
For what I tested, Heliom is a hell to install, it seems a hell to deploy, and it is bloated with specific Ocaml syntax that is always upcoming in new compiler versions.
Karax seems promising, it was recently used to rewrite the Nim forum. It has currently zero docs (not even a quickstart ;) ) and Nim’s ecosystem isn’t near as large as CL’s. (and, well, no REPL, no Lisp)
Nagare is actually based on Stackless Python. Looking at the code of the successfull Kansha Trello clone, it actually includes inline Javascript. And personnally, I’m running away from Python so…
Quickstart
warning
- This version of Weblocks is not in Quicklisp yet. To
- install it you need to clone the repository somewhere where ASDF will find it, for example, to the
~/common-lisp/directory.Load weblocks and create a package for a sandbox:
CL-USER> (ql:quickload '(:weblocks :weblocks-ui :find-port))
CL-USER> (defpackage todo
(:use #:cl
#:weblocks-ui/form
#:weblocks/html)
(:import-from #:weblocks/widget
#:render
#:update
#:defwidget)
(:import-from #:weblocks/actions
#:make-js-action)
(:import-from #:weblocks/app
#:defapp))
#<PACKAGE "TODO">
CL-USER> (in-package todo)
#<PACKAGE "TODO">
Now, create an application:
TODO> (defapp tasks)
TODO> (weblocks/debug:on)
TODO> (defvar *port* (find-port:find-port))
TODO> (weblocks/server:start :port *port*)
<INFO> [19:41:00] weblocks/server server.lisp (start) -
Starting weblocks WEBLOCKS/SERVER::PORT: 40000
WEBLOCKS/SERVER::SERVER-TYPE: :HUNCHENTOOT DEBUG: T
<INFO> [19:41:00] weblocks/server server.lisp (start-server) -
Starting webserver on WEBLOCKS/SERVER::INTERFACE: "localhost"
WEBLOCKS/SERVER::PORT: 40000 DEBUG: T
#<SERVER port=40000 running>
(NIL)
Open http://localhost:40000/tasks/ in your browser (double check the port) and you’ll see a text like that:
No weblocks/session:init method defined.
Please define a method weblocks.session:init to initialize a session.
It could be something simple, like this one:
(defmethod weblocks/session:init ((app tasks))
"Hello world!")
Read more in the documentaion.
It means that you didn’t write any code for your application. Let’s do it now and make an application which outputs a list of tasks.
In the end, we’ll build the mandatory TODO-list app:
The Task widget
TODO> (defwidget task ()
((title
:initarg :title
:accessor title)
(done
:initarg :done
:initform nil
:accessor done)))
This code defines a task widget, the building block of our application.
defwidget is similar to Common Lisp’s defclass, in fact it is only a
wrapper around it. It takes a name, a list of super-classes (here ())
and a list of slot definitions.
We can create a task with make-instance:
TODO> (defvar *task-1* (make-instance 'task :title "Make my first Weblocks app"))
TODO> *task-1*
#<TASK {1005406F33}>
Above, :title is the initarg, and since we didn’t give a :done
argument, it will be instanciated to its :initform, which is nil.
We defined accessors for both slots, so we can read and set them easily:
TODO> (title *task-1*)
"Make my first Weblocks app"
TODO> (done *TASK-1*)
NIL
TODO> (setf (done *TASK-1*) t)
T
We define a constructor for our task:
TODO> (defun make-task (&key title done)
(make-instance 'task :title title :done done))
It isn’t mandatory, but it is good practice to do so.
If you are not familiar with the Common Lisp Object System (CLOS), you can have a look at Practical Common Lisp and the Common Lisp Cookbook.
Now let’s carry on with our application.
The Tasks-list widget
Below we define a more general widget that contains a list of tasks, and
we tell Weblocks how to display them by specializing the render
method for our newly defined classes:
TODO> (defwidget task-list ()
((tasks
:initarg :tasks
:accessor tasks)))
TODO> (defmethod render ((task task))
"Render a task."
(with-html
(:span (if (done task)
(with-html
(:s (title task)))
(title task)))))
TODO> (defmethod render ((widget task-list))
"Render a list of tasks."
(with-html
(:h1 "Tasks")
(:ul
(loop for task in (tasks widget) do
(:li (render task))))))
The with-html macro uses
Spinneret under the hood,
but you can use anything that outputs html.
We can check how the generated html looks like by calling render in
the REPL:
TODO> (render *task-1*)
<div class="widget task"><span>Make my first Weblocks app</span>
</div>
NIL
But we still don’t get anything in the browser.
TODO> (defun make-task-list (&rest rest)
"Create some tasks from titles."
(loop for title in rest collect
(make-task :title title)))
TODO> (defmethod weblocks/session:init ((app tasks))
(declare (ignorable app))
(let ((tasks (make-task-list "Make my first Weblocks app"
"Deploy it somewhere"
"Have a profit")))
(make-instance 'task-list :tasks tasks)))
This defines a list of tasks (for simplicity, they are defined as a list in memory) and returns what will be our session’s root widget..
Restart the application:
TODO> (weblocks/debug:reset-latest-session)
Right now it should look like this:

Adding tasks
Now, we’ll add some ability to interact with a list – to add some tasks into it, like so:

Import a new module, weblocks-ui to help in creating forms and other
UI elements:
TODO> (ql:quickload "weblocks-ui")
TODO> (use-package :weblocks-ui/form)
Write a new add-task function and modify the render method of a
task-list:
TODO> (defmethod render ((widget task-list))
(flet ((add-task (&key title &allow-other-keys)
(push (make-task :title title)
(tasks (weblocks/widgets/root:get)))
(update (weblocks/widgets/root:get))))
(with-html
(:h1 "Tasks")
(loop for task in (tasks widget) do
(render task))
(with-html-form (:POST #'add-task)
(:input :type "text"
:name "title"
:placeholder "Task's title")
(:input :type "submit"
:value "Add")))))
TODO> (weblocks/debug:reset-latest-session)
The function add-task does only two simple things:
- it adds a task into a list;
- it tells Weblocks that our root widget should be redrawn.
This second point is really important because it allows Weblocks to
render necessary parts of the page on the server and to inject it into
the HTML DOM in the browser. Here it rerenders the root widget, but we
can as well update a specific task widget, as we’ll do soon.
We also took care of defining add-task inline, as a closure, for it to
be thread safe.
Another block in our new version of render of a task-list is the form:
(with-html-form (:POST #'add-task)
(:input :type "text"
:name "task"
:placeholder "Task's title")
(:input :type "submit"
:value "Add"))
It defines a text field, a submit button and an action to perform on
form submit. The add-task function will receive the text input as
argument.
note
This is really amazing!
With Weblocks, you can handle all the business logic server-side, because an action can be any lisp function, even an anonymous lambda, closuring all necessary variables.
Restart the application and reload the page. Test your form now and see in a Webinspector how Weblocks sends requests to the server and receives HTML code with rendered HTML block.
Now we’ll make our application really useful – we’ll add code to toggle the tasks’ status.
Toggle tasks
TODO> (defmethod toggle ((task task))
(setf (done task)
(if (done task)
nil
t))
(update task))
TODO> (defmethod render ((task task))
(with-html
(:p (:input :type "checkbox"
:checked (done task)
:onclick (make-js-action
(lambda (&rest rest)
(declare (ignore rest))
(toggle task))))
(:span (if (done task)
(with-html
;; strike
(:s (title task)))
(title task))))))
We defined a small helper to toggle the done attribute, and we’ve
modified our task rendering function by adding a code to render a
checkbox with an anonymous lisp function, attached to its onclick
attribute.
The function make-js-action returns a Javascript code, which calls
back a lisp lambda function when evaluated in the browser. And because
toggle updates a Task widget, Weblocks returns on this callback a new
prerendered HTML for this one task only.
What is next?
As a homework:
- Play with lambdas and add a “Delete” button next after each task.
- Add the ability to sort tasks by name or by completion flag.
- Save tasks in a database (the Cookbook might help).
- Read the rest of the documentation and make a real application, using the full power of Common Lisp.

Como en Noviembre del año pasado, escribí un artículo sobre árboles de decisión con Python, donde se tenía una serie de datos de entrada (altura, peso y talla) y de salida si era hombre o mujer. Para este artículo lo que se va a agregar es la visualización del árbol de decisión, para ello se usará dos librerías de Python pydot y graphviz .
Se da por sentado que ya se tiene instalado scikit-learn, se instala entonces pydot y graphviz:
#pip3 install pydot
#pip3 install graphviz
Ahora se muestra el código:



Ahora toca la visualización del árbol:


Para terminar se muestra el grafo del árbol:
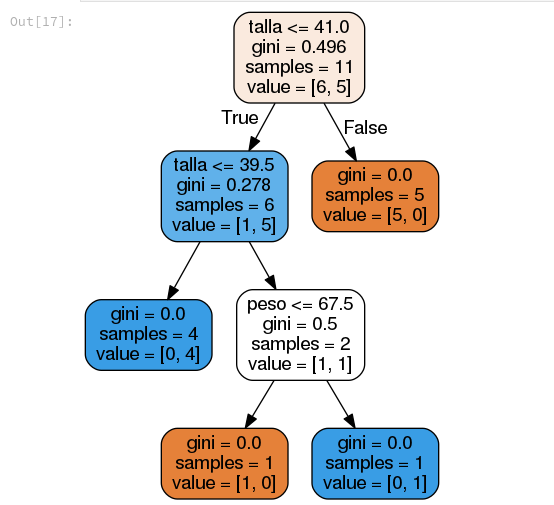
Este grafo se genera a partir de la instancia de la clase que se usa para ingresar los datos, se entrena, y se usa para predecir con nuevos datos.
La información que muestra cada nodo de decisión:
- Samples: La cantidad de muestras que se maneja.
- gini: Es un indice que indica el costo de la evaluación de separar los datos.
- value: Es un valor que se está evaluando en ese momento.
En próximo artículo se hará otro ejemplo ya con un mayor conjunto de datos.
Sí tienes algun pregunta u observación, puedes hacerlo en los comentarios del post.
¡Haz tu donativo!
Si te gustó el artículo puedes realizar un donativo con Bitcoin (BTC) usando la billetera digital de tu preferencia a la siguiente dirección: 17MtNybhdkA9GV3UNS6BTwPcuhjXoPrSzV
O Escaneando el código QR desde billetera:


Happy Flow
MonkeyUser 19 06 2018

TBD
MonkeyUser 19 06 2018

Root Cause
MonkeyUser 12 06 2018

Existe el área de análisis de redes sociales, puedes hacer gráficos de tendencias, lograr cual fue el origen de un tweet. La idea es usar la librería tweepy para conectase a Twitter y de allí capturar los tweets para luego realizar un análisis de sentimiento y graficar el resultado.
El análisis de sentimiento se refiere al uso de procesamiento de lenguaje natural, análisis de texto y lingüistica computacional para identificar y extraer información subjetiva de los recursos (más información en wikipedia).
Se puede realizar análisis de sentimiento a cualquier texto, puede ser de correos, de páginas web, de publicaciones en redes sociales como twitter, facebook, google+, entre otros. Con ello se puede lograr un aproximado de la evaluación emocional que tiene un tema o persona en algún momento en las redes sociales o contenidos evaluados.
La idea es obtener el tráfico de twitter sobre un tema o persona, aplicarle análisis de sentimiento y graficar los resultados.
Este artículo se basa en un artículo en inglés publicado en freecodecamp con título Basic data analysis on Twitter with Python . Este artículo se desarrolla una aplicación gráfica en TK para obtener la información y luego realizar la captura, cálculos y gráficos. El código fuente de la aplicación del artículo se encuentra en github.
Para tener acceso al API de twitter se tiene que crear una cuenta en la página para las aplicaciones que lo requieran.
Para autenticarse se usará el siguiente código:
consumer_key = 'consumer key'
consumer_secret = 'consumer secrets'
access_token = 'access token'
access_token_secret = 'access token secret'
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
En este caso se usará jupyer lab para mostrar la aplicación con ajustes en el código para su reutilización, por ejemplo, que realice el análisis en Español o Inglés.
La librería a usar será tweepy, la librería para análisis de texto TextBlob y matplotlib.
Para instalar tweepy se usará pip3:
pip3 install tweepy textblob
Revisemos primero las tendencias en twitter para Valencia (Venezuela), a continuación una imagen de las tendencias.
Se buscará el análisis de sentimiento de la tendencia Rafael Nadal, se buscará en 200 tweets y en español.
A continuación el código fuente:
El código fuente en el repositorio de gitlab lo pueden ver en el enlace.
#!/usr/bin/env python3
#Se importa la librería tweepy
import tweepy
#Se importa sleep, datetime, TextBlob y matplotlib
from time import sleep
from datetime import datetime
from textblob import TextBlob
import matplotlib.pyplot as plt
#Se define las variables para el acceso al API de twitter
consumer_key = ''
consumer_secret = ''
access_token = ''
access_token_secret = ''
#Se autentica en twitter
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
#se verifica que el usuario conectado en twitter es de uno
print(api.me().name)
#Se pregunta por la palabra a preguntar
palabra = input("Buscar: ")
#Se define la cantida de tweets a capturar
numero_de_Tweets = int(input(u"Número de tweets a capturar: "))
#Se define el idioma de los tweets a analizar
lenguaje = input("Idioma [es/en]:")
def ObtenerTweets(palabra="Trump",times=100,leguanje="en"):
#Se define las listas que capturan la popularidad
popularidad_list = []
numeros_list = []
numero = 1
for tweet in tweepy.Cursor(api.search, palabra, lang=lenguaje).items(numero_de_Tweets):
try:
#Se toma el texto, se hace el analisis de sentimiento
#y se agrega el resultado a las listas
analisis = TextBlob(tweet.text)
analisis = analisis.sentiment
popularidad = analisis.polarity
popularidad_list.append(popularidad)
numeros_list.append(numero)
numero = numero + 1
except tweepy.TweepError as e:
print(e.reason)
except StopIteration:
break
return (numeros_list,popularidad_list,numero)
def GraficarDatos(numeros_list,popularidad_list,numero):
axes = plt.gca()
axes.set_ylim([-1, 2])
plt.scatter(numeros_list, popularidad_list)
popularidadPromedio = (sum(popularidad_list))/(len(popularidad_list))
popularidadPromedio = "{0:.0f}%".format(popularidadPromedio * 100)
time = datetime.now().strftime("A : %H:%M\n El: %m-%d-%y")
plt.text(0, 1.25,
"Sentimiento promedio: " + str(popularidadPromedio) + "\n" + time,
fontsize=12,
bbox = dict(facecolor='none',
edgecolor='black',
boxstyle='square, pad = 1'))
plt.title("Sentimientos sobre " + palabra + " en twitter")
plt.xlabel("Numero de tweets")
plt.ylabel("Sentimiento")
plt.show()
numeros_list,popularidad_list,numero = ObtenerTweets(palabra,numero_de_Tweets,lenguaje)
GraficarDatos(numeros_list,popularidad_list,numero)
Al ejecutar el programa se tiene la siguiente gráfica.
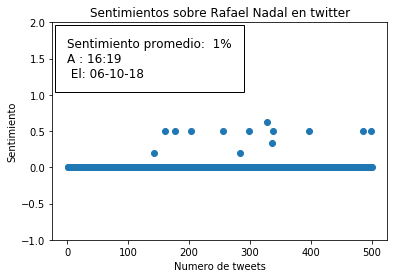
Para el caso de Nadal, tiene un valor promedio positivo, habrá casos donde el sentimiento sea de un valor negativo, pero para este caso, lo mejor es ampliar la cantidad de tweets a capturar para tener una mejor aproximación del sentimiento de la gente de lo que habla en twitter de Nadal.
Sí tienes algun pregunta u observación, puedes hacerlo en los comentarios del post.
¡Haz tu donativo!
Si te gustó el artículo puedes realizar un donativo con Bitcoin (BTC) usando la billetera digital de tu preferencia a la siguiente dirección: 197vyJ3KSCj287nLqhb7FSJpJUDayDoTMP
O Escaneando el código QR desde billetera:

Para el caso de paypal, tienes el botón del lado derecho de la página.

En este artículo la fuente de datos se usará la librería de Quandl directamente. La idea es obtener los precios de mercado de 3 Aerolineas (Delta con código DAL, Jet Blue con código JBLU y Southwest con código LUV). Se gráfica el historico de los precios de cierre, el volumen de ventas y movimientos promedios de estas tres aerolineas.
Continuando con los artículos sobre Pandas y Ciencia de Datos, en el artículo anterior se mostró como trabajar con Series de tiempo obteniendo datos desde Quandl.
Este artículo se basa en un artículo en inglés que se títula Visualizing Time Series Data of Stock Prices (en este artículo usan la librería pandas_datareader, pero está dando errores, así que se usará la librería Quandl).
El código del ejercicio se muestra a continuación:
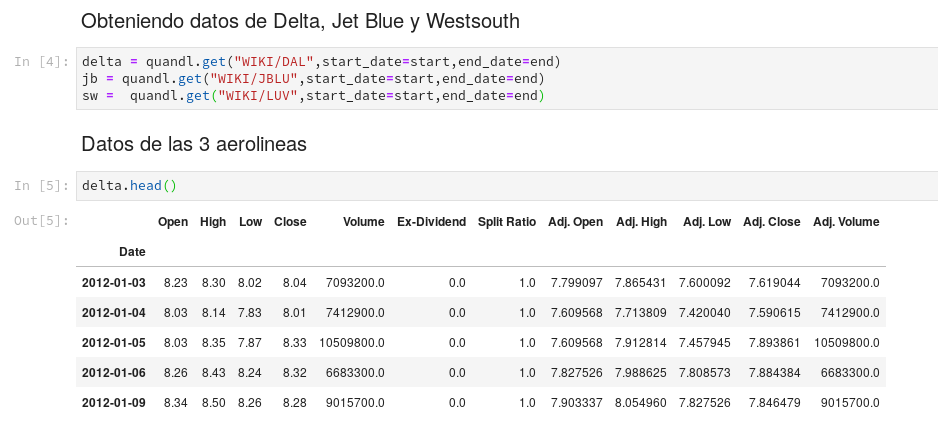
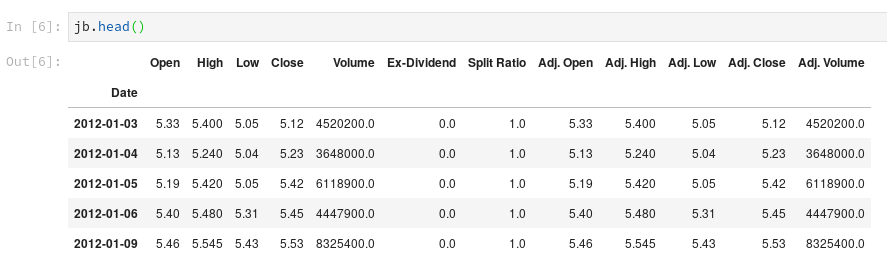
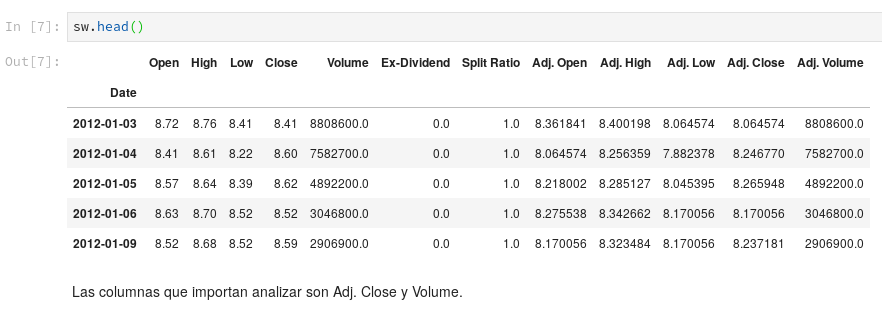
Visualizando
Se va a graficar el Ajuste de precio de cierre de las 3 aerolineas.


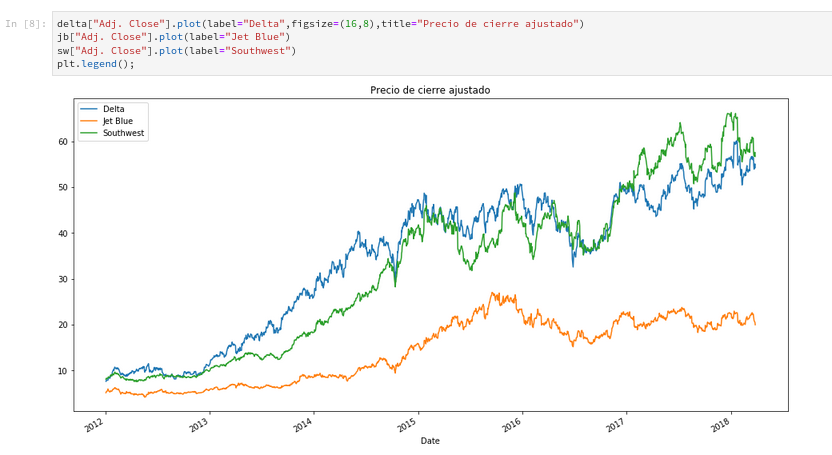
Graficar el Volumen (Volume)
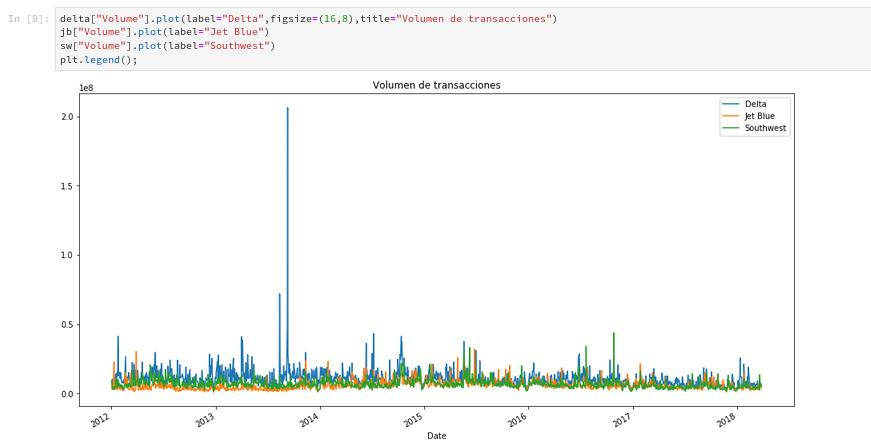
Se puede notar que la aerolinea Delta tiene un pico muy alto en algún momento del año 2013.
Para obtener la fecha se usa el método idxmax.

Los movimientos promedios se usan para detectar oportunidades de trading.
Este cálculo se toma de la media o promedio de los pasados precios (se llama movimientos promedio por que los datos están continuamente moviendose).
Dependiendo del tipo de inversor (alto riesgo vs bajo riesgo, corto término vs largo término), se pueden ajustar los movimientos promedio a 10 días, 20 días, 50 días, 200 días, 1 año, 5 años, etc.
Para este caso se calculará el movimiento promedio a 50 días y a 200 días.

Este cálculo se toma de la media o promedio de los pasados precios (se llama movimientos promedio por que los datos están continuamente moviendose).
Dependiendo del tipo de inversor (alto riesgo vs bajo riesgo, corto término vs largo término), se pueden ajustar los movimientos promedio a 10 días, 20 días, 50 días, 200 días, 1 año, 5 años, etc.
Para este caso se calculará el movimiento promedio a 50 días y a 200 días.
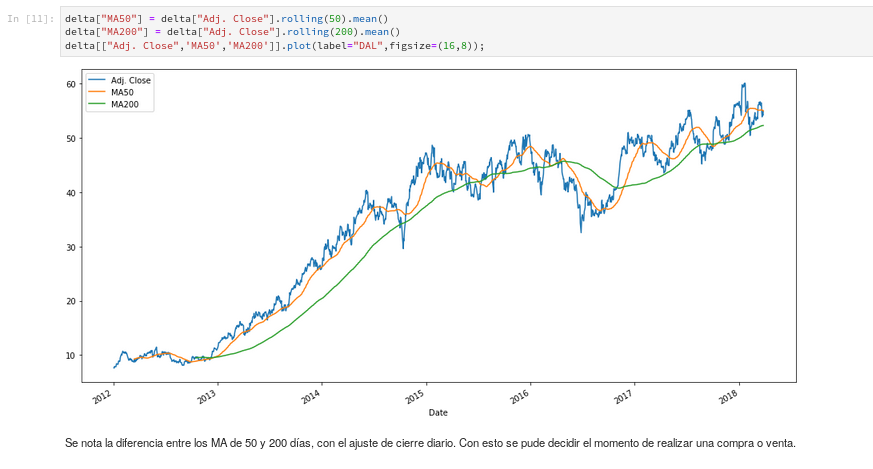
El raw del notebook lo pueden bajar del repositorio gitlab.
Si tienes alguna sugerencia o idea de como se puede aplicar este artículo, lo puedes dejar en los comentarios.
¡Haz tu donativo!
Si te gustó el artículo puedes realizar un donativo con Bitcoin (BTC) usando la billetera digital de tu preferencia a la siguiente dirección: 197vyJ3KSCj287nLqhb7FSJpJUDayDoTMP
O Escaneando el código QR desde billetera:
Para el caso de paypal, tienes el botón del lado derecho de la página.
![]()
June Update - Do you consent?
WhoTracksMe blog 06 06 2018

Refactoring
MonkeyUser 05 06 2018
Every team has a unique development style. Some teams implement localization and require translations. Some teams are more sensitive to database issues and require more careful handling of indexes and constraints. In this article we describe how we enforce our own development style using the Django check framework, the inspect and the ast modules from the Python standard library.
The Power of Recursive Macros in Vim
Jovica Ilic 03 06 2018
If for some crazy reason you’re not already a user of Vim, shutdown your computer and go think about your life choices. Joking aside, Vim is really a great editor. And if you didn’t know – Vim supports macros. Basics of macros in Vim Macros represent a simple concept which can be described as “record... Continue reading
The post The Power of Recursive Macros in Vim appeared first on Jovica Ilic.
Following is a tutorial on how to use the Mito ORM.
As usual, this is best read on the Common Lisp Cookbook. It will be updated there.
The Database section on the Awesome-cl list is a resource listing popular libraries to work with different kind of databases. We can group them roughly in four categories:
- wrappers to one database engine (cl-sqlite, postmodern, cl-redis,…),
- interfaces to several DB engines (clsql, sxql,…),
- persistent object databases (bknr.datastore (see chap. 21 of “Common Lisp Recipes”), ubiquitous,…),
- Object Relational Mappers (Mito),
and other DB-related tools (pgloader).
We’ll begin with an overview of Mito. If you must work with an existing DB, you might want to have a look at cl-dbi and clsql. If you don’t need a SQL database and want automatic persistence of Lisp objects, you also have a choice of libraries.
The Mito ORM and SxQL
Mito is in Quicklisp:
(ql:quickload :mito)
Overview
Mito is “an ORM for Common Lisp with migrations, relationships and PostgreSQL support”.
- it supports MySQL, PostgreSQL and SQLite3,
- when defining a model, it adds an
id(serial primary key),created_atandupdated_atfields by default like Ruby’s ActiveRecord or Django, - handles DB migrations for the supported backends,
- permits DB schema versioning,
- is tested under SBCL and CCL.
As an ORM, it allows to write class definitions, to specify relationships, and provides functions to query the database. For custom queries, it relies on SxQL, an SQL generator that provides the same interface for several backends.
Working with Mito generally involves these steps:
- connecting to the DB
- writing CLOS classes to define models
- running migrations to create or alter tables
- creating objects, saving same in the DB,
and iterating.
Connecting to a DB
Mito provides the function connect-toplevel to establish a
connection to RDBMs:
(mito:connect-toplevel :mysql :database-name "myapp" :username "fukamachi" :password "c0mon-1isp")
The driver type can be of :mysql, :sqlite3 and :postgres.
With sqlite you don’t need the username and password:
(connect-toplevel :sqlite3 :database-name "myapp")
As usual, you need to create the MySQL or Postgre database beforehand. Refer to their documentation.
Connecting sets mito:*connection* to the new connection and returns it.
Disconnect with disconnect-toplevel.
=> you might make good use of a wrapper function:
(defun connect ()
"Connect to the DB."
(connect-toplevel :sqlite3 :database-name "myapp"))
Models
Defining models
In Mito, you can define a class which corresponds to a database table
by specifying (:metaclass mito:dao-table-class):
(defclass user ()
((name :col-type (:varchar 64)
:initarg :name
:accessor user-name)
(email :col-type (or (:varchar 128) :null)
:initarg :email
:accessor user-email))
(:metaclass mito:dao-table-class))
Note that the class automatically adds some slots: a primary key named id
if there’s no primary keys, created_at and updated_at for
recording timestamps. To disable these behaviors, specify :auto-pk
nil or :record-timestamps nil to the defclass forms.
You can inspect the new class:
(mito.class:table-column-slots (find-class 'user))
;=> (#<MITO.DAO.COLUMN:DAO-TABLE-COLUMN-CLASS MITO.DAO.MIXIN::ID>
; #<MITO.DAO.COLUMN:DAO-TABLE-COLUMN-CLASS COMMON-LISP-USER::NAME>
; #<MITO.DAO.COLUMN:DAO-TABLE-COLUMN-CLASS COMMON-LISP-USER::EMAIL>
; #<MITO.DAO.COLUMN:DAO-TABLE-COLUMN-CLASS MITO.DAO.MIXIN::CREATED-AT>
; #<MITO.DAO.COLUMN:DAO-TABLE-COLUMN-CLASS MITO.DAO.MIXIN::UPDATED-AT>)
The class inherits mito:dao-class implicitly.
(find-class 'user)
;=> #<MITO.DAO.TABLE:DAO-TABLE-CLASS COMMON-LISP-USER::USER>
(c2mop:class-direct-superclasses *)
;=> (#<STANDARD-CLASS MITO.DAO.TABLE:DAO-CLASS>)
This may be useful when you define methods which can be applied for all table classes.
For more information on using the Common Lisp Object System, see the clos page.
Creating the tables
After defining the models, you must create the tables:
(mito:ensure-table-exists 'user)
So a helper function:
(defun ensure-tables ()
(mapcar #'mito:ensure-table-exists '(user foo bar)))
See Mito’s documentation for a couple more ways.
When you alter the model you’ll need to run a DB migration, see the next section.
Fields
Fields types
Field types are:
(:varchar <integer>) ,
:serial, :bigserial, :integer, :bigint, :unsigned,
:timestamp, :timestamptz,
:bytea,
Optional fields
Use (or <real type> :null):
(email :col-type (or (:varchar 128) :null)
:initarg :email
:accessor user-email))
Field constraints
:unique-keys can be used like so:
(defclass user ()
((name :col-type (:varchar 64)
:initarg :name
:accessor user-name)
(email :col-type (:varchar 128)
:initarg :email
:accessor user-email))
(:metaclass mito:dao-table-class)
(:unique-keys email))
We already saw :primary-key.
You can change the table name with :table-name.
Relationships
You can define a relationship by specifying a foreign class with :col-type:
(defclass tweet ()
((status :col-type :text
:initarg :status
:accessor tweet-status)
;; This slot refers to USER class
(user :col-type user
:initarg :user
:accessor tweet-user))
(:metaclass mito:dao-table-class))
(table-definition (find-class 'tweet))
;=> (#<SXQL-STATEMENT: CREATE TABLE tweet (
; id BIGSERIAL NOT NULL PRIMARY KEY,
; status TEXT NOT NULL,
; user_id BIGINT NOT NULL,
; created_at TIMESTAMP,
; updated_at TIMESTAMP
; )>)
Now you can create or retrieve a TWEET by a USER object, not a USER-ID.
(defvar *user* (mito:create-dao 'user :name "Eitaro Fukamachi"))
(mito:create-dao 'tweet :user *user*)
(mito:find-dao 'tweet :user *user*)
Mito doesn’t add foreign key constraints for refering tables.
One-to-one
A one-to-one relationship is simply represented with a simple foreign
key on a slot (as :col-type user in the tweet class). Besides, we
can add a unicity constraint, as with (:unique-keys email).
One-to-many, many-to-one
The tweet example above shows a one-to-many relationship between a user and his tweets: a user can write many tweets, and a tweet belongs to only one user.
The relationship is defined with a foreign key on the “many” side
linking back to the “one” side. Here the tweet class defines a
user foreign key, so a tweet can only have one user. You didn’t need
to edit the user class.
A many-to-one relationship is actually the contraty of a one-to-many. You have to put the foreign key on the approriate side.
Many-to-many
A many-to-many relationship needs an intermediate table, which will be the “many” side for the two tables it is the intermediary of.
And, thanks to the join table, we can store more information about the relationship.
Let’s define a book class:
(defclass book ()
((title
:col-type (:varchar 128)
:initarg :title
:accessor title)
(ean
:col-type (or (:varchar 128) :null)
:initarg :ean
:accessor ean))
(:metaclass mito:dao-table-class))
A user can have many books, and a book (as the title, not the physical copy) is likely to be in many people’s library. Here’s the intermediate class:
(defclass user-books ()
((user
:col-type user
:initarg :user)
(book
:col-type book
:initarg :book))
(:metaclass mito:dao-table-class))
Each time we want to add a book to a user’s collection (say in
a add-book function), we create a new user-books object.
But someone may very well own many copies of one book. This is an information we can store in the join table:
(defclass user-books ()
((user
:col-type user
:initarg :user)
(book
:col-type book
:initarg :book)
;; Set the quantity, 1 by default:
(quantity
:col-type :integer
:initarg :quantity
:initform 1
:accessor quantity))
(:metaclass mito:dao-table-class))
Inheritance and mixin
A subclass of DAO-CLASS is allowed to be inherited. This may be useful when you need classes which have similar columns:
(defclass user ()
((name :col-type (:varchar 64)
:initarg :name
:accessor user-name)
(email :col-type (:varchar 128)
:initarg :email
:accessor user-email))
(:metaclass mito:dao-table-class)
(:unique-keys email))
(defclass temporary-user (user)
((registered-at :col-type :timestamp
:initarg :registered-at
:accessor temporary-user-registered-at))
(:metaclass mito:dao-table-class))
(mito:table-definition 'temporary-user)
;=> (#<SXQL-STATEMENT: CREATE TABLE temporary_user (
; id BIGSERIAL NOT NULL PRIMARY KEY,
; name VARCHAR(64) NOT NULL,
; email VARCHAR(128) NOT NULL,
; registered_at TIMESTAMP NOT NULL,
; created_at TIMESTAMP,
; updated_at TIMESTAMP,
; UNIQUE (email)
; )>)
If you need a ‘template’ for tables which doesn’t related to any
database tables, you can use DAO-TABLE-MIXIN. Below the has-email
class will not create a table.
(defclass has-email ()
((email :col-type (:varchar 128)
:initarg :email
:accessor object-email))
(:metaclass mito:dao-table-mixin)
(:unique-keys email))
;=> #<MITO.DAO.MIXIN:DAO-TABLE-MIXIN COMMON-LISP-USER::HAS-EMAIL>
(defclass user (has-email)
((name :col-type (:varchar 64)
:initarg :name
:accessor user-name))
(:metaclass mito:dao-table-class))
;=> #<MITO.DAO.TABLE:DAO-TABLE-CLASS COMMON-LISP-USER::USER>
(mito:table-definition 'user)
;=> (#<SXQL-STATEMENT: CREATE TABLE user (
; id BIGSERIAL NOT NULL PRIMARY KEY,
; name VARCHAR(64) NOT NULL,
; email VARCHAR(128) NOT NULL,
; created_at TIMESTAMP,
; updated_at TIMESTAMP,
; UNIQUE (email)
; )>)
See more examples of use in mito-auth.
Troubleshooting
“Cannot CHANGE-CLASS objects into CLASS metaobjects.”
If you get the following error message:
Cannot CHANGE-CLASS objects into CLASS metaobjects.
[Condition of type SB-PCL::METAOBJECT-INITIALIZATION-VIOLATION]
See also:
The Art of the Metaobject Protocol, CLASS [:initialization]
it is certainly because you first wrote a class definition and then added the Mito metaclass and tried to evaluate the class definition again.
If this happens, you must remove the class definition from the current package:
(setf (find-class 'foo) nil)
or, with the Slime inspector, click on the class and find the “remove” button.
More info here.
Migrations
First create the tables if needed:
(ensure-table-exists 'user)
then alter the tables, if needed:
(mito:migrate-table 'user)
You can check the SQL generated code with migration-expressions
'class. For example, we create the user table:
(ensure-table-exists 'user)
;-> ;; CREATE TABLE IF NOT EXISTS "user" (
; "id" BIGSERIAL NOT NULL PRIMARY KEY,
; "name" VARCHAR(64) NOT NULL,
; "email" VARCHAR(128),
; "created_at" TIMESTAMP,
; "updated_at" TIMESTAMP
; ) () [0 rows] | MITO.DAO:ENSURE-TABLE-EXISTS
There are no changes from the previous user definition:
(mito:migration-expressions 'user)
;=> NIL
Now let’s add a unique email field:
(defclass user ()
((name :col-type (:varchar 64)
:initarg :name
:accessor user-name)
(email :col-type (:varchar 128)
:initarg :email
:accessor user-email))
(:metaclass mito:dao-table-class)
(:unique-keys email))
The migration will run the following code:
(mito:migration-expressions 'user)
;=> (#<SXQL-STATEMENT: ALTER TABLE user ALTER COLUMN email TYPE character varying(128), ALTER COLUMN email SET NOT NULL>
; #<SXQL-STATEMENT: CREATE UNIQUE INDEX unique_user_email ON user (email)>)
so let’s apply it:
(mito:migrate-table 'user)
;-> ;; ALTER TABLE "user" ALTER COLUMN "email" TYPE character varying(128), ALTER COLUMN "email" SET NOT NULL () [0 rows] | MITO.MIGRATION.TABLE:MIGRATE-TABLE
; ;; CREATE UNIQUE INDEX "unique_user_email" ON "user" ("email") () [0 rows] | MITO.MIGRATION.TABLE:MIGRATE-TABLE
;-> (#<SXQL-STATEMENT: ALTER TABLE user ALTER COLUMN email TYPE character varying(128), ALTER COLUMN email SET NOT NULL>
; #<SXQL-STATEMENT: CREATE UNIQUE INDEX unique_user_email ON user (email)>)
Queries
Creating objects
We can create user objects with the regular make-instance:
(defvar me
(make-instance 'user :name "Eitaro Fukamachi" :email "e.arrows@gmail.com"))
;=> USER
To save it in DB, use insert-dao:
(mito:insert-dao me)
;-> ;; INSERT INTO `user` (`name`, `email`, `created_at`, `updated_at`) VALUES (?, ?, ?, ?) ("Eitaro Fukamachi", "e.arrows@gmail.com", "2016-02-04T19:55:16.365543Z", "2016-02-04T19:55:16.365543Z") [0 rows] | MITO.DAO:INSERT-DAO
;=> #<USER {10053C4453}>
Do the two steps above at once:
(mito:create-dao 'user :name "Eitaro Fukamachi" :email "e.arrows@gmail.com")
You should not export the user class and create objects outside of
its package (it is good practice anyway to keep all database-related
operations in say a models package and file). You should instead use
a helper function:
(defun make-user (&key name)
(make-instance 'user :name name))
Updating fields
(setf (slot-value me 'name) "nitro_idiot")
;=> "nitro_idiot"
and save it:
(mito:save-dao me)
Deleting
(mito:delete-dao me)
;-> ;; DELETE FROM `user` WHERE (`id` = ?) (1) [0 rows] | MITO.DAO:DELETE-DAO
;; or:
(mito:delete-by-values 'user :id 1)
;-> ;; DELETE FROM `user` WHERE (`id` = ?) (1) [0 rows] | MITO.DAO:DELETE-DAO
Get the primary key value
(mito:object-id me)
;=> 1
Count
(mito:count-dao 'user)
;=> 1
Find one
(mito:find-dao 'user :id 1)
;-> ;; SELECT * FROM `user` WHERE (`id` = ?) LIMIT 1 (1) [1 row] | MITO.DB:RETRIEVE-BY-SQL
;=> #<USER {10077C6073}>
So here’s a possibility of generic helpers to find an object by a given key:
(defgeneric find-user (key-name key-value)
(:documentation "Retrieves an user from the data base by one of the unique
keys."))
(defmethod find-user ((key-name (eql :id)) (key-value integer))
(mito:find-dao 'user key-value))
(defmethod find-user ((key-name (eql :name)) (key-value string))
(first (mito:select-dao 'user
(sxql:where (:= :name key-value)))))
Find all
Use select-dao.
Get a list of all users:
(mito:select-dao 'user)
;=> (#<USER {10077C6073}>)
Find by relationship
As seen above:
(mito:find-dao 'tweet :user *user*)
Custom queries
It is with select-dao that you can write more precise queries by
giving it SxQL statements.
Example:
(select-dao 'tweet
(where (:like :status "%Japan%")))
Clauses
See the SxQL documentation.
Examples:
(select-dao 'foo
(where (:and (:> :age 20) (:<= :age 65))))
(order-by :age (:desc :id))
(group-by :sex)
(having (:>= (:sum :hoge) 88))
(limit 0 10)
and joins, etc.
Operators
:not
:is-null, :not-null
:asc, :desc
:distinct
:=, :!=
:<, :>, :<= :>=
:a<, :a>
:as
:in, :not-in
:like
:and, :or
:+, :-, :* :/ :%
:raw
Triggers
Since insert-dao, update-dao and delete-dao are defined as generic
functions, you can define :before, :after or :around methods to those, like regular method combination.
(defmethod mito:insert-dao :before ((object user))
(format t "~&Adding ~S...~%" (user-name object)))
(mito:create-dao 'user :name "Eitaro Fukamachi" :email "e.arrows@gmail.com")
;-> Adding "Eitaro Fukamachi"...
; ;; INSERT INTO "user" ("name", "email", "created_at", "updated_at") VALUES (?, ?, ?, ?) ("Eitaro Fukamachi", "e.arrows@gmail.com", "2016-02-16 21:13:47", "2016-02-16 21:13:47") [0 rows] | MITO.DAO:INSERT-DAO
;=> #<USER {100835FB33}>
Inflation/Deflation
Inflation/Deflation is a function to convert values between Mito and RDBMS.
(defclass user-report ()
((title :col-type (:varchar 100)
:initarg :title
:accessor report-title)
(body :col-type :text
:initarg :body
:initform ""
:accessor report-body)
(reported-at :col-type :timestamp
:initarg :reported-at
:initform (local-time:now)
:accessor report-reported-at
:inflate #'local-time:universal-to-timestamp
:deflate #'local-time:timestamp-to-universal))
(:metaclass mito:dao-table-class))
Eager loading
One of the pains in the neck to use ORMs is the “N+1 query” problem.
;; BAD EXAMPLE
(use-package '(:mito :sxql))
(defvar *tweets-contain-japan*
(select-dao 'tweet
(where (:like :status "%Japan%"))))
;; Getting names of tweeted users.
(mapcar (lambda (tweet)
(user-name (tweet-user tweet)))
*tweets-contain-japan*)
This example sends a query to retrieve a user like “SELECT * FROM user WHERE id = ?” at each iteration.
To prevent this performance issue, add includes to the above query
which only sends a single WHERE IN query instead of N queries:
;; GOOD EXAMPLE with eager loading
(use-package '(:mito :sxql))
(defvar *tweets-contain-japan*
(select-dao 'tweet
(includes 'user)
(where (:like :status "%Japan%"))))
;-> ;; SELECT * FROM `tweet` WHERE (`status` LIKE ?) ("%Japan%") [3 row] | MITO.DB:RETRIEVE-BY-SQL
;-> ;; SELECT * FROM `user` WHERE (`id` IN (?, ?, ?)) (1, 3, 12) [3 row] | MITO.DB:RETRIEVE-BY-SQL
;=> (#<TWEET {1003513EC3}> #<TWEET {1007BABEF3}> #<TWEET {1007BB9D63}>)
;; No additional SQLs will be executed.
(tweet-user (first *))
;=> #<USER {100361E813}>
Schema versioning
$ ros install mito
$ mito
Usage: mito command [option...]
Commands:
generate-migrations
migrate
Options:
-t, --type DRIVER-TYPE DBI driver type (one of "mysql", "postgres" or "sqlite3")
-d, --database DATABASE-NAME Database name to use
-u, --username USERNAME Username for RDBMS
-p, --password PASSWORD Password for RDBMS
-s, --system SYSTEM ASDF system to load (several -s's allowed)
-D, --directory DIRECTORY Directory path to keep migration SQL files (default: "/Users/nitro_idiot/Programs/lib/mito/db/")
--dry-run List SQL expressions to migrate
Introspection
Mito provides some functions for introspection.
We can access the information of columns with the functions in
(mito.class.column:...):
table-column-[class, name, info, not-null-p,...]primary-key-p
and likewise for tables with (mito.class.table:...).
Given we get a list of slots of our class:
(ql:quickload "closer-mop")
(closer-mop:class-direct-slots (find-class 'user))
;; (#<MITO.DAO.COLUMN:DAO-TABLE-COLUMN-CLASS NAME>
;; #<MITO.DAO.COLUMN:DAO-TABLE-COLUMN-CLASS EMAIL>)
(defparameter user-slots *)
We can answer the following questions:
What is the type of this column ?
(mito.class.column:table-column-type (first user-slots))
;; (:VARCHAR 64)
Is this column nullable ?
(mito.class.column:table-column-not-null-p
(first user-slots))
;; T
(mito.class.column:table-column-not-null-p
(second user-slots))
;; NIL
Testing
We don’t want to test DB operations against the production one. We need to create a temporary DB before each test.
The macro below creates a temporary DB with a random name, creates the tables, runs the code and connects back to the original DB connection.
(defun random-string (length)
;; thanks 40ants/hacrm.
(let ((chars "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789"))
(coerce (loop repeat length
collect (aref chars (random (length chars))))
'string)))
(defmacro with-empty-db (&body body)
"Run `body` with a new temporary DB.
"
`(let* ((*random-state* (make-random-state t))
(prefix (concatenate 'string
(random-string 8)
"/"))
(connection mito:*connection*))
(uiop:with-temporary-file (:pathname name :prefix prefix)
(let* ((*db-name* name)
(*db* (connect)))
(ensure-tables-exist)
(migrate-all)
,@body
(setf mito:*connection* connection)
(connect)))))
Use it like this:
(prove:subtest "Creation in a temporary DB."
(with-empty-db
(let ((user (make-user :name "Cookbook")))
(save-user user)
(prove:is (name user)
"Cookbook"
"Test username in a temp DB."))))
;; Creation in a temporary DB
;; CREATE TABLE "user" (
;; id BIGSERIAL NOT NULL PRIMARY KEY,
;; name VARCHAR(64) NOT NULL,
;; email VARCHAR(128) NOT NULL,
;; created_at TIMESTAMP,
;; updated_at TIMESTAMP,
;; UNIQUE (email)
;; ) () [0 rows] | MITO.DB:EXECUTE-SQL
;; ✓ Test username in a temp DB.
See also
- mito-attachment
- mito-auth
- can a role-based access right control library
- an advanced “defmodel” macro.

Drive Test
MonkeyUser 29 05 2018
![]()
Tracker Tax
WhoTracksMe blog 28 05 2018
Dynamic Bézier Curves
Josh Comeau's blog 23 05 2018

Reopened
MonkeyUser 22 05 2018

Workaround
MonkeyUser 15 05 2018
![]()

Update (Mar 2019): I left the Fathom project.
As I was browsing my Twitter feed a few weeks ago, I came across the following tweet.
I had the same idea in late 2016 when I set out to built my own open-source website analytics alternative called Ana. It even got some traction back then.
Sadly, I got sidetracked and didn’t spend any more time on it. I still firmly believe in the idea though.
Knowing Paul as a super knowledgeable power-user of our Mailchimp for WordPress plugin, I tweeted him that I would love to help out, if at all possible. And it was!
Together, we are setting out to build website analytics that is simple, transparent and that respects your visitor’s privacy. We’re a few weeks in at this point and already running a beta version on our personal sites:

We’re developing Fathom out in the open; here’s Fathom on GitHub.
![]()
May Update - Countdown to GDPR
WhoTracksMe blog 10 05 2018

Code Reuse
MonkeyUser 08 05 2018
![]()
![]()

Fixing Unit Tests
MonkeyUser 02 05 2018

Going Global
MonkeyUser 24 04 2018
![]()
Continuando con los artículos sobre Inteligencia Artificial con Python.
La serie de artículos sobre Scikit-Learn han sido:
- Árbol de decisión hecho con Python (esté tendrá una segunda parte).
- Una red neuronal para aprendizaje supervisado usando scikit-learn.
- Funciones de activación para un perceptron.
Scikit-learn es una librería de Machine Learning para Python que soporta algoritmos de clasificación, regresión y clustering (wikipedia).
A continuación el notebook de jupyter:
Se creará una red neuronal para clasificación¶
Se usará la tabla de la verdad de XOR| x | y | Salida | |
|---|---|---|---|
| 0 | 0 | 0 | |
| 0 | 1 | 1 | |
| 1 | 0 | 1 | |
| 1 | 1 | 0 |
Para instalar scikit-learn se usa pip
pip3 install scikit-learnIn [4]:
##Se importa Numpy, MLPCCLassifier y KNeighborsClassifier
import numpy as np
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
In [5]:
#un Arreglo con la tabla de la verdad
# 0 0
# 0 1
# 1 0
# 1 1
xs = np.array([
0, 0,
0, 1,
1, 0,
1, 1
]).reshape(4, 2)
xs
Out[5]:
In [6]:
#Se muestra un arreglo con el resultado de hacer un XOR
ys = np.array([0, 1, 1, 0]).reshape(4,)
ys
Out[6]:
In [7]:
#Se crea el clasificador con la función de activación relu,con 10k iteraciones y tiene capaz ocultas 4,2
model = MLPClassifier(activation='tanh', max_iter=10000, hidden_layer_sizes=(4,2))
model
Out[7]:
In [8]:
#Se entrena la red neuronal pasando los arreglos de entrada y de salida
model.fit(xs, ys)
Out[8]:
In [9]:
print('prediccion:', model.predict(xs)) # salida 0110
In [10]:
print('Se espera:', np.array([0, 1, 1, 0]))
Otro ejercicio¶
| Entrada | Salida | |
|---|---|---|
| 001 | 0 | |
| 111 | 1 | |
| 101 | 1 | |
| 011 | 0 | |
| 100 | ? |
In [11]:
#Se importa de numpy array
from numpy import array
In [12]:
#Datos de entrada y de salida
datos_entrada = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]]).reshape(4, 3)
datos_salida = array([[0, 1, 1, 0]]).reshape(4, )
print(datos_entrada)
print ("-"*4)
print(datos_salida)
In [13]:
#En este caso se usa KNeighborsClassifier con 2 capaz
KNC = KNeighborsClassifier(n_neighbors= 2)
In [14]:
KNC.fit(datos_entrada,datos_salida)
Out[14]:
In [15]:
#Se predice el valor de 1,0,0 que da como resultado el mismo del artículo anterior.
print(KNC.predict([[1, 0,0]]))
In [16]:
#Se crea la red de nuevo pero ahora con PLPCCLassifier.
#Se crea el clasificador con la función de activación relu,con 10k iteraciones y tiene capaz ocultas 4,2
KNC = MLPClassifier(activation='tanh', max_iter=10000, hidden_layer_sizes=(4,2))
In [17]:
#Se entrena la red neuronal pasando los arreglos de entrada y de salida
KNC.fit(datos_entrada, datos_salida)
Out[17]:
In [18]:
#Se predice el valor de 1,0,0 que da como resultado el mismo del artículo anterior.
print(KNC.predict([[1, 0,0]]))
En el siguiente artículo se explicará otro ejemplo de Árbol de decisión usando scikit-learn.

Continuando con la serie de artículos sobre Pandas, en este artículo se muestra un proceso de extracción de datos web de la página que contiene información sobre los Estados de Venezuela de Wikipedia.
En los procesos anteriores de WebScraping se trabajaba practicamente a mano para indentificar las secciones del código html donde se encuentra la información útil, para el caso con Pandas este abstrae ese proceso.
A continuación se muestra una captura de pantalla de la página donde se quiere extraer la información:

La información que maneja la página son los estados con sus capitales, densidad poblacional, superficie, año de admisión, población, densidad, región y código ISO, la parte de la bandera ni del mapa no se muestra por que son imágenes y no se obtiene información útil de ellas.
A continuación todo el proceso de extracción de información de la página:
In [1]:
#Se importa pandas como pd
import pandas as pd
#Se lee los datos de wikipedia de los estados de venezuela, este devuelve una lista
estados= pd.read_html('https://es.wikipedia.org/wiki/Estados_de_Venezuela')
estados
Out[1]:
In [2]:
#Tipo de los estados
type(estados)
Out[2]:
In [3]:
#Tipo del primer elemento es un dataframe
type(estados[0])
Out[3]:
In [4]:
#Se listan del dataframe estados y capitales (elementos 1 y 2 del dataframe, y se recorre)
for i in range(1,26):
print(estados[2][1][i],estados[2][2][i])
In [5]:
#Ahora se crea una lista de diccionarios donde estará la información de cada estado
lista = []
for i in range(1,26):
lista.append({'Estado':estados[2][1][i],
'Capital': estados[2][2][i],
'codigo_iso': estados[2][3][i],
u'año_admision': estados[2][4][i],
'Poblacion': int(estados[2][5][i].split(".")[0].split("&")[-1]),
'Superficie': int(estados[2][6][i].split(".")[0].split("&")[-1]),
'Densidad': float(estados[2][7][i].split(",")[0].split("&")[-1]),
'Region': estados[2][8][i]
})
print(lista)
In [6]:
#Luego se crea un dataframe de la lista de diccionarios
df = pd.DataFrame(lista)
df
Out[6]:
In [7]:
#Si se quiere la información de Carabobo
mascara = df["Estado"] == "Carabobo"
df[mascara]
Out[7]:
In [8]:
#Otra forma de traer la información de Carabobo
df.iloc[6]
Out[8]:
In [9]:
#Para obtener la capital del estado
df.iloc[6]["Capital"]
Out[9]:
In [ ]:

everytime
MonkeyUser 17 04 2018
![]()

ICO
MonkeyUser 03 04 2018
What’s the point of art?
James Sinclair 01 04 2018
These months in Common Lisp: Q1 2018
Lisp journey 01 04 2018
Documentation
- Multidimensional arrays – the Common Lisp Cookbook
- Error and condition handling - the Common Lisp Cookbook
- Scripting: parsing command line arguments, building self-contained executables - the Common Lisp Cookbook
- ASDF Best Practices for 2018
- The Quicklisp local-projects mechanism
- How to distribute your software, not library, on Quicklisp ala python pip
- Common Lisp Brazil Community
- Awesome Lisp companies
- Announcing Quickref: a global documentation project for Common Lisp
Announcements
Projects
- Next web browser
- cl-repl, the Common Lisp ipython-like REPL
- Emotiq - blockchain in Common Lisp
- original reddit code from 2005. reddit.
- Temperance - logic programming (in development, reached v1.0.0)
- QR code 2005 encoder in Common Lisp
- print-licences: print licenses used by the given project and its dependencies (from sjl and dk_jackdaniel’s utils)
- Dufy, color library
- cl-flow - Data-flowish computation tree library for non-blocking concurrent Common Lisp.
- A docker container for CL development (also lisp-devel, CI on CL Cookbook)
- Quickfork - Quicklisp for teams
- Apache Thrift gains CL support
- JSCL playground
- MAGICL: Matrix Algebra proGrams In Common Lisp - Rigetti Computing
- Eturia has been open-sourced. An Open Computer for Education for teaching #Lisp written in #Javascript.
New releases:
- Quicklisp dist update for february 2018
- SBCL 1.4.5
- Portacle 1.1 release: SBCL update, ASDF fixes
- McCLIM 0.9.7 “Imbolc” release
- Peter Norvig’s Paradigms of Artificial Intelligence Programming - book as pdf and lisp code on Github
- cl-torrents 0.9 - readline interface and 1337x.to scraper
Discoveries:
- Folio2 - a collection of small libraries that provide support for functional idioms and data structures in Common Lisp; seamless integration of Series and FSet
- Lisp Interface to Federal Reserve Economic Data (FRED®)
- cl-bench benchmarking tool. reddit.
- Screamer - nondeterministic programming. Augment Common Lisp with practically all of the functionality of both Prolog and constraint logic programming languages (10 yo, Nikodemus)
- C-Mera, a Common Lisp source-to-source compiler to generate C/C++
- Regex, regular expression library in Common Lisp
- Cells, spreadsheet-like expressiveness for CLOS
Articles
- Starting a minimal Common Lisp project
- Emacs + ECL on Android
- Generic, consistent and dotted access of data structures with Access - lisp-journey (reddit)
- Quicklisp’s per-project build failures RSS feed
- Quicklisp implementation stats for 2017+
- cl-charms crash course
- LLVM’s garbage collection facilities and SBCL’s generational GC
- A bunch of utilities from (again) sjl: higher order functions, sequences, debugging, profiling.
- Sheets as ideal forms
- The return of cl-notebook
- Testing the SERIES package
Discussion
- Portacle hits #1 on Hackernews
- What do you plan to work on in 2018?
- Pros and cons of different ways to declare types in Common Lisp?
- Has anyone considered or started a project to write a CL implementation in WebAssembly?
- What do you recommend to work with SQL databases ? What’s your experience with Mito ? and sqlite only interface: cl-sqlite or cl-dbi ? and is there an ORM that generates classes from table definitions ?
- How to get asdf system dependencies
- Join the cl-telegraph-bot refactoring effort !
- GUI development done in Lisp (2013 comment)
- Strategies for Dealing with Large Amounts of Memory in Lisp? (SBCL)
- GUI embedded plots in Lisp ?
- Is there any non-lisp that copies Common Lisp’s condition system?
Common Lisp VS …
- As a newbie, what I will miss if I choose Racket over Common Lisp? Or if I happen to learn both at somepoint in future, choosing Racket/Common Lisp now would make sense?
- What can other languages do that Lisp can’t ?
Screencasts
- Pushing Pixels with Lisp
- Lisp Treehouse
- Common Lisp study group 01-30-2018 (video)
- Little bits of Lisp
Jobs
- Research Scientist Interactive Theorem Proving (using PVS, a Common Lisp application)
- Lisp Engineer, Mind.ai
- lisp-based domain specific language, compiler design
- Seeking co-founder for Lisp game studio
If we missed anything: https://gitlab.com/lisp-journey/lisp-journey.gitlab.io
End of Year Review 2017-18
Blogs on Tom Spencer 31 03 2018
End of Year Review 2017-18
Blogs on Tom Spencer 31 03 2018

Sprint Break
MonkeyUser 27 03 2018
Migrating to Hugo
Blogs on Tom Spencer 23 03 2018
Migrating to Hugo
Blogs on Tom Spencer 23 03 2018
![]()

Compiler
MonkeyUser 20 03 2018

La internacionalización de programas permite que estos puedan ser entendidos por personas que hablan idiomas diferentes.
En este artículo enseño cómo internacionalizar un programa escrito en Python 3. Para este propósito se suele utilizar el módulo gettext, que esta incluido en Python.
Antes de nada, debemos tener un programa para poder traducirlo. Vamos a
traducir el siguiente programa llamado saluda.py:
#!/usr/bin/env python3
nombre = input('¿Cómo te llamas? ')
print('Hola, {}.'.format(nombre))
El programa es muy sencillo. Pregunta al usuario su nombre y le saluda por su nombre o, mejor dicho, le vuelve a repetir lo que el usuario ha escrito.
Para internacionalizar el programa anterior vamos a importar el módulo
gettext y a ejecutar la función install de gettext. Después, debemos
rodear el texto que queramos traducir con _(), es decir, si queremos
traducir 'texto' escribiremos
_('texto').
#!/usr/bin/env python3
import gettext
gettext.install('saluda', 'locale')
nombre = input(_('¿Cómo te llamas? '))
print(_('Hola, {}.').format(nombre))
Ahora creamos el directorio locale, donde guardaremos las traducciones:
mkdir locale
Después debemos ejecutar pygettext, que viene instalado con Python. Quizás debéis ejecutar pygettext3 para indicar que queréis trabajar con Python 3:
pygettext -d saluda -p locale saluda.py
Yo lo hice así desde la terminal:
Ahora tenemos el archivo saluda.pot en el directorio locale. Para
trabajar con archivos de traducción es recomendable usar un editor
preparado para dicha tarea, porque hacerlo a mano es muy tedioso.
Podemos usar el editor Poedit o cualquier otro editor diseñado para
traducir.
Si vamos a utilizar Poedit, seleccionamos Archivo>Nueva desde archivo
POT/PO y seleccionamos el archivo saluda.pot. A continuación,
debemos seleccionar el idioma al que queremos traducir, yo voy a elegir
el alemán.
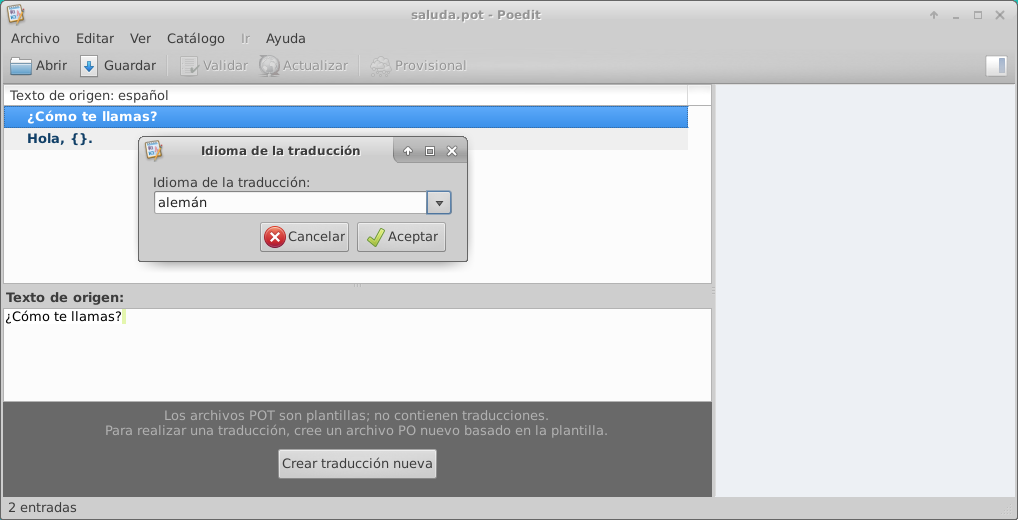
Cuando terminemos la traducción, debemos guardarla:
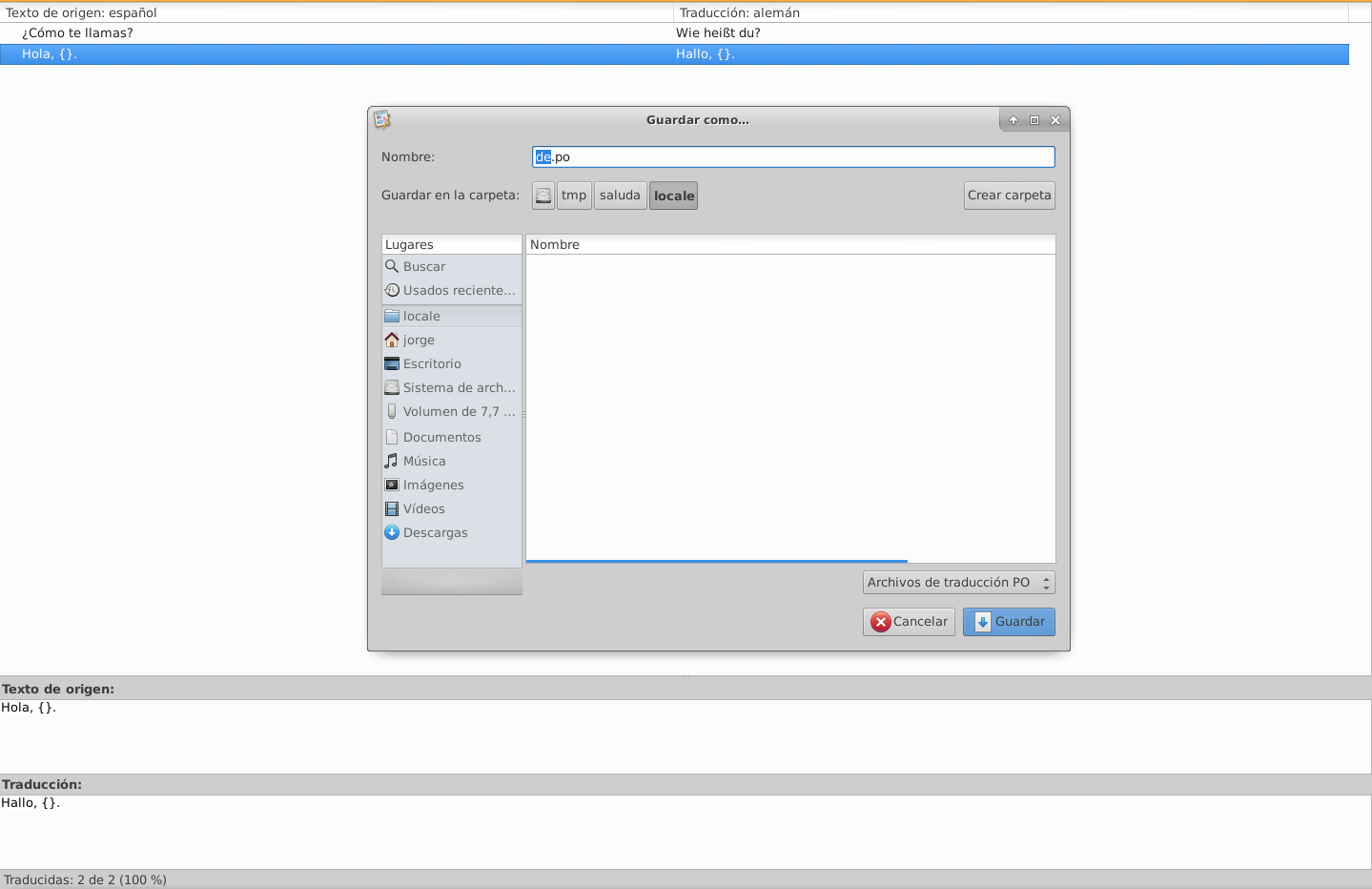
Se generarán dos archivos: de.po y
de.mo. El archivo de.po es legible por los humanos y el archivo
de.mo es legible por la máquina. El archivo de.mo debe guardarse
según la siguiente estructura de ficheros:
locale/de/LC_MESSAGES/de.mo. Para que no tengamos que acordarnos de la
anterior estructura cada vez que creemos o actualicemos una traducción,
podemos ubicar el siguiente programa en el directorio locale y
ejecutarlo cada vez que actualicemos un archivo .po:
#!/usr/bin/env python3
# Copyright (C) 2016 Julie Marchant <onpon4@riseup.net>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import os
import subprocess
if __name__ == "__main__":
for fname in os.listdir():
root, ext = os.path.splitext(fname)
if ext == ".po":
print("Generando {}...".format(fname))
d, root = os.path.split(root)
os.makedirs(os.path.join(d, root, "LC_MESSAGES"), exist_ok=True)
oname = os.path.join(d, root, "LC_MESSAGES", "saluda.mo")
subprocess.call(["msgfmt", "-o", oname, fname])
print("Terminado.")
Tras ejecutar el anterior programa, ya tendremos los archivos de
traducción donde corresponden. Al ejecutar saluda.py se utilizará el
idioma por defecto del sistema operativo que lo ejecute. Es decir, si
estamos utilizando el alemán como el idioma predeterminado del sistema
operativo, el programa se ejecutará en alemán. Podemos comprobar si
funciona para este idioma cambiando la variable de entorno LANGUAGE en
el caso de que estemos trabajando con GNU/Linux. Se puede probar así:
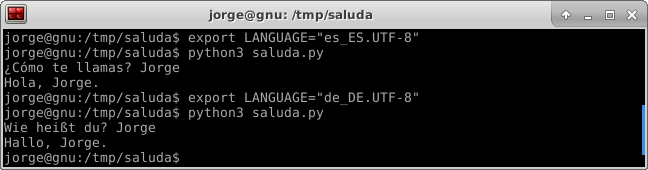

State of Clojure 2018 Results
Clojure News 19 03 2018
Welcome to the annual State of Clojure 2018 survey results! Thanks so much for taking the time to check in and provide your feedback. We are very fortunate to have data for some of these questions going all the way back to 2010, giving us a long view on how the data is trending. This year, we had 2325 respondents, about the same as last year.
Rapid Uptake of Clojure 1.9
With the release of Clojure 1.9 in December, we expected to see a shift in version usage, and we did. 72% of developers are already using it with about 60% still using Clojure 1.8 as well. Only a small (6%) number of developers are still using versions 1.7 or older.
We also keep an eye on JDK usage. Uptake of Java 1.9, released last year, has been a bit slower with only 29% adopting Java 1.9 so far and 88% of developers using Java 1.8. Only 6% of developers are using Java 1.7 and less than 1% are still using Java 1.6.
In the editor/IDE world we saw some consolidation this year with both Emacs (50%) and IntelliJ/Cursive (29%) making gains. All other editors saw decreases, although there is still a lot of interesting innovation happening around Atom and VS Code, which was not included but saw a lot of mentions in the comments (~5% of total respondents) - will definitely add next year!

In the ClojureScript world, Figwheel continues to dominate as a critical part of most ClojureScript developer’s REPL workflow (76%). Clojurists Together is a new community effort to support open source projects in the community and they have been funding work on Figwheel among other projects. Lumo was a new REPL option this year and made a strong showing of 12%.

In CLJS target environments, we saw an increase of +6% targeting Node (to 29%) and +4% targeting Lambda (to 13%) - both things to watch.
In the build tooling world, the entry of the clj tool is driving a lot of reevaluation and change right now. With so many things in flux, this area is sure to evolve significantly in 2018 and it will be interesting to see where we are in 2019. One important omission in the choices this year was shadow-cljs. There were a lot of mentions in the comments and it’s clearly an important tool for many to build and deploy - we’ll be sure to add it next year.
Interest Surging from JavaScript Programmers
When we look at which language communities people are coming from, those answers have been remarkably stable for years, but there was significant movement this year for JavaScript (which vaulted over both Python and Ruby). Clearly people are finding ClojureScript (and its strong resonance with React) as an interesting and viable alternative to JavaScript.

As to where Clojurists hang out, we saw significant increases in use of Reddit (+5%) and Slack (+4%) and some decreases in use of the Clojure mailing lists, IRC, and attendance at both in-person and on-line conferences. One new choice added this year was the ClojureVerse Discourse server - it seems to be a useful midpoint between Slack (high volume live chat) and mailing lists (low volume asynchronous discussion). This was a new option yet 17% of respondents reported using it.

Clojure and ClojureScript Used in Many Domains and Industries
One of the things we are always watching is the trend of people using Clojure for their day-to-day work. This year, we continued to see about 2/3 of respondents using Clojure for work (compare that to the very first survey back in 2010 when less than 1/3 were doing so). Web development has always been the most dominant domain - in 2010, 53% were doing web dev and these days fully 82% of Clojure devs are involved in some kind of web development (not surprising given how many Clojure devs are using both Clojure and ClojureScript together).

When looking at the industries using Clojure, we added a few choices this year based on prominent results in last year’s "Other" category - entertainment (3%), energy/utility (2%), automotive/manufacturing (2%). We also saw a noticeable increase (+3%) in Financial services. Perhaps due to the new choices, we saw small decreases in the largest and most generic categories, enterprise software and consumer software.

Interest in Hiring Stays Strong
There are several questions about how Clojure and ClojureScript should change or be prioritized for improvement. The results are largely similar to prior years, although the question format changed a little making it hard to directly compare every detail. The top result is clearly error messages though - while spec has started us down a road, that is still a work in progress which will continue this year. Many people have been using the Expound library for taking spec error output and making the data easier to read.
Hiring and staffing is always an interesting one to watch and that increased this year. We often see the seemingly contradictory dual complaints of companies that need more people and developers that have a hard time finding positions. To a large degree this is either a mismatch in the geographic distribution of jobs and people and/or a mismatch in needs and skill levels. It has been very encouraging to see so many large teams growing and hiring of late though.
The need for more docs and tutorials is also one that has gone up and down over the years and seems to be up again this year. While there are a wealth of resources for new Clojure developers now in every format, it is also sometimes difficult for people to find just the right resource for their experience level and need. There have been many good discussions lately about this and lots of active work in the community.
In general, there have been so many new tools, learning resources, companies, etc of late that it’s hard to keep up - 2018 is going to be a great year for Clojure!

Introducción
En el siguiente tutorial con Flask vamos a construir un API REST completa paso a paso en 18 sencillos temas. Aprenderemos a trabajar con Flask, a realizar un esquema sencillo, a conectar con una base de datos, realizar un CRUD, a conectar con una base de datos, crear una interfaz con VueJS, e integrarlo todo con comodidad. Todos temas son accesibles desde cada rama del repositorio.
El objetivo no es aburrirte con infinitas explicaciones, sino darte nociones reales para trabajar. De ese modo podrás experimentar revisando el código que te dejo en cada tema.
Indice
- Tema 1: Flask
- Tema 2: API Rest
- Tema 3: Base de datos
- Tema 4: Vue-cli
Objetivo final
Necesitaremos
- Portátil, y tuyo.
- Python 3.5>
- Internet superior a 56k
- Editor de texto enriquecido y con fundamento.
- httpie
- pipenv
¿Bibliotecas?
Microframework Web
- Flask.
Base de datos
- Flask-SQLAlchemy: ORM
- Flask-Migrate: Añade herramientas para gestionar nuestra base de datos.
- Flask-Script: Creación de comandos personalizados
- Faker: Generador de información falsa
API Rest
- Flask-restplus: Nos ayuda con las peticiones y autodocumentación
- Flask-JWT: Identificación básica.
- Flask-marshmallow: Convertirá los objetos ORM en JSON.
- Flask-CORS: Nos permitirá peticiones desde el exterior.
Herramientas de desarrollo
- httpie: Cliente de API Rest para pruebas.
- python-dotenv: Implementación de un archivo de configuración.
Instalación
Si estas en Debian/Ubuntu, antes necesitarás.
sudo apt-get install python3-venv¡Ahora sí!
git clone git@github.com:tanrax/workshop-flask-with-vuejs.git
cd workshop-flask-with-vuejs
python3 -m venv venv
source venv/bin/activate
pip3 install -r requirements.txt¿Empezamos?
¡Pista para programadores!
Para seguir el taller sin perderte puedes ir saltando a los 🎈checkpoints🎈 de la siguiente manera.
git checkout tema1-1

The Struggle
MonkeyUser 13 03 2018
Nine months with Vim
Posts on James Routley 11 03 2018
What if we want to capture standard (and/or error) output in order to ignore it or post-process it ? It’s very simple, a little search and we’re good:
(let ((*standard-output* (make-string-output-stream))
(*error-output* (make-string-output-stream)))
(apply function args) ;; anything
(setf standard-output (get-output-stream-string *standard-output*)))
(print-results standard-output))
and now in print-results we can print to standard output without
being intercepted (and in our case, we’ll highlight some user-defined
keywords).
Above, just don’t forget to get the output content with
(get-output-stream-string *standard-output*).
A thing to note is that if your app printed stuff on error output and standard output consecutively, now it will print all standard output as a single block.
(edit) Of course, with-output-to-string is simpler to capture one stream:
(setf standard-output (with-output-to-string (*standard-output*)
(apply function args)))
edit 2, thanks to redditers:
Don’t bind standard-output directly; bind the string stream to a
lexical, then bind *standard-output* to that:
(with-output-to-string (s)
(let ((*standard-output* s)) (write-string "abc")))
-> "abc"
Now, let’s bind both *standard-output* and *standard-error* to s:
(with-output-to-string (s)
(let ((*standard-output* s)
(*standard-error* s))
(write-string "abc")
(write-string "def" *standard-error*)))
-> "abcdef"
Eliminate s and just bind *standard-output* and then tie
*standard-error* to the same stream:
(with-output-to-string (*standard-output*)
(let ((*standard-error* *standard-output*))
(write-string "abc")
(write-string "def" *standard-error*)))
--> "abcdef"
The conclusion stays: it’s handy and easy :)

Focus
MonkeyUser 06 03 2018
The “dot” command in Vim
Jovica Ilic 02 03 2018
I believe you have already heard of the principle Don’t Repeat Yourself. In software engineering, this is a principle of software development where your focus is on reducing repetition of all kinds. As you’ll see throughout the book, Vim has many ways and commands to automate different kinds of tasks, so you don’t have to... Continue reading
The post The “dot” command in Vim appeared first on Jovica Ilic.
Pico-8 Game of life
Posts on James Routley 25 02 2018

Demo
MonkeyUser 19 02 2018
Your First Vim Session
Jovica Ilic 16 02 2018
The major barrier to any skill acquisition isn’t intellectual, but emotional. The same goes for learning Vim. That’s why, as one of the first chapters in my book Mastering Vim Quickly, I teach how to do something very cool. It’s very motivational, especially for someone who is new to the Vim world. You see you... Continue reading
The post Your First Vim Session appeared first on Jovica Ilic.

Testing during development
MonkeyUser 13 02 2018
I just updated my Quicklisp dist and suddenly couldn’t load some libraries any more. I got an error related to cl21 looking like the one below (I didn’t note the exact message sorry), even though the library was unrelate to cl21 (it was about osicat and cffi.grovel):
couldn’t find adjustable-vectors from CL21.core.arrays
If you skip through the restarts you’ll see mentions of a cache in
~/.cache/common-lisp/sbclxx-xx/quicklisp/…. It contains the compiled .fasl files.
I deleted this cache and I’m good to go.

Debugging
MonkeyUser 06 02 2018


![]()

Perspectives
MonkeyUser 30 01 2018
ORMs offer great utility for developers but abstracting access to the database has its costs. Developers who are willing to poke around the database and change some defaults often find that great improvements can be made.

10 Years of Instapaper
Instapaper 28 01 2018
On January 28, 2008, Marco Arment announced a new side project called Instapaper. Ten years and billions of articles later, we’re thrilled to be helping our readers learn, research and experience the Internet removed from the typical distractions.
First, we want to thank all of our users. Whether you’ve been around since the Marco days, joined us when betaworks took over the development or signed up after our acquisition by Pinterest, thank you! We wouldn’t be anywhere without you, and we look forward to incorporating your requests into our 2018 updates.
In Internet years a decade is a century. Instapaper predates the App Store, Google Chrome and the entire Android OS, so we wanted to take this opportunity to look back on some of our product and business milestones.
2008
At launch, Instapaper was more of a bookmarking tool than the full-featured reading product it is today. Users could save items to their Instapaper list and then go view the original website at their convenience.
In April, we introduced “Text mode” to reduce load times for slower phone connections. The parser behind that feature remains one of the most foundational and innovative components of Instapaper today.
Apple launched its App Store in July, and we were one of the first apps available. Instapaper got over 2,000 downloads on its first day (and more than 15,000 downloads before the end of the month), and we got our first of many App Store features.

By the end of the year, we also added the first proper offline mode, more fonts, the Archive section, “Give me something to read” (the precursor to the current Daily/Feature content), tilt-scroll and our first business model–a separate version of the app called Instapaper Pro which cost $9.99.
2009
With the core function of processing content for offline reading in place, 2009 was all about adding more ways to get content into and out of Instapaper with the launch of our API in January, Kindle support and Likes in March, folders and background updating in June and ePub and Kindle exports in November.
Instapaper Pro went on sale, and $4.99 became the new price for the paid version of the app.

2010
As more users saved more content, we introduced a bulk edit option for easier content management and paywall/multi-page support to improve saving overall. The app got a slight facelift for our iPad debut as well as the addition of pagination mode, themes, auto-dark mode, in-app dictionary, and length indicators for saves.
In October, Instapaper launched an optional subscription for $1 per-month to help support our operation and future feature development. Eventually, Instapaper’s full-text search feature would launch exclusively for subscribers.
To close out the year, Instapaper was added to Apple’s Hall of Fame and awarded a Macworld editors’ choice award.
2011
This was the year we got even more connected, with a full API launch, social sharing in the Instapaper 3.0 release, a brand new dictionary and zoomable images. It also was the year the FBI may have unintentionally confiscated–and later returned–one of our servers during an unrelated raid.
Additionally, the free version of our app was removed from the App Store, leaving only the $4.99 Instapaper Pro version.
2012
In 2012, our bookmarklet got a facelift, with a more prominent overlay, and confirmation and automatic multi-page save capability. The iOS app also got iBooks-style pagination mode, the option to manually select twilight sepia at any time and swipe gestures in Instapaper 4.2. In June, we released the first version of Instapaper for Android for $2.99 and dropped the price of the iOS app to $3.99. Lastly, we added support for the OpenDyslexie and FS Me fonts to improve accessibility.
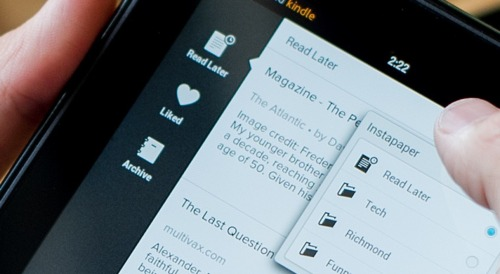
2013
Instapaper was acquired by betaworks in 2013. With a new team in place, we worked on backend infrastructure improvements, a site redesign, a Chrome extension launch and the development of InstaRank, which was our first attempt to gain insight into aggregate reading trends across the service.

The apps also got major updates with Instapaper 5.0 for iOS 7, including a modern user interface, video support, parsing improvements and localization for 13 languages in September; an Android app redesign in October; and an iPad redesign in November.
The year was rounded out with the launch of the InstaRank-based Instapaper Daily, a compilation of the most popular articles saved to Instapaper every day.
2014
With steady Instapaper Daily engagement, the articles from that feed became part of Instapaper’s Browse section and we began sending out a compilation of Daily articles as an email digest called Instapaper Weekly.

In May, Instapaper.com was fully redesigned. Highlights was introduced and has since become one of our most-used features. Also, after years of using Georgia (a standard serif font), we got our first “real logo” from Klim Type Foundry:
The App Store landscape had changed dramatically since 2008, and by September 2014 it made the most sense for us to transition Instapaper into a freemium product, marking the first time Instapaper was offered for free on the App Store since the removal of “Instapaper Free” in 2011.
In the same release, we added the iOS save extension, text-to-speech and public profiles. In the subsequent 6.1 update, Instapaper got its current slim save overlay, unread counts and handoff support for seamlessly picking up where you left off from your iPhone, iPad or the website.
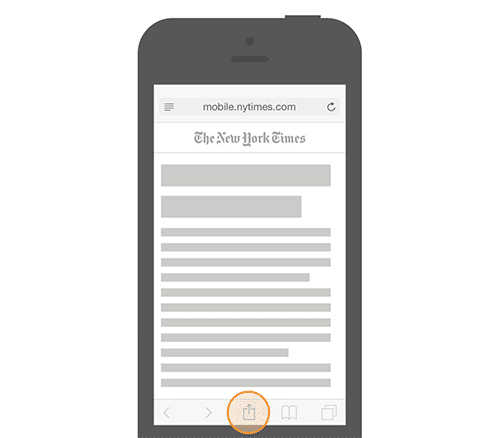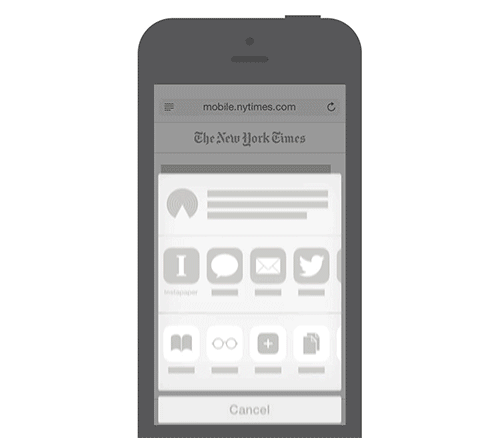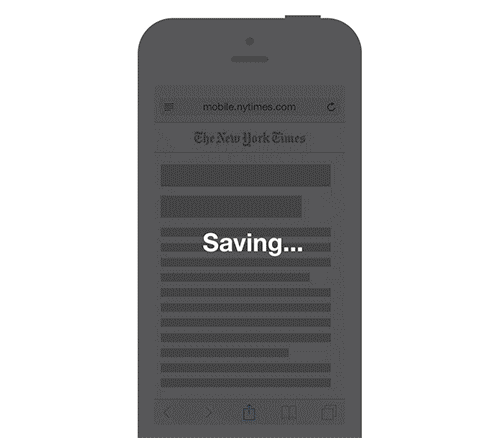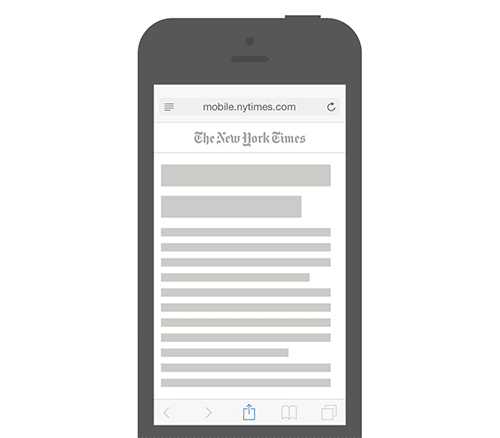
2015
Highlights were a great tool for pulling out key phrases in saves but a lot of users were asking to annotate what they were highlighting. That’s why we added Notes, the ability to add annotations to your Instapaper saves.
In addition to Notes, we implemented a speed reading feature and Instant Sync support in Instapaper 6.2 as well as an Apple Watch app for triggering text-to-speech. Instapaper 7 smoothed up all these developments and also included the addition of thumbnails, an iPad redesign, multi-task support and picture-in-picture for video playback.
2016
After adding so many new features, it was essential to bring legacy parts of Instapaper up to the same level. In January, we completely rewrote the parser and launched the first version of the current Instaparser. With Instaparser 1.0, we added enhanced video support, way better image handling, more aggressive stripping of non-article text and performance improvements that led to 10x faster saving.

Search was next on the update block. First, we overhauled search infrastructure entirely to improve speeds by 6x and allow us to add new features including sorting options, title searches, exact matches, site/author filtering, paged results and multi-language sort. With the new infrastructure in place, we then revamped mobile search to allow for local offline search, as well as searching for and opening items outside the device sync limit in Instapaper formatting.
Instapaper opened a few new business models in 2016, including the Instapaper Weekly Sponsorship and the Instaparser developer API, which allowed third-party developers to use our article parser.
In August, Instapaper joined Pinterest, where we continue to operate as a separate, standalone product. With added resources under Pinterest, we were able to make Instapaper Premium free for all users.
2017
Disaster struck in early 2017, as we experienced our first major, extended outage. While there was no data loss, Instapaper was offline for 20 hours, and it took almost five days to completely restore the service (quite the departure from our uptime of 99.93% the previous year).
On a more positive note, that year also included the launch of our Firefox extension, an iOS 11-optimized update with drag & drop support and an iPhone X-specific update that was featured on launch at Apple’s new App Store.
2018
This year, and beyond, we’ll continue the tradition of the past decade: offering a no-frills, high-quality service with total focus on the reader and the reading experience.
Whether you use text-to-speech in the car, speed reading to read faster, highlights for your research or just read the good-old fashioned way. We look forward to helping you read and learn.
We’d also like to reward anyone who made it all the way through this post, so if you send us an email to support@help.instapaper.com with your mailing address, we’ll send you some Instapaper stickers (U.S.-only, while stickers last).
If you have any requests for what you’d like to see in Instapaper or just want to say hello, please let us know via support@help.instapaper.com or @InstapaperHelp on Twitter.

In my quest to learn more about investing, I came across this post. The author writes “How One Simple Rule Can Beat Buy and Hold Investing” and then explains how following the trend is likely to beat a more traditional buy and hold investment approach.
Intrigued, I decided to dive into the data to see if I could replicate his results.
In this post I’ll walk you through the code and results for backtesting a 12-month simple moving average trend strategy on S&P 500 stock market data.
We’ll compare entering the market when it is trending up and moving to cash when it is trending down to simply staying invested at all times. The latter approach is known as buy & hold, or HODL depending on what corner of the internet you’re from.
Obtaining data on daily closing prices for the S&P 500
First things first, we need data.
Yahoo Finance provides us with historical data for the S&P 500 as far back as 1960. Let’s start out with parsing the CSV download into a DataFrame so we can get to work.
%matplotlib inline
import pandas as pd
sp500 = pd.read_csv('data/SP500.csv', sep=',', parse_dates=True, index_col='Date', usecols=['Adj Close', 'Date'])
sp500.head()
| Adj Close | |
|---|---|
| Date | |
| 1960-01-04 | 59.910000 |
| 1960-01-05 | 60.389999 |
| 1960-01-06 | 60.130001 |
| 1960-01-07 | 59.689999 |
| 1960-01-08 | 59.500000 |
Calculating the 12 month simple moving average
To test our trend strategy later on, we need the daily change (in %) and the 12-month simple moving average.
sp500['Pct Change'] = sp500['Adj Close'].pct_change()
sp500['SMA 365'] = sp500['Adj Close'].rolling(window=365).mean()
sp500.dropna().head()
| Adj Close | Pct Change | SMA 365 | |
|---|---|---|---|
| Date | |||
| 1961-06-14 | 65.980003 | 0.002736 | 58.350521 |
| 1961-06-15 | 65.690002 | -0.004395 | 58.366356 |
| 1961-06-16 | 65.180000 | -0.007764 | 58.379479 |
| 1961-06-19 | 64.580002 | -0.009205 | 58.391671 |
| 1961-06-20 | 65.150002 | 0.008826 | 58.406630 |
This leaves us with all the data we need to compare our two investment strategies.
Defining the trend strategy
To recap, we want to invest when the trend is moving up, ie when the stock price is higher than the average price over the last 12 months. When the stock is traded at a price lower than the moving average, we move to cash.
Let’s add a column to our dataframe indicating whether the criteria for our trend strategy is met.
sp500['Criteria'] = sp500['Adj Close'] >= sp500['SMA 365']
sp500['Criteria'].value_counts()
True 10577
False 4032
Name: Criteria, dtype: int64
This tells us that on our entire dataset, our criteria was met on 10577 of the market’s trading days.
Calculating our investment return
To calculate the return for our benchmark buy & hold strategy, all we need to do is calculate the cumulative product of the daily change in prices.
Let’s assume an initial investment of $100 and calculate the return if we were to hold for the entire time period.
sp500['Buy & Hold'] = 100 * (1 + sp500['Pct Change']).cumprod()
To calculate the return for our strategy, we should only add the compounded return for the days on which we are actually in the market.
On all other days the cash value of our investment remains unchanged.
sp500['Trend'] = 100 * (1 + ( sp500['Criteria'].shift(1) * sp500['Pct Change'] )).cumprod()
Let’s plot the values of both strategies in a single graph so that we can compare performances.
ax = sp500[['Trend', 'Buy & Hold']].plot(grid=True, kind='line', title="Trend (12 month SMA) vs. Buy & Hold", logy=True)
This shows us that a simple buy & hold investing approach actually outperformed our trend strategy when looking at the S&P 500 market data for 1960 to early 2018.
Seeking outperformance
Looking at the graph above, you can see that the trend did well during ongoing bear markets but sometimes failed to pick up on quick market recoveries.
Let’s cheat a little bit and look at “the lost decade”, which contains not just one but two relatively long bear markets!

This shows us that our trend strategy resulted in considerable outperformance during the last 2 decades, but only because of the two bear markets.
Conclusion: Trend following over Buy & Hold?
After playing with the data and looking at several time periods, I am still firmly in the “buy & hold” camp and think it is the way to go for most individual investors.
With some curve fitting, we can make the trend model outperform over some specific time periods like the 2000’s. Increase the holding period and this outperformance does not last though.
You can find the complete Jupyter Notebook for this post here.
From sjl’s utilities (thanks so much for the nice docstrings). The goal here is to read some code and learn about (hidden) gems.
The following snippets should be copy-pastable. They are the ones I find most interesting, I left some behind.
To reduce the dependency load, Alexandria or Quickutil functions can be imported one by one with Quickutil.
Table of Contents
Higher order functions
See also https://github.com/mikelevins/folio2 and How to do functional programming in CL.
(defun juxt (&rest functions)
"Return a function that will juxtapose the results of `functions`.
This is like Clojure's `juxt`. Given functions `(f0 f1 ... fn)`, this will
return a new function which, when called with some arguments, will return
`(list (f0 ...args...) (f1 ...args...) ... (fn ...args...))`.
Example:
(funcall (juxt #'list #'+ #'- #'*) 1 2)
=> ((1 2) 3 -1 2)
"
(lambda (&rest args)
(mapcar (alexandria:rcurry #'apply args) functions)))
(defun nullary (function &optional result)
"Return a new function that acts as a nullary-patched version of `function`.
The new function will return `result` when called with zero arguments, and
delegate to `function` otherwise.
Examples:
(max 1 10 2) ; => 10
(max) ; => invalid number of arguments
(funcall (nullary #'max)) ; => nil
(funcall (nullary #'max 0)) ; => 0
(funcall (nullary #'max 0) 1 10 2) ; => 10
(reduce #'max nil) ; => invalid number of arguments
(reduce (nullary #'max) nil) ; => nil
(reduce (nullary #'max :empty) nil) ; => :empty
(reduce (nullary #'max) '(1 10 2)) ; => 10
"
(lambda (&rest args)
(if (null args) result (apply function args))))
(defmacro gathering (&body body)
;; https://github.com/sjl/cl-losh/blob/master/losh.lisp#L515
"Run `body` to gather some things and return a fresh list of them.
`body` will be executed with the symbol `gather` bound to a function of one
argument. Once `body` has finished, a list of everything `gather` was called
on will be returned.
It's handy for pulling results out of code that executes procedurally and
doesn't return anything, like `maphash` or Alexandria's `map-permutations`.
The `gather` function can be passed to other functions, but should not be
retained once the `gathering` form has returned (it would be useless to do so
anyway).
Examples:
(gathering
(dotimes (i 5)
(gather i))
=>
(0 1 2 3 4)
(gathering
(mapc #'gather '(1 2 3))
(mapc #'gather '(a b)))
=>
(1 2 3 a b)
"
(with-gensyms (result)
`(let ((,result (make-queue)))
(flet ((gather (item)
(enqueue item ,result)))
(declare (dynamic-extent #'gather))
,@body)
(queue-contents ,result))))
Here we need the queue struct.
(defstruct (queue (:constructor make-queue))
(contents nil :type list)
(last nil :type list)
(size 0 :type fixnum))
;; real code is richer, with inline and inlinable function declarations.
(defun make-queue ()
"Allocate and return a fresh queue."
(make-queue%))
(defun queue-empty-p (queue)
"Return whether `queue` is empty."
(zerop (queue-size queue)))
(defun enqueue (item queue)
"Enqueue `item` in `queue`, returning the new size of the queue."
(let ((cell (cons item nil)))
(if (queue-empty-p queue)
(setf (queue-contents queue) cell)
(setf (cdr (queue-last queue)) cell))
(setf (queue-last queue) cell))
(incf (queue-size queue)))
(defun dequeue (queue)
"Dequeue an item from `queue` and return it."
(when (zerop (decf (queue-size queue)))
(setf (queue-last queue) nil))
(pop (queue-contents queue)))
(defun queue-append (queue list)
"Enqueue each element of `list` in `queue` and return the queue's final size."
(loop :for item :in list
:for size = (enqueue item queue)
:finally (return size)))
Sequences
(defun frequencies (sequence &key (test 'eql))
;; https://github.com/sjl/cl-losh/blob/master/losh.lisp#L1910
"Return a hash table containing the frequencies of the items in `sequence`.
Uses `test` for the `:test` of the hash table.
Example:
(frequencies '(foo foo bar))
=> {foo 2
bar 1}
"
(iterate
(with result = (make-hash-table :test test))
(for i :in-whatever sequence)
(incf (gethash i result 0))
(finally (return result))))
(defun proportions (sequence &key (test 'eql) (float t))
"Return a hash table containing the proportions of the items in `sequence`.
Uses `test` for the `:test` of the hash table.
If `float` is `t` the hash table values will be coerced to floats, otherwise
they will be left as rationals.
Example:
(proportions '(foo foo bar))
=> {foo 0.66666
bar 0.33333}
(proportions '(foo foo bar) :float nil)
=> {foo 2/3
bar 1/3}
"
(let* ((freqs (frequencies sequence :test test))
(total (reduce #'+ (hash-table-values freqs)
:initial-value (if float 1.0 1))))
(mutate-hash-values (lambda (v) (/ v total))
freqs)))
(defun group-by (function sequence &key (test #'eql) (key #'identity))
"Return a hash table of the elements of `sequence` grouped by `function`.
This function groups the elements of `sequence` into buckets. The bucket for
an element is determined by calling `function` on it.
The result is a hash table (with test `test`) whose keys are the bucket
identifiers and whose values are lists of the elements in each bucket. The
order of these lists is unspecified.
If `key` is given it will be called on each element before passing it to
`function` to produce the bucket identifier. This does not effect what is
stored in the lists.
Examples:
(defparameter *items* '((1 foo) (1 bar) (2 cats) (3 cats)))
(group-by #'first *items*)
; => { 1 ((1 foo) (1 bar))
; 2 ((2 cats))
; 3 ((3 cats)) }
(group-by #'second *items*)
; => { foo ((1 foo))
; bar ((1 bar))
; cats ((2 cats) (3 cats)) }
(group-by #'evenp *items* :key #'first)
; => { t ((2 cats))
; nil ((1 foo) (1 bar) (3 cats)) }
"
(iterate
(with result = (make-hash-table :test test))
(for i :in-whatever sequence)
(push i (gethash (funcall function (funcall key i)) result))
(finally (return result))))
(defun take-list (n list)
(iterate (declare (iterate:declare-variables))
(repeat n)
(for item :in list)
(collect item)))
(defun take-seq (n seq)
(subseq seq 0 (min n (length seq))))
(defmacro do-repeat (n &body body)
"Perform `body` `n` times."
`(dotimes (,(gensym) ,n)
,@body))
(defmacro do-range (ranges &body body)
"Perform `body` on the given `ranges`.
Each range in `ranges` should be of the form `(variable from below)`. During
iteration `body` will be executed with `variable` bound to successive values
in the range [`from`, `below`).
If multiple ranges are given they will be iterated in a nested fashion.
Example:
(do-range ((x 0 3)
(y 10 12))
(pr x y))
; =>
; 0 10
; 0 11
; 1 10
; 1 11
; 2 10
; 2 11
"
(if (null ranges)
`(progn ,@body)
(destructuring-bind (var from below) (first ranges)
`(loop :for ,var :from ,from :below ,below
:do (do-range ,(rest ranges) ,@body)))))
(defun enumerate (sequence &key (start 0) (step 1) key)
"Return an alist of `(n . element)` for each element of `sequence`.
`start` and `step` control the values generated for `n`, NOT which elements of
the sequence are enumerated.
Examples:
(enumerate '(a b c))
; => ((0 . A) (1 . B) (2 . C))
(enumerate '(a b c) :start 1)
; => ((1 . A) (2 . B) (3 . C))
(enumerate '(a b c) :key #'ensure-keyword)
; => ((0 . :A) (1 . :B) (2 . :C))
"
(iterate (for el :in-whatever sequence)
(for n :from start :by step)
(collect (cons n (if key
(funcall key el)
el)))))
uses iterate, on Quicklisp (see also Shinmera’s For).
The followingtake is taken from Serapeum (also available in CL21).
The original helpers (take-list, etc) are originally inlined for optimal performance with a custom “defun-inline”.
(defun take (n seq)
"Return a fresh sequence of the first `n` elements of `seq`.
The result will be of the same type as `seq`.
If `seq` is shorter than `n` a shorter result will be returned.
Example:
(take 2 '(a b c))
=> (a b)
(take 4 #(1))
=> #(1)
From Serapeum.
"
(check-type n array-index)
(ctypecase seq
(list (take-list n seq))
(sequence (take-seq n seq))))
(defun take-list (n list)
(iterate (declare (iterate:declare-variables))
(repeat n)
(for item :in list)
(collect item)))
(defun take-seq (n seq)
(subseq seq 0 (min n (length seq))))
(defun take-while-list (predicate list)
(iterate (for item :in list)
(while (funcall predicate item))
(collect item)))
(defun take-while-seq (predicate seq)
(subseq seq 0 (position-if-not predicate seq)))
(defun take-while (predicate seq)
"Take elements from `seq` as long as `predicate` remains true.
The result will be a fresh sequence of the same type as `seq`.
Example:
(take-while #'evenp '(2 4 5 6 7 8))
; => (2 4)
(take-while #'evenp #(1))
; => #()
"
(ctypecase seq
(list (take-while-list predicate seq))
(sequence (take-while-seq predicate seq))))
(defun drop-list (n list)
(copy-list (nthcdr n list)))
(defun drop-seq (n seq)
(subseq seq (min n (length seq))))
(defun drop (n seq)
"Return a fresh copy of the `seq` without the first `n` elements.
The result will be of the same type as `seq`.
If `seq` is shorter than `n` an empty sequence will be returned.
Example:
(drop 2 '(a b c))
=> (c)
(drop 4 #(1))
=> #()
From Serapeum.
"
(check-type n array-index)
(ctypecase seq
(list (drop-list n seq))
(sequence (drop-seq n seq))))
(defun drop-while-list (predicate list)
(iterate (for tail :on list)
(while (funcall predicate (first tail)))
(finally (return (copy-list tail)))))
(defun drop-while-seq (predicate seq)
(let ((start (position-if-not predicate seq)))
(if start
(subseq seq start)
(subseq seq 0 0))))
(defun drop-while (predicate seq)
"Drop elements from `seq` as long as `predicate` remains true.
The result will be a fresh sequence of the same type as `seq`.
Example:
(drop-while #'evenp '(2 4 5 6 7 8))
; => (5 6 7 8)
(drop-while #'evenp #(2))
; => #(2)
"
(ctypecase seq
(list (drop-while-list predicate seq))
(sequence (drop-while-seq predicate seq))))
(defun extrema (predicate sequence)
"Return the smallest and largest elements of `sequence` according to `predicate`.
`predicate` should be a strict ordering predicate (e.g. `<`).
Returns the smallest and largest elements in the sequence as two values,
respectively.
"
(iterate (with min = (elt sequence 0))
(with max = (elt sequence 0))
(for el :in-whatever sequence)
(when (funcall predicate el min) (setf min el))
(when (funcall predicate max el) (setf max el))
(finally (return (values min max)))))
(defun summation (sequence &key key)
"Return the sum of all elements of `sequence`.
If `key` is given, it will be called on each element to compute the addend.
This function's ugly name was chosen so it wouldn't clash with iterate's `sum`
symbol. Sorry.
Examples:
(sum #(1 2 3))
; => 6
(sum '(\"1\" \"2\" \"3\") :key #'parse-integer)
; => 6
(sum '(\"1\" \"2\" \"3\") :key #'length)
; => 3
"
(if key
(iterate (for n :in-whatever sequence)
(sum (funcall key n)))
(iterate (for n :in-whatever sequence)
(sum n))))
(defun product (sequence &key key)
;; https://github.com/sjl/cl-losh/blob/master/losh.lisp#L2181
"Return the product of all elements of `sequence`.
If `key` is given, it will be called on each element to compute the
multiplicand.
Examples:
(product #(1 2 3))
; => 6
(product '(\"1\" \"2\" \"3\") :key #'parse-integer)
; => 6
(product '(\"1\" \"2\" \"3\") :key #'length)
; => 1
"
(if key
(iterate (for n :in-whatever sequence)
(multiplying (funcall key n)))
(iterate (for n :in-whatever sequence)
(multiplying n))))
Debugging and logging
(defun pr (&rest args)
"Print `args` readably, separated by spaces and followed by a newline.
Returns the first argument, so you can just wrap it around a form without
interfering with the rest of the program.
This is what `print` should have been.
"
(format t "~{~S~^ ~}~%" args)
(finish-output)
(first args))
(defmacro prl (&rest args)
"Print `args` labeled and readably.
Each argument form will be printed, then evaluated and the result printed.
One final newline will be printed after everything.
Returns the last result.
Examples:
(let ((i 1)
(l (list 1 2 3)))
(prl i (second l)))
; =>
i 1
(second l) 2
"
`(prog1
(progn ,@(mapcar (lambda (arg) `(pr ',arg ,arg)) args))
(terpri)
(finish-output)))
(defmacro shut-up (&body body)
"Run `body` with stdout and stderr redirected to the void."
`(let ((*standard-output* (make-broadcast-stream))
(*error-output* (make-broadcast-stream)))
,@body))
(defmacro comment (&body body)
"Do nothing with a bunch of forms.
Handy for block-commenting multiple expressions.
"
(declare (ignore body))
nil)
Pretty-print a table.
Didn’t test.
See also https://github.com/vindarel/cl-ansi-term
(defun print-table (rows)
;; https://github.com/sjl/cl-losh/blob/master/losh.lisp#L2334
"Print `rows` as a nicely-formatted table.
Each row should have the same number of colums.
Columns will be justified properly to fit the longest item in each one.
Example:
(print-table '((1 :red something)
(2 :green more)))
=>
1 | RED | SOMETHING
2 | GREEN | MORE
"
(when rows
(iterate
(with column-sizes =
(reduce (alexandria:curry #'mapcar #'max)
(mapcar (alexandria:curry #'mapcar (compose #'length #'aesthetic-string))
rows))) ; lol
(for row :in rows)
(format t "~{~vA~^ | ~}~%" (weave column-sizes row))))
(values))
;; from Quickutil.
(defun ensure-function (function-designator)
"Returns the function designated by `function-designator`:
if `function-designator` is a function, it is returned, otherwise
it must be a function name and its `fdefinition` is returned."
(if (functionp function-designator)
function-designator
(fdefinition function-designator)))
;; from Quickutil.
(defun compose (function &rest more-functions)
"Returns a function composed of `function` and `more-functions` that applies its ;
arguments to to each in turn, starting from the rightmost of `more-functions`,
and then calling the next one with the primary value of the last."
(declare (optimize (speed 3) (safety 1) (debug 1)))
(reduce (lambda (f g)
(let ((f (ensure-function f))
(g (ensure-function g)))
(lambda (&rest arguments)
(declare (dynamic-extent arguments))
(funcall f (apply g arguments)))))
more-functions
:initial-value function))
(defun make-gensym-list (length &optional (x "G"))
"Returns a list of `length` gensyms, each generated as if with a call to `make-gensym`,
using the second (optional, defaulting to `\"G\"`) argument."
(let ((g (if (typep x '(integer 0)) x (string x))))
(loop repeat length
collect (gensym g))))
(define-compiler-macro compose (function &rest more-functions)
(labels ((compose-1 (funs)
(if (cdr funs)
`(funcall ,(car funs) ,(compose-1 (cdr funs)))
`(apply ,(car funs) arguments))))
(let* ((args (cons function more-functions))
(funs (make-gensym-list (length args) "COMPOSE")))
`(let ,(loop for f in funs for arg in args
collect `(,f (ensure-function ,arg)))
(declare (optimize (speed 3) (safety 1) (debug 1)))
(lambda (&rest arguments)
(declare (dynamic-extent arguments))
,(compose-1 funs))))))
;; from Quickutil.
(defun weave (&rest lists)
"Return a list whose elements alternate between each of the lists
`lists`. Weaving stops when any of the lists has been exhausted."
(apply #'mapcan #'list lists))
(defun aesthetic-string (thing)
"Return the string used to represent `thing` when printing aesthetically."
(format nil "~A" thing))
Pretty print a hash-table:
(defun print-hash-table (hash-table &optional (stream t))
"Print a pretty representation of `hash-table` to `stream.`
Respects `*print-length*` when printing the elements.
"
(let* ((keys (alexandria:hash-table-keys hash-table))
(vals (alexandria:hash-table-values hash-table))
(count (hash-table-count hash-table))
(key-width (-<> keys
(mapcar (alexandria:compose #'length #'prin1-to-string) <>)
(reduce #'max <> :initial-value 0)
(clamp 0 20 <>))))
(print-unreadable-object (hash-table stream :type t)
(princ
;; Something shits the bed and output gets jumbled (in SBCL at least) if
;; we try to print to `stream` directly in the format statement inside
;; `print-unreadable-object`, so instead we can just render to a string
;; and `princ` that.
(format nil ":test ~A :count ~D {~%~{~{ ~vs ~s~}~%~}}"
(hash-table-test hash-table)
count
(loop
:with limit = (or *print-length* 40)
:for key :in keys
:for val :in vals
:for i :from 0 :to limit
:collect
(if (= i limit)
(list key-width :too-many-items (list (- count i) :more))
(list key-width key val))))
stream)))
(terpri stream)
(values))
(defun pht (hash-table &optional (stream t))
"Synonym for `print-hash-table` for less typing at the REPL."
(print-hash-table hash-table stream))
(defun print-hash-table-concisely (hash-table &optional (stream t))
"Print a concise representation of `hash-table` to `stream.`
Should respect `*print-length*` when printing the elements.
"
(print-unreadable-object (hash-table stream :type t)
(prin1 (hash-table-test hash-table))
(write-char #\space stream)
(prin1 (hash-table-contents hash-table) stream)))
;; needed:
(defun clamp (from to value)
"Clamp `value` between `from` and `to`."
(let ((max (max from to))
(min (min from to)))
(cond
((> value max) max)
((< value min) min)
(t value))))
;; see
(defmacro -<> (expr &rest forms)
"Thread the given forms, with `<>` as a placeholder."
;; I am going to lose my fucking mind if I have to program lisp without
;; a threading macro, but I don't want to add another dep to this library, so
;; here we are.
`(let* ((<> ,expr)
,@(mapcar (lambda (form)
(if (symbolp form)
`(<> (,form <>))
`(<> ,form)))
forms))
<>))
For the -<> threading macro, see cl-arrows and arrow-macros.
Profiling (with SBCL)
#+sbcl
(defun dump-profile (filename)
(with-open-file (*standard-output* filename
:direction :output
:if-exists :supersede)
(sb-sprof:report :type :graph
:sort-by :cumulative-samples
:sort-order :ascending)
(sb-sprof:report :type :flat
:min-percent 0.5)))
#+sbcl
(defun start-profiling (&key call-count-packages (mode :cpu))
"Start profiling performance. SBCL only.
`call-count-packages` should be a list of package designators. Functions in
these packages will have their call counts recorded via
`sb-sprof::profile-call-counts`.
"
(sb-sprof::reset)
(-<> call-count-packages
(mapcar #'mkstr <>)
(mapcar #'string-upcase <>)
(mapc #'sb-sprof::profile-call-counts <>))
(sb-sprof::start-profiling :max-samples 50000
:mode mode
; :mode :time
:sample-interval 0.01
:threads :all))
#+sbcl
(defun stop-profiling (&optional (filename "lisp.prof"))
"Stop profiling performance and dump a report to `filename`. SBCL only."
(sb-sprof::stop-profiling)
(dump-profile filename))
#+sbcl
(defmacro profile (&body body)
"Profile `body` and dump the report to `lisp.prof`."
`(progn
(start-profiling)
(unwind-protect
(time (progn ,@body))
(stop-profiling))))
I’ll save here a reddit discussion, which I find interesting but that will be burried quickly down reddit’s history. The goal is to get all the dependencies of a system.
You’d better read the OP’s question and the discussion (where the OP is the experimented svetlyak40wt/40ants, at the moment doing a god’s work on Weblocks).
His solution is https://gist.github.com/svetlyak40wt/03bc68c820bb3e45bc7871870379c42e
(ql:quickload :fset)
(defun get-dependencies (system)
"Returns a set with all dependencies of a given system.
System should be loaded first."
(labels ((normalize (name)
(etypecase name
(string (string-downcase name))
(symbol (normalize (symbol-name name)))
(list
(let ((dep-type (first name))
(supported-dep-types (list :version :feature :require)))
(unless (member dep-type
supported-dep-types)
(error "This component \"~A\" should have first element from this list: ~A."
name
supported-dep-types))
(normalize
(case dep-type
(:version (second name))
(:feature (third name))
(:require (second name)))))))))
(let ((processed (fset:set))
(queue (fset:set (normalize system))))
(do ((current-name (fset:arb queue)
(fset:arb queue)))
((null current-name)
;; return result
processed)
;; Remove current name from the queue
(setf queue
(fset:less queue current-name))
;; And put it into the "processed" pool
(setf processed
(fset:with processed current-name))
;; And add it's dependencies which aren't processed or in the queue already
;; Sometimes system can't be found because itself depends on some feature,
;; for example, you can specify dependency as a list:
;; (:FEATURE :SBCL (:REQUIRE :SB-INTROSPECT))
;; and it will be loaded only on SBCL.
;; When we are collecting dependencies on another implementation,
;; we don't want to fail with an error because ASDF is unable to find
;; such dependencies
(let* ((system (ignore-errors
(asdf:find-system current-name)))
(deps (when system
(asdf:component-sideway-dependencies system))))
(dolist (dep deps)
(let ((normalized-dep (normalize dep)))
(unless (or (fset:lookup processed normalized-dep)
(fset:lookup queue normalized-dep))
(setf queue
(fset:with queue normalized-dep)))))))
(values processed))))
#|
DEPENDENCIES> (ql:quickload :clinch)
DEPENDENCIES> (get-dependencies :clinch)
#{
"cffi"
"sdl2"
"uiop"
"babel"
"swank"
"clinch"
"cl-glut"
"cl-json"
"cl-ppcre"
"rtg-math"
"cl-opengl"
"cl-plus-c"
"alexandria"
"cl-autowrap"
"glsl-symbols"
"defpackage-plus"
"trivial-garbage"
"trivial-timeout"
"bordeaux-threads"
"trivial-channels"
"trivial-features" }
|#
There’s also (ql-dist:dependency-tree "mgl") which has limitations
though, it’s only for Quicklisp projects and doesn’t work with
everything (see the thread).
That’s all folks !

Agile Conspiracy
MonkeyUser 23 01 2018
print-licenses is a little utility found in Steve Losh’s gigantic utilities and ported to a stand alone project.
Example usage:
(print-licenses 'fast-io)
=>
alexandria | Public Domain / 0-clause MIT
babel | MIT
cffi | MIT
cffi-grovel | MIT
cffi-toolchain | MIT
fast-io | NewBSD
static-vectors | MIT
trivial-features | MIT
trivial-gray-streams | MIT
uiop | Unspecified
It may be available on february, 2018 Quicklisp update (request).
One potential source of caution (feedback on reddit):
what many authors put as the license in their asd file is not the license file that is actually included in the source code.
Let’s read the source, there are many useful bits. The core of the job is:
(defun print-licenses (quicklisp-project-designator)
(print-table (sort (license-list quicklisp-project-designator)
#'string<
:key #'car)))
(defun license-list (quicklisp-project-designator)
(remove-duplicates
(mapcar (alexandria:rcurry #'coerce 'list)
(alexandria:flatten (license-tree quicklisp-project-designator)))
:key #'car :test #'string=))
(defun license-tree (quicklisp-project-designator)
(let ((sys (ql-dist:dependency-tree quicklisp-project-designator)))
(assert (not (null sys)) ()
"Cannot find Quicklisp project for designator ~S"
quicklisp-project-designator)
(shut-up
(ql:quickload quicklisp-project-designator))
(map-tree
(lambda (s)
(vector (slot-value s 'ql-dist:name)
(or (asdf:system-license
(asdf:find-system
(ql-dist:system-file-name s)))
"Unspecified")))
sys)))
and those are the remaining building blocks, with a useful
print-table function, and three of them taken from
Quickutil. See their website and how sjl does
to include them (and only them, to keep lightweight dependencies) in a
project without copy-pasting.
(defmacro shut-up (&body body)
"Run `body` with stdout and stderr redirected to the void."
`(let ((*standard-output* (make-broadcast-stream))
(*error-output* (make-broadcast-stream)))
,@body))
;; from Quickutil.
(defun map-tree (function tree)
"Map `function` to each of the leave of `tree`."
(check-type tree cons)
(labels ((rec (tree)
(cond
((null tree) nil)
((atom tree) (funcall function tree))
((consp tree)
(cons (rec (car tree))
(rec (cdr tree)))))))
(rec tree)))
;; from Quickutil
(defun aesthetic-string (thing)
"Return the string used to represent `thing` when printing aesthetically."
(format nil "~A" thing))
;; from Quickutil
(defun weave (&rest lists)
"Return a list whose elements alternate between each of the lists
`lists`. Weaving stops when any of the lists has been exhausted."
(apply #'mapcan #'list lists))
(defun print-table (rows)
"Print `rows` as a nicely-formatted table.
Each row should have the same number of colums.
Columns will be justified properly to fit the longest item in each one.
Example:
(print-table '((1 :red something)
(2 :green more)))
=>
1 | RED | SOMETHING
2 | GREEN | MORE
"
(when rows
(iterate
(with column-sizes =
(reduce (curry #'mapcar #'max)
(mapcar (curry #'mapcar (compose #'length #'aesthetic-string))
rows))) ; lol
(for row :in rows)
(format t "~{~vA~^ | ~}~%" (weave column-sizes row))))
(values))

Release day
MonkeyUser 16 01 2018
A common frustration for (impatient) beginners is to see different function names to access common data structures (alists, plists, hash-tables) and their inconsistencies (the order of arguments).
Now they are well documented in the… Common Lisp Coobook of course: https://lispcookbook.github.io/cl-cookbook/data-structures.html, but still;
and it is annoying to try things out with a data structure and refactor the code to use another one.
The library Access solves those problems, it’s always
(access my-var elt)
(if you’re into this, note that CL21 also does this with a generic and extensible getf).
edit: also rutils with generic-elt or ? in the rutilsx contrib package.
Access also solves another usecase.
Sometimes we deal with nested data structures (alist inside alist
inside alist, or mixed data structures, happens when working with an
API) and, as in other languages, we’d like a shortcut to access a
nested element. In Python, we can use addict to write
foo.one.2.three instead of foo['one'][2]['three'], with Access we
have two possibilities, see below.
Oh, and we can be confident it is a battle-tested library, since it is the one that powers Djula’s template variables interplolation (doc is here), where we can write
{{ var.foo }}
à la Django for the supported data structures, and Djula is in the top 100 of the most downloaded Quicklisp libraries (december 2017 stats).
Let’s install it:
(ql:quickload "access")
import its symbols in Slime:
(use-package :access)
Generic and consistent access accross alists, plists, hash-tables, CLOS slots
Let’s create our test variables first:
(defparameter my-alist '((:foo . "foo") (:bar . "bar")))
MY-ALIST
(defparameter my-plist (list :foo "foo" :bar "bar"))
MY-PLIST
(defparameter my-hashtable (make-hash-table))
MY-HASHTABLE
(setf (gethash :foo my-hashtable) "foo")
"foo"
(defclass obj-test ()
((foo :accessor foo :initarg :foo :initform :foo)
(bar :accessor bar :initarg :bar :initform :bar)))
;; #<STANDARD-CLASS OBJ-TEST>
(defparameter my-obj (make-instance 'obj-test))
;; MY-OBJ
Now, let’s access the :foo slot.
With alists:
(access my-alist :foo)
"foo"
T
instead of (cdr (assoc :foo my-alist)) (with :foo first argument) or alexandria’s (assoc-value my-alist :foo) (:foo second argument).
plists:
(access my-plist :foo)
"foo"
T
instead of (getf my-plist :foo) (unlike alists, with :foo as last argument).
hash-tables:
(access my-hashtable :foo)
"foo"
T
instead of (gethash :foo my-hashtable) (:foo first argument).
objects:
(access my-obj :foo) ;; <= accessor, not slot name
;; :FOO
;; T
instead of… it depends. Here we named the accessor foo, so we would have used simply (foo my-obj).
Also note that access returns two values, the value and a boolean, t
if the slot exists, nil otherwise.
And access is setfable:
(setf (access my-alist :foo) "oof")
with-access
Below, we can bind temporary variables inside with-access:
(with-access (foo bar (other-name plist))
my-obj
(format t "Got: ~a~a~a~&" foo bar other-name)
;; we can change variables
(setf other-name "hello plist")
(format t "other-name: ~a~&" other-name)
;; it changed the object too
(format t "object slot: ~a~&" (plist my-obj)))
Got: FOOBAR(FOO foo BAR bar)
other-name: hello plist
object slot: hello plist
NIL
Nested access
For this example we add a plist slot to our object, which copies our my-plist by default.
(defclass obj-test ()
((foo :accessor foo :initarg :foo :initform :foo)
(bar :accessor bar :initarg :bar :initform :bar)
(plist :accessor plist :initarg plist :initform (copy-list MY-PLIST))))
#<STANDARD-CLASS OBJ-TEST>
(as being a CLOS object, my-obj is automatically updated with the new slot).
We can access the nested plist element :foo inside the object in one go with accesses (plurial):
(accesses MY-OBJ 'plist :foo)
;; "foo"
instead of (getf (plist my-obj) :foo).
Dotted access
with-dot or #D
We can rewrite the previous examples with a dot:
(with-dot ()
my-alist.foo)
"foo"
or again
(with-dot ()
my-obj.foo)
"hello plist"
but even shorter, with the #D reader macro that we enable with
(enable-dot-syntax)
(also works in Slime/Sly, for what I am not sure if I enabled a special feature)
#Dmy-alist.foo
"foo"
and so, a nested dotted access through an object and a plist:
;; back to initial case
(setf my-obj (make-instance 'obj-test))
;; #<OBJ-TEST {1005AA3B13}>
#Dmy-obj.plist.foo
;; "foo"
It will return nil instead of an error if someone in the middle
doesn’t have the requested field.
Usage will tell how it is useful, and I hope it will be to fellow newcomers.
Logging errors is an important aspect of writing real-world applications. When something goes wrong at runtime it's very helpful to have a log detailing what went wrong in order to fix the problem. This is a straightforward process when we're working on the backend code. We can catch the exception and log it along with the stack trace. However, we need to get a bit more creative in order to handle client-side errors.
In this post we'll take a look at propagating errors from a Reagent based app back to the server. A naive implementation might look something like the following. We'll write a function that accepts an event containing the error, then send the error message along with the stack trace to the server:
(defn report-error! [event]
(let [error (.-error event)
message (.-message error)
stacktrace (.-stack error)]
(ajax/POST "/error"
{:headers
{"x-csrf-token"
(.-value (js/document.getElementById "__anti-forgery-token"))}
:params
{:message message
:stacktrace stacktrace}})))
Next, we'll set the report-error! function as the global error event listener:
(defn init! []
(.addEventListener js/window "error" report-error!)
(reagent/render [home-page] (.getElementById js/document "app")))
The home-page function will render a button that will throw an error when it's clicked:
(defn home-page []
[:div>h2 "Error Test"
[:div>button
{:on-click #(throw (js/Error. "I'm an error"))}
"throw an error"]])
If we pop up the console in the browser we should see something like the following there:
Uncaught Error: I'm an error
at app.core.home_page (core.cljs:25)
at Object.ReactErrorUtils.invokeGuardedCallback (react-dom.inc.js:9073)
at executeDispatch (react-dom.inc.js:3031)
at Object.executeDispatchesInOrder (react-dom.inc.js:3054)
at executeDispatchesAndRelease (react-dom.inc.js:2456)
at executeDispatchesAndReleaseTopLevel (react-dom.inc.js:2467)
at Array.forEach (<anonymous>)
at forEachAccumulated (react-dom.inc.js:15515)
at Object.processEventQueue (react-dom.inc.js:2670)
at runEventQueueInBatch (react-dom.inc.js:9097)
This gives us the namespace and the line number in the ClojureScript source that caused the error. However, if we print the message that we received on the server it will look as follows:
Error: I'm an error
at app.core.home_page (http://localhost:3000/js/out/app/core.js:51:8)
at Object.ReactErrorUtils.invokeGuardedCallback (http://localhost:3000/js/out/cljsjs/react-dom/development/react-dom.inc.js:9073:16)
at executeDispatch (http://localhost:3000/js/out/cljsjs/react-dom/development/react-dom.inc.js:3031:21)
at Object.executeDispatchesInOrder (http://localhost:3000/js/out/cljsjs/react-dom/development/react-dom.inc.js:3054:5)
at executeDispatchesAndRelease (http://localhost:3000/js/out/cljsjs/react-dom/development/react-dom.inc.js:2456:22)
at executeDispatchesAndReleaseTopLevel (http://localhost:3000/js/out/cljsjs/react-dom/development/react-dom.inc.js:2467:10)
at Array.forEach (<anonymous>)
at forEachAccumulated (http://localhost:3000/js/out/cljsjs/react-dom/development/react-dom.inc.js:15515:9)
at Object.processEventQueue (http://localhost:3000/js/out/cljsjs/react-dom/development/react-dom.inc.js:2670:7)
at runEventQueueInBatch (http://localhost:3000/js/out/cljsjs/react-dom/development/react-dom.inc.js:9097:18)
The stack trace is there, but it's no longer source mapped. So we'll know what namespace caused the error, but not the line in question. In order to get a source mapped stack trace we'll have to use a library such as stacktrace.js. Unfortunately, we won't be able to use the new :npm-deps option in the ClojureScript compiler. This works as expected when :optimizations are set to :none, but fails to provide us with the source mapped stack trace in the :advanced mode.
Instead, we'll use the WebJars dependency along with the ring-webjars middleware:
:dependencies
[...
[ring-webjars "0.2.0"]
[org.webjars.bower/stacktrace-js "2.0.0"]]
The middleware uses the /assets/<webjar>/<asset path> pattern to load the resources packaged in WebJars dependencies. Here's how this would look for loading the stacktrace-js resource.
We'll require the middleware:
(ns app.handler
(:require
...
[ring.middleware.webjars :refer [wrap-webjars]]))
Wrap the Ring handler with it:
(defn -main []
(run-jetty
(-> handler
(wrap-webjars)
(wrap-defaults site-defaults))
{:port 3000 :join? false}))
The stacktrace.min.js file packaged in the org.webjars.bower/stacktrace-js dependency will be available as a resource at the following path /assets/stacktrace-js/dist/stacktrace.min.js:
(defroutes handler
(GET "/" []
(html5
[:head
[:meta {:charset "utf-8"}]
(anti-forgery-field)]
[:body
[:div#app]
(include-js "/assets/stacktrace-js/dist/stacktrace.min.js"
"/js/app.js")]))
(POST "/error" {:keys [body]}
(let [{:keys [message stacktrace]}
(-> body
(transit/reader :json)
(transit/read))]
(println "Client error:" message "\n" stacktrace))
"ok")
(resources "/")
(not-found "Not Found"))
Finally, the ClojureScript compiler configuration will look as follows:
{:output-dir "target/cljsbuild/public/js"
:output-to "target/cljsbuild/public/js/app.js"
:source-map "target/cljsbuild/public/js/app.js.map"
:optimizations :advanced
:infer-externs true
:closure-warnings {:externs-validation :off
:non-standard-jsdoc :off}}
We need to specify the name of the source map file when using the advanced optimization, tell the compiler to infer the externs, and optionally suppress the warnings.
The new version of the report-error! function will look similar to the original, except that we'll now be passing the error to the StackTrace.fromError function. This function returns a promise containing the source mapped stack trace that we'll be sending to the server:
(defn report-error! [event]
(let [error (.-error event)]
(-> (js/StackTrace.fromError error)
(.then
(fn [stacktrace]
(ajax/POST "/error"
{:headers
{"x-csrf-token"
(.-value (js/document.getElementById "__anti-forgery-token"))}
:params
{:message (.-message error)
:stacktrace (->> stacktrace
(mapv #(.toString %))
(string/join "\n "))}}))))))
This time around we should see the source mapped error on the server with all the information that we need:
I'm an error
Error()@http://localhost:3000/js/app/core.cljs:27:23
mountComponent()@http://localhost:3000/js/app.js:40:5631
focusDOMComponent()@http://localhost:3000/js/app.js:38:22373
focusDOMComponent()@http://localhost:3000/js/app.js:38:22588
focusDOMComponent()@http://localhost:3000/js/app.js:38:18970
focusDOMComponent()@http://localhost:3000/js/app.js:38:19096
didPutListener()@http://localhost:3000/js/app.js:41:12120
focusDOMComponent()@http://localhost:3000/js/app.js:38:20154
mountComponent()@http://localhost:3000/js/app.js:40:5880
We can see that the error occurred on line 27 of the app.core namespace which is indeed where the code that throws the exception resides. The full listing for the example is available on GitHub.
While the example in this post illustrates bare bones exception handling, we can do more interesting things in a real world application. For example, re-frame based application could send the entire state of the re-frame database at the time of the error to the server. This allows us to put the application in the exact state that caused the error when debugging the problem.
![]()
![]()
WhoTracks.me January Update
WhoTracksMe blog 07 01 2018
Git Deps for Clojure
Clojure News 05 01 2018
Clojure was designed to empower developers by enabling them to leverage existing libraries. When Clojure was first released, this manifest itself in strong interop support for Java. Eventually tooling (Leiningen et al) arose around procuring Java libs from the Maven ecosystem, and Clojure, its contribs, and the community also adopted the Maven approach to delivering libraries via artifacts hosted in well known repositories like Maven Central and Clojars.
There were many benefits to this, but, like most things in programming, there were attendant costs. Artifact based releases predate the widespread adoption of content-based addressing systems like Git. Without content-based addressing, they depend on conventions of release naming and weak notions like semantic versioning. They also reflect the nature of languages like Java and C that require a build step prior to execution. Most Clojure libraries do not.
The modern reality of Clojure development is that (mostly) we use Git, we use centralized Git repos like Github, Bitbucket et al, and code is executable. Producing and consuming artifacts creates a lot of unnecessary friction between creating code and using it. Let’s get rid of it when not needed!
Today we’re happy to announce the availability of git deps support in Clojure tools. It leverages the fact that tools.deps does not use the Maven dependency resolver but instead resolves dependencies on its own. This decouples dependency resolution and classpath creation from any single library publishing/procurement mechanism. Git repos become a source of libraries directly.
You can now specify git coordinates (in addition to mvn and local) in deps.edn:
{:deps
{org.clojure/data.csv {:git/url "https://github.com/clojure/data.csv.git"
:sha "e5beccad0bafdb8e78f19cba481d4ecef5fabf36"}}}The tools support (available as a library in tools.gitlibs) will:
-
securely log into the git repository host and clone the repo (if needed)
-
checkout and cache (per library+sha) the specified working tree (if needed)
-
resolve transitive deps and incorporate the cached directory into the classpath
Of course, not every commit is stable, so one can designate stable points using tags.
This greatly reduces the ceremony and tooling required to share and consume libraries, facilitates parallel development of sibling libraries, testing, speculative forks etc. and fosters a greater connection to source truth while preserving the secure centralized hosting, stable repeatability and caching one gets from e.g. Maven.
I am hopeful this git support will usher in a new level of agility for Clojure development. Many thanks to Alex Miller for his tireless efforts to convert these ideas into a working system.
For more information see:
-
Getting Started - to install or update the Clojure tools
-
Deps and CLI Guide - on how to use the Clojure tools
-
Deps and CLI Reference - complete reference info
-
Spec-ulation keynote - on growth versus breakage
Structures offer a way to store data in named slots. They support single inheritance.
Classes provided by the Common Lisp Object System (CLOS) are more flexible however structures may offer better performance (see for example the SBCL manual).
As usual, this is best read in the Common Lisp Cookbook.
Structures
Creation
defstruct
(defstruct person
id name age)
At creation slots are optional and default to nil.
To set a default value:
(defstruct person
id
(name "john doe")
age)
Also specify the type after the default value:
(defstruct person
id
(name "john doe" :type string)
age)
We create an instance with the generated constructor make- +
<structure-name>, so make-person:
(defparameter *me* (make-person))
*me*
#S(PERSON :ID NIL :NAME "john doe" :AGE NIL)
note that printed representations can be read back by the reader.
With a bad name type:
(defparameter *bad-name* (make-person :name 123))
Invalid initialization argument:
:NAME
in call for class #<STRUCTURE-CLASS PERSON>.
[Condition of type SB-PCL::INITARG-ERROR]
We can set the structure’s constructor so as to create the structure without using keyword arguments, which can be more convenient sometimes. We give it a name and the order of the arguments:
(defstruct (person (:constructor create-person (id name age)))
id
name
age)
Our new constructor is create-person:
(create-person 1 "me" 7)
#S(PERSON :ID 1 :NAME "me" :AGE 7)
However, the default make-person does not work any more:
(make-person :name "me")
;; debugger:
obsolete structure error for a structure of type PERSON
[Condition of type SB-PCL::OBSOLETE-STRUCTURE]
Slot access
We access the slots with accessors created by <name-of-the-struct>- + slot-name:
(person-name *me*)
;; "john doe"
we then also have person-age and person-id.
Setting
Slots are setf-able:
(setf (person-name *me*) "Cookbook author")
(person-name *me*)
;; "Cookbook author"
Predicate
(person-p *me*)
T
Single inheritance
With the :include <struct> argument:
(defstruct (female (:include person))
(gender "female" :type string))
(make-female :name "Lilie")
;; #S(FEMALE :ID NIL :NAME "Lilie" :AGE NIL :GENDER "female")
Limitations
After a change, instances are not updated.
If we try to add a slot (email below), we have the choice to lose
all instances, or to continue using the new definition of
person. But the effects of redefining a structure are undefined by
the standard, so it is best to re-compile and re-run the changed
code.
(defstruct person
id
(name "john doe" :type string)
age
email)
attempt to redefine the STRUCTURE-OBJECT class PERSON
incompatibly with the current definition
[Condition of type SIMPLE-ERROR]
Restarts:
0: [CONTINUE] Use the new definition of PERSON, invalidating already-loaded code and instances.
1: [RECKLESSLY-CONTINUE] Use the new definition of PERSON as if it were compatible, allowing old accessors to use new instances and allowing new accessors to use old instances.
2: [CLOBBER-IT] (deprecated synonym for RECKLESSLY-CONTINUE)
3: [RETRY] Retry SLIME REPL evaluation request.
4: [*ABORT] Return to SLIME's top level.
5: [ABORT] abort thread (#<THREAD "repl-thread" RUNNING {1002A0FFA3}>)
If we choose restart 0, to use the new definition, we lose access to *me*:
*me*
obsolete structure error for a structure of type PERSON
[Condition of type SB-PCL::OBSOLETE-STRUCTURE]
There is also very little introspection. Portable Common Lisp does not define ways of finding out defined super/sub-structures nor what slots a structure has.
The Common Lisp Object System (which came after into the language) doesn’t have such limitations. See the CLOS section.

Error and condition handling
Lisp journey 02 01 2018
Common Lisp has mechanisms for error and condition handling as found in other languages, and can do more.
What is a condition ?
Just like in languages that support exception handling (Java, C++, Python, etc.), a condition represents, for the most part, an “exceptional” situation. However, even more so that those languages, a condition in Common Lisp can represent a general situation where some branching in program logic needs to take place, not necessarily due to some error condition. Due to the highly interactive nature of Lisp development (the Lisp image in conjunction with the REPL), this makes perfect sense in a language like Lisp rather than say, a language like Java or even Python, which has a very primitive REPL. In most cases, however, we may not need (or even allow) the interactivity that this system offers us. Thankfully, the same system works just as well even in non-interactive mode.
Let’s dive into it step by step. More resources are given afterwards.
Now best read in the Common Lisp Cookbook.
Credit: our cl-torrents tutorial.
Note: you can contribute any fix or addition to the Cookbook or this page via git ;)
Table of Contents
- Ignore all errors (and return nil)
- Catching any condition - handler-case
- Catching a specific condition
- handler-case VS handler-bind
- Handling conditions - handler-bind
- Creating conditions
- Signaling (throwing) conditions
- Restarts, interactive choices in the debugger
- Run some code, condition or not (“finally”)
- Resources
Ignore all errors (and return nil)
Sometimes you know that a function can fail and you just want to
ignore it: use ignore-errors:
(ignore-errors
(/ 3 0))
; in: IGNORE-ERRORS (/ 3 0)
; (/ 3 0)
;
; caught STYLE-WARNING:
; Lisp error during constant folding:
; arithmetic error DIVISION-BY-ZERO signalled
; Operation was (/ 3 0).
;
; compilation unit finished
; caught 1 STYLE-WARNING condition
NIL
#<DIVISION-BY-ZERO {1008FF5F13}>
We get a welcome division-by-zero warning but the code runs well and
it returns two things: nil and the condition that was signaled. We
could not choose what to return.
Rembember that we can inspect the condition with a right click in Slime.
Catching any condition - handler-case
ignore-error is built from handler-case. We can write the previous
example by catching the general error but now we can return whatever
we want:
(handler-case (/ 3 0)
(error (c)
(format t "We caught a condition.~&")
(values 0 c)))
; in: HANDLER-CASE (/ 3 0)
; (/ 3 0)
;
; caught STYLE-WARNING:
; Lisp error during constant folding:
; Condition DIVISION-BY-ZERO was signalled.
;
; compilation unit finished
; caught 1 STYLE-WARNING condition
We caught a condition.
0
#<DIVISION-BY-ZERO {1004846AE3}>
We also returned two values, 0 and the signaled condition.
The general form of handler-case is
(handler-case (code that errors out)
(condition-type (the-condition) ;; <-- optional argument
(code))
(another-condition (the-condition)
...))
We can also catch all conditions by matching t, like in a cond:
(handler-case
(progn
(format t "This won't work…~%")
(/ 3 0))
(t (c)
(format t "Got an exception: ~a~%" c)
(values 0 c)))
;; …
;; This won't work…
;; Got an exception: arithmetic error DIVISION-BY-ZERO signalled
;; Operation was (/ 3 0).
;; 0
;; #<DIVISION-BY-ZERO {100608F0F3}>
Catching a specific condition
We can specify what condition to handle:
(handler-case (/ 3 0)
(division-by-zero (c)
(format t "Caught division by zero: ~a~%" c)))
;; …
;; Caught division by zero: arithmetic error DIVISION-BY-ZERO signalled
;; Operation was (/ 3 0).
;; NIL
This workflow is similar to a try/catch as found in other languages, but we can do more.
Ignoring the condition argument
If you don’t access the condition object in your handlers, but you still keep it has an argument for good practice, you’ll see this compiler warning often:
; caught STYLE-WARNING:
; The variable C is defined but never used.
To remove it, use a declare call as in:
(handler-case (/ 3 0)
(division-by-zero (c)
(declare (ignore c))
(format t "Caught division by zero~%"))) ;; we don't print "c" here and don't get the warning.
handler-case VS handler-bind
handler-case is similar to the try/catch forms that we find in
other languages.
handler-bind (see the next examples), is what to use
when we need absolute control over what happens when a signal is
raised. It allows us to use the debugger and restarts, either
interactively or programmatically.
If some library doesn’t catch all conditions and lets some bubble out
to us, we can see the restarts (established by restart-case)
anywhere deep in the stack, including restarts established by other
libraries whose this library called. And we can see the stack
trace, with every frame that was called and, in some lisps, even see
local variables and such. Once we handler-case, we “forget” about
this, everything is unwound. handler-bind does not rewind the
stack.
Handling conditions - handler-bind
Here we use handler-bind.
Its general form is:
(handler-bind ((a-condition #'function-to-handle-it)
(another-one #'another-function))
(code that can...)
(...error out))
So, our simple example:
(handler-bind
((division-by-zero #'(lambda (c) (format t "hello condition~&"))))
(/ 3 0))
This prints some warnings, then it prints our “hello” and still enters the debugger. If we don’t want to enter the debugger, we have to define a restart and invoke it.
A real example with the
unix-opts library, that
parses command line arguments. It defined some conditions:
unknown-option, missing-arg and arg-parser-failed, and it is up
to use to write what to do in these cases.
(handler-bind ((opts:unknown-option #'unknown-option)
(opts:missing-arg #'missing-arg)
(opts:arg-parser-failed #'arg-parser-failed))
(opts:get-opts))
Our unknown-option function is simple and looks like this:
(defun unknown-option (condition)
(format t "~s option is unknown.~%" (opts:option condition))
(opts:describe)
(exit)) ;; <-- we return to the command line, no debugger.
it takes the condition as parameter, so we can read information from
it if needed. Here we get the name of the erronous option with the
defined reader (opts:option condition) (see below).
Creating conditions
With define-condition, and we can inherit from error or simple-error:
(define-condition my-division-by-zero (error) ())
It is a regular class, so we can add information into slots. Here, we add a custom message:
(define-condition my-division-by-zero (error)
((dividend :initarg :dividend
:reader dividend)) ;; <= so we'll get the dividend with (dividend condition), as soon as on the next line.
;; the :report is the message into the debugger:
(:report (lambda (condition stream) (format stream "You were going to divide ~a by zero.~&" (dividend condition)))))
The general form looks like a regular class definition:
(define-condition my-condition (condition-it-inherits-from)
;; list of arguments, can be "()".
((message :initarg :message
:reader my-condition-message)
(second ...))
;; class arguments
(:report (lambda (condition stream) (...))) ;; what is printed in the REPL.
(:documentation "a string")) ;; good practice ;)
Now when we throw this condition we must pass it an error message (it
is a required argument), and read it with error-message (the
:reader).
What’s in :report will be printed in the REPL.
Let’s try our condition. We define a simple function that checks our divisor, and signals our condition if it is equal to zero:
(defun my-division (x y)
(if (= y 0)
(error 'MY-DIVISION-BY-ZERO :dividend x))
(/ x y))
When we use it, we enter the debugger:
(my-division 3 0)
;;
;; into the debugger:
;;
You were going to divide 3 by zero.
[Condition of type MY-DIVISION-BY-ZERO]
Restarts:
0: [RETRY] Retry SLIME REPL evaluation request.
1: [*ABORT] Return to SLIME's top level.
2: [ABORT] abort thread (#<THREAD "repl-thread" RUNNING {1002957FA3}>)
Backtrace:
0: (MY-DIVISION 3 0)
We can inspect the backtrace, go to the source (v in Slime), etc.
Here is how unix-opts defines its unknown-option condition:
(define-condition troublesome-option (simple-error)
((option
:initarg :option
:reader option))
(:report (lambda (c s) (format s "troublesome option: ~s" (option c))))
(:documentation "Generalization over conditions that have to do with some
particular option."))
(define-condition unknown-option (troublesome-option)
()
(:report (lambda (c s) (format s "unknown option: ~s" (option c))))
(:documentation "This condition is thrown when parser encounters
unknown (not previously defined with `define-opts') option."))
Signaling (throwing) conditions
We can use error, like we did above. Two ways:
(error "some text"): signals a condition of typesimple-error(error 'my-error :message "We did this and this and it didn't work.")
Throwing these conditions will enter the interactive debugger, where a few options will be presented by default. We can give more options with restarts, and we can prevent from entering the debugger by handling the condition and invoking a restart.
Simple example from unix-opts: it adds information into the option slot:
(error 'unknown-option
:option opt)
Restarts, interactive choices in the debugger
Defining restarts
Restarts are the choices we get in the debugger, which always has the
RETRY and ABORT ones. We can add choices to the top of the list:
(defun division-restarter ()
(restart-case (/ 3 0)
(return-zero () 0)
(divide-by-one () (/ 3 1))))
By calling this stupid function we get two new choices at the top of the debugger:
Note: read in lisper.in’s blogpost on csv parsing (see Resources) how this system was used effectively in production.
But that’s not all, by handling restarts we can start over the operation as if the error didn’t occur (as seen in the stack).
Calling restarts programmatically
With invoke-restart.
(defun division-and-bind ()
(handler-bind
((error (lambda (c)
(format t "Got error: ~a~%" c) ;; error-message
(format t "and will divide by 1~&")
(invoke-restart 'divide-by-one))))
(division-restarter)))
;; (DIVISION-AND-BIND)
;; Got error: arithmetic error DIVISION-BY-ZERO signalled
;; and will divide by 1
;; Operation was (/ 3 0).
;; 3
Note that we called the form that contains our restarts
(division-restarter) and not the function that throws the error.
Using other restarts
find-restart 'name-of-restart will return the most recent bound
restart with the given name, or nil. We can invoke it with
invoke-restart.
Prompting the user to enter a new value
Let’s add a restart in our division-restarter to offer the user to
enter a new dividend, and run the division again.
(defun division-restarter ()
(restart-case (/ 3 0)
(return-nil () nil)
(divide-by-one () (/ 3 1))
(choose-another-dividend (new-dividend)
:report "Please choose another dividend"
:interactive (lambda ()
(format t "Enter a new dividend: ")
(list (read))) ;; <-- must return a list.
(format t "New division: 3/~a = ~a~&" new-dividend (/ 3 new-dividend)))))
We get prompted in the debugger:
arithmetic error DIVISION-BY-ZERO signalled
Operation was (/ 3 0).
[Condition of type DIVISION-BY-ZERO]
Restarts:
0: [RETURN-NIL] RETURN-NIL
1: [DIVIDE-BY-ONE] DIVIDE-BY-ONE
2: [CHOOSE-ANOTHER-DIVIDEND] Please choose another dividend <-- new
3: [RETRY] Retry SLIME REPL evaluation request.
4: [*ABORT] Return to SLIME's top level.
5: [ABORT] abort thread (#<THREAD "repl-thread" RUNNING {1002A47FA3}>)
The new choose-another-dividend restart takes an argument for the
new dividend, that will be fed by the :interactive lambda, which
reads for user input and must return a list.
We use it like this:
(division-restarter)
;;
;; Entered debugger, chose the 2nd restart.
;;
Enter a new dividend: 10 <-- got prompted to enter a new value.
New division: 3/10 = 3/10
NIL
In a real situation we might want to call our “restarter” recursively, to get into the debugger again if we enter a bad value.
Hide and show restarts
Restarts can be hidden. In restart-case, in addition to :report
and :interactive, they also accept a :test key:
(restart-case
(return-zero ()
:test (lambda ()
(some-test))
...
Run some code, condition or not (“finally”)
The “finally” part of others try/catch/finally forms is done with unwind-protect.
It is the construct used in “with-” macros, like with-open-file,
which always closes the file after it.
You’re now more than ready to write some code and to dive into other resources !
Resources
- Practical Common Lisp: “Beyond Exception Handling: Conditions and Restarts” - the go-to tutorial, more explanations and primitives.
- Common Lisp Recipes, chap. 12, by E. Weitz
- language reference
- lisper.in - example with parsing a csv file and using restarts with success, in a flight travel company.
- Condition Handling in the Lisp family of languages
- z0ltan.wordpress.com
- https://github.com/svetlyak40wt/python-cl-conditions - implementation of the CL conditions system in Python.
Using a program from a REPL is fine and well, but if we want to distribute our program easily, we’ll want to build an executable.
Lisp implementations differ in their processes, but they all create self-contained executables, for the architecture they are built on. The final user doesn’t need to install a Lisp implementation, he can run the software right away.
Start-up times are near to zero, specially with SBCL and CCL.
Binaries size are large-ish. They include the whole Lisp including its libraries, the names of all symbols, information about argument lists to functions, the compiler, the debugger, source code location information, and more.
Note that we can similarly build self-contained executables for web apps.
Now best read in the Common Lisp Cookbook.
Table of Contents
- Building a self-contained executable
- Parsing command line arguments
- Continuous delivery of executables
- Credit
Building a self-contained executable
With SBCL
How to build (self-contained) executables is implementation-specific (see below Buildapp and Rowsell). With SBCL, as says its documentation, it is a matter of:
(sb-ext:save-lisp-and-die #P"path/name-of-executable" :toplevel #'my-app:main-function :executable t)
sb-ext is an SBCL extension to run external processes. See other
SBCL extensions
(many of them are made implementation-portable in other libraries).
:executable t tells to build an executable instead of an
image. We could build an image to save the state of our current
Lisp image, to come back working with it later. Specially useful if
we made a lot of work that is computing intensive.
If you try to run this in Slime, you’ll get an error about threads running:
Cannot save core with multiple threads running.
Run the command from a simple SBCL repl.
I suppose your project has Quicklisp dependencies. You must then:
- ensure Quicklisp is installed and loaded at Lisp startup (you completed Quicklisp installation)
loadthe project’s .asd- install dependencies
- build the executable.
That gives:
(load "my-app.asd")
(ql:quickload :my-app)
(sb-ext:save-lisp-and-die #p"my-app-binary" :toplevel #'my-app:main :executable t)
From the command line, or from a Makefile, use --load and --eval:
build:
sbcl --load my-app.asd \
--eval '(ql:quickload :my-app)' \
--eval "(sb-ext:save-lisp-and-die #p\"my-app\" :toplevel #my-app:main :executable t)"
With ASDF [updated]
Now that we’seen the basics, we need a portable method. Since its
version 3.1, ASDF allows to do that. It introduces the make command,
that reads parameters from the .asd. Add this to your .asd declaration:
:build-operation "program-op" ;; leave as is
:build-pathname "<binary-name>"
:entry-point "<my-package:main-function>"
and call asdf:make :my-package.
So, in a Makefile:
LISP ?= sbcl
build:
$(LISP) --load torrents.asd \
--eval '(ql:quickload :my-app)' \
--eval '(asdf:make :my-app)' \
--eval '(quit)'
With Buildapp or Roswell
We might like a more shell-friendly way to build our executable, and while we’re at it a portable one, so we would have the same command to work with various implementations.
Buildapp is a battle-tested “application for SBCL or CCL that configures and saves an executable Common Lisp image”.
Example usage:
buildapp --output myapp \
--asdf-path . \
--asdf-tree ~/quicklisp/dists \
--load-system my-app \
--entry my-app:main
Many applications use it (for example,
pgloader). It is available on
Debian: apt install buildapp.
Roswell, an implementation manager and much
more, also has the ros build command, that should work for more
implementations than Buildapp.
We can also make our app installable with Roswell by a ros install
my-app. See its documentation
For web apps
We can similarly build a self-contained executable for our web-app. It would thus contain a web server and would be able to run on the command line:
$ ./my-web-app
Hunchentoot server is started.
Listening on localhost:9003.
Note that this runs the production webserver, not a development one, so we can run the binary on our VPS right away and access the app from outside.
We have one thing to take care of, it is to find and put the thread of
the running web server on the foreground. In our main function, we
can do something like this:
(defun main ()
(start-app :port 9003) ;; our start-app, for example clack:clack-up
;; let the webserver run.
;; warning: hardcoded "hunchentoot".
(handler-case (bt:join-thread (find-if (lambda (th)
(search "hunchentoot" (bt:thread-name th)))
(bt:all-threads)))
;; Catch a user's C-c
(#+sbcl sb-sys:interactive-interrupt
#+ccl ccl:interrupt-signal-condition
#+clisp system::simple-interrupt-condition
#+ecl ext:interactive-interrupt
#+allegro excl:interrupt-signal
() (progn
(format *error-output* "Aborting.~&")
(clack:stop *server*)
(uiop:quit)))
(error (c) (format t "Woops, an unknown error occured:~&~a~&" c))))
We used the bordeaux-threads library ((ql:quickload
"bordeaux-threads"), alias bt) and uiop, which is part of ASDF so
already loaded, in order to exit in a portable way (uiop:quit, with
an optional return code, instead of sb-ext:quit).
Size and startup times of executables per implementation
SBCL isn’t the only Lisp implementation. ECL, Embeddable Common Lisp, transpiles Lisp programs to C. That creates a smaller executable.
According to this reddit source, ECL produces indeed the smallest executables of all, an order of magnituted smaller than SBCL, but with a longer startup time.
CCL’s binaries seem to be as fast as SBCL and nearly half the size.
| program size | implementation | CPU | startup time |
|--------------+----------------+------+--------------|
| 28 | /bin/true | 15% | .0004 |
| 1005 | ecl | 115% | .5093 |
| 48151 | sbcl | 91% | .0064 |
| 27054 | ccl | 93% | .0060 |
| 10162 | clisp | 96% | .0170 |
| 4901 | ecl.big | 113% | .8223 |
| 70413 | sbcl.big | 93% | .0073 |
| 41713 | ccl.big | 95% | .0094 |
| 19948 | clisp.big | 97% | .0259 |
Parsing command line arguments
SBCL stores the command line arguments into sb-ext:*posix-argv*.
But that variable name differs from implementations, so we may want a library to handle the differences for us.
We also want to parse the arguments.
A quick look at the awesome-cl#scripting list and we’ll do that with the unix-opts library.
(ql:quickload "unix-opts")
We can call it with its opts alias (nickname).
As often work happens in two phases:
- declaring the options our app accepts, their optional argument, defining their type (string, integer,…), long and short names, and the required ones,
- parsing them (and handling missing or malformed parameters).
Declaring arguments
We define the arguments with opts:define-opts:
(opts:define-opts
(:name :help
:description "print this help text"
:short #\h
:long "help")
(:name :nb
:description "here we want a number argument"
:short #\n
:long "nb"
:arg-parser #'parse-integer) ;; <- takes an argument
(:name :info
:description "info"
:short #\i
:long "info"))
Here parse-integer is a built-in CL function.
Example output on the command line (auto-generated help text):
$ my-app -h
my-app. Usage:
Available options:
-h, --help print this help text
-n, --nb ARG here we want a number argument
-i, --info info
Parsing
We parse and get the arguments with opts:get-opts, which returns two
values: the list of valid options and the remaining free arguments. We
then must use multiple-value-bind to assign both into variables:
(multiple-value-bind (options free-args)
;; There is no error handling yet.
(opts:get-opts)
...
We can test this by giving a list of strings to get-opts:
(multiple-value-bind (options free-args)
(opts:get-opts '("hello" "-h" "-n" "1"))
(format t "Options: ~a~&" options)
(format t "free args: ~a~&" free-args))
Options: (HELP T NB-RESULTS 1)
free args: (hello)
NIL
If we put an unknown option, we get into the debugger. We’ll see error handling in a moment.
So options is a
property list. We
use getf and setf with plists, so that’s how we do our
logic. Below we print the help with opts:describe and then exit
(in a portable way).
(multiple-value-bind (options free-args)
(opts:get-opts)
(if (getf options :help)
(progn
(opts:describe
:prefix "You're in my-app. Usage:"
:args "[keywords]") ;; to replace "ARG" in "--nb ARG"
(opts:exit))) ;; <= optional return status.
(if (getf options :nb)
...)
For a full example, see its official example and cl-torrents’ tutorial.
The example in the unix-opts repository suggests a macro to do slightly better. Now to error handling.
Handling malformed or missing arguments
There are 4 situations that unix-opts doesn’t handle, but signals conditions for us to take care of:
- for an unknown argument: an
unknown-optioncondition is signaled - also
missing-arg arg-parser-failedwhen, for example, it expected an integer but got textmissing-required-option
So, we must create simple functions to handle those conditions, and
surround the parsing of the options with an handler-bind:
(multiple-value-bind (options free-args)
(handler-bind ((opts:unknown-option #'unknown-option) ;; the condition / our function
(opts:missing-arg #'missing-arg)
(opts:arg-parser-failed #'arg-parser-failed)
(opts:missing-required-option))
(opts:get-opts))
…
;; use "options" and "free-args"
Here we suppose we want one function to handle each case, but it could be a simple one. They take the condition as argument.
(defun handle-arg-parser-condition (condition)
(format t "Problem while parsing option ~s: ~a .~%" (opts:option condition) ;; reader to get the option from the condition.
condition)
(opts:describe) ;; print help
(opts:exit)) ;; portable exit
For more about condition handling, see error and condition handling.
Catching a C-c termination signal
Let’s build a simple binary, run it, try a C-c and read the stacktrace:
$ ./my-app
sleep…
^C
debugger invoked on a SB-SYS:INTERACTIVE-INTERRUPT in thread <== condition name
#<THREAD "main thread" RUNNING {1003156A03}>:
Interactive interrupt at #x7FFFF6C6C170.
Type HELP for debugger help, or (SB-EXT:EXIT) to exit from SBCL.
restarts (invokable by number or by possibly-abbreviated name):
0: [CONTINUE ] Return from SB-UNIX:SIGINT. <== it was a SIGINT indeed
1: [RETRY-REQUEST] Retry the same request.
The signaled condition is named after our implementation:
sb-sys:interactive-interrupt. We just have to surround our
application code with a handler-case:
(handler-case
(run-my-app free-args)
(sb-sys:interactive-interrupt () (progn
(format *error-output* "Abort.~&")
(opts:exit))))
This code only for SBCL though. We know about trivial-signal, but we were not satisfied with our test yet. So we can use something like this:
(handler-case
(run-my-app free-args)
(#+sbcl sb-sys:interactive-interrupt
#+ccl ccl:interrupt-signal-condition
#+clisp system::simple-interrupt-condition
#+ecl ext:interactive-interrupt
#+allegro excl:interrupt-signal
()
(opts:exit)))
here #+ includes the line at compile time depending on
the implementation. There’s also #-. What #+ does is to look for
symbols in the *features* list. We can also combine symbols with
and, or and not.
Continuous delivery of executables
We can make a Continuous Integration system (Travis CI, Gitlab CI,…) build binaries for us at every commit, or at every tag pushed or at wichever other policy.
Credit
Django Admin search fields are great, throw a bunch of fields in search_fields and Django will handle the rest. The problem with search field begins when there are too many of them. This is how we replaced Django search with text filters for specific fields, and made Django admin much faster.

Santa's Smart Contract
MonkeyUser 24 12 2017
Lately we exercised our Lisp skills by writing cl-torrents, an app that searches for torrents on several sources (the Pirate Bay through piratebay.to, Kickass torrents and torrent.cd), and we wrote an extensive tutorial in the making (that was actually our primary goal). It comes as a library to use from the REPL and as a self-contained executable (download and run, nothing more to install). You’ll find the following topics in the tutorial:
- how to create and load a new project,
- common pitfalls, basic data structures, useful libraries, where to find documentation,
- (async) web scraping,
- unit testing, with mocks,
- continuous integration and delivery of executables (Gitlab CI, Docker),
- parsing command line arguments,
- building self-contained executables,
- basics of error handling,
- …
Some topics have been ported to the Cookbook, some not (yet).
The next iteration will be about a self-contained web app.


(bug)fixing car using
MonkeyUser 12 12 2017
A few weeks ago we encountered a major performance regression in one of our main admin pages. The page took more than 10 seconds to load (at best) and hit the query execution timeout at worst. When we investigated the issue, we found that the date hierarchy was the cause for most of the time spent loading the admin page. In the article we describe how we significantly improved the performance of Django Admin date hierarchy
Clojure 1.9 is now available
Clojure News 08 12 2017
Clojure 1.9 is now available!
Clojure 1.9 introduces two major new features: integration with spec and command line tools.
spec (rationale, guide) is a library for describing the structure of data and functions with support for:
-
Validation
-
Error reporting
-
Destructuring
-
Instrumentation
-
Test-data generation
-
Generative test generation
-
Documentation
Clojure integrates spec via two new libraries (still in alpha):
-
spec.alpha - spec implementation
-
core.specs.alpha - specifications for Clojure itself
This modularization facilitates refinement of spec separate from the Clojure release cycle.
The command line tools (getting started, guide, reference) provide:
-
Quick and easy install
-
Clojure REPL and runner
-
Use of Maven and local dependencies
-
A functional API for classpath management (tools.deps.alpha)
The installer is available for Mac developers in brew, for Linux users in a script, and for more platforms in the future.
For more information, see the complete list of all changes in Clojure 1.9 for more details.
Contributors
Thanks to all of the community members who contributed to Clojure 1.9 (first time contributors in bold):
-
Adam Clements
-
Andy Fingerhut
-
Brandon Bloom
-
Cameron Desautels
-
Chad Taylor
-
Chris Houser
-
David Bürgin
-
Eli Lindsey
-
Gerrit Jansen Van Vuuren
-
Ghadi Shayban
-
Greg Leppert
-
Jason Whitlark
-
Johan Mena
-
Jozef Wagner
-
Lee Yen-Chin
-
Matthew Boston
-
Michael Blume
-
Michał Marczyk
-
Nicola Mometto
-
Ruslan Al-Fakikh
-
Steffen Dienst
-
Steve Miner
-
Yegor Timoshenko
-
Zhuang XiaoDan
![]()
WhoTracks.me December Update
WhoTracksMe blog 07 12 2017
Who's using Common Lisp ?
Lisp journey 05 12 2017
Everyone says “Nobody uses Lisp” and Lispers say “Yes they do, there’s ITA, and, um, Autocad, and, uh, oh yeah, Paul Graham wrote Viaweb in Lisp!” Not very helpful for either side.
Following Lisp Companies blog post (2008, many dead links).
Reddit and lispjobs are the major sources. Sponsors can be found on the European Lisp Symposium website.
Of course, see
- lisp-lang.org’s success stories for a showcase of projects and companies in aerospace, AI & Machine Learning, Science, Graphics etc.
- franz.com success stories
- lisp-journey’s short software list (pgloader,…)
- awesome-cl-software (old and current),
- awesome-cl libraries.
- awesome-lisp-companies, a bigger list.
Let’s quote Kent Pitman’s famous answer:
But please don’t assume this is an exhaustive list, and please don’t assume Lisp is only useful for Animation and Graphics, AI, Bioinformatics, B2B and Ecommerce, Data Mining, EDA/Semiconductor applications, Expert Systems, Finance, Intelligent Agents, Knowledge Management, Mechanical CAD, Modeling and Simulation, Natural Language, Optimization, Research, Risk Analysis, Scheduling, Telecom, and Web Authoring just because these are the only things they happened to list. Common Lisp really is a general language capable of a lot more than these few incidental application areas, even if this web page doesn’t totally bring that out.
(and this list doesn’t mention that it was used for auto-piloting the DS1 spaceship by the NASA for several days)
- D-wave systems, “quantum processor development”. “The software is implemented in Common Lisp (SBCL) and is an integral part of the quantum computing system.” lispjobs announce.
- Emotiq - a next-generation blockchain with an innovative natural-language approach to smart contracts.
- Grammarly, an English language writing-enhancement platform.
- m-creations, custom software solutions for mid-size to big companies in finance/payment, health care, and media. Using Common Lisp in different fields ranging from dynamic web applications and Natural Language Processing to systems engineering infrastructure in container clusters (DNS, dynamic load balancer).
- Ravenpack, “the leading big data analytics provider for financial services”. reddit announce.
- Rigetti, new quantum computing company. They already sponsored a Quicklisp development. They chose Common Lisp (SBCL). Video. Their Lisp even runs 40% faster than their C code.
- Secure Outcomes “builds and provides digital livescan fingerprinting systems for use by law enforcement, military, airports, schools, Fortune 500s, etc.”. “All of our systems are constructed in Common Lisp.”. lispjobs announce.
- Somewrite.jp, a “native advertising network platform”. Common Lisp web development. lispjobs announce. A Fukamachi company. press write up.
- Spycursion PC game. Reddit announce.

Compile vs Runtime Error
MonkeyUser 05 12 2017
Best read in the Cookbook ! also Travis CI, code coverage, testing with Prove.
Gitlab CI is part of
Gitlab and is available on Gitlab.com, for
public and private repositories. Let’s see straight away a simple
.gitlab-ci.yml:
image: daewok/lisp-devel
before_script:
- apt-get update -qy
- apt-get install -y git-core
- git clone https://github.com/foo/bar ~/quicklisp/local-projects/
test:
script:
- make test
Gitlab CI is based on Docker. With image we tell it to use the
daewok/lisp-devel
one. It includes SBCL, ECL, CCL and ABCL, and Quicklisp is installed
in the home (/home/lisp/), so we can quickload packages right
away. If you’re interested it also has a more bare bones option. Gitlab will load the
image, clone our project and put us at the project root with
administrative rights to run the rest of the commands.
test is a “job” we define, script is a
recognized keywords that takes a list of commands to run.
Suppose we must install dependencies before running our tests:
before_script will run before each job. Here we clone a library
where Quicklisp can find it, and for doing so we must install git
(Docker images are usually pretty bare bones).
We can try locally ourselves. If we already installed Docker and
started its daemon (sudo service docker start), we can do:
docker run --rm -it -v /path/to/local/code:/usr/local/share/common-lisp/source daewok/lisp-devel:latest bash
This will download the lisp image (±400Mo), mount some local code in
the image where indicated, and drop us in bash. Now we can try a make
test.
To show you a more complete example:
image: daewok/lisp-devel
stages:
- test
- build
before_script:
- apt-get update -qy
- apt-get install -y git-core
- git clone https://github.com/foo/bar ~/quicklisp/local-projects/
test:
stage: test
script:
- make test
build:
stage: build
only:
- tags
script:
- make build
artifacts:
paths:
- some-file-name
Here we defined two stages (see
environments),
“test” and “build”, defined to run one after another. A “build” stage
will start only if the “test” one succeesds.
“build” is asked to run only when a
new tag is pushed, not at every commit. When it succeeds, it will make
the files listed in artifacts’s paths available for download. We can
download them from Gitlab’s Pipelines UI, or with an url. This one will download
the file “some-file-name” from the latest “build” job:
https://gitlab.com/username/project-name/-/jobs/artifacts/master/raw/some-file-name?job=build
When the pipelines pass, you will see:
You now have a ready to use Gitlab CI.

Specs...
MonkeyUser 21 11 2017
![]()

Step By Step Debugging
MonkeyUser 14 11 2017

Merging Branches
MonkeyUser 07 11 2017
![]()
First impressions of Elm
Posts on James Routley 31 10 2017
Common Lisp may have more libraries than you think. See:
- Quickdocs - the library documentation hosting for CL.
- the Awesome-cl list, a curated list of libraries.
- lisp-lang.org’s recommended libraries (from State of the CL ecosystem, 2015)
Quicklisp is the de-facto package manager, but not the only tool.
Some terminology first
In the Common Lisp world, a package is a way of grouping symbols together and of providing encapsulation. It is similar to a C++ namespace, a Python module or a Java package.
A system is a collection of CL source files bundled with an .asd file which tells how to compile and load them. There is often a one-to-one relationship between systems and packages, but this is in no way mandatory. A system may declare a dependency on other systems. Systems are managed by ASDF (Another System Definition Facility), which offers functionalities similar to those of make and ld.so, and has become a de facto standard.
A Common Lisp library or project typically consists of one or several ASDF systems (and is distributed as one Quicklisp project).
Install Quicklisp
Quicklisp is more than a package manager, it is also a central repository (a dist) that ensures that all libraries build together. This involves some manual work (like reporting errors to package authors), so this is why Quicklisp releases its dist updates once a month (but fear not, we have other tools).
It provides its own dist but it is also possible to build our own.
To install it, we can either:
1- run this command, anywhere:
curl -O https://beta.quicklisp.org/quicklisp.lisp
and enter a Lisp REPL and load this file:
sbcl --load quicklisp.lisp
or
2- install the Debian package:
apt-get install cl-quicklisp
and load it, from a REPL:
(load "/usr/share/cl-quicklisp/quicklisp.lisp")
Then, in both cases, still from the REPL:
(quicklisp-quickstart:install)
This will create the ~/quicklisp/ directory, where Quicklisp will
maintain its state and downloaded projects.
If you want Quicklisp to always be loaded in your Lisp sessions, run
(ql:add-to-init-file): this adds the right stuff to the init file of
your CL implementation. Otherwise, you have to run (load
"~/quicklisp/setup.lisp") in every session if you want to use
Quicklisp or any of the libraries installed through it.
It adds the following in your (for example) ~/.sbclrc:
#-quicklisp
(let ((quicklisp-init (merge-pathnames "quicklisp/setup.lisp"
(user-homedir-pathname))))
(when (probe-file quicklisp-init)
(load quicklisp-init)))
Install libraries
In the REPL:
(ql:quickload "package-name")
and voilà. See Quicklisp’s documentation for more commands.
Note also that dozens of Common Lisp libraries are packaged in
Debian. The package names usually begin with the cl- prefix (use
apt-cache search --names-only "^cl-.*" to list them all).
For example, in order to use the CL-PPCRE library (for regular
expressions), one should first install the cl-ppcre package.
Then, in SBCL and ECL, it can be used with:
(require "asdf")
(require "cl-ppcre")
(cl-ppcre:regex-replace "fo+" "foo bar" "frob")
See more: https://wiki.debian.org/CommonLisp
Advanced dependencies management
Quicklisp installs the libraries into ~/quicklisp/local-projects/. A
library installed here is automatically available for every project.
Providing our own version of a library. Cloning projects.
Given the property above, we can clone any library into the local-projects directory and it will be found by quicklisp and available right-away:
(ql:quickload "package")
And also given the M-. “go to this symbol definition” feature in
Slime (and M-, to go back), it’s really easy to not only explore but
start tweaking and extending other libraries.
How to work with local versions of libraries
If we need libraries to be installed locally, for only one project, or in order to easily ship a list of dependencies with an application, we can use Qlot. This is like Python’s virtual environments.
Quicklisp also provides Quicklisp bundles. They are self-contained sets of systems that are exported from Quicklisp and loadable without involving Quicklisp.
At last, there’s Quicklisp controller to help us build dists. Some projects use this, like CL21.
Read more
- Source code organization, libraries and packages: https://lispmethods.com/libraries.html
- https://wiki.debian.org/CommonLisp
See also
- Qi - a package manager for Common Lisp
![]()

Opinions
MonkeyUser 24 10 2017
Lisp software
Lisp journey 19 10 2017
There’s a fantastic showcase of succesfull Common Lisp software on lisp-lang.org: http://lisp-lang.org/success/ so go there first.
However all are not open source and it doesn’t list new or not so awesome but very cool or interesting software. That’s what we’ll do here to see that yeah Lisp is used today and to have code bases to look at.
If you are looking for CL libraries, you of course had a look to the Awesome CL list.
Awesome Lisp software
- pgloader - re-written from Python with a 20 to 30x speed gain and more O_o - blog post By Dimitri Fontaine working at Postgres in 2014. He also maintains around 50 Debian packages of Lisp libraries for these needs. He gave a lightning talk at the 7th European Lisp Symposium. Uses Postmodern and lparallel for asynchronous IO. Also,
the new code base and feature set seems to attract way more users than the previous implementation ever did, despite using a less popular programming language.
pgchart - a self-contained web application that takes as input an SQL query text and outputs its data as a chart. By the same Dimitri Fontaine.
potato - a Slack-like conversation platform. Many features. CL in the backend, ClojureScript to the frontend. Apache Solr, RabbitMQ, email updates,… Web, Emacs and Android clients. web coding video.
turtl - a security focused online note taking app. Deployed at scale at Framanotes. Backend in CL.
Internet
- nEXT browser - Qt based web browser.
- cl-torrents - (my) library, cli and readline app to search for torrents on popular trackers, with an extensive tutorial.
Publishing software
- Coleslaw - a static site generator similar to Jekyll. With nifty features (build on git push,…). Example blog: http://40ants.com/
- Radiance - publishing software, between CMS and framework.
- Reader - a simple blogging platform for Radiance.
- Purplish - an imageboard app for Radiance.
Editors
Darkmatter - Common Lisp notebook (also exists cl-jupyter). Built on Clack.
Lem - an Emacs clone tailored for Common Lisp development, for the terminal or Electron. Screencast.
GUI apps
- Halftone - a multiplatform and portable image viewer. Simple app to demo building Qt GUIs with Qtools.
Terminal apps
todo: enhance !
- Pml - cli tool to parse my nginx logs and print statistics (and Tankfeeder for apache)
- shuffletron - a terminal music player. [staling]
- shtookovina - a program to help learn natural languages, based on audio recording by the Shtooka project, with an advanced readline interface and fully hackable in Common Lisp. Deprecated since 2015.

IT Hell
MonkeyUser 17 10 2017

Deadline
MonkeyUser 10 10 2017
Scaling Django Admin Date Hierarchy
Haki Benita 05 10 2017
The date hierarchy is a great feature but it comes at a price. On very large tables, the way date hierarchy is implemented can make an admin page nearly unusable. In this article we describe the limitations of the date hierarchy, and suggest a way to overcome them.
Lisps are famous for having powerful metaprogramming facilities derived from their homoiconic nature. Core language consists of a small set of built in primitives, and the rest is implemented using macros and functions in the standard library.
Since these same tools are available to the users, anybody can easily extend the language to add semantics for their problem domain. This is the aspect of macros that's discussed most often.
While this is certainly the case, Clojure community tends to discourage using macros if they can be avoided. The rationale behind this being that macros introduce additional complexity, and Clojure values simplicity. I generally agree with this sentiment, and I find that I tend to use macros sparingly myself. However, saying that macros shouldn’t be overused is not the same as saying they shouldn’t be used at all.
One place where macros work well is library APIs. Libraries that express a particular domain can create a DSL in their API that cleanly maps to that domain. Compojure, Specter, and Clara Rules are great examples of effective macro use. Such libraries are a powerful demonstration of users extending semantics of the language.
Since most ideas can be expressed via libraries, it becomes possible to experiment with different approaches to solving problems without modifying the core language. Extending the language through libraries has the advantage of keeping these extensions contained. It also lets them fade away when you no longer use them.
Clojure has been around for a decade now, and the core language hasn't changed much in that time. Some new features have been added, most notably reducers and transducers, but overall the language has stayed small and focused. In fact, I've even seen concerns that Clojure is stagnating because features aren't being added at the rate of other languages.
The idea of using libraries to add features is used by the Clojure core team as well. Consider the example of the core.async library that brings Go channel semantics and the CSP programming model to Clojure.
Perhaps, in time a better idea will come along, and core.async library will become deprecated. At that point developers would stop using the library and move on to use whatever happens to replace it.
Meanwhile, existing projects will not be affected as they can continue using the library. The community will move on, and most people won't have to learn about core.async semantics. This cycle may happen many times with many different ideas, without any baggage being accumulate by the language itself.
Unfortunately, mainstream languages are designed in a way where it's not practical to add new features without updating the language specification to accommodate them. Popular languages such as Java, Python, and JavaScript have accumulated a lot of complexity over the years.
As usage patterns change, new features are being added, while existing features become deprecated. Removing features is difficult since many projects in the wild end up relying on them, so they're typically left in place.
Having lots of features in a language can seem like a positive at first glance, but in practice, features often turn into a mental burden for the developer. Eventually languages become too large to understand fully, and developers settle on a subset of the features considered to be the current best practice.
In my opinion, this is the real power of homoiconicity. A language that can be extended in user space can evolve without accumulating baggage. New ideas can be implemented as libraries, and later discarded when better ideas come along. The end result is a small and focused language that doesn't sacrifice flexibility.

Visualized Codebase
MonkeyUser 03 10 2017

Design Patterns - Bureaucracy
MonkeyUser 26 09 2017

Instapaper is now optimized for iOS 11
Instapaper 20 09 2017
Today we’re launching our iOS 11-tailored update with drag and drop support for iPad and iPad Pro as well as performance improvements for Instapaper across all iOS devices.
Drop to save
iOS 11 makes saving articles and videos to Instapaper more seamless. To save from another app, first multitask Instapaper using Slide Over or Split View. From there, long-press on a link in another app, such as Safari, and drag it into Instapaper to save it. If you drag a link into an open folder, it will save directly to that folder.
Drag into other apps
It’s now easier to share articles from your Instapaper account to other apps. Just long-press on an article entry and drop it into a compatible app, like Mail or a browser. Dragging from Instapaper also works from search results, so it’s simple to find and share anything in your account, regardless of whether it’s synced to your device. Article highlights and notes can be shared by dragging from the Notes section.
iOS 11 Password AutoFill
We added support for iOS 11’s new Password AutoFill feature. If your Instapaper credentials are stored in your iCloud Keychain, you’ll now see the option to use your saved password above the keyboard when logging in on iOS.
Bug fixes
This update addresses a variety of user-reported issues from the last release. We’ve improved our handling of embedded video content, particularly for poor connection scenarios, to ensure better and faster opening of saves in all conditions.
We also fixed a recent issue where exiting an article with a swipe gesture could result in your current reading position not saving.
Lastly, we made several search UI improvements, including a fix for a small line that would occasionally appear across the search tab.
We hope these updates make reading, sharing and multitasking with Instapaper better than ever.
If you’ve got any questions or feedback, just let us know via support@help.instapaper.com or @InstapaperHelp on Twitter.

Web App - Visualized
MonkeyUser 19 09 2017

Productive Scrum Meetings
MonkeyUser 12 09 2017
If you didn’t know that, now you do. Quicklisp releases software updates once a month (see Quicklisp’s blog). I didn’t know why, it isn’t explained on its website, so I asked (issue #148). I found the discussion very insightful, everybody being constructive, existing solutions being discussed and architectural choices explained. But it ended up brutally with one more Common Lisp oddity.
My first impression was that this fact is annoying, because it already prevented me a couple of times to use my own library and its most recent updates into other projects. They would pull the lib from Quicklisp but wouldn’t benefit from its latest features.
This way of doing was also not the package management model I was most used to (pip, npm,…), but by wording things differently it makes more sense to me. As an user says:
I think it is a very unique to quicklisp, making sure that everything compiles together. I can’t think of any other libraries/frameworks system on other languages/platforms that would go as far. Really great work.
So Quicklisp is more than a package manager, it is a “dist” builder ensuring everything works together, closer to apt than to pip.
The situation and shortcomings is well described by axity on his blog post (now showing a 404):
Zach Beane has done an excellent job with Quicklisp, and it is far better than what we previously had available, but still has a few problems. Zach puts a lot of effort into curating a list of compatible software together into the form of a “Quicklisp dist” rolled out approximately every month. While this is great and puts near-zero maintenance on developers, it poses a few problems.
Firstly, Zach is a single point of failure. Yes, anyone can maintain their very own Quicklisp dist, but it isn’t going to see the masses, and the Quicklisp internals are not very well understood by anyone other than Zach.
Also the fact that the official dists are rolled out so far apart (a month or longer in the software world is an eternity), means developers cannot push hot-fixes or address user-reported bugs in a timely manner, without pushing maintenance onto the users by having them checkout upstream sources.
Modern languages such as Julia and Racket offer central repositories where a developer can register their software projects, and will be automatically indexed periodically, so that users can continue to install and update software without any maintenance, and still receive updates quickly when needed. Additionally, they push managing version dependencies onto the developer, which I do not believe to be a bad thing. In contrast, Common Lisp libraries are rarely versioned, and all of that maintenance is forced upon the Quicklisp dist curator.
I also like /u/ruricolist’s explanations (on reddit):
Quicklisp provides more assurance than you might expect. The criterion for inclusion, and maintenance, of a project in Quicklisp is that the project successfully load in SBCL alongside all the libraries in that Quicklisp distribution, and load without any errors or warnings. SBCL has extensive type inference and can catch and warn about many potential issues at compile time. And because of the pervasive use of macros in CL, successfully loading a library usually exercises a lot of code paths in its dependencies. To a surprising extent, “if it loads, it runs.”
Qlot isn’t something a library would use. You use it to set up the dependencies for an application. My approach (with TBRSS) is this. Obviously, every time I upgrade to a new Quicklisp dist, I run a test suite to make sure everything is working together. On the rare occasion there’s a problem, I either pin the offending library to an older version (with Qlot) or I fork it and fix it, again using Qlot to pull from the fork until the fix makes it into the next Quicklisp dist. And of course I also use Qlot for dependencies that are not, for whatever reason, available in Quicklisp.
So Quicklisp’s author answers:
The work relying on me is that I build everything in Quicklisp to make sure they build together before making a release. This covers a useful class of bugs. I’d love to incorporate more tests in the process to catch release problems that don’t manifest at build time.
I hope to make it easier for people to learn how to make their own dists. Then people will have the opportunity to make new software sets following the policies that are most important to them. I think there’s also plenty of room for other package managers for Common Lisp - maybe something styled more like clbuild would suit people who want instant access to updates.
Why a month ?
A month between updates is a compromise between chaos and stability.
I don’t think shorter release cycles are an unqualified good. In my experience, short release cycles can lead to instability and unpredictability, and I chose one month as a balance between getting timely updates and having a reliable, stable base.
The most labor-intensive part of making releases is monitoring daily failures and reporting bugs to the right people. The daily failure report is automated, but reporting bugs (and following up) can be a slog.
Then the discussion began. When voices support more frequent releases, Zach advertises again quicklisp-controller; I read one (and only one) small but direct criticism towards the maintainer:
@Hexstream I don’t think a fork will be required. I think this is less of an issue with @xach not willing to make changes required by the community and more of lack of manpower that’s willing and able to take up the burden of building and maintaining an automated Quicklisp dist/repository.
A one month update has its supporters, of course:
I have benefited multiple times from the 1 month release cycle and the due diligence that Xach and others put in every month. Even if they had a team of 50 I’d still vote to keep it as it is now. Making a separate dist is far more sensible if you need extra control over delivery times and it will still play well with quicklisp and your other projects.
I asked whether it would be possible to specify a git version, and I had an explanation:
Regarding pulling from git in the client, Quicklisp doesn’t work like that. I did not want to rely on external processes in order to be portable to all Common Lisp implementations and platforms. This was a real issue in clbuild and asdf-install.
If you want to update a bugfix of your library, fix it, and wait a month.
and the reminder to try Qlot, which allows exactly that (and to set dependencies locally).
Qlot will not help if you are writing a library and want to push fixes to its users quickly. It only helps for end-user application development. It works similar to virtualenv + pip (requirements.txt) from Python’s world, for example.
Phoe summed up the situation:
This thread is turning into a discussion about “why X approach is better than Quicklisp approach” which leads to a fruitful, but dead point.
If someone is not satisfied with the way the current Quicklisp dist works and would rather have a more automated solution, then they are free to extend the quicklisp-controller to their liking and implement the required functionality for:
- creating a centralized service that acts as a QL repository and dist manager,
- allowing the authors to upload and/or update their projects on that service,
- setting up a CI test loop on that service for verifying that the packages build,
- automatically updating the service’s dists with new releases,
- maintaining all of the above.
Until such a person or group of people appears, nothing is going to be be achieved and nothing in Quicklisp is going to change.
Talk is cheap - @xach has at least built something that works and can act as a foundation.
And now, after only 17 messages to the thread, Zach Beane closes the thread:
I can appreciate there are other approaches that have advantages over how Quicklisp works. I hope this thread has helped shed some light on why it works the way it does, and my hopes for the future. I’m not against requests for changes, but not all of them can or will be accommodated. I’m also fully in favour of people doing their own thing if they have other priorities, experiences, and preferences - I think it would be great if there were even more options for Common Lisp project management.
Closing this for now - thanks for the discussion.
Hexstream had just the time to disagree
Generally agree with your last comment, but I just wanted to express my discontent at the premature closing of this thread, it seemed pretty fruitful to me and I don’t think it had yet reached a point of serious diminishing returns.
(Your project, your rules, though.)
and this is it.
I think, and I’m not the only one, that the thread was fruitful.
Indeed, we had explanations (that don’t appear in the doc), we had presentation of means to the resolution (in no doc), we had the presentation of how to fix the mentioned problem for library developers (Qlot, comprehensibly not referenced in Quicklisp doc, and little talked about over here), we had questions regarding the lack of documentation that could be tracked from this thread (Zach too said he wanted to write more doc). And I think the discussion was professional, with no animosity. So we could have tracked some progress, maybe we would have received more tips, but more importantly we’d have been done with this question.
But the thread is closed O_o Preventing people from communicating means preventing people from learning from each other, and thus makes the CL world evolving slower. Or people quitting, or simply be very surprised and not staying here. Indeed, it’s a negative feeling to see that. Why did Zach close the thread ? Is he bored of this discussion ? He can ignore it. Bored of being asked that ? It’s a recurrent question in reddit and in blogs. But this issue is the only mention of the subject on Quicklisp’s website and repository. Closing it makes it much less visible.
Thus it is more likely newcomers will ask again. It’s sure newcomers won’t learn why Quicklisp works like it does, which appears in good light in that issue (and below in reddit). What happened is again a thing that makes the CL world impenetrable (or with great effort) and subject to rants. It doesn’t need more reasons, seriously.
I wouldn’t bother if this subject was documented, but it is not. The issue about documenting Quicklisp, which Zach wanted to fix “soon”, stalls since 2014. It’s still open, at least.
Final links, with a glimpse of light:
Qi, a Common Lisp package manager in the making - more traditional, no surprises - didn’t try.

Testing - in a nutshell
MonkeyUser 22 08 2017
We had a large codebase and a lot of tests. Unfortunately, a lot of our tests were a relic from when we were using fixtures extensively. In this article, we describe a different approach that reduced the number of fixtures we maintain.

Interview vs. Reality
MonkeyUser 15 08 2017
Flavours of prayer
James Sinclair 08 08 2017

Future Self
MonkeyUser 08 08 2017

Refactor Man
MonkeyUser 01 08 2017
or “Common Lisp is not very functional-programming oriented”. What are the options ?
I mean, map is uncommon and there is no short words like take etc
for functional composition. Right ?
edit see those snippets.
edit january, 2019: see this SO answer and the modf library.
Map and filter
Indeed, there are 8 or so map functions. The one we’re used to is
mapcar. The simple map needs a second argument to specify its return
type: (map 'list (lambda…. “filter” is named remove-if-not.
mapcan can also be useful. It concatenates the items into one
list. So with mapcar we get a list of lists with our items, with
mapcan simply a list of our items.
=> improved in cl21. It defines the usual map
and keep-if and more functional verbs: take, drop, take-while,
drop-while, butlast, sum,… in addition to fill, last,
find-if[-not], remove-if[-not], delete[-if[-not]], reverse,
reduce, sort, remove-duplicates, every, some,…
Note: remember that we still have access to cl symbols in CL21.
Functional composition
Lack of functional composition ? There is the Series library since 1989 that seems great, it lets us “write our program in a functional style without any runtime penalty at all !” [malisper on his blog post]
But yes again, it has not the modern vocabulary we expect and it seems abandonware (and its documentation is an old pdf paper but now hopefully this wiki is better).
edit 2021: GTWIWTG is a “generators” library similar in scope from Series, with modern idioms, but probably not as efficient. BTW, there are now lots of Series example snippets in the Cookbook/iteration page.
CL21 has an operator to compose functions: https://github.com/cl21/cl21/wiki/Language-Difference-between-CL21-and-Common-Lisp#function
Threading macros (pipes)
We have two packages in Quicklisp:
- cl-arrows defines
->,->>and the generalized ones-<>and-<>>. At the time of writing it has two unanswered PRs to add more, like the “when-guarded”-“nil shortcuting diamond wand”some->. - arrow-macros is a bit more
complete but has more dependencies (it needs a code walker) which
are not portable (failed on ECL, Allegro, ABCL, Clisp). It has the
some->,cond->andas->ones.
Data structures
We have the nice FSet, the functional collection for Common Lisp.
Anaphoric macros (for shorter lambdas)
I like anaphoric macros but I didn’t find one ready to use in a library to write shorter lambdas. The first macro I wrote was directly to mimick elisp’s dash.el excellent library:
(defmacro --map (form list)
`(mapcar (lambda (it) ,form) ,list))
so than we can write
(--map (* it 2) '(2 3))
instead of (mapcar (lambda (it) (* it 2) '(2 3))).
This macro is very simple. It should be in a library, I don’t want to copy-paste it in every project of mine. => in CL21 ? In Anaphora ?
=> Personnally I’m very happy with cl21’s short lambdas (that were not documented…):
(map ^(foo-bar %) items)
or with (lm (x)…. Unused arguments will be ignored automatically.
I also quite like the Arc way of doing, that I found in the Clamp project. Arc is another language and Clamp is more of a POC I guess.
For shorter lambdas we also have f-underscore, that I see used in the wild. It defines some macros to write shorter lambdas:
fis a synonym for lambdaf0is a lambda that takes 0 argumentsf_takes one, accessible in_(underscore)f_ntakes one&restargumentf_%ignores its rest argumentmis a lambda “that has a macro-lambda-list instead of an ordinary lambda-list”.
You might like Trivia for pattern matching too.
Hope this helps !
Data Structures
Lisp journey 27 07 2017
What the heck are alists and plists exactly, how do we manipulate data structures ? It seems tedious sometimes, are there helpers ?
Best read in the Cookbook.
We hope to give here a clear reference of the common data structures. To really learn the language, you should take the time to read other resources. The following ones, which we relied upon, have many more details:
- Practical CL, by Peter Seibel
- CL Recipes, by E. Weitz, full of explanations and tips,
- the CL standard with a nice TOC, functions reference, extensive descriptions, more examples and warnings (i.e: everything).
- a Common Lisp quick reference
Table of Contents
- Building lists. Cons cells, lists.
- car/cdr or first/rest (and second… to tenth)
- last, butlast, nbutlast (&optional n)
- reverse, nreverse
- append
- push (item, place)
- pop
- nthcdr (index, list)
- car/cdr and composites (cadr, caadr…) - accessing lists inside lists
- destructuring-bind (parameter*, list)
- Predicates: null, listp
- ldiff, tailp, list*, make-list, fill, revappend, nreconc, consp, atom
- Sequences
- Predicates: every, some,…
- Functions
- length (sequence)
- member (elt, sequence)
- elt (sequence, index)
- count (foo sequence)
- subseq (sequence start, [end])
- sort, stable-sort (sequence, test [, key function])
- find, position (foo, sequence)
- search (sequence-a, sequence-b)
- substitute, nsubstitute[if,if-not]
- sort, stable-sort, merge
- replace (sequence-a, sequence-b)
- remove, delete (foo sequence)
- mapping (map, mapcar, remove-if[-not],…)
- Flatten a list (Alexandria)
- Creating lists with variables
- Comparing lists
- Set
- Fset - immutable data structure
- Arrays and vectors
- Hash Table
- Alist
- Plist
- Tree
Lists
Building lists. Cons cells, lists.
A list is also a sequence, so we can use the functions shown below.
The list basic element is the cons cell. We build lists by assembling cons cells.
(cons 1 2)
;; => (1 . 2) ;; representation with a point, a dotted pair.
It looks like this:
[o|o]--- 2
|
1
If the cdr of the first cell is another cons cell, and if the cdr of
this last one is nil, we build a list:
(cons 1 (cons 2 nil))
;; => (1 2)
It looks like this:
[o|o]---[o|/]
| |
1 2
(ascii art by draw-cons-tree).
See that the representation is not a dotted pair ? The Lisp printer understands the convention.
Finally we can simply build a literal list with list:
(list 1 2)
;; => (1 2)
or by calling quote:
'(1 2)
;; => (1 2)
which is shorthand notation for the function call (quote (1 2)).
car/cdr or first/rest (and second… to tenth)
(car (cons 1 2)) ;; => 1
(cdr (cons 1 2)) ;; => 2
(first (cons 1 2)) ;; => 1
(first '(1 2 3)) ;; => 1
(rest '(1 2 3)) ;; => (2 3)
We can assign any new value with setf.
last, butlast, nbutlast (&optional n)
return the last cons cell in a list (or the nth last cons cells).
(last '(1 2 3))
;; => (3)
(car (last '(1 2 3)) )
;; => 3
(butlast '(1 2 3))
;; => (1 2)
reverse, nreverse
reverse and nreverse return a new sequence.
nreverse is destructive. The N stands for non-consing, meaning
it doesn’t need to allocate any new cons cells. It might (but in
practice, does) reuse and modify the original sequence:
(defparameter mylist '(1 2 3))
;; => (1 2 3)
(reverse mylist)
;; => (3 2 1)
mylist
;; => (1 2 3)
(nreverse mylist)
;; => (3 2 1)
mylist
;; => (1) in SBCL but implementation dependant.
append
append takes any number of list arguments and returns a new list
containing the elements of all its arguments:
(append (list 1 2) (list 3 4))
;; => (1 2 3 4)
The new list shares some cons cells with the (3 4):
http://gigamonkeys.com/book/figures/after-append.png
{kind=link}
Note: cl21’s append is generic (for strings, lists, vectors and
its abstract-sequence).
nconc is the recycling equivalent.
push (item, place)
push prepends item to the list that is stored in place, stores
the resulting list in place, and returns the list.
(defparameter mylist '(1 2 3))
(push 0 mylist)
;; => (0 1 2 3)
(defparameter x ’(a (b c) d))
;; => (A (B C) D)
(push 5 (cadr x))
;; => (5 B C)
x
;; => (A (5 B C) D)
push is equivalent to (setf place (cons item place )) except that
the subforms of place are evaluated only once, and item is evaluated
before place.
There is no built-in function to add to the end of a list. It is a
more costly operation (have to traverse the whole list). So if you
need to do this: either consider using another data structure, either
just reverse your list when needed.
pop
a destructive operation.
nthcdr (index, list)
Use this if first, second and the rest up to tenth are not
enough.
car/cdr and composites (cadr, caadr…) - accessing lists inside lists
They make sense when applied to lists containing other lists.
(caar (list 1 2 3)) ==> error
(caar (list (list 1 2) 3)) ==> 1
(cadr (list (list 1 2) (list 3 4))) ==> (3 4)
(caadr (list (list 1 2) (list 3 4))) ==> 3
destructuring-bind (parameter*, list)
It binds the parameter values to the list elements. We can destructure trees, plists and even provide defaults.
Simple matching:
(destructuring-bind (x y z) (list 1 2 3)
(list :x x :y y :z z))
;; => (:X 1 :Y 2 :Z 3)
Matching inside sublists:
(destructuring-bind (x (y1 y2) z) (list 1 (list 2 20) 3)
(list :x x :y1 y1 :y2 y2 :z z))
;; => (:X 1 :Y1 2 :Y2 20 :Z 3)
The parameter list can use the usual &optional, &rest and &key
parameters.
(destructuring-bind (x (y1 &optional y2) z) (list 1 (list 2) 3)
(list :x x :y1 y1 :y2 y2 :z z))
;; => (:X 1 :Y1 2 :Y2 NIL :Z 3)
(destructuring-bind (&key x y z) (list :z 1 :y 2 :x 3)
(list :x x :y y :z z))
;; => (:X 3 :Y 2 :Z 1)
The &whole parameter is bound to the whole list. It must be the
first one and others can follow.
(destructuring-bind (&whole whole-list &key x y z) (list :z 1 :y 2 :x 3)
(list :x x :y y :z z :whole whole-list))
;; => (:X 3 :Y 2 :Z 1 :WHOLE-LIST (:Z 1 :Y 2 :X 3))
Destructuring a plist, giving defaults:
(example from Common Lisp Recipes, by E. Weitz, Apress, 2016)
(destructuring-bind (&key a (b :not-found) c
&allow-other-keys)
’(:c 23 :d "D" :a #\A :foo :whatever)
(list a b c))
;; => (#\A :NOT-FOUND 23)
If this gives you the will to do pattern matching, see pattern matching.
Predicates: null, listp
null is equivalent to not, but considered better style.
listp tests wether an object is a cons cell or nil.
and sequences’ predicates.
ldiff, tailp, list*, make-list, fill, revappend, nreconc, consp, atom
(make-list 3 :initial-element "ta")
;; => ("ta" "ta" "ta")
(make-list 3)
;; => (NIL NIL NIL)
(fill * "hello")
;; => ("hello" "hello" "hello")
Sequences
lists and vectors (and thus strings) are sequences.
Note: see also the strings page.
Many of the sequence functions take keyword arguments. All keyword arguments are optional and, if specified, may appear in any order.
Pay attention to the :test argument. It defaults to eql (for
strings, use :equal).
The :key argument should be passed either nil, or a function of one
argument. This key function is used as a filter through which the
elements of the sequence are seen. For instance, this:
(find x y :key 'car)
is similar to (assoc* x y): It searches for an element of the list
whose car equals x, rather than for an element which equals x
itself. If :key is omitted or nil, the filter is effectively the
identity function.
Example with an alist (see definition below):
(defparameter my-alist (list (cons 'foo "foo")
(cons 'bar "bar")))
;; => ((FOO . "foo") (BAR . "bar"))
(find 'bar my-alist)
;; => NIL
(find 'bar my-alist :key 'car)
;; => (BAR . "bar")
For more, use a lambda that takes one parameter.
(find 'bar my-alist :key (lambda (it) (car it)))
Note: and cl21 has short lambdas:
(find 'bar my-alist :key ^(car %))
(find 'bar my-alist :key (lm (it) (car it)))
Predicates: every, some,…
every, notevery (test, sequence): return nil or t, respectively, as
soon as one test on any set of the corresponding elements of sequences
returns nil.
(defparameter foo '(1 2 3))
(every #'evenp foo)
;; => NIL
(some #'evenp foo)
;; => T
with a list of strings:
(defparameter str '("foo" "bar" "team"))
(every #'stringp str)
;; => T
(some #'(lambda (it) (= 3 (length it))) str)
;; => T
(some ^(= 3 (length %)) str) ;; in CL21
;; => T
some, notany (test, sequence): return either the value of the test, or nil.
mismatch (sequence-a, sequence-b): Return position in sequence-a where
sequence-a and sequence-b begin to mismatch. Return NIL if they match
entirely. Other parameters: :from-end bool, :start1, :start2 and
their :end[1,2].
Functions
See also sequence functions defined in
Alexandria:
starts-with, ends-with, ends-with-subseq, length=, emptyp,…
length (sequence)
member (elt, sequence)
elt (sequence, index)
beware, here the sequence comes first.
count (foo sequence)
Return the number of elements in sequence that match foo.
Additional paramaters: :from-end, :start, :end.
See also count-if, count-not (test-function sequence).
subseq (sequence start, [end])
It is “setf”able, but only works if the new sequence has the same length of the one to replace.
sort, stable-sort (sequence, test [, key function])
find, position (foo, sequence)
also find-if, find-if-not, position-if, position-if-not (test
sequence). See :key and :test parameters.
search (sequence-a, sequence-b)
Search sequence-b for a subsequence matching sequence-a. Return
position in sequence-b, or NIL. Has the from-end, end1/2 and others
parameters.
substitute, nsubstitute[if,if-not]
sort, stable-sort, merge
replace (sequence-a, sequence-b)
Replace elements of sequence-a with elements of sequence-b.
remove, delete (foo sequence)
Make a copy of sequence without elements matching foo. Has
:start/end, :key and :count parameters.
delete is the recycling version of remove.
(remove "foo" '("foo" "bar" "foo") :test 'equal)
;; => ("bar")
see also remove-if[-not] below.
mapping (map, mapcar, remove-if[-not],…)
If you’re used to map and filter in other languages, you probably want
mapcar. But it only works on lists, so to iterate on vectors (and
produce either a vector or a list, use (map 'list function vector).
mapcar also accepts multiple lists with &rest more-seqs. The
mapping stops as soon as the shortest sequence runs out.
Note: cl21’s map is a generic mapcar for lists and vectors.
map takes the output-type as first argument ('list, 'vector or
'string):
(defparameter foo '(1 2 3))
(map 'list (lambda (it) (* 10 it)) foo)
reduce (function, sequence). Special parameter: :initial-value.
(reduce '- '(1 2 3 4))
;; => -8
(reduce '- '(1 2 3 4) :initial-value 100)
;; => 90
Filter is here called remove-if-not.
Flatten a list (Alexandria)
With
Alexandria,
we have the flatten function.
Creating lists with variables
That’s one use of the backquote:
(defparameter *var* "bar")
;; First try:
'("foo" *var* "baz") ;; no backquote
;; => ("foo" *VAR* "baz") ;; nope
Second try, with backquote interpolation:
`("foo" ,*var* "baz") ;; backquote, comma
;; => ("foo" "bar" "baz") ;; good
The backquote first warns we’ll do interpolation, the comma introduces the value of the variable.
If our variable is a list:
(defparameter *var* '("bar" "baz"))
;; First try:
`("foo" ,*var*)
;; => ("foo" ("bar" "baz")) ;; nested list
`("foo" ,@*var*) ;; backquote, comma-@ to
;; => ("foo" "bar" "baz")
E. Weitz warns that “objects generated this way will very likely share structure (see Recipe 2-7)“.
Comparing lists
We can use sets functions.
Set
intersection
What elements are both in list-a and list-b ?
(defparameter list-a '(0 1 2 3))
(defparameter list-b '(0 2 4))
(intersection list-a list-b)
;; => (2 0)
set-difference
Remove the elements of list-b from list-a:
(set-difference list-a list-b)
;; => (3 1)
(set-difference list-b list-a)
;; => (4)
union
join the two lists:
(union list-a list-b)
;; => (3 1 0 2 4) ;; order can be different in your lisp
set-exclusive-or
Remove the elements that are in both lists:
(set-exclusive-or list-a list-b)
;; => (4 3 1)
and their recycling “n” counterpart (nintersection,…).
See also functions in
Alexandria:
setp, set-equal,…
Fset - immutable data structure
You may want to have a look at the FSet library (in Quicklisp).
Arrays and vectors
Arrays have constant-time access characteristics.
They can be fixed or adjustable. A simple array is neither displaced
(using :displaced-to, to point to another array) nor adjustable
(:adjust-array), nor does it have a fill pointer (fill-pointer,
that moves when we add or remove elements).
A vector is an array with rank 1 (of one dimension). It is also a sequence (see above).
A simple vector is a simple array that is also not specialized (it
doesn’t use :element-type to set the types of the elements).
Create an array, one or many dimensions
make-array (sizes-list :adjustable bool)
adjust-array (array, sizes-list, :element-type, :initial-element)
Access: aref (array i [j …])
aref (array i j k …) or row-major-aref (array i) equivalent to
(aref i i i …).
The result is setfable.
(defparameter myarray (make-array '(2 2 2) :initial-element 1))
myarray
;; => #3A(((1 1) (1 1)) ((1 1) (1 1)))
(aref myarray 0 0 0)
;; => 1
(setf (aref myarray 0 0 0) 9)
;; => 9
(row-major-aref myarray 0)
;; => 9
Sizes
array-total-size (array): how many elements will fit in the array ?
array-dimensions (array): list containing the length of the array’s dimensions.
array-dimension (array i): length of the *i*th dimension.
array-rank number of dimensions of the array.
(defparameter myarray (make-array '(2 2 2)))
;; => MYARRAY
myarray
;; => #3A(((0 0) (0 0)) ((0 0) (0 0)))
(array-rank myarray)
;; => 3
(array-dimensions myarray)
;; => (2 2 2)
(array-dimension myarray 0)
;; => 2
(array-total-size myarray)
;; => 8
Vectors
Create with vector or the reader macro #(). It returns a simple
vector.
(vector 1 2 3)
;; => #(1 2 3)
#(1 2 3)
;; => #(1 2 3)
vector-push (foo vector): replace the vector element pointed to by
the fill pointer by foo. Can be destructive.
vector-push-extend *(foo vector [extension-num])*t
vector-pop (vector): return the element of vector its fill pointer
points to.
fill-pointer (vector). setfable.
and see also the sequence functions.
Transforming a vector to a list.
If you’re mapping over it, see the map function whose first parameter
is the result type.
Or use (coerce vector 'list).
Hash Table
Hash Tables are a powerful data structure, associating keys with values in a very efficient way. Hash Tables are often preferred over association lists whenever performance is an issue, but they introduce a little overhead that makes assoc lists better if there are only a few key-value pairs to maintain.
Alists can be used sometimes differently though:
- they can be ordered
- we can push cons cells that have the same key, remove the one in front and we have a stack
- they have a human-readable printed representation
- they can be easily (de)serialized
- because of RASSOC, keys and values in alists are essentially interchangeable; whereas in hash tables, keys and values play very different roles (as usual, see CL Recipes for more).
Creating a Hash Table
Hash Tables are created using the function
make-hash-table. It
has no required argument. Its most used optional keyword argument is
:test, specifying the function used to test the equality of keys.
If we are using the cl21 extension library, we can
create a hash table and add elements in the same time with the new
#H reader syntax:
(defparameter *my-hash* #H(:name "Eitaro Fukamachi"))
then we access an element with
(getf *my-hash* :name)
Getting a value from a Hash Table
The function
gethash
takes two required arguments: a key and a hash table. It returns two
values: the value corresponding to the key in the hash table (or nil
if not found), and a boolean indicating whether the key was found in
the table. That second value is necessary since nil is a valid value
in a key-value pair, so getting nil as first value from gethash
does not necessarily mean that the key was not found in the table.
Getting a key that does not exist with a default value
gethash has an optional third argument:
(gethash 'bar *my-hash* "default-bar")
;; => "default-bar"
;; NIL
Getting all keys or all values of a hash table
The
Alexandria
library (in Quicklisp) has the functions hash-table-keys and
hash-table-values for that.
(ql:quickload :alexandria)
;; […]
(alexandria:hash-table-keys *my-hash*)
;; => (BAR)
Adding an Element to a Hash Table
If you want to add an element to a hash table, you can use gethash,
the function to retrieve elements from the hash table, in conjunction
with
setf.
CL-USER> (defparameter *my-hash* (make-hash-table))
*MY-HASH*
CL-USER> (setf (gethash 'one-entry *my-hash*) "one")
"one"
CL-USER> (setf (gethash 'another-entry *my-hash*) 2/4)
1/2
CL-USER> (gethash 'one-entry *my-hash*)
"one"
T
CL-USER> (gethash 'another-entry *my-hash*)
1/2
T
Testing for the Presence of a Key in a Hash Table
The first value returned by gethash is the object in the hash table
that’s associated with the key you provided as an argument to
gethash or nil if no value exists for this key. This value can act
as a
generalized boolean if you want to test for the presence of keys.
CL-USER> (defparameter *my-hash* (make-hash-table))
*MY-HASH*
CL-USER> (setf (gethash 'one-entry *my-hash*) "one")
"one"
CL-USER> (if (gethash 'one-entry *my-hash*)
"Key exists"
"Key does not exist")
"Key exists"
CL-USER> (if (gethash 'another-entry *my-hash*)
"Key exists"
"Key does not exist")
"Key does not exist"
But note that this does not work if nil is amongst the values that
you want to store in the hash.
CL-USER> (setf (gethash 'another-entry *my-hash*) nil)
NIL
CL-USER> (if (gethash 'another-entry *my-hash*)
"Key exists"
"Key does not exist")
"Key does not exist"
In this case you’ll have to check the second return value of gethash which will always return nil if no value is found and T otherwise.
CL-USER> (if (nth-value 1 (gethash 'another-entry *my-hash*))
"Key exists"
"Key does not exist")
"Key exists"
CL-USER> (if (nth-value 1 (gethash 'no-entry *my-hash*))
"Key exists"
"Key does not exist")
"Key does not exist"
Deleting from a Hash Table
Use
remhash
to delete a hash entry. Both the key and its associated value will be
removed from the hash table. remhash returns T if there was such an
entry, nil otherwise.
CL-USER> (defparameter *my-hash* (make-hash-table))
*MY-HASH*
CL-USER> (setf (gethash 'first-key *my-hash*) 'one)
ONE
CL-USER> (gethash 'first-key *my-hash*)
ONE
T
CL-USER> (remhash 'first-key *my-hash*)
T
CL-USER> (gethash 'first-key *my-hash*)
NIL
NIL
CL-USER> (gethash 'no-entry *my-hash*)
NIL
NIL
CL-USER> (remhash 'no-entry *my-hash*)
NIL
CL-USER> (gethash 'no-entry *my-hash*)
NIL
NIL
Traversing a Hash Table
If you want to perform an action on each entry (i.e., each key-value pair) in a hash table, you have several options:
You can use
maphash
which iterates over all entries in the hash table. Its first argument
must be a function which accepts two arguments, the key and the
value of each entry. Note that due to the nature of hash tables you
can’t control the order in which the entries are provided by
maphash (or other traversing constructs). maphash always returns
nil.
CL-USER> (defparameter *my-hash* (make-hash-table))
*MY-HASH*
CL-USER> (setf (gethash 'first-key *my-hash*) 'one)
ONE
CL-USER> (setf (gethash 'second-key *my-hash*) 'two)
TWO
CL-USER> (setf (gethash 'third-key *my-hash*) nil)
NIL
CL-USER> (setf (gethash nil *my-hash*) 'nil-value)
NIL-VALUE
CL-USER> (defun print-hash-entry (key value)
(format t "The value associated with the key ~S is ~S~%" key value))
PRINT-HASH-ENTRY
CL-USER> (maphash #'print-hash-entry *my-hash*)
The value associated with the key FIRST-KEY is ONE
The value associated with the key SECOND-KEY is TWO
The value associated with the key THIRD-KEY is NIL
The value associated with the key NIL is NIL-VALUE
You can also use
with-hash-table-iterator,
a macro which turns (via
macrolet)
its first argument into an iterator that on each invocation returns
three values per hash table entry - a generalized boolean that’s true
if an entry is returned, the key of the entry, and the value of the
entry. If there are no more entries, only one value is returned -
nil.
;;; same hash-table as above
CL-USER> (with-hash-table-iterator (my-iterator *my-hash*)
(loop
(multiple-value-bind (entry-p key value)
(my-iterator)
(if entry-p
(print-hash-entry key value)
(return)))))
The value associated with the key FIRST-KEY is ONE
The value associated with the key SECOND-KEY is TWO
The value associated with the key THIRD-KEY is NIL
The value associated with the key NIL is NIL-VALUE
NIL
Note the following caveat from the HyperSpec: “It is unspecified what
happens if any of the implicit interior state of an iteration is
returned outside the dynamic extent of the with-hash-table-iterator
form such as by returning some closure over the invocation form.”
And there’s always loop:
;;; same hash-table as above
CL-USER> (loop for key being the hash-keys of *my-hash*
do (print key))
FIRST-KEY
SECOND-KEY
THIRD-KEY
NIL
NIL
CL-USER> (loop for key being the hash-keys of *my-hash*
using (hash-value value)
do (format t "The value associated with the key ~S is ~S~%" key value))
The value associated with the key FIRST-KEY is ONE
The value associated with the key SECOND-KEY is TWO
The value associated with the key THIRD-KEY is NIL
The value associated with the key NIL is NIL-VALUE
NIL
CL-USER> (loop for value being the hash-values of *my-hash*
do (print value))
ONE
TWO
NIL
NIL-VALUE
NIL
CL-USER> (loop for value being the hash-values of *my-hash*
using (hash-key key)
do (format t "~&~A -> ~A" key value))
FIRST-KEY -> ONE
SECOND-KEY -> TWO
THIRD-KEY -> NIL
NIL -> NIL-VALUE
NIL
Last, we also have cl21’s (doeach ((key val) *hash*) …).
Traversign keys or values
To map over keys or values we can again rely on Alexandria with
maphash-keys and maphash-values.
Counting the Entries in a Hash Table
No need to use your fingers - Common Lisp has a built-in function to
do it for you:
hash-table-count.
CL-USER> (defparameter *my-hash* (make-hash-table))
*MY-HASH*
CL-USER> (hash-table-count *my-hash*)
0
CL-USER> (setf (gethash 'first *my-hash*) 1)
1
CL-USER> (setf (gethash 'second *my-hash*) 2)
2
CL-USER> (setf (gethash 'third *my-hash*) 3)
3
CL-USER> (hash-table-count *my-hash*)
3
CL-USER> (setf (gethash 'second *my-hash*) 'two)
TWO
CL-USER> (hash-table-count *my-hash*)
3
CL-USER> (clrhash *my-hash*)
#<EQL hash table, 0 entries {48205F35}>
CL-USER> (hash-table-count *my-hash*)
0
Performance Issues: The Size of your Hash Table
The make-hash-table function has a couple of optional parameters
which control the initial size of your hash table and how it’ll grow
if it needs to grow. This can be an important performance issue if
you’re working with large hash tables. Here’s an (admittedly not very
scientific) example with CMUCL pre-18d on
Linux:
CL-USER> (defparameter *my-hash* (make-hash-table))
*MY-HASH*
CL-USER> (hash-table-size *my-hash*)
65
CL-USER> (hash-table-rehash-size *my-hash*)
1.5
CL-USER> (time (dotimes (n 100000) (setf (gethash n *my-hash*) n)))
Compiling LAMBDA NIL:
Compiling Top-Level Form:
Evaluation took:
0.27 seconds of real time
0.25 seconds of user run time
0.02 seconds of system run time
0 page faults and
8754768 bytes consed.
NIL
CL-USER> (time (dotimes (n 100000) (setf (gethash n *my-hash*) n)))
Compiling LAMBDA NIL:
Compiling Top-Level Form:
Evaluation took:
0.05 seconds of real time
0.05 seconds of user run time
0.0 seconds of system run time
0 page faults and
0 bytes consed.
NIL
The values for
hash-table-size
and
hash-table-rehash-size
are implementation-dependent. In our case, CMUCL chooses and initial
size of 65, and it will increase the size of the hash by 50 percent
whenever it needs to grow. Let’s see how often we have to re-size the
hash until we reach the final size…
CL-USER> (log (/ 100000 65) 1.5)
18.099062
CL-USER> (let ((size 65)) (dotimes (n 20) (print (list n size)) (setq size (* 1.5 size))))
(0 65)
(1 97.5)
(2 146.25)
(3 219.375)
(4 329.0625)
(5 493.59375)
(6 740.3906)
(7 1110.5859)
(8 1665.8789)
(9 2498.8184)
(10 3748.2275)
(11 5622.3413)
(12 8433.512)
(13 12650.268)
(14 18975.402)
(15 28463.104)
(16 42694.656)
(17 64041.984)
(18 96062.98)
(19 144094.47)
NIL
The hash has to be re-sized 19 times until it’s big enough to hold 100,000 entries. That explains why we saw a lot of consing and why it took rather long to fill the hash table. It also explains why the second run was much faster - the hash table already had the correct size.
Here’s a faster way to do it: If we know in advance how big our hash will be, we can start with the right size:
CL-USER> (defparameter *my-hash* (make-hash-table :size 100000))
*MY-HASH*
CL-USER> (hash-table-size *my-hash*)
100000
CL-USER> (time (dotimes (n 100000) (setf (gethash n *my-hash*) n)))
Compiling LAMBDA NIL:
Compiling Top-Level Form:
Evaluation took:
0.04 seconds of real time
0.04 seconds of user run time
0.0 seconds of system run time
0 page faults and
0 bytes consed.
NIL
That’s obviously much faster. And there was no consing involved
because we didn’t have to re-size at all. If we don’t know the final
size in advance but can guess the growth behaviour of our hash table
we can also provide this value to make-hash-table. We can provide an
integer to specify absolute growth or a float to specify relative
growth.
CL-USER> (defparameter *my-hash* (make-hash-table :rehash-size 100000))
*MY-HASH*
CL-USER> (hash-table-size *my-hash*)
65
CL-USER> (hash-table-rehash-size *my-hash*)
100000
CL-USER> (time (dotimes (n 100000) (setf (gethash n *my-hash*) n)))
Compiling LAMBDA NIL:
Compiling Top-Level Form:
Evaluation took:
0.07 seconds of real time
0.05 seconds of user run time
0.01 seconds of system run time
0 page faults and
2001360 bytes consed.
NIL
Also rather fast (we only needed one re-size) but much more consing because almost the whole hash table (minus 65 initial elements) had to be built during the loop.
Note that you can also specify the rehash-threshold while creating a
new hash table. One final remark: Your implementation is allowed to
completely ignore the values provided for rehash-size and
rehash-threshold…
Alist
An association list is a list of cons cells.
This simple example:
(defparameter my-alist (list (cons 'foo "foo")
(cons 'bar "bar")))
;; => ((FOO . "foo") (BAR . "bar"))
looks like this:
[o|o]---[o|/]
| |
| [o|o]---"bar"
| |
| BAR
|
[o|o]---"foo"
|
FOO
The constructor pairlis associates a list of keys and a list of values:
(pairlis '(:foo :bar)
'("foo" "bar"))
;; => ((:BAR . "bar") (:FOO . "foo"))
To get a key, we have assoc (use :test 'equal when your keys are
strings, as usual). It returns the whole cons cell, so you may want to
use cdr or second to get the value. There is assoc-if, and
rassoc to get a cons cell by its value.
To add a key, we push another cons cell:
(push (cons 'team "team") my-alist)
;; => ((TEAM . "team") (FOO . "foo") (BAR . "bar"))
We can use pop and other functions that operate on lists, like remove:
(remove :team my-alist)
;; => ((:TEAM . "team") (FOO . "foo") (BAR . "bar")) ;; didn't remove anything
(remove :team my-alist :key 'car)
;; => ((FOO . "foo") (BAR . "bar")) ;; returns a copy
Remove only one element with :count:
(push (cons 'bar "bar2") my-alist)
;; => ((BAR . "bar2") (TEAM . "team") (FOO . "foo") (BAR . "bar")) ;; twice the 'bar key
(remove 'bar my-alist :key 'car :count 1)
;; => ((TEAM . "team") (FOO . "foo") (BAR . "bar"))
;; because otherwise:
(remove 'bar my-alist :key 'car)
;; => ((TEAM . "team") (FOO . "foo")) ;; no more 'bar
In the
Alexandria
library, see some functions like remove-from-plist, alist-plist,…
Plist
A property list is simply a list that alternates a key, a value, and
so on, where its keys are symbols (we can not set its :test). More
precisely, it first has a cons cell whose car is the key, whose
cdr points to the following cons cell whose car is the
value.
For example this plist:
(defparameter my-plist (list 'foo "foo" 'bar "bar"))
looks like this:
[o|o]---[o|o]---[o|o]---[o|/]
| | | |
FOO "foo" BAR "bar"
We access an element with getf (list elt) (it returns the value)
(the list comes as first element),
we remove an element with remf.
(defparameter my-plist (list 'foo "foo" 'bar "bar"))
;; => (FOO "foo" BAR "bar")
(setf (getf my-plist 'foo) "foo!!!")
;; => "foo!!!"
Tree
tree-equal, copy-tree. They descend recursively into the car and
the cdr of the cons cells they visit.
Sycamore - purely functional weight-balanced binary trees
https://github.com/ndantam/sycamore
Features:
- Fast, purely functional weight-balanced binary trees.
- Leaf nodes are simple-vectors, greatly reducing tree height.
- Interfaces for tree Sets and Maps (dictionaries).
- Ropes
- Purely functional pairing heaps
- Purely functional amortized queue.
See more in other resources !

A Programmer Walks Into A Bar
MonkeyUser 26 07 2017
![]()
Fingerprinting
WhoTracksMe blog 21 07 2017
![]()
![]()
Tracker Categories
WhoTracksMe blog 21 07 2017
![]()
Where does the data come from?
WhoTracksMe blog 21 07 2017
![]()
Tracking Pixel
WhoTracksMe blog 21 07 2017
![]()
What is a tracker?
WhoTracksMe blog 21 07 2017
![]()
Cookies
WhoTracksMe blog 21 07 2017
![]()

Bottom of the backlog
MonkeyUser 18 07 2017

Big Decisions
MonkeyUser 10 07 2017
The days of desktop systems serving single users are long gone. Web applications nowadays are serving millions of users at the same time. With many users comes a wide range of new problems: concurrency problems. In this article we describe two approaches for managing concurrency in Django models.

NPM Delivery
MonkeyUser 04 07 2017

Common Lisp Async Web Scraping
Lisp journey 29 06 2017
The set of tools to do web scraping in Common Lisp is pretty complete and pleasant. In this short tutorial we’ll see how to make http requests, parse html, extract content and do asynchronous requests.
Our simple task will be to extract the list of links on the CL Cookbook’s index page and check if they are reachable.
Best read in the Cookbook !
We’ll use the following libraries:
- Dexador - an HTTP client (that aims at replacing the venerable Drakma),
- Plump - a markup parser, that works on malformed HTML,
- Lquery - a DOM manipulation library, to extract content from our Plump result,
- lparallel - a library for parallel programming (read more in the process section).
Before starting let’s install those libraries with Quicklisp:
(ql:quickload '(:dexador :plump :lquery :lparallel))
Table of Contents
HTTP Requests
Easy things first. Install Dexador. Then we use the get function:
(defvar *url* "https://lispcookbook.github.io/cl-cookbook/")
(defvar *request* (dex:get *url*))
This returns a list of values: the whole page content, the return code (200), the response headers, the uri and the stream.
"<!DOCTYPE html>
<html lang=\"en\">
<head>
<title>Home – the Common Lisp Cookbook</title>
[…]
"
200
#<HASH-TABLE :TEST EQUAL :COUNT 19 {1008BF3043}>
#<QURI.URI.HTTP:URI-HTTPS https://lispcookbook.github.io/cl-cookbook/>
#<CL+SSL::SSL-STREAM for #<FD-STREAM for "socket 192.168.0.23:34897, peer: 151.101.120.133:443" {100781C133}>>
Remember, in Slime we can inspect the objects with a right-click on them.
Parsing and extracting content with CSS selectors
We’ll use Plump to parse the html and Lquery to extract
content. They have nice documentation:
(defvar *parsed-content* (plump:parse *request*))
;; => *PARSED-CONTENT**
*parsed-content**
;; => #<PLUMP-DOM:ROOT {1009EE5FE3}>
Now we’ll extract the links with CSS selectors.
Note: to find out what should be the CSS selector of the element I’m interested in, I right click on an element in the browser and I choose “Inspect element”. This opens up the inspector of my browser’s web dev tool and I can study the page structure.
So the links I want to extract are in a page with an id of value
“content”, and they are in regular list elements (li).
Let’s try something:
(lquery:$ *parsed-content* "#content li")
;; => #(#<PLUMP-DOM:ELEMENT li {100B3263A3}> #<PLUMP-DOM:ELEMENT li {100B3263E3}>
;; #<PLUMP-DOM:ELEMENT li {100B326423}> #<PLUMP-DOM:ELEMENT li {100B326463}>
;; #<PLUMP-DOM:ELEMENT li {100B3264A3}> #<PLUMP-DOM:ELEMENT li {100B3264E3}>
;; #<PLUMP-DOM:ELEMENT li {100B326523}> #<PLUMP-DOM:ELEMENT li {100B326563}>
;; #<PLUMP-DOM:ELEMENT li {100B3265A3}> #<PLUMP-DOM:ELEMENT li {100B3265E3}>
;; #<PLUMP-DOM:ELEMENT li {100B326623}> #<PLUMP-DOM:ELEMENT li {100B326663}>
;; […]
Wow it works ! We get here a vector of plump elements.
Since it is a vector we could map over them with (map 'vector (lambda
(elt) (…)) *).
But I’d like to easily check what those elements are. To see their textual
content we can append (text) to our lquery form:
(lquery:$ *parsed-content* "#content" (text))
#("License" "Editor support" "Strings" "Dates and Times" "Hash Tables"
"Pattern Matching / Regular Expressions" "Functions" "Loop" "Input/Output"
"Files and Directories" "Packages" "Macros and Backquote"
"CLOS (the Common Lisp Object System)" "Sockets" "Interfacing with your OS"
"Foreign Function Interfaces" "Threads" "Defining Systems"
"Using the Win32 API" "Testing" "Miscellaneous" "License" "Marco Antoniotti"
"Zach Beane" "Pierpaolo Bernardi" "Christopher Brown" "Frederic Brunel"
"Jeff Caldwell" "Bill Clementson" "Martin Cracauer" "Gerald Doussot"
"Paul Foley" "Jörg-Cyril
[…]
"Edi Weitz" "Fernando Borretti" "lisp-lang.org" "The Awesome-cl list"
"The Common Lisp HyperSpec by Kent M. Pitman" "The Common Lisp UltraSpec"
"Practical Common Lisp by Peter Seibel"
"Common Lisp Recipes by Edmund Weitz, published in 2016,"
[…]
"A Tutorial on Good Lisp Style by Peter Norvig and Kent Pitman"
"Lisp and Elements of Style by Nick Levine"
"Pascal Costanza’s Highly Opinionated Guide to Lisp"
"Loving Lisp - the Savy Programmer’s Secret Weapon by Mark Watson"
"FranzInc, a company selling Common Lisp and Graph Database solutions.")
Allright, so we see we are manipulating what we want. Now to get their href, a quick look at lquery’s doc and:
(lquery:$ *parsed-content* "#content li a" (attr :href))
;; => #("license.html" "editor-support.html" "strings.html" "dates_and_times.html"
;; "hashes.html" "pattern_matching.html" "functions.html" "loop.html" "io.html"
;; "files.html" "packages.html" "macros.html"
;; "/cl-cookbook/clos-tutorial/index.html" "sockets.html" "os.html" "ffi.html"
;; "process.html" "systems.html" "win32.html" "testing.html" "misc.html"
;; "license.html" "mailto:xach@xach.com" "mailto:skeptomai@mac.com"
;; "mailto:brunel@mail.dotcom.fr" "mailto:jdcal@yahoo.com"
;; "mailto:bill_clementson@yahoo.com" "mailto:gdoussot@yahoo.com"
;; […]
;; "mailto:matthieu@matthieu-villeneuve.net" "mailto:edi@agharta.de"
;; "http://lisp-lang.org/" "https://github.com/CodyReichert/awesome-cl"
;; "http://www.lispworks.com/documentation/HyperSpec/Front/index.htm"
;; "http://phoe.tymoon.eu/clus/doku.php" "http://www.gigamonkeys.com/book/"
;; […]
;; "http://www.nicklevine.org/declarative/lectures/"
;; "http://www.p-cos.net/lisp/guide.html" "https://leanpub.com/lovinglisp/"
;; "https://franz.com/")
Nice, we now have the list (well, a vector) of links of the page. We’ll now write an async program to check and validate they are reachable.
External resources:
Async requests
In this example we’ll take the list of url from above and we’ll check if they are reachable. We want to do this asynchronously, but to see the benefits we’ll first do it synchronously !
We need a bit of filtering first to exclude the email adresses (maybe that was doable in the CSS selector ?).
We put the vector of urls in a variable:
(defvar *urls* (lquery:$ *parsed-content* "#content li a" (attr :href)))
We remove the elements that start with “mailto:”: (a quick look at the strings page will help)
(remove-if (lambda (it) (string= it "mailto:" :start1 0 :end1 (length "mailto:"))) *urls*)
;; => #("license.html" "editor-support.html" "strings.html" "dates_and_times.html"
;; […]
;; "process.html" "systems.html" "win32.html" "testing.html" "misc.html"
;; "license.html" "http://lisp-lang.org/"
;; "https://github.com/CodyReichert/awesome-cl"
;; "http://www.lispworks.com/documentation/HyperSpec/Front/index.htm"
;; […]
;; "https://franz.com/")
Actually before writting the remove-if (which works on any sequence,
including vectors) I tested with a (map 'vector …) to see that the
results where indeed nil or t.
As a side note, there is a handy starts-with-p function in
cl-strings (disclainer: that’s our lib),
available in Quicklisp. So we could do:
(map 'vector (lambda (it) (str:starts-with-p "mailto:" it)) *urls*)
it also has an option to ignore or respect the case.
While we’re at it, we’ll only consider links starting with “http”, in order not to write too much stuff irrelevant to web scraping:
(remove-if-not (lambda (it) (string= it "http" :start1 0 :end1 (length "http"))) *) ;; note the remove-if-NOT
Allright, we put this result in another variable:
(defvar *filtered-urls* *)
and now to the real work. For every url, we want to request it and check that its return code is 200. We have to ignore certain errors. Indeed, a request can timeout, be redirected (we don’t want that) or return an error code.
To be in real conditions we’ll add a link that times out in our list:
(setf (aref *filtered-urls* 0) "http://lisp.org") ;; too bad indeed
We’ll take the simple approach to ignore errors and return nil in
that case. If all goes well, we return the return code, that should be
200.
As we saw at the beginning, dex:get returns many values, including
the return code. We’ll catch only this one with nth-value (instead
of all of them with multiple-value-bind) and we’ll use
ignore-errors, that returns nil in case of an error. We could also
use handler-case and catch specific error types (see examples in
dexador’s documentation) or (better yet ?) use handler-bind to catch
any condition.
(ignore-errors has the caveat that when there’s an error, we can not return the element it comes from. We’ll get to our ends though.)
(map 'vector (lambda (it)
(ignore-errors
(nth-value 1 (dex:get it))))
*filtered-urls*)
we get:
#(NIL 200 200 200 200 200 200 200 200 200 200 NIL 200 200 200 200 200 200 200
200 200 200 200)
update: we could write something like the following with
handler-case to be more flexible:
(handler-case ( <code> )
(error (c)
( <return sthg> )))
it works, but it took a very long time. How much time precisely ?
with (time …):
Evaluation took:
21.554 seconds of real time
0.188000 seconds of total run time (0.172000 user, 0.016000 system)
0.87% CPU
55,912,081,589 processor cycles
9,279,664 bytes consed
21 seconds ! Obviously this synchronous method isn’t efficient. We wait 10 seconds for links that time out. It’s time to write and measure and async version.
After installing lparallel and looking at
its documentation, we see that the parallel
map pmap seems to be what we
want. And it’s only a one word edit. Let’s try:
(time (lparallel:pmap 'vector
(lambda (it)
(ignore-errors (let ((status (nth-value 1 (dex:get it)))) status)))
*filtered-urls*)
;; Evaluation took:
;; 11.584 seconds of real time
;; 0.156000 seconds of total run time (0.136000 user, 0.020000 system)
;; 1.35% CPU
;; 30,050,475,879 processor cycles
;; 7,241,616 bytes consed
;;
;;#(NIL 200 200 200 200 200 200 200 200 200 200 NIL 200 200 200 200 200 200 200
;; 200 200 200 200)
Bingo. It still takes more than 10 seconds because we wait 10 seconds for one request that times out. But otherwise it proceeds all the http requests in parallel and so it is much faster.
Shall we get the urls that aren’t reachable, remove them from our list and measure the execution time in the sync and async cases ?
What we do is: instead of returning only the return code, we check it is valid and we return the url:
... (if (and status (= 200 status)) it) ...
(defvar *valid-urls* *)
we get a vector of urls with a couple of nils: indeed, I thought I
would have only one unreachable url but I discovered another
one. Hopefully I have pushed a fix before you try this tutorial.
But what are they ? We saw the status codes but not the urls :S We have a vector with all the urls and another with the valid ones. We’ll simply treat them as sets and compute their difference. This will show us the bad ones. We must transform our vectors to lists for that.
(set-difference (coerce *filtered-urls* 'list)
(coerce *valid-urls* 'list))
;; => ("http://lisp-lang.org/" "http://www.psg.com/~dlamkins/sl/cover.html")
Gotcha !
BTW it takes 8.280 seconds of real time to me to check the list of valid urls synchronously, and 2.857 seconds async.
Have fun doing web scraping in CL !
More helpful libraries:
- we could use VCR, a store and replay utility to set up repeatable tests or to speed up a bit our experiments in the REPL.
- cl-async, carrier and others network, parallelism and concurrency libraries to see on the awesome-cl list, Cliki or Quickdocs.
- Mockingbird is nice to mock network requests in unit tests.

// TODO
MonkeyUser 27 06 2017

AdLitteram 30
MonkeyUser 23 06 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

Seeking Answer
MonkeyUser 20 06 2017
There is nothing built-in since CL predates the posix standard.
After a look at
Awesome CL, the
Osicat library
was my go-to package to look for such functionnality. There is its
osicat-posix package indeed, even though it is undocumented
(issue)…
Now a look at the Cookbook is ok.
osicat, osicat-posix
osicat-posix is included in osicat.
(ql:quickload :osicat)
(describe (osicat-posix:stat #P"/tmp/file"))
#<OSICAT-POSIX:STAT {1004F20C93}>
[standard-object]
Slots with :INSTANCE allocation:
DEV = 2065
INO = 7349974
MODE = 33204
NLINK = 1
UID = 1000
GID = 1000
RDEV = 0
SIZE = 4304
BLKSIZE = 4096
BLOCKS = 16
ATIME = 1497626097
MTIME = 1497347216
CTIME = 1497347216
; No value
and so we can access the slots with their related functions:
osicat-posix:stat-dev
osicat-posix:stat-gid
osicat-posix:stat-ino
osicat-posix:stat-uid
osicat-posix:stat-mode
osicat-posix:stat-rdev
osicat-posix:stat-size
osicat-posix:stat-atime
osicat-posix:stat-ctime
osicat-posix:stat-mtime
osicat-posix:stat-nlink
osicat-posix:stat-blocks
osicat-posix:stat-blksize
so for example:
(let ((stat (osicat-posix:stat #P"./files.md")))
(osicat-posix:stat-size stat)) ;; => 10629
Trivial-file-size
Now for the size there’s also the lightweight (and portable) trivial-file-size.
This library exports a single function, file-size-in-octets. It returns the size of a file in bytes, using system calls when possible.
The canonical way to determine the size of a file in bytes, using Common Lisp, is to open the file with an element type of (unsigned-byte 8) and then calculate the length of the stream. This is less than ideal. In most cases it would be better to get the size of the file from its metadata, using a system call.
The author new about osicat-posix.

AdLitteram 29
MonkeyUser 16 06 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

Keep Up To Date
MonkeyUser 13 06 2017

AdLitteram 28
MonkeyUser 09 06 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)
5 Ways to Make Django Admin Safer
Haki Benita 08 06 2017
With great power comes great responsibility. The more powerful your Django admin is, the safer it should be. Making a Django admin safer and more secure doesn't have to be hard - you just have to pay attention. In this article I present 5 ways to protect the Django Admin from human errors and attackers.

Open Source Issues
MonkeyUser 06 06 2017

Angular vs. React
MonkeyUser 30 05 2017
![]()

AdLitteram 27
MonkeyUser 26 05 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)
![]()

Code Review Stages
MonkeyUser 23 05 2017
![]()

AdLitteram 26
MonkeyUser 19 05 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

Code Progression
MonkeyUser 16 05 2017

AdLitteram 25
MonkeyUser 12 05 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)
I started my programming career as an Oracle DBA. It took a few years but eventually I got fed up with the corporate world and I went about doing my own thing. After I gotten over not having proper partitions and MERGE statement, I found some nice unique features in PostgreSQL. Oddly enough, a lot of them contained the word DISTINCT.

Unit Tests Coverage Degradation
MonkeyUser 09 05 2017

AdLitteram 24
MonkeyUser 05 05 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)
edit: I found Snooze (by Sly and Yasnippet’s author) easier and cleaner in this regard. It also has built-in settings to choose where to catch errors: with Slime’s debugger, with a full stacktrace in the browser or displaying a custom error page.
If you’re using Lucerne don’t search more like I did, its
with-params macro works with url query parameters (as well as POST
parameters).
If you’re accessing the url hello?search=kw, this works:
@route app "/hello"
(defview index (name)
(with-params (search)
(render-template (+index+)
:search search)))
An illustration with a POST parameter from the “utweet” example:
@route app (:post "/tweet")
(defview tweet ()
(if (lucerne-auth:logged-in-p)
(let ((user (current-user)))
(with-params (tweet)
(utweet.models:tweet user tweet))
(redirect "/"))
(render-template (+index+)
:error "You are not logged in.")))
The macro is implemented like this:
;; https://github.com/eudoxia0/lucerne/blob/master/src/http.lisp
(defmacro with-params (params &body body)
"Extract the parameters in @cl:param(param) from the @c(*request*), and bind
them for use in @cl:param(body)."
`(let ,(loop for param in params collecting
`(,param (let ((str (parameter *request*
,(intern (string-downcase
(symbol-name param))
:keyword))))
(if (equal str "")
nil
str))))
,@body))
For Caveman it is possible but a bit awkward and inconsistent.
There’s an example for Ningle on the related StackOverflow question.
And in Clack generally ?
It is only scarcely documented on Clack’s api documentation.
We can access the parameters with (clack.request:query-parameter
lucerne:*request*). So to get the value of a given param:
(assoc "a-param" (clack.request:query-parameter lucerne:*request*) :test 'string=)
and this returns the key and the value, so we need another cdr to get the value…
(defun query-param (param)
(cdr (assoc param (clack.request:query-parameter lucerne:*request*) :test #'string=)))
See also:
Looks like there is: trident-mode, an “Emacs minor mode for live Parenscript interaction”, based on skewer but: trident-mode doesn’t seem to be used in the wild (while skewer-mode is) and I don’t know Figwheel so all I can say is that it seems a bit different: instead of letting us selectively evaluate and send code to the browser, Figwheels seems to rebuild the entire project and send the result when we write a file.
I tried trident-mode quickly, it works and the author was responsive. It offers commands and shortcuts to see the Javascript code produced by Parenscript forms and (optionally) send them to the browser.
An example use:
((@ document write)
(ps-html ((:a :href "foobar") "blorg")))
to evaluate with trident-eval-dwim, which generates
document.write("<A HREF=\"foobar\">blorg</A>")
so it uses js to insert html into the DOM. It doesn’t leverage Skewer’s capacity to send only html.
I’ll update this post if/when I can.
builds your ClojureScript code and hot loads it into the browser as you are coding!
Skewer
Provides live interaction with JavaScript, CSS, and HTML in a web browser. Expressions are sent on-the-fly from an editing buffer to be evaluated in the browser, just like Emacs does with an inferior Lisp process in Lisp modes.
and we can also connect to sites on servers we don’t control.
They have demo videos.
or “could not find recent and easy installation steps [fixed]“.
When I started I was a bit confused by old instructions (google is not good at CL), so hopefully this post will help show up recent and easy steps and most of all, help every CL enthousiast discover Portacle.
(and this post is editable through its Gitlab repository)
Portable, a multiplatform development environment
The productive Shinmera was waiting for the last details to be fixed before showing Portacle but it was already great. On GNU/Linux, MacOs or Windows, just download an archive and click an icon to open Emacs ready to use for CL development. It is that easy.
It ships: Emacs (customized), the SBCL implementation, Slime (Emacs IDE), Quicklisp (package manager) and Git. Emacs comes with a nice theme, autocompletion in drop-downs (company-mode) and Magit.
Manual install
Lisp implementation
Install a CL implementation:
apt-get install sbcl
Now you can run sbcl and write lisp at the prompt:
(print "hello lisp!")
(quit) ;; or C-d
More are packaged for Debian and probably for your distro, notably ECL, and note that you can install more easily with Roswell.
If you find the prompt horribly unfriendly (no history, no navigation…) use rlwrap:
apt-get install rlwrap
and now this will be slightly better:
rwrap sbcl
Even better, a slight wrapper around the SBCL REPL with readline support (Emacs and Vim modes, history, etc): sbcli, straightforward to use.
But still, we really need an editor.
Editors support
You’re not bound to Emacs, there’s good support for Vim, Sublime Text (via the SublimeREPL package) and Atom.
See the Cookbook#editors.
For Emacs, Slime is the de-facto solution (there’s also the Sly fork). It is in the GNU Elpa default Emacs package repository, so:
M-x package-install RET slime RET
(you may need a M-x package-refresh-content).
Now start Slime with M-x slime and wait a few seconds that it starts
its backend (Swank server).
Might help:
- using Emacs (and other instructions): https://www.darkchestnut.com/2017/getting-started-with-common-lisp/#using-emacs
- http://wikemacs.org/wiki/Common_Lisp
- Slime manual: https://common-lisp.net/project/slime/doc/html/ (see
the Emacs menu). In very short: compile a file with
C-c C-k, compile one function withC-c C-cand use it at the REPL.
Quicklisp package manager
To install Quicklisp:
from anywhere, download this file:
wget https://beta.quicklisp.org/quicklisp.lisp
start a Lisp and load this file:
sbcl --load quicklisp.lisp
we get in the sbcl prompt. We have one Quicklisp command to type to install it:
(quicklisp-quickstart:install)
it will install itself in ~/quicklisp/quicklisp/.
it should output something like this, showing the basic commands:
==================================================
2,846 bytes in 0.001 seconds (2779.30KB/sec)
Upgrading ASDF package from version 2.004 to version 2.009
; Fetching #<URL "http://beta.quicklisp.org/dist/quicklisp.txt">
; 0.40KB
==================================================
408 bytes in 0.003 seconds (132.81KB/sec)
==== quicklisp installed ====
To load a system, use: (ql:quickload "system-name")
To find systems, use: (ql:system-apropos "term")
To load Quicklisp every time you start Lisp, use: (ql:add-to-init-file)
For more information, see http://www.quicklisp.org/beta/
NIL
Does it work ? Let’s try to install something:
(ql:quickload "dexador")
It is installed but we want to have Quicklisp available everytime we
start sbcl. Otherwise we’d have to load the file located at
~/quicklisp/quicklisp/setup.lisp.
Each implementation uses a startup file, like our shells, so we can
add this into our ~/.sbclrc:
;;; The following lines added by ql:add-to-init-file:
#-quicklisp
(let ((quicklisp-init (merge-pathnames "quicklisp/setup.lisp"
(user-homedir-pathname))))
(when (probe-file quicklisp-init)
(load quicklisp-init)))
To quit sbcl, (quit) or C-d.
Quicklisp is a bit different than others package managers and it is not the only solution. That’s for another post.
Starting a project
I advise cl-project which, unlike others (quickproject) also sets up tests.
Now we can C-c C-k the .asd file and (ql:quickload "my-app") our
app in the Slime REPL. But this is for another post.
Managing implementations and installing libraries in the command line: Roswell
This is done together with Roswell.
Roswell is in brew for MacOS, in linuxbrew, and it has a Debian package.
It allows to install pinned versions of SBCL or of other implementations (Embedable CL, Clozure CL,…) easily:
ros install sbcl/1.2.14
ros install sbcl # the latest
ros install ccl-bin
what’s available ?
ros list versions
change the current lisp:
ros use sbcl/1.2.14
Install scripts:
ros install qlot
Install packages:
ros install dexador # http client
and it does more to help scripting and distributing software. See its wiki !
See also
- a Debian package for CCL (2016): http://mr.gy/blog/clozure-cl-deb.html
One of the first things I wanted to do in the REPL was some string manipulation. But it was tedious.
To trim whitespace, and I mean all whitespaces, we had to define
#\Space #\Newline #\Backspace #\Tab #\Linefeed #\Page #\Return
#\Rubout.
To concatenate two strings: either giving an unusual 'string argument to
concatenate, like this:
(concatenate 'string "fo" "o")
either we had to use a format construct, which is another source of
frustration for (impatient) beginners, and sure isn’t straightforward
and self-explanatory.
Many common stuff was split in various external libraries
(cl-ppcre), and many common stuff was made more difficult than
necessary (weird format construct again, entering a regexp, thus
esaping what’s necessary, when all you want to do is simple search and
replace, dealing with strings’ lengths and corner cases, lack of
verbs,… see below).
And all of that with many inconsistencies (the string as first argument, then as the last, etc).
So I just joined everything in a little library, which has now more features. Let’s see its code and its tests to learn at the canonical way to do stuff, their shortcomings, and the library api at the same time.
I just don’t know how come this lib didn’t exist yet.
str
You can install it with
(ql:quickload "str")
See on https://github.com/vindarel/cl-str.
Package definition
(in-package #:asdf-user)
(defsystem :str
:source-control (:git "git@github.com:vindarel/cl-s.git")
:description "Modern, consistent and terse Common Lisp string manipulation library."
:depends-on (:prove :cl-ppcre) ;; <= depends only on cl-ppcre.
:components ((:file "str"))
)
Trim
(defvar *whitespaces* '(#\Space #\Newline #\Backspace #\Tab
#\Linefeed #\Page #\Return #\Rubout))
(defun trim-left (s)
"Remove whitespaces at the beginning of s. "
(string-left-trim *whitespaces* s))
(defun trim-right (s)
"Remove whitespaces at the end of s."
(string-right-trim *whitespaces* s))
(defun trim (s)
(string-trim *whitespaces* s))
Concat
(defun concat (&rest strings)
"Join all the string arguments into one string."
(apply #'concatenate 'string strings))
Join
Snippets on the old cookbook or stackoverflow advised to use a
format construct. Which is weird, and causes problems if your
separator contains the ~ symbol.
(defun join (separator strings)
(let ((separator (replace-all "~" "~~" separator)))
(format nil
(concatenate 'string "~{~a~^" separator "~}")
strings)))
Now:
(is "foo~bar"
(join "~" '("foo" "bar")))
Split
cl-ppcre takes a regexp, but we don’t need this for the basic cases
of split. And disabling this regexp was not straightforward:
(defun split (separator s &key omit-nulls)
"Split s into substring by separator (cl-ppcre takes a regex, we do not)."
;; cl-ppcre:split doesn't return a null string if the separator appears at the end of s.
(let* ((val (concat s
(string separator)
;; so we need an extra character, but not the user's.
(if (string-equal separator #\x) "y" "x")))
(res (butlast (cl-ppcre:split (cl-ppcre:quote-meta-chars (string separator)) val))))
(if omit-nulls
(remove-if (lambda (it) (empty? it)) res)
res)))
Now: (split "." "foo.bar") just works.
Repeat
(defun repeat (count s)
"Make a string of S repeated COUNT times."
(let ((result nil))
(dotimes (i count)
(setf result (cons s result)))
(apply #'concat result)))
Replace-all
This required to use cl-ppcre and one switch of it to avoid regexps.
(defun replace-all (old new s)
"Replace `old` by `new` in `s`. Arguments are not regexs."
(let* ((cl-ppcre:*allow-quoting* t)
(old (concatenate 'string "\\Q" old))) ;; treat metacharacters as normal.
(cl-ppcre:regex-replace-all old s new)))
starts-with? start string
The Lisp way was to check if the beginning of “string” contains “start”, taking its length, dealing with corner cases,…
(defun starts-with? (start s &key (ignore-case nil))
"Return t if s starts with the substring 'start', nil otherwise."
(when (>= (length s) (length start))
(let ((fn (if ignore-case #'string-equal #'string=)))
(funcall fn s start :start1 0 :end1 (length start)))))
;; An alias:
;; Serapeum defines a "defalias".
(setf (fdefinition 'starts-with-p) #'starts-with?)
(defun ends-with? (end s &key (ignore-case nil))
"Return t if s ends with the substring 'end', nil otherwise."
(when (>= (length s) (length end))
(let ((fn (if ignore-case #'string-equal #'string=)))
(funcall fn s end :start1 (- (length s) (length end))))))
(setf (fdefinition 'ends-with-p) #'ends-with?)
Usage illustrated by the tests:
(subtest "starts-with?"
(ok (starts-with? "foo" "foobar") "default case")
(ok (starts-with? "" "foo") "with blank start")
(ok (not (starts-with? "rs" "")) "with blank s")
(ok (not (starts-with? "foobar" "foo")) "with shorter s")
(ok (starts-with? "" "") "with everything blank")
(ok (not (starts-with? "FOO" "foobar")) "don't ignore case")
(ok (starts-with-p "f" "foo") "starts-with-p alias")
(ok (starts-with? "FOO" "foobar" :ignore-case t) "ignore case"))
Predicates: empty? blank?
There was no built-in to make those differences.
(defun empty? (s)
"Is s nil or the empty string ?"
(or (null s) (string-equal "" s)))
(defun emptyp (s)
"Is s nil or the empty string ?"
(empty? s))
(defun blank? (s)
"Is s nil or only contains whitespaces ?"
(or (null s) (string-equal "" (trim s))))
(defun blankp (s)
"Is s nil or only contains whitespaces ?"
(blank? s))
words, unwords, lines, unlines
Classic stuff:
(defun words (s &key (limit 0))
"Return list of words, which were delimited by white space. If the optional limit is 0 (the default), trailing empty strings are removed from the result list (see cl-ppcre)."
(if (not s)
nil
(cl-ppcre:split "\\s+" (trim-left s) :limit limit)))
(defun unwords (strings)
"Join the list of strings with a whitespace."
(join " " strings))
(defun lines (s &key omit-nulls)
"Split the string by newline characters and return a list of lines."
(split #\NewLine s :omit-nulls omit-nulls))
(defun unlines (strings)
"Join the list of strings with a newline character."
(join (make-string 1 :initial-element #\Newline) strings))
Substring
The builtin subseq is much poorer compared to what we have in other languages.
Take Python, we can do:
"foo"[:-1] # negative index and starting from the end
"foo"[0:100] # end is too large, thus it returns the entire array.
This was not possible with subseq, it throws a condition. Nothing
found in Alexandria or other helper libraries.
(defun substring (start end s)
"Return the substring of `s' from `start' to `end'.
It uses `subseq' with differences:
- argument order, s at the end
- `start' and `end' can be lower than 0 or bigger than the length of s.
- for convenience `end' can be nil or t to denote the end of the string.
"
(let* ((s-length (length s))
(end (cond
((null end) s-length)
((eq end t) s-length)
(t end))))
(setf start (max 0 start))
(if (> start s-length)
""
(progn
(setf end (min end s-length))
(when (< end (- s-length))
(setf end 0))
(when (< end 0)
(setf end (+ s-length end)))
(if (< end start)
""
(subseq s start end))))))
Usage:
(subtest "substring"
(is "abcd" (substring 0 4 "abcd") "normal case")
(is "ab" (substring 0 2 "abcd") "normal case substing")
(is "bc" (substring 1 3 "abcd") "normal case substing middle")
(is "" (substring 4 4 "abcd") "normal case")
(is "" (substring 0 0 "abcd") "normal case")
(is "d" (substring 3 4 "abcd") "normal case")
(is "abcd" (substring 0 t "abcd") "end is t")
(is "abcd" (substring 0 nil "abcd") "end is nil")
(is "abcd" (substring 0 100 "abcd") "end is too large")
(is "abc" (substring 0 -1 "abcd") "end is negative")
(is "b" (substring 1 -2 "abcd") "end is negative")
(is "" (substring 2 1 "abcd") "start is bigger than end")
(is "" (substring 0 -100 "abcd") "end is too low")
(is "" (substring 100 1 "abcd") "start is too big")
(is "abcd" (substring -100 4 "abcd") "start is too low")
(is "abcd" (substring -100 100 "abcd") "start and end are too low and big")
(is "" (substring 100 -100 "abcd") "start and end are too big and low")
)
See also
and afterwards I saw cl-strings which does help but can have its shortcomings.
The Cookbook is updated: https://lispcookbook.github.io/cl-cookbook/strings.html

Shady Logic Gates
MonkeyUser 02 05 2017
A rundown of all the ways you can use Prefetch to speed up queries in Django.

AdLitteram 23
MonkeyUser 28 04 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

QA Engineer - Bed Shopping
MonkeyUser 24 04 2017

AdLitteram 22
MonkeyUser 21 04 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

Easter Eggs
MonkeyUser 18 04 2017
Why is there no generic operators ?
Lisp journey 14 04 2017
TLDR; because the object system came afterwards (and it was not the intention to make CL entirely object oriented).
As a CL enthousiast coming from Python, I feel the pain not to have generic or polymorphic operators but having to learn about many specialized operators instead. Why is it so and are there solutions ?
I asked on SO.
In CL, there are many operators to check for equality that depend on
the data type: =, string-equal, char=, then equal, eql and
whatnot, so on for other data types, and the same for comparison
operators. There are no generic and extendible operators. For our
own types, we define its own functions.
As a reminder for those equality operators: equal does work on
integers, strings and characters and equalp also works for lists,
vectors and hash tables an other Common Lisp types but objects. See
the SO answers
for precisions and experienced lispers debatting of the inner
subtilities and traps of those functions.
The language has mechanisms to create generics though, see generics (defgeneric, defmethod) as described in Practical Common Lisp.
There have been work in that direction (https://common-lisp.net/project/cdr/document/8/cleqcmp.html) but no library as of today.
It’s a recurrent concern, also this blog post (“Not a monad tutorial”, great serie) points to this. The guy moved to Clojure, for other reasons too of course, where there are only one (or two?) equality operators.
So it seems that the reason is mostly historical, the object system (CLOS) appearing afterwards. Of course the generics would be slower. But how much slower ? I really don’t care, as a beginner and for web stuff.
Generic CLOS functions were added several years after CL was originally designed (82-84). The variant with CLOS was widely published with CLtL2 (1990) and then ANSI CL. The language was only slightly updated. It was not the intention to make Common Lisp fully object oriented. Also performance of CLOS for relatively low-level functions is kind of problematic. Dylan, which is something like Scheme + CLOS - s-expression syntax, did this: it defines more of the language in terms of generic functions. [Rainer Joswig on SO]
The CL21 way
Fortunately CL21 introduces (more) generic
operators, particularly for sequences it defines length, append,
setf, getf, first, rest, subseq, replace, take, drop, fill,
take-while, drop-while, last, butlast, find-if, search,
remove-if, delete-if, reverse, reduce, sort, split,
join, remove-duplicates, every, some, map, sum (and some
more). Those should work at least for strings, lists,
vectors and extend the new abstract-sequence type.
Now CL21 is something worth presenting and debatting in another post.
More:
The awesome example we will read comes from a comment by user lispm inside a discussion on this reddit thread: https://www.reddit.com/r/programming/comments/65ct5j/a_pythonist_finds_a_new_home_at_clojure_land/.
The article it discusses is a
“Not a monad tutorial”
post, where the interviewee is experienced in C++, Java, Javascript and Python and
turns into Clojure. He wrote about his first impressions with Common
Lisp
here,
where he raises usual concerns that I agree with but IMO that stay
supercifial (“not readable” because of stuff like (format t
"~{~{~a:~10t~a~%~}~%~}" *db*), “huge operators set”, “macros look
promising”…).
Here starts the discussion.
dzecniv On Common Lisp, I agree with the criticisms except
the code was very difficult to read
I find it very easy, always well expressed, with concise
functions. And I find Clojure’s harder, with more
[, { and the same number of other symbols (#, *).
Anyway, I’m in the process of trying to go from python to CL. The CL ecosystem is quite good nowadays (equivalents of pip, venvs, pyenv, implementations (even for the JVM or iOS), CI, sphinx, readthedocs, wsgi, setup.py,,…), it’s moving, we can do quite a lot (awesome list), it has unique features but yeah, the ecosystem is tiny compared to clojure’s…
ps: interested ? http://lisp-lang.org/ !
lispm
tiny compared to clojure
In many ways is it much broader than Clojure, since there is much more choice. Interpreters, compilers, native code compilers, batch compilers, compilers targeting C/LLVM/JVM/ARM/ARM64/x86/x86-64/SPARC64/POWER/…
Clojure on the JVM uses a relatively simple and not very user-friendly compiler to the JVM. No Interpreter. No mixed use of interpreted and compiled code. Functions need to be declared before used. Error messages are exposing the underlying JVM. No TCO. No images. Slow startup.
The Roomba cleans your home with a CL program.
MagicMurderBagYT
No Interpreter.
Hol up. What about the REPL?
lispm
That’s not an interpreter. A REPL is not the same as a Lisp interpreter. REPL means read eval print loop. EVAL can be implemented by a compiler or an interpreter. Common Lisp has both and mixed implementations with both compiler and interpreter.
A Lisp interpreter is executing Lisp code directly. Clojure does not have an Interpreter.
https://clojure.org/reference/evaluation
Clojure has no interpreter.
Example in LispWorks, which uses the Interpreter in the REPL:
CL-USER 29 > (let ((f (lambda (a b)
(+ (prog1 2 (break)) ; we have a break here
(* a b)))))
(funcall f 2 3))
Break.
1 (continue) Return from break.
2 (abort) Return to level 0.
3 Return to top loop level 0.
Type :b for backtrace or :c <option number> to proceed.
Type :bug-form "<subject>" for a bug report template or :? for other options.
As you see Lisp comes with a sub-repl in the break. The sub-repl is just another repl, but in the context of the break. The break could be done by the debugger when it sees an error or by user code - as above.
Now we ask the interpreter for the current lambda expression:
CL-USER 30 : 1 > :lambda
(LAMBDA (A B) (+ (PROG1 2 (BREAK)) (* A B)))
Above is actually Lisp data. Code as data.
Now I’m changing the + function in the code to be expt, exponentiation. To be clear: I’m changing in the debugger the current executed Lisp function on the Lisp level. We take the third element of the list, and then the first one of that. This is the + symbol. We change it to be expt. * holds the last evaluation result of the REPL.
CL-USER 31 : 1 > (setf (first (third *)) 'expt)
EXPT
Then I’m restarting the current stack frame:
CL-USER 32 : 1 > :res
We get another break, which we just continue from:
Break.
1 (continue) Return from break.
2 (abort) Return to level 0.
3 Return to top loop level 0.
Type :b for backtrace or :c <option number> to proceed.
Type :bug-form "<subject>" for a bug report template or :? for other options.
CL-USER 33 : 1 > :c 1
64 ; we computed 2^(2*3) instead of 2+(2*3)
What did we see? We saw that the interpreter uses actual Lisp code. Lisp code we can change with Lisp code in the debugger.
A second example.
What can we do with that for debugging? Well, we can for example write our own evaluation tracer. The Evaluator prints each expression and its result nicely indented, while walking the expression tree and evaluating subexpressions. Remember: this is now user-level code. The example is from CLtL2. You will also see that LispWorks can freely mix compiled and interpreted functions. The function COMPILE takes a function name and compiles its Lisp code to machine code.
CL-USER 1 > (defvar *hooklevel* 0)
*HOOKLEVEL*
CL-USER 2 > (defun hook (x)
(let ((*evalhook* 'eval-hook-function))
(eval x)))
HOOK
CL-USER 3 > (compile 'hook)
HOOK
NIL
NIL
CL-USER 4 > (defun eval-hook-function (form &rest env)
(let ((*hooklevel* (+ *hooklevel* 1)))
(format *trace-output* "~%~V@TForm: ~S"
(* *hooklevel* 2) form)
(let ((values (multiple-value-list
(evalhook form
#'eval-hook-function
nil
env))))
(format *trace-output* "~%~V@TValue:~{ ~S~}"
(* *hooklevel* 2) values)
(values-list values))))
EVAL-HOOK-FUNCTION
CL-USER 5 > (compile 'eval-hook-function)
EVAL-HOOK-FUNCTION
NIL
NIL
Now we can trace the evaluation of expressions on the Lisp level:
CL-USER 6 > (hook '(cons (floor *print-base* 2) 'b))
Form: (CONS (FLOOR *PRINT-BASE* 2) (QUOTE B))
Form: (FLOOR *PRINT-BASE* 2)
Form: *PRINT-BASE*
Value: 10
Form: 2
Value: 2
Value: 5 0
Form: (QUOTE B)
Value: B
Value: (5 . B)
(5 . B)
dzecniv
that’s an awesome example and tutorial that I’d love to see on a blog post or just a gist or something for further reference and better archiving, this will be buried too quickly on reddit !
So here it is.
Epilogue: the Roomba robot vacuums.

AdLitteram 21
MonkeyUser 14 04 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

Steps to reproduce
MonkeyUser 11 04 2017
Persistent Undo in Vim
Jovica Ilic 07 04 2017
As you already saw in the chapter on Undo/redo, Vim is pretty powerful when it comes to these features. However, there’s one more feature which I didn’t mention, as it takes a bit of configuration. In Vim, like in every other text editor, you can perform undo/redo in your current session. Once the session is... Continue reading
The post Persistent Undo in Vim appeared first on Jovica Ilic.

AdLitteram 20
MonkeyUser 07 04 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

Different Perspectives
MonkeyUser 04 04 2017

AdLitteram 19
MonkeyUser 31 03 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)
Django Admin is a powerful tool for managing data in your app. However, it was not designed with summary tables and charts in mind. Luckily, the developers of Django Admin made it easy for us to customize. We are going to turn Django Admin into a dashboard by adding a chart and a summary table.

Product Stages
MonkeyUser 28 03 2017

I recently ran across a comparison of React.js to Vue.js for rendering dynamic tabular data, and I got curious to see how Reagent would stack up against them.
The benchmark simulates a view of football games represented by a table. Each row in the table represents the state of a particular game. The game states are updated once a second triggering UI repaints.
I structured the application similarly to the way that React.js version was structured in the original benchmark. The application has a football.data namespace to handle the business logic, and a football.core namespace to render the view.
Implementing the Business Logic
Let's start by implementing the business logic in the football.data namespace. First, we'll need to provide a container to hold the state of the games. To do that we'll create a Reagent atom called games:
(ns football.data
(:require [reagent.core :as reagent]))
(defonce games (reagent/atom nil))
Next, we'll add a function to generate the fake players:
(defn generate-fake-player []
{:name (-> js/faker .-name (.findName))
:effort-level (rand-int 10)
:invited-next-week? (> (rand) 0.5)})
You can see that we're using JavaScript interop to leverage the Faker.js library for generating the player names. One nice aspect of working with ClojureScript is that JavaScript interop tends to be seamless as seen in the code above.
Now that we have a way to generate the players, let's add a function to generate fake games:
(defn generate-fake-game []
{:id (-> js/faker .-random (.uuid))
:clock 0
:score {:home 0 :away 0}
:teams {:home (-> js/faker .-address (.city))
:away (-> js/faker .-address (.city))}
:outrageous-tackles 0
:cards {:yellow 0 :read 0}
:players (mapv generate-fake-player (range 4))})
With the functions to generate the players and the games in place, we'll now add a function to generate a set of initial game states:
(defn generate-games [game-count]
(reset! games (mapv generate-fake-game (range game-count))))
The next step is to write the functions to update the games and players to simulate the progression of the games. This code translates pretty much directly from the JavaScript version:
(defn maybe-update [game prob path f]
(if (< (rand-int 100) prob)
(update-in game path f)
game))
(defn update-rand-player [game idx]
(-> game
(assoc-in [:players idx :effort-level] (rand-int 10))
(assoc-in [:players idx :invited-next-week?] (> (rand) 0.5))))
(defn update-game [game]
(-> game
(update :clock inc)
(maybe-update 5 [:score :home] inc)
(maybe-update 5 [:score :away] inc)
(maybe-update 8 [:cards :yellow] inc)
(maybe-update 2 [:cards :red] inc)
(maybe-update 10 [:outrageous-tackles] inc)
(update-rand-player (rand-int 4))))
The last thing we need to do is to add the functions to update the game states at a specified interval. The original code uses Rx.js to accomplish this, but it's just as easy to do using the setTimeout function with Reagent:
(defn update-game-at-interval [interval idx]
(swap! games update idx update-game)
(js/setTimeout update-game-at-interval interval interval idx))
(def event-interval 1000)
(defn update-games [game-count]
(dotimes [i game-count]
(swap! games update i update-game)
(js/setTimeout #(update-game-at-interval event-interval i)
(* i event-interval))))
The update-games function updates the state of each game, then sets up a timeout for the recurring updates using the update-game-at-interval function.
Implementing the View
We're now ready to write the view portion of the application. We'll start by referencing the football.data namespace in the football.core namespace:
(ns football.core
(:require
[football.data :as data]
[reagent.core :as reagent]))
Next, we'll write the components to display the players and the games:
(defn player-component [{:keys [name invited-next-week? effort-level]}]
[:td
[:div.player
[:p.player__name
[:span name]
[:span.u-small (if invited-next-week? "Doing well" "Not coming again")]]
[:div {:class-name (str "player__effort "
(if (< effort-level 5)
"player__effort--low"
"player__effort--high"))}]]])
(defn game-component [game]
[:tr
[:td.u-center (:clock game)]
[:td.u-center (-> game :score :home) "-" (-> game :score :away)]
[:td.cell--teams (-> game :teams :home) "-" (-> game :teams :away)]
[:td.u-center (:outrageous-tackles game)]
[:td
[:div.cards
[:div.cards__card.cards__card--yellow (-> game :cards :yellow)]
[:div.cards__card.cards__card--red (-> game :cards :red)]]]
(for [player (:players game)]
^{:key player}
[player-component player])])
(defn games-component []
[:tbody
(for [game @data/games]
^{:key game}
[game-component game])])
(defn games-table-component []
[:table
[:thead
[:tr
[:th {:width "50px"} "Clock"]
[:th {:width "50px"} "Score"]
[:th {:width "200px"} "Teams"]
[:th "Outrageous Tackles"]
[:th {:width "100px"} "Cards"]
[:th {:width "100px"} "Players"]
[:th {:width "100px"} ""]
[:th {:width "100px"} ""]
[:th {:width "100px"} ""]
[:th {:width "100px"} ""]]]
[games-component]])
You can see that HTML elements in Reagent components are represented using Clojure vectors and maps. Since s-expressions cleanly map to HTML, there's no need to use an additional DSL for that. You'll also notice that components can be nested within one another same way as plain HTML elements.
Noe thing to note is that the games-component dereferences the data/games atom using the @ notation. Dereferencing simply means that we'd like to view the current state of a mutable variable.
Reagent atoms are reactive, and listeners are created when the atoms are dereferenced. Whenever the state of the atom changes, any components that are observing the atom will be notified of the change.
In our case, changes in the state of the games atom will trigger the games-component function to be evaluated. The function will pass the current state of the games down to its child components, and this will trigger any necessary repaints in the UI.
Finally, we have a bit of code to create the root component represented by the home-page function, and initialize the application:
(defn home-page []
[games-table-component])
(defn mount-root []
(reagent/render [home-page] (.getElementById js/document "app")))
(def game-count 50)
(defn init! []
(data/generate-games game-count)
(data/update-games game-count)
(mount-root))
We now have a naive implementation of the benchmark using Reagent. The entire project is available on GitHub. Next, let's take a look at how it performs.
Profiling with Chrome
When we profile the app in Chrome, we'll see the following results:
Here are the results for React.js and Vue.js running in the same environment for comparison:


As you can see, the naive Reagent version spends about double the time scripting compared to React.js, and about four times as long rendering.
The reason is that we're dereferencing the games atom at top level. This forces the top level component to be reevaluated whenever the sate of any game changes.
Reagent provides a mechanism for dealing with this problem in the form of cursors. A cursor allows subscribing to changes at a specified path within the atom. A component that dereferences a cursor will only be updated when the data the cursor points to changes. This allows us to granularly control what components will be repainted when a particular piece of data changes in the games atom. Let's update the view logic as follows:
(defn player-component [player]
[:td
[:div.player
[:p.player__name
[:span (:name @player)]
[:span.u-small
(if (:invited-next-week? @player)
"Doing well" "Not coming again")]]
[:div {:class-name (str "player__effort "
(if (< (:effort-level @player) 5)
"player__effort--low"
"player__effort--high"))}]]])
(defn game-component [game]
[:tr
[:td.u-center (:clock @game)]
[:td.u-center (-> @game :score :home) "-" (-> @game :score :away)]
[:td.cell--teams (-> @game :teams :home) "-" (-> @game :teams :away)]
[:td.u-center (:outrageous-tackles @game)]
[:td
[:div.cards
[:div.cards__card.cards__card--yellow (-> @game :cards :yellow)]
[:div.cards__card.cards__card--red (-> @game :cards :red)]]]
(for [idx (range (count (:players @game)))]
^{:key idx}
[player-component (reagent/cursor game [:players idx])])])
(def game-count 50)
(defn games-component []
[:tbody
(for [idx (range game-count)]
^{:key idx}
[game-component (reagent/cursor data/games [idx])])])
(defn games-table-component []
[:table
[:thead
[:tr
[:th {:width "50px"} "Clock"]
[:th {:width "50px"} "Score"]
[:th {:width "200px"} "Teams"]
[:th "Outrageous Tackles"]
[:th {:width "100px"} "Cards"]
[:th {:width "100px"} "Players"]
[:th {:width "100px"} ""]
[:th {:width "100px"} ""]
[:th {:width "100px"} ""]
[:th {:width "100px"} ""]]]
[games-component]])
(defn home-page []
[games-table-component])
The above version creates a cursor for each game in the games-components. The game-component in turn creates a cursor for each player. This way only the components that actually need updating end up being rendered as the state of the games is updated. Let's profile the application again to see how much impact this has on its performance:

The performance of the Reagent code using cursors now looks similar to that of the Vue.js implementation. You can see the entire source for the updated version here.
Conclusion
In this post we saw that ClojureScript with Reagent provides a compelling alternative to JavaScript offerings such as React.js and Vue.js.
Reagent allows writing succinct solutions that perform as well as those implemented using native JavaScript libraries. It also provides us with tools to intuitively reason about what parts of the view are going to be updated.
Likewise, we get many benefits by simply switching from using JavaScript to ClojureScript.
For example, We already saw that we didn't need any additional syntax, such as JSX, to represent HTML elements. Since HTML templates are represented using regular data structures, they follows the same rules as any other code. This allows us to transform them just like we would any other data in our project.
In general, I find ClojureScript to be much more consistent and less noisy than equivalent JavaScript code. Consider the implementation of the updateGame function in the original JavaScript version:
function updateGame(game) {
game = game.update("clock", (sec) => sec + 1);
game = maybeUpdate(5, game, () => game.updateIn(["score", "home"], (s) => s + 1));
game = maybeUpdate(5, game, () => game.updateIn(["score", "away"], (s) => s + 1));
game = maybeUpdate(8, game, () => game.updateIn(["cards", "yellow"], (s) => s + 1));
game = maybeUpdate(2, game, () => game.updateIn(["cards", "red"], (s) => s + 1));
game = maybeUpdate(10, game, () => game.update("outrageousTackles", (t) => t + 1));
const randomPlayerIndex = randomNum(0, 4);
const effortLevel = randomNum();
const invitedNextWeek = faker.random.boolean();
game = game.updateIn(["players", randomPlayerIndex], (player) => {
return player.set("effortLevel", effortLevel).set("invitedNextWeek", invitedNextWeek);
});
return game;
}
Compare it with the equivalent ClojureScript code:
(defn update-rand-player [game idx]
(-> game
(assoc-in [:players idx :effort-level] (rand-int 10))
(assoc-in [:players idx :invited-next-week?] (> (rand) 0.5))))
(defn update-game [game]
(-> game
(update :clock inc)
(maybe-update 5 [:score :home] inc)
(maybe-update 5 [:score :away] inc)
(maybe-update 8 [:cards :yellow] inc)
(maybe-update 2 [:cards :red] inc)
(maybe-update 10 [:outrageous-tackles] inc)
(update-rand-player (rand-int 4))))
ClojureScript version has a lot less syntactic noise, and I find this has direct impact on my ability to reason about the code. The more quirks there are, the more likely I am to misread the intent. Noisy syntax results in situations where code looks like it's doing one thing, while it's actually doing something subtly different.
Another advantage is that ClojureScript is backed by immutable data structures by default. My experience is that immutability is crucial for writing large maintainable projects, as it allows safely reasoning about parts of the code in isolation.
Since immutability is pervasive as opposed to opt-in, it allows for tooling to be designed with it in mind. For example, Figwheel plugin relies on this property to provide live hot reloading in the browser.
Finally, ClojureScript compiler can do many optimizations, such as dead code elimination, that are difficult to do with JavaScript. I highly recommend the Now What? talk by David Nolen that goes into more details regarding this.
Overall, I'm pleased to see that ClojureScript and Reagent perform so well when stacked up against native JavaScript libraries. It's hard to overstate the fact that a ClojureScript library built on top of React.js can outperform React.js itself.
JavaScript. But less iffy.
James Sinclair 24 03 2017

AdLitteram 18
MonkeyUser 24 03 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

Testing Vs Production Environment
MonkeyUser 21 03 2017

AdLitteram 17
MonkeyUser 17 03 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)
![]()

Trivial Bug
MonkeyUser 16 03 2017

Shared DB
MonkeyUser 14 03 2017

AdLitteram 16
MonkeyUser 10 03 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)
Suggested by: @jaivalis

Bugshots
MonkeyUser 07 03 2017

AdLitteram 15
MonkeyUser 03 03 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

SHA-1 Collision
MonkeyUser 28 02 2017

Static vs. Dynamic Linking
MonkeyUser 27 02 2017

AdLitteram 14
MonkeyUser 24 02 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)
Mastering Vim Quickly: Introduction
Jovica Ilic 23 02 2017
This post presents a chapter from my upcoming book Mastering Vim Quickly: From WTF to OMG in no time Introduction There’s so much you want to do in life, and so little time. The story of our modern lives. Take a moment and consider how many things you want to learn. Since you’re reading... Continue reading
The post Mastering Vim Quickly: Introduction appeared first on Jovica Ilic.

Tales of RegEx: #42
MonkeyUser 21 02 2017
How to Test Django Signals Like a Pro
Haki Benita 17 02 2017
Django signals are extremely useful for decoupling modules. They allow a low-level Django app to send events for other apps to handle without creating a direct dependency. Signals are easy to set up, but harder to test. In this article we implement a context manager for testing Django signals, step by step.

AdLitteram 13
MonkeyUser 17 02 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

DevOps Life
MonkeyUser 16 02 2017
Instapaper Service Fully Restored
Instapaper 14 02 2017
After suffering from an extended outage on Wednesday, February 9 at 12:30PM PT through Thursday, February 10 at 7:30PM PT, we brought the Instapaper service back up with limited access to archives as a short-term solution while we worked to restore the service completely.
Today at 1AM PT we completely restored the Instapaper service, including access to all archives. We performed the restoration without losing any of your older articles, changes made to more recent articles or articles saved after recovering from the outage.
We apologize for the extended downtime and the time it took to regain access to your complete archives. Instapaper has operated as a high availability service over the last nine years without many hiccups. The root cause of this outage was both difficult to predict and prevent, and the nature of the outage is extremely rare and unlikely to recur. We appreciate your patience during this time.
We’d like to thank the Pinterest Site Reliability Engineering team for guiding us through the recovery, and the Amazon Relational Database Service team for working with us throughout the weekend to dramatically expedite the recovery process.
Lastly, if you’re interested in a more detailed overview of the issue that caused the outage and our process to recover the service, you can learn more on our Engineering Blog.
– Instapaper Team

Hotfix
MonkeyUser 14 02 2017
![]()
As we shared earlier today, Instapaper is experiencing an extended outage. After 31 hours of downtime, we were able to rebuild a database instance to get Instapaper back online! In the interest of coming back up as soon as possible, this instance only has the last six weeks of articles. For now, anything you’ve saved since December 20, 2016 is accessible.
We’re working on getting the rest of your articles restored, but wanted to give you access to your most recently saved articles in the meantime. Again, there hasn’t been any data loss. The full database exports are taking much longer than anticipated.
We’re aiming to get the full archives available by next Friday, February 17 at the latest. We appreciate your patience and understanding in the interim.
– Instapaper Team

AdLitteram 12
MonkeyUser 10 02 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)
JavaScript Without Loops
James Sinclair 09 02 2017
Extended Outage
Instapaper 09 02 2017
Yesterday, February 8th, at 12:30PM PT Instapaper suffered from an outage that has extended through this morning.
After spending multiple hours on the phone with our cloud service provider, it appears we hit a system limit for our hosted database that’s preventing new articles from being saved. At this time, our only option is to export all data from our old database and import it into a new one. We expect the service to be fully recovered today, February 9.
We pride ourselves on being a reliable service with minimal downtime (we were up for 99.93% of 2016), and know many of you rely on Instapaper every day. We apologize that this issue has resulted in an extended period of downtime.
We assure you we haven’t lost any data. While you may not have been able to save articles during the outage, anything you’ve already saved to Instapaper is safe. We appreciate your patience while we work diligently to get it resolved.
- Instapaper Team

Programming languages as humans
MonkeyUser 07 02 2017
Caution: this is a draft. I take notes and write more in other resources (the Cookbook, my blog).
update july, 5th 2019: I put this content into the Cookbook: https://lispcookbook.github.io/cl-cookbook/web.html, fixing a long-standing request.
new post: why and how to live-reload one’s running web application: https://lisp-journey.gitlab.io/blog/i-realized-that-to-live-reload-my-web-app-is-easy-and-convenient/
new project skeleton: lisp-web-template-productlist: Hunchentoot + easy-routes + Djula templates + Bulma CSS + a Makefile to build the project
See also the Awesome CL list.
Information is at the moment scarce and spread appart, Lisp web frameworks and libraries evolve and take different approaches.
I’d like to know what’s possible, what’s lacking, see how to quickstart everything, see code snippets and, most of all, see how to do things that I couldn’t do before such as hot reloading, building self-contained executables, shipping a multiplatform web app.
Table of Contents
- Web application environments
- Web frameworks
- Tasks
- Templating engines
- Javascript
- Shipping
- Deployment
- Appendice I: Example websites built with Lisp:
- Appendice II: Example software
Web application environments
Clack, Lack
Clack is to Lisp what WSGI is to Python. However it is mostly undocumented and not as battle-proofed as Hunchentoot.
Web frameworks
Hunchentoot
The de-facto web server, with the best documentation (cough looking old cough), the most websites on production. Lower level than a web framework (defining routes seems weird at first). I think worth knowing.
Its terminology is different from what we are used to (“routes” are not called routes but we create handlers), part I don’t know why and part because the Lisp image-based development allows for more, and thus needs more terminology. For example, we can run two applications on different URLs on the same image.
https://edicl.github.io/hunchentoot/
edit: here’s a modern looking page: https://digikar99.github.io/common-lisp.readthedocs/hunchentoot/
Caveman
A popular web framework, or so it seems by the github stars, written by a super-productive lisper, with nice documentation for basic stuff but lacking for the rest, based on Clack (webserver interface, think Python’s WSGI), uses Hunchentoot by default.
I feel like basic functions are too cumbersome (accessing url parameters).
https://github.com/fukamachi/caveman
Snooze
By the maintainer of Sly, Emacs’ Yasnippet,…
Defining routes is like defining functions. Built-in features that are available as extensions in Clack-based frameworks (setting to get a stacktrace on the browser, to fire up the debugger or to return a 404,…). Definitely worth exploring.
https://github.com/joaotavora/snooze
Radiance
Radiance, with extensive tutorial and existing apps.
It doesn’t look like a web framework to me. It has ready-to-use components:
- admin page (but what does it do?)
- auth system
- user: provide user accounts and permissions
- image hosting
- there is an email marketing system in development…
cl-rest-server
a library for writing REST Web APIs in Common Lisp.
Features: validation via schemas, Swagger support, authentication, logging, caching, permission checking…
It seems complete, it is maintained, the author seems to be doing web development in CL for a living. Note to self: I want to interview him.
Wookie
https://github.com/orthecreedence/wookie
An asynchronous web server, by an impressive lisper, who built many async libraries. Used for the Turtl api backend. Dealing with async brings its own set of problems (how will be debugging ?).
Nice api to build routes, good documentation: http://wookie.lyonbros.com/
Weblocks (solving the Javascript problem)
Weblocks allows to create dynamic pages without a line of JavaScript, all in Lisp. It was started years ago and it saw a large update and refactoring lately.
It isn’t the easy path to web development in CL but there’s great potential IMO.
It doesn’t do double data binding as in modern JS frameworks. But new projects are being developed…
See our presentation below.
http://40ants.com/weblocks/quickstart.html
Tasks
Accessing url parameters
It is easy and well explained with Hunchentoot or easy-routes in the Cookbook.
Lucerne has a nice
with-params macro that makes accessing post or url query parameters a breeze:
@route app (:post "/tweet")
(defview tweet ()
(if (lucerne-auth:logged-in-p)
(let ((user (current-user)))
(with-params (tweet)
(utweet.models:tweet user tweet))
(redirect "/"))
(render-template (+index+)
:error "You are not logged in.")))
Snooze’s way is simple and lispy: we define routes like methods and parameters as keys:
(defroute lispdoc (:get :text/* name &key (package :cl) (doctype 'function))
...
matches /lispdoc, /lispdoc/foo and /lispdoc/foo?package=arg.
On the contrary, I find Caveman’s and Ningle’s ways cumbersome.
Ningle:
(setf (ningle:route *app* "/hello/:name")
#'(lambda (params)
(format nil "Hello, ~A" (cdr (assoc "name" params :test #'string=)))))
The above controller will be invoked when you access to “/hello/Eitaro” or “/hello/Tomohiro”, and then (cdr (assoc “name” params :test #‘string=)) will be “Eitaro” and “Tomohiro”.
and it doesn’t say about query parameters. I had to ask:
(assoc "the-query-param" (clack.request:query-parameter lucerne:*request*) :test 'string=)
Caveman:
Parameter keys contain square brackets (”[” & “]”) will be parsed as structured parameters. You can access the parsed parameters as _parsed in routers.
(defroute "/edit" (&key _parsed)
(format nil "~S" (cdr (assoc "person" _parsed :test #'string=))))
;=> "((\"name\" . \"Eitaro\") (\"email\" . \"e.arrows@gmail.com\") (\"birth\" . ((\"year\" . 2000) (\"month\" . 1) (\"day\" . 1))))"
Session an cookies
Data storage
SQL
Mito works for MySQL, Postgres and SQLite3 on SBCL and CCL.
https://lispcookbook.github.io/cl-cookbook/databases.html
We can define models with a regular class which has a mito:dao-table-class :metaclass:
(defclass user ()
((name :col-type (:varchar 64)
:initarg :name
:accessor user-name)
(email :col-type (:varchar 128)
:initarg :email
:accessor user-email))
(:metaclass mito:dao-table-class)
(:unique-keys email))
We create the table with ensure-table-exists:
(ensure-table-exists 'user)
;-> ;; CREATE TABLE IF NOT EXISTS "user" (
; "id" BIGSERIAL NOT NULL PRIMARY KEY,
; "name" VARCHAR(64) NOT NULL,
; "email" VARCHAR(128),
; "created_at" TIMESTAMP,
; "updated_at" TIMESTAMP
; ) () [0 rows] | MITO.DAO:ENSURE-TABLE-EXISTS
Persistent datastores
Migrations
Mito has migrations support and DB schema versioning for MySQL, Postgres and SQLite3, on SBCL and CCL. Once we have changed our model definition, we have commands to see the generated SQL and to apply the migration.
We inspect the SQL: (suppose we just added the email field into the user class above)
(mito:migration-expressions 'user)
;=> (#<SXQL-STATEMENT: ALTER TABLE user ALTER COLUMN email TYPE character varying(128), ALTER COLUMN email SET NOT NULL>
; #<SXQL-STATEMENT: CREATE UNIQUE INDEX unique_user_email ON user (email)>)
and we can apply the migration:
(mito:migrate-table 'user)
;-> ;; ALTER TABLE "user" ALTER COLUMN "email" TYPE character varying(128), ALTER COLUMN "email" SET NOT NULL () [0 rows] | MITO.MIGRATION.TABLE:MIGRATE-TABLE
; ;; CREATE UNIQUE INDEX "unique_user_email" ON "user" ("email") () [0 rows] | MITO.MIGRATION.TABLE:MIGRATE-TABLE
;-> (#<SXQL-STATEMENT: ALTER TABLE user ALTER COLUMN email TYPE character varying(128), ALTER COLUMN email SET NOT NULL>
; #<SXQL-STATEMENT: CREATE UNIQUE INDEX unique_user_email ON user (email)>)
Crane advertises automatic
migrations, i.e. it would run them after a C-c C-c. Unfortunately Crane has
some issues, it doesn’t work with sqlite yet and the author is busy
elsewhere. It didn’t work for me at first try.
Let’s hope the author comes back to work on this in a near future.
Forms
There are a few libraries, see the awesome-cl list. At least one is well active.
Debugging
On an error we are usually dropped into the interactive debugger by default.
Snooze gives options:
- use the debugger,
- print the stacktrace in the browser (like clack-errors below, but built-in),
- display a custom 404.
clack-errors. Like a Flask or Django stacktrace in the browser. For Caveman, Ningle and family.
By default, when Clack throws an exception when rendering a page, the server waits for the response until it times out while the exception waits in the REPL. This isn’t very useful. So now there’s this.
It prints the stacktrace along with some request details on the browser. Can return a custom error page in production.
Are you tired of jumping to your web browser every time you need to test your work in Clack? Clack-pretend will capture and replay calls to your clack middleware stack. When developing a web application with clack, you will often find it inconvenient to run your code from the lisp REPL because it expects a clack environment, including perhaps, cookies or a logged-in user. With clack-pretend, you can run prior web requests from your REPL, moving development back where it belongs.
Testing
Testing with a local DB: example of a testing macro.
We would use envy to switch configurations.
Misc
Oauth, Job queues, etc
Templating engines
HTML-based
Djula: as Django templates. Good documentation. Comes by default in Lucerne and Caveman.
We also use a dot to access attributes of dict-like variables (plists, alists, hash-tables, arrays and CLOS objects), such a feature being backed by the access library.
We wanted once to use structs and didn’t find how to it directly in Djula, so we resorted in a quick helper function to transform the struct in an alist.
Defining custom template filters is straightforward in Djula, really a breeze compared to Django.
Eco - a mix of html with lisp expressions.
Truncated example:
<body>
<% if posts %>
<h1>Recent Posts</h1>
<ul id="post-list">
<% loop for (title . snippet) in posts %>
<li><%= title %> - <%= snippet %></li>
<% end %>
</ul>
...
Lisp-based
I prefer the semantics of Spinneret over cl-who. It also has more features (like embeddable markdown, warns on malformed html, and more).
Javascript
Parenscript
Parenscript is a translator from an extended subset of Common Lisp to JavaScript. Parenscript code can run almost identically on both the browser (as JavaScript) and server (as Common Lisp). Parenscript code is treated the same way as Common Lisp code, making the full power of Lisp macros available for JavaScript. This provides a web development environment that is unmatched in its ability to reduce code duplication and provide advanced meta-programming facilities to web developers.
https://common-lisp.net/project/parenscript/
JSCL
A Lisp-to-Javascript compiler bootstrapped from Common Lisp and executed from the browser.
https://github.com/jscl-project/jscl
https://t-cool.github.io/jscl-playground/
Ajax
Is it possible to write Ajax-based pages only in CL?
The case Webblocks - Reblocks, 2017
Weblocks is an “isomorphic” web frameworks that solves the “Javascript problem”. It allows to write the backend and an interactive client interface in Lisp, without a line of Javascript, in our usual Lisp development environment.
The framework evolves around widgets, that are updated server-side and are automatically redisplayed with transparent ajax calls on the client.
It is being massively refactored, simplified, rewritten and documented since 2017. See the new quickstart:
http://40ants.com/weblocks/quickstart.html
Writing a dynamic todo-app resolves in:
- defining a widget class for a task:
(defwidget task ()
((title
:initarg :title
:accessor title)
(done
:initarg :done
:initform nil
:accessor done)))
- doing the same for a list of tasks:
(defwidget task-list ()
((tasks
:initarg :tasks
:accessor tasks)))
- saying how to render these widgets in html by extending the
rendermethod:
(defmethod render ((task task))
"Render a task."
(with-html
(:span (if (done task)
(with-html
(:s (title task)))
(title task)))))
(defmethod render ((widget task-list))
"Render a list of tasks."
(with-html
(:h1 "Tasks")
(:ul
(loop for task in (tasks widget) do
(:li (render task))))))
- telling how to initialize the Weblocks app:
(defmethod weblocks/session:init ((app tasks))
(declare (ignorable app))
(let ((tasks (make-task-list "Make my first Weblocks app"
"Deploy it somewhere"
"Have a profit")))
(make-instance 'task-list :tasks tasks)))
- and then writing functions to interact with the widgets, for example adding a task:
(defmethod add-task ((task-list task-list) title)
(push (make-task title)
(tasks task-list))
(update task-list))
Adding an html form and calling the new add-task function:
(defmethod render ((task-list task-list))
(with-html
(:h1 "Tasks")
(loop for task in (tasks task-list) do
(render task))
(with-html-form (:POST (lambda (&key title &allow-other-keys)
(add-task task-list title)))
(:input :type "text"
:name "title"
:placeholder "Task's title")
(:input :type "submit"
:value "Add"))))
Shipping
Building
We can build an executable also for web apps. That makes for a simple deployment process.
We can even get a Lisp REPL and interact with the running web app, including installing new Quicklisp dependencies. That’s quite incredible, and it’s very useful, if not to hot-reload a web app (which I do anyways), at least to reload a user configuration file.
This is the general way:
(sb-ext:save-lisp-and-die #p"name-of-executable" :toplevel #'main :executable t)
we need a step more for web apps:
(defun main ()
;; with bordeaux-threads. Also sb-ext: join-thread, thread-name, list-all-threads.
(bt:join-thread (find-if (lambda (th)
(search "hunchentoot" (bt:thread-name th)))
(bt:all-threads))))
I can now build my web app, send it to my VPS and see it live.
When I run it, Hunchentoot stays listening at the foreground:
$ ./my-webapp
Hunchentoot server is started.
Listening on localhost:9003.
I need to put it in the background (C-z bg), or use a tmux session
(tmux, then C-b d to detach it).
To be complete, you’ll notice that we can not C-c our running app,
we get trapped into the debugger (which responds only to C-z and
kill). As with any command line, we have to catch the corresponding
signal. We also stop our app. See
our cl-torrents tutorial
on how to build command-line applications.
(defun main ()
(start-app :port 9003)
;; with bordeaux-threads
(handler-case (bt:join-thread (find-if (lambda (th)
(search "hunchentoot" (bt:thread-name th)))
(bt:all-threads)))
(#+sbcl sb-sys:interactive-interrupt
#+ccl ccl:interrupt-signal-condition
#+clisp system::simple-interrupt-condition
#+ecl ext:interactive-interrupt
#+allegro excl:interrupt-signal
() (progn
(format *error-output* "Aborting.~&")
(clack:stop *server*)
(uiop:quit 1)) ;; portable exit, included in ASDF, already loaded.
;; for others, unhandled errors (we might want to do the same).
(error (c) (format t "Woops, an unknown error occured:~&~a~&" c)))))
See also how to daemonize an application (below in Deployment).
To see:
- a Debian package for every Quicklisp system: http://margaine.com/2015/12/22/quicklisp-packagecloud-debian-packages.html.
Multiplatform delivery with Electron (Ceramic)
Ceramic makes all the work for us.
It is as simple as this:
;; Load Ceramic and our app
(ql:quickload '(:ceramic :our-app))
;; Ensure Ceramic is set up
(ceramic:setup)
(ceramic:interactive)
;; Start our app (here based on the Lucerne framework)
(lucerne:start our-app.views:app :port 8000)
;; Open a browser window to it
(defvar window (ceramic:make-window :url "http://localhost:8000/"))
;; start Ceramic
(ceramic:show-window window)
and we can ship this on Linux, Mac and Windows.
More:
Ceramic applications are compiled down to native code, ensuring both performance and enabling you to deliver closed-source, commercial applications.
(so no need to minify our JS)
with one more line:
(ceramic.bundler:bundle :ceramic-hello-world
:bundle-pathname #p"/home/me/app.tar")
Copying resources...
Compiling app...
Compressing...
Done!
#P"/home/me/app.tar"
This last line was buggy for us.
Deployment
When you build a self-contained binary, deployment gets easy.
Radiance’s tutorial talks about deployment. https://github.com/Shirakumo/radiance-tutorial/blob/master/Part%207.md
Running the app on a web server
Manually
sbcl --load <my-app> --eval (start-my-app)
For example, a run Makefile target:
run:
sbcl --load my-app.asd \
--eval '(ql:quickload :my-app)' \
--eval '(my-app:start-app)' ;; given this function starts clack or hunchentoot.
this keeps sbcl in the foreground. Can use tmux or just C-z bg to put it in background.
Then, we need of a task supervisor, that will restart our app on failures, start it after a reboot, handle logging. See the section below and example projects (such as Quickutil).
with Clack
$ clackup app.lisp
Hunchentoot server is started.
Listening on localhost:5000.
with Docker
So we have various implementations ready to use: sbcl, ecl, ccl… with Quicklisp well configured.
https://lispcookbook.github.io/cl-cookbook/testing.html#gitlab-ci
On Heroku
See heroku-buildpack-common-lisp and the Awesome CL#deploy section.
Daemonizing, restarting in case of crashes, handling logs (Systemd)
Generally, this depends on your system. But most GNU/Linux distros now come with Systemd. Write a service file like this:
$ /etc/systemd/system/my-app.service
[Unit]
Description=stupid simple example
[Service]
WorkingDirectory=/path/to/your/app
ExecStart=sbcl --load run.lisp # your command
Type=simple
Restart=always
RestartSec=10
run a command to start it:
sudo systemctl start my-app.service
a command to check its status:
systemctl status my-app.service
Systemd handles logging. We write to stdout or stderr, it writes logs:
journalctl -f -u my-app.service
and it handles crashes and restarts the app:
Restart=always
and it can start the app after a reboot:
[Install]
WantedBy=basic.target
to enable it:
sudo systemctl enable my-app.service
Debugging SBCL error: ensure_space: failed to allocate n bytes
If you get this error with SBCL on your server:
mmap: wanted 1040384 bytes at 0x20000000, actually mapped at 0x715fa2145000
ensure_space: failed to allocate 1040384 bytes at 0x20000000
(hint: Try "ulimit -a"; maybe you should increase memory limits.)
then disable ASLR:
sudo bash -c "echo 0 > /proc/sys/kernel/randomize_va_space"
Connecting to a remote Swank server
Little example here: http://cvberry.com/tech_writings/howtos/remotely_modifying_a_running_program_using_swank.html.
It defines a simple function that prints forever:
;; a little common lisp swank demo
;; while this program is running, you can connect to it from another terminal or machine
;; and change the definition of doprint to print something else out!
;; (ql:quickload '(:swank :bordeaux-threads))
(require :swank)
(require :bordeaux-threads)
(defparameter *counter* 0)
(defun dostuff ()
(format t "hello world ~a!~%" *counter*))
(defun runner ()
(bt:make-thread (lambda ()
(swank:create-server :port 4006)))
(format t "we are past go!~%")
(loop while t do
(sleep 5)
(dostuff)
(incf *counter*)))
(runner)
On our server, we run it with
sbcl --load demo.lisp
we do port forwarding on our development machine:
ssh -L4006:127.0.0.1:4006 username@example.com
this will securely forward port 4006 on the server at example.com to our local computer’s port 4006 (swanks accepts connections from localhost).
We connect to the running swank with M-x slime-connect, typing in
port 4006.
We can write new code:
(defun dostuff ()
(format t "goodbye world ~a!~%" *counter*))
(setf *counter* 0)
and eval it as usual with M-x slime-eval-region for instance. The output should change.
There are more pointers on CV Berry’s page.
Hot reload
When we run the app as a script we get a Lisp REPL, so we can hot-reload the running web app. Here we demonstrate a recipe to update it remotely.
Example taken from Quickutil.
It has a Makefile target:
hot_deploy:
$(call $(LISP), \
(ql:quickload :quickutil-server) (ql:quickload :swank-client), \
(swank-client:with-slime-connection (conn "localhost" $(SWANK_PORT)) \
(swank-client:slime-eval (quote (handler-bind ((error (function continue))) \
(ql:quickload :quickutil-utilities) (ql:quickload :quickutil-server) \
(funcall (symbol-function (intern "STOP" :quickutil-server))) \
(funcall (symbol-function (intern "START" :quickutil-server)) $(start_args)))) conn)) \
$($(LISP)-quit))
It has to be run on the server (a simple fabfile command can call this
through ssh). Beforehand, a fab update has run git pull on the
server, so new code is present but not running. It connects to the
local swank server, loads the new code, stops and starts the app in a
row.
![]()
(yes that currently helps, thanks!)

Resources
Lisp journey 05 02 2017
search libraries on
Individual sites:
- sjl’s road to Lisp
- Martin Cracauer’s Gentle Introduction to compile-time computing - excellent article series
- https://www.darkchestnut.com/ - he encountered deployment obstacles, wrote a book and blogs about it.
- http://lispmethods.com/
- Malisper’s series on debugging
Screencasts:
- Little Bits of Lisp - short videos on various topics: inspecting a condition, basics of lisp’s evaluation model,…
- Common Lisp Tutorials, of which Emacs and Slime - useful keyboard shortcuts
- Programming a message bus in Common Lisp - shows the interactive nature of lisp, good use of the debugger, test-driven development to shape the api, bordeaux-threads.
- Marco Baringer’s SLIME Tutorial Video - a video showing Marco develop a package and explaining Slime and Lisp features, with many little important explanations (1 hour). It only has some rotten bits, for example it installs packages with asdf-install and not Quicklisp.
- Interactively fixing failing tests - very short video to showcase the interactive debugger and that we can re-compile a failing function and resume the execution from where it failed to see it finally pass.
- Web development in Emacs with Common Lisp and ClojureSCript - building Potato, a Slack-like app.
- Shinmera playlists: Treehouse (game dev), Demos (of small programs).
- Pushing pixels with Lisp, and by the same author:
- CEPL demo - working with OpenGL
- Baggers’ channels.
Common Lisp Study Group (long videos)
McClim interactive GUI demos. Code examples. Presentation of Clim listener, Clim debugger, drawing objects into the GUI repl.
and more on Cliki.
Some games:
- Spycursion - “a sandbox “edutainment” MMO centered around hacking and espionage which takes place in a near-future world”.



http://www.sebity.com/projects.php (Snake, the Invaders,… with OpenGL)
cl-snake snake in the terminal
Fruktorama, Tetris-like with fruits.
Home
Lisp journey 05 02 2017
Hi, it’s Vincent. I write about my Common Lisp journey here. I
started the blog when I was discovering the language and the
ecosystem, wishing more people wrote about CL. Because Common Lisp is was
the most hidden world I know.
I now wrote tools, libraries and software, and I run a web app in production©.
I write intensively about Common Lisp on collaborative resources. My hidden plan is to make Common Lisp popular again. For this, I contribute to the Common Lisp Cookbook (I am the main contributor, by far). I wrote about: CLOS, data structures, building executables, scripting, web scraping, debugging, error handling, testing, databases, GUI programming, web development, etc, and I added a theme, a sidebar and syntax highlighting. I also take time to maintain the awesome-cl list, an important resource in my eyes. I dig up, reference and sort Common Lisp libraries (and I still discover hidden gems three years after). I do community stuff for Lisp Advocates (not the creator).
Now a newcomer has far more practical information for getting started than a few years ago. But there’s still a lot to do, and I’d like to do more. You can thank me and encourage me by donations on the following platforms. As I currently don’t have a fixed (nor big) income, that helps. Thanks!
- ko-fi: https://ko-fi.com/vindarel (exempt of charges)
- liberapay: https://liberapay.com/vindarel/ (exempt of charges)
- patreon: https://www.patreon.com/vindarel
I also write and maintain tools, libraries, software and project skeletons. Among others:
libraries:
- cl-str, that fixed my first frustration with CL
- CIEL (in development)
- replic, to help create a readline application in no time
- fuzzy-match
- cl-sendgrid, to send emails easily with the Sendgrid API.
- progressons - a progress bar.
- cl-readline (maintainer)
- cl-ansi-term (maintainer)
software:
- Abelujo, a free software for bookshops (Python)
- ABStock, a catalogue of books (and other products)
- OpenBookStore, a personal book manager, aiming to replace Abelujo
- cl-torrents, with an experimental Weblocks front-end
tools:
- colisper, an interface to Comby, for syntactic code checking and refactoring of Lisp code.
- indent-tools (emacs package)
- print-licences
project skeletons and demos:
- lisp-web-template-productlist: Hunchentoot + easy-routes + Djula templates + Bulma CSS + a Makefile to build the project
- lisp-web-live-reload-example: an example of how image-based development is useful. Learn to interact with a running website, including with a remote one with Swank.
- Weblocks-todomvc
and others:
- the lisp-maintainers list.
- the funny Hacker Typer in Lisp.
- the list of languages implemented in Lisp.
I contribute to awesome projects such as:
- Weblocks, an isomorphic web framework. I helped write the quickstart, fixed HTML generation in tables, wrote more documentation, raised issues.
- the Nyxt browser: I was part of the team in 2019, I am the second contributor of that year.
and I fix bugs when I see them (Mito (my contributions!), Djula…).
You can reach me by email at vindarel, mailz dot org. I am /u/(reverse (str:concat “vince” “zd”)) on reddit.
This website’s sources are on Gitlab: https://gitlab.com/lisp-journey/lisp-journey.gitlab.io/issues

AdLitteram 11
MonkeyUser 02 02 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

State of Clojure 2016 Results
Clojure News 31 01 2017
Welcome back to the annual State of Clojure survey results. This year we held steady in our response rate as 2,420 of you took the time and effort to weigh in on your experience with Clojure - as always, we appreciate that time and effort very much. And, as always, thanks to Chas Emerick for starting this survey 7 years ago.
Clojure (and ClojureScript) were envisioned as tools that could make programming simple, productive, and fun. They were always aimed squarely at the working developer - someone being paid to solve complicated problems who needed to focus more on the solution and less on the unnecessary complexity surrounding it. While we love the academics, open source developers, and hobbyists who have flocked to Clojure, we are always happy to see signs of commercial adoption.
Last year, we had an outright majority of users (57%) using Clojure at work. This year, that number accelerates up to 67%.
Within this group of users, several interesting themes emerge:
In addition to these themes, we’ve included detailed analysis of the individual questions as well as links to the raw data.
Commercial Clojure use is for products, not just internal tools
A whopping 60% of respondents who use Clojure at work are building applications for people "outside my organization". We changed the wording of the answers to this question from the 2015 survey, so a direct head-to-head comparison isn’t possible. However, in 2015, fully 70% of respondents said their use was for "personal" projects, while 42% said "company-wide/enterprise". This year, only 5% answered "just me". Even without the direct results comparison, the data shows a dramatic shift towards building products.

This year we also introduced a new question, asking what industry or industries people develop for. For commercial users, "Enterprise Software" was the leader (at 22%), followed by "Financial services/fintech", "Retail/ecommerce", "Consumer software", "Media/advertising", and "Healthcare". Everything else was at under 5% reporting. When we dig deeper and look at each of those industries in turn, we find that within each one, "outside my organization" is still the most common answer. In fact, only in "Financial services/fintech" do internal tools come within 15% of "outside my organization".

Clojure users are adopting the public cloud
Last year, 51% of respondents said they were deploying into the public cloud. This year, that number is up to 57%, coming almost entirely at the expense of "traditional infrastructure" (private/hybrid cloud was essentially unmoved). Recently, rescale released a report estimating that "we are in fact only at about 6% enterprise cloud penetration today" (https://blog.rescale.com/cloud-3-0-the-rise-of-big-compute/). Clojurists in the workforce are considerably ahead of this curve, if true.

There is, unsurprisingly, a heavy correlation between use of the public cloud and developing applications for use "outside my organization". The use of the public cloud also skews heavily towards smaller organizations (companies of fewer than 100 people make up 70% of the public cloud group, while only 55% of the "traditional infrastructure" fell into that category).
There were only two industries where traditional infrastructure dramatically beat public cloud: Government/Military (which seems obvious) and Academia (which seems sad, although it could be a reflection of universities' sunk investment in infrastructure). And only Telecom had a majority of respondents indicating "private/hybrid", which is almost certainly a reflection of the fact that hybrid cloud offerings are, by and large, products from the Telecom sector.

Clojure has penetrated all kinds of companies, not just startups
If you look at the spread of response for size of organization, while there is a clear winner (11-100), the split is fairly even otherwise. A full 17% of responses were from companies of 1000+ people.

Web development and open source development are the dominant two domains regardless of company size, but coming in at a strong #3 is "building and delivering commercial services", except when you look at responses from 1000+ companies, in which case "enterprise apps" unsurprisingly moves ahead.

"Enterprise software" is the #1 industry regardless of company size. However, #2 is quite distinctly different across sizes — in smaller companies (< 100 employees), "consumer software" is the strong #2, whereas for companies > 100 employees, financial services is the dominant #2.
(An interesting aside: most industries show a normal bell curve, with most respondents coming from the middle two categories, 11-100 and 101-1000. For example:

Only two industries show the inverted bell curve, with the most respondents at the edges — Academia, and Government/Military.

You will note that these are the two industries where "traditional infrastructure" also dominates, so the distribution of respondents either being from the largest [most conservative] and smallest [most disruptive] paints an interesting picture of how industries change.)
One of the biggest barriers to adoption is corporate aversion to new technologies
As was true the last two years, error messages and "hiring and staffing" are the top 2 reasons given for "What has been most frustrating or has prevented you from using Clojure more than you do now?" though both have fallen several percent since then. Interestingly, "Need docs/tutorials" has jumped from #5 in 2015 to #3 now, which corresponds well with a continuing growth of new entrants into the community.

When you break down respondents by size, each category is relatively uniform with one glaring exception: for some reason, companies of 100-1000+ people have a problem with the lack of static typing (it is a strong #3 in that cohort). Everyone else has a carbon copy distribution of the overall answers. When you look by industry, the "enterprise software" crowd would clearly benefit from more tools and a better IDE experience.
What we found fascinating was drilling through the free answer portion of the responses to this question. Next year, we’ll be adding a new possible answer: "corporate aversion to new technologies". If it was captured as one of the main responses, it would come in #2 or #3 overall. We clearly have work to do as a community to arm the technologists who wish to adopt Clojure with the materials and support they need to overcome internal inertia or resistance. That’s an area we’d love to both see more people contributing, but also letting us at Cognitect know what else we could provide that would be useful.
Summary
When you dig into these numbers, you see a technology that has been accepted as a viable tool for crafting solutions across industries, company types and sizes, and target domains. As you might expect, adoption of Clojure seems closely correlated with the adoption of other new technologies, like the public cloud, and Clojure is beset with some of the same headwinds, like corporate aversion to new things. We are encouraged by the maturation of the community and of the ability of the technology and its adherents to tackle the hard problems of commercial software development.
Detailed Results
In addition to the big themes above, this section highlights a few of the more interesting results for specific questions in the survey. For details on all questions, see the full results.
Which dialects of Clojure do you use?
The interesting detail here was that the percentage of respondents using ClojureScript rose yet again, such that 2/3 of users are now using both Clojure and ClojureScript together (this has continually risen from about 1/2 3 years ago):

Clojure increasingly delivers on the promise of a single unified language stack that can be used to cover an entire application.
Prior to using Clojure, ClojureScript, or ClojureCLR, what was your primary development language?
We’ve changed the way this question is asked and the options provided several times so it’s difficult to assess trends. However, it’s clear that developers come to Clojure either from imperative/OO languages (Java, C#, C/C++) or from dynamic languages (Ruby, Python, JavaScript, etc) with only small numbers coming from functional programming languages like Scala, Common Lisp, Haskell, Erlang, etc.

What is your primary Clojure, ClojureScript, or ClojureCLR development environment?
Due to the general volatility of tools, it’s interesting to see how this changes year to year. However, this year things were mostly pretty static with the three most common choices again Emacs/CIDER, Cursive/IntelliJ, and Vim with no major changes in percent use. Sublime, Light Table, and Eclipse/Counterclockwise all became a bit less common. The most interesting development was the rise in the use of Atom which was a new choice and selected by 6% of respondents.

What Clojure, ClojureScript, or ClojureCLR community forums have you used or attended in the last year?
This was a new question this year, trying to get a sense of how people are interacting with other members of the community. The Clojurians slack channel was the most frequently used - this is a great place to connect with others and has taken the place of IRC for many. About half of respondents are using the original language mailing lists, and almost that many have looked at the Clojure subreddit.

Interestingly, most respondents have not attended either local Clojure meetups or Clojure conferences either in-person or remotely. There are many active Clojure meetups and conferences in the world - if you’d like to talk to other Clojurists, take a look and see if one is near you!
Which versions of Clojure do you currently use in development or production?
Library maintainers are often interested in how quickly users are migrating to newer versions of Clojure as they decide whether they can use new features. We can see in this year’s survey that most users are on the latest stable version (1.8.0) - 83%, with a third of respondents already using the 1.9 prereleases prior to final release. Less than 5% are using a Clojure version older than Clojure 1.7, which is good news for those that wish to rely on 1.7 features like cljc files or transducers.

What versions of the JDK do you target?
Similar to the prior question, it’s useful to track what versions of the JDK are in use in the community. We saw significant consolidation to Java 1.8 over the past year (with Java 1.9 on the horizon) - 95% of users are using it with only about 2% using a version older than Java 1.7. For the moment, Clojure is still supported on Java 1.6 but eventually that support will be dropped.

What tools do you use to compile/package/deploy/release your Clojure projects?
While Leiningen continues to be ubiquitous, boot made significant advances this year, moving from 13% usage to 22% usage.

What has been most frustrating or has prevented you from using Clojure more than you do now?
Error messages continued to be the top frustration for people and we will continue to improve those with the integration of spec in Clojure 1.9. Interestingly, the majority of the other frustrations went down this year compared to last year:
-
Hiring/staffing - from 33% to 30%
-
Scripting - from 33% to 18% (maybe due to the rise of Planck and Lumo)
-
Docs - from 25% to 22% (hopefully the new Clojure and ClojureScript web sites have helped)
-
Static typing - from 23% to 16% (maybe due to the release of spec)
-
Long-term viability - from 20% to 10%
-
Finding libraries - from 16% to 11%
-
Portability - from 10% to 5% (continued uptake of cljc / reader conditionals)

Which JavaScript environments do you target?
The most interesting story here is the rise in three areas:
-
React Native - 18% (new choice this year)
-
Electron - 11% (new choice this year)
-
AWS Lambda - 9% (vs 5% last year)
As JavaScript continues to seep into every area of computing, ClojureScript is following along with it and seeing new and interesting uses.

Which tools do you use to compile/package/deploy/release your ClojureScript projects?
We saw a small increase in Figwheel this year (after a huge jump after its release) with about 2/3 of ClojureScript users now using it. And as we saw in the prior tools question, there is a big jump in the number of ClojureScript developers using boot (from 15 to 23%).

Which ClojureScript REPL do you use most often?
Again, even more usage of Figwheel here (76%, up from 71% last year). We added Planck this year and it registered at 9%. The Lumo repl was not listed as a choice but did make a showing in the comments.

How are you running your ClojureScript tests?
We added this question to gather some information on what seems like an underserved area of the ecosystem. Of those who responded, we saw:

However, there was a lot of information in the "Other" responses as well. At least 60 people (more than replied for the Nashorn choice above) responded that they were either not testing at all or were relying on testing their ClojureScript via cljc tests that ran in Clojure. This is a great area for future improvements with no real consensus and a lot of developers not even doing it at all. Some other choices seen in the comments were Devcards, Karma, Phantom, and doo.
What has been most frustrating or has prevented you from using ClojureScript more than you do now?
The top answer here was "Using JavaЅcript libs with ClojureScript / Google Closure", which was a new choice we added this year. David Nolen and the ClojureScript community have been working hard on some of the biggest pain points in this area, which culminated in the recent release of a new ClojureScript version with better support for externs and modules.

Some of the other choices fell in importance this year (similar to Clojure):
-
"Using ClojureScript REPLs" went from 45% to 34% (rise of Figwheel, Planck, Lumo)
-
"Availability of docs" went from 39% to 31% (new ClojureScript web site)
-
"Long-term viability" went from 15% to 10%
Here you can add any final comments or opinions…
The majority of responses (~62%) here either expressed sentiments of happiness or gratitude (always good to see). Other categories centered around expected themes (many are areas of current or future work): docs/tutorials, error messages, tooling, startup time, etc. One relatively stronger theme this year was the need for better marketing for the purposes of expanding or introducing Clojure within organizations, which is a great area for contribution from the entire community.

Technically not a bug
MonkeyUser 31 01 2017

AdLitteram 10
MonkeyUser 27 01 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

Vim vs Emacs
MonkeyUser 24 01 2017
Special thanks to Fabian for suggesting the topic for this comic.

AdLitteram 9
MonkeyUser 20 01 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

Today we’re launching an official Instapaper extension for Firefox!
We’ve been getting a lot of requests from Firefox users to build an extension to match the ones we offer for Chrome, Opera and Safari. Now, we’re happy to roll out the same great saving features for Firefox.
To install the new Firefox extension, open www.instapaper.com/save on Firefox or go to Mozilla’s Add-on page for Instapaper.
Like our other browser extensions, when you find an article or video you want to save, just tap or click once to save it to Instapaper. Other convenient features include:
A keyboard shortcut: A Ctrl+shift+S keyboard shortcut to save the article you’re currently viewing.
A right-click menu option: To save the current page–or any link on the current page–we added an “Instapaper” option to the right-click menu.
More Instapaper save buttons: Now you can “Save to Instapaper” directly from Twitter and Hacker News. Alongside each tweet containing a URL or a Hacker News post, you’ll now see an inline Instapaper save button.
Saving directly to folders: Once your save is confirmed, click the folder icon on the save overlay to direct the article right into one of your folders.
Toggle options: The keyboard shortcut and inline saving options can be toggled on/off.

If you’ve got any questions or feedback, just let us know via support@help.instapaper.com or @InstapaperHelp on Twitter.
– Instapaper Team

var thanks = [‘Jonathan Cary’, ‘Микола Махін’, ‘Maksim Tsvetovat’, ‘Shane Hutter’, ‘/u/GeneReddit123’, ‘Bram Patelski’, ‘Reddit’, ‘Twitter’, ‘Facebook’]
Special thanks to: NixCraft ](https://www.facebook.com/nixcraft/) [

Security
MonkeyUser 17 01 2017

AdLitteram 8
MonkeyUser 13 01 2017
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

HTTP Status Codes
MonkeyUser 10 01 2017
 Thanks Lionel
Thanks Lionel
 Thanks /u/spartaboy
Thanks /u/spartaboy
 Thanks @brampatelski
Thanks @brampatelski
 Thanks @brampatelski
Thanks @brampatelski
Working With APIs the Pythonic Way
Haki Benita 04 01 2017
Communication with external services is an integral part of any modern system. Whether it's a payment service, authentication, analytics or an internal one - systems need to talk to each other. In this short article we are going to implement a module for communicating with a made-up payment gateway, step by step.
Chrome DevTools provide a lot of useful features for debugging and profiling applications in the browser. As it happens, you can to connect DevTools to a Node.js process as well. Let's take a look at debugging the guestbook project from the examples repository.
You'll first have to start Figwheel to compile the project by running the following command:
lein build
Once the project is compiled, you have to start Node with the --inspect flag:
$ node --inspect target/out/guestbook.js
Debugger listening on port 9229.
Warning: This is an experimental feature and could change at any time.
To start debugging, open the following URL in Chrome:
chrome-devtools://devtools/bundled/inspector.html?experiments=true&v8only=true&ws=127.0.0.1:9229/0dbaef2a-996f-4229-8a52-6c4e50d0bf18
INFO [guestbook.core:19] - guestbook started on 127.0.0.1 : 3000
Figwheel: trying to open cljs reload socket
Figwheel: socket connection established
You'll see that there's a URL printed in the console when the app starts. Copy this URL and open it in Chrome to connect DevTools to your Node process. At this point you can use all the tools the same way you would with an application running in the browser. You can debug ClojureScript files, profile the process, and so on.
Gotchas
Unfortunately, there's a small bug in the ClojureScript compiler that prevents timestamped source maps from working with Node. The problem is that that the compiler assumes that ClojureScript is running in browser and appends ?timestamp at the end of the file name as if it was a URL. Since Node is looking for actual files on disk, it fails to find the source map.
Currently, the workaround for this is to set :source-map-timestamp false in the compiler options. However, since Node caches the source maps, you have to restart the process any time you make a change in the code to get accurate line numbers.
The good news is that restarts happen instantaneously, and you can automate this process using Node supervisor as follows:
npm install supervisor -g
supervisor --inspect target/out/guestbook.js
That's all there is to it.

MonkeyUser in 2016
MonkeyUser 23 12 2016

Decision Boundary
MonkeyUser 22 12 2016
Macchiato Modules
(iterate think thoughts) 20 12 2016
As I discussed in the last post, Ring middleware stack closely resembles modules in a framework. However, one notable difference is that middleware functions aren't directly aware of one another. When the handler is passed to a middleware function, that function has no way of knowing what other middleware might have been wrapped around the handler by the time it got to it.
Conversely, these functions can't know what middleware will be wrapped after that they may depend on. Since middleware that was wrapped last will be invoked first, inner middleware ends up being dependent on the outer middleware.
This presents a number of problems. We can end up with multiple copies of the same middleware wrapped around the handler, middleware could be wrapped in the wrong order, or required middleware might be missing altogether. All of the above cases can lead to unpredictable behaviors, and can be difficult to debug.
One way to mitigate the problem is by creating a default middleware stack, such as seen in the ring-defaults library. This takes care of ensuring that all the core middleware is wrapped correctly, but doesn't help with middleware libraries added by the user. Another approach is to wrap the Ring stack in a higher level abstraction as seen with Integrant.
The solution I came up with for Macchiato is to use metadata attached to the handler to track the middleware that's been applied to it. This metadata can be used to inform how the middleware is loaded, and address the problems outlined above.
Let's take a look at an example of how this works in practice. Let's say we have the default handler such as:
(defn handler [req res raise]
(res {:body (str (-> req :params :name))}))
Then, let's say we have two pieces of middleware we wish to wrap the handler with. The first will parse the request params, and the second will keywordize the params. The second middleware function depends on the first in order to work.
(defn parse-params [req]
;;parses request parameters into a map
)
(defn wrap-params [handler]
(fn [req res raise]
(handler (parse-params req) res raise)))
(defn keywordize-params [params]
;;keywordizes the params
)
(defn wrap-keyword-params [handler]
(fn [req res raise]
(handler (update req :params keywordize-params) res raise)))
We have to make sure that the middleware is chained as follows to get keywordized params:
(def wrapped-handler (-> handler
wrap-keyword-params
wrap-params))
However, it's not possible to deduce that this actually happened given the resulting handler function. Let's see how we can use metadata to address this problem. We'll update the wrap-params and the wrap-keyword-params functions as follows:
(defn
^{:macchiato/middleware
{:id :wrap-params}}
wrap-params [handler]
(fn [req res raise]
(handler (parse-params req) res raise)))
(defn
^{:macchiato/middleware
{:id :wrap-keyword-params
:required [:wrap-params]}}
wrap-keyword-params [handler]
(fn [req res raise]
(handler (update req :params keywordize-params) res raise)))
The :id key in the metadata is meant to specify the specific type of middleware as opposed to a concrete implementation. If two pieces of middleware happen to implement the same functionality they should use the same :id.
The :required key specifies the keys for the :ids that the particular middleware function depends on. In this case, wrap-keyword-params requires wrap-params to be present.
Next, we can write the code that will update the handler metadata each time it's wrapped with a middleware function.
(defn update-middleware-meta [handler handler-middleware middleware-meta]
(with-meta
handler
{:macchiato/middleware
(conj handler-middleware middleware-meta)}))
(defn loaded? [middleware {:keys [id]}]
(some #{id} (map :id middleware)))
(defn- middleware-from-handler [handler]
(->> handler meta :macchiato/middleware (remove nil?) vec))
(defn wrap
([handler middleware-fn]
(wrap handler middleware-fn nil))
([handler middleware-fn opts]
(let [handler-middleware (middleware-from-handler handler)
middleware-meta (-> middleware-fn meta :macchiato/middleware)]
(if (loaded? handler-middleware middleware-meta)
handler
(update-middleware-meta
(if opts
(middleware-fn handler opts)
(middleware-fn handler))
handler-middleware
middleware-meta)))))
The wrap function uses the :macchiato/middleware metadata key to get the currently applied middleware. When a middleware function with the same :id is already present, then the original handler is returned. Otherwise, the handler is wrapped with the middleware and its metadata is updated.
Let's update the original code that wrapped the handler to use the wrap function:
(def wrapped-handler (-> handler
(wrap #'wrap-keyword-params)
(wrap #'wrap-params)))
We can now use the meta function to access the metadata that was generated for the handler:
(meta wrapped-handler)
{:macchiato/middleware
[{:id :wrap-params}
{:id :wrap-keyword-params
:required [:wrap-params]}]}
This tells us exactly what middleware has been applied to the handler and in what order, allowing us to validate that the middleware chain. This is accomplished as follows:
(defn validate [handler-middleware
{:keys [id required] :as middleware-meta}]
(when (not-empty (difference (set required)
(set (map :id handler-middleware))))
(throw (js/Error. (str id " is missing required middleware: " required))))
middleware-meta)
(defn validate-handler [handler]
(let [middleware (middleware-from-handler handler)]
(loop [[middleware-meta & handler-middleware] middleware]
(when middleware-meta
(validate handler-middleware middleware-meta)
(recur handler-middleware)))
handler))
With the above code in place we're now able to ensure that middleware functions are not loaded more than once, and that the order of middleware is correct.
Finally, Macchiato provides the macchiato.middleware/wrap-middleware convenience function that allows wrapping multiple middleware functions around the handler:
(m/wrap-middleware
handler
#'wrap-anti-forgery
[#'wrap-session {:store (mem/memory-store)}]
#'wrap-nested-params
#'wrap-keyword-params
#'wrap-params)
I think that the approach of using metadata provides an elegant view into the state of the middleware chain, while allowing Macchiato to stay compliant with Ring middleware semantics.
Another advantage of using metadata is that it makes the mechanism user extensible. If you're using a piece of middleware that doesn't have the metadata you need, you can always set it yourself.
The latest release of Macchiato has all the core middleware tagged with the appropriate metadata, and macchiato-defaults generates a handler that has the :macchiato/middleware key pointing to the vector of the middleware that was applied.

Acquisition
MonkeyUser 20 12 2016
Thanks @i_am_r0by
I've been making steady progress on Macchiato in the past weeks. This post will discuss some of my thought process and design decisions I settled on during this time.
One of the core questions is what problem the project aims to solve, and how it aims to do that.
The goal for Macchiato is to provide a way to build Node web applications using CojureScript. Ultimately, I'd like to produce something that's immediately usable and works well out of the box. The best way to accomplish that is to leverage the existing work in this domain.
The Ring stack is the most popular platform for developing Clojure applications on the JVM, and rightfully so in my opinion. It does an excellent job of abstracting the HTTP protocol, and provides a simple and intuitive API to the user.
Ring added async handler support in version 1.6, making it possible to implement compatible HTTP handlers on top of Node. This in turn allowed to port the core middleware stack to Macchiato.
As I was porting ring-core on Node, I've come to realize that Ring middleware libraries have a lot in common with framework modules.
These libraries are meant to be used together in a standard way, they're designed to compose, and they're often built on top of each other.
However, the Ring stack acts as a foundation rather than a framework. To understand this idea, let's first look at the traditional framework approach.
Frameworks
The core problem the frameworks attempt to solve is to provide a standard way to build software where the user can focus on writing the code that's relevant to their application. Meanwhile, the framework attempts to take care of all the incidental details around it.
The way traditional frameworks, such as Spring, accomplish this is through inversion of control. However, since the connections are no longer expressed directly in code, it makes it difficult to navigate them clouding the logic of the application.
Another problem with this approach is that the framework necessarily has to make a lot of decisions up front. Yet, a general purpose framework also has to be flexible enough to accommodate many types of application.
A framework typically turns into an exercise in designing a solution without knowing the problem. My experience is that it's not an effective way to write software in practice.
However, I think that the problem the frameworks attempt to solve is real. Having to artisanally handcraft each application from ground up is tedious and error prone.
Foundations
A better way to approach this problem is by addressing the known common needs. The key insight of Ring is that majority of reusable work is centred around processing the incoming HTTP requests and outgoing responses.
Ring provides a simple core that different middleware can be attached to in order to extend its functionality. We can add middleware that facilitates authentication, sessions, and so on. Buddy, compojure-api, and Sente are all great examples of this approach in practice.
One of the downsides of the library approach is that libraries aren't aware of one another, and the user has to glue them together. However, Ring middleware stack is not just a set of random libraries. Since Ring defines what the request and response must look like, it informs the design of libraries built on top of it.
The Ring stack is a mature and battle tested foundation for building the rest of the application on top of. At the same time, it doesn't attempt to guess the problems that are specific to your application. You're free to solve them in a way that makes sense to you.
Macchiato
Macchiato implements Ring 1.6 async handlers on top of the ClientRequest and the ServerResponse classes exposed by the Node HTTP module. Using the same API provides a consistent experience developing web applications on both platforms, and facilitates code reuse between them.
One immediate benefit of making Macchiato compatible with Ring was the ability to leverage its test harness. As I port the middleware to Node, I'm able to verify that it still behaves the same as the original. Going forward, it will be possible to write cljc middleware that targets both Ring and Macchiato.
Alongside the creation of the core libraries, I've been working on the template that packages everything together for the user. This template is informed by my experience working on Luminus and uses many of the same patterns and structure. If you're already familiar with Luminus, then you'll feel right at home with Macchiato.
As I noted in the last post, Macchiato development experience is very similar to working with Clojure on the JVM, and Chrome devtools along with Dirac look promising for debugging and profiling apps.
Meanwhile, the project has already garnered interest from the community. Ricardo J. Méndez has been working on creating a HugSQL style database access library, and Andrey Antukh, has been working on the dost crypto library.
It's great to see such prominent members of the community take interest in the project in the early stages. My hope is that as Macchiato matures we'll see many more supporting libraries built around it.
There's now a #macchiato channel on Clojurians slack. Feel free to drop by and discuss problems and ideas.
If you're looking to contribute to an open source project, Macchiato is a great opportunity. The project is still in the early days and there are many low hanging fruit. The project needs more tests, libraries, and documentation. This is a great time to make an impact on its future direction.

AdLitteram 7
MonkeyUser 16 12 2016
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

If Buildings Were Built Like Software
MonkeyUser 15 12 2016


Development Platforms
MonkeyUser 13 12 2016

AdLitteram 6
MonkeyUser 09 12 2016
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

Targeted Branding
MonkeyUser 08 12 2016

Developer Productivity
MonkeyUser 06 12 2016

AdLitteram 5
MonkeyUser 02 12 2016
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)
From time to time I like to read documentation of modules I think I know well. The python documentation is not a pleasant read but sometimes you strike a gem.

Everysoft Corporation
MonkeyUser 01 12 2016
I recently started the Macchiato project to provide a platform for building ClojureScript based apps on top Node.js.
First, let's look at some of the reasons for running ClojureScript on the server. The JVM is an excellent platform, it's mature, performant, and has a large ecosystem around it. This makes it a solid choice for a wide range of applications.
However, there are situations where the JVM might not be a good fit. It's a complex piece of technology that requires experience to use effectively. It has a fairly large footprint even from small applications. The startup times can be problematic, especially when it comes to loading Clojure runtime.
Meanwhile, Node.js also happens to be a popular platform with a large ecosystem around it. It requires far less resources for certain types of applications, has very fast startup times, and its ecosystem is familiar to many JavaScript developers.
Another appeal for Node based servers comes from building full stack ClojureScript single-page applications, since using Node on the server facilitates server-side rendering for any React based libraries.
While there are a few existing experiments using ClojureScript on Node, such as Dog Fort, none of these appear to be actively maintained. Since ClojureScript and its ecosystem have evolved in the meantime, I wanted to create a fresh stack using the latest tools and best practices.
Overview
My goal for Macchiato is to provide a stack modeled on Ring based around the existing Node ecosystem, and a development environment similar to what's available for Clojure on the JVM.
The Stack
I think it makes sense to embrace the Node ecosystem and leverage the existing modules whenever possible. For example, Ring style cookies map directly to the cookies NPM module. Conversely, there are a number of excellent ClojureScript libraries available as well, such as Timbre, Bidi, and Mount.
I used a Ring inspired model where I created wrappers around Node HTTP request and response objects. This allowed adapting parts of Ring, such as its session store implementation, with minimal changes.
The ClientRequest object is translated to a Clojure map, and the response map is written to the ServerResponse object. The request handler is implemented as follows:
(defprotocol IHTTPResponseWriter
(-write-response [data res] "Write data to a http.ServerResponse"))
(defn response [req res opts]
(fn [{:keys [cookies headers body status]}]
(cookies/set-cookies cookies req res (:cookies opts))
(.writeHead res status (clj->js headers))
(when (-write-response body res)
(.end res))))
(defn handler [handler-fn & [opts]]
(let [opts (or opts {})]
(fn [req res]
(handler-fn (req->map req res opts) (response req res opts)))))
The handler accepts a handler-fn function that's passed the request map produced by the req->map helper. The handler-fn is expected to return a request handler function that will be used to generate the response. This function should accept the request map and the response call back function that writes the response map to the ServerResponse object. The IHTTPResponseWriter protocol is used to serialize different kinds of responses.
Concurrent Request Handling
JVM servers commonly use a listener thread for accepting client requests, the connections are then passed on to a thread pool of request handlers. This allows the listener to continue accepting connections while the requests are being processed.
Since Node is single threaded, long running request handlers block the server until they finish. While async operations can be used to handle IO in the background, any business logic will end up preventing the server from accepting new connections while it's running.
One way around this is to use the cluster module that spins up a single listening process that forks child processes and dispatches the requests to them. Setting this up is pretty straight forward:
(defstate env :start (config/env))
(defstate http :start (js/require "http"))
(defn app []
(mount/start)
(let [host (or (:host env) "127.0.0.1")
port (or (some-> env :port js/parseInt) 3000)]
(-> @http
(.createServer
(handler
router
{:cookies {:signed? true}
:session {:store (mem/memory-store)}}))
(.listen port host #(info "{{name}} started on" host ":" port)))))
(defn start-workers [os cluster]
(dotimes [_ (-> os .cpus .-length)]
(.fork cluster))
(.on cluster "exit"
(fn [worker code signal]
(info "worker terminated" (-> worker .-process .-pid)))))
(defn main [& args]
(let [os (js/require "os")
cluster (js/require "cluster")]
(if (.-isMaster cluster)
(start-workers os cluster)
(app))))
However, it's worth noting that unlike threads, processes don't share memory. So, each child that gets spun up will require its own copy of the memory space.
The Template
I setup a template that creates a minimal app with some reasonable defaults. This template is published to Clojars, and you can try it out yourself by running:
lein new macchiato myapp
The template is setup similarly to Luminus. The source code for the project is found in the src folder, and the env folder contains code that's specific for dev and prod environments.
The project.clj contains dev and release profiles for working with the app in development mode and packaging it for production use. The app can be started in development mode by running:
lein build
This will clean the project, download NPM modules, and start the Figwheel compiler. Once Figwheel compiles the sources, you can run the app with Node in another terminal as follows:
node target/out/myapp.js
The app should now be available at http://localhost:3000.
Figwheel also starts the nREPL at localhost:7000. You can connect to it from the editor and run (cljs) to load the ClojureScript REPL.
Packaging the app for production is accomplished by running:
lein package
This will print out package.json for the app and generate the release artifact called target/release/myapp.js.
Looking Forward
Overall, I think that ClojureScript on top of Node is ready for prime time. It opens up server-side Clojure development to a large community of JavaScript developers, and extends the reach of Clojure to any platform that supports Node.
While the initial results are very promising, there is still much work to be done in order to provide a solid stack such as Luminus. If you think this project is interesting, feel free to ping me via email or on the Clojurians slack. I would love to collaborate on making Macchiato into a solid choice for developing Node based applications.
Updating site CSS
Posts on James Routley 29 11 2016

CSS Layout
MonkeyUser 29 11 2016

AdLitteram 4
MonkeyUser 25 11 2016
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

Retrospective Accesories
MonkeyUser 24 11 2016

Requirements vs. Implementation
MonkeyUser 22 11 2016
En este tutorial se va a explicar como solucionar los problemas ocasionados por la tarjeta de red inalámbrica Asus AC750 en Linux, que provoca lentitud y cortes en la conexión a Internet.
Lo primero que se tendrá que realizar será abrir la terminal del sistema, que nos servirá para inroducir los comandos necesarios (Puedes utilizar el atajo del teclado Ctr+Alt+T)
1- Comprobar la tarjeta de red inalámbrica detectada por el sistema:
lspci | grep Wireless
2- Si utilizas Ubuntu será necesario instalar las siguientes herramientas necesarias:
sudo apt-get install linux-headers-generic build-essential git
3- Descargar de Git el driver necesario y acceder a su carpeta:
git clone https://github.com/lwfinger/rtlwifi_new.git
cd rtlwifi_new
4- Se comenzará la instalación del driver:
make
sudo make install
sudo modprobe rtl8821ae
5- Finalmente reinicia el sistema:
reboot
De esta forma ya debería funcionar correctamente la conexión a Internet inalámbrica, para comprobarlo recomendamos realizar un test de velocidad y comprobar si ya da una velocidad acuerdo a tú conexión a Internet

If you use an Nvidia driver with a Gnome desktop and you decide to resume your system from a suspension or hibernation, you will see that your desktop it's broken like in this screenshot.
To fix this problem we need to refresh the Gnome desktop after this happens. We have created a bash script that refresh Gnome desktop after resuming the system. Follow the steps below to implement it in your system:
- At your terminal you need to go to the path /lib/systemd/system-sleep/ and create a new file that will contain the bash script. You can use the text editor that you prefer, we will use nano.
- Now you can copy and paste in this new file the follow bash script that we mentioned. This script will refresh Gnome desktop each time you resume after suspension/hibernation.
- After saving the file you will need assign file permissions.
- Finally, the script be working. You can try to suspend to check it's fixed after resume.
[code]sudo nano /lib/systemd/system-sleep/broken-desktop-fix[/code]
[code]#!/bin/bash
case "$1" in
post)
DISPLAY=:0.0 ; export DISPLAY
STR="$(users)"
echo ${STR}
IFS=' ' read -ra NAMES <<< ${STR}
for i in "${NAMES[@]}"; do
su $i -c 'dbus-send --type=method_call --dest=org.gnome.Shell /org/gnome/Shell org.gnome.Shell.Eval "string:global.reexec_self()"'
done;;
esac[/code]
[code]sudo chmod 755 /lib/systemd/system-sleep/broken-desktop-fix[/code]
Also we can do it manually each time it happens with Alt + F2 and then in the text box introduce r and finally press Enter, and Gnome will refresh to fix it.

Four years. Three hundred (mostly nonfiction) books. There are a few simple lessons I learned after reading all of those. They might seem too obvious, but aren’t all the great truths simple? Anyway, here they are: It’s much better to read the best book on the topic 5 times, than to read 5 different books on... Continue reading
The post Lessons learned after 300 books in 4 years appeared first on Jovica Ilic.

AdLitteram 3
MonkeyUser 18 11 2016
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)

Testing: Hammering Nails
MonkeyUser 17 11 2016

Division
MonkeyUser 15 11 2016

AdLitteram 2
MonkeyUser 11 11 2016
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image. (use the commenting section if you think you know the answer)
Hunting down slow tests by reporting tests that take longer than a certain threshold (Because the first step to better test performance is awareness!)

Battle of the JS frameworks in 2016
MonkeyUser 08 11 2016

Open Source: Expectation vs. Reality
MonkeyUser 08 11 2016
There are many situations where the application needs to react to changes in the data. The simplest way to handle this requirement is to keep state in the server session. Unfortunately, this makes it difficult to scale applications horizontally, and can incur additional memory requirements.
A common solution to this problem is to use an external queue service that each instance of the application subscribes to. However, this adds a new component to the architecture that needs to be maintained.
A less known option is to use Postgres NOTIFY command to send push notifications from the database. This allows multiple instances of the application can subscribe directly to the database to listen for events.
This post will walk you through configuring a Luminus app to listen for Postgres notification, and broadcast them to the connected clients over a WebSocket.
prerequisites:
Let's start by creating a new project for our app:
lein new luminus pg-feed-demo +postgres +re-frame
The database
The first step is to create a schema for the app, and set the connection URL in the profiles.clj, e.g:
{:profiles/dev
{:env
{:database-url
"jdbc:pgsql://localhost:5432/feeds_dev?user=feeds&password=feeds"}}
Migrations
Once the schema is ready, we can write a migrations script that creates a table called events, and sets up a notification trigger on it. Let's run the following command in the project root folder to create the migration files:
lein migratus create events-table
Next, add the following script as the up migration:
CREATE TABLE events
(id SERIAL PRIMARY KEY,
event TEXT);
--;;
CREATE FUNCTION notify_trigger() RETURNS trigger AS $$
DECLARE
BEGIN
-- TG_TABLE_NAME - name of the table that was triggered
-- TG_OP - name of the trigger operation
-- NEW - the new value in the row
IF TG_OP = 'INSERT' or TG_OP = 'UPDATE' THEN
execute 'NOTIFY '
|| TG_TABLE_NAME
|| ', '''
|| TG_OP
|| ' '
|| NEW
|| '''';
ELSE
execute 'NOTIFY '
|| TG_TABLE_NAME
|| ', '''
|| TG_OP
|| '''';
END IF;
return new;
END;
$$ LANGUAGE plpgsql;
--;;
CREATE TRIGGER event_trigger
AFTER INSERT or UPDATE or DELETE ON events
FOR EACH ROW EXECUTE PROCEDURE notify_trigger();
Thenotify_trigger function will broadcast a notification with the table name, the operation, and the parameters when available. The event_trigger will run it whenever insert, update, or delete operations are performed on the messages table.
We'll also add the down migration for posterity:
DROP FUNCTION notify_trigger() CASCADE;
DROP TABLE events;
We can now run migrations as follows:
lein run migrate
Queries
Let's open the resources/sql/queries.sql file and replace the default queries with the following:
-- :name event! :! :n
-- :doc insert a new event
INSERT INTO events (event) VALUES (:event)
The server
Unfortunately, the official Postgres JDBC driver cannot receive asynchronous notifications, and uses polling to check if any notifications were issued. Instead, we'll use the pgjdbc-ng driver that provides support for many Postgres specific features, including async notifications. Let's update our app to use this driver instead by swapping the dependency in project.clj:
;[org.postgresql/postgresql "9.4.1211"]
[com.impossibl.pgjdbc-ng/pgjdbc-ng "0.6"]
Notification listener
Let's open up the pg-feed-demo.db.core namespace and update it to fit our purposes. Since we're no longer using the official Postgres driver, we'll need to update the namespace declaration to remove any references to it. We'll also add the import for the PGNotificationListener class that will be used to add listeners to the connection. To keep things simple, we'll also remove any protocol extensions declared there. The resulting namespace should look as follows:
(ns pg-feed-demo.db.core
(:require
[cheshire.core :refer [generate-string parse-string]]
[clojure.java.jdbc :as jdbc]
[conman.core :as conman]
[pg-feed-demo.config :refer [env]]
[mount.core :refer [defstate]])
(:import
com.impossibl.postgres.api.jdbc.PGNotificationListener))
(defstate ^:dynamic *db*
:start (conman/connect! {:jdbc-url (env :database-url)})
:stop (conman/disconnect! *db*))
(conman/bind-connection *db* "sql/queries.sql")
In order to add a notification listener, we first have to create a connection. Let's create a Mount defstate called notifications-connection to hold it:
(defstate notifications-connection
:start (jdbc/get-connection {:connection-uri (env :database-url)})
:stop (.close notifications-connection))
Next, we'll add functions that will allow us to add and remove listeners for a given connection:
(defn add-listener [conn id listener-fn]
(let [listener (proxy [PGNotificationListener] []
(notification [chan-id channel message]
(listener-fn chan-id channel message)))]
(.addNotificationListener conn listener)
(jdbc/db-do-commands
{:connection notifications-connection}
(str "LISTEN " (name id)))
listener))
(defn remove-listener [conn listener]
(.removeNotificationListener conn listener))
Let's start the application by running lein run in the terminal. Once it starts, the nREPL will become available at localhost:7000. When the REPL is connected, run the following code in it to start the database connection and register a listener:
(require :reload 'pg-feed-demo.db.core)
(in-ns 'pg-feed-demo.db.core)
(mount.core/start
#'*db*
#'notifications-connection)
(add-listener
notifications-connection
"events"
(fn [& args]
(apply println "got message:" args)))
We can now test that adding a new message produces the notification:
(event! {:event "hello world"})
One the function runs, we should see something like the following printed in the terminal as the message is added to the database:
got message: 32427 messages INSERT (0,"hello world")
WebSocket connection
We're now ready to setup the WebSocket connection that will be used to push notifications to the clients. We'll update the pg-feed-demo.routes.homenamespace to look as follows:
(ns pg-feed-demo.routes.home
(:require [pg-feed-demo.layout :as layout]
[compojure.core :refer [defroutes GET]]
[pg-feed-demo.db.core :as db]
[mount.core :refer [defstate]]
[immutant.web.async :as async]
[clojure.tools.logging :as log]))
(defstate channels
:start (atom #{}))
(defstate ^{:on-reload :noop} event-listener
:start (db/add-listener
db/notifications-connection
:events
(fn [_ _ message]
(doseq [channel @channels]
(async/send! channel message))))
:stop (db/remove-listener
db/notifications-connection
event-listener))
(defn persist-event! [_ event]
(db/event! {:event event}))
(defn connect! [channel]
(log/info "channel open")
(swap! channels conj channel))
(defn disconnect! [channel {:keys [code reason]}]
(log/info "close code:" code "reason:" reason)
(swap! channels #(remove #{channel} %)))
(defn home-page []
(layout/render "home.html"))
(defroutes home-routes
(GET "/" []
(home-page))
(GET "/events" request
(async/as-channel
request
{:on-open connect!
:on-close disconnect!
:on-message persist-event})))
The channels state will contain a set of all the channels for the currently connected clients.
The event-listener will create a new listener that's triggered when events are stored in the database. The handler function will broadcast each event to all the connected clients. Note that we need ^{:on-reload :noop} metadata on the listener to prevent it being registered multiple times in case the namespace is reloaded during development.
Whenever the server receives a message from a client, the message will be persisted to the database by the persist-event! function.
Finally, we'll create the /events route that will be used to manage WebSocket communication with the clients.
The client
The client will need to track the currently available messages, allow the user to send new messages to the server, and update the available messages based on server WebSocket notifications.
Let's run Figwheel to start the ClojureScript compiler before we start working on the client-side code by running the following command:
lein figwheel
Re-frame events
We'll start by adding a handler for adding messages in the pg-feed-demo.handlers namespace:
(reg-event-db
:event
(fn [db [_ event]]
(update db :events (fnil conj []) event)))
Next, we'll add a corresponding subscription to see the current messages in the pg-feed-demo.subscriptions namespace:
(reg-sub
:events
(fn [db _]
(:events db)))
WebSocket connection
We can now add a pg-feed-demo.ws namespace to manage the client-side of the WebSocket connection:
(ns pg-feed-demo.ws)
(defonce ws-chan (atom nil))
(defn send
[message]
(if @ws-chan
(.send @ws-chan message)
(throw (js/Error. "Websocket is not available!"))))
(defn connect-ws [url handler]
(if-let [chan (js/WebSocket. url)]
(do
(set! (.-onmessage chan) #(-> % .-data handler))
(reset! ws-chan chan))
(throw (js/Error. "Websocket connection failed!"))))
User interface
Finally, we'll update the pg-feed-demo.core namespace to list incoming events and allow the user to generate an event. To do that, We'll update the namespace to look as follows:
(ns pg-feed-demo.core
(:require [reagent.core :as r]
[re-frame.core :as rf]
[pg-feed-demo.handlers]
[pg-feed-demo.subscriptions]
[pg-feed-demo.ws :as ws]))
(defn home-page []
[:div.container
[:div.navbar]
[:div.row>div.col-sm-12>div.card
[:div.card-header>h4 "Events"]
[:div.card-block>ul
(for [event @(rf/subscribe [:events])]
^{:key event}
[:li event])]]
[:hr]
[:div.row>div.col-sm-12>span.btn-primary.input-group-addon
{:on-click #(ws/send (str "user event " (js/Date.)))}
"generate event"]])
(defn mount-components []
(r/render [#'home-page] (.getElementById js/document "app")))
(defn init! []
(rf/dispatch-sync [:initialize-db])
(ws/connect-ws
(str "ws://" (.-host js/location) "/events")
#(rf/dispatch [:event %]))
(mount-components))
That's all there is to it. We should now be able to send events to the server and see the notifications in the browser. We should also be able to generate events by running queries directly in the database, or in another instance of the application.
The complete source for the project is available here.

AdLitteram 1
MonkeyUser 04 11 2016
Welcome to AdLitteram. The challenge is to guess the programming term that is represented in the image.

Java vs. Javascript: For recruiters
MonkeyUser 03 11 2016
The built-in admin actions, operate on a queryset and are hidden in a dropbox menu. They are not suitable for most use cases. In this article we are going to add custom action buttons for each row in a Django Admin list view.
Today we’re making Instapaper Premium available to all Instapaper users, free of charge. Instapaper Premium is the best way to experience all that Instapaper has to offer, and we’re excited to open it up to everyone.
Before, some of our greatest features were limited to Instapaper Premium subscribers. Now that we’re better resourced, we’re able to offer everyone the best version of Instapaper. Starting today, all users will have access to:
- An ad-free Instapaper website
- Full-text search for all articles
- Unlimited Notes
- Text-to-speech playlists
- Unlimited speed reading
- “Send to Kindle” via bookmarklet and mobile apps
- Kindle Digests of up to 50 articles
For existing Instapaper Premium users, we’ll offer prorated refunds for your current subscription, and you’ll no longer be billed for Instapaper Premium. Thanks for your support throughout the years, we appreciate it.
All users will continue to have an ad-free Instapaper app experience, and we’re eliminating ads on the web entirely.
Opening Instapaper Premium is something we’ve always wanted to do, and we’re thrilled to give everyone the very best Instapaper experience. If you’ve got any questions or feedback, just let us know via support@help.instapaper.com or @InstapaperHelp on Twitter.
– Instapaper Team

Null Pointer
MonkeyUser 01 11 2016
Bullet Proofing Django Models
Haki Benita 25 10 2016
We recently added a bank account like functionality into one of our products. During the development we encountered some textbook problems and I thought it can be a good opportunity to go over some of the patterns we use in our Django models.

Heisenbug
MonkeyUser 25 10 2016

How Project Managers Are Seen By
MonkeyUser 25 10 2016
Doctor, te extraño
Legión del Espacio 24 10 2016

Bugfixing - for developers
MonkeyUser 20 10 2016

disaster Scale
MonkeyUser 17 10 2016

There are many editors and IDEs available for Clojure today. The most popular ones are Emacs with CIDER and IntelliJ with Cursive. While both of these options provide excellent development environments, they also require a bit of learning to become productive in.
Good news is that you don't have to learn a complex environment to get started. This post will walk you through the steps of configuring Atom editor editor to work with a Luminus project. We'll see how to configure Atom for editing Clojure code and how to connect it to the remote REPL started by the Luminus app for interactive development.
Prerequisites
You'll need the following installed to follow along with this post:
Configuring Atom
Let's take a look at the bare minimum Atom configuration for working with Clojure. Once you're up and running, you may with to look here for a more advanced configuration. We'll start by installing the following packages:
- parinfer or lisp-paredit package for structural editing
- proto-repl to connect to a Clojure REPL
Structural Editing
A structural editor understands the structure of Clojure code and provides shortcuts for manipulating s-expressions instead of lines of text. It also eliminates the need to manually balance the parens. This takes a bit of getting used to, but it will make working with Clojure a lot more pleasant in the long run.
Parinfer
The parinfer mode will attempt to automatically infer the necessary parens based on the indentation. This mode has a gentle learning curve and attempts to get our of your way as much as possible. You can read more about how it works here.
Paredit
The paredit mode takes a bit more getting used to, but provides you with precise control over code structure. Whenever you add a peren, a matching closing paren will be inserted automatically. Paredit will also prevent you you from deleting parens unless you have an empty pair.
The package also provides a handy ctrl-w shortcut that will extend the selection by s-expression. This is the recommended way to select code as you don't have to manually match the start and end of an expression when selecting.
The REPL
The REPL is an essential tool for working with Clojure. When integrated with the editor, it allows running any code that you write directly in the application.
Connecting the REPL
We'll create a new Luminus project with SQLite database support by running the following command:
lein new luminus myapp +sqliteOnce the project is created, we can go to the project folder and run the migrations:
cd myapp
lein run migrate
lein runThe app will start the nREPL server on localhost:7000 once it loads. Let's open the project in Atom and connect to the nREPL instance.
The default keybinding for connecting to the nREPL is ctrl-alt-, y on Windows/Linux and cmd-alt-, y on OS X. This should pop up a dialog asking for the host and the port.
Enter 7000 as the port and hit enter. If everything went well the REPL should now be connected to your project.
Once the REPL is connected we can try to evaluate some code in it. For example, let's check what namespace we're currently in by typing *ns* in the REPL and then hitting shift-enter. The result should look something like the following:

Let's navigate to the myapp.routes.home namespace and try to run some of the database query functions from there. We'll first need to require the database namespace:
(ns myapp.routes.home
(:require [myapp.layout :as layout]
[compojure.core :refer [defroutes GET]]
[ring.util.http-response :as response]
[clojure.java.io :as io]
;; add a reference to the db namespace
[myapp.db.core :as db]))
Once we've done that, we'll need to reload myapp.routes.home namespace. To do that we'll need to send the code from the editor to the REPL for evaluation.
There are a few commands for doing this. I recommend starting by using the ctrl-alt-, B shortcut that sends the top-level block of code to the REPL for execution. Place the cursor inside the ns declaration and hit ctrl-alt-, B to send it to the REPL. We can see that the REPL displays the code that was sent to it along with the result:

Now that we have the db namespace required, we can start the database connection state by typing the following command in the REPL:
(mount.core/start #'db/*db*)
The result should look as follows:

With the database is started, let's add a user to it by running the following code in the REPL:
(db/create-user!
{:id "foo"
:first_name "Bob"
:last_name "Bobberton"
:email "bob@foo.bar"
:pass "secret"})
We can also test that the user was added successfully by running:
(db/get-user {:id "foo"})
We can see that the user record exists in the database:
{:id "foo"
:admin nil
:is_active nil
:last_login nil
:first_name "Bob"
:last_name "Bobberton"
:email "bob@foo.bar"
:pass "secret"}
As you can see, the code that we run in the REPL executes in the context of the application and has access to all the resources and the application state. Let's take a closer look at how this helps us during development.
You might have noticed that the records we get back from the database use the _ character as word separator. Meanwhile, idiomatic Clojure code uses the - character. Let's write a couple of functions to transform the key names in the results.
A Clojure map represents its entities as vectors containing key-value pairs. We'll start by writing a function to rename underscores to dashes in map entries:
(defn clojurize [[k v]]
[(-> k name (.replaceAll "_" "-") keyword) v])
We'll load the function in the namespace by placing the cursor anywhere inside it and hitting ctrl-alt-, B to load it. Let's run this function in the REPL to see that it works:
(clojurize [:first_name "Bob"])
=>[:first-name "Bob"]
We can see that the result is what we expect. Next, let's write a function to rename the keys in a map:
(defn clojurize-keys [m]
(->> m (map clojurize) (into {})))
We'll load the new function and test that this works as expected in the REPL:
(clojurize-keys (db/get-user {:id "foo"}))
We see that the result is the translated map that we want:
{:id "foo"
:admin nil
:is-active nil
:last-login nil
:first-name "Bob"
:last-name "Bobberton"
:email "bob@foo.bar"
:pass "secret"}
Now that we have a nicely formatted result, let's add a route to query it in the browser:
(defroutes home-routes
(GET "/" [] (home-page))
(GET "/user/:id" [id]
(-> (db/get-user {:id id})
(clojurize-keys)
(response/ok)))
(GET "/about" [] (about-page)))
We can now navigate to http://localhost:3000/user/foo and see the user data.
Conclusion
That's all there is to it. While this setup is fairly minimal, it will let you play with a lot of Clojure features without having to spend practically any time learning and configuring an editor.

Universal Do Not Disturb Indicator
MonkeyUser 13 10 2016

Project Lifecycle
MonkeyUser 11 10 2016

Earlier this year, we rebuilt our search backend as a first step in making search on Instapaper faster and easier to scale. Today, we’re launching a completely overhauled search experience on iOS, which is now available to all users on Instapaper version 7.2.
Search in half the taps
The new search comes with big improvements and is accessible directly at the top of your article list (without having to go through the side menu). Just scroll up on the article list to reveal the search bar.
Local search for everyone
Once you tap the search bar, you’ll see an option to search either your current section (e.g. Home) or All Articles. Everyone can search by title in the current section, regardless of connectivity. If you’re an Instapaper Premium subscriber, the All Articles tab provides you access to full-text search.
Manage articles in search results
In addition to filtering results by section, you can also manage your articles in search results. Swipe across any article entry in search for options including “move to a folder”, “archive”, “delete” or “share”.
Open search results in reader view
Previously, articles in search results would open within the in-app browser. Now, if you open an article from search results, you’ll stay in the Instapaper app–even if the article isn’t stored on your device–and have access to all Instapaper reader features.
Other improvements
This release also has several fixes and improvements based on your feedback, including support for iOS10. If you have any questions, feature requests or issues you’d like us to sort out, please reach out to support@help.instapaper.com or @InstapaperHelp on Twitter. We love hearing from our users, and we thank you for choosing Instapaper!
– Instapaper Team
Reusable Components
(iterate think thoughts) 25 09 2016
One of the projects my team works is a clinical documentation platform. The goal of the project is to facilitate the implementation of different kinds of workflows for the clinics at our hospital.
Requirements
One major requirement for the platform is support for multiple concurrent users working on the same document. For example, both a physician and a pharmacist may have to enter the prescribed medications for a patient. Both users have to be able to complete their work concurrently and to be aware of the changes made by the other.
Another requirement is to visualize the data differently depending on the discipline. Patient lab results may need to be shown as a table in one place, but as a trending chart in another. A physician may call a piece of data by one name, while the pharmacist calls it by another.
In other words, the data model needs to have different views associated with it. Furthermore, some information may not be shown in a particular view at all, but it would still need to be updated when a field in the view changes.
Consider an example where you're collecting patient height and weight, then the BMI is calculated based on that. The user may only be interested in seeing height and weight in their workflow, but once that data changes the BMI still needs to be recalculated even if it's not displayed in that view.
Finally, we have a large data model based on the Hl7 FHIR standard. This standard specifies resources for describing different kinds clinical data, such as patient demographics, medications, allergies and so on. An example of a resource definition can be seen in the Resources section.
Architecture
The concurrent user requirement means that the changes made by different users have to be kept in sync. Meanwhile, business rules have to be applied transactionally for each change.
The easiest way to address the above requirements is to keep the master document on the server. Any time a client makes a change, a request is sent to the server over a WebSocket. The server updates the field in the document and runs the business rules. It will then notify the clients viewing a particular document of all the fields that were updated in the transaction.
The clients simply reflect the state of the document managed by the server and never make local updates to the model. This ensures that all the changes are handled centrally, and that the business rules are applied regardless of what is displayed on the client.
The second problem is the creation of views for the data. Since we have many distinct fields, but only a small number of types of fields, it made sense for us to create widgets to represent specific data types. The widgets are bound to the fields in the data model using the path as a unique identifier.
Let's take a look at a sample project that illustrates the above architecture to see how this works in practice.
Server-Side State Management
We'll start by examining the server-side implementation of the architecture starting with the components-example.document namespace. The server in our example keeps its state in a ref, and updates it transactionally whenever it receives an update from the client.
(defonce document (ref {}))
(defn bmi [weight height]
(when (and weight height (pos? height))
(/ weight (* height height))))
(defn bmi-rule [doc]
(let [weight (get-in doc [:vitals :weight])
height (get-in doc [:vitals :height])]
[{:path [:vitals :bmi]
:value (bmi weight height)}]))
(def rules
{[:vitals :weight] bmi-rule
[:vitals :height] bmi-rule})
(defn run-rules [doc {:keys [path]}]
(when-let [rule (rules path)]
(rule doc)))
(defn update-document! [{:keys [path value] :as path-value}]
(dosync
(let [current-document (alter document assoc-in path value)
updated-paths (run-rules current-document path-value)]
(doseq [{:keys [path value]} updated-paths]
(alter document assoc-in path value))
(into [path-value] updated-paths))))
Note the use of the dosync block in the update-document! function to update the document and run the business rules as a transaction.
Each rule can in turn create additional changes in the document. A vector of updated path-value pairs is returned as the result of the update. Our setup has a single rule that calculates the BMI. This rule is triggered whenever the weight or height fields are changed.
While the example keeps the document in memory, there's nothing stopping us from keeping it in the database and running the updates using a transaction against it. This is especially easy to do with PostgreSQL as it supports working with individual JSON fields directly.
Client-Server Communication
When the client loads, it establishes a WebSocket connection with the server. This connection is used to notify the server of the user actions and to push the changes back to the clients.
Server side of the connection can be found in the components-example.routes.ws namespace. The part that's of most interest to us is the handle-message multimethod that's keyed on the :document/update event:
(defmethod handle-message :document/update [{:keys [?data]}]
(let [updated-paths (update-document! ?data)]
(doseq [uid (-> @socket :connected-uids deref :any)]
((:send-fn @socket) uid [:document/update updated-paths]))))
The multimethod calls the update-document! function we just saw and then notifies the connected clients with its result.
Conversely, the client portion of the WebSocket connection is found in the components-example.ws namespace. Here we have the update-value function that sends the update event to the server, and the handle-message multimethod that handles incoming update messages:
(defn update-value [path-value]
((:send-fn @socket) [:document/update path-value]))
(defmethod handle-message :document/update [[_ updated-paths]]
(doseq [{:keys [path value]} updated-paths]
(dispatch [:set-doc-value path value])))
The multimethod dispatches a re-frame event for each path/value pair in the message. Let's take a look at the re-frame handlers and subscriptions next.
Client-Side State Management
Re-frame handlers are found in the components-example.handlers namespace, where the document state is updated using the following handlers:
(reg-event-db
:set-doc-value
(fn [db [_ path value]]
(assoc-in db (into [:document] path) value)))
(reg-event-db
:save
(fn [db [_ path value]]
(ws/update-value {:path path :value value})
db))
The :save event creates a WebSocket call to notify the server of the change. Meanwhile, the :set-doc-value event is used to update the client state with the set of changes. This event will be triggered by a WebSocket message from the server, whenever the master document is updated.
We also need to have a corresponding subscription to view the state of the document. This subscription is found in the components-example.subscriptions namespace:
(reg-sub
:document
(fn [db [_ path]]
(let [doc (:document db)]
(if path (get-in doc path) doc))))
Next, let's take a look at how the UI components are defined and associated with the data model.
Application Components
The UI for the application consists of widgets representing individual data types. When a widget is instantiated it's associated with a particular path in the document. The widgets are found in the components-example.widgets namespace.
The set of all valid paths is contained in the components-example.model namespace. This namespace is written using CLJC, and provides a single schema for both the client and the server portions of the application.
The widgets are associated with the model using the components-example.model-view namespace. Each of the paths found in the model can have multiple views associated with it. In our example, we have the form for entering the data and a preview for displaying it.
Finally, we have the components-example.view namespace that provides the layout for the page. This namespace instantiates the widgets defined in the model-view namespace and lays them out as needed for a particular page in the application.
Let's explore each of these namespaces in detail below.
Model
The data model in our application consists of a map that's keyed on the element path where each key points to the type of data found in that element. Let's take a look at a simple demographics model below:
(def Name
{:first s/Str
:last s/Str})
(def demographics
{[:demographics :mrn]
s/Str
[:demographics :name]
Name
[:demographics :name :dob]
#?(:clj java.util.Date
:cljs js/Date)
[:demographics :address :province]
(s/enum "AB" "BC" "MB" "NB" "NL" "NS" "NT" "NU" "ON" "PE" "QC" "SK" "YT")})
We can see that the demographics model contains the name, the date of birth, and the province for the patient.
The paths can point to any type of data structure. For example, the [:demographics :name] path points to a map containing the first and the last name.
Meanwhile, the [:demographics :name :dob] path leverages CLJC to provide different validators for Clojure and ClojureScript.
Widgets
Now, let's take a look at the approach we took to map the FHIR data model to the UI in the application.
At the lowest level we have widgets that represent a particular type of element. These would include text fields, datepickers, dropdowns, tables, and so on. The way we chose to represent the widgets was to use multimethods. The widgets are initialized using a map containing the :type key:
(defmulti widget :type)
Given the multimethod definition above, a text input widget might look as follows:
(defmethod widget :text-input [{:keys [label path]}]
(r/with-let [value (r/atom nil)
focused? (r/atom false)]
[:div.form-group
[:label label]
[:input.form-control
{:type :text
:on-focus #(do
(reset! value @(rf/subscribe [:document path]))
(reset! focused? true))
:on-blur #(do
(rf/dispatch
[:save path @value])
(reset! focused? false))
:value (if @focused? @value @(subscribe-doc path))
:on-change #(reset! value (-> % .-target .-value))}]]))
The text input widget subscribes to the given path in the document as its value. Since we don't want to generate unnecessary WebSocket events while the user is typing, the input keeps a local state while it's focused.
When the user focuses the input, its local state is set to the current document state, and when the focus is lost, the update event is generated with the new value.
Each widget is a reusable component that is associated with a path in the document to create a concrete instance:
[widget {:type :text-input
:lable "first name"
:path [:patient :name :first]}]
Since the widgets are mapped to the data elements via the path when instantiated, they can easily be composed into larger components. For example, we'll create a patient name component using two :text-input widgets:
(defmethod widget :name [{:keys [first-name last-name path]}]
[:div
[widget {:label first-name
:type :text-input
:path (conj path :first)}]
[widget {:label last-name
:type :text-input
:path (conj path :last)}]])
Composite widgets provide us with the ability to describe complex data elements that are common among different resources.
Model-View
The widgets are associated with the concrete paths using a model-view map. This map is keyed on the same paths as the model map, but points to widget declarations instead of the types. We can represent the MRN and name fields as follows:
(def demographics-form
{[:demographics :mrn]
{:label "medical record number"
:type :text-input}
[:demographics :name]
{:first-name "first name"
:last-name "last name"
:type :name}})
The model/view map contains a set of UI elements for representing the data model. Note that this approach allows us to create multiple view definitions for any particular data element.
This is useful as we may wish to present the data differently depending on the use case. For example, some users may manipulate the data, while others will simply want to view it.
View
This brings us to the view portion of the architecture. The view aggregates the widgets defined in the model-view map into a particular layout. The demographics view could look as follows:
(defn create-widget [view path]
(let [opts (view path)]
[widget (assoc opts :path path)]))
(defn form-row [view path]
[:div.row>div.col-md-12
(create-widget view path)])
(defn demographics [view]
[:div
(form-row demographics-form [:demographics :mrn])
(form-row demographics-form [:demographics :name])])
Here we use a create-widget helper function that looks up the options for a widget in the view and instantiate it with the given path.
The widgets are then wrapped in the layout tags in the form-row and inserted in the the div that represents the demographics view.
Once the widgets are defined, it becomes trivial to create different kinds of interfaces using them. This is perfect for our use case where we have a large common data model with many different views into it.
Conclusion
I hope this provides a bit of an insight into building large UIs with reusable components using Reagent and re-frame. My team has found that this approach scales very nicely and allows us to quickly build different kinds of UIs against a common data model.
A recent post compared WebSocket server performance in Clojure, C++, Elixir, Go, NodeJS, and Ruby. Chris Allen wrote a nice follow-up post where he implemented the benchmark using Haskell.
The initial results looked extremely favorable for Haskell. However, it turned out that the Haskell implementation failed to deliver messages reliably, dropping 98% of the messages it received. What's interesting is that this is exactly the kind of behavior we would expect Haskell type system to prevent from happening. So, how did the fact that messages were being dropped slip by completely undetected?
update
As a couple of people helpfully pointed out, the problem was not in fact caused by using unsafe functions. It's simply a type of error that would not be caught by the Haskell type system in general.
While the problems I outline with the unsafe operations are still present, it's clearly possible for serious problems to slip by even when you're not using them.
If anything, I think this bolsters the argument for the importance of a mature ecosystem and specification testing.
Type system escape hatches
Haskell provides escape hatches from its type system, and these are often used in practice to achieve reasonable performance. When we look at code in the unagi-chan library used in the Haskell implementation, we can see that it uses unsafeInterleaveIO to get the channel contents.
This is an example of an escape hatch that bypasses the type checker entirely. While Haskell is conceptually a pure language, the internal GHC implementation is imperative in nature. GHC runtime evaluates impure functions that produce side effects making the order of evaluation important. Functions like unsafeInterleaveIO expose the impure runtime to the user, and open the gate for all the types of errors we're familiar with from imperative languages.
The way GHC implements Haskell inherently precludes safety guarantees by its type system. The purity is effectively an honor system, and cannot be proved by the compiler. In other words, once we use a library that happens to use unsafe operations any guarantees that we get from the type system go out of the window.
Types are not a specification
While Haskell type system can help ensure that our code is self-consistent, it clearly can't provide any guarantees regarding the behavior of third party code. Since most real world applications tend to rely on many third party libraries, it means that unless we know what each library is doing we can't ever be certain that our code will work as expected.
The developer can't possibly be expected to audit every library they use in their project to ensure that it behaves safely. Since most applications rely on large amounts of third party code, availability of mature and reliable libraries is a major factor when it comes to building robust applications.
While the benchmark in this example is trivial, it's a good example of real world problems many projects have to deal with. Most applications have to interact with the external resources such as queues, databases, and other services. Therefore, we need mature and tested libraries in order to accomplish these tasks effectively.
I think this is one of the major reasons why hosted languages have been gaining popularity in recent years. When the language relies on a mature ecosystem, such as the JVM, it inherits a lot of battle tested code along with it.
However, this problem exists in every language. Ultimately, we need to know what the code is doing, and clearly types don't provide us with enough information to really be sure the code is doing what was intended.
Achieving correctness
The only way to know that the code is doing what was intended is to have a specification, and test the code against it. This is true pretty much for any language in use today. Tests allow us to validate complex properties that are difficult or even impossible to encode using most type systems.
Consider the trivial case of validating a user generated password. We need to check its length, combinations of characters it contains, and whether it matches the retyped password. All most type systems can tell us is that we have to pass the function a couple of strings and it will return a boolean.
To check any of the properties that prove that the function does what was intended, we need to come up with a specification and test the code against it. While the tests do not provide an exhaustive proof of correctness, they provide proof that the code satisfies the intended use cases.
An argument can be made that types save time in finding bugs when the tests fail. However, my experience is that it's often trivial to track down the actual problem once you're aware of it.
I think this is where the trade-off between static and dynamic languages lies. The former forces us to describe the types up front, and makes it easier to track down potential errors. Meanwhile, the latter approach allows us to skip this step at the cost of potentially having to do more work to find bugs later.
To the best of my knowledge nobody knows whether one approach is strictly more efficient than the other. The overall amount of work appears to be comparable with both approaches. However, the nature of work is different, therefore each approach appeals to a different mindset.
One interesting approach is to generate types from tests as seen in recent version of Typed Clojure. Using tests to drive type generation has the potential to offer the best of both worlds. We can work with a dynamic language, and offload the work of figuring out the type relationships to a library. As long as we're diligent about writing tests, we get the types for free.
Another powerful tool for writing robust code is the REPL. When it's integrated with the editor, testing code as you write it becomes very natural. It's quite common for me to test functions as I develop them, then extract the REPL session into a test suite for the feature I'm working on.
Takeaways
Even a strong type system, such as one found in Haskell, provides a very weak specification in practice. Just because the code compiles doesn't mean it's actually doing what was intended.
The type system does not help debugging many real world problems. The code in this benchmark worked as expected under small load, and started exhibiting errors when it was stress tested.
The ecosystem around the language is an important factor when it comes to productivity. When we use mature and battle tested libraries, we're much less likely to be surprised by their behavior.
Tests are ultimately the only practical way to provide a specification for the application. Behaviors that are easily tested can be difficult or impossible to encode using a type system.
Instapaper is joining Pinterest
Instapaper 23 08 2016
Today, we’re excited to announce that Instapaper is joining Pinterest. In the three years since betaworks acquired Instapaper from Marco Arment, we’ve completely rewritten our backend, overhauled our mobile and web clients, improved parsing and search, and introduced tons of great features like highlights, text-to-speech, and speed reading to the product.
All of these features and developments revolved around the core mission of Instapaper, which is allowing our users to discover, save, and experience interesting web content. In that respect, there is a lot of overlap between Pinterest and Instapaper. Joining Pinterest provides us with the additional resources and experience necessary to achieve that shared mission on a much larger scale.
Instapaper provides a compelling source for news-based content, and we’re excited to take those learnings to Pinterest’s discovery products. We’ll also be experimenting with using our parsing technology for certain Rich Pin types.
For you, the Instapaper end user and customer, nothing changes. The Instapaper team will be moving from betaworks in New York City to Pinterest’s headquarters in San Francisco, and we’ll continue to make Instapaper a great place to save and read articles.
As we focus on the future of the user experience, we’ll be sunsetting our developer product, Instaparser. Starting today, we will cease signups for Instaparser and halt billing for existing customers. In order to ensure a smooth transition for current users, we will keep Instaparser running until November 1, 2016.
Lastly, and most importantly, we want to thank all of our readers for your support throughout the years. Whether you supported us back when Marco built and ran Instapaper, from the betaworks acquisition, or just found out about us recently, we truly appreciate your continued support and look forward to bringing you the same great product at Pinterest.
If you have any questions at all, please reach out to us at support@help.instapaper.com
- Instapaper Team
Tests can be a bummer to write but even a bigger nightmare to maintain. When we noticed we are putting off simple tasks just because we were afraid to update some monster test case, we started looking for more creative ways to simplify the process of writing and maintaining tests. In this article I will describe a class based approach to writing tests.
The Django admin is a very powerful tool. We use it for day to day operations, browsing data and support. As we grew some of our projects from zero to 100K+ users we started experiencing some of Django's admin pain points - long response times and heavy load on the database.
I'm glad to announce that the second edition of Web Development with Clojure is finally finished. The book took longer to put together than I anticipated, and I ended up missing the original release target by a few months.
However, all the delays resulted in a much better book in the end. Having a long beta period allowed me to collect a lot of feedback from the readers and address any concerns that came up. This process helped ensure that the material is clear and easy to follow, while keeping a good pace. I discussed the specifics of what the book covers an earlier post here.
It's my sincere hope that the book will provide the readers with a smooth path into the wonderful world of Clojure web development.
The Java standard library provides a rich networking API. For example, the java.net.URL class provides a simple way to access resources using a URL location pattern. We can do fun stuff like this using it:
(-> "https://gist.githubusercontent.com/yogthos/f432e5ba0bb9d70dc479/raw/768050c7fae45767b277a2ce834f4d4f00158887/names.clj"
(java.net.URL.)
(slurp)
(load-string))
(gen-name 11 6)
Unfortunately, the SSL certificates bundled with the default Java runtime aren't comprehensive. For example, the https://http.cat/ site has a valid certificate that's not part of the default Java trust store.
Let's write a function to read an image from the site using java.net.URL, then save it to a file to see what happens.
(defn read-image [url]
(let [conn (.openConnection (java.net.URL. url))]
(.getInputStream conn)))
(clojure.java.io/copy
(read-image "https://http.cat/200")
(java.io.FileOutputStream. "200.jpg"))
When we try to access the resource, we end up with a security exception because the default trust store does not contain the right certificate.
javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException:
PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException:
unable to find valid certification path to requested target
...
One way we could work around this problem would be to add the certificate to the local store. This is the proper solution that should be used in the vast majority of cases.
However, there are situations where this approach isn't possible. I've run into many situations working in the enterprise where SSL was misconfigured, and the application would need to connect to an intranet service over such a connection. At the same time I had no control over the deployment environment and wasn't able to manage the keystore there.
An alternative approach is to replace the default certificate check for a specific connection with a custom one. Let's take a look at how this can be accomplished.
We'll first have to create a proxy TrustManager, then use it to create a socket factory for our connection as seen in the following code:
(defn set-socket-factory [conn]
(let [cert-manager (make-array X509TrustManager 1)
sc (SSLContext/getInstance "SSL")]
(aset cert-manager 0
(proxy [X509TrustManager][]
(getAcceptedIssuers [])
(checkClientTrusted [_ _])
(checkServerTrusted [_ _])))
(.init sc nil cert-manager (java.security.SecureRandom.))
(.setSSLSocketFactory conn (.getSocketFactory sc))))
The custom socket factory will use the X509TrustManager proxy that we provide and rely on it for validation. We can simply return nil from each of the validation methods to skip the certificate validation.
Note that while we're skipping validation entirely in the above example, we'd likely want to supply a custom validator that validates against an actual certificate in practice.
Next, let's update the read-image function to set the custom socket factory for the connection before trying to read from it:
(defn read-image [url]
(let [conn (.openConnection (java.net.URL. url))]
(set-socket-factory conn)
(.getInputStream conn)))
(clojure.java.io/copy
(read-image "https://http.cat/200")
(java.io.FileOutputStream. "200.jpg"))
We should now have a 200.jpg file on our file system with the following content:
That's all there is to it. We can now enjoy consuming cat HTTP status pictures using the java.net.URL and even make some silly Ring middleware using it. :)
Beach Games
Legión del Espacio 01 07 2016
Amor de verano
Legión del Espacio 30 06 2016
Tinta de veranooooo
Legión del Espacio 29 06 2016
#BudSpencer NO #RIP
Legión del Espacio 28 06 2016
Consider Hoplon
(iterate think thoughts) 06 06 2016
A recent discussion of Hoplon vs React has been making rounds. While I don't necessarily agree that using React is as difficult as Micha makes it sound, I do think that Hoplon provides an interesting alternative to React that has a number of benefits.
The main selling point for Hoplon is that it's simple. Hoplon doesn't use a virtual DOM, and thus it doesn't have a component lifecycle. One major benefit of this approach is in making it natural to use with existing Js libraries that expect to work with the browser DOM.
An example of this would be something like using a jQuery date picker widget. With Reagent, we'd have to use the lifecycle hooks, and make sure that the component is mounted in the browser DOM before the library is called. Conversely, we may need to consider the case of the component updating separately. While, it's not difficult to reason about in most cases, it does introduce some mental overhead. Using the same date picker in Hoplon can be seen here.
However, while I found the idea of Hoplon interesting, I've never gave it a serious look due to the fact that it looked to be a monolithic stack. When you read Hoplon documentation, it's easy to get the impression that it has to be used with Boot, you have to use special .hl files to define ClojureScript, and you're expected to work with its server implementation.
This all can be appealing if you're looking for a full-stack solution where decisions have been made for you, but it's a bit of a deterrent for somebody who already has a preferred workflow and uses other tools such as Figwheel and Leiningen.
After having a discussion with Micha on Reddit, I realized that this wasn't the case and decided to give Hoplon another shot.
The Setup
I used the reagent-template that I maintain as the base for he project by running the following command in the terminal:
lein new reagent hoplon-app
Next, I updated the dependencies in project.clj to remove the references to Reagent, and add the Hoplon dependency instead:
:dependencies [[org.clojure/clojure "1.8.0"]
[ring-server "0.4.0"]
[hoplon "6.0.0-alpha15"]
[ring "1.4.0"]
[ring/ring-defaults "0.2.0"]
[compojure "1.5.0"]
[hiccup "1.0.5"]
[yogthos/config "0.8"]
[org.clojure/clojurescript "1.9.36"
:scope "provided"]
[secretary "1.2.3"]]
That's all the changes I had to do in order to switch to using Hoplon in the project.
The next step was to open up the ClojureScript source in the src/cljs/hoplon_app/core.cljs file and replace the references to Reagent with Hoplon:
(ns hoplon-app.core
(:require
[hoplon.core
:as h
:include-macros true]
[javelin.core
:refer [cell]
:refer-macros [cell= dosync]]))
(h/defelem home []
(h/div
:id "app"
(h/h3 "Welcome to Hoplon")))
(defn mount-root []
(js/jQuery #(.replaceWith (js/jQuery "#app") (home))))
(defn init! []
(mount-root))
At this point I could start Figwheel and see the page load in the browser by running:
lein figwheel
As you can see the main difference so far is that we mount the Hoplon DOM using plain jQuery call, and the elements are defined using Hoplon helper macros.
Let's see how we can add a bit of state to our Hoplon app. Hoplon state management is handled by the Javelin library. It uses a similar concept to the Reagent atom where we can define cells, and then whenever the state of the cells changes any elements that are looking at its value will be notified.
We'll create a simple to-do list to illustrate how this works. First, we need to create a cell to hold the data. We'll add the following code at the top of the namespace to do that:
(def todo-items (cell ["foo"]))
The above code will define a Javelin cell that contains a vector with the string "foo" in it. We can now render the value of the cell as follows the the home element:
(h/defelem home []
(h/div
:id "app"
(h/h3 "Welcome to Hoplon")
(h/p (cell= todo-items))))
The cell= call is reactive and whenever the state of the cell changes the paragraph will be repainted to with its current value. We can now add some code to add new items to the to-do list:
(h/defelem add-todo []
(let [new-item (cell "")]
(h/div
(h/input :type "text"
:value new-item
:change #(reset! new-item @%))
(h/button :click #(dosync
(swap! todo-items conj @new-item)
(reset! new-item ""))
(h/text "Add #~{(inc (count todo-items))}")))))
The above code should be fairly familiar to anybody who's used Reagent. We define a local state in a let binding and create a div that contains an input and a button. The input displays the value of the new-item cell and updates it in its :change event. Meanwhile, the button will swap the todo-items cell and add the value of the new item, then reset it to an empty string.
Notice that the button text displays the current item count. This is accomplished by Hoplon #~ helper that allows us to easily display cell values within strings.
We should now be able to update our home element as follows to have the add-todo component show up on the page:
(h/defelem home []
(h/div
:id "app"
(h/h3 "Welcome to Hoplon")
(h/p (cell= todo-items))
(add-todo)))
When we add to-do items, they should be showing up in the list. So far everything looks nearly identical to working with Reagent.
Now, let's update the items to be rendered in the list a bit nicer. We'll write the following element to render the list:
(h/defelem todo-list [{:keys [title]}]
(h/div
(h/h4 (or title "TODO"))
(h/ul
(h/for-tpl [todo todo-items]
(h/li todo)))))
The element uses the Hoplon for-tpl macro to run through the elements in the list. The macro is used to map dynamically sized collections to DOM nodes. With the element in place, we can update our home element to display a nice HTML list:
(h/defelem home []
(h/div
:id "app"
(h/h3 "Welcome to Hoplon")
(todo-list {:title "TODO List"})
(add-todo)))
We should now see a list of items displayed that will get updated as we add items using the add-todo element. That's all there's to it. While it's a trivial app, I hope it gives you a taste of what working with Hoplon is like. The full source for the project can be seen here.
Conclusion
I was very pleasantly surprised by how easy it was to use Hoplon in a project setup with Leiningen and Figwheel. The semantics that Hoplon provides are very similar to Reagent, and are arguably simpler since there's no need to worry about the component lifecycle.
The one aspect of Reagent that I prefer is that the UI is defined declaratively using the Hiccup syntax. This makes it possible to manipulate UI elements as plain data. However, I don't think that using functions to define the UI is a deal breaker.
Overall, I think that Hoplon is often overlooked when ClojureScript UI libraries are considered, and this is very unfortunate. It's a solid library that provides clean and simple semantics to the user.
If, like me, you've been avoiding Hoplon because you were under the impression that you have to use it in a specific way, then I strongly urge you to give it another look.
Update
Luminus now provides a Hoplon profile using the +hoplon flag.
How to fight like a man
James Sinclair 01 06 2016
Introducing clojure.spec
Clojure News 23 05 2016
I’m happy to introduce today clojure.spec, a new core library and support for data and function specifications in Clojure.
Better Communication
Clojure is a dynamic language, and thus far we have relied on documentation or external libraries to explain the use and behavior of functions and libraries. But documentation is difficult to produce, is frequently not maintained, cannot be automatically checked and varies greatly in quality. Specs are expressive and precise. Including spec in Clojure creates a lingua franca with which we can state how our programs work and how to use them.
More Leverage and Power
A key advantage of specifications over documentation is the leverage they provide. In particular, specs can be utilized by programs in ways that docs cannot. Defining specs takes effort, and spec aims to maximize the return you get from making that effort. spec gives you tools for leveraging specs in documentation, validation, error reporting, destructuring, instrumentation, test-data generation and generative testing.
Improved Developer Experience
Error messages from macros are a perennial challenge for new (and experienced) users of Clojure. Specs can be used to conform data in macros instead of using a custom parser. And Clojure’s macro expansion will automatically use specs, when present, to explain errors to users. This should result in a greatly improved experience for users when errors occur.
More Robust Software
Clojure has always been about simplifying the development of robust software. In all languages, dynamic or not, tests are essential to quality - too many critical properties are not captured by common type systems. spec has been designed from the ground up to directly support generative testing via test.check. When you use spec you get generative tests for free.
Taken together, I think the features of spec demonstrate the ongoing advantages of a powerful dynamic language like Clojure for building robust software - superior expressivity, instrumentation-enhanced REPL-driven development, sophisticated testing and more flexible systems. I encourage you to read the spec rationale and overview. Look for spec’s inclusion in the next alpha release of Clojure, within a day or so.
I hope you find spec useful and powerful.
Rich
I recently needed to create an expandable widget and I wanted to be able to close it by clicking elsewhere on the screen. An example would be an input field and an associated component to select the input value such as a date picker.
We'll define an example component to look as follows:
(defn expandable-component []
[:div
[:input
{:type :text}]
[:table>tbody
(for [row (range 5)]
[:tr
(for [n (range 5)]
[:td>button.btn
{:on-click
#(do
(reset! value n)
(reset! expanded? false))} n])])]])
Next, we'll use the with-let statement to define some state for the component.
(defn expandable-component1 []
(r/with-let
[expanded? (r/atom false)
value (r/atom nil)]
[:div
[:input
{:type :text
:value @value
:on-click #(swap! expanded? not)}]
[:table>tbody
{:style (if @expanded?
{:position :absolute}
{:display "none"})}
(for [row (range 5)]
[:tr
(for [n (range 5)]
[:td>button.btn.btn-secondary
{:on-click
#(do
(reset! value n)
(reset! expanded? false))} n])])]]))
The table is now hidden by default, and it's displayed when the user clicks the input. The table contains cells with numbers. When the user clicks a number, then the table is hidden and the input is reset to the value selected.
This works fine. However, the only way we can hide the table is by either picking a number or clicking on the input itself. It's not terrible, but it would be nicer if we could simply click off the table to have it go away.
The problem is that there is no local event the widget can use to detect that the user clicked elsewhere. So, what can we do here?
The solution I ended up using was to use a combination of events to detect the state of the widget. Let's see how this works below.
First, I added the :on-blur event to the input. When the input loses focus, the table is hidden. Now if I click elsewhere on the screen the table will disappear as intended.
Unfortunately, this breaks the interaction with the table itself. Since now the focus goes away and I'm no longer able to select the number I want.
In order to get around that problem we can use the :on-mouse-enter and :on-mouse-leave events on the table. This way we can check if the mouse is in the table before changing the visibility.
(defn expandable-component []
(r/with-let
[expanded? (r/atom false)
value (r/atom nil)
mounse-on-table? (r/atom false)]
[:div
[:input
{:type :text
:value @value
:on-click #(swap! expanded? not)
:on-blur #(when-not @mounse-on-table? (reset! expanded? false))}]
[:table>tbody
{:style (if @expanded? {:position :absolute} {:display "none"})
:on-mouse-enter #(reset! mounse-on-table? true)
:on-mouse-leave #(reset! mounse-on-table? false)}
(for [row (range 5)]
[:tr
(for [n (range 5)]
[:td>button.btn.btn-secondary
{:on-click
#(do
(reset! value n)
(reset! expanded? false))} n])])]]))
The new approach works as intended. The table will now close whenever the user clicks outside it. You can see this in action here.
Hopefully this trick will save you some time creating these types of components in Reagent.
TDD Should be Fun
James Sinclair 07 05 2016
New and Improved Search
Instapaper 05 05 2016
For a while now, some of the most consistent feature requests we’ve gotten from users have involved improvements to Instapaper’s full-text search engine. For months now, the existing search infrastructure had been stretched to its current limits. In order to continue scaling and implement a lot of the features you’ve been requesting, we needed to completely rebuild our search infrastructure.
Today, we’re very excited to launch the new search infrastructure, which is the first of several steps in what we intend to be a complete overhaul of Instapaper’s search feature. For Instapaper Premium customers, the most noticeable difference will be query speed. We’ve improved the speed of search queries by 6x on average, and far better on certain cases. Additionally, we’ve implemented a handful of new features in the search engine.
- Sorting Options: The previous search engine only returned results sorted by most recent. The new search engine defaults to a “Relevance” sort, with the options to sort by “Newest” and “Oldest” as well.
- Title Searches: The new full-text search automatically searches article titles, along with the complete text of the article.
- Exact Matches: By putting a search query around quotes, you can search for an exact phrase.
- Site and Author Filtering: We’ve implemented an “Advanced Search” option that allows you to filter by domain name (e.g., nytimes.com) and author.
- Paged Results: Previously, searches were limited to only the 50 most-recent matching results. With the new search, you can page through all of the search results.
- Multi-Language Support: Instapaper has users from all over the world, however, the previous search only supported queries with English characters. The new search engine supports queries in all languages.
Rebuilding the backend for Instapaper’s full-text search is the first (and most complicated) step in our overhaul for search. Some of the features listed above like paged results, sorting options, and advanced search options are only available on instapaper.com at launch. However, we will also be reimplementing search on iOS and Android, which will bring the full functionality to those platforms.
If you have any feedback on the new search or have any particular features you’d like us to keep in mind as we continue our revamp of search, we’d love to hear from you @InstapaperHelp on Twitter or via email at support@help.instapaper.com. Thanks, as always, for using Instapaper!
Luminus Workflow
(iterate think thoughts) 28 04 2016
I recently presented at the Philly ETE conference, and it was a really great experience. The conference was well organized, there were lots of great talks, and I got to meet a bunch of interesting people.
My talk focused on the workflow using Luminus and Reagent. During the talk I built a simple app from scratch. The app illustrates how to work with a relational database, create a documented service API, and build a UI for it using Reagent. The live demo portion stats around the 11 minute mark.
If you're interested in my workflow using Luminus and Cursive, then I definitely recommend watching the talk.
The Kickstarter for the Arachne framework was just announced. I think this is very exciting, and I sincerely hope that it will be successful. There is plenty of room for frameworks in the Clojure web application domain. However, I also think that the pitch in the video severely misrepresents the current state of Clojure web development.
Is it hard to make an app?
Luke says that the motivation for the project is that there is no simple way to put a Clojure web app together. You want to make a website quickly, but unfortunately Clojure is not well suited for this task because the lead time is just too long.
Luke goes as far as to say that starting a new Clojure web application with all the parts together, that's actually deployable is a one to three months process.
Simplifying this process is precisely the motivation behind Luminus. In fact, Luminus, and other frameworks such as Hoplon, have been filling this exact niche for years now. While I’m not as familiar with Hoplon, I will focus on contrasting the stated goals behind Arachne and the goals for Luminus.
First thing I’d like to address is the claim that it takes a long time to create a web application following best practices. Creating a new Luminus app is as easy as running lein new luminus myapp in the terminal. Perhaps what Luke meant was that creating an application using his preferred stack and defaults takes a long time.
Luminus is based on over a decade of experience working in the enterprise environment and building real world applications. It's built on top of mature libraries that are known to work well together. These are wrapped up in a template that follows the best practices, and makes it easy to create a working application that's ready for deployment out of the box.
Some of the things Luke lists are:
- Overall structure
- Resource lifecycle management
- Routing
- Content negotiation
- HTML rendering
- Authentication & authorization
- Validation
- Logging
- Testing
All of these are supported out of the box in Luminus.
What about beginners?
Another problem Luke identifies is that there needs to be a tool for beginners, or people new to the Clojure language. Once again, this is precisely the target demographic for Luminus.
I've literally spent years working with existing libraries, creating my own when necessary, writing documentation, and putting things together for that express purpose. I've even written a couple of books on this topic now.
Arachne aims to experiment with creating an easy to start with solution that will scale. Luminus is designed to scale, and it’s currently being used in production in the enterprise. It's not experimental in any way, it's an actual proven solution that exists today.
Luminus allows you to start fast and deploy out of the box, but it is also designed to be built on as you go. Like Arachne aims to do, Luminus already embraces modular design. It's built on top of battle tested libraries such as Ring and Compojure, but it doesn't lock you into doing things a particular way.
Luminus makes it trivial to swap things like the underlying HTTP server, templating engine, the database you're using, and so on. The core template provides a minimal skeleton app. This template can then be extended using hints to provide additional functionality.
But is it modular?
Arachne has an ambitious goal to provide a way to specify the application using a data driven approach. The idea being that this makes it easier to swap different components in the existing project.
I’ve considered similar approaches for Luminus, but ultimately decided against that. First, I think that Ring middleware already provides an extremely powerful mechanism for injecting functionality in the request handling pipeline. This is where most of the changes will happen in your project. You might decide to swap out or change things like session handling middleware as your project evolves.
However, my experience is that in most cases it’s not possible to simply swap a component such as the database for a different one without having to change some code in the application.
For example, if I switch the templating engine, then I have to update my HTML templates. When I switch a database from SQL to Datomic, I have to rewrite the queries and the business logic. That’s where the most of effort will end up being spent.
That said, the code that deals with any particular component in Luminus is minimal by design. So, the vast majority of the code you’d have to change would be the code that you’ve written yourself.
The one place I found it to be possible to provide swappable components is the underlying HTTP server. Luminus provides wrapper libraries for all the popular servers, and it’s possible to swap them out by simply changing the dependency in the project.
I think it would be possible to build things like authentication and authorization modules that are swappable. However, a generic solution is necessarily more complex than a focused one. A component that can be used in many different situations will always be more complex than one that solves a specific problem.
For this reason, I firmly believe that such design decisions should be left up to the user. The libraries should provide focused functionality, while the user decides how to put them together in a way that makes sense for their project.
Conclusion
At the end of the day, Luminus isn’t based just on my experience, but also that of the contributors and the users over the years. Arachne will be informed by Luke’s experience and that necessarily means that it will provide a new and interesting way to put together Clojure web applications.
Overall, I think it will be great to see a new web framework for Clojure. There is plenty of room for alternatives to Luminus, and Arachne could explore many areas that aren't the focus for Luminus at the moment. Therefore, I wholeheartedly urge you to support the Kickstarter so that we can have more choices for Clojure web development.

Instapaper Weekly Sponsorship
Instapaper 11 04 2016
Update 8/29/2016: Since Instapaper is now a Pinterest product we no longer offer sponsorships for Instapaper Weekly. Thanks to all of our previous sponsors!
We’re excited to announce that we’ll be opening up sponsorship slots for our Instapaper Weekly email.
About Instapaper Weekly
Instapaper Weekly is an algorithmically-generated newsletter delivered every Sunday. The email contains the most popular highlight created by all Instapaper users for the week, and a list of the most popular articles saved to Instapaper for each day of the past week.
The Weekly is currently delivered to about 1.5 million Instapaper users. The open rate for the weekly email is 17% and the click-through rate is about 2.7%.
Why Sponsorships?
By design, the Instapaper Weekly is a reflection of what our readers consider to be the most important and noteworthy topics for a given week. Sponsoring the Weekly places your content amongst the best content Instapaper has to offer and provides access to a large, engaged audience of tech-oriented and well-read professionals.
Sponsoring
As the Weekly compiles content our users found most compelling, we will be holding our sponsorship choices to the same standards of high quality. Your sponsored content should fit within our existing format for Instapaper Weekly and consist of a link, title, description, and thumbnail image. Ideally, the link would be something that our mobile-centric users can save to Instapaper for later reading.
We will run the sponsorship between the “Top Highlight” and “Most Popular” sections of the weekly email:
If you’d like to sponsor Instapaper Weekly, please send us an email to sponsors@instapaper.com.
Thanks,
Instapaper Team
Luminus embraces HugSQL
(iterate think thoughts) 22 02 2016
There are lots of Clojure libraries available for working with SQL. The core libraries that provide the low level functionality are clojure.java.jdbc and the more recent clojure.jdbc. Some of the more popular libraries built on top of them are Korma, Honey SQL, and Yesql.
I've been a huge fan of the approach that Yesql takes since it was released. Every time I've worked with a DSL for SQL, I've found that I'd always run into cases where I knew exactly what to do if I was writing plain SQL, but I couldn't find a clean way to express using the abstraction on top of it. Since Yesql approach lets you keeps your SQL as SQL the problem largely goes away.
Luminus has been using Yesql since it came out and I think it made the framework much more approachable. Unfortunately, Yesql doesn't appear to be actively developed, and I found myself falling back to using clojure.java.jdbc directly for things like batch inserts.
Another problem from Luminus perspective is that Yesql API defines query functions directly. Luminus uses conman for connection management, and it creates its own connection-aware functions. This required an ugly hack of using a shadow namespace for interning the functions generated by Yesql.
I recently learned about the HugSQL library that is inspired by Yesql, and addresses all the issues I've run into using it. The official site does a good job enumerating the major differences from Yesql. Some of the highlights for HugSQL are:
- snippets that facilitate composable queries
- support for multi-row inserts
- supports multiple backends such as clojure.java.jdbc and clojure.jdbc
- great documentation
The latest version of HugSQL provides an API that returns a map of query functions keyed on their names as well as the ability to define the functions directly.
I think this is a very useful feature even if you're not using conman or Luminus. Having a map of the query functions allows the user to decide what they want to do with them explicitly. For example, you're able to do things like the following:
(def queries (hugsql.core/map-of-db-fns "queries.sql")
(defn get-user [db opts]
((-> queries :get-user :fn) db opts))
Yesql vs HugSQL
Let's take a look at the basic usage of HugSQL and differences from Yesql.
The core syntax in HugSQL is quite similar to Yesql. Both Yesql and HugSQL use comments with a special format to provide the metadata for generating the functions to work with queries.
Yesql
-- name: create-user!
-- creates a new user record
INSERT INTO users
(id, pass)
VALUES (:id, :pass)
-- name: get-users
-- retrieve all users
SELECT * FROM users
-- name: get-user
-- retrieve a user given the id.
SELECT * FROM users
WHERE id = :id
Yesql uses the -- name: fn-name syntax to specify the function name, the comment below the function name is implicitly used as the doc for the function. The ! at the end of the function name is used as a convention to indicate that it mutates the data. The query parameter placeholders are identified using the : prefix.
HugSQL
-- :name create-user! :! :n
-- :doc creates a new user record
INSERT INTO users
(id, pass)
VALUES (:id, :pass)
-- :name get-users :? :*
-- :doc retrieve all users
SELECT * FROM users
-- :name get-user :? :1
-- :doc retrieve a user given the id
SELECT * FROM users
WHERE id = :id
The HugSQL version uses the -- :name syntax instead that mirrors the Clojure keyword syntax. The function name is followed by two additional flags. The first flag indicates the SQL command type and the second indicates the result.
This provides more flexibility for handling the results. For example, the get-users query indicates that it selects multiple records, while the get-user indicates that it selects exactly one record. This helps document the intent of the query and cuts down on boilerplate, as you'd have to write a wrapper otherwise that gets the first result from the query.
command flags
:queryor:?- query with a result-set (default):executeor:!- any statement:returning-executeor:<!- support forINSERT ... RETURNING:insertor:i!- support for insert and jdbc.getGeneratedKeys
result flags
:oneor:1- one row as a hash-map:manyor:*- many rows as a vector of hash-maps:affectedor:n- number of rows affected (inserted/updated/deleted):raw- passthrough an untouched result (default)
In HugSQL, all the comments that represent metadata start with a key describing the type of metadata. In the examples above, the doc string is explicitly specified using the -- :doc prefix.
HugSQL also supports additional syntax within its queries. For example, if we wanted to insert multiple records using a single query, then we could use a vector of records as follows:
-- :name add-users! :! :n
-- :doc add multiple users
INSERT INTO users
(id, pass)
VALUES :t*:users
(add-users! db {:users
[["bob" "Bob"]
["alice" "Alice"]]})
The syntax for for in-list queries is also a bit different from Yesql. The SQL query uses the :v* flag to indicate the value list parameter.
-- :name find-users :? :*
-- :doc find users with a matching ID
SELECT *
FROM users
WHERE id IN (:v*:ids)
The function parameters will now consist of a map with the key :ids that points to a vector of ids that we would like to match on.
(find-users db {:ids ["foo" "bar" "baz"]})
As you can see, the syntactic differences for basic queries are very minor. I've migrated a number of projects to HugSQL already, and found the process to be completely painless.
I haven't covered the advanced features of HugSQL, but I highly recommend looking over the official documentation to see what's available.
Animating the Unanimatable
Josh Comeau's blog 15 02 2016
State of Clojure 2015 survey results
Clojure News 28 01 2016
Check out the State of Clojure 2015 survey results here:
Thanks for responding - it’s great to see the community growing and doing great things!
Clojure 1.8 is now available
Clojure News 19 01 2016
Some of the new features for 1.8 are:
-
More string functions in clojure.string (portable to ClojureScript): index-of, last-index-of, starts-with?, ends-with?, includes?
-
Compiler direct linking - improves performance and startup time
-
Socket server and socket server REPL - adds the ability to allow remote Clojure REPL connections
For more information, see the complete list of all changes since Clojure 1.7 for more details.
Contributors
Thanks to all of those who contributed to Clojure 1.8 (first time contributors in bold):
-
Alexander Yakushev
-
Alex Miller
-
Alex Redington
-
Alf Kristian Stoyle
-
Ambrose Bonnaire-Sergeant
-
Andrew Rosa
-
Andy Fingerhut
-
Andy Sheldon
-
Aspasia Beneti
-
Blake West
-
Bozhidar Batsov
-
Daniel Compton
-
Erik Assum
-
Gary Fredericks
-
Ghadi Shayban
-
Gordon Syme
-
Howard Lewis Ship
-
Jean Niklas L’orange
-
Jeremy Heiler
-
Jonas Enlund
-
Jozef Wagner
-
Karsten Schmidt
-
Kevin Downey
-
Mark Simpson
-
Michael Blume
-
Nahuel Greco
-
Nicola Mometto
-
Nikita Prokopov
-
Nola Stowe
-
Ragnar Dahlén
-
Ralf Schmitt
-
Rich Hickey
-
Russ Olsen
-
Shogo Ohta
-
Steve Miner
-
Stuart Halloway
-
Timothy Baldridge
-
Tsutomu Yano
-
Yanxiang Lou
There was a recent wave of discussions on pros and cons of using Component and Mount approaches to state management. Both libraries aim to provide a clean way to manage stateful resources in the application. However, each one takes a very different approach.
Component is the currently accepted way to manage state, and it works well when you structure your application around it. However, it does require certain trade-offs in order to make the most of it. Let's take a look at some of the reasons you may wish to choose Mount over Component for your project.
Managing the State with Component
Component uses the dependency injection approach to managing stateful resources in the application. A system map is used to track all the components and their relationships. This map is then passed around the application explicitly, and used to provide access to the resources.
This approach encourages coupling between the code managing the resources and the business logic. A common pattern is to pass the component system around the application. The system is injected from the top level, and then functions pick parts of the system to pass down until they're eventually used by a function that relies on a particular resource.
One side-effect of this design is that it becomes impossible to test any part of the application without having the resources available. Therefore, if we wish to run tests in the REPL, then we need to instantiate a separate system map using the test resources. This problem makes it important to be able to create multiple instances of the components at runtime.
Component and the REPL
Since Component is based on protocols it doesn't play well with the REPL workflow, as changes to defrecord do not affect the instances that have already been created. The whole app needs to be restarted in order to make sure that the REPL is still in a good state.
This problem is discussed in detail by Stuart Sierra in his post on the reloaded workflow. I find that the reloaded workflow used with Component is much closer to TDD than the traditional Lisp style REPL driven workflow.
However, one of the advantages of working with a language like Clojure is that we shouldn't need to run tests all that often. Since development is primarily done using the REPL, we should have a good idea of what the code is doing while we're working on it.
RDD provides a very tight feedback loop. I can develop the features interactively, then create the tests based on the REPL session once the code is doing what I need.
There are only a handful of situations where I find it necessary to run the full test suite. I run tests before I commit code, I run tests on the CI server, but I don't find it necessary to rerun tests any time I write a bit of code during development. I certainly shouldn't have to reload the whole app for changes to take effect.
I like the guard rail metaphor Rich Hickey used in his Simple Made Easy talk:
"I can make changes 'cause I have tests! Who does that?! Who drives their car around banging against the guard rails saying, "Whoa! I'm glad I've got these guard rails!"
This is a good reminder that the tests are primarily a sanity check. We should have confidence in our code because we understand it and are able to reason about it.
To facilitate understanding, most code in the application should be pure, and we shouldn't have to rely on any external resources to test such code. I think that it helps to treat core business logic as you would a library. It should be completely agnostic about where the data is coming from and where it's going.
However, Component encourages a different kind of design where business logic ends up being reliant on the resources. In this situation, it's no longer possible to test the business logic in isolation.
Finally, any functions that takes the system map as a parameter are invariably tied to it. This is at odds with treating functions as core reusable building blocks.
The Mount Approach
Mount takes the approach of encapsulating stateful resources using namespaces. This leads to a natural separation between the code that deals with state from the pure core of the application logic.
When the core is kept pure, then it can be safely tested in isolation without having to provide any mock resources to it. This also makes the code reusable out of the box.
Mount makes it trivial to integrate into existing applications. The app doesn't need to be designed up front to take advantage of it, as it does with Component.
Since Mount doesn't rely on protocols, it doesn't impact the REPL driven workflow. There's no need for an elaborate setup to facilitate reloading the whole application any time a change is made.
The primary disadvantages of Mount are that it's not possible to create multiple instances of a resource, and that we have to be mindful not to couple namespaces representing resources to the business logic.
Conceptually, most resources in the application are singletons by their very nature. When we have a database connection or a queue, there is precisely one external resource that we're working with.
As I illustrated earlier, the primary reason for having multiple instances of a resource is testing. Mount provides a simple solution for running tests with alternate implementations as described in its documentation. This facilitates practically the same workflow as Component, where an instance of the resource can be swapped out with another for testing. However, the bigger advantage is that we no longer need to have resources available to test majority of the code in the first place.
Another argument is that you may have different instances of the same type of resource. For example, an application might use multiple queues that all have the same API. In this case, we can use defrecord to define the class representing the API for the queue. We'll then manage the lifecycle of each instance using defstate.
While we do have to be mindful of our design when using Mount, the same is true for Component as well. For example, nothing stops us from putting the Component system in a var that's referenced directly. The same reasoning we use to avoid doing that should be used when working with Mount as well.
In general, I see very few downsides to using Mount and I see a lot of practical benefits, some of which I've outlined above.
Conclusion
I think that both Component and Mount have their own sets of trade-offs. Component is a framework that requires the application to be structured around it. Conversely, it necessitates a TDD style workflow to work with it effectively.
On the other hand, Mount is not prescriptive about the workflow or application structure. I think this makes it a more flexible solution that's a great fit for many kinds of applications. The flip side is that we have to be more careful about how we structure the application as Mount is agnostic regarding the architecture.
Welcome to the new clojure.org!
Clojure News 14 01 2016
You are reading this on the newly updated Clojure web site! The first thing you will notice is that everything got a fresh coat of paint and the design is a big step forward. Essentially all of the old page content has been moved over to the new site, however some things are in new locations - in virtually all of those cases, you should find redirects taking you to the new location.
There are also several new things on the site:
-
News - periodically we will post topical news here about new features, releases, or other things of note - these also appear as links on the home page
-
Events - there is now a page for each upcoming Clojure event, also with links on the home page
-
Guides - a new section for building out community guides and tutorials
Most importantly, all of the site content is stored in a repository and open for pull requests from contributors with a signed contributor agreement. If you are interested in adding or changing content, please check out the page on site contributions and the current issues list.
Beta Release Update
Unfortunately, it looks like there's been a bit of editorial delay and we missed the 13th release date. The new date is set for the second of February. Apologies to everybody who's waiting for the release.
I'm glad to report that the second edition of Web Development with Clojure is just around the corner. The beta release is planned for January the 13th, and then I'm hoping to have the final release shortly after. The second edition took a bit longer than I anticipated, but I think the wait will be worth it.
What to Expect
The primary goal of the book is to provide a solid introduction to the world of Clojure web development. Clojure community is growing rapidly and most new users come from languages such as Java, Ruby, and Python.
My aim is to illustrate how to build typical web applications using Clojure in a style that's friendly to those who come from using a mainstream language. In order to keep the material accessible, I deliberately chose to focus on the core concepts and avoid some of the more advanced topics. Conversely, if you're already familiar with Clojure and would like to get into web development then the book will serve as a great introduction.
The first edition of my book came out at the time when Clojure web stack was in a great deal of flux. Noir micro-framework just got deprecated, Cognitect announced Pedestal, and ClojureScript was in its infancy. It was hard to predict where things would go from there.
Much has changed in the past year in Clojure web ecosystem, and the second edition of the book reflects that. While the first edition was fairly unopinionated and gave a broad overview of different libraries, the new version primarily focuses on the Luminus stack.
Majority of the tools and libraries I cover are the ones I've used professionally to build real world applications. This naturally means that there is an inherent bias towards my workflow and the way I like to build applications. On the other hand, if you're new to building Clojure web applications it's helpful to learn using a particular workflow that you can adjust to your needs as you get comfortable.
Just like the first edition, the book is based around projects that illustrate how to accomplish different tasks in a typical web app. Each chapter introduces a particular concept and gets the reader to work through it by building a project from scratch. By the end of the book the reader should be comfortable writing many typical web applications using Clojure and have the background to explore further on their own.
Topics Covered
The book will consist of the following chapter:
Getting Your Feet Wet
- takes the reader through setting up the environment and building a simple application using Luminus
Clojure Web Stack
- takes a step back and looks at Ring and Compojure in detail
Luminus Architecture
- provides an overview of the Luminus template and ways to organize your projects
Add ClojureScript
- illustrates how to convert the applications from the first chapter to a SPA style app using Reagent
Real-time Messaging With Websockets
- illustrates how to use Websockets in a Clojure/Script application using Sente
Writing RESTful Web Services
- covers the basics of using the compojure-api library to provide Swagger style service API
Database Access
- introduces clojure.java.jdbc and Yesql, and how to use these libraries to work with a relational database
Picture Gallery
- ties all the above concepts together by working through a picture gallery application
Finishing Touches
- covers testing and packaging the application for deployment
The book will also contain a number of appendices that deal with topics such as NoSQL databases.
What's Not Covered
As Clojure web ecosystem continues to evolve, many new tools and libraries, such as the JUXT stack, have appeared just this year. While I would love to cover them all, that simply wouldn't fit the goals I set for this project.
One notable omission from the book is Om Next. First, I'd like to say that it's a fantastic library and I think very highly of it as well as the ideas behind it. However, I simply haven't used it in anger as I have Reagent. I also think that Reagent is the simpler of the two libraries and therefore more suitable for beginners. I hope that the book will provide a solid foundation for the reader to explore libraries like Om on their own.
Trouble with AOT
(iterate think thoughts) 26 12 2015
I recently ran into an interesting issue when I added the slf4j-timbre dependency to a project. As soon as the dependency was added the project would fail to build and I'd see the following error:
Caused by: java.io.FileNotFoundException: Could not locate clojure/tools/reader/impl/ExceptionInfo__init.class or clojure/tools/reader/impl/ExceptionInfo.clj on classpath.
The slf4j-timbre library does not depend on clojure.tools.reader, and at first glance there's nothing in it that should've caused problems. I did notice that the library depends on com.taoensso/timbre 4.1.4 that in turn depends on com.taoensso/encore 2.18.0, and it uses on an older version of clojure.tools.reader.
At this point I thought the solution would be simple. I'd just include the latest version of encore and everything should work fine. However that didn't turn out to be the case.
I decided to take another look at slf4j-timbre to see what else might be happening. At this point I noticed that it uses :aot :all in the project configuration. This causes the library to be compiled to Java classes as opposed to being distributed at source. This is necessary since the library has to implement the SLF4J interface and has to provide a Java class in its implementation.
When the namespace that references Timbre is compiled then any namespaces it depends on are also compiled and packaged in the jar. These compiled classes will take precedence over the source dependencies when the library is included in the project.
So, even though I was explicitly including the version of encore that uses the latest clojure.tools.reader, the compiled version packaged in slf4j-timbre would end up being used causing the exception above. As far as I can tell there's no way to overwrite these in the project configuration.
Implications for Luminus
Unfortunately, Luminus dependencies require both a SLF4J compliant logger and the latest clojure.tools.reader. While I think Timbre is an excellent library, it's just not the right fit at the moment.
Luckily, clojure.tools.logging provides a SLF4J compliant API for Clojure logging. The latest release of Luminus uses clojure.tools.logging along with the log4j library as the default logging implementation. It's a mature library that has excellent performance and provides a plethora of logging appenders.
Since log4j can be configured using a properties file, it fits the Luminus approach of using 12 factor style configuration. The library will look for a file called log4j.properties on the classpath to get its default configuration. Luminus packages this file in the resources folder with the following configuration:
### stdout appender
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%d][%p][%c] %m%n
### rolling file appender
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=./log/app-name.log
log4j.appender.R.MaxFileSize=100KB
log4j.appender.R.MaxBackupIndex=20
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=[%d][%p][%c] %m%n
### root logger sets the minimum logging level
### and aggregates the appenders
log4j.rootLogger=DEBUG, stdout, R
As you can see the configuration is very straight forward, it's also well documented. The default configuration can be overridden at runtime by setting the :log-config environment variable. You can now create a custom logging configuration on the target system and then set an environment variable to point to it as seen below:
export LOG_CONFIG=prod-log.properties
I think that the new approach provides a solid solution for most situations with minimal changes from the existing behavior.
Final Thoughts
The moral of the story is that you want to be very careful when using AOT in libraries. Whenever possible it is best to avoid it, and if you do have to use it then try to find the minimal subset of the namespaces that absolutely have to be compiled.
The problem of State
Most real-world applications will interact with external resources such as databases. Typically, in order to interact with a database we have to initialize a connection when our application starts, use this connection to access the database, and then tear it down when the application shuts down.
In some cases these resources may even depend on one another. We may be getting configuration from one resource and then using it to initialize another. A large application may have a number of different resources that are interdependent and have to be coordinated.
Using Component
One popular approach to addressing this problem is to use the component library. Component creates a graph that describes all the resources and then we pass it around to any functions that rely on them. This library was originally developed to support the reloaded workflow advocated by Stuart Sierra.
The advantage of this approach is that it allows us to keep the application code completely stateless and lets us inject the stateful resources at runtime. The two main benefits are that the core application logic remains pure and we can easily provide mock resources to it for testing. If you're interested in learning more about building applications based on component I recommend checking out the Duct framework by James Reeves that I covered in an earlier post.
I think that's a fine approach for building applications, but I also think that there are tradeoffs that one has to buy into when using component.
Component introduces simplicity by providing a formal separation between pure and impure code, but also adds complexity in terms of the structure of the application.
The application has to keep a global component graph that tracks the relationships between the resources and pass it explicitly to any code that needs to interact with them. My experience is that this introduces boilerplate and indirection making the overall application structure more complex. Component also requires the developer to adopt a specific workflow to take full advantage of it.
Component can also be rather confusing for beginners and I have avoided using it in Luminus for that reason. However, the problems that component addresses are real and if we're not using component we still need a way to address them. For this reason Luminus uses the mount library to orchestrate the stateful resources in the application.
Using Mount
Unlike component, mount does not require us to structure the application in a specific way or to adopt a particular workflow to use it.
The library leverages the existing namespace hierarchy to resolve the resource dependencies. This approach obviates the need to keep a separate component graph and pass it all over the application.
Mount uses the defstate macro to define stateful resources. The macro allows specifying the code to initialize and tear down the resource by associating it with the :start and :stop keys. In case of a connection we would associate the code that initializes the connection in the :start key and the code that tears it down with the :stop key respectively.
Mount will look for any namespaces that define states with defstate and and compile a set of stateful resources based on that. The resources are started and stopped based on the order of reference of their namespaces.
Mount system is started by calling mount.core/start and stopped using mount.core/stop. This ensures that the lifecycle of the resources is managed in automated fashion and their relationships are all accounted for.
Like component, mount supports the reloaded workflow and even provides ways to restart parts of the application. Mount also supports swapping in alternate implementations for the resources. This provides a simple way to run tests with mock resources without having to restart the REPL.
Structuring the Application
While mount provides us with a solution for managing the lifecycle of the components, we still need a way to ensure that our application is easy to reason about. Since mount does not enforce the separation between pure and impure code, we have to structure the application in such a way that side effects aren't mixed into the core application logic.
Encapsulating Resources
The approach I like to take in my applications is to keep the code that interacts with external resources at the edges of the application. The core business logic should be pure and testable, while anything that deals with side effects and external resources should be pushed to a thin layer around it.
I also find it useful to localize resource management in order to reduce coupling between components. For example, when I'm dealing with a database resource I'll create a namespace to manage it. This namespace will be responsible for handling the connection lifecycle internally and providing the connection to the functions defined in it.
Such a namespace provides an API for interacting with the resource for the rest of the application. Any functions calling this API do not have to be aware of its internal implementation.
My experience is that this approach allows compartmentalizing the application into self-contained components that can be reasoned about individually. When I update the internal implementation of a particular component the rest of the application does not need to be aware of the change.
An example of this would be changing the underlying resource. We may start writing the application by using a database directly, then realize that the functionality can be extracted into a shared service. When the mechanics of communicating with an external resource are internal to the component we can safely update it to use the new type of resource without affecting the rest of the application.
Organizing the Components
The workflows in web applications are typically driven by the client requests. Since requests will often require interaction with a resource, such as a database, we will generally have to access that resource from the route handling the request. In order to isolate the stateful code we should have our top level functions deal with managing the side effects.
Consider a concrete example. Let's say we have a route that facilitates user authentication. The client will supply the username and the password in the request. The route will have to pull the user credentials from the database and compare these to the ones supplied by the client. Then a decision is made whether the user logged in successfully or not and its outcome communicated back to the client.
In this workflow, the code that deals with the external resources should be localized to the namespace that provides the route and the namespace that handles the database access.
The route handler function will be responsible for calling the function that fetches the credentials from the database. The code that determines whether the password and username match represents the core business logic. This code should be pure and accept the supplied credentials along with those found in the database explicitly. This structure can be seen in the diagram below.
pure code
+----------+
| business |
| logic |
| |
+-----+----+
|
------|---------------------
| stateful code
+-----+----+ +-----------+
| route | | |
| handlers +---+ database |
| | | |
+----------+ +-----------+
Keeping the business logic pure ensures that we can reason about it and test it without considering the external resources. Meanwhile the code that deals with side effects is pushed to the top making it easy for us to manage it.
Conclusion
Clojure makes it easy to structure the application in such a way that the core of the application logic is kept pure. Doing this is a very good practice and will help you keep your applications manageable as they continue to grow. While it's possible to formalize the handling of stateful resources, using libraries such as component, I personally have not found this to be necessary in my applications.
I hope this post provides a bit of an insight into how Luminus based applications should be structured for long term maintainability.
The Sky Is not Falling
(iterate think thoughts) 28 11 2015
A recent post by Elben Shira boldy proclaims the end of dynamic languages. There was a great followup by Maxime Chevalier-Boisvert that I'd like to expand on a bit in this post.
I think that people often forget that programming is a human endeavor. When all is said and done what really matters is whether you enjoy working with a particular language or not. Of course, different people like different things and hence the plethora of languages available today.
I would not presume to tell people that the way I develop is the one true way. I've found an approach that works for me, I know I'm productive with it, and most importantly I enjoy it.
The truth is that this is the case for everybody else out there as well. Anybody who tells you that they found the one true way is frankly deluded. There's no empirical evidence to show that the typing discipline is the deciding factor of code quality, and everybody out there is using their own anecdotal experience to find the workflow that works for them.
Proponents of static typing accept its benefits as axiomatic. However, I think that's a case of putting the cart before the horse. Let's take a look at the claims from the perspective of a dynamic language user.
The Case for Static Typing
Static typing provides a way to formally track relationships in code and thus allows catching a certain class of errors at compile time. The advantage of this approach is that it becomes possible to guarantee that these types of errors cannot occur at runtime.
Many proponents of static typing argue that this is a common source of errors in dynamic languages and that it's not possible to write and maintain large codebases in absence of static types. It's common to see assertions such as the following:
In practice, very little research has been done to determine whether this is a major source of errors for applications written in dynamic languages, and the few studies that are available don’t show anything conclusive in this regard.
Furthermore, there’s no evidence that real world projects written in statically typed languages produce superior results to their dynamic counterparts. In fact, some of the largest and most robust systems out there are written in dynamic languages such as Erlang:
Erlang is a poster child for robust and fault tolerant systems. However, plenty of large projects have been written in other dynamic languages as well. There's a good chance that a piece of software you rely on daily is written using a dynamic language and it works just fine.
Complexity inherent in static typing
Since static typing sounds like a net win on paper, the obvious questions are why many people prefer dynamic languages and why hasn't static typing been decisively shown to be more effective.
The main drawback of static typing is that you're required to prove what you're stating to the compiler. Anybody who has done proofs knows that stating something is always simpler than proving it. In fact, many things are very simple to state, but are notoriously difficult to prove. Fermat's last theorem is a famous example of this.
Baking a proof into the solution leads to incidental complexity. Once you run into limits of what the type system can easily express then you end up having to write increasingly more convoluted code to satisfy it.
This results in code that’s harder to understand because it compounds the complexity of the problem being solved with the complexity of expressing it using the type system. Effectively, any statement we make in our program has to be accompanied by a proof of correctness to make it possible for the compiler to verify it. The requirement of proving that the code is self-consistent is often at odds with making it simple.
A concrete example of this would be the use of state monad to formally represent mutation in a language like Haskell. Here's what Timothy Baldridge has to say about his experience trying to apply this pattern in Clojure when working on the core.async library:
In a language that forces us to use a particular formalism to represent this problem there would be no alternative solution. While the resulting code would be provably correct, it would be harder for the developer to reason about its intent. Therefore, it's difficult to say whether it's correct in any meaningful sense.
Ultimately, a human needs to be able to understand what the code is doing and why. The more complexity is layered on top of the original problem the more difficult it becomes to tell what purpose the code serves.
As another example, let’s consider what we would need to understand to read an HTTP request using a Haskell web framework such as Scotty. We'll quickly run into ScottyM type that's defined as type ScottyM = ScottyT Text IO. To use it effectively we need to understand the ScottyT. It in turn requires understanding the ReaderT.
Understanding ReaderT relies on understanding of monads, monad transformers and the Reader monad. Meanwhile, to understand the Reader we have to know about functors and applicatives. To understand these we have to understand higher kinded types and constructor classes. This leads us to type classes, type constructors, algebraic datatypes, and so forth.
All of this is needed to satisfy the formalisms of the Haskell type system and is completely tangential to the problem of reading HTTP requests from a client.
Of course, one might argue that Haskell is at the far end of the formal spectrum. In a language with a more relaxed type system you have escape hatches such as casting and unchecked side effects.
However, once you go down that road then it's only a matter of degrees with how relaxed a system you're comfortable with. At this point you've already accepted that working around the type system can make your life easier.
I recently watched a great talk titled Optimizing ClojureScript Apps For Speed, where Allen Rohner discusses the benefits and hurdles of server-side rendering.
React supports hooking in to server generated HTML at runtime. However, since React is a JavaScript library it becomes problematic to leverage this functionality from Clojure. While the JVM provides a Js runtime with Nashorn, it's extremely slow and requires a lot of twiddling to work for even basic examples.
Another approach is to run an instance of Node.js and farm out React rendering to it. This avoids the limitations of Nashorn, but introduces a host of new problems described in the talk.
Allen then proposes an alternative approach where he implements parts of the Om API and cross-compiles the components that way. You can see how this works in his Foam library.
The main difficulty identified in the talk is in implementing a sufficient amount of Om API in order to generate HTML on the server.
This got me thinking about what it would take to leverage this approach using Reagent. Unlike Om, Reagent has a tiny API and the only part of it used to create components is the Reagent atom implementation. The components themselves are written using plain Hiccup syntax.
Let's see how this could work. We'll start by creating a new Reagent project:
lein new reagent reagent-serverside
Next, we'll add a new namespace in called reagent-serverside.home src/cljc/reagent_serverside/home.cljc. This namespace will house the home page component that we'll pre-render on the server.
All we have to do now is to use a reader conditional to only require the Reagent atom during ClojureScript compilation:
(ns reagent-serverside.home
#?(:cljs
(:require [reagent.core :as reagent :refer [atom]])))
We can now write our components as we would normally:
(ns reagent-serverside.home
#?(:cljs
(:require [reagent.core :as reagent :refer [atom]])))
(def items (atom nil))
(defn item-list [items]
[:ul
(for [item items]
^{:key item}
[:li item])])
(defn add-item-button [items]
[:button
{:on-click #(swap! items conj (count @items))}
"add item"])
(defn home-page []
[:div [:h2 "Welcome to reagent-serverside"]
[add-item-button items]
[item-list @items]])
We'll have the items atom to house a collection of items, an item-list function to render it, and the home-page function that will use the item-list component. We also have a button that lets the user add new items with an :on-click event. This is all standard Reagent code.
Rendering on the Server
Now, let's navigate to the reagent-serverside.handler namespace and reference the reagent-serverside.home we just created.
(ns reagent-serverside.handler
(:require ...
[reagent-serverside.home :refer [items home-page]]))
We'll now have to write the functions that will traverse the components and render them as appropriate. We'll attach a :data-reactid key to each one to give it an identifier that React looks for, and inject the result into our Hiccup markup.
(defn react-id-str [react-id]
(assert (vector? react-id))
(str "." (clojure.string/join "." react-id)))
(defn set-react-id [react-id element]
(update element 1 merge {:data-reactid (react-id-str react-id)}))
(defn normalize [component]
(if (map? (second component))
component
(into [(first component) {}] (rest component))))
(defn render
([component] (render [0] component))
([id component]
(cond
(fn? component)
(render (component))
(not (coll? component))
component
(coll? (first component))
(map-indexed #(render (conj id %1) %2) component)
(keyword? (first component))
(let [[tag opts & body] (normalize component)]
(->> body
(map-indexed #(render (conj id %1) %2))
(into [tag opts])
(set-react-id id)))
(fn? (first component))
(render id (apply (first component) (rest component))))))
(reset! items (range 10))
(def mount-target
[:div#app (render home-page)])
The render function will recursively walk the components evaluating any functions it finds and assigning the React id to each element.
Next, we'll set the items atom to a range of numbers, and then call render inside the mount-target to generate the markup.
Rendering on the Client
Finally, let's navigate to the reagent-serverside.core namespace in the src/cljs source path. We'll update it to reference the home namespace we created and render the home-page component on load.
(ns reagent-serverside.core
(:require [reagent.core :as reagent :refer [atom]]
[reagent-serverside.home :refer [items home-page]]))
(defn mount-root []
(reagent/render [home-page] (.getElementById js/document "app")))
(defn init! []
(reset! items (range 20))
(mount-root))
When we load the page we'll immediately see the server generated markup and then it will be updated by Reagent when ClojureScript is loaded. There are a few caveats here that you should be aware of.
Any components you wish to render on the server have to be written in cljc, so you may end up having to add some shims for things like Ajax calls.
The component syntax has to work with both Reagent and Hiccup, so you have to be mindful to use the common subset.
React is fairly picky about the structure and the data-reactid tags. So, it can be tricky to generate a DOM tree that it likes. The example in the post will give a React warning about the DOM being different. Some more work is needed around this.
However, even in the case that React doesn't reuse the DOM, the user will see the page immediately and you'll get the benefits of SEO for your site.
Full source is available on GitHub.
Conclusions
Overall, I'm very happy with the results and it looks like it would be fairly easy to wrap this up into a library. The data focused approach is a huge win for Reagent here in my opinion. Since the components are laid out using regular Clojure data structures there's no need to implement any special API and things just work out of the box.
ClojureScript can now compile itself without relying on the Google Closure compiler, and it's now possible to evaluate code straight in the browser. In this post we'll look at how that's accomplished by creating a code editor using CodeMirror, highlight.js, and Reagent. The code entered in the editor will be sent for evaluation and the result displayed to the user.
Let's start by creating a new Reagent project by running the following command:
lein new reagent cljs-eval-example +figwheel
Next, we'll navigate to the project folder and start Figwheel by running:
lein figwheel
Let's open the browser at http://localhost:3449 and navigate to the cljs-eval-example.core namespace in the src/cljs folder. We'll first need to reference cljs.js namespace:
(ns cljs-eval-example.core
(:require
...
[cljs.js :refer [empty-state eval-str js-eval]]))
We'll create evaluate function that will accept a string and a callback. This function calls cljs.js/eval-str as follows:
(defn evaluate [s cb]
(eval-str
(empty-state)
s
nil
{:eval js-eval
:source-map true
:context :expr}
cb))
The eval-str function accepts an initial state, followed by the string representing the form to evaluate, a name, a map with the options, and a callback function for handling the result of the evaluation. We can create an initial state by calling cljs.js/empty-state function. We can now test that our code works by adding a button to our home-page component:
(defn home-page []
[:div
[:button
{:on-click #(evaluate "(println \"hello world!\")" (fn [_]))}
"let's compile!"]])
When we click the button we should see "hello world!" printed in the browser console. Next, let's add a :textarea to allow entering some text and then send it for evaluation.
(defn home-page []
(let [input (atom nil)
output (atom nil)]
(fn []
[:div
[:textarea
{:value @input
:on-change #(reset! input (-> % .-target .-value))}]
[:div>button
{:on-click #(evaluate @input (fn [result] (reset! output result)))}
"let's compile!"]
[:p @output]])))
At this point we can type some code in our input box, click the button to evaluate it, and see the result. So far so good, now let's make the editor look a bit nicer by replacing it with the CodeMirror version.
We'll open up the cljs-eval-example.handler namespace in the src/clj folder. There, we'll update the include-css and include-js portions of the head to add the respective CSS and Js files for running CodeMirror.
(defn head []
[:head
[:meta {:charset "utf-8"}]
[:meta {:name "viewport"
:content "width=device-width, initial-scale=1"}]
(include-css
(if (env :dev) "/css/site.css" "/css/site.min.css")
"//cdnjs.cloudflare.com/ajax/libs/codemirror/5.8.0/codemirror.min.css"
(if (env :dev) "css/site.css" "css/site.min.css"))
(include-js
"//cdnjs.cloudflare.com/ajax/libs/codemirror/5.8.0/codemirror.min.js"
"//cdnjs.cloudflare.com/ajax/libs/codemirror/5.8.0/mode/clojure/clojure.min.js")])
With that in place we'll need to reload the page for the new assets to become available. Since we're using external JavaScript that modifies the DOM, we'll need to use the reagent.core/create-class function to create the editor component.
The create-class function accepts a map keyed on the React lifecycle methods. The methods that we wish to implement are :render and :component-did-mount:
(defn editor [input]
(reagent/create-class
{:render (fn [] [:textarea
{:default-value ""
:auto-complete "off"}])
:component-did-mount (editor-did-mount input)}))
The editor component will accept the input atom as the parameter and pass it to the editor-did-mount function. This function will look as follows:
(defn editor-did-mount [input]
(fn [this]
(let [cm (.fromTextArea js/CodeMirror
(reagent/dom-node this)
#js {:mode "clojure"
:lineNumbers true})]
(.on cm "change" #(reset! input (.getValue %))))))
The editor-did-mount is a closure that returns a function that accepts the mounted React component, it then calls reagent/dom-node on it to get the actual DOM node mounted in the browser. We'll then call .fromTextArea method on js/CodeMirror and pass it the node along with a map of rendering hints.
Calling .fromTextArea returns an instance of the CodeMirror. As a last step we'll add the change event to this instance to reset the input atom with the updated text whenever the text in the editor is changed.
We can now update the home-page component to use the editor component instead of a plain textarea:
(defn home-page []
(let [input (atom nil)
output (atom nil)]
(fn []
[:div
[editor input]
[:div
[:button
{:on-click #(evaluate @input (fn [{:keys [value]}] (reset! output value)))}
"run"]]
[:p @output]])))
The editor looks a lot nicer now, but the output doesn't have any highlighting. Let's fix that by running it through highlight.js to generate nicely formatted results.
Once again, we'll need to add the additional CSS and Js files in the cljs-eval-example.handler namespace:
(defn head []
[:head
[:meta {:charset "utf-8"}]
[:meta {:name "viewport"
:content "width=device-width, initial-scale=1"}]
(include-css
(if (env :dev) "/css/site.css" "/css/site.min.css")
"//cdnjs.cloudflare.com/ajax/libs/codemirror/5.8.0/codemirror.min.css"
"//cdnjs.cloudflare.com/ajax/libs/highlight.js/8.9.1/styles/default.min.css"
(if (env :dev) "css/site.css" "css/site.min.css"))
(include-js
"//cdnjs.cloudflare.com/ajax/libs/highlight.js/8.9.1/highlight.min.js"
"//cdnjs.cloudflare.com/ajax/libs/codemirror/5.8.0/codemirror.min.js"
"//cdnjs.cloudflare.com/ajax/libs/codemirror/5.8.0/mode/clojure/clojure.min.js")])
Back in the cljs-eval-example.core namespace we'll add a reference for [cljs.pprint :refer [pprint]] and write the result-view component that will take care of highlighting the output.
(ns cljs-eval-example.core
(:require ...
[cljs.pprint :refer [pprint]]))
...
(defn result-view [output]
(reagent/create-class
{:render (fn []
[:pre>code.clj
(with-out-str (pprint @output))])
:component-did-update render-code}))
Highlight.js defaults to using <pre><code>...</pre></code> blocks, so we'll generate one in the :render function. Then we'll call the render-code function when the :component-did-update state is triggered. This function will simply pass the node to the .highlightBlock function provided by highlight.js:
(defn render-code [this]
(->> this reagent/dom-node (.highlightBlock js/hljs)))
Finally, we'll have to update the home-page component to use the result-view component we just wrote:
(defn home-page []
(let [input (atom nil)
output (atom nil)]
(fn []
[:div
[editor input]
[:div
[:button
{:on-click #(evaluate @input (fn [{:keys [value]}] (reset! output value)))}
"run"]]
[:div
[result-view output]]])))
Now both the editor and the output should look nicely highlighted, and the output will be formatted as a bonus. The entire code listing is as follows:
(ns cljs-eval-example.core
(:require
[reagent.dom :as dom]
[reagent.core :as reagent :refer [atom]]
[cljs.js :refer [empty-state eval-str js-eval]]
[cljs.pprint :refer [pprint]]))
(defn evaluate [s cb]
(eval-str
(empty-state)
s
nil
{:eval js-eval
:source-map true
:context :expr}
cb))
(defn editor-did-mount [input]
(fn [this]
(let [cm (.fromTextArea js/CodeMirror
(dom/dom-node this)
#js {:mode "clojure"
:lineNumbers true})]
(.on cm "change" #(reset! input (.getValue %))))))
(defn editor [input]
(reagent/create-class
{:render (fn [] [:textarea
{:default-value ""
:auto-complete "off"}])
:component-did-mount (editor-did-mount input)}))
(defn render-code [this]
(->> this dom/dom-node (.highlightBlock js/hljs)))
(defn result-view [output]
(reagent/create-class
{:render (fn []
[:pre>code.clj
(with-out-str (pprint @output))])
:component-did-update render-code}))
(defn home-page []
(let [input (atom nil)
output (atom nil)]
(fn []
[:div
[editor input]
[:div
[:button
{:on-click #(evaluate @input (fn [{:keys [value]}] (reset! output value)))}
"run"]]
[:div
[result-view output]]])))
(defn mount-root []
(dom/render [home-page] (.getElementById js/document "app")))
(defn init! []
(mount-root))
A complete example project is available on GitHub.

It's often useful to be able to tell how much resources your app happens to be using. I've previously discussed how JVisualVM can be used to do some basic profiling for the application. In this post we'll look at how to use another great tool called jconsole that also comes with the JVM. First, let's create and run a new Luminus web app as follows:
lein new luminus guestbook
cd guestbook
lein uberjar
java -jar target/guestbook.jar
We'll run the following command in a separate terminal:
jconsole
We should be greeted by a screen that looks something like the following:
We'll select guestbook and connect to it. Once the connection is established we'll see an overview screen detailing memory, class instances, threads, and CPU usage.

We can also select tabs to drill down into details about each of these as well as the VM summary. The Memory tab is the one of most interest to start. This screen will let us see a graph of memory usage over time and allow us to initiate garbage collection. It also shows the details about application memory usage and how it compares to the overall memory allocated by the JVM.

Let's run the Apache HTTP server benchmarking tool, that comes bundled by default on OS X, and see how that affects our application.
ab -c 10 -n 1000 http://127.0.0.1:3000/
This is ApacheBench, Version 2.3 <$Revision: 1663405 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 127.0.0.1 (be patient)
Completed 100 requests
Completed 200 requests
Completed 300 requests
Completed 400 requests
Completed 500 requests
Completed 600 requests
Completed 700 requests
Completed 800 requests
Completed 900 requests
Completed 1000 requests
Finished 1000 requests
Server Software: undertow
Server Hostname: 127.0.0.1
Server Port: 3000
Document Path: /
Document Length: 3918 bytes
Concurrency Level: 10
Time taken for tests: 3.544 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 4251000 bytes
HTML transferred: 3918000 bytes
Requests per second: 282.14 [#/sec] (mean)
Time per request: 35.444 [ms] (mean)
Time per request: 3.544 [ms] (mean, across all concurrent requests)
Transfer rate: 1171.26 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.1 0 3
Processing: 15 35 27.4 26 252
Waiting: 15 35 26.3 26 226
Total: 15 35 27.5 26 252
Percentage of the requests served within a certain time (ms)
50% 26
66% 31
75% 37
80% 41
90% 54
95% 75
98% 110
99% 227
100% 252 (longest request)
- note that 282 req/sec number is running without any warmup while being instrumented
We can see that as the server is getting hammered by requests the memory usage spikes from roughly a 100 megs to about 275. However, once GC is performed the memory usage goes right back down.

This tells us that the application starts using more resources as it serves multiple concurrent requests, but then releases these as the GC runs indicating that no memory leaks are happening. We can also confirm that the threads and class instances are not getting out of hand as the application continues to run using the the respective tabs.


As you can see jconsole is a handy tool that can be used to quickly diagnose the behavior of a Clojure application. Should we find anything that warrants further investigation then it would be time to run a profiler such as jvisualvm to see where specifically the resources are being used.
In this post we'll look at writing a RESTful service using Duct and compojure-api. Our service will use a SQLite database and illustrate how to do operations such as adding, remove, and authenticating users.
Prerequisites
Creating the Project
Duct is a minimal web framework with emphasis on using component to manage stateful resources such as database connections. We can create a new Duct application by running the following command:
lein new duct swagger-service +example
This will generate a fresh application and add an example route component to it. Once the application is created we'll have to run the setup task to generate local assets in the root folder of the application:
cd swagger-service
lein setup
We can now test that our application works as follows:
lein run
If everything went well then we should be able to navigate to localhost:3000 and see Hello World displayed on the page. We're now ready to start working on creating our service.
Adding Dependencies
We'll start by adding some dependencies in project.clj that we'll need in order to create our service:
:dependencies
[...
[crypto-password "0.1.3"]
[metosin/compojure-api "0.23.1"]
[org.xerial/sqlite-jdbc "3.8.11.1"]
[yesql "0.5.0"]
[migratus "0.8.4"]]
We'll use crypto-password to handle password hashing when we create user accounts and checking passwords during authentication. The compojure-api library will be used to generate the service endpoints. The sqlite-jdbc driver will be used as our data store, we'll access it using yesql, and we'll generate the database using migratus.
Configuring Migrations
Let's add the migratus plugin along with its configuration to our project:
:plugins [[lein-environ "1.0.1"]
[lein-gen "0.2.2"]
[migratus-lein "0.1.7"]]
:migratus {:store :database
:db {:classname "org.sqlite.JDBC"
:connection-uri "jdbc:sqlite:service-store.db"}}
We can now run the following commands to generate the migration files for the users table:
mkdir resources/migrations
lein migratus create users
This will produce files for up and down migrations such as:
20151001145313-users.down.sql
20151001145313-users.up.sql
The up migrations file will create the table:
CREATE TABLE users
(id VARCHAR(20) PRIMARY KEY,
first_name VARCHAR(30),
last_name VARCHAR(30),
email VARCHAR(30),
admin BOOLEAN,
last_login TIME,
is_active BOOLEAN,
pass VARCHAR(100));
Conversely, the down migrations file will delete it:
DROP TABLE users;
We can now run the following command to create the database:
lein migratus migrate
Adding Database Queries
With the database created, we'll need to add some queries to access the database. We'll create a new file called resources/sql/queries.sql and put the following SQL queries in it:
-- name: create-user!
-- creates a new user record
INSERT INTO users
(id, first_name, last_name, email, pass)
VALUES (:id, :first_name, :last_name, :email, :pass)
-- name: get-user
-- retrieve a user given the id.
SELECT * FROM users
WHERE id = :id
-- name: get-users
-- retrieve a user given the id.
SELECT id, first_name, last_name, email FROM users
-- name: delete-user!
-- delete a user given the id
DELETE FROM users
WHERE id = :id
Creating the Database Component
Now, let's create a component that will be used to access it. We'll create a new namespace called swagger-service.component.db then put the following code there:
(ns swagger-service.component.db
(:require [yesql.core :refer [defqueries]]
[com.stuartsierra.component :as component]
[crypto.password.bcrypt :as password]
[environ.core :refer [env]]))
(defqueries "sql/queries.sql")
(defn create-user-account! [user db]
(create-user! (update user :pass password/encrypt) db))
(defn authenticate [user db]
(boolean
(when-let [db-user (-> user (get-user db) first)]
(password/check (:pass user) (:pass db-user)))))
(defrecord DbComponent [connection]
component/Lifecycle
(start [component]
(assoc component :connection connection))
(stop [component]
(dissoc component :connection)))
(defn db-component [connection]
(->DbComponent connection))
The namespace will define query functions by calling the defqueries macro and giving it the path to the queries.sql file we just created.
Then we'll add a couple of helper functions to create a user account with a hashed password and to check whether the user and the password match the stored credentials.
Next, we define the DbComponent record that will manage the lifecycle of the database. The start function in the component will associate the given connection settings with the :connection key in the component, and the stop function will remove the connection.
The connection is specified in the swagger-service.config namespace and points to the connection-uri key that is expected to be found in the environment.
(def environ
{:http {:port (some-> env :port Integer.)}
:db {:connection-uri (:connection-uri env)}})
We'll add the actual connection information under the :env key in profiles.clj:
;; Local profile overrides
{:profiles/dev {:env {:connection-uri "jdbc:sqlite:service-store.db"}}
:profiles/test {}}
Finally, we have a helper function to instantiate the component called db-component.
Adding a New Component to the System
With the component created we can now add it to the system found in the swagger-service.system namespace:
(ns swagger-service.system
(:require ...
[swagger-service.component.db :refer [db-component]]))
...
(defn new-system [config]
(let [config (meta-merge base-config config)]
(-> (component/system-map
:db (db-component (:db config))
:app (handler-component (:app config))
:http (jetty-server (:http config))
:example (endpoint-component example-endpoint))
(component/system-using
{:http [:app]
:app [:example]
:example []
:db []}))))
Creating an HTTP Endpoint Component
The final step is to add the service endpoint that will provide the RESTful interface to the database. We'll create a new namespace called swagger-service.endpoint.service. The namespace will use the compojure-api library to define the service operations. The library requires us to declare the types of request parameters and responses for each endpoint using the schema library.
Let's start by creating the namespace declaration with the following references:
(ns swagger-service.endpoint.service
(:require [clojure.java.io :as io]
[ring.util.http-response :refer :all]
[compojure.api.sweet :refer :all]
[schema.core :as s]
[swagger-service.component.db :as db]))
Then we'll create the schema for the User type that matches the user table in our database:
(s/defschema User
{:id String
(s/optional-key :first_name) String
(s/optional-key :last_name) String
(s/optional-key :email) String
(s/optional-key :pass) String})
Finally, let's create the service-endpoint component that will define the service routes. The component accepts the config as its parameter. The config will contain the :db key that we added to our system earlier with the database connection.
The routes are created by calling the api macro from compojure-api:
(defn service-endpoint [config]
(api
(ring.swagger.ui/swagger-ui
"/swagger-ui")
(swagger-docs
{:info {:title "User API"}})
(context* "/api" []
:tags ["users"]
(GET* "/users" []
:return [User]
:summary "returns the list of users"
(ok (db/get-users {} (:db config))))
(GET* "/user/:id" []
:return User
:path-params [id :- String]
:summary "returns the user with a given id"
(ok (db/get-users {:id id} (:db config))))
(POST* "/authenticate" []
:return Boolean
:body-params [user :- User]
:summary "authenticates the user using the id and pass."
(ok (db/authenticate user (:db config))))
(POST* "/user" []
:return Long
:body-params [user :- User]
:summary "creates a new user record."
(ok (db/create-user-account! user (:db config))))
(DELETE* "/user" []
:return Long
:body-params [id :- String]
:summary "deletes the user record with the given id."
(ok (db/delete-user! {:id id} (:db config)))))))
Notice that we call ring.swagger.ui/swagger-ui and swagger-docs at the beginning of the definition of api. This will automatically produce the API documentation for the service operations defined within it. Once our service is hooked up, we'll be able to navigate to localhost:3000/swagger-ui and see an interactive page for testing the API endpoints.
As you may have noticed, compojure-api mimics Compojure route definitions with the difference that the route method name has a * after it. The route definition also has some additional keys associated with it.
- the
:returnkey specifies the return type for the service operation - the
:summarykey provides the documentation about the purpose of the operation - the parameters are specified using different keys depending on the parameter type, such as
:path-paramsand:body-params.
Finally, each route will return a response type with the result of calling the handler associated with it.
If we look at the "/users" route we see that it calls the get-users function from the database and passes it the value of the :db key from the config. This will be used to resolve the database connection at runtime.
Adding the Endpoint to the System
With the route added we can now navigate back to the swagger-service.system namespace and add the component there:
(ns swagger-service.system
(:require ...
[swagger-service.component.db :refer [db-component]]
[swagger-service.endpoint.service :refer [service-endpoint]]))
...
(defn new-system [config]
(let [config (meta-merge base-config config)]
(-> (component/system-map
:db (db-component (:db config))
:app (handler-component (:app config))
:http (jetty-server (:http config))
:example (endpoint-component example-endpoint)
:service (endpoint-component service-endpoint))
(component/system-using
{:http [:app]
:app [:example :service]
:service [:db]
:example []
:db []}))))
The service component is initialized using the endpoint-component Duct helper. Next, the component relationships have to be described explicitly. We can see that the :service component depends on the :db component, and the :app in turn depends on both the :example and the :service.
We can now restart our app and navigate to localhost:3000/swagger-ui to see the service test page. Using this page we can test all the service operations that we defined such as creating new users, authenticating, and listing users.
The full source for this tutorial is available on GitHub.
Conclusion
As you can see, compojure-api allows us to easily define RESTful services with type assertions, documentation, and a helpful test page. I've found this approach to be extremely effective when creating service APIs as it documents what each endpoint is doing and makes it easy to collaborate with consumers of the service. Meanwhile, Duct provides an excellent base for building services using the component pattern.
Update
After having some discussions with the author of HTTP Kit and doing a deeper evaluation of Immutant I'm switching to it as the default.
It turns out that Immutant addresses all of the concerns as well as HTTP Kit while having the benefit of a larger team maintaining it.
The version 2 of Immutant is modular and provides a minimal runtime that has low overhead. The websocket support works similarly to HTTP Kit and is now documented as well. Unlike Jetty 9 adapters with websocket support, Immutant builds do not require JRE 8 to run.
Finally, Immutant provides many useful pluggable libraries for caching, message queues, and scheduling.
End Update
One of the guiding principles for Luminus has been to provide a great user experience out of the box. Having to go through a tedious setup before you can focus on the problem you actually want to solve should be unnecessary.
Luminus removes the burden or having to find the libraries, configure middleware, and add the common boilerplate. The application generated by the template is ready for deployment out of the box. The only part that's missing is the domain logic for your application.
As the project evolves I'm always looking for new ways to streamline user experience. Clojure web ecosystem is rapidly evolving along with the best practices and tools. Luminus aims to keep abreast of these changes and to provide a reference implementation for Ring based applications.
Recently, Luminus moved to using Migratus for handling database migrations for reasons discussed in this post. This time we'll look at the reasons for moving to HTTP Kit as the default server.
Up to now, Luminus applications would use the version of Jetty packaged by the Ring dependency. The major drawback of the default Jetty adapter is its lack of support for websockets. After evaluating the alternatives I settled on HTTP Kit as the default server for Luminus.
HTTP Kit is built on top of NIO. It combines high performance when handling a large number of connections with low memory overhead per connection. Finally, it provides a Ring/Compojure compatible API for working with websockets that's now part of the official Luminus documentation.
While HTTP Kit is the default, all the major HTTP servers are supported via their respective flags:
+alpeh- Aleph is a stream based server built on top of Netty+immutant- Immutant is a JBoss based server with many built in features such as messaging, scheduling and caching+jetty- Jet is the Ring Jetty adapter with websocket support
Another major change is that the lein-ring plugin is no longer used by default. Since the plugin is based on the Jetty based ring-server library, a separate workflow was required for the alternative HTTP servers.
Instead, the template now provides its own core namespace that manages the server lifecycle. This provides a consistent experience regardless of the server being used. The lein-ring plugin is now part of the +war profile used to generate server independent WAR archives for deployment to application servers such as Apache Tomcat.
Data Focused
(iterate think thoughts) 07 07 2015
One interesting part I noticed about working with Clojure is that I practically never look for solutions to problems on Google or StackOverflow. I might google to see if a library exists for accomplishing a particular task, but I rarely end up having to google how to do a specific task.
This got me thinking about why that may be since I used to do that commonly back when I worked with Java. I think the key reason is that Clojure encourages writing code that operates on plain data.
Object Oriented Approach
Object oriented languages, such as Java, encourage encapsulating the data in domain specific abstractions. Rich Hickey discusses this in detail in his excellent Clojure, Made Simple talk. The OO approach ultimately leads to creation of frameworks that provide formalized ways to tie all the different domain abstractions together.
The problem with frameworks is that they impose a particular workflow on the user. However, in most cases there are many valid ways to solve a particular problem. The approach that the framework takes is just one way to do things and not necessarily the best way. If you happen to think about a problem differently from the authors of the framework then using it will not feel intuitive.
When you encounter a problem then you either have to spend the time to understand the internals of the framework and its design or simply memorize how different tasks are accomplished.
Understanding the internals of a complex piece of software is an arduous process that can take a long time and it's often time that you do not have. Conversely, having to understand the internals typically indicates that the abstraction you're working with is a leaky one.
This is where googling comes in. You know what your problem is, you know how you would solve it given the time, but you don't know how the authors of the framework expect you to solve it using their approach.
Since the choice of the solution completely arbitrary, there's no way for you to logically deduce what it is. In many cases the only realistic option is to hope that someone else ran into a similar problem already and see how they solved it within the context of the framework.
Data Centric Approach
Clojure takes the approach of keeping the data and logic separate. Instead of building local abstractions for each domain as we do with objects, all the functions operate on a common set of data structures. When a function is called its output can be used in a new context without any additional ceremony.
Since all Clojure libraries use the same core data structures, it's trivial to take the output of one library and pass it as input to another. Using the REPL we can quickly see how a particular library behaves and what output it generates.
This approach allows the user to find the libraries that fit the problem they're solving and then compose them in the way that makes sense in their particular scenario. The same core pattern of composing data transformations can be applied at different resolutions within a project.
At the lowest level we have functions as our building blocks. We combine these in different ways to transform the data on the small scale.
Once we have a number of related functions that represent a particular domain we combine them into a namespace, and then we pass the data between the namespaces to move data from one domain to another.
Libraries are simply collections of namespaces, and we use the same pattern when transform the data by combining them. A great example of this would be the ring-defaults library that chains a number libraries to achieve complex transformations of HTTP requests and responses.
Finally, at the top level we may have multiple projects passing data between each other in form of services. This approach is becoming increasingly popular in the industry as seen with the micro-services movement.
With Clojure, the focus is always on the data. When solving a problem, all we have to do is figure out how we need to transform the data and then find the appropriate building blocks for our problem.
Focusing on the data helps keep code simple and reusable without introducing unnecessary indirection into the process. I think this is the key reason why it's possible to work with Clojure without having to constantly memorize new patterns to solve different kinds problems.
Clojure 1.7 is now available
Clojure News 30 06 2015
We are pleased to announce the release of Clojure 1.7. The two headline features for 1.7 are transducers and reader conditionals. Also see the complete list of all changes since Clojure 1.6 for more details.
Transducers
Transducers are composable algorithmic transformations. They are independent from the context of their input and output sources and specify only the essence of the transformation in terms of an individual element. Because transducers are decoupled from input or output sources, they can be used in many different processes - collections, streams, channels, observables, etc. Transducers compose directly, without awareness of input or creation of intermediate aggregates.
Many existing sequence functions now have a new arity (one fewer argument than before). This arity will return a transducer that represents the same logic but is independent of lazy sequence processing. Functions included are: map, mapcat, filter, remove, take, take-while, drop, drop-while, take-nth, replace, partition-by, partition-all, keep, keep-indexed, map-indexed, distinct, and interpose. Additionally some new transducer functions have been added: cat, dedupe, and random-sample.
Transducers can be used in several new or existing contexts:
-
into - to collect the results of applying a transducer
-
sequence - to incrementally compute the result of a transducer
-
transduce - to immediately compute the result of a transducer
-
eduction - to delay computation and recompute each time
-
core.async - to apply a transducer while values traverse a channel
Portable Clojure and Reader Conditionals
It is now common to see a library or application targeting multiple Clojure platforms with a single codebase. Clojure 1.7 introduces a new extension (.cljc) for files that can be loaded by Clojure and ClojureScript (and other Clojure platforms).
There will often be some parts of the code that vary between platforms. The primary mechanism for dealing with platform-specific code is to isolate that code into a minimal set of namespaces and then provide platform-specific versions (.clj/.class or .cljs) of those namespaces.
To support cases where is not feasible to isolate the varying parts of the code, or where the code is mostly portable with only small platform-specific parts, 1.7 provides Reader Conditionals.
Reader conditionals are a new reader form that is only allowed in portable cljc files. A reader conditional expression is similar to a cond in that it specifies alternating platform identifiers and expressions. Each platform is checked in turn until a match is found and the expression is read. All expressions not selected are read but skipped. A final :default fallthrough can be provided. If no expressions are matched, the reader conditional will read nothing. The reader conditional splicing form takes a sequential expression and splices the result into the surrounding code.
Contributors
Thanks to all of those who contributed patches to Clojure 1.7:
-
Timothy Baldridge
-
Bozhidar Batsov
-
Brandon Bloom
-
Michael Blume
-
Ambrose Bonnaire-Sergeant
-
Aaron Cohen
-
Pepijn de Vos
-
Andy Fingerhut
-
Gary Fredricks
-
Daniel Solano Gómez
-
Stuart Halloway
-
Rich Hickey
-
Immo Heikkinen
-
Andrei Kleschinsky
-
Howard Lewis Ship
-
Alex Miller
-
Steve Miner
-
Nicola Mometto
-
Tomasz Nurkiewicz
-
Ghadi Shayban
-
Paul Stadig
-
Zach Tellman
-
Luke VanderHart
-
Jozef Wagner
-
Devin Walters
-
Jason Wolfe
-
Steven Yi
Also, continued thanks to the total list of contributors from all releases.
There was a recent discussion on google groups regarding migrations and handling of database credentials in Luminus. Up to now, Luminus would generate a template where the database credentials were hardcoded in the <app>.db.core namespace and migrations were handled by the ragtime.lein plugin.
This was not ideal for a couple of reasons. First, the hardcoded credentials aren't great for any serious applications. The credentials end up being checked in the code repository and have to be manually updated for each environment the application runs in. Second, you end up with separate sets of database configuration for the application and for the plugin. This is error prone as it puts the burden on the user to keep the credentials in sync.
The proposed approach was to use the profiles.clj instead to keep a single set of credentials for development. The production credentials would then be supplied using environment variables. This is a much cleaner approach to handling credentials as they're no longer part of the code and can be configured in a single place.
In the meantime, Ragtime had a new major version release 0.4.0 that introduces a number of changes. Ragtime is moving away from using a Leiningen plugin, and instead recommends running the commands from the REPL. The other major change is that it no longer allows multiple statements in a single migrations file.
The rationale here is that different SQL databases have different restrictions on the commands that can be sent in a single message. Therefore using a heuristic to split up migrations isn't guaranteed to work correctly across different database engines.
While this is true, in my view it also results in subpar user experience. While it's ok for trivial migrations, such as the ones seen in the examples, it doesn't scale well for larger ones. I think that there is a lot of value in being able to see the entirety of a migration in a single place without having to jump across multiple files.
update: Since the writing of the post, Ragtime has added the ability to use a custom separator, so it should be available in the next release.
At this point I decided to see what other migrations libraries were available and to evaluate if any of them would be a good fit for the workflow that Luminus aims to provide. The one I settled on was Migratus. It provides a workflow that's nearly identical to the original Ragtime based one that Luminus used.
Migrtus elegantly addresses the problem of splitting up statements by using a custom separator --;; to identify individual statements within the file. This removes the ambiguity of having to infer where one statement ends and another begins without forcing the user to split their migrations into multiple files.
Unfortunately, Migratus has not been maintained for the past two years and relied on a deprecated version of the clojure.java.jdbc library. Since Migratus already works well and it's a relatively simple library I decided to see if I could bring it up to date.
This turned out to be a relatively painless process and I ended up making some minor changes and improvements along the way. I contacted Paul Stadig, who is the author of the library, and he graciously agreed to transfer the ownership as he's no longer planning on developing it himself. I've released the updated library to Clojars and the latest version of Luminus uses Migratus to handle migrations.
As I mentioned earlier, using a Leiningen plugin to handle dev migrations requires dupliction of credentials. Instead, Luminus now provides an <app>.db.migrations namespace that manages migrations. This namespace is invoked from the <app>.core/-main when it's passed in migrate or rollback arguments. These arguments can be optionally followed by the migration ids in order to apply specific migrations. So, when previously you would run lein ragtime migrate, you'd now run lein run migrate to apply migrations.
Since this code is now part of the project it can now be run from the packaged uberjar as well. This allows the application to run its migrations on the server without necessitating a separate process for migrating the production database. Complete migrations documentation is available on the offical Luminus site.
Having a straight forward way to run migrations and store credentials securely, taking into account production environments, is an important aspect of providing a solid base for developing web applications.
Using Pulsar
(iterate think thoughts) 17 06 2015
In this post, we'll take a look at a basic usage example for Pulsar and see how to package it for production.
What is Pulsar?
Pulsar is the official Clojure API for the Quasar library that provides lightweight green threads and Erlang style actors for the JVM.
Quasar has a lot of similarities to the popular Akka framewok, but has the advantage of being a library as opposed to a framework that imposes its own workflow. For those interested, a detailed comparison of Quasar and Akka is availble here.
Using Pulsar is very straight forward, however there are a few caveats to be aware of when it comes to packaging it for production. Quasar requires bytecode instrumentation in order to provide suspendanble functions, and this means that the project.clj needs to have additional hints to facilitate it.
Creating the Project
Let's start by creating a new project called pulsar-example:
lein new pulsar-example
Next, we'll add the following dependencies to the project.clj file:
[co.paralleluniverse/pulsar "0.7.2"]
[co.paralleluniverse/quasar-core "0.7.2"]
We'll also have to add a :java-agents key that will invoke the Quasar agent responsible for the instrumentation:
:java-agents [[co.paralleluniverse/quasar-core "0.7.2"]]
Adding Actors
Let's open up the pulsar-example.core namespace and update the ns declaration as follows:
(ns pulsar-example.core
(:require
[co.paralleluniverse.pulsar
[core :refer :all]
[actors :refer :all]])
(:refer-clojure :exclude [promise await])
(:gen-class))
We'll implement one of the official examples where two actors send messages to one another. In the example we have two functions called ping and pong. These are defined using the defsfn macro as opposed to regular defn. This is necessary in order for these functions to be suspendable.
The ping function will accept two parameters consisting of the number representing remaining iterations and the actor to send messages to.
The function checks if there are remaining iterations and notfies pong that the conversation is complete when n is zero. Otherwise, it sends a ping message to the pong actor and waits to receive an acknowledgement before recurring. As you may have guessed, the receive call will block until a message is received.
The @self notation is used to access the actor itself. This is needed to pass it to the other actor as part of the message in order to receive a response.
(defsfn ping [n pong]
(if (== n 0)
(do
(! pong :finished)
(println "ping finished"))
(do
(! pong [:ping @self])
(receive
:pong (println "Ping received pong"))
(recur (dec n) pong))))
Meanwhile, the pong function will wait to receive a message, if the message is :finished then it finishes its run, and if it matches [:ping ping] then it will return the message :ping to the caller and recur:
(defsfn pong []
(receive
:finished (println "Pong finished")
[:ping ping] (do
(println "Pong received ping")
(! ping :pong)
(recur))))
Note that the message can either be a keyword or a vector containing the parameters we wish to pass to the actor. Finally, we'll add a -main function as the entry point to our program. Note that we join our actors to ensure that the application keeps running until the actors exit.
(defn -main []
(let [a1 (spawn pong)
b1 (spawn ping 3 a1)]
(join a1)
(join b1)
:ok))
We can now test that everything is working by running it from the REPL or using lein run.
Packaging for Deployment
Once we're ready to package our app for deployment we need to make sure that the Quasar agent can be run to instrument our suspendable functions. To do that we'll have to add a :manifest key to our project that points to the following configuration:
:manifest
{"Premain-Class" "co.paralleluniverse.fibers.instrument.JavaAgent"
"Agent-Class" "co.paralleluniverse.fibers.instrument.JavaAgent"
"Can-Retransform-Classes" "true"
"Can-Redefine-Classes" "true"}
This will be written out to the META-INF/MANIFEST.MF file in the jar and provide the necessary information about the agent. The project can now be packaged by running lein uberjar. One final thing to be aware of is that the resulting jar must be run with the -javaagent flag as follows:
java -javaagent:target/pulsar-example.jar -jar target/pulsar-example.jar
This is all that needs to be done in order to package and run Pulsar projects using Leiningen. As always, the complete source for the example is available on GitHub.
update: Figwheel changed recently and the new process of starting the REPL is documented on the official Wiki.
Figwheel provides a fantastic developer experience and if you're not using it already I highly encourage you to give it a shot. I found that in most cases live code reloading is sufficient for my workflow, but there are occasions where I do want to have an actual REPL available.
This mostly comes up when I'm working with code that's not directly tied to rendering UI components and it can quickly devolve into println debugging.
You probably noticed that Figwheel starts a REPL in the terminal when it runs. However, this REPL is not terribly useful in practice. What would be better is to have a REPL that's connected to the editor, such as Cursive or Emacs, so that you can evaluate the code you're working on the same way you would with Clojure.
Luckily, getting this to work turns out to be a pretty simple affair. First thing we need to do is to make sure that the Figwheel config in project.clj has the :nrepl-port key set as seen below:
:figwheel
{:http-server-root "public"
:server-port 3449
:nrepl-port 7002 ;;start nREPL on port 7002
:css-dirs ["resources/public/css"]
:ring-handler yourapp/handler}
When you run lein figwheel the nREPL server will become available and you can connect your editor to it at localhost:7002, or whatever port you've specifcied. Once the nREPL is connected you'll have to run the following commands there:
user> (use 'figwheel-sidecar.repl-api)
user> (cljs-repl)
You should see the Figwheel REPL start up the same way it did when you ran lein figwheel in the terminal. You should now be able to send any code from the editor to the REPL for evaluation.
Websockets with HTTP Kit
(iterate think thoughts) 11 06 2015
In this post we'll look at working with websocks using Reagent and HTTP Kit. We'll see how to create a multi-user chat server that allows multiple clients to communicate with one another.
First thing to mention is that there are a couple of Clojure/Script libraries for working with websockets, such as Sente and Chord. However, what I'd like to illustrate is that using websockets directly from ClojureScript is extremely straight forward. Let's start by creating a new Luminus project that we'll use as the base for our example. We'll create the project using the +http-kit profile:
lein new luminus multi-client-ws +http-kit +cljs
Once the application is created we'll need to startup the server and Figwheel. To do that, we'll need to run the following commands in separate terminals.
lein run
lein figwheel
The Server
Let's create a new namespace called multi-client-ws.routes.websockets and add the following references there:
(ns multi-client-ws.routes.websockets
(:require [compojure.core :refer [GET defroutes]]
[org.httpkit.server
:refer [send! with-channel on-close on-receive]]
[cognitect.transit :as t]
[taoensso.timbre :as timbre]))
Next, we'll create a Compojure route for our websocket handler:
(defroutes websocket-routes
(GET "/ws" request (ws-handler request)))
Where the ws-handler function will look as follows:
(defn ws-handler [request]
(with-channel request channel
(connect! channel)
(on-close channel (partial disconnect! channel))
(on-receive channel #(notify-clients %))))
The function accepts the request and passes it to the org.httpkit.server/with-channel macro provided by the HTTP Kit API. The macro creates accepts the request as its argument and binds the value of the :async-channel key to the second paramets representing the name of the channel. The statement following the channel name will be called once when the channel is created. In our case we'll call the connect! function defined below any time a new client connects:
(defonce channels (atom #{}))
(defn connect! [channel]
(timbre/info "channel open")
(swap! channels conj channel))
The function will log that a new channel was opened and add the channel to the set of open channels defined above.
When the client disconnects the on-close function will be called. This function accepts the channel along with a handler. The handler should accept the channel and the disconnect status. Our handler will log that the channel disconnected and remove it from the set of open channels.
(defn disconnect! [channel status]
(timbre/info "channel closed:" status)
(swap! channels #(remove #{channel} %)))
Finally, we have the on-receive function that's called any time a client message is received. We'll pass it the notify-clients function as the handler. This function will broadcast the message to all the connected clients.
(defn notify-clients [msg]
(doseq [channel @channels]
(send! channel msg)))
That's all we need to do to manage the lifecycle of the websocket connections and to handle client communication.
Next, We'll need to add the routes in our multi-client-ws.handler namespace:
(def app
(-> (routes
websocket-routes
(wrap-routes home-routes middleware/wrap-csrf)
base-routes)
middleware/wrap-base))
We will also have to update our multi-client-ws.middleware/wrap-base middleware wrapper to remove the wrap-formats middleware as it conflicts with handling websocket requests.
The Client
We'll start by creating a multi-client-ws.websockets in the src-cljs/multi_client_ws folder. The namespace will require the transit library:
(ns multi-client-ws.websockets
(:require [cognitect.transit :as t]))
Next, we'll define an atom to hold our websocket channel and a couple of helpers for reading and writing the JSON encoded transit messages.
(defonce ws-chan (atom nil))
(def json-reader (t/reader :json))
(def json-writer (t/writer :json))
We'll now create a function to handle received messages. The function will accept the callback handler and return a function that decodes the transit message and passes it to the handler:
(defn receive-transit-msg!
[update-fn]
(fn [msg]
(update-fn
(->> msg .-data (t/read json-reader)))))
We'll also create a function that sends messages to the socket if it's open:
(defn send-transit-msg!
[msg]
(if @ws-chan
(.send @ws-chan (t/write json-writer msg))
(throw (js/Error. "Websocket is not available!"))))
Finally, we'll add a function to create a new websocket given the URL and the received message handler:
(defn make-websocket! [url receive-handler]
(println "attempting to connect websocket")
(if-let [chan (js/WebSocket. url)]
(do
(set! (.-onmessage chan) (receive-transit-msg! receive-handler))
(reset! ws-chan chan)
(println "Websocket connection established with: " url))
(throw (js/Error. "Websocket connection failed!"))))
The UI
We'll now navigate to the multi-client-ws.core namespace and remove the code that's already there. We'll set the ns definition to the following:
(ns multi-client-ws.core
(:require [reagent.core :as reagent :refer [atom]]
[multi-client-ws.websockets :as ws]))
Next, we'll create an atom to keep a list of messages and a Reagent component that renders it:
(defonce messages (atom []))
(defn message-list []
[:ul
(for [[i message] (map-indexed vector @messages)]
^{:key i}
[:li message])])
We'll now create a message-input component that will allow us to type in a message and send it to the server. This component creates a local atom to keep track of the message being typed in and sends the message to the server when the enter key is pressed.
(defn message-input []
(let [value (atom nil)]
(fn []
[:input.form-control
{:type :text
:placeholder "type in a message and press enter"
:value @value
:on-change #(reset! value (-> % .-target .-value))
:on-key-down
#(when (= (.-keyCode %) 13)
(ws/send-transit-msg!
{:message @value})
(reset! value nil))}])))
We can now create the home-page component that looks as follows:
(defn home-page []
[:div.container
[:div.row
[:div.col-md-12
[:h2 "Welcome to chat"]]]
[:div.row
[:div.col-sm-6
[message-list]]]
[:div.row
[:div.col-sm-6
[message-input]]]])
We'll also create an update-messages! function that will be used as the handler for the received messages. This function will append the new message and keep a buffer of 10 last received messages.
All that's left to do is mount the home-page component and create the websocket in the init! function:
(defn mount-components []
(reagent/render-component [#'home-page] (.getElementById js/document "app")))
(defn init! []
(ws/make-websocket! (str "ws://" (.-host js/location) "/ws") update-messages!)
(mount-components))
We should now be able to open multiple browser windows and any messages typed in one window should show up in all the open windows.
Conclusion
As you can see, it's very easy to setup basic client-server communication between HTTP Kit and ClojureScript. While you may wish to use one of the libraries mentioned earlier for more sophisticated apps, it's certainly not necessary in many cases. The complete source for the example can be found on GitHub.
First, I'd like to thank all those who purchased the first edition of the book. I was overwhelmed by the response from the readers, and exhilirated to learn that it helped many start developing their web applications using Clojure. I'm excited to announce that I'm working on the second edition of Web Development with Clojure and that I'm expecting to publish it sometime this summer.
What to Expect
The main goal of the book is to provide a no-nonsense introduction to web development using Clojure. As such, I chose to cover tools and libraries that I consider to be beginner friendly.
Clojure web ecosystem has been steadily maturing since the release of the first edition. Last time I illustrated a number of approaches for putting applications together without recommending any one in particular over the others. This time around I'm primarily focusing on building application based on the Luminus stack. Luminus has recently seen a major update and continues to provide a solid foundation for building Clojure web applications according to best practices.
Clojure community favors using composable libraries over monolithic frameworks. This approach offers a number of advantages by giving the developer full control over the structure of the application the components used in it.
However, this approach works best for experienced developers who have a good understanding of the ecosystem and the available libraries. Having to develop this experience presents a significant barrier for newcomers. Luminus mitigates this issue by providing a batteries included template coupled with centralized documentation. This makes it a perfect foundation for a book aimed at beginners.
If you're familiar with the Clojure basics and you're looking to apply it for building web applications then this book is for you. The book aims to provide the reader with the understanding of the core ecosystem and the available tooling.
What's New
Those who are familiar with the first edition will find a number of changes and a number of new topics covered this time around.
At the time of writing of the first edition I felt that ClojureScript was not quite ready for general consumption. While some companies were already using it in production, the tooling around it was often challenging to use. As such, the book only gave it a very brief introduction and focused on traditional server side templating instead.
ClojureScript has matured greatly in the past year and the tooling is rapidly improving, while libraries such as Om and Reagent provide a clear benefit over using plain JavaScript. This time around ClojureScript is front and center with a primary focus on building single page apps using the Reagent library. I chose Reagent over Om for reasons I've discussed here. In short, I find that it's much easier to learn and apply effectively. The main project in the book that guides the reader through developing a multi-user picture gallery application is now developed as a single page application using Reagent.
Another major change is that I no longer recommend using lib-noir for developing new applications. While the library provides a number of helpers for achieving many common tasks found in typical web applications, it also introduces some problems inherent in its design. I've discussed some of these in my last post. Today, there are excellent standalone libraries available for each of the tasks that lib-noir was used for and I recommend using these instead.
The database chapter has been updated to introduce the excellent Yesql library and use the syntax of the latest version of clojure.java.jdbc.
I’m now covering the use of the compojure-api library along side Liberator. I’ve had an excellent experience using this library and I highly recommend trying it out if you haven’t already. The library uses Prismatic/schema to define the service API and allows automatic generation of interactive Swagger documentation such as seen here.
Finally, the book will provide more information on topics such as database migrations and deployment as part of addressing some of the feedback from the previous edition.
My hope is that the book will be useful to both new readers as well as those who purchased the first edition.
Announcing Luminus 2.0
(iterate think thoughts) 28 02 2015
I'm excited to announce the release of Luminus 2.0. This release is a major update and introduces a number of changes to the framework. These changes reflect the evolution of the Clojure web stack and best practices over the past year.
The biggest change is that Luminus is no longer using lib-noir, nor will I be actively developing the library going forward. I intend to continue maintaining it and to provide bug fixes, but I will not be working on additional features. If anybody is interested in taking it over then please leave a comment on GitHub in that regard.
I believe that lib-noir has served an important role providing many useful features such as input validation, access rules, session handling and so on. However, today there are great standalone libraries available for accomplishing each of these tasks. I believe that using simple and focused libraries leads to better overall user experience. The libraries that Luminus currently defaults to are as follows:
- access rules - Buddy
- cache - core.cache
- crypto - Buddy
- database - Yesql
- sessions/cookies - Ring
- validation - Bouncer
Session management is the biggest change from the user perspective. While lib-noir uses a request bound session that can be manipulated anywhere within the scope of the request, Ring requires sessions to be associated with the response explicitly by the handler.
While lib-noir approach is unquestionably convenient it introduces a subtle problem. Since the session is bound to a thread-local variable it's possible to run into race conditions with the in-memory session store. I feel that the Ring approach results in simpler design that’s more explicit about what it’s doing.
The new middleware stack is now based on ring-defaults instead of the app-handler from lib-noir as Noir specific middleware is no longer required.
The move from Korma to Yesql is another major change. While Korma provides a nice DLS for working with SQL, I feel that the sheer simplicity of Yesql is preferable in the long run.
Meanwhile, Buddy is an exciting set of libraries for handling authorization, authentication, and access rules. It has an intuitive API and excellent documentation.
Bouncer is an excellent validation library that works with both Clojure and ClojureScript allowing for shared validation logic between the server and the client.
Some other changes include the +cljs profile updates for Figwheel support and the deprecation of the +site profile. It's been replaced with the +auth profile that sets up Buddy middleware for session based authentication instead.
As always, the framework primarily strives to remove the boilerplate from typical web projects and provide reasonable defaults. If you don’t agree with any of the library choices that it makes it’s trivial to swap them out with your own. The base profile is intentionally kept minimal to provide an unopinionated default.
The template project for Luminus has been completely rewritten as well. The new template cleanly separates different profiles making it much easier to maintain and add new features.
Finally, all the documentation has been updated to reflect the changes with the original made available on GitHub.
In this post we’ll see how to create a simplistic plugin system where plugins can be supplied as Leiningen dependencies and automatically initialized without any additional code change in the application.
Let’s take a look at Cryogen for a concrete example of how this can be useful. Cryogen started out using Markdown for content encoding, and we recently got a pull request that adds AsciiDoc support.
It’s always great to get additional features, but sometimes features also carry an undesirable cost. It turns out that AsciiDoc support relies on AsciidoctorJ, that in turn relies on JRuby and pulls in a huge amount of additional dependencies. This has a significant impact on the startup time of the application.
For anybody who isn’t using AsciiDoc the new feature simply degrades the user experience. So, ideally we’d like to keep AsciiDoc as a feature, but also avoid impacting users who aren’t using it. The ideal scenario is to be able to split out the parsers into standalone libraries and include the ones we need. This also has the benefit of people being able to write their own custom plugins that add the features they need without having to update the core project.
The approach I took here was to create an init function for each plugin that will take care of any initialization that the plugin needs to do and register it with the system.
All the available parsers are stored in an atom called markup-registry in cryogen-core, and each plugin simply updates the registry when it loads:
(defn init []
(swap! markup-registry conj (markdown)))
The full code for the Markdown plugin can be seen here.
Next, we need to make our plugins discoverable so that they can be loaded when the application starts. This can be done using a configuration file that can be found on a classpath. Cryogen plugin configuration is stored in resources/plugin.edn using the following format:
{:description "Markdown parser"
:init cryogen-markdown.core/init}
Using the above information we can load the appropriate namespace and run the initializer function for the plugin.
First, we need to grab all the resources with the name plugin.edn which can done as follows:
(defn load-plugins []
(let [plugins (.getResources (ClassLoader/getSystemClassLoader) "plugin.edn")]
(loop []
(load-plugin (.. plugins nextElement openStream))
(when (.hasMoreElements plugins)
(recur)))))
Next, we read the configuration for each resource, require its namespace and then run the initializer functions as seen below:
(defn load-plugin [url]
(let [{:keys [description init]} (edn/read-string (slurp url))]
(println (green (str "loading module: " description)))
(-> init str (s/split #"/") first symbol require)
((resolve init))))
With that in place we simply run load-plugins when the applicatin starts and any plugins found on the classpath will be initialized. All the user has to do is select what plugins they want to include in their dependencies to get the functionality they need.
The State of Reagent
(iterate think thoughts) 01 12 2014
I'm happy to report that Dan Holmsand has graciously agreed to move Reagent to a GitHub Organization called the reagent-project. The organization will help spread the work as well as provide a hub for all the related projects. There has been a lot of recent interest in the org and several projects have already migrated under the umbrella.
First, I'd like to mention the reagent-cookbook project that provides many recipes for accomplishing common tasks, such as Js library integration, using Reagent. The project provides clear and simple guidelines for contributing to help ensure that all recipes have a common format that's easy to follow. Next addition is the Historian project that provides drop-in undo/redo functionality for Reagent. World Singles has recently switched from Om to Reagent and Sean Corfield has added reagent-cursor library for Om-like cursor support in the process. Finally, there is my own reagent-forms library for creating data bindings using Reagent.
New Reagent projects can now be easily created and run using the reagent-template as follows:
lein new reagent my-app
cd my-app
lein cljsbuild auto &
lein ring server
The template will generate a Clojure/Clojurescript web app that's designed to get you up and running without any tedious setup. The resulting project is setup to use Figwheel for live code reloading and weasel for the REPL enabling smooth development out of the box.
The template uses sane library and configuration choices across the stack with Reagent for the UI, Secretary for client side routing, and the Ring/Compojure stack on the backend.
The dev server and packaging are handled by lein-ring that will take care of reloading changes during development and producing either an uberjar or an uberwar for running standalone or deploying to a container respectively. The project also contains a Procfile for instant Heroku deployment. For more details, please visit the project page here.
As you can see, much has happened with Reagent in the past month and the future is looking very bright. If you haven't tried Reagent yet, there's never been a better time than now. :)
Moving to Cryogen
(iterate think thoughts) 26 11 2014
The blog has officially been moved over to Cryogen. While, all the content has been migrated over, the links for the posts have changed and the original comments are no longer available since I'm now using Disqus.
Yuggoth was a fun experment and it held up to most traffic storms over the years, but at the end of the day it's hard to beat the simplicity of a static site.
Porting the content from my old blog turned out to be a simple affair. I used Postgres to store all the blog content in Yuggoth. The database contains tables for the posts, the comments, the tags, and the files. All I had to do was extract the data and write it back out using the Cryogen format. First, I extracted the binary data for the files as seen below.
(defn write-file [{:keys [data name]}]
(with-open [w (clojure.java.io/output-stream
(str "resources/templates/files/" name))]
(.write w data)))
(defn extract-files []
(doseq [file (sql/query db ["select * from file"])]
(write-file file)))
The posts table contains the content, while the tags are stored in a separate table. The tags can be aggregated by post using the handy array_agg function. This function will produce a Jdbc4Array as the result, and its contents can then be extracted to a vector.
(defn extract-tags [post]
(update-in post [:tags] #(vec (.getArray %))))
(defn get-posts []
(map extract-tags
(sql/query db
["select array_agg(t.tag) as tags,
b.id, b.time, b.title, b.content from blog b, tag_map t
where t.blogid = b.id
group by b.id, b.time, b.title, b.content"])))
Now, all that's left to do is to generate the post metadata and the file name. Since each post contains a publication date and a title, these can be used to produce a filename in the format expected by Cryogen.
(defn format-post-date [date]
(let [fmt (java.text.SimpleDateFormat. "dd-MM-yyyy")]
(.format fmt date)))
(defn format-post-filename [time title]
(str
(->> (re-seq #"[a-zA-Z0-9]+" title)
(clojure.string/join "-")
(str "resources/templates/md/posts/" (format-post-date time) "-"))
".md"))
With that in place we can simply run through all the posts and extract them into appropriate files.
(defn write-post [{:keys [id time tags content title]}]
(with-open [wrt (clojure.java.io/writer (format-post-filename time title))]
(.write wrt
(with-out-str
(clojure.pprint/pprint
{:title title
:layout :post
:tags (vec (.split tags " "))})))
(.write wrt "\n")
(.write wrt content)))
(defn extract-posts []
(doseq [post (get-posts)]
(write-post post)))
And that's all there is to it. Moral of the story is that we should always keep the data separate from its representation as you never know when you will need it down the road.
Cryogen is a new Clojure static site generator by Carmen La. Since there are already many popular site generators such as Jekyll, let's take a look at what makes Cryogen interesting.
In my opinion, the main feature of this project is its simplicity. Cryogen is shipped as a Leiningen template and all you have to do to create a site is run:
lein new cryogen my-blog
This will create an instance of the project with a template site initialized. The site can be run in dev mode using:
lein ring server
Once started, a helpful readme is shown on what to do next, which is a really nice touch.
The server will watch for changes in the resources/templates folder and recompile the site whenever updates are detected. The compiled site is served from resources/public. The static assets generated there can now be copied to over to be served by Nginx or Apache in production.
The layout is handled using Selmer templates, while the content of the posts and the pages is written using Markdown with the help of markdown-clj.
The generator handles all the common things like linking up pages, creating tags, syntax highlighting, sitemap, and RSS our of the box.
While most site generators take the approach of providing numerous configuration options for customization, Cryogen simply gives you the code to customize any way you see fit. You can simply go to the cryogen.compiler namespace and easily change its behaviour to fit whatever it is you're doing. The compiler code is very clean and easy to follow, making it easy to customize.
I definitely recommend taking a look at this project if you're looking to make a static site in the future.
Clojure Cup Results
(iterate think thoughts) 08 10 2014
Clojure Cup results are in and you can see the winning entries here. Kudos to all the teams who participated in the event!
It was exciting to see a wide variety of ideas explored during the event as well as the number of projects that were taken to completion. It's extremely impressive to see the kinds of Clojure apps that can be built from scratch in just a couple of days.
The scope of the competition clearly grew from last year, the prizes were bigger, the teams were larger, and the projects were more ambitious. One major change that I noticed was that a lot more projects were using ClojureScript and many of these used Om and Reagent to build the UI. It's great to see ClojureScript taking off and bringing some sanity to the world of front-end development.
Overall, I think it was an exciting event and I highly recommend browsing through the apps. Many of the projects are hosted on GitHub and it's worth exploring the code to learn some new tricks. :)
I can't wait to see what Clojure Cup 2015 will bring.
A little while back Chris Allen discovered the joys of Haskell. We had a few discussions regarding the merits of static typing and whether Haskell would be a more productive language than Clojure.
Haskell was my first foray into functional programming, and it's the language that made me fall in love with it. However, I also found that non-trivial type relationships would often require a lot of mental gymnastics. Eventually, I ended up moving to Clojure as I realized that I was simply more productive in it.
Chris would have none of this, and repeatedly told me that I was simply lying about having tried Haskell, since nobody could possibly enjoy using a dynamic language after seeing the glory of HM type inference.
These sorts of debates are rather tiring, so instead I proposed that Chris would translate a small piece of Clojure code to Haskell. Then we could discuss the merits of each approach using a concrete example.
On December of 2013, I posted this gist and while it's not trivial, it weighs in at about 70 lines of code. It's a minimal example where I find Haskell starts making things unnecessarily difficult.
The code runs through a stream and looks for either {{...}} or {% if ... %} tags. It is intentionally kept short to limit noise, so it simply reads the tag names and prints them out. Since the code is a dumbed down version of Selmer, which Chris participated on writing, I assumed he would have little difficulty reading and translating it.
To my surprise he started making excuses that if he did translate it then it would give me ammunition to complain about Haskell being difficult. I think that's a rather strange argument to make for somebody making the case that Haskell makes things simpler.
Then he said he'd do it using the Parsec library, which obviously defeats the point. The question is not whether you can figure out a library API in Haskell, but how would you translate specific piece of Clojure code to Haskell.
The power of Clojure is that it allows me to solve hard problems instead of having to rely on somebody else to write libraries that do the hard stuff and then glue them together.
At this point Chris proceeded to ignore the request for over half a year, until he suddenly decided to start messaging me about it on Twitter last night. All of a sudden he couldn't wait a second more and what's more apparently my code was broken! As he so eloquently put it "@yogthos broken software in a unityped language...whodathunkit...". He proceeded to berate me and insisted that the code does not work, that I'm a liar for suggesting that it does, and he must make a blog post regarding this situation immediately.
I was surprised to hear this as I clearly recall the parser example working last I touched it. Since there was no reason to change it, I was fairly confident that it would be in working order. However, not having access to a computer at the time I could not check it myself.
Normally, if an individual contacts me respectfully I would be glad to help and work with them to figure out what the problem is. I make mistakes, we all do, and it's conceivable that there might've been a problem with my code. The approach Chris chosen was frankly insulting.
I explained to Chris that I was not at a computer and I can't look at the code, but evidently the blog post simply could not wait. You can read it in full here.
The problem turned out to be that Chris is apparently incapable of reading code. The parser gets initialized with the render-file function:
(defn render-file [filename args]
(render (parse filename) args))
This function calls the parse function on the filename and then passes the parsed content to render. Chris tried to call render with:
(parser/render "Hello {{name}}!" {:name "Yogthos"})
Shockingly enough he got an error doing that, at this point he evidently was incapable figuring out on his own what was causing the error and proceeded to throw a tantrum on Twitter.
Of course, if the goal was to actually figure out what the problem was then one would at least look at what parse is doing:
(defn parse [file]
(with-open [rdr (clojure.java.io/reader file)]
Then it would immediately become obvious that we must pass in something that can be read by clojure.java.io/reader, such as java.io.StringBufferInputStream, and then pass the result of parse to render. Naturally, when called correctly the code does exactly what it's supposed to:
(render
(parse
(java.io.StringBufferInputStream. "Hello {{name}}"))
{:name "Yogthos"})
=>"Hello filter tag value: name"
Since Chris managed to run the render-file function as seen in one the snippets in his blog post, he doesn't seem to understand that I asked him to translate that code to Haskell. For whatever reason, he includes a screenshot of Selmer documentation, which is not the behavior of the parser and was never intended to be. The spec that Chris was asked to translate to Haskell is the code in the gist.
In his post, Chris went ahead and answered the question he would like to have been asked as opposed to the one he was actually asked. I suppose making a straw man is a lot easier than answering the original question.
What I learned from this experience is that some Haskell users like to talk a lot about their favorite language, but when asked to solve a simple problem they will do anything but that. I don't find that to be terribly convincing myself.
There are already lots of guides introducing Clojure syntax and many of its features, but these guides tend to focus on individual examples as opposed to the broad concepts behind the language.
In my experience, the difficulty in learning Clojure doesn't stem from the syntax, but from having to approach problems with a new mindset. The goal of this guide is to impart such a mindset on the reader. How badly I fail at this task remains to be seen. :P
Without further ado, here's the guide itself, and I hope you'll find it useful if you're starting out with Clojure.
I recently discovered that Light Table REPL works with ClojureScript without the need for any specific setup in your project. All you need is the lein-cljsbuild plugin to run the incremental compiler and follow the steps below:
- start the ClojureScript compiler using
lein cljsbuild auto - start the server using
lein ring server - open the Light Table browser connection to the server
- navigate to a ClojureScript namespace in your project and start evaluating expressions
I tried other ClojureScript REPL setups before and I always found the process extremely fiddly, with Light Table everything just worked out of the box. I definitely recommend giving it a shot if you haven't yet, especially if you're working with ClojureScript.
No REST for the whippet
Blogs on Tom Spencer 16 09 2014
No REST for the whippet
Blogs on Tom Spencer 16 09 2014
One thing I’ve always found to be particularly tedious is having to create data bindings for form elements. Reagent makes this much more palatable than most libraries I’ve used. All you need to do is create an atom and use it to track the state of the components.
However, creating the components and binding them to the state atom is still a manual affair. I decided to see if I could roll this into a library that would provide a simple abstraction for tracking the state of the fields in forms.
The usual way to bind inputs to atoms as illustrated in the official Reagent docs can be seen below:
(ns example
(:require [reagent.core :as reagent :refer [atom]]))
(defn atom-input [value]
[:input {:type "text"
:value @value
:on-change #(reset! value (-> % .-target .-value))}])
(defn shared-state []
(let [val (atom "foo")]
(fn []
[:div
[:p "The value is now: " @val]
[:p "Change it here: " [atom-input val]]])))
We create an atom with some state and then pass it to our input component. The component will display the current value and update the state when its :on-change event is triggered.
Normally, we’d have to go through each field in the form and pass the state to it so that it can bind itself to the document we’re generating.
I wanted to be able to specify a template for a form and then pass the entire template to a function that would take care of binding all the fields to an atom representing the document.
This function would need to know what parts of the form need to be bound, how to bind each type of element, and how to uniquely identify it in the document.
My solution was to introduce the :field attribute that would identify the component as a form field, and to use the :id attribute as the unique key for the element.
The binding function would then walk the form and check for any component that contain the :field key in its attribute map. The key would point to the type of component such as text, numeric, list, and so on.
Then it could pass the component to a specific binding function that would be responsible for linking the field with the document and return a bound component. Let’s take a look at how this all works with an example.
We’ll first need to include the library in our project `[reagent-forms "0.1.3"] , then we’ll require the reagent-forms.core/bind-fields` function in our namespace:
(ns myform.core
(:require [reagent-forms.core :refer [bind-fields]])
Next, we need to create a form template to represent our form:
(defn row [label input]
[:div.row
[:div.col-md-2 [:label label]]
[:div.col-md-5 input]])
(def form-template
[:div
(row "first name" [:input {:field :text :id :person.first-name}])
(row "last name" [:input {:field :text :id :person.last-name}])
(row "age" [:input {:field :numeric :id :person.age}])
(row "email" [:input {:field :email :id :person.email}])
(row "comments" [:textarea {:field :textarea :id :comments}])])
Note that we call helper functions, such as row, eagerly. The bind-fields function will walk the template to construct the actual components that will be used by Reagent.
The . in the :id key indicates nested structure. When we have a key like :person.first-name, then its value will be stored under {:person {:first-name <field-value>}}.
Our form component will then create an atom to represent the document and bind it to the template to produce the actual form:
(defn form []
(let [doc (atom {})]
(fn []
[:div
[:div.page-header [:h1 "Reagent Form"]]
[bind-fields form-template doc]
[:label (str @doc)]])))
That’s all there is to it. Whenever the state of any of the components changes the doc atom will be updated and vice versa.
The bind-fields function also accepts optional events. Events are triggered whenever the document is updated, and will be executed in order they are listed. Each event sees the document modified by its predecessor. The event must take 3 parameters, which are the id, the value, and the document.
The id and the value represent the value that was changed to trigger the event, and the document is the atom that contains the state of the form. Note that the id is in form of a vector representing the path in the document. The event can either return an updated document or nil, when nil is returned then the state of the document is unmodified. The following is an example of an event to calculate the value of the :bmi key when the :weight and :height keys are populated:
(defn row [label input]
[:div.row
[:div.col-md-2 [:label label]]
[:div.col-md-5 input]])
(def form-template
[:div
[:h3 "BMI Calculator"]
(row "Height" [:input {:field :numeric :id :height}])
(row "Weight" [:input {:field :numeric :id :weight}])
(row "BMI" [:input {:field :numeric :id :bmi :disabled true}])])
[w/bind-fields
form-template
doc
(fn [[id] value {:keys [weight height] :as doc}]
(when (and (some #{id} [:height :weight]) weight height)
(assoc-in doc [:bmi] (/ weight (* height height)))))]
The library provides support for a number of common fields such as inputs, checkboxes, radio buttons, lists, and multi-selects. However, it also makes it easy to add your own custom fields by implementing the reagent-forms.core/init-field multimethod.
The method must take two parameters, where the first parameter is the field component and the second is the options map. The options contain two keys called get and save!. The get key points to a function that accepts an id and returns the document value associated with it. The save! function accepts an id and a value that will be associated with it. Let’s take a look at the :radio field implementation as an example:
(defmethod init-field :radio
[[type {:keys [field id value] :as attrs} & body]
{:keys [get save!]}]
(let [state (atom (= value (get id)))]
(fn []
(into
[type
(merge {:type :radio
:checked @state
:class "form-control"
:on-change
#(do
(save! id value)
(reset! state (= value (get id))))}
attrs)]
body))))
As you can see, the method simply returns a new component that’s bound to the supplied id in the document. For more details please see the documentation on the project page.
The library is still rather new and as such has some rough edges, such as poor error reporting. However, I already find it to be quite useful in my own projects.
File Snooping
(iterate think thoughts) 17 08 2014
I recently needed to watch files for changes and had a chance to play around with using the WatchService functionality in JDK 7. As is generally the case with Java, the API requires you to jump through a number of hoops to do anything, but turns out that it’s possible to wrap it up into something reasonable in the end.
The WatchService can be used to watch directories and provides different types of events, such as create, modify, delete, and overflow. The first three are self-explanatory and the last is a special event that’s triggered when an event might have been discarded or lost.
What we’d like to do is create a function called watch that accepts an input path along with event handlers for each of the above events.
To create a watcher we first need to get an instance of a Path. To do that we have to call (-> path (file) (.toURI) (Paths/get)). Next, we can get an instance of the WatchService by calling (.newWatchService (FileSystems/getDefault))
Now that we have a Path and a WatchService, we can register the service with the path to listen for the events we specify.
To handle this, I ended up creating a map with the keys representing the events and the values being the event handling functions.
{:create event-handler
:modify event-handler}
When the event is triggered we will receive an instance of the WatchEvent. So, the handler functions should accept it as the parameter.
(defn event-handler [event]
(println (.kind event) (.context event)))
Next, I created a couple of helpers to map the keywords to the appropriate events:
(defn register-events! [dir watch-service opts]
(.register dir watch-service
(-> opts
(select-keys [StandardWatchEventKinds/ENTRY_CREATE
StandardWatchEventKinds/ENTRY_MODIFY
StandardWatchEventKinds/ENTRY_DELETE
StandardWatchEventKinds/OVERFLOW])
(keys)
(into-array))))
(defn rename-event-keys [opts]
(rename-keys opts
{:create StandardWatchEventKinds/ENTRY_CREATE
:modify StandardWatchEventKinds/ENTRY_MODIFY
:delete StandardWatchEventKinds/ENTRY_DELETE
:overflow StandardWatchEventKinds/OVERFLOW}))
The transformed map is now ready for use. The WatchService implements closeable, so we can use the with-open macro to manage it:
(defn watch [path opts]
(let [dir (-> path (file) (.toURI) (Paths/get))
opts (rename-event-keys opts)]
(with-open [watch-service
(.newWatchService (FileSystems/getDefault))]
(register-events! dir watch-service opts)
(watch-loop watch-service opts))))
The watch function will register the events we passed in, open the watch service and then call the watch-loop function to do the actual watching.
(defn watch-loop [watch-service opts]
(loop []
(let [k (.take watch-service)]
(doseq [event (.pollEvents k)]
(if-let [handler (get opts (.kind event))]
(handler event)))
(when (.reset k) (recur)))))
The watch-loop starts each iteration by calling take on the watch service. This method blocks until it receives an event, the service is closed or it’s interrupted.
Once we receive an event we can look it up in our options map and call the handler for the event. Finally, we need to call reset on the key before we start the next iteration.
Since the take function blocks, we probably want to run it in a thread:
(defn start-watcher! [path opts]
(doto (Thread. #(watch path opts))
(.setDaemon true)
(.start)))
The above will start a background watcher thread and return it. The thread is daemonized, so that it doesn’t prevent the application from exiting. Example usage for the above can be to track when files are created or modified in the directory:
(start-watcher! “~/downlads”
{:create #(println “file created” (-> % (.context) (.toString)))
:modify #(println “file modified” (-> % (.context) (.toString)))})
That’s all there is to it and the full source for the example can be seen here.
Update
As one of the comments points out, JDK will poll on OS X and the default poll interval is quite large. In order to get around this we can force high sensitivity when we register the WatchService as follows:
(defn register-events! [dir watch-service]
(.register dir
watch-service
(into-array
[StandardWatchEventKinds/ENTRY_CREATE
StandardWatchEventKinds/ENTRY_MODIFY
StandardWatchEventKinds/ENTRY_DELETE
StandardWatchEventKinds/OVERFLOW])
(into-array
[(com.sun.nio.file.SensitivityWatchEventModifier/HIGH)])))
Routing With Secretary
(iterate think thoughts) 14 08 2014
In the last post, we looked at using Reagent for building single page apps. The example app contained a single page with a form in it, which isn't terribly exciting as far as single page apps go.
In this post we’ll see see how to create an app with multiple pages and how we can route between them using the secretary library.
The app will be a guestbook with a page that shows a list of users and another page that allows new users to sign in. We’ll use the project from the last post as the base for this tutorial.
update the tutorial has been updated to the latest version of Luminus, you'll need to create a new project to follow along using lein new luminus guestbook +cljs
First thing that we have to do is to add the [secretary "1.2.3"] dependency to our project.clj. Next, let’s refactor our namespaces in src/cljs as follows:
src
└ cljs
└ guestbook
└ core.cljs
└ pages
└ guest.cljs
└ guest_list.cljs
- The
corenamespace will act as the entry point for the client. - The
sessionwill house the global state of the application. - The
guestnamespace will house the sign-in form. - The
guest-listnamespace will display the guests.
Since we refactored the namespaces we’ll also need to update our app.html template to reflect that.
<script type="text/javascript">goog.require("guestbook.core");</script>
Session Management
In our example, the session will track the currently selected page and the saved documents.
We’ll use the reagent-utils session. The session is simply a Ragent atom with some helper functions around it.
Listing Guests
Let’s open up the guest-list namespace and add the following code there.
(ns guestbook.pages.guest-list
(:require [reagent.session :as session]
[clojure.string :as s]
[reagent.core :as reagent :refer [atom]]
[secretary.core :refer [dispatch!]]))
(defn guest-list-page []
[:div
[:div.page-header [:h2 "Guests"]]
(for [{:keys [first-name last-name]}
(session/get :guests)]
[:div.row
[:p first-name " " last-name]])
[:button {:type "submit"
:class "btn btn-default"
:on-click #(dispatch! "/sign-in")}
"sign in"]])
The namespace will contain a page that lists the guests that are currently in the session. The “sign in” button on the page uses the dispatch! function in order to route to the “/sign-in” page.
Adding Routes
The core namespace will specify the list of routes and provide an init! function to set the current page and render it when the application loads.
(ns guestbook.core
(:require [reagent.core :as r]
[reagent.session :as session]
[secretary.core :as secretary :include-macros true]
[goog.events :as events]
[goog.history.EventType :as HistoryEventType]
[guestbook.ajax :refer [load-interceptors!]]
[guestbook.pages.guest-list
:refer [guest-list-page]]
[guestbook.pages.guest :refer [guest-page]])
(:import goog.History))
(defn page []
[(session/get :current-page)])
;; -------------------------
;; Routes
(secretary/set-config! :prefix "#")
(secretary/defroute "/" []
(session/put! :current-page guest-list-page))
(secretary/defroute "/sign-in" []
(session/put! :current-page guest-page))
;; -------------------------
;; History
;; must be called after routes have been defined
(defn hook-browser-navigation! []
(doto (History.)
(events/listen
HistoryEventType/NAVIGATE
(fn [event]
(secretary/dispatch! (.-token event))))
(.setEnabled true)))
;; -------------------------
;; Initialize app
(defn mount-components []
(r/render [#'page] (.getElementById js/document "app")))
(defn init! []
(load-interceptors!)
(hook-browser-navigation!)
(mount-components))
As we can see above, secretary uses Compojure inspired syntax that should look very familiar to anybody who's dabbled in Clojure web development.
In our case the routes will simply set the appropriate page in the session when called. The render function will then be triggered by the atom update and render the page for us.
Signing In
Finally, we’ll add the sign-in form in the guest namespace. The page will keep its local state in an atom and update the session using the callback handler in the save-doc function.
Note that we don’t have to do anything else to update the list of guests once the callback completes. Since the session atom has been updated, it will trigger the guest list to repaint with the new elements.
I found that this behavior largely obviates the need to use core.async since the Reagent atom can act as a sync point between the view and the model. It also makes it trivial to implements the React Flux pattern.
Views--->(actions) --> Dispatcher-->(callback)--> Stores---+
Ʌ |
| V
+--(event handlers update)--(Stores emit "change" events)--+
Our view components dispatch updates to the atoms, which represent the stores. The atoms in turn notify any components that dereference them when their state changes.
Using get/set! functions to access the atoms, as we’re doing in this example, allows us to easily listen for changes and hook in event handlers.
(ns guestbook.pages.guest
(:refer-clojure :exclude [get])
(:require [reagent.session :as session]
[reagent.core :as reagent :refer [atom]]
[secretary.core :refer [dispatch!]]
[ajax.core :refer [POST]]))
(defn put! [doc id value]
(swap! doc assoc :saved? false id value))
(defn get [doc id]
(id @doc))
(defn row [label & body]
[:div.row
[:div.col-md-2 [:span label]]
[:div.col-md-3 body]])
(defn text-input [doc id label]
[row label
[:input {:type "text"
:class "form-control"
:value (get doc id)
:onChange #(put! doc id (-> % .-target .-value))}]])
(defn save-doc [doc]
(POST "/save"
{:params (dissoc @doc :saved?)
:handler
(fn [_]
(put! doc :saved? true)
(session/update-in! [:guests] conj @doc)
(dispatch! "/"))}))
(defn guest-page []
(let [doc (atom {})]
(fn []
[:div
[:div.page-header [:h1 "Sign In"]]
[text-input doc :first-name "First name"]
[text-input doc :last-name "Last name"]
(if (get doc :saved?)
[:p "Saved"]
[:button {:type "submit"
:class "btn btn-default"
:on-click #(save-doc doc)}
"Submit"])
[:button {:type "submit"
:class "btn btn-default"
:on-click #(dispatch! "/")} "back"]])))
The form code on this page is based on the previous tutorial and should hopefully be self explanatory at this point.
Hooking in Browser Navigation
As a final touch, we can add support for managing history using goog.events to enable more intelligent navigation using the browser.
(ns guestbook.core
(:require [reagent.session :as session]
[guestbook.pages.guest-list
:refer [guest-list-page]]
[guestbook.pages.guest :refer [guest-page]]
[reagent.core :as reagent :refer [atom]]
[secretary.core :as secretary
:include-macros true :refer [defroute]]
[goog.events :as events]
[goog.history.EventType :as EventType]))
(defn hook-browser-navigation! []
(doto (History.)
(events/listen
EventType/NAVIGATE
(fn [event]
(secretary/dispatch! (.-token event))))
(.setEnabled true)))
The function is then run by the init! function when the app loads:
(defn init! []
(load-interceptors!)
(hook-browser-navigation!)
(mount-components))
As usual, the source for the project can be found here.
Final Thoughts
The example in this post is intentionally kept trivial, but hopefully it illustrates a simple way to hook up multiple pages and navigate between them using Reagent and secretary.
I recently rewrote this blog engine to use Reagent and I found that it made the code much cleaner and easier to maintain. I think one of the main benefits of the single page approach is that it enforces a clear separation between the server and the client portions of the application.
If you’d like to see a complete application built using the approach discussed here, don’t hesitate to take a look at the code behind this blog.
Transducers are Coming
Clojure News 06 08 2014
Transducers are a powerful and composable way to build algorithmic transformations that you can reuse in many contexts, and they’re coming to Clojure core and core.async.
Two years ago, in a blog post describing how reducers work, I described the reducing function transformers on which they were based, and provided explicit examples like mapping, filtering and mapcatting. Because the reducers library intends to deliver an API with the same 'shape' as existing sequence function APIs, these transformers were never exposed a la carte, instead being encapsulated by the macrology of reducers.
In working recently on providing algorithmic combinators for core.async, I became more and more convinced of the superiority of reducing function transformers over channel→channel functions for algorithmic transformation. In fact, I think they are a better way to do many things for which we normally create bespoke replicas of map, filter etc.
So, reducing function transformers are getting a name - transducers, and first-class support in Clojure core and core.async.
What’s a Transducer?
To recap that earlier post:
A reducing function is just the kind of function you’d pass to reduce - it takes a result so far and a new input and returns the next result-so-far. In the context of transducers it’s best to think about this most generally:
;;reducing function signature
whatever, input -> whateverand a transducer is a function that takes one reducing function and returns another:
;;transducer signature
(whatever, input -> whatever) -> (whatever, input -> whatever)The primary power of transducers comes from their fundamental decoupling - they don’t care (or know about):
-
the 'job' being done (what the reducing function does)
-
the context of use (what 'whatever' is)
-
the source of inputs (where input comes from).
The other source of power comes from the fact that transducers compose using ordinary function composition.
The reducers library leverages transducers' decoupling from the job, the representation, and the source of inputs to accomplish parallel reduction. But transducers can also be used for:
-
a la carte laziness
-
transformations during collection building
-
collection/iteration/laziness-free transforming reductions
-
channel transformations, event notifications and more.
All of this is coming to Clojure core and core.async.
New stuff
Concretely, most of the core sequence functions are gaining a new arity, one shorter than their current shortest, which elides the final collection source argument. This arity will return a transducer that represents the same logic, independent of lazy sequence processing.
Thus:
;;look Ma, no collection!
(map f)returns a 'mapping' transducer. filter et al get similar support.
You can build a 'stack' of transducers using ordinary function composition (comp):
(def xform (comp (map inc) (filter even?)))You might notice the similarity between the above comp and a call to →>:
(->> aseq (map inc) (filter even?))One way to think of transducers is like →> but independent of the job (lazy sequence creation) and the source of inputs (aseq).
Transducers in action
Once you’ve got a transducer, what can you do with it? An open set of things.
For instance, given the above transducer and some data in a vector, you can:
-
lazily transform the data (one lazy sequence, not three as with composed sequence functions)
(sequence xform data)
-
reduce with a transformation (no laziness, just a loop)
(transduce xform + 0 data)
-
build one collection from a transformation of another, again no laziness
(into [] xform data)
-
create a recipe for a transformation, which can be subsequently sequenced, iterated or reduced
(iteration xform data)
-
or use the same transducer to transform everything that goes through a channel
(chan 1 xform)
The latter demonstrates the corresponding new capability of core.async channels - they can take transducers.
This post is just to serve as a heads up on what the ongoing work is about. There will be more explanations, tutorials and derivations to follow, here and elsewhere.
I’m excited about transducers and the power they bring, and I hope you are too!
Rich
Background
I recently started working on a new project that has a significant UI component. I decided that this was a good opportunity to take a look at Angular and React for building the client as a single page application.
After a bit of evaluation, I decided that React was a better fit for the project. Specifically, I found the idea of the virtual DOM very appealing and its component based approach to be a good way to manage the application state.
Once I got a bit deeper into using React I found it lacking in many areas. For example, it doesn't provide an adequate solution for complex data binding and while there are a few libraries such as react-forms, I didn't find them to be a good fit for my needs.
Having heard lots of great things about Om, I decided that this might be a good time to revisit ClojureScript. While I've done some projects in ClojureScript previously, I always ended up going back to JavaScript in the end.
For me, the benefits were not enough to outweigh the maturity of JavaScript and the tooling available for it. One of the things I found to be particularly painful was debugging generated JavaScript. This problem has now been addressed by the addition of source maps.
Trying Om
As I went through Om tutorials, I found that it exposes a lot of the incidental details to the user. Having to pass nil arguments, reify protocols, and manually convert to Js using #js hints are a but a few warts that I ran into. Although, it's worth noting that the om-tools library from Prismatic address some of these issues.
Overall, I feel that Om requires a significant time investment in order to become productive. I found myself wanting a higher level of abstraction for creating UI components and tracking state between them. This led me to trying Reagent. This library provides a very intuitive model for assembling UI components and tracking their state, and you have to learn very few concepts to start using it efficiently.
Differences between Om and Reagent
Om and Reagent make different design decisions that result in different tradeoffs, each with its own strength and weaknesses. Which of these libraries is better primarily depends on the problem you're solving.
The biggest difference between Om and Reagent is that Om is highly prescriptive in regards to state management in order to ensure that components are reusable. It's an anti-pattern for Om components to manipulate the global state directly or by calling functions to do so. Instead, components are expected to communicate using core.async channels. This is done to ensure high modularity of the components. Reagent leaves this part of the design up to you and allows using a combination of global and local states as you see fit.
Om takes a data centric view of the world by being agnostic about how the data is rendered. It treats the React DOM and Om components as implementation details. This decision often results in code that's verbose and exposes incidental details to the user. These can obviously be abstracted, but Om does not aim to provide such an abstraction and you'd have to write your own helpers as seen with Prismatic and om-tools.
On the other hand, Reagent provides a standard way to define UI components using Hiccup style syntax for DOM representation. Each UI component is a data structure that represents a particular DOM element. By taking a DOM centric view of the UI, Reagent makes writing composable UI components simple and intuitive. The resulting code is extremely succinct and highly readable. It's worth noting that nothing in the design prevents you from swapping in custom components. The only constraint is that the component must return something that is renderable.
Using Reagent
The rest of this post will walk through building a trivial Reagent app where I hope to illustrate what makes Reagent such an excellent library. Different variations of CRUD apps are probably the most common types of web applications nowadays. Let's take a look at creating a simple form with some fields that we'll want to collect and send to the server.
I won't go into details of setting up a ClojureScript project in this post, but you can use the reagent-example project to follow along. The project requires Leiningen build tool and you will need to have it installed before continuing.
Once you check out the project, you will need to start the ClojureScript compiler by running lein cljsbuild auto and run the server using lein ring server.
The app consists of UI components that are tied to a model. Whenever the user changes a value of a component, the change is reflected in our model. When the user clicks the submit button then the current state is sent to the server.
The ClojureScript code is found in the main.core under the src-cljs source directory. Let's delete its contents and start writing our application from scratch. As the first step, we'll need to reference reagent in our namespace definition.
(ns main.core
(:require [reagent.core :as reagent :refer [atom]]))
Next, let's create a Reagent component to represent the container for our page.
(defn home []
[:div
[:div.page-header [:h1 "Reagent Form"]]])
We can now render this component on the page by calling the render-component function.
(reagent/render-component [home]
(.getElementById js/document "app"))
As I mentioned above, the components can be nested inside one another. To add a text field to our form we'll write a function to represent it and add it to our home component.
(defn text-input [label]
[:div.row
[:div.col-md-2
[:span label]]
[:div.col-md-3
[:input {:type "text" :class "form-control"}]]])
(defn home []
[:div
[:div.page-header [:h1 "Reagent Form"]]
[text-input "First name"]])
Notice that even though text-input is a function we're not calling it, but instead we're putting it in a vector. The reason for this is that we're specifying the component hierarchy. The components will be run by Reagent when they need to be rendered.
We can also easily extract the row into a separate component. Once again, we won't need to call the row function directly, but can treat the component as data and leave it up to Reagent when it should be evaluated.
(defn row [label & body]
[:div.row
[:div.col-md-2 [:span label]]
[:div.col-md-3 body]])
(defn text-input [label]
[row label [:input {:type "text" :class "form-control"}]])
We now have an input field that we can display. Next, we need to create a model and bind our component to it. Reagent allows us to do this using its atom abstraction over the React state. The Reagent atoms behave just like standard Clojure atoms. The main difference is that a change in the value of the atom causes any components that dereference it to be repainted.
Any time we wish to create a local or global state we create an atom to hold it. This allows for a simple model where we can create variables for the state and observe them as they change over time. Let's add an atom to hold the state for our application and a couple of handler functions for accessing and updating it.
(def state (atom {:doc {} :saved? false}))
(defn set-value! [id value]
(swap! state assoc :saved? false)
(swap! state assoc-in [:doc id] value))
(defn get-value [id]
(get-in @state [:doc id]))
We can now update our text-input component to set the state when the onChange event is called and display the current state as its value.
(defn text-input [id label]
[row label
[:input
{:type "text"
:class "form-control"
:value (get-value id)
:on-change #(set-value! id (-> % .-target .-value))}]])
(defn home []
[:div
[:div.page-header [:h1 "Reagent Form"]]
[text-input :first-name "First name"]])
Let's add a save button to our form so that we can persist the state. For now, we'll simply log the current state to the console.
(defn home []
[:div
[:div.page-header [:h1 "Reagent Form"]]
[text-input :first-name "First name"]
[:button {:type "submit"
:class "btn btn-default"
:on-click #(.log js/console (clj->js @state))}
"Submit"]])
If we open the console, then we should see the current value of the :first-name key populated in our document whenever we click submit. We can now easily add a second component for the last name and see that it gets bound to our model in exactly the same way.
(defn home []
[:div
[:div.page-header [:h1 "Reagent Form"]]
[text-input :first-name "First name"]
[text-input :last-name "First name"]
[:button {:type "submit"
:class "btn btn-default"
:onClick #(.log js/console (clj->js @state))}
"Submit"]])
So far we've been using a global variable to hold all our state, while it's convenient for small applications this approach doesn't scale well. Fortunately, Reagent allows us to have localized states in our components. Let's take a look at implementing a multi-select component to see how this works.
When the user clicks on an item in the list, we'd like to mark it as selected. Obviously, this is something that's only relevant to the list component and shouldn't be tracked globally. All we have to do to create a local state is to initialize it in a closure.
We'll implement the multi-select by creating a component to represent the list and another to represent each selection item. The list component will accept an id and a label followed by the selection items.
Each item will be represented by a vector containing the id and the value of the item, eg: [:beer "Beer"]. The value of the list will be represented by a collection of the ids of the currently selected items.
We will use a let binding to initialize an atom with a map keyed on the item ids to represent the state of each item.
(defn selection-list [id label & items]
(let [selections (->> items (map (fn [[k]] [k false])) (into {}) atom)]
(fn []
[:div.row
[:div.col-md-2 [:span label]]
[:div.col-md-5
[:div.row
(for [[k v] items]
[list-item id k v selections])]]])))
The item component will be responsible for updating its state when clicked and persisting the new value of the list in the document.
(defn list-item [id k v selections]
(letfn [(handle-click! []
(swap! selections update-in [k] not)
(set-value! id (->> @selections
(filter second)
(map first))))]
[:li {:class (str "list-group-item"
(if (k @selections) " active"))
:on-click handle-click!}
v]))
Let's add an instance of the selection-list component to our form and see how it looks.
(defn home []
[:div
[:div.page-header [:h1 "Reagent Form"]]
[text-input :first-name "First name"]
[text-input :last-name "First name"]
[selection-list :favorite-drinks "Favorite drinks"
[:coffee "Coffee"]
[:beer "Beer"]
[:crab-juice "Crab juice"]]
[:button {:type "submit"
:class "btn btn-default"
:onClick #(.log js/console (clj->js @state))}
"Submit"]])
Finally, let's update our submit button to actually send the data to the server. We'll use the cljs-ajax library to handle our Ajax calls. Let's add the following dependency [cljs-ajax "0.2.6"] to our project.clj and update our namespace to reference it.
(ns main.core
(:require [reagent.core :as reagent :refer [atom]]
[ajax.core :refer [POST]]))
With that in place we can write a save-doc function that will send the current state of the document to the server and set the state to saved on success.
(defn save-doc []
(POST (str js/context "/save")
{:params (:doc @state)
:handler (fn [_] (swap! state assoc :saved? true))}))
We can now update our form to either display a message indicating that the document has been saved or the submit button based on the value of the :saved? key in our state atom.
(defn home []
[:div
[:div.page-header [:h1 "Reagent Form"]]
[text-input :first-name "First name"]
[text-input :last-name "Last name"]
[selection-list :favorite-drinks "Favorite drinks"
[:coffee "Coffee"]
[:beer "Beer"]
[:crab-juice "Crab juice"]]
(if (:saved? @state)
[:p "Saved"]
[:button {:type "submit"
:class "btn btn-default"
:onClick save-doc}
"Submit"])])
On the server side we'll simply log the value submitted by the client and return "ok".
(ns reagent-example.routes.services
(:use compojure.core)
(:require [reagent-example.layout :as layout]
[noir.response :refer [edn]]
[clojure.pprint :refer [pprint]]))
(defn save-document [doc]
(pprint doc)
{:status "ok"})
(defroutes service-routes
(POST "/save" {:keys [body-params]}
(edn (save-document body-params))))
With the route hooked up in our handler we should see something like the following whenever we submit a message from our client:
{:first-name "Jasper", :last-name "Beardly", :favorite-drinks (:coffee :beer)}
As you can see, getting started with Reagent is extremely easy and it requires very little code to create a working application. You could say that single page Reagent apps actually fit on a single page. :) In the next installment we'll take a look at using the secretary library to add client side routing to the application.
Pattern Libraries
Blogs on Tom Spencer 08 07 2014
Pattern Libraries
Blogs on Tom Spencer 08 07 2014
Angular Boilerplate
Blogs on Tom Spencer 15 05 2014
Angular Boilerplate
Blogs on Tom Spencer 15 05 2014
Righteousness
James Sinclair 14 05 2014
Over Easter, our pastor challenged us to live like Jesus is actually risen. Someone I know (quite rightly) asked the question “but what does that look like?” My response is that part of the answer is righteousness, but that might need some explaining.
Mongoose Validations
Blogs on Tom Spencer 23 04 2014
Mongoose Validations
Blogs on Tom Spencer 23 04 2014
Using Mongoose
Blogs on Tom Spencer 21 04 2014
Using Mongoose
Blogs on Tom Spencer 21 04 2014
Learning Angular
Blogs on Tom Spencer 07 04 2014
Learning Angular
Blogs on Tom Spencer 07 04 2014
Becoming Angular
Blogs on Tom Spencer 31 03 2014
Becoming Angular
Blogs on Tom Spencer 31 03 2014
Self Employment
Blogs on Tom Spencer 25 03 2014
Self Employment
Blogs on Tom Spencer 25 03 2014
A New Beginning
Blogs on Tom Spencer 18 03 2014
A New Beginning
Blogs on Tom Spencer 18 03 2014
No Free Lunch
(iterate think thoughts) 26 01 2014
On paper static typing sounds strictly superior to dynamic typing. The compiler can track the data flow throughout our code and tell us when we're using the data incorrectly. This clearly eliminates a whole class of errors that are otherwise possible. What's more, types allow us to encode the business logic of our application allowing us to write code that's provably correct.
All this is unarguably correct, however these benefits do not come for free. One major problem is that static typing requires us to declare all the relationships globally. When you have global relationships a change at any level requires global refactoring at every level.
In my opinion, this makes static typing poorly suited for situations where your requirements are incomplete or subject to change, and in reality there are very few scenarios where your requirements are set in stone.
In most cases, we only care about a local contract between any two functions. What we want to know is that the function being called produces the type expected by the caller. A modification of a local contract should not cause global change in our code base.
Another cost of static typing is that it forces us to handle cases that are not part of the application workflow. For example, our code might have an undefined behavior, but the interface does not allow the user to access this state. This is a case of a tree falling in the woods when no one's around.
Regardless of the type system that you use, you will need to do functional testing in order to ensure that the business logic does what's intended. At the end of the day, the goal of the application is to handle the intended use cases as opposed to providing a proof of correctness.
When I look at the GitHub issues for my own projects such as Selemer or markdown-clj, vast majority of them stem from lack of specification. Practically none of these issues would have been caught by the type system. Had I used a statically typed language to write these projects, I would've simply had to jump through more hoops to end up with the same result.
In my opinion the value added by a static type system has to be weighed against the complexity of the problem and the cost of errors. Since it's obviously useful in some cases and provides dubious value in others, an optional type system might provide the right balance. Static typing is a tool and it should be up to the developer to decide how and when to apply it.
With an optional static checker we can add types where it makes sense and leave the rest of the code dynamic. This is precisely the situation CircleCI found themselves in.
First thing I'd like to say is that I'm very excited by the shift in nature of Clojure books that are coming out. There are already many excellent books about the language itself. Some of these include The Joy of Clojure, Programming Clojure, and Clojure in Action.
This year we can add Clojure Data Analysis Cookbook, Clojure Cookbook, my own Web Development With Clojure, and Clojure High Performance Programming to the roster. All these books focus on applying the language in the real world.
To me this indicates that developers are moving from simply experimenting with the language to actually using it professionally. The results from the 2013 State of Clojure & ClojureScript, where more than half the respondents reported using Clojure at work, appear to corroborate this idea.
One of the things that makes Clojure attractive is the fact that it's one of the more performant dynamic languages. As can be seen in the recent round of TechEmpower Benchmarks, Clojure web frameworks fare quite well compared to the popular offerings in Ruby and Python. Since performance is a major factor in using Clojure, a book discussing high performance programming is a welcome addition.
The book starts off by introducing the reader to performance use case classification. It does a decent job of explaining the background concepts and the vocabulary that will be used throughout.
Different types of scenarios are discussed and their related performance concerns. For example, when we deal with user interfaces, responsiveness is our main concern. On the other hand if we're doing data-processing then we want to optimize CPU and memory usage.
The author then moves on to discuss how common Clojure idioms impact the performance of the application. Understanding what goes on behind the scenes helps reason about potential pitfalls down the road.
There's a good discussion about the explicit use of loop/recur over higher order functions that illustrates a way to squeeze out additional performance. In another section the author goes on to explain the impact of laziness on performance in functional languages.
There are also tips regarding the use of different data formats. One example compares the benefits of EDN over JSON. EDN can save memory by using interned symbols and keywords, while JSON uses string keys which will not be interned. The author explains that in addition to saving memory, interning also avoids heap usage and this helps minimize garbage collection. This is something you would definitely want to consider if you were working with a high performance application.
The techniques used by some of the popular libraries, such as Nippy, are examined to see how they achieve high performance. These kinds of real world examples are very helpful. Not only do we learn about the theory, but we also get to see how it's applied in practice.
In general, the book covers a wide range of topics, but only offers a superficial overview for many. The reader will most certainly need to do further research in order to apply many of the concepts discussed.
If you're looking for a refresher or a primer on the topics discussed, then it's not a bad place to start. However, if you're looking for a comprehensive discussion on doing high performance programming with Clojure, you'll likely be left wanting.
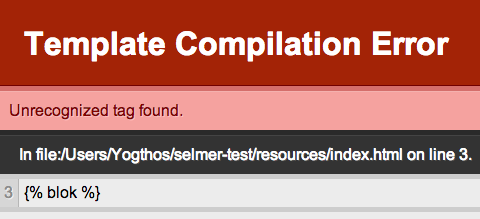
It's been nearly 5 month since Selmer was released. In that time many bugs have been squashed and lots of new features added. However, there is one aspect that remained shameful and that was error reporting.
When Selmer failed to parse a template it would often produce error messages that were less than useful. For example, given the following template:
<html>
<body>
{% blok %}
{% endblock %}
<h2>Hello {{name}}</h2>
</body>
</html>
we'd end up with the following error after trying to render it:
Exception in thread "main" java.lang.Exception: unrecognized tag: :blok - did you forget to close a tag?
While the error indicated the name of the problem tag, it didn't say what template this tag originated from or on what line it appeared.
These types of errors can result in a lot of wasted time and frustration. It would be much better to provide a clear error that contains the actual offending tag along with the name of the template and the line number.
As of version 0.4.8, Selmer has a validator that checks the following cases:
- can the tag be parsed successfully
- is the filter found in the map of filters
- does the tag contain a name
- is the tag name found in the map of tags
- if a tag is a block tag, is the corresponding closing tag found
- is the tag a closing tag for an opening tag that's not present
Here's the error returned by the validator when rendering the above template:
Exception in thread "main" java.lang.Exception: Unrecognized tag: {% blok %} on line 3 for template file:/Users/Yogthos/selmer-test/resources/index.html
This gives us a lot more information as to what went wrong and where. This is a big improvement on the original error, however we still have an ugly stacktrace to look at to figure out what happened.
It would be even better to return a distinct validation error that could be intercepted by some middleware to produce a friendly error page.
This is precisely what Selmer does as of version 0.5.3. The validator will now return ex-info with a key :type that's set to :selmer-validation-error.
It will also contain an error page template that can be rendered using the ex-data attached to the exception. We can now write a simple middleware function to catch these errors and render the error page:
(defn template-error-page [handler]
(fn [request]
(try
(handler request)
(catch clojure.lang.ExceptionInfo ex
(let [{:keys [type error-template] :as data} (ex-data ex)]
(if (= :selmer-validation-error type)
{:status 500
:body (selmer.parser/render error-template data)}
(throw ex)))))))
Using the above middleware, we'll see the following page whenever the parser fails to compile a template:
We can now immediately tell that an error occurred during the template compilation and see only the information pertaining to the nature of the error.
Of course, we wouldn't want to display this information when running in production. A simple solution would be to set a dev flag and check for it in our middleware.
This is precisely what the latest Luminus template will do using the environ library. The project.clj now contains an :env key under the :dev profile with the :selmer-dev flag set to true:
:dev {:dependencies [[ring-mock "0.1.5"]
[ring/ring-devel "1.2.1"]]
:env {:selmer-dev true}}}
The middleware will check that the key is present and only render the error page in development mode:
(defn template-error-page [handler]
(if (env :selmer-dev)
(fn [request]
(try
(handler request)
(catch clojure.lang.ExceptionInfo ex
(let [{:keys [type error-template] :as data} (ex-data ex)]
(if (= :selmer-validation-error type)
{:status 500
:body (parser/render error-template data)}
(throw ex))))))
handler))
When it comes to writing libraries it's easy to forget about the little things like error reporting and documentation. However, these things are just as important as having good code and a clean API.
In the end, this is what makes the difference between a pleasant development experience and one that's fraught with frustration.
First of all, I write this to myself as much as anybody. Now, with that said…
I am concerned about how Christianity is perceived by those who don’t call themselves ‘Christian.’ It’s not that Christians are ridiculed in the media (we’ve always been ridiculed), but rather, what people assume I mean when I call myself a Christian is so very different from what I actually mean that I’m almost hesitant to use the word.
For a recent project I needed to process some code in parallel. A colleague pointed me to the pcntl_fork() function, and it turns out it’s not quite as scary and complicated as I thought. So I turned the simple use case into a generic function.
For a recent project I needed to process some code in parallel. A colleague pointed me to the pcntl_fork() function, and it turns out it’s not quite as scary and complicated as I thought. So I turned the simple use case into a generic function.
I'm happy to announce that Web Development With Clojure has finally reached beta and it's now available for purchase.
The book covers working with the core Ring/Compojure stack, common libraries as well as techniques for accomplishing common tasks. My main goal is to make the reader comfortable with the Clojure ecosystem and demonstrate how to take an application from inception all the way to deployment.
It's been a long journey to get to this point and I learned much along the way. This book is my way to share that experience with you and hopefully save you time when working on your projects.
There's still some clean up left to do and you might see a few typos here and there. However, there won't be any changes to the core content at this point and I hope that you'll be curious enough to take a look. :)
I find that I often get excited about learning a new language, but after I use it for a while it will inevitably lose its lustre. Eventually it becomes just another language in my tool box.
One exception to this rule is Clojure. I still enjoy using the language as much as I did when I first learned it. The reason for this is that it strikes the right balance between power and simplicity.
The Balance of Power
Some languages are simple but they're also verbose. You've probably heard people say that verbosity really doesn't matter. These people will go to great length to point out that all languages are Turing complete and that in certain languages you simply have to write a bit more code.
I think that's missing the point however. The question is not whether something can be expressed in principle. It's how well the language maps to the problem being solved. One language will let you think in terms of your problem domain, while another will force you to translate the problem to its constructs.
The latter is often tedious and rarely enjoyable. You end up writing a lot of boilerplate code and constantly repeating yourself. I hope you'll agree that there is a certain amount of irony involved in having to write repetitive code.
Other languages aren't verbose and they provide many different tools for solving problems. Unfortunately, working in such languages is often akin to trying to decide on a particular set of screwdrivers at a hardware megastore.
You end up comparing this brand against that, checking the number of bits that comes with each set, seeing which one's on sale today, and soon you forget why you wanted a screwdriver in the first place.
The more features there are the more things you have to keep in your head to work with the language effectively. With many languages I find myself constantly expending mental overhead thinking about all the different features and how they interact with one another.
What matters to me in a language is whether I can use it without thinking about it. When the language is lacking in expressiveness I'm acutely aware that I'm writing code that I shouldn't be. On the other hand when the language has too many features I often feel overwhelmed or I get distracted playing with them.
To make an analogy with math, it's nicer to have a general formula that you can derive others from than having to memorize a whole bunch of formulas for specific problems.
This is where Clojure comes in. With it I can always easily derive a solution to a particular problem from a small set of general patterns. The number of things I have to keep in my head is not overbearing.
All you need to become productive is to learn a few simple concepts and a bit of syntax. However, the number of ways that these concepts can be combined to solve all manner of problems appears to be inexhaustible. I've been writing Clojure for years and I discover new ways to combine the things I already know every single day.
Macros are a good example of this. The fact that you can transform the language using itself allows tackling a wide range of problems that would otherwise require a range of specific tools and language features.
Interactive Development
When I'm solving a problem in Clojure I inevitably want to write an elegant solution that expresses the gist of it cleanly and clearly. This is largely due to the fact that the development process is interactive.
When I work with the REPL I can fumble around looking for a solution and make sense of it through experimentation. Once I've internalized the problem I can quickly write a clean solution using my newly gained understanding.
The REPL also helps keep me engaged in trying to find the solution. Being able to try things and get immediate feedback is enjoyable. Even when your code doesn't do what you want you can see the progression and that is often enough of a motivator to keep going.
Another important feature of the REPL is that it encourages refactoring. I'm much more likely to refactor code when I can easily test it without disrupting my workflow.
Finishing Things
Interactivity alone isn't enough however. All the feedback in the world wouldn't make one bit of difference if you couldn't actually solve your problem in a reasonable amount of time.
I find that I have a sharp falloff curve when it comes to staying engaged in a project. You've probably noticed this phenomenon yourself. When you start a project you're excited and you enjoy seeing it take shape.
However, after working on a project for some amount of time the excitement wanes. Eventually, you might even dread having to touch the code again. I find that it's critical to get the core functionality working before I hit this stage.
Once the project solves a particular problem that I have I'll start using it. At this point I get to reap the benefits of having spent the effort on it. This also lets me identify the functionality that I'm missing through usage. There is a lot more incentive to add features to a project that you're actually using.
Most recently I found this to be the case working on Selmer. I was able to implement the base parser in just a couple of days, while cesarbp implemented the logic for the filters.
It took a couple of more days to get the template inheritance logic working. All of a sudden we had a usable library in under a week of effort. I'm already actively using it for actual work and new features are added piecemeal as the need comes up.
Here's the GitHub activity graph for Selmer:
As you can see there's a big initial spike with a very sharp falloff. A similar patten can be seen in my other projects such as clj-pdf and with Luminus:
As the project matures bugs are inevitably found or new features are added, these correspond the occasional spikes in the activity. However, if the initial phase of the project can't be completed in a timely fashion then nothing else can happen.
In my experience, if you can't get something interesting working in a few days the likelihood of actually finishing the project starts rapidly approaching zero.
With Clojure you can get things done fast, fast enough that you get something working while the initial spark of excitement is still present. I would hazard to guess that this is the reason why Clojure has so many great libraries despite being a young language.
Introducing Selmer
(iterate think thoughts) 30 07 2013
Rationale
There are a number of templating engines available in Clojure. Some of the popular ones include Hiccup, Enlive, Laser, Stencil, mustache.clj and Clabango.
As I've mentioned previously, my personal preference is for Clabango syntax. In my opinion it provides the right balance between simplicity and flexibility. Being modeled on Django template syntax it's also very accessible to those who are new to Clojure web development.
However, one major downside to Clabango is that it's slow. On TechEmpower fortunes benchmark Luminus is crawling behind the Compojure results. Yes, you read that right, it's nearly 20 times slower for Clabango to render the results. The difference being that the Compojure benchmark is using Hiccup for rendering the results while Luminus is using Clabango.
The core problem is that Clabango always parses the source files when rendering a template. This is very expensive as it involves disk access and scanning each character in the source file each time a page is served. Dan states that performance has not been a priority.
On top of that, some of the existing behaviours put limitations on how much the performance can ultimately be improved. For example, the child templates aren't required to put their content inside blocks. Clabango parses the templates and creates the AST that's then evaluated. This means that you can put blocks inside the if tags and decide at runtime whether they will be included. If inheritance resolution is pushed to compile time this becomes a problem.
After having some discussions with bitemyapp and ceaserbp we decided that it would be worth writing a fresh impelementation with pefromance as its primary goal. Another reason is that I would like to be able to ensure that the templating engine in Luminus isn't a compromise between speed and convenience. Owning the implementation is the best way to achieve that.
Enter Selmer
All this resulted in Selmer named after the guitar favored by Django Reinhardt whom in turn Django is named after. Selmer aims to be a near drop in replacement for Clabango. The current version is already quite fast keeping pace with Stencil which is one of the faster engines around.
In order to minimize the work that's done at runtime Selmer splits the process into three distinct steps. These steps include preprocessing, compilation and rendering.
First, Selmer will resolve the inheritance hierarchy and generate the definitive template source to be compiled. The extends and include tags will be handled at this time.
The compilation step then produces a vector of text nodes and runtime transformer functions.
The renderer uses these compiled templates to generate its output. The text gets rendered without further manipulation while the transformers use the context map to generate their output at runtime.
Using this approach we minimize the amount of logic that needs to be executed during each request as well as avoiding any disk access in the process.
In order not to have to restart the application when the source templates are changed the renderer checks the last updated timestamp of the template. When the timestamp is changed a recompile is triggered.
Performance Tricks
To our chagrin the first run of the parser ran no better than Clabango. This was rather disappointing considering we took pains to be mindful of the performance issues. However, this mystery was quickly solved by profiling the parser.
Sure enough majority of time was spent in reflection calls. One major problem was that the renderer had to check whether each node was text or a function:
(defn render [template params]
(let [buf (StringBuilder.)]
(doseq [element template]
(.append buf (if (string? element) element (element params))))
(.toString buf)))
Protocols offer an elegant solution to this problem. With their help we can move this work to compile time as follows:
(defprotocol INode
(render-node [this context-map] "Renders the context"))
(deftype FunctionNode [handler]
INode
(render-node ^String [this context-map]
(handler context-map)))
(deftype TextNode [text]
INode
(render-node ^String [this context-map]
text))
Now our parser can happily run along and call render-node on each element:
(defn render-template [template context-map]
""" vector of ^selmer.node.INodes and a context map."""
(let [buf (StringBuilder.)]
(doseq [^selmer.node.INode element template]
(if-let [value (.render-node element context-map)]
(.append buf value)))
(.toString buf)))
With this change and a few type annotations the performance improved dramatically. Running clojure-template-benchmarks the results are comparable to Stencil. Here are the results from benchmarking on my machine:
Clabango
- Simple Data Injection
- Execution time mean : 657.530826 µs
- Execution time std-deviation : 2.118301 µs
- Small List (50 items)
- Execution time mean : 2.446739 ms
- Execution time std-deviation : 17.448003 µs
- Big List (1000 items)
- Execution time mean : 28.230365 ms
- Execution time std-deviation : 173.518425 µs
Selmer
- Simple Data Injection
- Execution time mean : 42.444958 µs
- Execution time std-deviation : 235.652171 ns
- Small List (50 items)
- Execution time mean : 209.158509 µs
- Execution time std-deviation : 4.045131 µs
- Big List (1000 items)
- Execution time mean : 3.223797 ms
- Execution time std-deviation : 55.511322 µs
Stencil
- Simple Data Injection
- Execution time mean : 92.317566 µs
- Execution time std-deviation : 213.253353 ns
- Small List (50 items)
- Execution time mean : 290.403204 µs
- Execution time std-deviation : 1.801479 µs
- Big List (1000 items)
- Execution time mean : 1.223634 ms
- Execution time std-deviation : 4.264979 µs
As you can see Selmer is showing a large improvement over Clabango and has no trouble keeping up with Stencil.
Obviously, this benchmark is fairly simplistic so you can take it with a grain of salt. If anybody would like to put together a more comprehensive suite that would be great. :)
Current status
The library implements all the functionality offered by Clabango and passes the Clabango test sutie. There are a few minor deviations, but overall it should work as a drop in replacement without the need to change your existing HTML templates.
We also have a few new features such as the Django {{block.super}} tag support and ability to use filters in if statements. In Selmer you can write things like:
(selmer.filters/add-filter! :empty? empty?)
(render
"{% if files|empty? %}
no files available
{% else %}
{% for file in files %}{{file}}{% endfor %}
{% endif %}"
{:files []})
Switching to Selmer involves swapping the [clabango "0.5"] dependency for [selmer "0.5.3"] and referencing selmer.parser instead of clabango.parser. Selmer provides the same API for rendering templates using the selmer.parser/render and selmer.parser/render-file functions.
One major area of difference is in how custom tags and filters are defined. Defining a filter is done by calling selmer.filters/add-filter! with the id of the filter and the filter function:
(use 'selmer.filters)
(add-filter! :embiginate #(.toUpperCase %))
(render "{{shout|embiginate}}" {:shout "hello"})
=>"HELLO"
Defining custom tags is equally simple using the selmer.parser/add-tag! macro:
(use 'selmer.parser)
(add-tag! :foo
(fn [args context-map]
(str "foo " (first args))))
(render "{% foo quux %} {% foo baz %}" {})
=>"foo quux foo baz"
tags can also contain content and intermediate tags:
(add-tag! :foo
(fn [args context-map content]
(str content))
:bar :endfoo)
(render "{% foo %} some text {% bar %} some more text {% endfoo %}" {})
=>"{:foo {:args nil, :content \" some text \"}, :bar {:args nil, :content \" some more text \"}}"
Selmer also supports overriding the default tag characters using :tag-open, :tag-close, :filter-open, :filter-close and :tag-second keys:
(render "[% for ele in foo %]<<[{ele}]>>[%endfor%]"
{:foo [1 2 3]}
{:tag-open \[
:tag-close \]})
This makes it much easier to use it in conjunction with client-side frameworks such as AngularJs.
One limitation Selmer has is the way it handles inheritance. Since the inheritance block hierarchy is compiled before the parsing step, any content in child templates must be encapsulated in block tags. Free-floating tags and text will simply be ignored by the parser. This is in line with Django behavior.
So there you have it. If you like Django template syntax or just want a fast templating engine then give Selmer a try.
As it is a new project there may be bugs and oddities so don't hesitate to open an issue on the project page if you find any. So far I haven't found any problems in switching my application from Clabango to Selmer and the test coverage is fairly extensive at this point.
Clojure core.async Channels
Clojure News 28 06 2013
core.async is a new contrib library for Clojure that adds support for asynchronous programming using channels.
Rationale
There comes a time in all good programs when components or subsystems must stop communicating directly with one another. This is often achieved via the introduction of queues between the producers of data and the consumers/processors of that data. This architectural indirection ensures that important decisions can be made with some degree of independence, and leads to systems that are easier to understand, manage, monitor and change, and make better use of computational resources, etc.
On the JVM, the java.util.concurrent package provides some good concurrent blocking queues, and they are a viable and popular choice for Clojure programs. However, in order to use the queues one must dedicate one or more actual threads to their consumption. Per-thread stack allocation and task-switching overheads limit the number of threads that can be used in practice. Another limitation of j.u.c. queues is there is no way to block waiting on a set of alternatives.
On JavaScript engines, there are no threads and no queues.
Thread overheads or lack of threads often cause people to move to systems based upon events/callbacks, in the pursuit of greater efficiency (often under the misnomer 'scalability', which doesn’t apply since you can’t scale a single machine). Events complect communication and flow of control. While there are various mechanisms to make events/callbacks cleaner (FRP, Rx/Observables) they don’t change their fundamental nature, which is that upon an event an arbitrary amount of other code is run, possibly on the same thread, leading to admonitions such as "don’t do too much work in your handler", and phrases like "callback hell".
The objectives of core.async are:
-
To provide facilities for independent threads of activity, communicating via queue-like channels
-
To support both real threads and shared use of thread pools (in any combination), as well as ClojureScript on JS engines
-
To build upon the work done on CSP and its derivatives
It is our hope that async channels will greatly simplify efficient server-side Clojure programs, and offer simpler and more robust techniques for front-end programming in ClojureScript.
History
The roots of this style go back at least as far as Hoare’s Communicating Sequential Processes (CSP), followed by realizations and extensions in e.g. occam, Java CSP and the Go programming language.
In modern incarnations, the notion of a channel becomes first class, and in doing so provides us the indirection and independence we seek.
A key characteristic of channels is that they are blocking. In the most primitive form, an unbuffered channel acts as a rendezvous, any reader will await a writer and vice-versa. Buffering can be introduced, but unbounded buffering is discouraged, as bounded buffering with blocking can be an important tool coordinating pacing and back pressure, ensuring a system doesn’t take on more work than it can achieve.
Details
Just a library
core.async is a library. It doesn’t modify Clojure. It is designed to support Clojure 1.5+.
Creating channels
You can create a channel with the chan function. This will return a channel that supports multiple writers and readers. By default, the channel is unbuffered, but you can supply a number to indicate a buffer size, or supply a buffer object created via buffer, dropping-buffer or sliding-buffer.
The fundamental operations on channels are putting and taking values. Both of those operations potentially block, but the nature of the blocking depends on the nature of the thread of control in which the operation is performed. core.async supports two kinds of threads of control - ordinary threads and IOC (inversion of control) 'threads'. Ordinary threads can be created in any manner, but IOC threads are created via go blocks. Because JS does not have threads, only go blocks and IOC threads are supported in ClojureScript.
go blocks and IOC 'threads'
go is a macro that takes its body and examines it for any channel operations. It will turn the body into a state machine. Upon reaching any blocking operation, the state machine will be 'parked' and the actual thread of control will be released. This approach is similar to that used in C# async. When the blocking operation completes, the code will be resumed (on a thread-pool thread, or the sole thread in a JS VM). In this way the inversion of control that normally leaks into the program itself with event/callback systems is encapsulated by the mechanism, and you are left with straightforward sequential code. It will also provide the illusion of threads, and more important, separable sequential subsystems, to ClojureScript.
Channel on ordinary threads
There are analogous operations for use on ordinary threads - >!! (put blocking) and <!! (take blocking), which will block the thread on which they are called, until complete. While you can use these operations on threads created with e.g. future, there is also a macro, thread, analogous to go, that will launch a first-class thread and similarly return a channel, and should be preferred over future for channel work.
Mixing modes
You can put on a channel from either flavor of >!/>!! and similarly take with either of <!/<<! in any combination, i.e. the channel is oblivious to the nature of the threads which use it.
alt
It is often desirable to be able to wait for any one (and only one) of a set of channel operations to complete. This powerful facility is made available through the alts! function (for use in go blocks), and the analogous alts!! (alts blocking). If more than one operation is available to complete, one can be chosen at random or by priority (i.e. in the order they are supplied). There are corresponding alt! and alt!! macros that combine the choice with conditional evaluation of expressions.
Timeouts
Timeouts are just channels that automatically close after a period of time. You can create one with the timeout function, then just include the timeout in an alt variant. A nice aspect of this is that timeouts can be shared between threads of control, e.g. in order to have a set of activities share a bound.
The value of values
As with STM, the pervasive use of persistent data structures offers particular benefits for CSP-style channels. In particular, it is always safe and efficient to put a Clojure data structure on a channel, without fear of its subsequent use by either the producer or consumer.
Contrasting Go language channels
core.async has obvious similarities to Go channels. Some differences with Go are:
-
All of the operations are expressions (not statements)
-
This is a library, not syntax
-
alts!is a function (and supports a runtime-variable number of operations) -
Priority is supported in
alt
Finally, Clojure is hosted, i.e. we are bringing these facilities to existing platforms, not needing a custom runtime. The flip-side is we don’t have the underpinnings we would with a custom runtime. Reaching existing platforms remains a core Clojure value proposition.
Whither actors?
I remain unenthusiastic about actors. They still couple the producer with the consumer. Yes, one can emulate or implement certain kinds of queues with actors (and, notably, people often do), but since any actor mechanism already incorporates a queue, it seems evident that queues are more primitive. It should be noted that Clojure’s mechanisms for concurrent use of state remain viable, and channels are oriented towards the flow aspects of a system.
Deadlocks
Note that, unlike other Clojure concurrency constructs, channels, like all communications, are subject to deadlocks, the simplest being waiting for a message that will never arrive, which must be dealt with manually via timeouts etc. CSP proper is amenable to certain kinds of automated correctness analysis. No work has been done on that front for core.async as yet.
Also note that async channels are not intended for fine-grained computational parallelism, though you might see examples in that vein.
Future directions
Networks channels and distribution are interesting areas for attention. We will also being doing performance tuning and refining the APIs.
Team
I’d like to thank the team that helped bring core.async to life:
-
Timothy Baldridge
-
Ghadi Shayban
-
Alex Miller
-
Alex Redington
-
Sam Umbach
And once again, Tom Faulhaber for his work on autodoc.
Status
While the library is still in an early state , we are ready for people to start trying it out and giving us feedback. The CLJS port is still work in progress. Please have a look at the examples, which we will expand over time.
It should be noted that the protocols behind the implementation should still be considered an implementation detail for the time being, until we finish our exploratory work around network channels, which might impact their design.
I hope that these async channels will help you build simpler and more robust programs.
Rich
Access rule handling in lib-noir has seen some major rework. James Reeves pointed out that the way the restrict macro worked was not ideal as it wasn't entirely idiomatic and wasn't very composable. For example it didn't take into account the use of the context macro in Compojure.
While there are some breaking changes, it's pretty easy to migrate the old rules and the new approach provides a lot more flexibility.
The first thing that's changed is how the restricted routes are defined. The macro now wraps the handler itself instead of the whole route. So instead of doing
(restricted GET "/private" [] handler)
you would now write:
(GET "/private" [] (restricted handler))
Access rules definitions in the noir.util.middleware/app-handler have been revamped as well. The rules can now be specified by passing either a function representing a single rule or a map representing a group of rules.
When specified as a function, the rule must accept a single parameter that is the request map. Such rules will implicitly redirect to the "/" URI.
The rule group map contains the following keys:
:redirect- the URI string or a function to specify where requests will be redirected to if rejected (optional defaults to "/"):uri- the URI for which the rules in the map will be activated (optional if none specified applies to all URIs):uris- a vector of URI patterns for which the rules in the map will be activated (optional):rule- a single rule function for the group:rules- a vector containing the rule functions associated with the specified:redirectand the:uri:on-fail- alternative to:redirectallows providing a function that accepts a request and handles the failure case
The :rules key can point to either a vector or a map. If the rules are a vector the default behavior is that every rule in the group must succeed. If rules are specified as a map, you can provide the resolution strategy using the :any and :every keys.
Let's take a look at an example of how this all works below:
(def-restricted-routes
(defroutes app-routes
;;restricted routes
(GET "/restricted" [] (restricted "this page is restricted"))
(GET "/restricted1" [] (restricted "this is another restricted page"))
(GET "/users/:id" [] (restricted "howdy"))
(GET "/admin" [] (restricted "admin route"))
(GET "/config" [] (restricted "config route"))
(GET "/super-secret" [] (restricted "secret route"))
;;public routes
(GET "/denied1" [] "denied")
(GET "/denied2" [] "denied differently"))
(def app
(middleware/app-handler
[app-routes]
:access-rules
[(fn [req] (session/get :user))
{:uri "/restricted"
:redirect "/denied1"
:rule (fn [req] false)}
{:redirect (fn [req]
(log/info (str "redirecting " (:uri req)))
"/denied2")
:uri "/users/*"
:rule (fn [req] false)}
{:uris ["/admin*" "/config*"]
:rules {:any [(fn [req] (session/get :admin))
(fn [req] (session/get :root))]}}
{:on-fail (fn [req] "you tried to access the super secret page!")
:uri "/super-secret*"
:rules [(fn [req] (session/get :admin))
(fn [req] (session/get :root))]}
{:uri "/super-secret*"
:rules {:every [(fn [req] (session/get :admin))
(fn [req] (session/get :root))]
:any [(fn [req] (session/get :zeus))
(fn [req] (session/get :athena))]}}
]))
The first rule will be activated for any handler that's marked as restricted. This means that all of the restricted pages will redirect to "/" if there is no user in the session.
The second rule will only activate if the request URI matches "/restricted" and will be ignored for other URIs. The "/restricted" route will redirect to the "/denied1" URI.
The third rule will match any requests matching the "/users/" URI pattern. These requests will be redirected to the "/denied2" URI and the URI of the request will be logged.
The next rule group matches both the "/admin*" and the "/config*" patterns and required that either the :admin or the :root keys are set in the session in addition to the :user key specified by the global rule.
Next, we have a rule group that uses :on-fail function that can provide its own handler instead of doing a redirect. It requires that both the :admin or the :root keys are set in the session.
Finally, we have a group that uses a mix of :every and :any keys to specify its rules.
The access-rule macro has been removed in favor of specifying rule groups directly in the handler. This makes it easier to see how all the rules are defined and what routes each set of rules affects.
With this new approach we can create independent rule groups for specific URI patterns as well as easily specify generic rules that affect all restricted handlers.
I found the new rule managing scheme to work better for my projects. I'd be interested on getting feedback whether it works for others as well and I'm always open to suggestions for improvements. :)
what's new in lib-noir
(iterate think thoughts) 25 05 2013
It's been nearly a year since lib-noir was split out into a stand-alone library. During this time the work on it has continued at a steady pace. There have been numerous bug fixes and many new features have been added to the library.
Many of these come either from user suggestions or contributions. So, if there is something that you'd like to see improved don't hesitate to submit an issue or make a pull request.
In this post I'd like to highlight some of the major new features that have been recently added.
Middleware
The app-handler in noir.util.middleware now accepts optional:middleware and :access-rules parameters.
Since the outer middleware is evaluated first, if you wrap the app-handler in custom middleware it will execute before any of the standard middleware is executed. This is a problem if you wish to get access to things like the session, eg:
(defn log-user-in-session [handler]
(fn [req]
(timbre/info (session/get :user))
(handler req)))
(def app (-> (middleware/app-handler all-routes)
log-user-in-session))
If we try to run our app with the above handler we'll get the following exception:
java.lang.ClassCastException: clojure.lang.Var$Unbound cannot be cast to java.util.concurrent.Future
This happens due to the fact that noir.session uses the *noir-session* dynamic variable to keep track of the session. This variable is bound by the wrap-noir-session middleware. Since the log-user-in-session executes before it, the session is not yet bound.
The :middleware key allows specifying a vector containing custom middleware to wrap the handler before the standard middleware:
(def app (middleware/app-handler all-routes
:middleware [log-user-in-session]))
Now, the log-user-in-session will be called after the wrap-noir-session is called and work as expected.
The :access-rules key allows specifying the access rules for the wrap-access-rules middleware. Each set of rules should be specified as a vector with the contents matching the wrap-access-rules arguments:
(defn private-pages [method url params]
(session/get :user-id))
(def app (middleware/app-handler all-routes
:access-rules
[[{:redirect "/unauthorized"} private-pages]]))
There's also a new middleware wrapper called wrap-rewrites that allows rewriting URIs based on regex.
The rewrite rules should be supplied as pairs of the regex and the string the matching URL should be rewritten with. The first regex that matches the request's URI will cause it to be replaced with its corresponding string before calling the wrapped handler:
(wrap-rewrites handler #"/foo" "/bar")
Above, all occurances of the/foo URI will be replaced with /bar.
Routes
There's now a noir.util.route/def-restricted-routes macro for creating groups of restricted routes. Where before you had to do something like this:
(defroutes private-routes
(restricted GET "/route1" [] handler1)
(restricted GET "/route2" [] handler2)
(restricted GET "/route3" [] handler3)
(restricted GET "/route4" [] handler4))
you can now simply do:
(def-restricted-routes private-routes
(GET "/route1" [] handler1)
(GET "/route2" [] handler2)
(GET "/route3" [] handler3)
(GET "/route4" [] handler4))
The macro will automatically mark all the routes as restricted for you.
Finally, the access rules used to control the restricted routes are more flexible now as well. The redirect target can now point to a function as well as a string, eg:
(def app (middleware/app-handler all-routes
:access-rules
[[{:redirect
(fn []
(println "redirecting") "/unauthorized")}
private-pages]]))
As always, Luminus provides the latest lib-noir, so all the new features are available there as well.
I maintain a Clojure Markdown parser library called markdown-clj. I originally wrote it because I was curious to see just how concise a Clojure Markdown parser would be. Turns out that it's pretty concise. :)
Then I saw a post from Brian Carper that highlighted a problem with having different Markdown parsers on the client and the server.
Since Markdown specification is somewhat loose, most implementations interpret it differently. This means that if you're rendering a preview on the client using a JavaScript library and using a different library, such as pegdown, to render it on the server you may get some surprises.
Since my library was already written in pure Clojure I figured it wouldn't be difficult to cross-compile it to ClojureScript as well.
That turned out to be very easy to do. I split out the element transformers into a separate namespace that's shared between Clojure and ClojureScript cores. However, for the longest time I only packaged it for distribution as a Clojure library.
I finally had a bit of free time to look at ClojureScript packaging over the weekend and I'm happy to report that the dependency now works for both Clojure and ClojureScript out of the box.
While pure ClojureScript libraries compile without any extra work, I found a few gotchas that are specific to cross-compiling.
If you have a project that contains both Clojure and ClojureScript code in it, then only the clj files will be packaged in the jar by default. After some reading of the lein-cljsbuild docs I found the solution.
Here's what I ended up doing to get cljs namespaces to be packaged along with the clj namespaces:
:cljsbuild
{:crossovers [markdown.transformers]
:crossover-path "crossover"
:crossover-jar true
:builds {:main
{:source-paths ["src-cljs"]
:jar true
:compiler {:output-to "js/markdown.js"
:optimizations :advanced
:pretty-print false}}
:dev
{:compiler {:optimizations :whitespace
:pretty-print true}}}}
I specify the :crossover-path, note that this path has to be different from your :source-paths or the files there will be overwritten.
Next, I added the :corssover-jar true to indicate that I wish the crossover namespaces to appear in the resulting jar.
I also added :jar true to the :main section of the :builds. This is needed to include the namespaces in the src-cljs source directory.
Finally, you also need to include :clojurescript? true in project.clj to indicate that the project contains ClojureScript sources. Here's the complete project file that I'm using:
(defproject markdown-clj "0.9.25"
:clojurescript? true
:description "Markdown parser"
:url "https://github.com/yogthos/markdown-clj"
:license {:name "Eclipse Public License"
:url "http://www.eclipse.org/legal/epl-v10.html"}
:dependencies [[org.clojure/clojure "1.5.1"]
[criterium "0.3.1" :scope "test"]]
:plugins [[lein-cljsbuild "0.3.2"]]
:hooks [leiningen.cljsbuild]
:test-selectors {:default (complement :benchmark)
:benchmark :benchmark
:all (constantly true)}
:cljsbuild
{:crossovers [markdown.transformers]
:crossover-path "crossover"
:crossover-jar true
:builds {:main
{:source-paths ["src-cljs"]
:jar true
:compiler {:output-to "js/markdown.js"
:optimizations :advanced
:pretty-print false}}
:dev
{:compiler {:optimizations :whitespace
:pretty-print true}}}})
The resulting jar will contain all your clj and cljs files along with the crossover namespaces.
For me, being able to manage dependencies using Leiningen is a definite killer feature when it comes to ClojureScript.
I was recently asked to review the Clojure Data Analysis Cookbook. Data analysis happens to one of the major niches where Clojure has been gaining popularity. However, the documentation on the subject is far from focused.
The book provides a collection of recipes for accomplishing common tasks associated with analyzing different types of data sets. It starts out by showing how to read data from a variety of sources such as JSON, CSV, and JDBC. The next chapter provides a number of examples of how to sanitize the collected data and sample large data sets. After covering loading and sanitizing the data, the book discusses a number of different strategies for processing it.
Some of the highlights include using the Clojure STM, parallel processing of the data, including useful tricks for partitioning, using reducers, and distributed processing with Hadoop and Casalog.
I found the sections on handling large amounts of data particularly interesting. Often times, it's easy to come up with a solution that works for a small data set, but doesn't scale to handle large amounts of data. One of the techniques the book discusses is the use of lazy sequences. Another example is using heuristics to decide how to partition large data sets data sets effectively.
The book closes with a chapter dealing with the presentation the processed data. First, it covers using Incanter charts and then shows how to display the results in the browser with ClojureScript and NVD3.
For the most part, the book is very much example oriented. The examples are accompanied by explantation of how they all fit together. If you're like me and like to get hands on experience then I think you'll like the style of the book.
The examples are short in size and easy to understand. I found that the best way to work through the book was by following along with a REPL.
The book also introduces the reader to a number of libraries. Some, such as Incanter are well known, while others like parse-ez less so. In my experience, the documentation for many Clojure libraries is often lacking. The recipes in the book serve as a good reference for how to make the most of the tools available.
I would say one missed opportunity in the book is that the examples don't seem to build on each other. You'll see many examples of doing specific tasks, but they will tend to be self contained and don't build up to anything more substantial.
I suspect this was done in order to keep content accessible so that the reader can look at any section without having to have read the others. Conversely, don't expect to see examples of how to structure your projects and build applications end to end.
Overall, I would say this book is aimed at somebody who is already comfortable using Clojure and would like to learn some of the more advanced techinques for working with data processing and analysis. If you're thinking of using Clojure for analyzing your data sets this book will likely save you a lot of time and serve as a handy reference down the road.
Introducing cljs-ajax
(iterate think thoughts) 09 04 2013
I recently started working on a project using ClojureScript and it's turning out to be a really good experience so far. I've been using Domina and Dommy for DOM manipulation and templating. Both libraries are very easy to use and provide all the functionality needed for common operations.
Surprisingly, I didn't find any up to date libraries for handling Ajax. The only one I could find is fetch. Unfortunately, it depends on Noir which is no longer maintained.
I ended up writing a wrapper for goog.net.XhrIo called cljs-ajax. It provides an API similar to clj-http and handles all the nitty gritty details for you.
Currently, the API provides ajax-request, GET, and PUT functions. The ajax-request function accepts the following parameters:
uri- the URI for the requestmethod- a string representing the HTTP request type, eg: "PUT", "DELETE", etc.format- a keyword indicating the response format, can be either:jsonor:edn, defaults to:ednhandler- success handler, a function that accepts the response as a single argumenterror-handler- error handler, a function that accepts a map representing the error with keys:statusand:status-textparams- a map of params to be sent to the server
The GET and POST are helper functions that accept a URI followed by a map of options containing any of the following keys:
:handler- the handler function for successful operation should accept a single parameter which is the deserialized response:error-handler- the handler function for errors, should accept a map with keys:statusand:status-text:format- the format for the response:ednor:jsondefaults to:edn:params- a map of parameters that will be sent with the request
Here's some example usage:
(ns foo
(:require [ajax.core :refer [GET POST]]))
(defn handler [response]
(.log js/console (str response)))
(defn error-handler [{:keys [status status-text]}]
(.log js/console
(str "something bad happened: " status " " status-text)))
(GET "/hello")
(GET "/hello" {:handler handler
:error-handler error-handler})
(POST "/hello")
(POST "/send-message"
{:params {:message "Hello World"
:user "Bob"}
:handler handler
:error-handler error-handler})
(POST "/send-message"
{:params {:message "Hello World"
:user "Bob"}
:handler handler
:format :json
:error-handler error-handler})
The latest version of Luminus comes packaged with a ClojureScript example when the +cljs option is selected. Let's create a new project called ajax-example and take a look at how it works:
lein new luminus ajax-example +cljs
The project.clj will contain the dependencies for Domina, Dommy, and cljs-ajax as well as a cljsbuild configuration. The current version of cljsbuild references an old version of ClojureScript, so the latest version is also explicitly included as a dependency.
In order to use the ClojureScript from our page we'll first need to compile it. This is done by running lein cljsbuild once. The resulting artifact will be placed under resources/public/js/site.js as specified in the cljsbuild section of the project.
You'll notice that the build takes a while to run. Luckily, if we run it using lein cljsbuild auto it will run much faster and any time we make changes to any of the ClojureScript namespaces they will trigger an incremental build.
Working with the auto build running is nearly as seamless as working with plain old JavaScript. You make a change in the source, save, and reload the page. The compilation step tends to take under a second, so the intermediate delay is barely noticeable.
Our project has a source directory called src-cljs where ClojureScript namespaces live. It contains a file called main.cljs. This example illustrates using GET and POST calls to interact with the server as well as rendering DOM elements. Let's take a look inside it:
(ns cljs-test.main
(:require [ajax.core :refer [GET POST]]
[domina :refer [value by-id destroy-children! append!]]
[domina.events :refer [listen!]]
[dommy.template :as template]))
(defn render-message [{:keys [message user]}]
[:li [:p {:id user} message " - " user]])
(defn render-messages [messages]
(let [messages-div (by-id "messages")]
(destroy-children! messages-div)
(->> messages
(map render-message)
(into [:ul])
template/node
(append! messages-div))))
(defn add-message [_]
(POST "/add-message"
{:params {:message (value (by-id "message"))
:user (value (by-id "user"))}
:handler render-messages}))
(defn ^:export init []
(GET "/messages" {:handler render-messages})
(listen! (by-id "send")
:click add-message))
Here, we have a couple of functions to render the messages we receive from the server. The render-message function accepts a map with the keys message and user and creates a list item. The render-messages will create a list from the messages and render it using template/node function. The rendered messages will be appended to the div with the id messages using the append! function.
Next, we have a function to add a a new message. It grabs the values from elements selected by their ids and sends them as params named message and user. The server responds with a list of current messages. So we use render-messages as the response handler.
In our init function, we send a GET request to grab the current messages, then we bind the add-message function to the button with the id send.
On the server side we have a ajax-example.routes.cljsexample namespace. It provides the routes to render the page and handle the /messages and /add-message operations.
(ns ajax-example.routes.cljsexample
(:require [compojure.core :refer :all]
[noir.response :as response]
[ajax-example.views.layout :as layout]))
(def messages
(atom
[{:message "Hello world"
:user "Foo"}
{:message "Ajax is fun"
:user "Bar"}]))
(defroutes cljs-routes
(GET "/cljsexample" [] (layout/render "cljsexample.html"))
(GET "/messages" [] (response/edn @messages))
(POST "/add-message" [message user]
(response/edn
(swap! messages conj {:message message :user user}))))
As you can see, the routes simply return EDN responses to the client. Finally, we have the template for the actual example page, that looks as follows:
{% extends "cljs_test/views/templates/base.html" %}
{% block content %}
<br/>
<div id="messages"></div>
<textarea id="message"></textarea>
<br/>
<input type="text" id="user"></input>
<br/>
<button id="send">add message</button>
<!-- scripts -->
<script type="text/javascript" src="js/site.js"></script>
<script type="text/javascript">
cljs_test.main.init();
</script>
{% endblock %}
The page references the site.js script that will be output by the compiler and calls the init function that we saw above.
Overall, I feel that ClojureScript is rapidly becoming a viable alternative to using JavaScript on the client. There are still some rough edges, but most things work out of the box and you get many of the same benefits associated with using Clojure on the server.
a book is coming
(iterate think thoughts) 23 03 2013
First of all, I'd like to thank all those who've helped with Luminus. Since the original release on Clojars at the end of December there's been over 700 downloads, and the framework site has over 3,500 unique visits!
There's also been many contributions for improved documentation, template fixes, and lib-noir improvements. I'm really thankful for all the help improving the framework and moving it forward. I'd especially like to thank Ed Tsech, who's been toiling on it with me for the last few months. :)
I'm really glad to be able to contribute to popularizing the language and making it more accessible. On that note I have some exciting news. I've recently got signed by the The Pragmatic Programmers to write a book on web development using Clojure.
There is a number of books discussing the fundamentals of Clojure as a language. However, none of the books focus on applying these fundamentals to building real-world solutions. Respondents of the 2012 State of Clojure survey indicated that there still exists a gap in traditional documentation. Specifically, an interest in current tools, libraries, and best practices is not being met. It is my goal to help fill this gap.
I will provide an overview of Clojure as a web development platform, highlighting exactly what makes it so effective. The book will take a tutorial-focused approach to building a production-ready web application from conception to deployment.
The target audience is anyone interested in using Clojure as a web development platform. This includes: those who are currently using the JVM for development; Ruby and Python users who would like to take advantage of the breadth of features and libraries offered by the JVM; and readers simply interested in learning how to develop web applications using Clojure.
I'm quite thrilled about this project and I hope to write the book I wish I had when I spent countless hours googling for tutorials and examples. :)
I'm happy to announce that Luminus now defaults to using Clabango for HTML templating instead of Hiccup.
I'd like to explain some of the reasoning behind this decision. The primary drive behind Luminus is to make Clojure web development more accessible. This means that the barrier to entry for those who are new to the language should be as low as possible.
Since Clabango is based on the Django templates, it's immediately familiar to anybody who's done templating with other frameworks such as Django, Rails, or JSP. This also makes it easier to migrate exiting sites to use Luminus.
Because the templates are written in plain HTML it's easy to work with designers and other people who aren't versed in Clojure.
Finally, Clabango enforces the separation between the application logic and the presentation. When using Hiccup it's for one to start bleeding into the other if you're not careful.
However, if you are a fan of Hiccup there's nothing to worry about. Everything will work as it did before if you use the +hiccup flag when creating the application.
As always feedback and suggestions are most welcome. :)
Update: Selmer is currently the recommended Django style templating engine
As you may know, there are a few Clojure templating engines floating around. The two most popular ones are probably Hiccup and Enlive.
Hiccup is a nice and simple templating engine. Unfortunately, its biggest advantage is also it's greatest weakness. Since Hiccup templates are written using Clojure data structures, they're simply part of your regular code.
This makes the templates inaccessible to people not versed in Clojure. For example, if you're working with a designer, you can't just give them your template to work with.
Another issue is that it makes it easy for your frontend and backend logic to bleed into each other if you're not careful. Finally, you have to redeploy your site any time you wish to make a change to the layout.
Enlive avoids these problems by using a more traditional approach and using plain HTML markup for its templates. The problem with Enlive lies in its complexity. This spawned Laser, which also allows using pure HTML without any additional markup for its templates. In the words of the author:
Enlive does its job and is the precursor to the way laser does things. However, it is very large and (arguably?) complex compared to laser. laser strives to be as simple as possible.
If you haven't already checked out Laser I certainly urge you to do so!
However, the engine I'd like to focus on in this post is Clabango. It's modeled after Django's templating library and I found that it clicked with me immediately.
Let's take a look at how to convert the example guestbook application from Luminus to use Clabango instead of Hiccup.
We'll first create the project with support for H2 embedded DB by running:
lein new luminus guestbook +h2
We'll then open up our project.clj and add the Clabango [clabango "0.5"] dependency it.
Next, we'll create a templates folder under resources/public. This is where all the Clabango templates will live.
Clabango provides two way to load templates using the clabango.parser namespace. We can either use render-file function to load a template from a file or render to load it from a string.
These functions take two parameters, the template source and a map containing the items that will be populated in the template when it's compiled.
For example, if we had a template such as:
<h2>Hello {{user}}</h2>
We could then render it by calling render as follows:
(render "<h2>Hello {{user}}</h2>" {:user "John"})
Clabango will then replace every occurance of {{user}} with John instead. In case user happens to be a map, we can access its keys using the dot notation:
<h2>Hello {{user.last}}", " {{user.first}}</h2>
The templates provide support for some other useful things like filters, tag definitions, and template inheritance. However, we won't worry about any of that right now.
Let's take a look how to load up the templates using the render function. We won't use render-file since it looks for resources relative to the src folder. We'll use lib-noir.io/slurp-resource to load our templates from the public folder instead. We'll create a helper in our guestbook.util namespace to do that:
(ns guestbook.util
(:require ...
[clabango.parser :as parser]))
(defn render [template params]
(parser/render (io/slurp-resource template) params))
With that out of the way, let's create the model for our application. We'll open up the guestboook.models.schema namespace and replace create-users-table with create-guestbook table:
(defn create-guestbook-table []
(sql/with-connection
db-spec
(sql/create-table
:guestbook
[:id "INTEGER PRIMARY KEY AUTO_INCREMENT"]
[:timestamp :timestamp]
[:name "varchar(30)"]
[:message "varchar(200)"])
(sql/do-commands
"CREATE INDEX timestamp_index ON guestbook (timestamp)")))
then update create-tables to call it instead:
(defn create-tables
"creates the database tables used by the application"
[]
(create-guestbook-table))
We'll also update the init function in the guestbook.handler to call create-tables if the database isn't already initialized:
(defn init []
(if-not (schema/initialized?) (schema/create-tables))
(println "guestbook started successfully..."))
Next, let's open up the guestbook.models.db namespace and replace the code to create and retrieve users with the code to save and load messages:
(ns guestbook.models.db
(:use korma.core
[korma.db :only (defdb)])
(:require [guestbook.models.schema :as schema]))
(defdb db schema/db-spec)
(defentity guestbook)
(defn save-message
[name message]
(insert guestbook
(values {:name name
:message message
:timestamp (new java.util.Date)})))
(defn get-messages []
(select guestbook))
We can test that everything works by calling save-message from the REPL to create some messages and then calling get-messages to see that they're retrieved correctly. If everything works as expected then we're ready to take a look at making our pages.
First, let's create a template for the home page. We'll do this by making a welcome.html file under the resources/public/templates folder.
Here is where we finally get to see Clabango in action. We'll first use it to iterate the messages and create a list from them:
<ul>
{% for item in messages %}
<li>
<blockquote>{{item.message}}</blockquote>
<p> - {{item.name}}</p>
<time>{{item.timestamp}}</time>
</li>
{% endfor %}
</ul>
As you can see above, we use a for iterator to walk the messages. Since each message is a map with the message, name, and timestamp keys, we can access them by name.
Next, we'll add an error block for displaying errors that might be populated by the controller:
{% if error %}
<p>{{error}}</p>
{% endif %}
Here we simply check if the error field was populated and display it. Finally, we'll create a form to allow users to submit their messages:
<form action="/" method="POST">
<p>Name: <input type="text" name="name" value={{name}}></p>
<p>Message: <input type="text" name="message" value={{message}}></p>
<input type="submit" value="comment">
</form>
This takes care of creating the template, now let's take a look at how we populate the templated fields in our controller.
We'll navigate to the guestbook.routes.home namespace and update our home function to render the template when called:
(defn home-page [& [name message error]]
(layout/common
(util/render "/templates/welcome.html"
{:error error
:name name
:message message
:messages (db/get-messages)})))
Above, we simply create a map with all the fields we wish to populate. Then we pass it along with the name of the template file to the render function we defined earlier. Note that we can keep using the Hiccup layout to create the skeleton for the pages. The rest of the code in the home namespace stays the same as it was:
(defn save-message [name message]
(cond
(empty? name)
(home-page name message "Some dummy who forgot to leave a name")
(empty? message)
(home-page name message "Don't you have something to say?")
:else
(do
(db/save-message name message)
(home-page))))
(defroutes home-routes
(GET "/" [] (home-page))
(POST "/" [name message] (save-message name message))
(GET "/about" [] (about-page)))
As you can see, Clabango is very simple to use and allows cleanly separating your markup from your controllers. I think it's an excellent addition to the ever growing Clojure toolbox.
Complete sources for this post are available here.
update
The approach I took with putting templates under the resources folder will not work with template inheritance. So, you're best off simply using render-file from Clabango and keeping your templates under the src folder.
lib-noir updates
(iterate think thoughts) 24 02 2013
I've had a bit of time to hack on lib-noir recently. Specifically, I decided to update the handling of access rules.
Previously, you could use wrap-access-rules by passing one or more rule functions. Each function would accept a method, url, and params and return a boolean indicating whether the rule is satisfied. Using these functions the wrapper would then decide wether the page should be displayed or if the client will be redirected to "/".
This was serviceable for doing some basic restrictions, like making pages private where a rule would check if a user was in the session:
(defn private-page [method url params]
(session/get :user))
However, it provided no way to redirect to a different URIs based on what rules failed. The update allows using multiple wrap-access-rules wrappers each redirecting to its own redirect URI, as follows:
(-> handler
(wrap-access-rules rule1)
(wrap-access-rules {:redirect "/unauthorized"} rule2 rule3))
The first set of rules that fails will redirect to its redirect target, defaulting to "/" if none is provided. This way we can create rule groups each having different behaviours.
Another addition is the noir.util.route/access-rule macro. The macro accepts a URI pattern and a condition. The condition is only checked if the URI of the page being checked matches the pattern.
The macro implicitly defines the method, url, and params variables, so they can be used by the logic in the condition:
(def private-pages
(access-rule "/private/:id" (= (session/get :user) (first params))))
The above rule will only be triggered for pages matching the "/private/:id" pattern. Hopefully, the new additions will make it easier to work with access rules in lib-noir. Complete documentation for the feature is available at Luminus.
I'm also interested in hearing any feedback and suggestions regarding the current implementation. :)
update
After a bit of discussion with Ed Tsech, we decided that it would be better to make the parameters to the access-rule explicit.
So, now instead of defining access-rule by simply providing the URL pattern and a condition, you would also pass the arguments vector with the method, url, and params:
(def private-pages
(access-rule "/private/:id" [_ _ params]
(= (session/get :user) (first params))))
While it's slightly more verbose, it's a lot less magical and there's no risk of the macro masking any variables in scope.
These are some notes to myself on how I would like to approach my work, at least, an ideal for who I would like to be as a Christian web developer. I write this mostly to organise my own thoughts, but I am publishing it just in case there are others who might find it helpful.
The latest release of Luminus is no longer using a custom server.clj which starts up Jetty using run-jetty. Instead, it now relies on lein-ring, which in turns uses ring-server to create the server.
Snice you no longer have a -main in the project, you can't use lein run to start it up for development. Instead, use lein ring server, which will run Jetty for you.
If you need to start the server from within a REPL, then you can use the new repl namespace, which provides start-server and stop-server functions.
When you're packaging the application as a standalone, you run would now run lein ring uberjar instead of lein uberjar. The -main will be created by lein-ring for you based on the handler specified in your project.clj.
This means that all the configuration now lives under project.clj and gets picked up consistently both in development and production modes.
The new changes also simplify Heroku deployment. You no longer need to specify +heroku, the application will have all the necessary settings to run on Heroku out of the box.
Finally, I dropped support for Leiningen 1.x as it doesn't have support for profiles. There's no good reason to continue using it instead of upgrading to 2.x.
Luminus progress report
(iterate think thoughts) 08 01 2013
The work on the framework continues steadily, and I've been integrating some of the feedback I got on the initial release.
I quickly discovered that simply using different files for template modules is insufficient. Many features need to update the project.clj with dependencies or other options.
To deal with this I made a util which reads in the project file and injects dependencies, plugins and other options. Now each plugin can add its own project elements independently of others.
I'm considering taking the same approach to managing the layout as well. For example, if bootstrap support was selected, then its js/css would be included in layout/common. Another use case would be to update the application routes if a module provided some new routes of its own.
I'd also like to highlight some of the additions to lib-noir. There are several new namespaces, such as noir.util.cache, noir.io, and noir.util.route. Let's take a look at each of these in turn.
Caching
Basic caching is provided via noir.util.cache. Cache allows wrapping any expr using (cache id expr), and the expr will only be evaluated if it's not found in the cache or if the cache has been invalidated. In case expr throws an exception the current cached value will be kept.
There are a couple of helpers for invalidating the cache. First, there's invalidate-cache!, which takes a key and removes it from the cache. Then, there's clear-cache! which removes all currently cached items.
It's also possible to set the timeout for cached items using set-cache-timeout! and passing it a value in seconds. If an item remains in the cache longer than the timeout, the cache will attempt to refresh the value by running the expr associated with the item.
Finally, you can set the maximum size of the cache by calling set-cache-size!, when the cache grows past the specified size, oldest items will be removed to make room for new ones.
I'm currently using the cache in Luminus for the documentation pages. Luminus fetches the documentation from github as markdown and then translates it to HTML. This is slow enough to be noticeable to the user. On top of that, github is known to have an occasional outage or two. :)
With this scheme, I can keep the docs up to date without having to redeploy the site, and I don't have to worry about the latency or github uptime.
IO
The noir.io namespace provides some helper functions to make it easier to handle static resources.
You can get the absolute path to the public directory of your application by calling resource-path.
If you need to read a file located in the public folder you can get a URL for the resource by calling get-resource and provided the path relative to the public directory.
If the resource is a text file, such as a markdown document, you can use slurp-resource to read it into a string.
Another addition is the upload-file function which saves the file generated by a multipart/form-data form POST to a path relative to the public folder. An example can be seen here:
(ns myapp.upload
...
(:require [noir.io :as io]))
(defn upload-page []
(common/layout
[:h2 "Upload a file"]
(form-to {:enctype "multipart/form-data"}
[:post "/upload"]
(file-upload :file)
(submit-button "upload"))))
(defn handle-upload [file]
(upload-file "/uploads" file)
(redirect
(str "/" (session/get :user) "/" (:filename file))))
(defroutes upload-routes
(GET "/upload" [] (upload-page))
(POST "/upload" [file] (handle-upload file)))
Access rules
Noir used to have a pre-route macro, which allowed for filtering and redirecting based on some rules.
Now, lib-noir provides a restricted macro which provides similar functionality.
You can define access rules as functions which accept the method, url, and params. The function then returns a boolean to indicate if the rule succeeded or not.
For example, if we wanted to restrict access to a page so that it's only accessible if the id in session matches the id in the page, we could write a rule like this:
(defn user-page [method url params]
(and (= url "/private/:id")
(= (first params) (session/get :user))))
Then we wrap our handler in wrap-access-rules middleware. The middleware accepts one or more access rule functions, and checks if restricted pages match any of the rules provided.
(def app (-> all-routes
(middleware/app-handler)
(middleware/wrap-access-rules user-page)))
With that in place, we can restrict access to our page as follows.
(restricted GET "/private/:id" [id] "private!")
Note that, you have to use noir.util.middleware/app-handler for wrap-access-rules to work correctly. Or manually bind the noir.request/*request*, eg:
(defn wrap-request-map [handler]
(fn [req]
(binding [noir.request/*request* req]
(handler req))))
update I've since made wrap-request-map public in lib-noir, so if you need to wrap the request for any reason, you don't need to roll your own.
I hope you find the new features useful, and as always I'm open to feedback and suggestions for improvements as well as new features.
Luminus progress updates
(iterate think thoughts) 28 12 2012
In this post I'd like to give some updates on the progress of Luminus and the direction it's moving in.
I've had some great chats over at #clojure on IRC, and there's been lots of ideas and brainstorming. It's a very friendly and informative place if you haven't yet visited. :)
After talking it over with Raynes we decided that it would be much better to simply add things to lib-noir than to roll a new library. So, lib-luminus is no more, and instead all the updates will be happening in lib-noir now.
All the current helper functions have already been rolled into version 0.3.0 of lib-noir, so definitely switch to it if you're using lib-luminus currently. The good news is that all you need to do is replace [lib-luminus "0.1.5"] with [lib-noir "0.3.0"] in your project.clj`, and update your namespaces to reference it instead. The function names and behaviour haven't changed.
This segues into the next topic of how the line is drawn between what goes into the library and what belongs in the template.
The strategy here is to add functionality to `lib-noir, while putting configuration in the template. This facilitates an easy path for upgrades as the library continues to improve and evolve, while keeping all the customization in the hands of the user. It also means that the template will act as documentation for how to configure your application.
As the template continues to grow, it will be increasingly difficult to please everybody with a single template. For example, somebody might want to use PostreSQL for their db, while another person might like MySQL, and yet another uses CouchDB and doesn't want to see any of the SQL business at all.
As these things tend to be rather polarizing, the approach will be to let people choose the items they want. Luminus aims to be more of a buffet, where you pick what's on your plate, as opposed omakase with the chef telling you what to eat. :)
To this end, the latest release of Luminus provides a base template which can be extended using +feature notation. Currently, there's two features supported, the first is the addition of bootstrap into the project and the second is support for SQLite.
The way this works is if you want to make a basic application, you'd do the same thing you did before.
lein new luminus myapp
But if you wanted to have bootstrap in your app, then you'd simply do this:
lein new luminus myapp +bootstrap
The best part is that you can mix different extensions together, eg:
lein new luminus myapp +bootstrap +sqlite
When you do that, both features will be added to the resulting project. However, if they have any common files between the two features, then the latest one overwrites the former.
Hopefully, this approach will provide an easy way to add extended configuration while keeping things compartmentalized and easy to maintain. The latest documentation and examples are available at the official Luminus site.
Since the retirement of Noir, there aren't any batteries included web frameworks for Clojure. As I mentioned in an earlier post, moving to Compojure is fairly painless. However, you still have to put a lot of things together by hand.
I suspect this isn't a problem for most people who've already been doing Clojure development. However, it can be daunting for beginners and it also means having to write a lot of boiler plate when making a new site.
I decided to see if I could tie some common libraries together to provide a more comprehensive solution for creating web applications in Clojure. This led to the creation of the Luminus framework, which follows in footsteps of Noir in attempting to make web development in Clojure an easy and accessible experience.
The framework consists of two parts, first is the lib-luminus, which provides some useful utility functions, which I found to be helpful when writing applications. The second is the luminus-template, which is used to generate the base application.
The resulting app is ready to be run standalone or deployed as a war. It can also be run on Heroku by following the steps in the official documentation.
The application generated by the template can be easily modified to fit your needs and shouldn't be any more restrictive than a standard Compojure app. This avoids some of the issues with Noir, where things like using custom middleware were problematic.
The documentation site for Luminus is built using the framework in the spirit of eating my own dog food, and its source is available on github as well.
Hopefully this will be useful in helping people get started. I intend to continue working on it and I'm always open to suggestions, patches, and collaboration. :)
If you've used Leiningen before, you've already seen templates in action. When you create a project using lein new myproject, you end up with a project folder with a namespace called myproject and a core.clj inside it.
The templates are really useful if you need to setup some common boilerplate for your project. In the last post I referenced a template for Compojure, which creates a new batteries included project.
Leiningen uses the lein-newnew plugin for this task. All you have to do to create a new template is to run lein new template <template name>. In my case I created a template called compojure-app:
lein new template compojure-app
As all Leiningen projects, it will contain the project.clj, which will contain the description for our project:
(defproject compojure-app/lein-template "0.2.7"
:description "Compojure project template for Leiningen"
:url "https://github.com/yogthos/compojure-template"
:eval-in-leiningen true
:license {:name "Eclipse Public License"
:url "http://www.eclipse.org/legal/epl-v10.html"}
:dependencies [[leinjacker "0.2.0"]])
It looks like a regular project file, except for the eval-in-leiningen key which causes Leiningen to launch a subprocess prevents Leiningen from launching a separate process for the given project during the build time.
The actual template resides under
src/compojure-template/leiningen/new/compojure_app.clj
It looks as follows:
(ns leiningen.new.compojure-app
(:use [leiningen.new.templates :only [renderer sanitize year ->files]]
[leinjacker.utils :only [lein-generation]]))
(def project-file
(if (= (lein-generation) 2)
"project_lein2.clj"
"project_lein1.clj"))
(defn compojure-app
"Create a new Compojure project"
[name]
(let [data {:name name
:sanitized (sanitize name)
:year (year)}
render #((renderer "compojure_app") % data)]
(println "Generating a lovely new Compojure project named" (str name "..."))
(->files data
[".gitignore" (render "gitignore")]
["project.clj" (render project-file)]
["README.md" (render "README.md")]
["src/{{sanitized}}/handler.clj" (render "handler.clj")]
["src/{{sanitized}}/server.clj" (render "server.clj")]
["src/{{sanitized}}/common.clj" (render "common.clj")]
["resources/public/css/screen.css" (render "screen.css")]
"resources/public/js"
"resources/public/img"
"src/{{sanitized}}/models"
["test/{{sanitized}}/test/handler.clj" (render "handler_test.clj")])))
The compojure-app function is where all the fun happens, and it's what gets called when we run lein new compojure-app myapp to create an application using this template.
The function is mostly self explanatory. It uses the render function from leiningen.new.templates to take the template files and put them at the specified path. The {{sanitized}} tag ensures that the generated names for the package folders are valid.
Our template files live under
src/compojure-template/leiningen/new/compojure_app
and they don't need to have the same folder structure as the resulting project. As you can see above, we specify the resulting path explicitly in our template.
The template files look exactly like any regular Clojure source file, except for the {{name}} anchor. This will be replaced with the name of the application we specified when creating the project. Here's the common.clj template as an example:
(ns {{name}}.common
(:use [hiccup.page :only [html5 include-css]]))
(defn layout [& body]
(html5
[:head
[:title "Welcome to {{name}}"]
(include-css "/css/screen.css")]
(into [:body] body)))
Every occurrence of {{name}} will be replaced with myapp instead and we'll have our namespace and greeting customized.
Once you've created your template, you'll need to install it using lein install and then add it as a plugin to your profile under ~/.lein/profiles.clj using the following format:
{:user
{:plugins [[compojure-app/lein-template "0.2.7"]]}}
That's it, you can now use your new template and never have to write boilerplate for this kind of project again.
If you wish to make your template available to others you can publish it to Clojars by running lein deploy clojars from the console.
Any template published on Clojars can be used directly without needing to add it to your plugins in the profiles.clj as shown above.
The complete source for the template discussed in this post is available here.
Moving to Compojure
(iterate think thoughts) 15 12 2012
It was recently announced that Noir is being deprecated. The primary reason cited is that it simply doesn't add a lot of useful functionality over what's already available in Compojure and makes it difficult to integrate other middleware, such as friend.
The useful parts of Noir have been moved to lib-noir. Together, Compojure and lib-noir provide a very similar experience to what you're already used to if you've been using Noir up to now.
There are some differences of course. The main one is that instead of using the defpage macro, you would now declare your routes using defroutes.
So, if you previously had something like the following:
(defpage "/" []
(common/layout
(form-to [:post "/"]
(text-area {:placeholder "say something..."} "message")
[:br]
(text-field {:placeholder "name"} "id")
(submit-button "post message"))))
(defpage [:post "/"] params
(common/layout
[:p (:id params) " says " (:message params)]))
Noir would then create the GET and POST routes for "/" behind the scenes. With Compojure we'll have to define the routes explicitly using defroutes.
(defroutes app-routes
(GET "/" [] (message))
(POST "/" params (display-message params))
(route/resources "/")
(route/not-found "Not Found"))
Then, we'll write the message and display-message functions and put the logic for the pages in them.
(defn message []
(html5
[:body
(form-to [:post "/"]
(text-area {:placeholder "say something..."} "message")
[:br]
(text-field {:placeholder "name"} "id")
(submit-button "post message"))]))
(defn display-message [params]
(let [form-params (:form-params params)]
(html5
[:body
[:p (get form-params "id") " says " (get form-params "message")]])))
The Noir template comes with a common namespace which defines a layout macro, which we use to wrap our pages so that we don't have to keep typing in the boilerplate. We can easily write a helper function to do the same thing.
(ns myapp.common
(:use [hiccup.def :only [defhtml]]
[hiccup.page :only [include-css]]))
(defhtml layout [& body]
[:head
[:title "Welcome to myapp"]
(include-css "/css/screen.css")]
(into [:body] body))
The next difference is that our request map contains the complete request as opposed to just the form params as is the case with the one in defpage.
This means that we have to grab the :form-params key from it to access the form parameters. Another thing to note is that the parameter keys are strings, meaning that we can't destructure them using :keys.
This problem is also easily addressed by a macro which will grab the form-params and keywordize them for us. Note that the original request map will still be available as request in the resulting function.
(defmacro page [f form-params & body]
`(defn ~f [~'request]
(let [~form-params
(into {} (for [[k# v#] (:form-params ~'request)]
[(keyword k#) v#]))]
~@body)))
Now, we can rewrite our app as follows:
(page message []
(layout
(form-to [:post "/"]
(text-area {:placeholder "say something..."} "message")
[:br]
(text-field {:placeholder "name"} "id")
(submit-button "post message"))))
(page display-message {:keys [id message]}
(layout
[:p id " says " message]))
(defroutes app-routes
(GET "/" [] (message []))
(POST "/" params (display-message params))
(route/resources "/")
(route/not-found "Not Found"))
update
Turns out Compojure already provides the functionality provided by the page macro, and to get the form params, we can destructure them as follows:
(defn display-message [id message]
(layout [:p id " says " message]))
(defroutes app-routes
(POST "/" [id message] (display-message id message))
(route/not-found "Not Found"))
Big thanks to James Reeves aka weavejester on setting me straight there. :)
This is starting to look very similar to the Noir style apps we're used to. Turns out that migrating from Noir to Compojure is fairly painless.
If you use lib-noir when converting your existing Noir application, then the changes end up being minimal. You can continue using noir.crypt, noir.validation, and etc. as you did before. The only caveat is that you now have to remember to add the appropriate wrappers to your handler, eg:
(-> handler
(wrap-noir-cookies)
(session/wrap-noir-session
{:store (memory-store session/mem)})
(wrap-noir-validation))
One thing which Noir provided was a nice batteries included template. I created a similar one called compojure-app.
To use the template you can simply run:
lein new compojure-app myapp
The template sets up a project with a main, which can be compiled into a standalone using lein uberjar or into a deployable WAR using leing ring uberwar. The project is setup to correctly handle loading static resources located in resources/public and correctly handle the servlet context.
When run with lein run the project will pickup the dev dependencies and use the wrap-reload, so that changes to source are picked up automatically in the running app.
This should get all the boiler plate out of the way and let you focus on making your app just as you did with Noir. :)
ClojureScript Adventures
(iterate think thoughts) 26 10 2012
I finally got a chance to play around a bit more with ClojureScript. When I was updating markdown-clj to compile to it, the extent of interaction was to accept a markdown string and return the corresponding HTML.
This time around I decided to dive into doing interop with JavaScript and actual interaction with the page. I wrote a silly Tetris game a while back, and it seemed like a perfect fit for the task.
So, let's see what's involved in porting Clojure to ClojureScript and Canvas. First, I had to separate the pure Clojure code from any code which relies on Java interop. The original code can be seen here.
After, splitting it up, I ended up with a game namespace which contains the bulk of the game logic, and a core namespace containing all the logic pertaining to the UI and input. The split turned out to be fairly painless since I already had the game logic separated from UI in the original design.
Now it's time to add some ClojureScript to the project. First, we need to create a new source folder for the ClojureScript namespaces. In my project I called this folder src-cljs. Then we need some way to compile our script.
The easiest way to do that is to use the lein-cljsbuild plugin. With it you can specify the ClojureScript sources, Clojure namespaces you'd like to reference, and the output Js files to produce.
In my case the project file looks as follows:
(defproject tetris "0.1.0-SNAPSHOT"
:description "a simple Tetris game"
:url "https://github.com/yogthos/Clojure-Tetris"
:license {:name "Eclipse Public License"
:url "http://www.eclipse.org/legal/epl-v10.html"}
:dependencies [[org.clojure/clojure "1.4.0"]]
:plugins [[lein-cljsbuild "0.2.9"]]
:source-paths ["src"]
:main tetris.core
:cljsbuild {:crossovers [tetris.game]
:builds
[{:source-path "src-cljs"
:compiler
{:output-to "js/tetris.js"
:optimizations :advanced
:pretty-print false}}]})
All that's needed to include ClojureScript compilation is to add the lein-cljsbuild in the plugins and specify the options for the cljsbuild. The crossovers section specifies a vector of Clojure namespaces which will be included during compilation.
Once the project file is setup, we have two options for invoking ClojureScript compilation. We can either run lein cljsbuild once or lein cljsbuild auto. When using the auto option, the build will watch for changes in the source and automatically recompile the Js files as needed. This takes much less time than when compiling using the once option, and turns out to be quite handy for development.
The ClojureScript version of the UI, which uses the canvas, can be seen here .
Interacting with JavaScript turns out to be pretty simple and the syntax is similar to Java interop in Clojure. However, there are some differences which are worth mentioning.
Any standard Js functions can be accessed using the js namespace, for example if we want to make a logger which logs to the console we can write something like the following:
(defn log [& items]
(.log js/console (apply str items)))
This works exactly like the Java interop, where we denote methods by using the . notation and pass in the object as the first argument.
Exporting functions so that they're visible from JavaScript is also quite simple. Instead of denoting them with - as we do when we interop with Java, we use ^:export annotation:
(defn ^:export init []
(log "Hello ClojureScript!"))
One thing that's not obvious is the interaction with JavaScript object properties. To access these we use (.-property obj) notation. Where - indicates that we're referencing a property and not a function. Writing properties is accomplished by calling the set! function. Here's an example:
(defn ^:export init []
(let [canvas (.getElementById js/document "canvas")
ctx (.getContext canvas "2d")
width (.-width canvas)
height (.-height canvas)]
(log "width: " width ", height: " height)
;;set a property
(set! (.-fillStyle ctx) "black")
(.fillRect ctx 0 0 width height)))
Another quirk I ran into is that :use doesn't seem to work in the namespace declaration as it expects a collection.
For example, if you have the following setup:
(ns foo)
(defn bar [])
(ns hello
(:use foo))
(defn ^:export init []
(js/alert "Hello from ClojureScript!"))
the compiler throws the following error:
java.lang.UnsupportedOperationException: nth not supported on this type: Symbol
Fortunately, both (:use [foo :only [bar]]) and (:require foo) work as expected.
Finally, to make a timer, it's possible to use js/setTimeout and simply pass it the function to call after the timeout:
(declare game-loop)
(defn game-loop [state]
(if (not (:game-over state))
(js/setTimeout
(fn [] (game-loop (update-state state)))
10)))
Everything else appeared to work exactly as it does in Clojure itself. The only caveat when porting code is that it cannot contain any Java interop or use libraries which do so. In case of the game, I simply put the game logic into a shared namespace and wrote separate UI logic for both Java and JavaScript versions.
To try out the ClojureScript version simply grab tetris.js and tetris.html which expects the tetris.js file to be in the js folder relative to it.
One thing to note is that ClojureScript is definitely chunky compared to writing JavaScript by hand. The game weighs in at a hefty 100k. That said, it should be noted that jQuery weighs in about that as well, and nobody would claim that it's outrageous for a site to include it.
I feel that the benefits of ClojureScript offers far outweigh the downsides of its size. You get a much nicer language without all the quirks of working in JavaScript, immutability, persistent data structures, and the ability to easily share code between the server and the browser.
The good news is that ClojureScript is under active development, and performance and size are both targets for future improvement. As it stands I find it very usable for many situations.

making reporting easy
(iterate think thoughts) 17 10 2012
There are a bunch of reporting options out there, JasperReports is one popular example. While it's got a ton of features, it often involves a disproportionate amount of effort to create even the simplest of reports. Here's what's involved in simply printing out some fields from the database to a PDF.
Let's see if we can make things easier with Clojure. We'll produce the same report as the one in the linked example.
First, we'll create our database connection using java.jdbc.
(def db {:classname "org.postgresql.Driver"
:subprotocol "postgresql"
:subname "//localhost:5432/testdb"
:user "user"
:password "secret"})
then we'll make an employee table and populate it with the sample data
(defn create-employee-table []
(sql/create-table
:employee
[:name "varchar(50)"]
[:occupation "varchar(50)"]
[:place "varchar(50)"]
[:country "varchar(50)"]))
(sql/with-connection
db
(create-employee-table)
(sql/insert-rows
:employee
["Babji, Chetty", "Engineer", "Nuremberg", "Germany"]
["Albert Einstein", "Engineer", "Ulm", "Germany"]
["Alfred Hitchcock", "Movie Director", "London", "UK"]
["Wernher Von Braun", "Rocket Scientist", "Wyrzysk", "Poland (Previously Germany)"]
["Sigmund Freud", "Neurologist", "Pribor", "Czech Republic (Previously Austria)"]
["Mahatma Gandhi", "Lawyer", "Gujarat", "India"]
["Sachin Tendulkar", "Cricket Player", "Mumbai", "India"]
["Michael Schumacher", "F1 Racer", "Cologne", "Germany"]))
finally we'll write a function to read the records from the table.
(defn read-employees []
(sql/with-connection db
(sql/with-query-results rs ["select * from employee"] (doall rs))))
Let's run read-employees to make sure everything is working as expected, we should see something like the following:
(clojure.pprint/pprint (read-employees))
({:country "Germany",
:place "Nuremberg",
:occupation "Engineer",
:name "Babji, Chetty"}
{:country "Germany",
:place "Ulm",
:occupation "Engineer",
:name "Albert Einstein"}
...)
You'll notice that the result is simply a list of maps where the keys are the names of the columns in the table.
We're now ready to generate our report, clj-pdf provides a template macro, which uses $ to create anchors which are populated from the data using the keys of the same name.
The template returns a function which accepts a sequence of maps and applies the supplied template to each element in the sequence. In our case, since we're building a table, the template is simply a vector with the names of the keys for each cell in the row.
(def employee-template
(template [$name $occupation $place $country]))
if we pass our data to the template we'll end up with the following:
(employee-template (take 2 (read-employees)))
(["Babji, Chetty" "Engineer" "Nuremberg" "Germany"]
["Albert Einstein" "Engineer" "Ulm" "Germany"])
All that's left is to stick this data into our report:
(pdf
[{}
(into [:table
{:border false
:cell-border false
:header [{:color [0 150 150]} "Name" "Occupation" "Place" "Country"]}]
(employee-template (read-employees)))]
"report.pdf")
here's the result of running the above code, which looks just as we'd expect:
It only took a few lines to create the report and we can see and manipulate the layout of the report in one place. Of course, the template we used for this report was completely boring, so let's look at another example. Here we'll output the data in a list, and style each element:
(def employee-template-paragraph
(template
[:paragraph
[:heading $name]
[:chunk {:style :bold} "occupation: "] $occupation "\n"
[:chunk {:style :bold} "place: "] $place "\n"
[:chunk {:style :bold} "country: "] $country
[:spacer]]))
when writing the report, we can mix the templated elements with regular ones:
(pdf
[{:font {:size 11}}
[:heading {:size 14} "Employees Test"]
[:line]
[:spacer]
(employee-template-paragraph (read-employees))]
"report.pdf")
here's the new report with the fancy formatting applied to it:

I think that this approach provides a lot of flexibility while keeping things concise and clear. In my experience there are many situations where all you need is a simple well formatted report, and the effort to create that report should be minimal.
Why Christians should watch movies
James Sinclair 10 10 2012
Why would Christians watch movies at all? They are full of violence and bad language and plenty of other things we try to avoid. They are made by people who have completely different world views than our own, and disagree with most of the beliefs we hold most dear. Why would we fill our heads with all this simply for the sake of entertainment?
Liberator is a recent Clojure library for writing RESTful services. Its primary feature is that it puts strong emphasis on decoupling the front end and the back end of the application.
Conceptually, Liberator provides a very clean way to reason about your service operations. Each request passes through a series of conditions and handlers defined in the resource. These map to the codes specified by the HTTP rfc, such as 200 - OK, 201 - created, 404 - not found, etc. This makes it very easy to write standards compliant services and to group the operations logically.
While the official site has some fairly decent documentation, I found there were a few areas where I had to dig around and look through the source to figure out what to do.
In this post I'll walk you through the steps to create a simple application which serves static resources, provides basic session management, and JSON operations.
Our application will be structures as follows:
src/liberator_service
server.clj
resources.clj
static_resources.clj
ui.clj
resources/public
site.js
project.clj
Our project.clj will look as follows:
(defproject liberator-example "0.1.0-SNAPSHOT"
:description "Example for the Liberator library"
:url "https://github.com/yogthos/liberator-example"
:license {:name "Eclipse Public License"
:url "http://www.eclipse.org/legal/epl-v10.html"}
:dependencies [[org.clojure/clojure "1.4.0"]
[compojure "1.0.2"]
[liberator "0.5.0"]
[sandbar "0.4.0-SNAPSHOT"]
[org.clojure/data.json "0.1.2"]
[ring/ring-jetty-adapter "1.1.0"]]
:dev-dependencies [[lein-ring "0.7.3"]]
:ring {:handler liberator-service.server/handler}
:main liberator-service.server)
Now we'll take a look at the service namespace, in it we'll add the required libraries and create an atom to hold the session information.
(ns liberator-service.server
(:use [liberator.representation :only [wrap-convert-suffix-to-accept-header]]
[ring.middleware.multipart-params :only [wrap-multipart-params]]
ring.middleware.session.memory
sandbar.stateful-session
compojure.core
[compojure.handler :only [api]]
liberator-service.ui
liberator-service.resources
liberator-service.static-resources)
(:require
[ring.adapter.jetty :as jetty]))
(defonce my-session (atom {}))
Next we will define the routes which our application responds to. In our case we've defined routes for serving the home page, our services, and static content:
(defn assemble-routes []
(routes
(GET "/" [] home)
(POST "/login" [] login)
(POST "/logout" [] logout)
(GET "/resources/:resource" [resource] static)))
we'll also need to create a handler for the application:
(defn create-handler []
(fn [request]
((->
(assemble-routes)
api
wrap-multipart-params
(wrap-stateful-session {:store (memory-store my-session)})
(wrap-convert-suffix-to-accept-header
{".html" "text/html"
".txt" "text/plain"
".xhtml" "application/xhtml+xml"
".xml" "application/xml"
".json" "application/json"}))
request)))
The session handling in our handler is provided by the wrap-stateful-session from the sandbar library. The wrap-convert-suffix-to-accept-header is used by the Liberator to decide what types of requests it will accept. Finally, we'll create a main to run our service:
(defn start [options]
(jetty/run-jetty
(fn [request]
((create-handler) request))
(assoc options :join? false)))
(defn -main
([port]
(start {:port (Integer/parseInt port)}))
([]
(-main "8000")))
Next let's write a resource which will display a login page:
(ns liberator-service.ui
(:use hiccup.page
hiccup.element
hiccup.form
sandbar.stateful-session
[liberator.core :only [defresource]]))
(defresource home
:available-media-types ["text/html"]
:available-charsets ["utf-8"]
:handle-ok (html5 [:head (include-js
"http://ajax.googleapis.com/ajax/libs/jquery/1.8.0/jquery.min.js"
"/resources/site.js")]
[:body
[:div#message]
[:div#login
(text-field "user")
(password-field "pass")
[:button {:type "button" :onclick "login()"} "login"]]]))
Here we get a glimpse at how Liberator works. We use defresource to define the handler for the home route we specified earlier in our service. The resource specifies what media types it provides as well as the encoding for the content. If the handler is invoked successfully then the :handle-ok handler is called and its output is set as the body of the response. In our site.js we'll define login and logout functions which will use POST to call login and logout operations on the server:
function login() {
$("#message").text("sending login request");
$.post("/login",
{user: $("#user").val(), pass: $("#pass").val()},
function({window.location.reload(true);},
"json")
.error( function(xhr, textStatus, errorThrown) {
$("#message").text(textStatus + ": " + xhr.responseText);
});
}
function logout() {
$.post("/logout",
function() {window.location.reload(true);});
}
Since we reference a local JavaScript file, we'll need to create a handler to serve it. We'll create a static-resources namespace for this purpose:
(ns liberator-service.static-resources
(:use [liberator.core :only [defresource]]
[ring.util.mime-type :only [ext-mime-type]])
(:require [clojure.java.io :as io]))
(let [static-dir (io/file "resources/public/")]
(defresource static
:available-media-types
#(let [file (get-in % [:request :route-params :resource])]
(if-let [mime-type (ext-mime-type file)]
[mime-type]
[]))
:exists?
#(let [file (get-in % [:request :route-params :resource])]
(let [f (io/file static-dir file)]
[(.exists f) {::file f}]))
:handle-ok (fn [{{{file :resource} :route-params} :request}]
(io/file static-dir file)))
:last-modified (fn [{{{file :resource} :route-params} :request}]
(.lastModified (io/file static-dir file))))
When our home page requests /resources/site.js, this resource will set the mime type to "text/javascript" based on the extension of the file. It will check if the resource exists and the last modified time, and finally serve the resource in :handle-ok as needed.
Now let's create a resource which the client can call to login and create a session on the server. We'll put it in the resources namespace:
(ns liberator-service.resources
(:use clojure.data.json
sandbar.stateful-session
[liberator.core :only [defresource request-method-in]]))
For our testing, we'll simply create a dummy list of users and a helper to check if one matches our login params:
(def users [{:user "foo"
:pass "bar"
:firstname "John"
:lastname "Doe"}])
(defn valid-user [user]
(some #(= user (select-keys % [:user :pass])) users))
and now we'll create the login resource itself:
(defresource login
:available-media-types ["application/json" "text/javascript"]
:method-allowed? (request-method-in :post)
:authorized? (fn [{{user :params} :request}]
(or (session-get :user) (valid-user user)))
:post! (fn [{{{:keys [user]} :params} :request :as ctx}]
(session-put! :user user))
:handle-unauthorized (fn [ctx] (:message ctx))
:handle-created (json-str {:message "login successful"}))
Again, the above is fairly straight forward. We specify the media types the handler responds to, set it to allow the POST request type , check if the supplied user params are valid, and either create the user or return an error based on whether the :authorized? handler succeeds.
As I mentioned above, each handler responds to a specific HTTP code. For example, if :authorized? returns false then the code will be set to 401, which will cause :handle-unauthorized handler to be invoked. If :authorized? it true then the :post! handler gets called, and if it succeeds then subsequently:handle-created. Next we need a logout resource, and it looks as follows:
(defresource logout
:available-media-types ["application/json" "text/javascript"]
:method-allowed? (request-method-in :post)
:post! (session-delete-key! :user)
:handle-created (json-str {:message "logout successful"}))
You might have noticed that Liberator is pretty flexible regarding what you can supply as the handler. It can either be a callable function, an evaluated expression, or a value.
Now that we have a way for the user to login and logout, let's revisit our UI handler and update it to render different content based on whether there is a user in the session:
(ns liberator-service.ui
(:use hiccup.page
hiccup.element
hiccup.form
sandbar.stateful-session
liberator-service.resources
[liberator.core :only [defresource]]))
(defn get-user []
(first (filter #(= (session-get :user) (get-in % [:user])) users)))
(def login-page
[:body
[:div#message]
[:div#login
(text-field "user")
(password-field "pass")
[:button {:type "button" :onclick "login()"} "login"]]])
(defn home-page []
[:body
(let [{firstname :firstname lastname :lastname} (get-user)]
[:div#message (str "Welcome " firstname " " lastname)])
[:div#logout
[:button {:type "button" :onclick "logout()"} "logout"]]])
(defresource home
:available-media-types ["text/html"]
:available-charsets ["utf-8"]
:handle-ok (html5 [:head (include-js
"http://ajax.googleapis.com/ajax/libs/jquery/1.8.0/jquery.min.js"
"/resources/site.js")]
(if (session-get :user) (home-page) login-page)))
That's all there is to it. We have a page which checks if there is a user in the session, if there is then it dsiplays the content of the home-page and if not then the login-page content is displayed. The page interacts with the service by calling login and logout resources via Ajax.
Complete source for the example is available here.
Overall, I definitely think that Liberator makes writing RESTful applications easy and natural. This is a fairly different approach from Noir, where you think in terms of pages and simply implement the UI and the backend portion for each one.
While the Noir approach can easily result in tight coupling between the UI and the backend, the Liberator ensures that we're always thinking in terms of service operations whenever any interaction between the service and the client is happening.
Noir tutorial - part 7
(iterate think thoughts) 03 09 2012
In the last part of the tutorial we saw how we can use a request handler wrapper to fix the redirect URLs. There is another option for doing this that I'd like to mention.
As we've seen, the defpage params only contain form parameters, but there is a way to access the complete parameter map provided by ring using the noir.request/ring-request helper.
If the application is running on a servlet its context will show up in this map and we can use it in our redirects. We can write a simple macro called local-redirect which will do this for us:
(defmacro local-redirect [url]
`(noir.response/redirect
(if-let [context# (:context (noir.request/ring-request))]
(str context# ~url) ~url)))
The advantage to this approach is that we do not try to infer if the redirect is supposed to be local or not. If we want to redirect to the local servlet context we can do it explicitly, and if we wish to do an absolute redirect then we can use the noir.response/redirect directly.
With that out of the way, I'd like to cover using the servlet init function and accessing files located on the classpath of the servlet. This allows us to run a function once when our serlvet starts up.
For example, we might want to read in a configuration file and setup some environment parameters based on it. To do that we'll open up our project.clj and add an :init key to our map or ring parameters:
(defproject my-website "0.1.0-SNAPSHOT"
:description "my Noir website"
:dependencies [[org.clojure/clojure "1.4.0"]
[noir "1.3.0-beta3"]
[org.clojure/java.jdbc "0.2.3"]
[postgresql/postgresql "9.1-901.jdbc4"]
[joda-time "2.0"]]
:dev-dependencies [[lein-ring "0.7.3"]]
:ring {:handler my-website.server/handler
;;initialization function which will be run
;;once when the servlet is loaded
:init my-website.config/init-config}
:main my-website.server)
update: with Leiningen 2.0 you will need to use :plugins instead of :dev-dependencies to get lein-ring to work correctly:
(defproject my-website "0.1.0-SNAPSHOT"
:description "my Noir website"
:dependencies [[org.clojure/clojure "1.4.0"]
[noir "1.3.0-beta3"]
[org.clojure/java.jdbc "0.2.3"]
[postgresql/postgresql "9.1-901.jdbc4"]
[joda-time "2.0"]]
;;lein 2
:plugins [[lein-ring "0.7.5"]]
;;lein 1
:dev-dependencies [[lein-ring "0.7.3"]]
:ring {:handler my-website.server/handler
;;initialization function which will be run
;;once when the servlet is loaded
:init my-website.config/init-config}
:main my-website.server)
Now we'll create a new namespace which the :init key is pointing to, and create an init-config function in it:
(ns my-website.config
(:use clojure.java.io))
(defn init-config []
(println "servlet has been initialized"))
If you build and deploy the application, the "servlet has been initialized" message is printed in the server log once after deployment. Now, let's add a configuration file in our resources folder:
touch my_webapp/resources/site.config
When we run lein ring uberwar this file will be packaged under /WEB-INF/classes/ path in the servlet. To access this file we'll need to add the following function to our config namespace:
(def config-file "site.config")
(defn load-config-file []
(let [url (..
(Thread/currentThread)
getContextClassLoader
(findResource config-file))]
(if (or (nil? url)
(.. url
getPath
(endsWith (str "jar!/" config-file))))
(doto (new java.io.File config-file)
(.createNewFile))
url)))
The load-config-file function will get the context class loader and attempt to find the resource by name. If the resource is found we will get back a URL pointing to it. Unfortunately, if we're running as a standalone jar, we cannot modify the resource inside it. So, in case the URL is nil, meaning that the file was not found, or if it ends with "jar!/site.config" we will create a new file instead. When running standalone, the file will be created in the same folder as the jar.
Now that we have a function to read the configuration, let's load it so we can actually use it. To do that we will add an atom to hold the configuration, and update our init-config function as follows:
(def app-config (atom nil))
(defn init-config []
(with-open
[r (java.io.PushbackReader. (reader (load-config-file)))]
(if-let [config (read r nil nil)]
(reset! app-config config)))
(println "servlet has been initialized"))
In our log-stats namespace the path to the logs is currently hard coded. Let's change it to read the path from our config file. We'll open our resources/config and add the following to it:
{:log-path "logs/"}
Then in our log-stats namespace we'll change all references to "logs/" to (:log-path @app-config) instead:
(ns my-website.views.log-stats
...
(:use ... my-website.config))
(defpage [:post "/get-logs"] params
(response/json
(hits-per-second
(read-logs (last-log (:log-path @app-config))))))
To ensure that the application still runs correctly standalone we will have to call init-config in our -main in the server namespace:
(ns my-website.server
(:use my-website.config)
...)
(defn -main [& m]
(let [mode (keyword (or (first m) :dev))
port (Integer. (get (System/getenv) "PORT" "8080"))]
(init-config)
(server/start port {:mode mode
:ns 'my-website})))
Now the log path can be specified in the config file without having to rebuild and redeploy the application each time. Complete source for this section is available here.

Noir tutorial - part 6
(iterate think thoughts) 02 09 2012
In the first part of the tutorial we've already seen how to run our application in standalone mode. Here we will look at what we need to do to deploy it on an application server such as Glassfish, Tomcat, jBoss, or Immutant which is a modification of jBoss geared specifically towards Clojure.
There are numerous reasons as to why you might want to do this. For example, an application server lets you run multiple applications at the same time. Another advantage is that the application server can take care of the configuration details, such as handling database connections.
When building real world applications, you will likely have separate dev/staging/prod configurations. Instead of having different builds for our application, we can instead configure our application servers appropriately for each environment. Then we can have a single build process which is much less error prone in my opinion. We can also configure CI, such as Jenkins to build our application and automatically deploy it to the server ensuring that we always have the latest code running.
Finally, if you plan on using a hosting provider, you may end up deploying on a shared application server as opposed to being able to run your application standalone.
Let's go over the prerequisites for building our application into a WAR and deploying it to a server. You will need to setup an application server of your choice for this section. I will be using Tomcat, but the steps will be similar for other servers as well. If you will be using Tomcat, then download the latest version. To start up the server you simply unpack the archive, navigate to the resulting directory, and run:
chmod +x bin/catalina.sh
bin/catalina.sh start
Using CATALINA_BASE: apache-tomcat-7.0.29
Using CATALINA_HOME: apache-tomcat-7.0.29
Using CATALINA_TMPDIR: apache-tomcat-7.0.29/temp
Using JRE_HOME: /Library/Java/Home
Using CLASSPATH: apache-tomcat-7.0.29/bin/bootstrap.jar:apache-tomcat-7.0.29/bin/tomcat-juli.jar
Your Tomcat should now be up and running and you can test it by navigating to localhost:8080:
server namespace requires all the namespaces in our views package, and has the gen-class directive specified:(ns my-website.server
(:require [noir.server :as server]
[my-website.views
common
files
log-stats
users
welcome])
(:gen-class))
This will ensure that the server and the views are compiled during the build step, which is needed for them to be picked up by the application server when the application is deployed. Next, we will change server/load-views call to server/load-vews-ns:
(server/load-views-ns 'my-website.views)
If you used Leiningen 2 to create the project template, then load-views-ns should already be set correctly.
Finally, we have to add a handler which will be used instead of the -main when running on the application server:
(def base-handler
(server/gen-handler
{:mode :prod,
:ns 'my-website
:session-cookie-attrs {:max-age 1800000}}))
It is possible to chain different handlers together. In our case, we will need a wrapper for our handler to prepend the servlet context to all the requests coming to our servlet. This is a workaround for a bug in the current version of Noir, which ignores it. Without this fix none of the redirects will work correctly as they will be routed to the base application server URL instead.
Each wrapper is a function which accepts the current handler, and returns a function which accepts a request, does something to it, and then return the result of calling the handler on it. The result is in turn a handler itself, so we can chain as many wrappers together as we like. In our case we will override the resolve-url function in noir.options with one of our own making:
(defn fix-base-url [handler]
(fn [request]
(with-redefs [noir.options/resolve-url
(fn [url]
;prepend context to the relative URLs
(if (.contains url "://")
url (str (:context request) url)))]
(handler request))))
Above, we will check that the URL contains "://", if not then we treat it as a local URL and prepend the servlet context to it. Now we have to hook it up with our initial handler to produce the final request handler for our servlet:
(def handler (-> base-handler fix-base-url))
Now that we've created our handler, we need to point our project.clj to it:
(defproject my-website "0.1.0-SNAPSHOT"
:description "my Noir website"
:dependencies [[org.clojure/clojure "1.4.0"]
[noir "1.3.0-beta3"]
[org.clojure/java.jdbc "0.2.3"]
[postgresql/postgresql "9.1-901.jdbc4"]]
:dev-dependencies [[lein-ring "0.7.3"]]
:ring {:handler my-website.server/handler}
:main my-website.server)
We've also added lein-ring plugin to our dev-dependencies, this is required for generating the WAR artifact from our build. Under the :ring key we set the :handler to the one we defined above.
Let's test that our project builds correctly and produces a working WAR by running the following commands from the temrinal:
lein deps
Copying 29 files to Noir-tutorial/lib
[INFO] snapshot thneed:thneed:1.0.0-SNAPSHOT: checking for updates from clojars
[INFO] snapshot thneed:thneed:1.0.0-SNAPSHOT: checking for updates from central
Copying 5 files to Noir-tutorial/lib/dev
lein ring uberwar
Compiling my-website.server
Compilation succeeded.
Created Noir-tutorial/my-website-0.1.0-SNAPSHOT-standalone.war
If we have our application server running, then we should be able to simply drop this WAR in its deployment folder and the server will take care of the rest. If we're using Tomcat, then we have to copy it to the webapps folder:
cp my-website-0.1.0-SNAPSHOT-standalone.war ../apache-tomcat-7/webapps/my-website.war
Make sure to replace the ../apache-tomcat-7 above with the location of your Tomcat server. We can now take a look at our server log and see that the application was deployed successfully:
tail -f logs/catalina.out
...
INFO: Deploying web application archive apache-tomcat-7.0.29/webapps/my-website.war
Now let's navigate to localhost:8080/my-website and we should see our application running:

One last thing to note is that any Ajax calls in our pages will have to use the servlet context to be resolved correctly. A workaround for this issue is to use noir.request/ring-request to check if a context is present and set it as a hidden field on the page:
(ns my-website.views.log-stats
(:require [my-website.views.common :as common]
[noir.request :as request]
[noir.response :as response])
(:use clojure.java.io hiccup.page hiccup.form noir.core)
(:import java.text.SimpleDateFormat))
(defpage "/access-chart" []
(common/basic-layout
(include-js "/js/site.js")
(hidden-field "context" (:context (request/ring-request)))
[:div#hits-by-time "loading..."]))
Then we can check this value and prepend it to the URL when making our Ajax query:
$(document).ready(function(){
var context = $('#context').val();
var url = '/get-logs';
if (context) url = context + url;
var options = {xaxis: { mode: "time",
minTickSize: [1, "minute"]}};
$.post(url, function(data){
$.plot($("#hits-by-time"), [data], options);
});
});
As usual, the complete code for this section is available here.

Noir tutorial - part 5
(iterate think thoughts) 01 09 2012
In this section we will learn how to add some JavaScript to the application and how to use Ajax to query the service. We'll use the flot jQuery library to display the usage statistics for our site. When the page loads it will call the service which will parse today's access log and return a JSON response which will be used to generate the chart.
First, let's generate some sample usage data in the apache combined log format:
(defn gen-log-line [[cur-time]]
(let [new-time (doto (new java.util.Date) (.setTime (+ (.getTime cur-time) (rand-int 5000))))
browsers ["\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.7; rv:15.0) Gecko/20100101 Firefox/15.0\""
"\"Mozilla/5.0 (Linux; U; Android 2.2; en-gb; LG-P500 Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko)\""
"\"Mozilla/5.0 (X11; Linux i686) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11\""]]
[new-time
(->>
(concat
(interpose "." (take 4 (repeatedly #(rand-int 255))))
[" - - [" (.format (new java.text.SimpleDateFormat
"dd/MMM/YYYY:HH:mm:ss ZZZZ") new-time) "]"]
[" \"GET /files/test.jpg\" " 200 " " (rand-int 4000) " \"http://my-website/files/test.jpg\" " (first (shuffle browsers))])
(apply str))]))
(defn gen-test-logs [size]
(->> (gen-log-line [(new java.util.Date)])
(iterate gen-log-line)
(take size)
(map second)
(interpose "\n")
(apply str)))
(spit "test-log.txt" (gen-test-logs 500))
If you run the above in the REPL, you will end up with test-log.txt file which should have the contents that look roughly like the following:
120.138.220.117 - - [31/Aug/2012:21:06:47 -0400] "GET /files/test.jpg" 200 3989 "http://my-website/files/test.jpg" "Mozilla/5.0 (Linux; U; Android 2.2; en-gb; LG-P500 Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko)"
201.59.151.159 - - [31/Aug/2012:21:06:49 -0400] "GET /files/test.jpg" 200 1729 "http://my-website/files/test.jpg" "Mozilla/5.0 (Linux; U; Android 2.2; en-gb; LG-P500 Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko)"
122.39.249.88 - - [31/Aug/2012:21:06:51 -0400] "GET /files/test.jpg" 200 1650 "http://my-website/files/test.jpg" "Mozilla/5.0 (Linux; U; Android 2.2; en-gb; LG-P500 Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko)"
...
Now that we have a log file with some access logs in it, we'll parse those logs into structured data to make them easier to analyze:
(defn round-ms-down-to-nearest-sec [date]
(let [date (.parse
(new SimpleDateFormat
"dd/MMM/yyyy:HH:mm:ss zzzzz")
date)]
( * 1000 (quot (.getTime date) 1000))))
(defn parse-line [line]
{:ip (re-find #"\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b" line)
:access-time (round-ms-down-to-nearest-sec
(second (re-find #"\[(.*?)\]" line))) })
(defn read-logs [file]
(with-open [rdr (reader file)]
(doall (map parse-line (line-seq rdr)))))
Above, we simply return a map containing the ip and the access-time for each line in the logs. Using this map we can aggregate the logs by IP to get unique hits, and then group them by time to see hits per second:
(defn hits-per-second [logs]
(->> logs
(group-by :ip)
(map #(first (second %)))
(group-by :access-time)
(map (fn [[t hits]] [t (count hits)]))
(sort-by first)))
(hits-per-second (read-logs "test-log.txt"))
=>([1346460948000 2] [1346460949000 1] [1346460954000 1] ...)
We now have a list where each element has a time rounded down to the nearest second with a number of unique hits associated with it. This happens to be the exact format that flot time series is expecting. We can serve the this data as JSON by using noir.response/json:
(defpage [:post "/get-logs"] params
(response/json (hits-per-second (read-logs "test-log.txt"))))
Finally, we will have to create the page with a placeholder where our chart will be displayed and reference a Js file which will create shortly:
(defpage "/access-chart" []
(common/basic-layout
(include-js "/js/site.js")
[:div#hits-by-time "loading..."]))
We will also have to add the CSS to set the height and width of the chart as well as the margin:
#hits-by-time {
margin: 25px;
width: 400px;
height: 400px;
}
All that's left to do is to add the JavaScript which will get the stats and display them. To do that we'll have to download flot, and put jquery.flot.min.js in the resources/public/js folder.
Then we will include it and jQuery in the header of our page. This can be done using include-js from Hiccup. We'll open up our common namespace and modify the basic-layout as follows:
(defpartial basic-layout [& content]
(html5
[:head
[:title "my-website"]
(include-css "/css/reset.css")
(include-js "http://code.jquery.com/jquery-1.7.2.min.js"
"/js/jquery.flot.min.js"
"/js/site.js")]
[:body content]))
Now let's create a site.js file in resources/public/js and add the following to it:
$(document).ready(function(){
var options = {xaxis: {mode: "time",
minTickSize: [1, "minute"]}};
$.post('/get-logs', function(data){
$.plot($("#hits-by-time"), [data], options);
});
});
If all went well, then when we start up our site and browse to localhost:8080/access-chart. we should see something like this:
Finally, here's some fun daily stats for the blog generated using the above approach. The sources for this part of the tutorial can be found here.

Noir tutorial - part 4
(iterate think thoughts) 25 08 2012
Securing Pages
This part of the tutorial will focus on controlling page visibility, form validation, and handling complex form parameters. In the last section we added support for uploading files, it would make sense to make the upload page private. This way only registered users can access it.
Noir provides a pre-route macro for handling this. However, we will not be using it for a couple of reasons.
First, there is currently a bug in Noir, where pre-route ignores the servlet context, meaning that unless our application is deployed to "/" the routing will not work as expected. The second reason is that you have to remember to add a pre-route entry for each page that you want to make private.
A better solution, in my opinion, is to simply write a macro which will behave the same way as defpage, but will check if there is a user in session and redirect to "/" otherwise. With this approach we make pages private right in their definition. Let's open up our common namespace and add the macro:
(defmacro private-page [path params & content]
`(noir.core/defpage
~path
~params
(if (session/get :user)
(do ~@content)
(resp/redirect "/"))))
As you can see it has exactly same signature as defpage and calls it internally as you normally would, but only adds the content if the session contains a user, otherwise the page will redirect to "/".
Now, we'll go to our files namespace and mark all the pages as private:
(common/private-page "/upload" {:keys [info]}
...)
(common/private-page [:post "/upload"] {:keys [file]}
...)
(common/private-page "/files/:name" {:keys [name]}
...)
Let's test that it works by navigating to localhost:8080/upload without logging in. We should be redirected right back to "/".
Site navigation
Since we now have a couple of pages that we will be navigating we can add a navigation menu in our common namespace:
(defn menu []
[:div.menu
[:ul
[:li (form-to [:post "/logout"] (submit-button "logout"))]
[:li (link-to "/upload" "my files")]
[:li (link-to "/" "home")]]])
(defpartial layout [& content]
(html5
[:head
[:title "my-website"]
(include-css "/css/reset.css")]
[:body
(if-let [user (session/get :user)]
[:div
(menu)
[:h2 "welcome " user]]
[:div.login
(login-form) [:p "or"] (link-to "/signup" "sign up")])
content]))
Now, if a user logs in, they will see the navigation menu and can either select home or their files page. To keep things clean we'll also move the logout link into our menu. This is functional, but it's rather ugly, so let's add some CSS to make it a bit nicer. We'll open up our stock resources/public/css/reset.css which was generated for our site and add the following to it:
.menu ul {
list-style: none;
margin: 0;
padding-left: 0;
}
.menu li {
float: right;
position: relative;
margin-right: 20px;
}
Things should look much better now:
Input Validation
Next, let's reexamine our sign up page, previously we didn't bother doing any validation when creating a new user, so let's add some now. Noir provides a simple way to validate input fields via the noir.validation namespace. Let's open the users namespace and add it in:
(ns my-website.views.users
(:use [noir.core]
hiccup.core hiccup.form)
(:require [my-website.views.common :as common]
[my-website.models.db :as db]
[noir.util.crypt :as crypt]
[noir.session :as session]
[noir.response :as resp]
[noir.validation :as vali]))
Next we will create our validation function:
(defn valid? [{:keys [handle pass pass1]}]
(vali/rule (vali/has-value? handle)
[:handle "user ID is required"])
(vali/rule (vali/min-length? pass 5)
[:pass "password must be at least 5 characters"])
(vali/rule (= pass pass1)
[:pass "entered passwords do not match"])
(not (vali/errors? :handle :pass :pass1)))
The function will check that all the fields conform to the rules, such as user id being provided, minimum password length, and that retyped password matches the original. The rules have the following form:
(rule validator [:filed-name "error message"])
where the validator must return a boolean. We'll also need a helper for displaying the error on the page:
(defpartial error-item [[first-error]]
[:p.error first-error])
Next we will update our signup page to show the errors generated by the validator:
(defpage "/signup" {:keys [handle error]}
(common/layout
[:div.error error]
(form-to [:post "/signup"]
(vali/on-error :handle error-item)
(label "user-id" "user id")
(text-field "handle" handle)
[:br]
(vali/on-error :pass error-item)
(label "pass" "password")
(password-field "pass")
[:br]
(vali/on-error :pass1 error-item)
(label "pass1" "retype password")
(password-field "pass1")
[:br]
(submit-button "create account"))))
All we have to do here is add on-error statements for each field we're validating. Finally, we'll have to update the POST part of the page, to call the validator and return the errors:
(defpage [:post "/signup"] user
(if (valid? user)
(try
(db/add-user (update-in (dissoc user :pass1) [:pass] crypt/encrypt))
(resp/redirect "/")
(catch Exception ex
(render "/signup" (assoc user :error (.getMessage ex)))))
(render "/signup" user)))
This should give you a basic idea of how to validate input using Noir, and more details about validation can be found on the official site.
One thing you'll notice that when we navigate to the signup page, we still see the login option as well as the link to sign up:

layout in the common namespace as follows:(defpartial basic-layout [& content]
(html5
[:head
[:title "my-website"]
(include-css "/css/reset.css")]
[:body content]))
(defpartial layout [& content]
(basic-layout
[:div
(if-let [user (session/get :user)]
[:div
(menu)
[:h2 "welcome " user]]
[:div
[:div.login
(login-form)
[:p "or"]
(link-to "/signup" "sign up")]])
content]))
Then we simply change:
(defpage "/signup" {:keys [handle error]}
(common/layout
...)
(defpage "/signup" {:keys [handle error]}
(common/basic-layout
...)
Another clean up item is to make our form items aligned, to do that we can use the following bit of CSS:
label {
margin-left: 10px;
width:120px;
float:left;
}
The sign up page should now look as follows:

Complex Form Items
Now that we've cleaned up our singup page, we'll turn our attention back to file management. We'll add the ability for the user to filter files by their type. To do that we will first create a function in our db namespace to get all the file types from our database:
(defn file-types []
(map :type (db-read "select distinct type from file")))
Then in our files namespace we will create a new helper called select-files-by-type:
(defn select-files-by-type []
(let [file-types (db/file-types)]
(form-to [:post "/show-files"]
"select file types to show"
(into
(with-group "file-types")
(for [type file-types]
[:div
type
(check-box type)]))
(submit-button "show files"))))
which we will add to our "/upload" page:
(common/private-page "/upload" {:keys [info]}
(common/layout
[:h2.info info]
(select-files-by-type)
(list-files)
(form-to {:enctype "multipart/form-data"}
[:post "/upload"]
(label :file "File to upload")
(file-upload :file)
[:br]
(submit-button "upload"))))
This function will read the file types from the database and create a checkbox group from them. When we hit submit we'll see something like the following in our params:
{"image/png" "true", "image/jpeg" "true"}
Where the value of each selected checkbox will appear as a key in the params map with the value of "true". We will now have to update our list-files function to accept optional file type restriction and in turn pass it to list-files in db namespace:
(defn list-files [& [types]]
(into [:ul]
(for [name (db/list-files types)]
[:li.file-link (link-to (str "/files/" name) name)
[:span " "]
[:div.file]])))
The following changes will have to be made to retrieve files based on type:
(defn params-query [params]
(apply str (interpose ", " (repeat (count params) "?"))))
(defn list-files [& [types]]
(map :name
(if types
(apply (partial db-read (str "select name from file where type in (" (params-query types) ")")) types)
(db-read "select name from file"))))
The params-query helper will create an appropriate WHERE clause based on the number of types we pass in, and list-files will now check if types have been passed in and create the appropriate query. Finally, we'll add a new page which will display the selected files:
(common/private-page [:post "/show-files"] params
(let [file-types (keys params)]
(common/layout
[:h2 "showing files types "
(apply str (interpose ", " file-types))]
(list-files file-types)
(link-to "/upload" "back"))))
The "/upload" page should now look as follows:


Summary
In this section we covered the following topics:
- restricting access to pages
- creating a navigation menu
- input validation
- handling inputs from multi part items such as check boxes
The complete code for this section is available here.

Noir tutorial - part 3
(iterate think thoughts) 22 08 2012
Last time we created a database to store users, and created pages allowing users to create new accounts and login. This time we'll look at how we can allow users to upload files to the server and how to serve them back using the proper content type. To make things easy, we'll stick our files in the database, so let's design a table to hold them:
(defn create-file-table []
(sql/with-connection
db
(sql/create-table
:file
[:type "varchar(50)"]
[:name "varchar(50)"]
[:data "bytea"])))
if we run the above in the REPL a file table should be created. We'll now need a few helper functions to read the list of files and add new files to the table:
(defn to-byte-array [f]
(with-open [input (new java.io.FileInputStream f)
buffer (new java.io.ByteArrayOutputStream)]
(clojure.java.io/copy input buffer)
(.toByteArray buffer)))
(defn store-file [{:keys [tempfile filename content-type]}]
(sql/with-connection
db
(sql/update-or-insert-values
:file
["name=?" filename]
{:type content-type
:name filename
:data (to-byte-array tempfile)})))
(defn list-files []
(map :name (db-read "select name from file")))
(defn get-file [name]
(first (db-read "select * from file where name=?" name)))
The first helper is used by store-file to copy the file out of the input stream into a byte array and then store it in the table. The other two functions simply read the file columns from our database.
Uploading Files
We'll create a new namespace called files under views, and make a page facilitating the uploads:
(ns my-website.views.files
(:use hiccup.util
noir.core
hiccup.core
hiccup.page
hiccup.form
hiccup.element)
(:require [my-website.views.common :as common]
[my-website.models.db :as db]
[noir.response :as resp]))
(defpage "/upload" {:keys [info]}
(common/layout
[:h2.info info]
(form-to {:enctype "multipart/form-data"}
[:post "/upload"]
(label :file "File to upload")
(file-upload :file)
[:br]
(submit-button "upload"))))
There shouldn't be anything too surprising here, we create an "/upload" page with a an info header and a form. On the form we set enctype to multipart/form-data, then we use file-upload function from hiccup.form to create the file upload dialog and add a submit button. As a note, all Hiccup helper functions also accept a map of attributes as an optional first parameter, these attributes will be merged with the ones already provided by the helper.
Now we'll have to make its POST counterpart to handle the upload request on the server:
(defpage [:post "/upload"] {:keys [file]}
(render "/upload"
{:info
(try
(db/store-file file)
"file uploaded successfully"
(catch Exception ex
(do
(.printStackTrace ex)
(str "An error has occured while uploading the file: "
(.getMessage ex)))))}))
Here we accept the params, grab the file and pass it to store-file function we created earlier in the db namespace. The file is a map containing the following keys:
- :tempfile - the file itself
- :filename - the name of the file being uploaded
- :content-type - the content type of the file being uploaded
- :size - size of the file in bytes
eg:
{:size 422668,
:tempfile #<File /var/folders/0s/1vrmt9wx6lqdjlg1qtgc34600000gn/T/ring-multipart-3157719234459115704.tmp>,
:content-type "image/jpeg",
:filename "logo.jpg"}
We can now test that file uploading works correctly by navigating to localhost:8080/upload and uploading a file.

Serving Files
At this point it might be nice to be able to see what files we have on the server, so let's update our "/upload" page to display a list of files and allow downloading them:
(defn list-files []
(into [:ul]
(for [name (db/list-files)]
[:li.file-link (link-to (str "/files/" name) name)
[:span " "]
[:div.file]])))
(defpage "/upload" {:keys [info]}
(common/layout
[:h2.info info]
(list-files)
(form-to {:enctype "multipart/form-data"}
[:post "/upload"]
(label :file "File to upload")
(file-upload :file)
[:br]
(submit-button "upload"))))
(defpage "/files/:name" {:keys [name]}
(let [{:keys [name type data]} (db/get-file name)]
(resp/content-type type (new java.io.ByteArrayInputStream data))))
Above, list-files reads the file names from the database, using the helper function we defined earlier and then sticks them into an unordered list. Notice, that Hiccup allows literal notation for any HTML tags, the syntax is as follows:
[:tag {:attr "value"} content]
So, if we don't have a helper function for a particular tag, or we need to make a custom tag, we can always just make a vector and set the attributes we care about.
The new "/files/:name" page we defined uses resp/content-type function to set the appropriate content type when returning the file. It accepts the content type string and an input stream as parameters.
If we reload the page after making the above changes we should see the following:

and when we click on the file link it should display the image in the browser:

Summary
In this section we learned the following:
- storing files in the database
- setting custom attributes on Hiccup elements
- using
multipart/form-dataform to upload a binary file - serving a file with a custom content type
The complete code for this section is available here.
In the next section we'll talk about creating private pages, form input validation, and handling multi-select form parameters, such as multi checkbox set.

I'm going to take a short break from Noir tutorials and do a post on optimization and profiling instead. I was playing around with rendering Metaballs and I stumbled on a neat visualization.
To get the above effect we simply calculate the influence of each metaball on each point on the screen based on the distances to each ball's center and radius:
imp = rmp / √ (δxmp2 + δymp2)
where r is the radius of the metabll and δxmp and δymp are the x and y distances from the center of the metaball
cp = Σ imp
The algorithm is on the order of
The code to accomplish this is as follows:
;;compute influence of each metaball
(defn influence [{:keys [x y radius]} px py]
(let [dx (- x px)
dy (- y py)]
(/ radius (Math/sqrt (+ (* dx dx) (* dy dy))))))
;;compute the resulting r g b values based on influence
(defn compute-color [x y [red-cur green-cur blue-cur] ball]
(let [influence (influence ball x y)
[r g b] (:color ball)]
[(+ red-cur (* influence r))
(+ green-cur (* influence g))
(+ blue-cur (* influence b))]))
...
;;reverse direction if we hit the edge of the screen
(defn direction [p v]
(if (or (> p SIZE) (neg? p)) (- v) v))
;;compute the position and velocity of the ball
(defn move [{:keys [x y vx vy radius color]}]
(let [vx (direction x vx)
vy (direction y vy)]
{:x (+ x vx)
:y (+ y vy)
:vx vx
:vy vy
:radius radius
:color color}))
;;for each x,y coordinate compute the color
(reduce (partial compute-color x y) [0 0 0] balls)
;;run this in a loop where we move the
;;balls around and render them
(loop [balls (take 2 (repeatedly metaball))]
(draw canvas balls)
(recur (map move balls)))
complete code can be seen here
First thing to do is to time our our loop:
(loop [balls (take 2 (repeatedly metaball))]
(time (draw canvas balls))
(recur (time (map move balls))))
"Elapsed time: 250.345 msecs"
"Elapsed time: 0.004 msecs"
"Elapsed time: 171.136 msecs"
"Elapsed time: 0.005 msecs"
"Elapsed time: 212.646 msecs"
"Elapsed time: 0.004 msecs"
As can be expected the draw function eclipses the move function. So we'll focus on what's happening in our rendering code and see where the CPU time is being spent. Instead of guessing, let's profile the application using VisualVM, which should already be bundled with your JVM, and see what's happening.

We can see that the vast majority of the CPU time is being spent in the color function, and that reflection is the culprit. So, let's see why reflection is happening by setting the *warn-on-reflection* flag to true:
(set! *warn-on-reflection* true)
Reflection warning, metaballs.clj:32 - call to java.awt.Color ctor can't be resolved.
Reflection warning, metaballs.clj:40 - call to setColor can't be resolved.
Reflection warning, metaballs.clj:40 - call to fillRect can't be resolved.
Reflection warning, metaballs.clj:52 - reference to field getBufferStrategy can't be resolved.
Reflection warning, metaballs.clj:53 - reference to field getDrawGraphics can't be resolved.
Reflection warning, metaballs.clj:64 - reference to field dispose can't be resolved.
Reflection warning, metaballs.clj:65 - reference to field contentsLost can't be resolved.
Reflection warning, metaballs.clj:66 - reference to field show can't be resolved.
Now we know precisely which spots are causing us trouble. Let's see if adding some annotations will improve things. First warning we hit happens when we create a new instance of Color:
(defn color-in-range [c]
(int
(cond
(< c 0) 0
(> c 255) 255
:default c)))
(defn color [r g b]
(new Color (color-in-range r) (color-in-range g) (color-in-range b)))
what's happening here is that even though we cast the result into int inside color-in-range, color is not aware of it and uses reflection to resolve the constructor for Color. So we should be doing the cast inside color instead:
(defn color [r g b]
(new Color (int (color-in-range r))
(int (color-in-range g))
(int (color-in-range b))))
The rest of the warnings simply require annotations for the classes in the function arguments:
(defn paint-square [g color x y size]
(doto g
(.setColor color)
(.fillRect x y size size)))
becomes
(defn paint-square [^Graphics g ^Color color x y size]
(doto g
(.setColor color)
(.fillRect x y size size)))
and so on. Finally, we'll cast our distances to doubles when we compute the influence:
(defn influence [{:keys [x y radius]} px py]
(let [dx (double (- x px))
dy (double (- y py))]
(double (/ radius (Math/sqrt (+ (* dx dx) (* dy dy)))))))
optimized version can be seen here
Now that we've annotated our code let's see if performance is any better:
"Elapsed time: 55.424 msecs"
"Elapsed time: 55.399 msecs"
"Elapsed time: 55.373 msecs"
"Elapsed time: 55.482 msecs"
Indeed it is, we went from ~200ms to ~55ms a 4X improvement in speed! Let's see what the profiler has to say now:

From here we can clearly see that majority of the time is spent in the paint-square function, meaning that our code performs as it should. Turns out the the only real factor on performance is reflection.
We could've spent time doing random optimizations here and there, but it's clear from profiling which functions are actually eating up the resources and need optimizing. While this is a toy project, the technique is equally effective for large projects where it might be much more difficult to guess which functions need tuning.
P.S. try setting a negative radius for some of the metaballs in the scene :P

Noir tutorial - part 2
(iterate think thoughts) 18 08 2012
This is the second part of the Noir tutorial, where we'll continue to cover the basics of building a website. In the comments for part 1, somebody suggested that Noir might be abandoned. This is absolutely not the case, I've contacted Chris Granger and this is what he has to say:
Hey Dmitri,
Light Table actually uses Noir, so it's certainly still alive. I'm not the primary one driving things day to day right now, Raynes has been helping out with that.
Cheers,
Chris.
Hopefully, this should put any fears regarding the health of the project to rest. And with that out of the way, lets continue building our site. In the previous section of the tutorial we setup a basic project and learned how to add pages to it. This time let's look at how to persist data to a database, create sessions, and do some basic user management.
Database Access
There are several Clojure libraries for dealing with relational databases, such as SQLKorma, ClojureQL, Lobos, and [clojure.data.jdbc])(http://clojure.github.com/java.jdbc/doc/clojure/java/jdbc/UsingSQL.html). In this tutorial we'll be using clojure.data.jdbc to keep things simple, but I do encourage you to take a look at the others.
Setting up the DB connection
First, we'll need to define our database connection, this can be done by either providing a map of connection parameters:
(def db {:subprotocol "postgresql"
:subname "//localhost/my_website"
:user "admin"
:password "admin"})
by specifying the JNDI name for a connection managed by the application server:
(def db {:name "jdbc/myDatasource"})
I personally like this option, because it completely separates the code in the application from the environment. For example, if you have dev/staging/production servers, you can point the JNDI connection to their respective databases, and when you deploy your application it will pick it up from the environment.
Finally, you can provide a JDBC data source, which you configure manually:
(def db
{:datasource
(doto (new PGPoolingDataSource)
(.setServerName "localhost")
(.setDatabaseName "my_website")
(.setUser "admin")
(.setPassword "admin")
(.setMaxConnections 10))})
At this point you should setup a database and create a schema for this tutorial called my_website. I will be using PostgreSQL so if you use a different DB there might be slight syntactic differences in your SQL. Once you have the DB up and running, we'll need to add the clojure.data.jdbc and JDBC driver dependencies to project.clj:
(defproject my-website "0.1.0-SNAPSHOT"
:description ""my Noir website""
:dependencies [[org.clojure/clojure "1.4.0"]
[noir "1.3.0-beta3"]
[org.clojure/java.jdbc "0.2.3"]
[postgresql/postgresql "9.1-901.jdbc4"]]
:main my-website.server)
Using to the Database
Next, let's create a new namespace called my-website.models.db in the models directory of our project, and open it up. Here we'll first need to add a require statement for clojure.data.jdbc:
(ns my-website.models.db
(:require [clojure.java.jdbc :as sql]))
now let's create a connection:
(def db
{:subprotocol "postgresql"
:subname "//localhost/my_website"
:user "admin"
:password "admin"})
we'll add the following function which will allow us to create the users table:
(defn init-db []
(try
(sql/with-connection
db
(sql/create-table
:users
[:id "SERIAL"]
[:handle "varchar(100)"]
[:pass "varchar(100)"]))
(catch Exception ex
(.getMessage (.getNextException ex)))))
Here's you'll notice that the create-table needs to be wrapped in a with-connection statement which ensures that the connection is cleaned up correctly after we're done with it. The only other thing to note is the use of "SERIAL" for the id field in the table, which is PostgreSQL specific way to create auto incrementing fields. It's also possible to use keywords such as :int, :boolean, and :timestamp for field types as well as the corresponding SQL string as is done in the above example. The whole statement is wrapped in a try block, so if we get any errors when it runs we'll print the error message.
In the REPL we'll run:
(init-db)
If your DB is configured correctly, then you should now have a users table. We'll now write a function to add a user to it:
(defn add-user [user]
(sql/with-connection
db
(sql/insert-record :users user)))
now test that the function works correctly:
(add-user {:handle "foo" :pass "bar"})
=>{:pass "bar", :handle "foo", :id 1}
finally we'll need a way to read the records from the database, I wrote the following helper function to do that:
(defn db-read [query & args]
(sql/with-connection
db
(sql/with-query-results
res
(vec (cons query args)) (doall res))))
the function accepts an SQL string and optional parameters:
(db-read "select * from users")
({:pass "bar", :handle "foo", :id 1})
(db-read "select * from users where id=?" 1)
({:pass "bar", :handle "foo", :id 1})
we'll write another helper function to fetch the user by handle
(defn get-user [handle]
(first
(db-read "select * from users where handle=?" handle)))
at this point we've got a user table and helper functions to create and query users. Let's hook that up to our pages and provide the functionality to create user accounts and allow users to login.
Creating a Registration Page
Noir provides a very simple way to manage sessions using noir.ession namespace. Let's update our site to allow a user to create an account. First we'll create a new namespace called my-website.views.users and add the following code to it:
(ns my-website.views.users
(:use [noir.core]
hiccup.core hiccup.form)
(:require [my-website.views.common :as common]
[my-website.models.db :as db]
[noir.util.crypt :as crypt]
[noir.session :as session]
[noir.response :as resp]))
(defpage "/signup" {:keys [handle error]}
(common/layout
[:div.error error]
(form-to [:post "/signup"]
(label "user-id" "user id")
(text-field "handle" handle)
[:br]
(label "pass" "password")
(password-field "pass")
[:br]
(submit-button "create account"))))
(defpage [:post "/signup"] user
(try
(db/add-user (update-in user [:pass] crypt/encrypt))
(resp/redirect "/")
(catch Exception ex
(render "/signup" (assoc user :error (.getMessage ex))))))
You'll notice that we've required a few new namespaces which we'll be using shortly. Otherwise, we see a similar setup to what we did in the first part of the tutorial, except when we accept the post from the form, we actually add the user to the database.
We will encrypt the user password using noir.util.crypt and then attempt to store the user in the database. If we fail to add the user we'll render our signup page again, but this time with an error message.
create user page

error displayed when user creation fails
Session Management
At this point we need to provide the users with the ability to login with their accounts. Let's go to the common namespace and add a way for users to login. We'll need to add noir.session to our :require statement:
(ns my-website.views.common
...
(:require [noir.session :as session])
then we'll go back to users namespace and create a page to handle logins:
(defpage [:post "/login"] {:keys [handle pass]}
(render "/"
(let [user (db/get-user handle)]
(if (and user (crypt/compare pass (:pass user)))
(session/put! :user handle)
{:handle handle :error "login failed"}))))
We'll use noir.crypt to validate the password against the one we have in the database, and if the password matches we'll stick the user handle into the session. The syntax for updating the session is fairly straightforward, and the documentation page explains it well. We'll be using get, put!, and clear! functions, notice that put! and clear! have an exclamation mark at the end indicating that they mutate the data in place.
The users will also need a way to logout, so let's add a page to handle that as well:
(defpage [:post "/logout"] []
(session/clear!)
(resp/redirect "/"))
When the user logs out, we'll simply clear the session and send them back to the homepage. We will now go to our common namespace and add the noir.session and hiccup.form in our namespace:
(ns my-website.views.common
(:use [noir.core :only [defpartial]]
hiccup.element
hiccup.form
[hiccup.page :only [include-css html5]])
(:require [noir.session :as session]))
then add a helper function to create the login form:
(defn login-form []
(form-to [:post "/login"]
(text-field {:placeholder "user id"} "handle")
(password-field {:placeholder "password"} "pass")
(submit-button "login")))
and finally add it to our layout:
(defpartial layout [& content]
(html5
[:head
[:title "my-website"]
(include-css "/css/reset.css")]
[:body
(if-let [user (session/get :user)]
[:h2 "welcome " user
(form-to [:post "/logout"] (submit-button "logout"))]
[:div.login
(login-form) [:p "or"] (link-to "/signup" "sign up")])
content]))
At this point our main page should look like the following:

and after we sign up and login, we should see:

The logout button should take us back to the login page by clearing the user session. We now have a complete website with some basic user management, the only thing left to add is actual content. :)
Summary
In this section we learned the following:
- how to setup the database and do basic queries
- do basic authentication using
noir.crypt - use sessions to store user information
Hopefully this is enough to get you started using Noir and making your sites with it. If I omitted anything important let me know in comments and I'll be glad to go over it.
The complete source for this part of the tutorial is available here. Also, for an example of a complete real world site you can see the source for this blog here.
In the next section we'll talk about setting content types and doing file uploads and downloads.

Noir tutorial - part 1
(iterate think thoughts) 17 08 2012
Background
Clojure web stack consists of Ring, which is the base HTTP library akin to Python's WSGI and Ruby's Rack. On top of Ring lives Compojure, which provides some basic routing, and that in turn is leveraged by Noir to provide a simple framework for developing websites. Here's we'll see how to use Noir to build a basic website.
Setting Up a Noir Project With Leiningen
The easiest way to get Noir setup is to use Leiningen 2, which has become the de facto build tool for Clojure. Once you have Leiningen installed, you can simply do the following to get a template site created:
lein new noir my-website
cd my-website
Alternatively, if you're using Counterclockwise with Eclipse, then all you need to do is make a new Leiningen project and put noir in the "Leiningen Template to use:" field.
Project Structure
The template site will have the following structure:
/my-website
project.clj
--src/
--my_website/
server.clj
--models/
--views/common.clj
welcome.clj
--test/my_website
--resources/public/
--css/reset.css
--img/
--js/
The skeleton application contains a few files in it. The project.clj file is used for building the application and managing dependencies by Leiningen. Under the src folder, we have the folder called my_website which contains server.clj. This file contains the entry point to our application. It loads up all the views and provides a main function which can be used to start the application.
The models folder is used to keep the data layer of the application, such as code for the database access and table management. The views folder contains the namespaces describing the pages of our application and their supporting code. The template contains common.clj which provides a basic layout and any code shared between the pages. The welcome.clj is the namespace where an example page is defined.
Dependency Management
Let's first look at the project.clj file:
(defproject my-site "0.1.0-SNAPSHOT"
:description "FIXME: write this!"
:dependencies [[org.clojure/clojure "1.4.0"]
[noir "1.3.0-beta3"]]
:main my-site.server)
The file is fairly self explanatory, and currently only contains dependencies for Clojure and Noir.
Running the Project in Development Mode
At this point we should be able to start up our website:
lein run
Starting server...
2012-08-16 09:39:22.479:INFO::Logging to STDERR via org.mortbay.log.StdErrLog
Server started on port [8080].
You can view the site at http://localhost:8080
#<Server Server@2206270b>
2012-08-16 09:39:22.480:INFO::jetty-6.1.25
2012-08-16 09:39:22.521:INFO::Started SocketConnector@0.0.0.0:8080
Let's point the browser to localhost:8080 and make sure everything is working as expected. We should be greeted with a Noir help page since we haven't defined one for "/" route yet. At this point we can start editing our pages and any changes we make should be reflected immediately.
Creating Pages
Noir provides two primary way to manipulate pages. One useful macro is defpartial which simply wraps the body in html function from Hiccup, which will generate the resulting HTML string from our content:
(defpartial foo [content]
[:p content])
(foo "some stuff")
"<p>some stuff</p>"
The other is defpage, this macro will create a Compojure route for the specified URL. It has the following syntax:
(defpage url params content)
By default defpage is expected to return an HTML string. How that string is generated is up to you. In this tutorial we'll be using Hiccup, but you could just as easily use something like Enlive to create your templates using actual HTML. Noir itself is completely agnostic in this regard.
Now, let's look at the parameters that defpage accepts. First we have a URL which supports the following formats:
- a simple string such as
"/welcome" - a RESTful path such as
"/welcome/:user"where the key:userwill be appended to the params map with the value provided when the URL is accessed - a vector specifying the request type which the page responds too :
[:post "/welcome"]
Next, we have params, which is simply a map of keywords and their associated values generated from the request parameters. Any keys from the URL will also appear in this map:
(defpage "/welcome/:user" {:keys [user]}
(html [:html [:body "hello " user]]))
Finally, we add the actual page content to be rendered. As I mentioned above the result must be a string, so generally we'll wrap the contents of each page in (common/layout ...) which was provided by the template. The official documentation for defpage with lots of other examples and details is available here.
Handling Form Input
When making pages with forms the general pattern is to create a defpage for the GET request which will contain the UI, and another for POST which contains the server component. To test that out, let's change welcome.clj to look like the following:
(ns my-website.views.welcome
(:require [my-website.views.common :as common]
[noir.content.getting-started])
(:use [noir.core :only [defpage]]
hiccup.core hiccup.form))
(defpage "/welcome" {:keys [greeting]}
(common/layout
(if greeting [:h2 greeting])
(form-to [:post "/welcome"]
(label "name" "name")
(text-field "name")
(submit-button "submit"))))
(defpage [:post "/welcome"] {:keys [name]}
(noir.core/render "/welcome"
{:greeting (str "Welcome " name)}))
As can be seen above, the page which responds to GET creates a form and submits it to its POST counterpart. It in turn generates a greeting and renders the page with it. Note that the names for fields used in the form get translated into keys in the params map when we submit it.

before submit

and after submit
This covers the basic model for creating pages and interacting with them. Now, let's look at how we can package our website into a standalone application.
Packaging and Running Standalone
To package our project we need to change our server to compile into a class, we can do this by simply adding gen-class to its namespace like so:
(ns my-website.server
(:require [noir.server :as server])
(:gen-class))
Now we can build and run our project:
lein uberjar
java -jar my-website-0.1.0-SNAPSHOT-standalone.jar
Starting server...
2012-08-16 20:12:47.846:INFO::Logging to STDERR via org.mortbay.log.StdErrLog
2012-08-16 20:12:47.846:INFO::jetty-6.1.x
2012-08-16 20:12:47.882:INFO::Started SocketConnector@0.0.0.0:8080
Server started on port [8080].
You can view the site at http://localhost:8080
Summary
To recap, in this section of the tutorial we learned the following:
- how to create a new Noir project
- manage dependencies
- create pages
- handle submits from forms
- create a standalone instance of our application
Next time we'll look at how to do session management and database access.
The source for the tutorial is available here.
A few months ago I was tasked with generating reports for one of the applications I was working on. I looked around for some off the shelf libraries for doing this sort of thing. The most popular library in the Java world appears to be iText. It's a mature library with lots of features, but it takes entirely too much code to produce anything useful with it. On top of that, the latest version licensed under LGPL2 is 2.1.7 which, while serviceable, is full of quirks and odd behaviors.
After spending a bit of time playing with it I decided that it would make more sense to have a declarative API for describing the PDF document. I really like the way Hiccup allows generating HTML using nested vectors, and decided that something similar could be done for generating PDF documents.
This lead to the creating of clj-pdf, which allows describing the document using this approach. Each vector represents a different element, such as a paragraph, a list, or a table. Internally, I leverage iText to produce the actual PDF document, but the API is completely declarative. The library attempts to abstract away any of the quirks as well as provide useful elements such as headings, spacers, page breaks, etc.
Let's look at how this all works in practice. A document is simply a vector which contains metadata describing it followed by one or more inner elements:
[{:title "My document"} "some content here..."]
In the spirit of Hiccup, each element is represented by a vector, where the first item must be a tag describing the type of the element, followed by optional metadata, and finally the content of the element. For example if we wanted to create a paragraph we'd do the following:
[:paragraph "a fine paragraph"]
to set the font style we could add the following metadata:
[:paragraph
{:style :bold :size 10 :family :halvetica :color [0 255 221]}
"Lorem ipsum dolor sit amet, consectetur adipiscing elit."]
any metadata in an element will propagate to its children:
[:paragraph
{:style :bold :size 12 :family :halvetica :color [0 255 221]}
"Lorem ipsum dolor sit amet, consectetur adipiscing elit."
[:phrase "some text here"]]
here the phrase will inherit the font style of its parent paragraph. However, the child element is always free to overwrite the parent metadata:
[:paragraph
{:style :bold :size 12}
"Lorem ipsum dolor sit amet, consectetur adipiscing elit."
[:phrase {:style :normal :size 10} "some text here"]]
This provides us with a lot of flexibility, while allowing to specify defaults for the entire document. The library attempts to provide reasonable behavior out of the box, so that adding metadata should not be necessary in most cases.
Some reports might include things like usage statistics. And to that end I leveraged the excellent JFreeChart library to provide a simple charting API:
[:chart {:type :line-chart
:title "Line Chart"
:x-label "checkpoints"
:y-label "units"}
["Foo" [1 10] [2 13] [3 120] [4 455] [5 300] [6 600]]
["Bar" [1 13] [2 33] [3 320] [4 155] [5 200] [6 300]]]
At this time bar charts, line charts, time series, and pie charts are supported. And because a chart is just an image, all the image styling, such as scaling and alignment, can be applied to it as well.
Since the API is completely declarative, it doesn't actually have to be encoded in Clojure structures. We could instead encode it in something like JSON, which is exactly what I ended up doing next. I created a service which would accept POST requests containing JSON encoded documents and return PDF documents. The service can be accessed by any application regardless of what language its written in, and can even be called by JavaScript from a browser as can be seen here.
Documentation and examples are available on the github project page.
Blogging with Noir
(iterate think thoughts) 14 08 2012
Writing a blog engine in Noir turned out to be a very pleasant experience. The engine which is currently powering this blog supports all the features one would expect from a blogging engine, some of which include:
- content caching
- RSS feed
- tags
- markdown in posts and comments with live preview
- syntax highlighting
- file uploads and management through web UI
- captchas for comments
- latest comments view
- controlling post visibility
All that weighs in at under 1K lines of Clojure, and some 50 lines of Js. I've outlined some of the quirks I ran into previously. Now, I'd like to talk about what went right and what facilitated writing a complete functional website in only a few hundred lines of code.
I used clojure.java.jdbc for database access. The library is very easy to use and provides all the basic functionality you'd expect with minimal fuss. You can define a database either using a map:
(def mysql-db {:subprotocol "postgresql"
:subname "//127.0.0.1:3306/clojure_test"
:user "clojure_test"
:password "clojure_test"})
by providing a JNDI name and configuring a JNDI data source on the app server:
(def my-db {:name "jdbc/myDatasource"})
or by simply instantiating a data source as I do in the blog:
(def db
{:datasource
(doto (new PGPoolingDataSource)
(.setServerName (:host blog-config))
(.setDatabaseName (:schema blog-config))
(.setUser (:user blog-config))
(.setPassword (:pass blog-config))
(.setMaxConnections 10))})
Calling SQL commands is straightforward as well, all statements must be wrapped with a with-connection statement. This ensures that any result sets are cleaned up and the connection is closed once you're done with it. I found the library to be very intuitive and easy to work with. The documentation is available on github and covers most use cases. All of my db interaction ended up fitting in just under 250 lines, which makes it easy to keep on top of.
Noir has been indispensable in making things concise and easy to manage. Noir and Hiccup make it trivial to organize the pages and their controllers into self contained chunks.
Because it encourages making things stateless, it's easy to add functionality in isolated chunks. This means that you can add a particular feature, such as RSS support, without having to worry how it might interact with existing code. I find this especially important when writing side projects as it means that you have a very short ramp up time when you come back to a project after not having touched it for a while.
I'm personally a fan of using Hiccup for generating HTML, as it allows using the full power of Clojure for templating. However, some people have concerns about not having the actual HTML that designers can then style. Fortunately, there's nothing inherent to Noir that ties it to Hiccup. A defpage simply has to return an HTML string, how that string gets generated is entirely up to you. And there's a great guide for using Noir with Enlive, which is designed for HTML based templating. Again, I have to point out the thoughtfulness of design which separates creating routes and serving pages from the libraries which deal with actually generating them.
For Markdown parsing I dredged up an old library of mine, and with a few tweaks it's been doing its job as far as far as this blog is concerned. One advantage of this particular library is that it compiles to both Clojure and ClojureScript, so I can do previews in the browser and guarantee that they will be rendered the same by the server.
I added the ability to add language hinting using github style markdown, eg: ```clojure, to output tags compatible with the syntax highlighter, which I then use to do code highlighting in the browser.
I also didn't find any readily available libraries for generating RSS from Clojure, so I proceeded to make clj-rss, which turned out to be very easy thanks to the excellent XML support in the standard library and a few macros.
For my captcha needs I turned to a Java library called jlue. Thanks to the excellent Java interop, using it is quite seamless:
(defn gen-captcha []
(let [text (gen-captcha-text)
captcha (doto (new Captcha))]
(session/put! :captcha
{:text text
:image (.gen captcha text 250 40)})))
(defpage "/captcha" []
(gen-captcha)
(resp/content-type
"image/jpeg"
(let [out (new ByteArrayOutputStream)]
(ImageIO/write (:image (session/get :captcha)) "jpeg" out)
(new ByteArrayInputStream (.toByteArray out)))))
Finally, all of the building and packaging is handled by Leiningen, which makes it trivial to track dependencies and package up the resulting application. In my case I'm deploying the blog to Tomcat, and so I simply build a WAR using:
lein ring uberwar
The resulting WAR can be dropped on any Java application server. If you wanted to deploy to Heroku, you simply have to add a Procfile to the root directory of the project with the following contents:
web: lein trampoline run -m yuggoth.server
Overall, I experienced very few issues and found the experience to be overwhelmingly positive. In my opinion the current tools and libraries available in Clojure allow writing web sites just as easily, if not more so, as most of the established languages out there.
Why be conservative
(iterate think thoughts) 11 08 2012
Steve Yegge has made a post introducing the idea of liberalism and conservatism in programming languages. While it is an entertaining read I have to question the usefulness of the proposed metric.
In my opinion the language either gets out of your way and makes it easy to do what you need to do or it doesn't. I don't really care how it does it as long as at the end of the day I enjoy using it and I'm productive in it.
It can certainly be argued that Clojure is conservative in some ways. As has been pointed out in the results of the 2012 State of Clojure survey, some people find the process for contributing to the language too restrictive. Rich Hickey is very cautious about adding new features and about the way they're added to the language.
But I would argue that this is in fact a good thing and the end result is a cleaner and more consistent language. Destructuring is a concrete example of this. At one point people were asking for named arguments for functions and Rich resisted the idea of adding them. Instead, we got destructuring which is a more powerful and general purpose tool. It can be used for naming arguments in functions, but it can also be used for many other things as well.
Let's consider what the result would have been if Clojure was more liberal about adding features, and named arguments were in fact added. There would now be two separate ways to do the same thing, each with its own quirks. Different code bases would use different rules for naming function parameters and you would have to make adapters to make them work together.
The more eagerly features get accepted into a language, the more likely they it is that the solution won't be elegant or general purpose. Which means that inevitably a new feature needs to be added to cover the case which isn't adequately addressed by the original attempt.
In my opinion this quickly leads to having a crufty syntax, and requires a lot of mental overhead to work with code written by others. Since, some people will prefer this or that particular style of doing things you have to be aware of every quirk and their interactions.
Fact of the matter is that Lisp is already phenomenally powerful, more so than most languages out there. It would seem prudent not to be rash about trying to improve it.
The Results of the 2012 State of Clojure survey are out, and they look very exciting indeed. More people are using Clojure, the community is growing, and for the most part things appear to be progressing well. However, one notable problem that people are reporting is actually getting started with Clojure.
I'd like to spend some time here to help people actually get up and running with the language. First, I'll cover setting up the development environment. Many Clojure users gravitate towards Emacs, which is a natural choice for Lisp development. But if you're new to Clojure and you haven't used Emacs before, I would strongly suggest against learning both Emacs and Clojure at the same time.
The reason being is that Emacs is fairly arcane in many ways, and it behaves very differently from traditional IDEs, such as NetBeans or Eclipse. Learning a new language, which has very different syntax from languages you might be used to, and requires learning a new programming paradigm is enough to keep one busy without having to learn a quirky IDE on the side.
My recommendation would be to grab a copy of Eclipse and install the Counterclockwise plugin. Installing the plugin is incredibly simple, once you have Eclipse running follow the following steps:
- navigate to the "Install new Software" tab under the help menu
- paste in the CCW update URL: http://ccw.cgrand.net/updatesite in the "Work with:" text field
- check the "Clojure Programming" checkbox and hit the "Next" button
Counterclockwise takes care of setting up Clojure and Leiningen for you. And once the plugin is installed, you will be able to create a new Clojure project or a new Leiningen project. I would recommend making Leiningen projects, since they allow easily managing dependencies by updating the project.clj file in the project directory. I'll touch more on this later.
At this point, I'll assume that you have Eclipse with CCW up and running. So, navigate to File->new->project in Eclipse menu. Then select Leiningen->Leiningen project. Here you'll see the default Leiningen Template filled in. And only thing you have to do is provide a project name. Let's call our project "clojure-test" and hit the finish button.
You should now see a new project in your Package Explorer view on the left. The project template will have a src folder which will contain the package folder named clojure_test. Since Java cannot use dashes in names, all the dashes in package folders for namespaces get converted to underscores. The pckage will contain a core.clj file, and its contents should look like the following:
(ns clojure-test.core)
(defn -main
"I don't do a whole lot."
[& args]
(println "Hello, World!"))
Let's open it and then hit the run button. You should see a REPL pop up momentarily on the bottom of the IDE. If all went well, your project should be ready to work on. The code that's in the file will have already been loaded up in the REPL when we hit run, and we should now be able to call our -main function.
To do that, let's write the code which calls main below it:
(-main)
Then navigate the cursor inside the call body and hit CTRL+ENTER on Linux/Windows or CMD+ENTER on OS X. You should see "Hello, World!" printed in the REPL view on the bottom. We can now change the behavior of the -main function and after it is reloaded the new behavior will be available next time it's called.
I would also recommend enabling the "strict/paredit" mode under Preferences->Clojure->Editor section. This will allow the editor to keep track of balancing the parens for you. It might seem odd at first, but I highly encourage you to stick with it.
Another useful feature of the editor is the ability to select code by expression. If you navigate inside a function and press ALT+SHIFT+UP (use CMD instead of ALT in OS X), then inner body of the expression will be selected, pressing it again, will select the expression, and then the outer body, and so on. Conversely pressing ALT+SHIFT+DOWN will narrow the selection. This allows you to quickly navigate nested structures, and select code by chunks of logic as opposed to simply selecting individual lines.
I've also mentioned the project.clj file in your project folder earlier. This file should look like the following:
(defproject clojure-test "0.1.0-SNAPSHOT"
:description "FIXME: write description"
:url "http://example.com/FIXME"
:license {:name "Eclipse Public License"
:url "http://www.eclipse.org/legal/epl-v10.html"}
:dependencies [[org.clojure/clojure "1.3.0"]])
You can add new dependencies to your project by simply sticking them in the dependencies vector. For example, if we wanted to add an HTTP client, we'd go to http://clojuresphere.herokuapp.com/ click on clj-http link. From there select the Clojars link and copy the following:
[clj-http "0.5.2"]
now we'll simply paste it under dependencies in our project.clj:
:dependencies [[org.clojure/clojure "1.3.0"]
[clj-http "0.5.2"]]
In our package explorer view on the left we should be able to expand "Leiningen dependencies" and see the clj-http jar included there. We will now have to kill our current REPL, to do that navigate to the terminal view next to it and press the stop button. When we start a new instance of the REPL, the library will be available for use. In the core file we can now add it to the namespace:
(ns clojure-test.core
(:require [clj-http.client :as client]))
and test using the client by typing
(client/get "http://google.com")
and running it as we did earlier. This should cover all the basics of using Clojure with Counterclockwise, and allow you to get hacking on your project.
I'd also recommend visiting the following sites:
- 4Clojure is an excellent site for practicing small exercises in Clojure. Be sure to make an account and follow some of the top users. When you solve a problem, you'll be able to see how others solve it and get a taste for idiomatic Clojure code.
- Clojure - Functional Programming for the JVM is a very comprehensive introduction to Clojure aimed at Java programmers.
- ClojureDocs is an excellent documentation site for Clojure which contains many examples on using the functions in the standard library.
- Noir is an great Clojure framework for making web apps, in fact this blog is built on top of it with source available here.
There are many other great Clojure sites that I failed to mention here, but the above should provide a good starting point.
Serving RSS with Clojure
(iterate think thoughts) 04 08 2012
I recently got invited to join Planet Clojure, which is an excellent place for keeping up with what people are up to in Clojure world. As part of being syndicated I had to add an RSS feed to my blog. A cursory Google search came up with lots of tutorials for parsing RSS, but nothing regarding generating it. Turns out that it's very straight forward and it takes less than a 50 lines of code to create a proper RSS feed for your site.
First, a bit of background about RSS. Essentially, it's a very simple syndication format designed to allow pushing out notifications about frequently updated content such as blog posts. RSS is served as XML and each feed has to consist of a channel tag with some metadata and item tags, each one describing a specific update such as a new blog post.
All we have to do to create our RSS feed is to structure the data accordingly and serialize it to XML. Clojure standard library provides a simple way to output XML using the emit function in the clojure.xml namespace. It accepts data in the following format:
{:tag :tag-name :attrs attrs-map :content [content]}
The content in the above can contain a mix of strings and tags. One thing to be aware of is that any other content will result in a null pointer exception, so it's one of rare cases where that doesn't get handled gracefully by default. Once we've constructed a proper tag we can serialize it to XML as follows:
(with-out-str
(clojure.xml/emit
{:tag :channel :attrs nil :content []}))
which results in
<?xml version='1.0' encoding='UTF-8'?>
<channel>
</channel>
Note that emit needs to be wrapped in with-out-str to capture its output into a string. RSS also specifies the format in which time should be output, so we'll make a helper function to handle that:
(defn format-time [time]
(.format (new java.text.SimpleDateFormat
"EEE, dd MMM yyyy HH:mm:ss ZZZZ") time))
Writing out the tags by hand gets tedious, so I wrote a macro to output the tags for us:
(defmacro tag [id attrs & content]
`{:tag ~id :attrs ~attrs :content [~@content]})
I covered macros briefly in an earlier post. The only new syntax used here is the ~@ notation, which simply says that the items in content should be inserted into the enclosing structure, eg:
(tag :foo nil "foo" "bar" "baz")
{:tag :foo, :attrs nil, :content ["foo" "bar" "baz"]}
Armed with this macro let's write the function to describe an individual post. The function accepts the site, the author and a map describing the post as parameters, then generates the appropriate tags as per RSS specification.
(defn item [site author {:keys [id title content time]}]
(let [link (str site "/" id )]
(tag :item nil
(tag :guid nil link)
(tag :title nil title)
(tag :dc:creator nil author)
(tag :description nil content)
(tag :link nil link)
(tag :pubDate nil (format-time time))
(tag :category nil "clojure"))))
Let's test that it does what we expect:
(item "http://yogthos.net"
"Yogthos"
{:id 1
:title "Test post"
:content "Some content"
:time (new Date)})
{:content
[{:content ["http://yogthos.net/1"], :attrs nil, :tag :guid}
{:content ["Test post"], :attrs nil, :tag :title}
{:content ["Yogthos"], :attrs nil, :tag :dc:creator}
{:content ["Some content"], :attrs nil, :tag :description}
{:content ["http://yogthos.net/1"], :attrs nil, :tag :link}
{:content ["Sat, 04 Aug 2012 18:16:03 -0400"],
:attrs nil,
:tag :pubDate}
{:content ["clojure"], :attrs nil, :tag :category}],
:attrs nil,
:tag :item}
If we pass the above to xml/emit we'll get the corresponding XML. Next we'll need a function which will will create the representation of the channel:
(defn message [site title author posts]
(let [date (format-time (new Date))]
(tag :rss {:version "2.0"
:xmlns:dc "http://purl.org/dc/elements/1.1/"
:xmlns:sy "http://purl.org/rss/1.0/modules/syndication/"}
(update-in
(tag :channel nil
(tag :title nil (:title (first posts)))
(tag :description nil title)
(tag :link nil site)
(tag :lastBuildDate nil date)
(tag :dc:creator nil author)
(tag :language nil "en-US")
(tag :sy:updatePeriod nil "hourly")
(tag :sy:updateFrequency nil "1"))
[:content]
into (map (partial item site author) posts)))))
Again, this is fairly straight forward, the function takes the site url, blog title, the author and the posts. Then it creates the necessary tags to describe the channel and inserts the formatted posts into it. We should now be able to generate valid RSS content by calling it with some data:
(message "http://yogthos.net" "My blog" "Yogthos"
[{:id 1
:title "Test post"
:content "Some content"
:time (new Date)}])
{:content
[{:content
[{:content ["Test post"], :attrs nil, :tag :title}
{:content ["My blog"], :attrs nil, :tag :description}
{:content ["http://yogthos.net"], :attrs nil, :tag :link}
{:content ["Sat, 04 Aug 2012 18:23:06 -0400"],
:attrs nil,
:tag :lastBuildDate}
{:content ["Yogthos"], :attrs nil, :tag :dc:creator}
{:content ["en-US"], :attrs nil, :tag :language}
{:content ["hourly"], :attrs nil, :tag :sy:updatePeriod}
{:content ["1"], :attrs nil, :tag :sy:updateFrequency}
{:content
[{:content ["http://yogthos.net/blog/1"], :attrs nil, :tag :guid}
{:content ["Test post"], :attrs nil, :tag :title}
{:content ["Yogthos"], :attrs nil, :tag :dc:creator}
{:content ["Some content"], :attrs nil, :tag :description}
{:content ["http://yogthos.net/blog/1"], :attrs nil, :tag :link}
{:content ["Sat, 04 Aug 2012 18:23:06 -0400"],
:attrs nil,
:tag :pubDate}
{:content ["clojure"], :attrs nil, :tag :category}],
:attrs nil,
:tag :item}],
:attrs nil,
:tag :channel}],
:attrs
{:version "2.0",
:xmlns:dc "http://purl.org/dc/elements/1.1/",
:xmlns:sy "http://purl.org/rss/1.0/modules/syndication/"},
:tag :rss}
Finally, we'll write a function which converts the message to XML:
(defn rss-feed [site title author posts]
(with-out-str (emit (message site title author posts))))
We can confirm that we're generating valid content by pasting it to W3C Feed Validation Service. This is all that's needed to create a valid RSS message. It can now be served over HTTP using your favorite library or framework.
Complete code for the example can be found here.
Updates
I've since rolled all of the above into a (hopefully :) friendly clj-rss library.
Noir tricks
(iterate think thoughts) 02 08 2012
This blog is built on top of Noir, which is quite excellent for the most part. However, I did run into one problem which I spent a bit of time on. I'd like to share my workarounds to save others time.
First issue I noticed is that response/redirect doesn't respect the servlet context. This means that if you're not deploying your app to the root context, your redirects will not work properly.
After some digging and questions on the Google groups I found out that the offending function is resolve-url in noir.options namespace. When it builds the URL string it doesn't check for the context and as such the resulting URL ends up redirecting to the root of the app server regardless of what context the servlet was deployed at.
My workaround for this is a bit of a hack, and if anybody has a better solution I'd love to know, but it works well for most purposes. In my server.clj I added a new handler wrapper, which redefines the offending function with one that checks if the URL is relative and prepends the context to it as needed.
(defn fix-base-url [handler]
(fn [request]
(with-redefs [noir.options/resolve-url
(fn [url]
;prepend context to the relative URLs
(if (.contains url "://")
url (str (:context request) url)))]
(handler request))))
A related issue is that pre-route doesn't respect the context either. I decided to simply write a macro for defining private pages:
(defmacro private-page [path params & content]
`(noir.core/defpage
~path
~params
(if (session/get :admin)
(do ~@content) (resp/redirect "/"))))
An added advantage of the macro is that I don't have to remember to update pre-routes when I want to make a page private.
Also, there are a couple of things to be aware of if you wish to make a WAR. Make sure that all your views are required in your server namespace, :gen-class is set and that server/load-views-ns is used instead of server/load-views:
(ns yuggoth.server
(:require
...
[yuggoth.views archives auth blog comments common profile rss upload])
(:gen-class))
(server/load-views-ns 'yuggoth.views)
In your project.clj add the following:
:ring {:handler yuggoth.server/handler}
With the above in place you can build an uberwar with
lein ring uberwar
The resulting WAR should deploy on any app server such as Tomcat or Glassfish without problems. Aside from the above quirks, I haven't run into any other issues with Noir, and I'm absolutely in love with it.
open access
(iterate think thoughts) 31 07 2012
Sometimes you might run into a situation where you're using a library which defines a certain function in a way that might not work the way you need it to in a particular context. To make things worse, this function might be used by the library internally, so you can't simply write your own version and use it.
In some languages it's possible to use monkey patching to get around this problem. This approach allows you to simply redefine the offending function at runtime with your own version. The downside of this approach is that the change is global and as such might interact poorly with other code which expects the original version.
In Clojure it's possible redefine an existing function in a particular context using with-redefs. This approach gives us the ability to make runtime modifications in a safer fashion where we know exactly what code is affected.
Let's look at an example where we have a get-data function defined in namespace foo which is used by display-results in namespace bar. When we write tests for bar we would like to use preset test data instead of calling out to the database:
(ns foo)
(defn get-data []
;gets some data from a db
)
(ns bar
(:require foo))
(defn display-results []
(apply str (interpose ", " (foo/get-data))))
(ns tests
(:use clojure.test)
(:require foo bar))
(deftest display-results-test
(with-redefs [foo/get-data (fn[] ["Doe", "John"])]
(is (= "Doe, John" (bar/display-results)))))
Now any code that references foo/get-data inside the with-redefs scope will get ["Doe", "John"] as a result.
a look at macros
(iterate think thoughts) 27 07 2012
Lisp macros can be rather confusing and especially so for newcomers. In fact, the rule of thumb is not to use macros if you can avoid them. That said, macros can be an incredibly powerful tool and have innumerable uses. I'd like to give a concrete example of a macro that I'm using in this blog engine.
I wanted to be able to cache page content in memory, so that the page doesn't need to be generated for every single request. This means that before rendering a page I want to check if the page is in my cache, and if the cache hasn't expired then serve the cached page, otherwise render a new version and cache it.
First I created an atom which would store the cached content:
(def cache (atom {}))
Next I wrote the cache logic for the /blog page:
(defpage "/blog/:postid" {:keys [id]}
(let [last-updated (:time (get @cache id))
cur-time (.getTime (new java.util.Date))]
(if (or (nil? last-updated)
(> (- cur-time last-updated) 10000))
(swap! cache assoc id {:time cur-time
:content (entry (db/get-post id))}))
(:content (get @cache id)))
Obviously, we don't want to repeat this logic each time we wish to cache something, and we'd like an easy way to modify existing functions to allow caching. Here's where macros come in. One property of macros is that, unlike functions, they do not execute the s-expressions which are passed in. Let's look at how this works in practice:
(defn foo [] (println "foo was called"))
(defn bar [f])
(bar (foo))
=>foo was called
Here foo is executed as we would expect and "foo was called" is printed, but what happens if we make bar a macro instead?
(defmacro bar [f])
(bar (foo))
=>
This time nothing is printed! In a macro the parameters are treated as data and are not evaluated unless we explicitly choose to do so:
(defmacro bar [f] f)
(bar (foo))
=>foo was called
A macro allows us to change code before it is compiled, and at compile time it is replaced with its output. We can check this by running macroexpand:
(macroexpand '(bar (foo)))
=>(foo)
We can see that (bar (foo)) simply gets replaced with (foo) which is what our macro is returning. While the previous version would evaluate to nil, and foo would never be executed.
As you might have guessed by now, we can pass any s-expression to a macro and then decide inside the macro whether we'd like to evaluate it. So, let's see how we can use this to make our caching macro:
(defmacro cache [id content]
`(let [last-updated# (:time (get @cached ~id))
cur-time# (.getTime (new java.util.Date))]
(if (or (nil? last-updated#)
(> (- cur-time# last-updated#) 10000))
(swap! cached assoc ~id {:time cur-time#
:content ~content}))
(:content (get @cached ~id))))
We can move the logic which checks if we should use a cached value into our macro and pass in the id and the s-expression to run if cache needs to be updated. The code looks very similar to our original version, except for a few new symbols. First thing you'll notice is that we used ` in front of our let expression, this quotes the body of the expression. The # at the end of the binding names ensures that the names are unique and won't collide with other symbols at compile time. Finally ~ says that the next expression should be unquoted.
Let's run macroexpand again to make sure our macro is outputting something reasonable:
(pprint (macroexpand '(cache postid (entry (get-post postid)))))
(let*
[last-updated__1294__auto__
(:time (clojure.core/get @agents/cached postid))
cur-time__1295__auto__
(.getTime (new java.util.Date))]
(if
(clojure.core/or
(clojure.core/nil? last-updated__1294__auto__)
(clojure.core/>
(clojure.core/- cur-time__1295__auto__ last-updated__1294__auto__)
10000))
(clojure.core/swap!
agents/cached
clojure.core/assoc
postid
{:content (entry (get-post postid)), :time cur-time__1295__auto__}))
(:content (clojure.core/get @agents/cached postid)))
This definitely looks like the logic we're expecting. Any time we use this macro, it will be replaced with the code similar to the above, where the s-expression is inside the if block, and only gets called if cache needs to be updated. Now we can easily cache any s-expressions with minimal change to the original code and all the caching logic sits in one convenient place:
(defpage "/blog/:postid" {:keys [postid]}
(cache postid (entry (db/get-post postid))))
As I've mentioned before, there are many other uses for macros, but I hope this gives a clear example of a concrete situation where a macro facilitates cleaner code and provides an easy way to avoid repetition.
less is more
(iterate think thoughts) 20 07 2012
An expressive language has many benefits. The most obvious one is that you have to write less code to solve your problem. The reason you write less code is often not because the syntax is more terse, but because you're using better abstractions. For example, instead of writing a loop, you can use an iterator function to do the work:
(loop [count 0
[head & tail] items]
(if tail
(recur (+ count head) tail)
(+ count head)))
(reduce + items)
One non-obvious benefit of having less code is that it makes it much easier to throw code away. In a verbose language where you have to write a lot of code to solve simple problems, you tend to become attached to that code. In a language where you can express complex things in a relatively few lines, it's not a big issue to replace those with a few different lines. This encourages refactoring as you go, instead of waiting until you have a mountain of code accumulated and you really need to do something about it.
perfection
(iterate think thoughts) 20 07 2012
There's a quote by Antoine de Saint-Exupery that says: "Perfection is achieved, not when there is nothing more to add, but when there is nothing left to take away". I think any experienced programmer can relate to that. You always strive to find the most elegant solution which describes the problem simply and clearly.
A lot of novice programmers have a habit of writing clever code which uses some esoteric properties of the language, or other tricks to get the job done. An experienced programmer knows that the real cleverness lies in being able to solve a problem with very simple code, that might even seem obvious in retrospect.
Eventually one develops an intuition for coming up with solutions which do not involve kludges, avoid edge cases, and forgo cleverness in favor of simplicity. Sometimes, however, this can lead to paralysis, where you don't yet know the elegant solution and you are unwilling to write down the one you know to be imperfect.
I find that REPL development is a great tool for overcoming this dilemma. You can quickly start experimenting with your problem, and through the experimentation gain the understanding necessary to implement it properly. At this point you can easily refactor your existing ugly solution into something beautiful.
all things being equal
(iterate think thoughts) 13 07 2012
You might have heard terms such as anonymous functions, first class functions, higher order functions, and closures. These might sounds mathy and imposing, but they're very simple ideas. In fact, I'll argue that they make the language simpler and more consistent.
In some languages there's a distinction between a function and a variable. You can assign variables, pass them in as parameters, and return them. Yet when it comes to functions, all you can do is define them and call them.
If you take a moment to think about it, I think you'll agree that this distinction is fairly arbitrary. There's no practical reason why we shouldn't be able to do all the things we do with variables with functions.
Let's look at some things that become possible once this distinction is erased. Sometimes we like to use values inline and not assign them to a variable, we usually do this because the value is only going to appear once, and we don't want to go through the ceremony of naming it.
If our language supports anonymous functions, we can do the same thing with a small piece of logic. If it's only needed in a single situation then we can make an anonymous function and call it directly:
((fn [x] (* 2 x)) 5)
10
Here we created an anonymous function which takes a value and multiplies it by 2, and we passed 5 to it as a parameter. Just as we name values which we reuse in multiple places, so can we name functions:
(def times-2 (fn [x] (* 2 x)))
and then call them by their name instead
(times-2 5)
10
The other thing we said that we can do with variables is pass them as parameters to functions. By being able to pass functions to other functions, we're able to decompose our logic into smaller chunks.
If we takes our times-2 function and pass it in as a parameter to an iterator function such as map, it in turn can apply it to each element in a collection:
(map times-2 '(1 2 3 4))
(2 4 6 8)
You might recognize this as the strategy pattern from OO. Turns out that all the complexity in the pattern comes from the idea of treating functions as second class citizens. Which brings us to the idea of a first class function. All that means is that a function is treated no differently than a variable. The only other thing we haven't defined is the higher order function, map in the above example is such a function. Once again, there's nothing complicated about the concept. Any function which can accept another function as a parameter is a higher order function.
Finally, what happens if functions can return functions as output. There are many uses for this, but I'd like to focus on one that will be familiar from OO. When we create a class we often use a constructor to initialize some data that will be available to the methods of the instantiated object.
In a functional language we can achieve this by having a function which takes some parameters and returns another function. Because the inner function was defined in scope where the parameters are declared it too can access them. Here's an example:
(defn foo [x]
(fn [y] (* x y)))
((foo 2) 5)
10
Function foo accepts parameter x and returns an anonymous function which in turn accepts a parameter y and multiplies them together. Function foo is said to close over its parameters, and hence it's called a closure. Unlike a constructor a closure does not introduce any special cases. It's just a function that returns a result which itself happens to be a function.
Treating functions as first class citizens makes the language more uniform. Instead of having special constructs for specific cases, we have a general purpose tool that we can apply in many situations.
limits of mutation
(iterate think thoughts) 12 07 2012
When you start learning functional programming you will quickly notice that you can't simply mutate data in place as you might be used to. Initially you might find this odd and restrictive, but it turns out there are also some tangible benefits to this approach.
Mutable data structures are very simple in nature. They reference a location in memory where some value can be stored, when that value changes the old one is simply replaced with the new.
Persistent data structures create revisions of the data when changes are made. We pay a small penalty in performance compared to in place mutation, but we gain a history of changes that exists as long as its referenced somewhere.
This means that if a function accepts some data as a parameter, you don't have to worry if anybody else is referencing that data when you work with it. Any time you change the data you get a new version without paying the penalty of copying it. By contrast, we always have to be aware if a reference may be used else where when working with mutable data. By removing this worry, we can reduce the scope of things that we need to keep in our heads when trying to understand what a particular piece of code does.
The benefits stack up as your project grows, as it becomes infeasible to keep the totality of the code in ones head. And it's a huge benefit when working in a threaded environment and shared data can easily be corrupted.
What might seem like an inconvenience at first turns out to be a net benefit. Ensuring that the data is not modified outside the intended context has been offloaded to the language instead of being done by you manually. I would liken this to use of garbage collection, where the language is responsible for most memory reclamation. In both cases it's better to let the machine do tasks that can be automated leaving you to solve the real problems.
we'll do it live!
(iterate think thoughts) 10 07 2012
One thing I love about working in Clojure is how interactive the development environment is. Clojure being a Lisp provides a REPL (read, evaluate, print, loop), which works exactly like it sounds. You send an expression to the reader, which will then evaluate it, print the result, and wait for another expression to read.
Clojure IDEs provide tight integration with the REPL. It is possible to connect your application to it and have it load all the libraries and dependencies. At this point you can write your new code in the IDE and have the REPL evaluate it in the context of your running application.
In non-trivial applications it's often necessary to build up a particular state before you can add more functionality. For example a user has to login then view some data from a backend, then you need to write functions to format and display this data. With a REPL you can get the application to the state where the data is loaded and then write the display logic interactively without having to reload the application every time you make a change.
I find this method of development a lot more satisfying, as you get immediate feedback from your application when you add or modify code, and you can easily try things and see how they work. It encourages extermination and refactoring code as you go, which I think helps write better and cleaner code.
This technique is common in Lisp and Smalltalk development, but for reasons unknown has not penetrated into mainstream languages.
lost in patterns
(iterate think thoughts) 09 07 2012
Design patterns are heavily used in the OO world, and there are many lengthy books written about them. I'd like to examine why this is and what these patterns stem from exactly.
As the name implies, design patterns are templates for structuring code to solve common problems. This is a fine idea in and of itself, but the following question needs to be asked. If programming is ultimately about automation, and patterns are repetitive tasks by their very nature, then why are we forced to write them out by hand each time?
The reason for this appears to be due to lack of abstraction in the language. Many design patterns are simply specific cases of an underlying abstraction which unifies them. Having a language which can express such abstractions means that you don't have to learn many different patterns for specific situations.
Bruce Lee once said "I fear not the man who has practiced ten thousand kicks once. But I fear the man who has practiced one kick ten thousand times". I think this applies here as well: it's better to learn a general solution for many problems, than to have a specific solution for each small problem you run into.
So, next time you're looking at a language, don't simply look at the one that has the bigger list of features, instead look for one with a few features that work well together.
If you've seen any Lisp code before, you've probably noticed that it looks different from other languages in that the parens come before the function name, prefix notation is prevalent, and that functions are often nested inside one another. The technical term for this is that Lisp uses s-expressions.
These might look awkward at first, and many newcomers immediately think that they can and should be improved upon. Surely it would be easy to write a preprocessor that would let you write code as you write it in other languages and then convert it to s-expressions. This is absolutely true and in fact there is one prominent attempt called sweet-expressions. Despite all that, the idea just doesn't catch on and I'd like to explore what the advantages of working with raw s-expressions are.
One immediate benefit is that Lisp syntax follows the principle of least astnoishment very well. Any time you read code, it always follows the pattern of (function-name arguments), which makes for very consistent looking code. This helps reduce the mental overhead when reading and writing code, instead of worrying about language quirks you can focus on the actual problem you're solving.
Another benefit is that the code provides extra information about itself, which is not available in other languages. With s-expressions you can visually see how functions relate to one another. In essence the code is rendered as a tree representing the execution logic.
Finally, the s-expressions make editing code a completely different experience from other languages. Instead of working in terms of lines, you work in terms of functions. With a ParEdit style editor you can select code not by line but by function! Now you can easily select, move, and reparent pieces of logic. Editing code becomes like playing with Lego pieces and arranging them in different ways.
In my experience these things make the language more enjoyable to work with and the benefits far outweigh any perceived ugliness. After a while you don't even see the parens.
Temporally oblivious
(iterate think thoughts) 04 07 2012
Objects are state machines, yet no mainstream OO language ensures the consistency of the internal state of the object over time. This means that in a multi-threaded environment it's possible to see the internal state of the object while it's being updated. What's even worse is that even if you don't see a partial state, you might be seeing an unexpected state, since someone else with a reference to the object might have updated it for their use, which conflicts with the way you're using it.
The whole situation is fairly messy, but what is the alternative you might ask. My answer would be not to use in place mutation unless absolutely necessary. Instead it's much better to use persistent data structures, which are temporally aware. A persistent data structure works in a fashion akin to version control. Any time a change to the data is made, a delta is created between the existing data and the new data. From user perspective you're simply copying the data, but you're only paying the price of the change.
This concept turns out to be very powerful as it inherently contextualizes any changes. It also allows doing things like rollbacks trivially as you just have to unwind your operations to see a previous state.
why all the parens
(iterate think thoughts) 28 06 2012
A common complaint you hear from people about Lisp is that there are too many parens. Let's compare what's involved in writing a Java method to writing a Clojure function:
public static void foo(String bar, Integer baz) {
System.out.println(bar + ", " + baz);
}
(defn foo [bar baz]
(println bar ", " baz))
The number of parens is exactly the same, but there's clearly more noise in the Java version. In my opinion the noise adds up and it distracts from the intent of the code. The more code you have the harder it is to tell what it's doing and conversely the harder it is to spot bugs in it. I'll illustrate this with a concrete example.
The problem is to display a formatted address given the fields representing it. Commonly an address has a street, a city, a postal code, and a country. We'll have to examine each of these pieces, remove the null and empty ones and insert some separator between them.
So given something like
street: 1 Main street
city: Toronto
posal: A1B 2C3
country: Canadawe'd like to output
1 Main street, Toronto, A1B 2C3, Canadawe should obviously handle empty fields and not have ,, if the field isn't there, and we should make sure we handle nulls in case the whole address is null or some fields in the address are null.
Let's first examine how we would write this in Java:
public static String concat(String... strings) {
if (null == strings) return null;
StringBuffer sb = new StringBuffer();
for (String s : strings) {
if (null == s || s.equals("")) continue;
sb.append(s);
sb.append(',');
}
String s = sb.toString();
return s.substring(0, s.lastIndexOf(','));
}
- lines of code : 11
- parens: 26
- curly braces: 4
- semicolons: 7
- colons: 1
- dots: 6
Now let's compare this to Clojure:
(defn concat-fields [& fields]
(apply str (interpose "," (remove empty? fields))))
- lines of code : 2
- parens: 8
- brackets: 2
The Clojure version has significantly less code, and a lot less noise. In addition, we didn't have to do any explicit null checks in our code, and we were able to write the complete solution simply by composing together functions from the standard library!
One very important difference between the Java version and the Clojure version is that the Java version talks about how something is being done, while the Clojure version talks about what is being done. In other words, we have to step through the Java version in our heads to understand what the code is doing.
In the Clojure version this step is not present because the code says what it's doing, and all the implementation details have been abstracted from us. This is code reuse at work, where we can write simple functions that do one thing well and chain them together to achieve complex functionality.
This bears a lot of resemblance with the Unix philosophy: "Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface." Except in our case we're dealing with functions instead of programs and common data structures as a universal interface in the language.
popularity contests
(iterate think thoughts) 23 06 2012
The argument that Lisp is not popular because it's somehow a bad language is not really sound. A lot of great technologies have lost out to inferior ones because of poor marketing. The Lisp community has not in general been great at marketing the language, and it is viewed as downright scary by majority of people.
It also doesn't help that there is no definitive standard distribution of Lisp, or a comprehensive standard library. Most people aren't going to jump through hoops to learn an esoteric language. So, it is no surprise that there aren't a lot of big commercial Lisp projects. It becomes a catch 22, where due to lack of Lisp developers companies develop apps in more popular languages, and people don't bother learning Lisp because there are no jobs for it.
Clojure avoids a lot of the pitfalls by running on the JVM and interfacing with Java. Java is rather dominant in the industry, a lot of companies already use it, and using alternative languages on the JVM is also becoming a fairly common practice. Strong Java integration also means that you have access to a great wealth of existing libraries.
Having the ability to introduce Clojure in an existing project without having to change your environment is a huge plus. You can continue to use the same build tools, the same IDE, and same application servers for deployment. The only thing that changes is the actual language.
From the language design perspective I think it is also an improvement over the traditional Lisp syntax. For example let's compare let in CL to let in Clojure:
(let
((a1 b1)
(a2 b2)
(an bn))
(some-code a1 a2 an))
(let [a1 b1
a2 b2
an bn]
(some-code a1 a2 an))
To me Clojure version is easier to read because there's less noise, and I find the literal vector notation helps break up the code visually. Which brings me to the second thing I like, having literal vector, set, and map notation. I find it makes code more legible and helps see what's going on in a function.
The next thing I really like, that Clojure introduces, is destructuring. You can take any arbitrary data structure and read it backwards. Here are a few examples of what I'm talking about:
(def {:a [1 2 3] :b {:c 4} :d 5})
(defn foo [{a :a b :b}]
(println a b))
(defn bar [{:keys [a b d]]
(println a b d))
(defn baz [{[a b c] :a {d :c} :b e :d}]
(println a b c))
this also works in let statements, and again I find that it improves readability, especially in larger programs. While a minor nitpick I also like the naming conventions in Clojure standard library better. Names such as car and cdr are archaic in my opinion.
In Java passing logic as a parameter requires an inordinate amount of work and it's never the first choice to do so. So in most cases you're better off just writing a loop and doing the null check in it. Let's look at a concrete example of what I'm talking about here. Let's say we want to filter collections based on a predicate. The standard way you would do that in Java is to write a loop:
public static List<Integer> filterEven(Collection<Integer> col) {
if (null == col) return null;
List<Integer> result = new LinkedList<Integer>();
for (Integer i : col) {
if (i % 2 == 0) result.add(i);
}
return result;
}
then if later I need to filter odd numbers I'll probably write another loop that looks almost identical except for the actual test. Obviously, the looping logic should be abstracted here, but let's look at what's involved in doing that in Java:
public interface Predicate<T> {
public boolean matches(T t);
}
public class EvenPredicate implements Predicate<Integer> {
public boolean matches(Integer i) {
return i % 2 == 0;
}
}
import java.util.Collection;
import java.util.LinkedList;
import java.util.List;
public class Filter {
public static <T> List<T> filterCollection(Collection<T> col,
Predicate<T> predicate) {
List<T> result = new LinkedList<T>();
for (T t : col) {
if (predicate.matches(t)) {
result.add(t);
}
}
return result;
}
}
That's a lot more work than just writing a loop, and unless you saw this pattern many times you probably wouldn't consider doing it. Now let's compare this to a language like Clojure, where I would use a higher order function and pass in the matcher without having to do any preliminary setup:
(filter even? (range 10))
what if I wanted to write a loop to do that
(loop [nums (range 10)
even-nums []]
(if (empty? nums)
even-nums
(recur (rest nums)
(if (even? (first nums))
(conj even-nums (first nums)) even-nums))))
all of a sudden the situation is reversed, it's a lot more code to do explicit looping, and it's trivial to use a higher order function to do this task. So the language encourages you to write code through function composition by design. Being able to easily separate iteration from the logic applied inside it means that we can write code that's shorter, cleaner, and less error prone.
Instance methods are always associated with a particular object that may or may not exist. This means that before we can call a method we must first check if an object is null. This becomes especially tedious if you have nested objects. For example if we have a following situation:
users.getUser("foo").getAddress().getStreet();
the above code would be unsafe, since every single method call could potentially lead to a null pointer. This means that we have to instantiate and check each object individually:
String street = null;
User user = users.getUser("foo");
if (null != user)
Address address = user.getAddress();
if (null != address)
street = address.getStreet();
Not only is this tedious and error prone, but it's also one more thing that you actively have to think about.
Let's compare this situation to the functional approach. In a functional language functions exist independent of data, much like static methods in OO. This means that we can't get a null pointer while calling a function. The author of the function can do all the error checking in the function once, and the user does not need to worry about it. When you chain such functions together, the null values can bubble up as the result:
(:street (:address (:foo users)))
This code will not throw any null pointer exceptions, and instead a null value will be returned. It has less noise, it's less error prone, and it's easier to read.
Anatomy of a Reducer
Clojure News 15 05 2012
Last time, I blogged about Clojure’s new reducers library. This time I’d like to look at the details of what constitutes a reducer, as well as some background about the library.
What’s a Reducing Function?
The reducers library is built around transforming reducing functions. A reducing function is simply a binary function, akin to the one you might pass to reduce. While the two arguments might be treated symmetrically by the function, there is an implied semantic that distinguishes the arguments: the first argument is a result or accumulator that is being built up by the reduction, while the second is some new input value from the source being reduced. While reduce works from the 'left', that is neither a property nor promise of the reducing function, but one of reduce itself. So we’ll say simply that a reducing fn has the shape:
(f result input) -> new-resultIn addition, a reducing fn may be called with no args, and should then return an identity value for its operation.
Transforming Reducing Functions
A function that transforms a reducing fn simply takes one, and returns another one:
(xf reducing-fn) -> reducing-fnMany of the core collection operations can be expressed in terms of such a transformation. Imagine if we were to define the cores of map, filter and mapcat in this way:
(defn mapping [f]
(fn [f1]
(fn [result input]
(f1 result (f input)))))
(defn filtering [pred]
(fn [f1]
(fn [result input]
(if (pred input)
(f1 result input)
result))))
(defn mapcatting [f]
(fn [f1]
(fn [result input]
(reduce f1 result (f input)))))There are a few things to note:
-
The functions consist only of the core logic of their operations
-
That logic does not include any notion of collection, nor order
-
filtering and kin can 'skip' inputs by simply returning the incoming result
-
mapcatting and kin can produce more than one result per input by simply operating on result more than once
Using these directly is somewhat odd, because we are operating on the reducing operation rather than the collection:
(reduce + 0 (map inc [1 2 3 4]))
;;becomes
(reduce ((mapping inc) +) 0 [1 2 3 4])Reducers
We expect map/filter etc to take and return logical collections. The premise of the reducers library is that the minimum definition of collection is something that is reducible. reduce ends up using a protocol (CollReduce) to ask the collection to reduce itself, so we can make reducible things by extending that protocol. Thus, given a collection and a reducing function transformer like those above, we can make a reducible with a function like this:
(defn reducer
([coll xf]
(reify
clojure.core.protocols/CollReduce
(coll-reduce [_ f1 init]
(clojure.core.protocols/coll-reduce coll (xf f1) init)))))Now:
(reduce + 0 (map inc [1 2 3 4]))
;;becomes
(reduce + 0 (reducer [1 2 3 4] (mapping inc)))That’s better. It feels as if we have transformed the collection itself. Note:
-
reducer ultimately asks the source collection to reduce itself
-
reducer will work with any reducing function transformer
Another objective of the library is to support reducer-based code with the same shape as our current seq-based code. Getting there is easy:
(defn rmap [f coll]
(reducer coll (mapping f)))
(defn rfilter [pred coll]
(reducer coll (filtering pred)))
(defn rmapcat [f coll]
(reducer coll (mapcatting f)))
(reduce + 0 (rmap inc [1 2 3 4]))
;=> 14
(reduce + 0 (rfilter even? [1 2 3 4]))
;=> 6
(reduce + 0 (rmapcat range [1 2 3 4 5]))
;=> 20From Reducible to (Parallel) Foldable
While it is an interesting exercise to find another fundamental way to define the core collection operations, the end result is not much different, just faster, certainly something a state-of-the-art compilation and type system (had we one) might do for us given sequence code. To stop here would be to completely miss the point of the library. These operations have different, fundamentally simpler semantics than their sequence-based counterparts.
How does one define parallel mapping/filtering/mapcatting etc? We already did! As long as the transformation itself doesn’t care about order (e.g. as take does), then a reducer is as foldable as its source. As with reduce, fold bottoms out on a protocol (CollFold), and our reducer can extend that:
(defn folder
([coll xf]
(reify
;;extend CollReduce as before
CollFold
(coll-fold [_ n combinef reducef]
(coll-fold coll n combinef (xf reducef))))))Note that:
-
folder has the same requirements as reducer - collection + reducing function transformer
-
when fold is applied to something that can’t fold, it devolves to reduce
Thus the real definitions of reducers/map et al use folder (while take uses reducer):
(defn rmap [f coll]
(folder coll (mapping f)))
(defn rfilter [pred coll]
(folder coll (filtering pred)))
(defn rmapcat [f coll]
(folder coll (mapcatting f)))Thus a wide variety of collection transformations can instead be expressed as reducing function transformations, and applied in both sequential and parallel contexts, across a wide variety of data structures.
The library deals with several other details, such as:
-
the transformers all need a nullary arity that just delegates to the transformed reducing function
-
the transformers support a ternary arity where 2 inputs are supplied per step, as occurs with reduce-kv and map sources
-
all of the reducers are curried
These additions are all mechanical, and are handled by macros. It is my hope that the above will help illuminate the core logic underlying the library.
Background
Much prior work highlights the value of fold as a primary mechanism for collection manipulation, superior to iteration, although most of that work was done in the context of recursively defined functions on lists or sequences - i.e. fold implies foldl/foldr, and the results remain inherently sequential.
The two primary motivators for this library were the Haskell Iteratee library and Guy Steele’s ICFP '09 talk.
Haskell Iteratees
The Haskell Enumerator/Iteratee library and its antecedents are an inspiring effort to disentangle the source of data and the operations that might apply to it, and one of the first I think to reify the role of the 'iteratee'. An enumerator makes successive calls to the iteratee to supply it items, decoupling the iteratee from the data source. But the iteratee is still driving in some sense, as it is in charge of signaling Done, and, it returns on each step the next iteratee to use, effectively dictating a single thread of control. One benefit is that even operations like take can be defined functionally, as they can encode their internal state in the 'next' iteratee returned. OTOH, and unlike reducers, the design wraps the result being built up in a new iteratee each step, with potential allocation overhead.
Being an automaton in a state, an iteratee is like a reified left fold, and thus inherently serial. So, while they form quite a nice substrate for the design of, e.g. parsers, iteratees are unsuitable for defining things like map/filter etc if one intends to be able to parallelize them.
Guy Steele’s ICFP '09 talk
This talk boils down to - stop programming with streams, lists, generators etc if you intend to exploit parallelism, as does the reducers library.
Where reducers diverges from that talk is in the structure of the fork/join parallel computation. Rather than map+reduce, reducers uses reduce+combine. This reflects 2 considerations:
-
It is accepted fork/join practice that at some point you stop splitting in half and handle the leaves 'sequentially'
-
if the best way to do that at the top is reduce, why not at the bottom as well?
-
-
map forces a result per input
You can see the awkwardness of the latter in the map/reduce-oriented definition of parallel filter in the talk, which must 'listify' items or return empty lists, creating a bunch of concatenation busy-work for the reducing step. Many other collection algorithms suffer similarly in their map/reduce-oriented implementations, having greater internal complexity and wrapping the results in collection representations, with corresponding creation of more garbage and reduction busy-work etc vs the reducing function transformer versions of same.
It is interesting that the accumulator style is not completely absent from the reducers design, in fact it is important to the characteristics just described. What has been abandoned are the single initial value and serial execution promises of foldl/r.
I’m happy to have pushed today the beginnings of a new Clojure library for higher-order manipulation of collections, based upon reduce and fold. Of course, Clojure already has Lisp’s reduce, which corresponds to the traditional foldl of functional programming. reduce is based upon sequences, as are many of the core functions of Clojure, like map, filter etc. So, what could be better? It’s a long story, so I’ll give you the ending first:
-
There is a new namespace: clojure.core.reducers
-
It contains new versions of
map,filteretc based upon transforming reducing functions - reducers -
It contains a new function,
fold, which is a parallel reduce+combine -
folduses fork/join when working with (the existing!) Clojure vectors and maps -
Your new parallel code has exactly the same shape as your existing seq-based code
-
The reducers are composable
-
Reducer implementations are primarily functional - no iterators
-
The model uses regular data structures, not 'parallel collections' or other OO malarkey
-
It’s fast, and can become faster still
-
This is work-in-progress
Basics
The story starts best at the bottom.
Clojure and other functional languages have a function called map that takes a function and a collection/list.
-
What does it mean to map a function on a collection?
-
What are the common signatures?
-
Do they complect what to do with how to do it?
The classic recursive functional definition of map is to apply f to the first thing in the collection, then cons the result onto the result of mapping f on the rest of the collection. This definition includes plenty of 'how':
-
How: mechanism - recursion
-
How: order - sequentially
-
How: laziness - (often) lazily
-
How: representation - making a list/seq, or other concrete collection
Newer OO frameworks will often remove some of these problems by having map be a function of fn * Coll → Coll for any type of Coll, removing the sequentiality but also losing the laziness, and they still specify a concrete collection result.
Semantically, and minimally, map means "apply-to-all" e.g. (map inc coll) means give me a (logical) collection where every item is one greater than it was in coll. But, map doesn’t know how to navigate around every collection - the use of seqs/lists/iterators/streams etc forces a shared known representation. Nor does inc (or any function) know how to apply itself to every collection representation, else we could just say (inc coll).
The only thing that knows how to apply a function to a collection is the collection itself.
What is the generic gateway to a collection applying things to itself? In Clojure, it is (internal) reduce.
We now have a new super-generalized and minimal abstraction for collections - a collection is some set of things that, when given a function to apply to its contents, can do so and give you the result, i.e. a collection is (at minimum) reducible. In other words, you can call reduce on it.
Thus, core.reducers/map is a function of fn * reducible → reducible. (Whereas core/map is a function of fn * seqable → seqable.)
Now, how? If someone is going to ask the result of (map inc coll) to reduce itself with some function f, map must ultimately ask coll to do the job. Rather than pass coll f, map passes coll a new, transformed, reducing function that takes what coll supplies, calls inc on it, and then calls f on that.
(reduce + (r/map inc [1 2 3])) === (reduce (fn [ret x] (+ ret (inc x))) (+) [1 2 3])i.e. the core work of map f looks like this:
(fn [f1]
(fn [ret v]
(f1 ret (f v))))It takes a reducing function f1, and returns a new reducing function that calls f1 after applying f to its input.
Thus you can define map as a function of fn * reducible → reducible by merely transforming the reducing function. Mapping is semantically a function of the function of one step of a reduction. This transformation is decomplected from both representation and order. We call functions such as this map, that take a reducible, and in turn return something reducible via transformation of the reducing function, reducers.
Now let’s revisit the hows above…
-
How: mechanism - functional transformation of reducing function
-
How: order - doesn’t know
-
How: laziness - doesn’t know
-
How: representation - doesn’t build anything
It is important to note that now, when (map f coll) is called nothing happens except the creation of a recipe for a new collection, a recipe that is itself reducible. No work is done yet to the contained elements and no concrete collection is produced.
The beautiful thing is that this 'transformation of reducing function' mechanism also works for many of the traditional seq functions, like filter, take, flatten etc. Note the fact that filter is (potentially) contractive, and flatten is (potentially) expansive per step - the mechanism is general and not limited to 1:1 transformations. And other reducer definitions are as pretty as map’s - none of the imperativeness of iterators, or generators with yield.
Ok, So Where’s My Cake?
If map doesn’t do the work of mapping, but merely creates a recipe, when does the work get done? When you reduce its result:
(require '[clojure.core.reducers :as r])
(reduce + (r/filter even? (r/map inc [1 1 1 2])))
;=> 6That should look familiar - it’s the same named functions, applied in the same order, with the same arguments, producing the same result as the Clojure’s seq-based fns. The difference is that, reduce being eager, and these reducers fns being out of the seq game, there’s no per-step allocation overhead, so it’s faster. Laziness is great when you need it, but when you don’t you shouldn’t have to pay for it.
The reducer fns are curried, and they can be easily composed:
;;red is a reducer awaiting a collection
(def red (comp (r/filter even?) (r/map inc)))
(reduce + (red [1 1 1 2]))
;=> 6Thus reduction 'recipes' (reducers) are first class.
What if we want a collection result? It’s good to know that into uses reduce:
(into [] (r/filter even? (r/map inc [1 1 1 2])))
;=> [2 2 2]Note there are no intermediate collections produced.
And, of course, you don’t always want a result of the same collection type:
(into #{} (r/filter even? (r/map inc [1 1 1 2])))
;=> #{2}Simplicity is Opportunity
Decomplecting the core operations from representation and laziness has given us some speed, but what about the elimination of order? It should open the door to parallelism, but we are stuck with the semantics of reduce being foldl, i.e. it uses an accumulator and is fundamentally serial. We can parallelize reduction by using independent sub-reductions and combining their results, and the library defines a function that does just that: fold.
The primary signature of fold takes a combining function, a reducing function, and a collection and returns the result of combining the results of reducing subsegments of the collection, potentially in parallel. Obviously if the work is to occur in parallel, the functions must be associative, but they need not be commutative - fold preserves order. Note that there is no initial 'seed' or 'accumulator' value, as there may be with reduce and foldl. But, since the subsegments are themselves reduced (with reduce), it raises the question as to what supplies the seed values for those reductions?
The combining function (an associative binary fn) must have some 'identity' value, a value that, when combined with some X, yields X. 0 is an identity value for +, as is 1 for *. The combining fn must supply an identity value when called with no arguments (as do + and *). It will be called with no arguments to supply a seed for each leaf reduction. There is a fn (called monoid, shh!) to help you build such combining functions.
If no combining fn is supplied, the reducing fn is used. Simple folds look like reduces:
(r/fold + [1 2 3 4])
;=> 10But by promising less (i.e. not promising stepwise reduction from left or right) fold can do more - run in parallel. It does this when the collection is amenable to parallel subdivision. Ideal candidates are data structures built from trees. Clojure vectors and maps are trees, and have parallel implementations of fold based upon the ForkJoin framework.
What if the underlying collection is not amenable (e.g. is a sequence)? fold just devolves into reduce, producing the same semantic, if not physical, result.
There’s a tremendous amount you can accomplish with this reduce+combine strategy, especially when you consider that the map, filter etc reducers will not constitute independent layers of parallel jobs - they just transform the reducing fn working on the leaves.
You can have a look at the cat function included in the library for an interesting example of a combining fn. cat quickly gathers up the fold results, forming a binary tree with the reductions as leaves. It returns a highly abstract, yet now quite useful 'collection' that is just counted, reducible, foldable and seqable.
Oh yeah, perf. Don’t be surprised to see things become 2-3X faster, or more with more cores.
More Opportunity (i.e. Work)
As much fun as this is, there’s still more fun to be had by those so inclined:
-
There are more seq fns that could become reducer fns
-
Given multiple iterable sources, we should be able to build a multi-reducible, recovering the multi-input capabilities of map.
-
Arrays, arraylists, strings etc are all amenable to parallel fold.
-
fork/join-based vector fold is 14 lines, so these are not difficult.
-
-
Those IFn.LLL, DDD etc primitive-taking function interfaces can now spring to life.
-
We should be able to build primitive-transmitting reducer function pipelines.
-
We’d then need to look for and use them in the reductions of arrays and vectors of primitives
-
-
Internal reduce solves the lazily dangling open resource problem, a problem solved similarly by Haskell’s enumerators and iteratees. (Note that unlike iteratees, reducers do not allocate wrappers per step)
-
We need reducible I/O sources.
-
Summary
By adopting an alternative view of collections as reducible, rather than seqable things, we can get a complementary set of fundamental operations that tradeoff laziness for parallelism, while retaining the same high-level, functional programming model. Because the two models retain the same shape, we can easily choose whichever is appropriate for the task at hand.
Follow Up
See the follow up blog post for more details about what constitutes a reducer, as well as some background about the library.
Rich
subject to change
(iterate think thoughts) 03 05 2012
The OO world view requires us to classify data in order to work with it. For example if we're talking about a person, we might create a Person class and add some fields to it, such as age, name, and etc. Then we'll create instances of this class and use them in our program.
The problem with this approach is that the classification is only meaningful within a particular context. The classification is not inherent to the data itself, but rather it's a transient view of the data at a specific time in a particular domain.
When we create a class we make assumptions about the context in which the data will be used. These assumptions are often incomplete, and even when they are, the nature of the problem can change over time. The requirements may change, new requirements might come up, or we might have simply misunderstood the problem when we designed our classes.
The way OO deals with this is by remapping the classes to a new domain. We might extend the class, write a wrapper, or use an adapter pattern to bridge the contexts. But this is solving a problem we ourselves have introduced by assigning a permanent classification to our data.

Enter Rich, with Parentheses
In the beginning, there was a guy with an idea. That guy was Rich Hickey, and his idea was to combine the power of Lisp with the reach of a modern managed runtime. He started with Jfli, embedding a JVM in Lispworks' Common Lisp implementation. When that proved inadequate, he took a two-year sabbatical to write the compiler that would eventually become Clojure: a completely new Lisp for the JVM with language-level concurrency support.
In late 2007, Rich Hickey presented Clojure at a meeting of the New York Lisp users' group, LispNYC. I was there, and I was so excited by what I saw that I wrote one of the first blog articles about Clojure. Three days later, I was asking questions about Java interop on the Clojure mailing list.
Those early days were fun, participating in heady discussions about fundamental language features like nil vs. false and argument order. It felt like the beginning of something genuinely new. The community was tiny, and Rich participated in almost every discussion on the mailing list or IRC.
How times have changed. The Clojure mailing list has over five thousand members, and we just wrapped up the second international Clojure conference with nearly four hundred attendees. Google Groups tells me I’ve racked up over a thousand posts on the mailing list, which is shocking to me. There are five books and counting about Clojure. People are building businesses and careers on it. Who would have guessed, in 2007, that we would be here in just four years?
Enter Second Stuart
(That was a cheap shot. Hi, Stu! :)
In the Summer of 2008, Stuart Halloway started blogging about Clojure. With his co-founder Justin Gehtland, Stuart H. had already built a business helping big companies navigate from ponderous Java development to more agile practices and more expressive languages like Ruby. Stuart H. decided that Clojure was the next big thing. He wrote the first book about Clojure (soon to get a 2nd edition). When he and Rich met at the 2008 JVM Language Summit, they started a long conversation that would eventually become a partnership.
Clojure Contrib: The Beginning
Around the same mid-2008 time frame, "clojure-contrib" began its life as a Subversion repository where community members could share code. There were twelve committers and no rules, just a bunch of Clojure source files containing code that we found useful. I contributed str-utils, seq-utils, duck-streams, and later test-is.
The growth of contrib eventually led to the need for some kind of library loading scheme more expressive than load-file. I wrote a primitive require function that took a file name argument and loaded it from the classpath. Steve Gilardi modified require to take a namespace symbol instead of a file. I suggested use as the shortcut for the common case of require followed by refer. This all happened fairly quickly, without a lot of consideration or planning, culminating in the ns macro. The peculiarities of the ns macro grew directly out of this work, so you can blame us for that.
Clojure-contrib also prompted a question that every open-source software project must grapple with: how to handle ownership. We’d already gone through two licenses: the Common Public License and its successor, the Eclipse Public License.
Rich proposed a Clojure Contributor Agreement as a means to protect Clojure’s future. The motivation for the CA was to make sure Clojure would always be open-source but never trapped by a particular license. The Clojure CA is a covenant between the contributor and Rich Hickey: the contributor assigns joint ownership of his contributions to Rich. In return, Rich promises that Clojure will always be available under an open-source license approved by the FSF or the OSI.
Some open-source projects got stuck with the first license under which contributions were made. Under the CA, if the license ever needs to change again, there would be no obstacles and no need to get permission from every past contributor. Agreements like this have become standard practice for owners of large open-source projects like Eclipse, Apache, and Oracle.
Clojure/core and "New Contrib"
In 2010 I left my cozy academic job and went to work for Relevance, where Stuart Halloway and Rich were discussing a strategic partnership that would eventually become Clojure/core. So what is Clojure/core? It’s a business initiative of Relevance (though not an independent business entity) to provide consulting, training, and development-for-hire services around Clojure. Rich Hickey is an advisor to Clojure/core, but not a Relevance employee.
Members of Clojure/core, of which I am one, have made a commitment to spend their 20% time supporting the Clojure ecosystem. Although Rich still personally reviews every patch for the language itself, the job of answering questions and organizing contributions from a 5000-member community is too big for one person, so Rich delegated that responsibility to Clojure/core.
The first big issue Clojure/core had to confront was the distribution of clojure-contrib. With sixty-plus libraries in one binary release, it was already unwieldy. Since clojure-contrib releases were tied to Clojure language releases, which happened infrequently, development had stalled. There was also vast confusion about what, exactly, clojure-contrib was meant to be. Was it an essential component of the language, a nascent standard library, or a load of crap? (I was inclined to the latter view, especially with regard to my own contributions.)
My attempts at modularizing clojure-contrib within a single Git repository failed to improve the situation. Eventually, we settled on the solution of separate Git repositories for each library. This was a huge amount of work: dozens of repositories to create and hundreds of files to move. Many of the contrib libraries were stagnant, their original authors lacking time to continue working on them.
Finally, almost a year later, the situation has stabilized: contrib libraries, each with its own Git repository, test suite, continuous integration, and independent release cycle. The overall code quality is higher and development is moving forward again.
It was a painful transition for everyone, not least for those of us trying to manage it all and bear the brunt of the inevitable carping. On top of everything else, the whole process overlapped with the release of Clojure 1.3, the first release to break backwards-compatibility in noticeable ways (non-dynamic Vars as a default, long/double as default numeric types).
Our technology choices for Clojure and "new contrib" — GitHub, JIRA, Hudson, and Maven — were driven by several concerns:
-
to be first-class participants in the Java ecosystem
-
to preserve the future-proof licensing structure of the CA
-
to give library developers freedom to develop/release on their own schedule
-
to ensure changes are made only after a thorough review process
The last point was particularly important for patches to the Clojure language. Clojure is very stable: since its first public release, implementation bugs have been rare and regressions almost nonexistent. Most reported bugs are edge cases in Java interop. But stability has a price: new features come more slowly. The majority of JIRA tickets on Clojure are really feature requests. Rich is extremely conservative about adding features to the language, and he has impressed this view on Clojure/core for the purpose of screening tickets.
To take one prominent example, named arguments were discussed as far back as January 2008. Community members developed the defnk macro to facilitate writing functions with named arguments, and lobbied to add it to Clojure. Finally, in March 2010, Rich made a one-line commit adding support for map destructuring from sequential collections. This gave the benefit of keyword-style parameters everywhere destructuring is supported, including function arguments. By waiting, and thinking, we got something better than defnk. If defnk had been accepted earlier, we might have been stuck with an inferior implementation.
Conversely, the decision to move some libraries into the language, notably my testing library, was probably premature. (Stuart Halloway accepts blame for that one. :) Some of the decisions I made in that library could use revisiting, but now clojure.test is what we’re stuck with.
Clojure/dev and the Future
If there was one mistake that I personally made during the 1.3 migration, it was speaking as if Clojure/core owned Clojure and clojure-contrib. We don’t: Clojure is owned by Rich Hickey, and clojure-contrib is owned jointly by Rich Hickey and contributors. But we are the appointed stewards (and Stuarts!) of the open-source Clojure ecosystem. In that role, we have to make decisions about what we choose to invest time in supporting. Given limited time, and following Rich’s conservative position on new features, that decision is usually "no."
It’s a difficult position to be in. Most of Clojure/core’s members come from the free-wheeling, fast-paced open-source world of Ruby on Rails. We really don’t enjoy saying "no" all the time. But a conservative attitude toward new features is exactly the reason Clojure is so stable. Patches don’t get into the language until they have been reviewed by at least three people, one of them Rich Hickey. New libraries don’t get added to contrib without mailing-list discussions. None of the new contrib libraries has reached the 1.0.0 milestone, and probably won’t for some time. These hurdles are not arbitrary; they are an attempt to guarantee that new additions to Clojure reflect the same consideration and careful design that Rich invested in the original implementation.
So what is clojure-contrib today? It’s a curated set of libraries whose ownership and licensing is governed by the Clojure Contributor Agreement. It could also serve as a proving ground for new features in the language, but this does not imply that every contrib library will eventually make it into the language.
With the expansion of contrib, we’ve given name to another layer of organization: Clojure/dev. Clojure/dev is the set of all people who have signed the Clojure Contributor Agreement. This entitles them to participate in discussions on the clojure-dev mailing list, submit patches on JIRA, and become committers on contrib libraries. Within Clojure/dev is the smaller set of people who have been tasked with screening Clojure language tickets. Clojure/core overlaps with both groups.
At the tail end of this year’s Clojure/conj, Stuart Halloway opened the first face-to-face meeting of Clojure/dev with these words: "This is the Clojure/dev meeting. It’s a meeting of volunteers talking about how they’re going to spend their free time. The only thing we owe each other is honest communication about when we’re planning to do something and when we’re not. There is no obligation for anybody in this room to build anything for anybody else."
One consensus that came out of the Clojure/dev meeting was that we need to get better at using our tools, particularly JIRA. We would like to streamline the processes of joining Clojure/dev, screening patches, and creating new contrib libraries. We also need better integration testing between Clojure and applications that use it. Application and library developers can help by running their test suites against pre-release versions of Clojure (alphas, betas, even SNAPSHOTs) and reporting problems early.
But Stu’s last point is an important one: no one in the Clojure community owes anybody anything. If you want something, it’s not enough to ask for it, you need to be willing to do the work to make it happen. At the same time, don’t let a lukewarm response to ideas on the mailing list dissuade you from implementing something you think is valuable. It might just be that no one has time to think about it. Recall keyword arguments: more than two years from inception to completion. We’re in this for the long haul. Join us, be patient, and let’s see where we can go.
Introducing ClojureScript
Clojure News 22 07 2011
The Clojure team is proud to introduce an important addition to the Clojure language ecosystem. ClojureScript is a new compiler for Clojure that targets JavaScript.
A video recording of the ClojureScript announcement is available, along with slides (PDF) from the presentation.
Why JavaScript
The Clojure language was first built on the Java Virtual Machine because of its reach and power on server platforms. For non-server platforms, nothing has greater reach than JavaScript. It’s been called the assembly language of the Web. But beyond Web browsers, JavaScript can be found in mobile devices, set-top boxes, and desktop applications. JavaScript has even made inroads on the server in databases and Web servers. As a result of this reach, a lot of work has gone into making JavaScript engines performant, including JIT-compilation into native code.
But JavaScript’s weakness remains the language itself. Although it has some powerful features such as first-class functions, JavaScript is noted more for its flaws than for its strengths. It was never designed to be a language for large applications.
What if we had a modern, robust, powerful language that could reach to all the places that JavaScript does? This is the goal of ClojureScript.
Where We Are
Try it out! Follow the Quick Start instructions on the ClojureScript wiki.
Here’s a partial list of what has been implemented so far:
-
Protocols and
deftype -
Namespaces
-
Functions:
fn,defn, multiple-arities, variadics -
Destructuring
-
Higher-order functions:
map,reduce,filter, … -
Data structures: lists, maps, vectors, sets
-
Data manipulation functions:
conj,assoc,update-in,… -
Sequences and sequence functions:
first,rest, … -
Macros:
assert,cond,doto,loop,->and->>, … -
Metadata
-
Reader in ClojureScript (think JSON but better)
-
Regular expressions
-
Atoms
-
Core libraries:
clojure.string,clojure.set,clojure.zip, … -
REPL using JDK-embedded JavaScript (Rhino)
ClojureScript is currently in Alpha status. The compiler and core libraries are usable for developing applications, but expect to find bugs and missing pieces of functionality. ClojureScript aims to be a complete implementation of the Clojure language, but some parts aren’t finished yet.
Some parts of the Clojure language have no direct analog in ClojureScript, in particular the concurrency primitives, since JavaScript is single-threaded. There may also be edge cases where the requirements of the JavaScript environment force ClojureScript to have slightly different semantics from Clojure. We will document these differences as we find them.
Obviously, any code making interop calls to Java, as most existing Clojure libraries do, will not work in ClojureScript. Code written in pure Clojure will probably work in ClojureScript with minor adjustments. For example, clojure.zip in Clojure and clojure.zip in ClojureScript are nearly identical. With a little effort, purely algorithmic code can be made portable between implementations. However, trying to abstract over all the differences among host platforms has never been a goal of Clojure, nor will it be a goal of ClojureScript.
We have a ClojureScript JIRA instance set up to track bugs. As with Clojure itself, submitting patches requires signing the Clojure Contributor Agreement. We can only accept patches through JIRA, not GitHub pull requests.
The Relationship to Google Closure
Google has led the way in developing rich client-side applications in JavaScript. Because Google needs the Web to succeed as an application-delivery platform, they have released some of their JavaScript tools as open source under the name Closure. The homophonic name clash is unfortunate, but not something we can do anything about.
Google Closure is a suite of tools for delivering complex JavaScript applications to memory-constrained devices over slow connections. It consists of three parts: a large library of JavaScript classes and functions, a client-side templating system, and an optimizing JavaScript compiler. These parts are designed to work in symbiosis.
The Google Closure compiler is a sophisticated JavaScript-to-JavaScript compiler that performs whole-program analysis to inline and rearrange code for optimal performance on modern JavaScript runtimes. Most importantly, it eliminates unused or unreachable code. The Google Closure compiler makes it possible to have a large library of JavaScript functions written in a straightforward manner without concern for code size, and to deliver minified versions of only the code your application needs. However, taking full advantage of the Google Closure compiler requires adherence to strict conventions for JavaScript source code.
The ClojureScript compiler emits JavaScript which follows Google Closure’s code conventions, and then invokes the Google Closure compiler to generate compact, optimized JavaScript for delivery to clients. ClojureScript also makes use of the Google Closure library for capabilities such as event handling, DOM manipulation, and user interface widgets.
It is possible to use ClojureScript with JavaScript libraries other than Google Closure, but those libraries typically do not follow the conventions of the Google Closure compiler and therefore will not be able to take full advantage of its optimizations.
What ClojureScript is Not
ClojureScript is not Clojure implemented in JavaScript.
The Clojure community has tried various ways of generating JavaScript from Clojure in the past. One early attempt by Chris Houser, also called ClojureScript, used JavaScript as a implementation language for the core data structures and compiler, the way the current version of Clojure uses Java.
The new ClojureScript does not take this approach. Instead, ClojureScript is written entirely in Clojure, as a compiler which emits JavaScript and a large library of functions. Therefore, ClojureScript does not aim to provide a complete development environment in JavaScript. There is no eval and no runtime access to the ClojureScript compiler from within ClojureScript.
ClojureScript is not JavaScript with Clojure syntax.
Another approach sometimes used to overcome JavaScript’s syntactic shortcomings is to layer another syntax on top of it while keeping all of the JavaScript language semantics. Parenscript and CoffeeScript are examples of this approach.
ClojureScript has the same language semantics as Clojure, not JavaScript. The ClojureScript compiler emits JavaScript, similar to the way the Clojure compiler emits Java bytecode.
How We Got Here
ClojureScript was initially developed by Rich Hickey, creator of Clojure. Members of the Clojure/core team, along with others invited from the Clojure community, have participated in the development of the compiler.
Where to Learn More
-
\#clojure IRC on Freenode
Why is communication so difficult?
Sometimes I will talk to somebody, and think that I’m expressing myself really clearly when I’m not. I seem to make perfect sense. Yet when I hear what the other person says in response, it is obvious that they heard something quite different from what I thought I said.

State machines are wonderful tools
null program 06 07 2021
Effects of Fortuna
null program 06 07 2021
The cost of Java's EnumSet
null program 06 07 2021
How to build and use DLLs on Windows
null program 06 07 2021
August 2019 Alpha
Release notes from darling 06 07 2021
December 2019 Alpha
Release notes from darling 06 07 2021
Alpha: January 3, 2020
Release notes from darling 06 07 2021
Alpha: March 16, 2020
Release notes from darling 06 07 2021
Alpha: March 31, 2020
Release notes from darling 06 07 2021
YAVP
code · words · emotions: Daniel Janus’s blog 06 07 2021
News
Planet Clojure 06 07 2021
More On Types
Planet Clojure 06 07 2021
Announcing Alda 2
Planet Clojure 06 07 2021
REPL vs CLI: IDE wars
Planet Clojure 06 07 2021
Pre and post conditions in Clojure
Planet Clojure 06 07 2021
Time traveling with Fluree
Planet Clojure 06 07 2021
Announcing Clojure Morsels
Planet Clojure 06 07 2021
Clojure Deref (July 2, 2021)
Planet Clojure 06 07 2021
Debugging in Clojure
Planet Clojure 06 07 2021
What if data is a really bad idea?
Planet Clojure 06 07 2021
What are the Clojure Tools?
Planet Clojure 06 07 2021
What the Reagent Component?!
Planet Clojure 06 07 2021
737 Max 8
The Clean Code Blog 06 07 2021
Types and Tests
The Clean Code Blog 06 07 2021
Classes vs. Data Structures
The Clean Code Blog 06 07 2021
Why won't it...
The Clean Code Blog 06 07 2021
Why Clojure?
The Clean Code Blog 06 07 2021
Circulatory
The Clean Code Blog 06 07 2021
A New Hope
The Clean Code Blog 06 07 2021
A Little Clojure
The Clean Code Blog 06 07 2021
A Little More Clojure
The Clean Code Blog 06 07 2021
REPL Driven Design
The Clean Code Blog 06 07 2021
The Disinvitation
The Clean Code Blog 06 07 2021
Conference Conduct
The Clean Code Blog 06 07 2021
Loopy
The Clean Code Blog 06 07 2021
Solid Relevance
The Clean Code Blog 06 07 2021
Pairing Guidelines
The Clean Code Blog 06 07 2021
if-else-switch
The Clean Code Blog 06 07 2021
On Types
The Clean Code Blog 06 07 2021
More On Types
The Clean Code Blog 06 07 2021
![]()